实验-产生式系统(python)
实验-产生式系统
- 实验内容
- 实验数据
-
- 规则库
- 实验关键步骤
- 实验要求
- 实验过程
-
- 数据保存
- 代码展示
-
- 不带GUI界面(命令行界面)
- GUI界面
- 实验结果
-
- 命令行界面
- GUI界面
实验内容
本实验要求创建一个植物识别系统,根据输入特征判断库中是否存在该植物,并输出查找结果
实验数据
规则库
R1:种子有果皮 -> 被子植物
R2:种子无果皮 -> 裸子植物
R3:无茎叶 & 无根 -> 藻类植物
R4:被子植物 & 有托叶 -> 蔷薇科
R5:被子植物 & 吸引菜粉蝶 -> 十字花科
R6:被子植物 & 十字形花冠 -> 十字花科
R7:被子植物 & 缺水环境 -> 仙人掌科
R8:被子植物 & 蔷薇科 & 有刺 -> 玫瑰
R9:被子植物 & 水生 & 可食用 & 结果实 -> 荷花
R10:被子植物 & 仙人掌科 & 喜阳 & 有刺 -> 仙人球
R11:藻类植物 & 水生 & 药用 -> 水棉
R12:被子植物 & 蔷薇科 & 木本 & 可食用 & 结果实 -> 苹果树
R13:被子植物 & 十字花科 & 黄色花 & 可食用 & 结果实 -> 油菜
R14:藻类植物 & 水生 & 可食用 & 有白色粉末 -> 海带
R15:裸子植物 & 木本 & 叶片针状 & 结果实 -> 松树
实验关键步骤
1.根据已知的数据建立数据库,存储植物个体(玫瑰、荷花、仙人球、水棉、苹果树、油菜、海带、松树)、个体特征等
2.实现规则编码
3.实现推理:综合数据库存储初始已知事实,控制系统将其与已有知识进行匹配,被触发的知识,将其结论作为新的事实添加到综合数据库中。重复上述过程,用更新过的综合数据库中的事实再与知识库中另一条知识匹配,将其结论更新至综合数据库中,直到没有可匹配的新知识和不再有新的事实加入到综合数据库中为止。
4.根据最终的综合数据库得到结论,判断是否得到植物名,是则返回植物名,否则提示该系统中未找到匹配对象。
实验要求
1.展现推理过程(即综合数据库的变化)。
2.对应各种特征情况系统都需要有响应。
3.交互界面
实验过程
数据保存
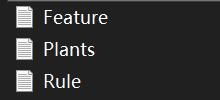
将题目所给的规则库数据,分别保存到三个文本中,分别是:所有特征,植物名称,规则。以便后续的再添加,如图所示:



代码展示
不带GUI界面(命令行界面)
Plants = [] # 目标植物库
Feature = [] # 特征信息库
Rules = [] # 规则库
dy_data = [] # 综合数据库
tested_1 = [] # 存放当轮测试成功的规则,若为空,则匹配失败 ,!!!切记每新一轮都要设置为空
tested_2 = [] # 存放所有轮匹配成功的规则,避免重复匹配
def Database(file1, file2, file3): # 导入文件内容,建立相关库
with open(file1, 'r', encoding='utf8') as f1:
for line in f1.readlines():
line = str(line).split()
Plants.extend(line)
f1.close()
with open(file2, 'r', encoding='utf8') as f2:
for line in f2.readlines():
line = str(line).split()
Feature.extend(line)
f2.close()
with open(file3, 'r', encoding='utf8') as f3:
for line in f3:
line = line.split()
Rules.append(line)
f3.close()
def inference(): # 控制系统
flag = 1 # 标记是否匹配成功
while (flag):
if (dy_data[-1] in Plants): # 得出结果后退出匹配
return dy_data[-1]
else:
tested_1 = [] # 切记每新一轮要重新赋值
for i in range(len(Rules)): # 用规则库的规则去一一检查现有的规则
if (Rules[i] in tested_2): # 防止规则重复匹配
pass
else:
sub = Rules[i][:-1] # Rules[i][-1]是结论
for j in sub:
if (j not in dy_data): # 该规则前件不符合
break
if (j == sub[-1]):
if (Rules[i][-1] not in dy_data): # 避免匹配到的规则后件重复加入
dy_data.append(Rules[i][-1])
print("匹配的规则是:", *Rules[i])
print("目前的综合数据库中的信息为:", *dy_data)
tested_1.append(Rules[i])
tested_2.append(Rules[i])
if (tested_1 == []): # 当前现有的规则已经没有规则库里的规则可以与之匹配了,失败
flag = 0
return False
file1_path = "D:/Plants.txt"
file2_path = "D:/Feature.txt"
file3_path = "D:/Rule.txt"
Database(file1_path, file2_path, file3_path)
print("所有植物的特征信息的知识库有:")
for i in range(len(Feature)): # 使输出有序
if (i == 0):
print(str(i + 1) + ":", Feature[i], " ", end=" ")
elif (i % 5 != 0):
print(str(i + 1) + ":", Feature[i], " ", end=" ")
else:
print("\n" + str(i + 1) + ":", Feature[i], " ", end=" ")
print("\n")
num = [] # 存储信息序号
num.append(list(map(int, input("请输入已有特征信息的序号:").split()))) # 放进去的为一整个数组
for i in num[0]: # 将初始的已知信息放入综合数据库
dy_data.append(Feature[i - 1])
print("您初始输入的植物特征信息有:")
print(*dy_data)
infer = inference()
print("您得到的答案是:", infer)
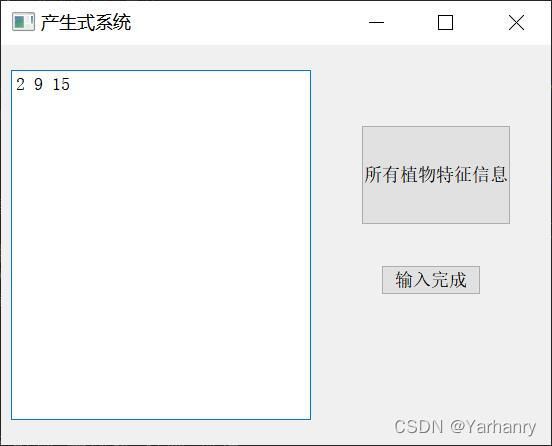
GUI界面
from PySide2.QtWidgets import QApplication, QMainWindow, QPushButton
from PySide2.QtWidgets import QPlainTextEdit
from PySide2.QtWidgets import QMessageBox
# 2 9 15 为玫瑰
Plants = [] # 目标植物库
Feature = [] # 特征信息库
Rules = [] # 规则库
dy_data = [] # 综合数据库
tested_1 = [] # 存放当轮测试成功的规则,若为空,则匹配失败 ,!!!切记每新一轮都要设置为空
tested_2 = [] # 存放所有轮匹配成功的规则,避免重复匹配
num = [] # 存储初始所得信息的序号
mid_result = [] # 保存中间结果(匹配的规则,数据库变化等)的信息
class GUI(): # 与用户交互
def __init__(self):
self.window = QMainWindow()
self.window.resize(550, 400)
self.window.move(300, 310)
self.window.setWindowTitle('产生式系统')
self.textEdit = QPlainTextEdit(self.window)
self.textEdit.setPlaceholderText("请输入已有特征信息的序号(以空格分隔)")
self.textEdit.move(10, 25)
self.textEdit.resize(300, 350)
self.button1 = QPushButton('输入完成', self.window)
self.button1.move(380, 220)
self.button1.clicked.connect(self.handle)
self.button2 = QPushButton('所有植物特征信息', self.window)
self.button2.resize(150, 100)
self.button2.move(360, 80)
self.button2.clicked.connect(self.display_init)
def handle(self):
global num
init_info = [] # 存放初始输入的信息
info = self.textEdit.toPlainText()
num = list(map(int, info.split()))
for i in num: # 将初始的已知信息放入综合数据库
dy_data.append(Feature[i - 1])
init_info.append(Feature[i - 1])
infer = inference()
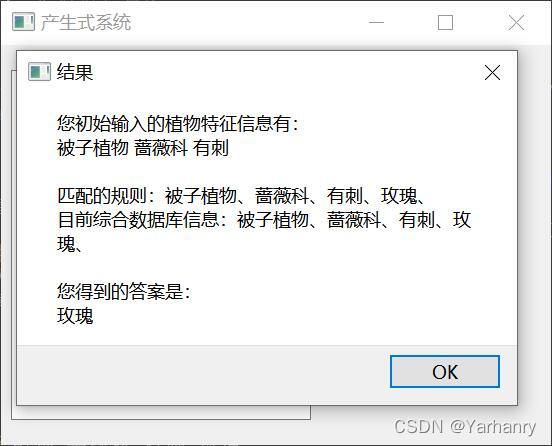
QMessageBox.about(
self.window, '结果', f'''您初始输入的植物特征信息有:\n{' '.join(init_info)}
\n{' '.join(mid_result)}
\n您得到的答案是:\n{infer}''')
def display_init(self): # 显示特征信息
info = []
for i in range(len(Feature)): # 使输出有序
s = "%d: %s " % (i + 1, Feature[i])
info.append(s)
QMessageBox.about(self.window, '所有植物特征信息',
f'''如下:\n\n{' '.join(info)}''')
def Database(file1, file2, file3): # 导入文件内容,建立相关库
with open(file1, 'r', encoding='utf8') as f1:
for line in f1.readlines():
line = str(line).split()
Plants.extend(line)
f1.close()
with open(file2, 'r', encoding='utf8') as f2:
for line in f2.readlines():
line = str(line).split()
Feature.extend(line)
f2.close()
with open(file3, 'r', encoding='utf8') as f3:
for line in f3:
line = line.split()
Rules.append(line)
f3.close()
def inference(): # 控制系统
flag = 1 # 标记是否匹配成功
while (flag):
if (dy_data[-1] in Plants): # 得出结果后退出匹配
return dy_data[-1]
else:
tested_1 = [] # 切记每新一轮要重新赋值
for i in range(len(Rules)):
if (Rules[i] in tested_2): # 防止规则重复匹配
pass
else:
sub = Rules[i][:-1]
for j in sub:
if (j not in dy_data): # 该规则前件不符合
break
if (j == sub[-1]):
if (Rules[i][-1] not in dy_data): # 避免匹配到的规则后件重复加入
dy_data.append(Rules[i][-1])
s = "匹配的规则:"
for g in Rules[i]:
s += g
s += '、'
mid_result.append(s)
ss = "目前综合数据库信息:"
for g in dy_data:
ss += g
ss += '、'
mid_result.append(ss)
tested_1.append(Rules[i])
tested_2.append(Rules[i])
if (tested_1 == []):
flag = 0 # 匹配失败,查找不到
return False
file1_path = "D:/Plants.txt"
file2_path = "D:/Feature.txt"
file3_path = "D:/Rule.txt"
Database(file1_path, file2_path, file3_path)
app = QApplication([])
gg = GUI()
gg.window.show()
app.exec_()
实验结果
命令行界面

GUI界面