前后端对接规范初版
写在前面
我认为且希望的工作流程。
1、收到客户新需求
2、产品经理初筛功能并完成原型以及功能点文档(原型需注明每个交互,功能点文档利于管理)
3、项目组开会,产品讲解业务逻辑和功能点,技术人员确定需求可行性
4、分配技术人员,准备开发
5、前后端对接接口返回结构,排查可能出现的问题,满足前后端代码友好,前端性能不受到影响
6、书写接口文档,注明接口中返回字段所对应的内容
7、根据接口文档拿到mock的demo数据,前端先开始开发
8、真实接口完成,前端接入真实接口
9、不断的测试、迭代,中途出现的问题放在版本管理工具中便于查看和确认
10、完成新功能迭代。
谈谈接口
随着前后端的分离,后端工程师不需要编写页面,不需要写JS,只需要提供接口即可,可是就是仅仅这一个接口,对于很多后端开发工程师而言,在实际开发,同前端对接的过程中,依然问题重重
很多后端同学说我只负责写接口,其他我一概不管,这样造成的后果就是
1、接口结构无序、杂乱无章
2、接口和实际业务场景不相匹配、不可用
3、频繁的同前端沟通,简单的事情复杂化,前后端都很恼火
4、事情没做好
后端在编写接口前,首先是对业务的理解,在对业务未理解透彻之前,编码都是无意义的,作为后端来说,需要锻炼自己对整个系统全局考虑的能力,接口之间并非是毫无关联的,我们在写第一个接口之间,其他接口之间的业务逻辑也许考虑到,这在后端团队合作开发不同功能的情况下显得尤为重要.
后端在开发接口时,我觉得主要从以下几个方面需要注意:
接口url 定义
接口类型、参数
全局错误码定义
接口json格式
接口文档编写
接口url定义
对于后端开发人员来说,接口前端入参,最终组合查询数据库资源,经过一系列相关业务场景下的计算,响应给前端json数据,每一层url的path定义需要清晰明了,这和后端在使用AOP定义事务管理同理,后端service需要满足一定的命名规范,这样方便统一管理,而且有这层规范后,后续的前后端对接会轻松很多
为了在许多API和长时间内提供一致的开发人员体验,API使用的所有名称应为:
-
简单
-
直觉
-
一致
这包括接口,资源,集合,方法和消息的名称。
由于许多开发人员不是英文母语人士,因此这些命名约定的目标之一是确保大多数开发人员能够轻松了解API。 它通过鼓励在命名方法和资源时使用简单,一致和小的词汇表来实现。
-
API中使用的名称应该是正确的美国英语。例如,许可证(而不是许可证),颜色(而不是颜色)。
-
可以简单地使用常用的简短形式或长字的缩写。例如,API优于应用程序编程接口。
-
尽可能使用直观,熟悉的术语。例如,当描述删除(和销毁)资源时,删除是优先于擦除。
-
对同一概念使用相同的名称或术语,包括跨API共享的概念。
-
避免名称重载。为不同的概念使用不同的名称。
-
仔细考虑使用可能与常用编程语言中的关键字冲突的名称。可以使用这些名称,但在API审查期间可能会触发额外的审查。谨慎和谨慎地使用它们。
接口类型、参数
关于接口的请求类型,目前比较常用的:GET、POST、PUT、DELETE、PATCH
GET(SELECT):从服务器取出资源(一项或多项)。
POST(CREATE):在服务器新建一个资源。
PUT(UPDATE):在服务器更新资源(客户端提供改变后的完整资源)。
PATCH(UPDATE):在服务器更新资源(客户端提供改变的属性)。
DELETE(DELETE):从服务器删除资源。
后端可根据不同的业务场景定义不同的接口类型
在定义接口参数之时,目前我们常用的几种提交方式
表单提交,application/x-www-form-urlencoded

表单提交主要针对key-value的提交形式
如下Java片段:
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
文件流提交
json提交,application/json
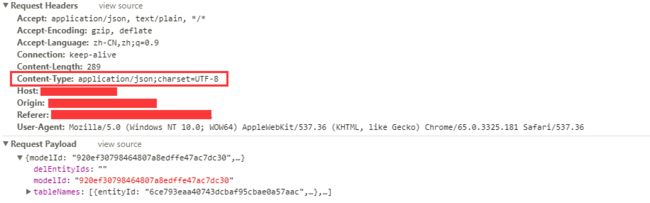
json提交方式在SpringMVC或Spring Boot中主要有两种,一种是以@RequestBody注解接收方式,另外一种是以HttpEntity字节接收
Java代码示例:
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
全局错误码定义
错误码的定义同HTTP请求状态码一样,对接者能通过系统定义的错误码,快速了解接口返回错误信息,方便排查错误原因
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
接口json格式
后端响应json给前端需要注意以下几点:
1、json格式需固定
例如如下图形
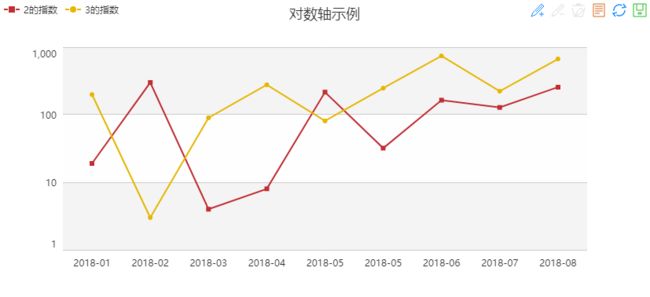
如上图所示,横向是时间,纵向是value值
我们给出的json结构应该如此:
| 1 2 3 4 5 6 7 8 9 10 11 |
|
在工作中,我们经常碰见这样的数据格式:
| 1 2 3 4 5 6 7 8 9 |
|
这里所说的json格式固定主要针对此种情况,后端给到前端的接口格式必须是固定的,所有动态数据值都需相应的key与之对应
2、所有返回接口数据需直接可用,越简单越好
后端提供给前端的接口数据,最终交给前端的工作,只需要让前端渲染数据即可,越简单越好,不应掺杂过多的业务逻辑让前端处理,所有复杂的业务逻辑,能合并规避掉的都需后端处理掉。
接口文档编写
接口文档编写是前后端对接重要依据,后端写明接口文档,前端根据接口文档对接。
接口文档需注明字段对应页面内容。不写接口文档的坏处:
第一:前后端开发没有标准,没有依据。
第二:容易扯皮,没法追踪,职责不清。
第三:开发效率低。等等。
文档形势目前主要分几种:
1、依赖swagger框架,自动生成接口文档(swagger只能生成基于key-value详细参数方式,针对json格式,无法说明具体请求内容)
2、手动编写说明文档,推荐markdown编写
在这里多说几句,渲染页面是前端去做,复杂的逻辑极大影响页面的加载速度和浏览器性能,我举出几个现在发现的问题。
1、需要顺序显示的内容返回值为中文key:value 的对象。这个结构没有索引没有顺序,且中文key这种低级的不符合前后端规范的错误希望能够规避。这种数据前端处理很复杂影响性能,代码不必要的逻辑增加,代码冗余。
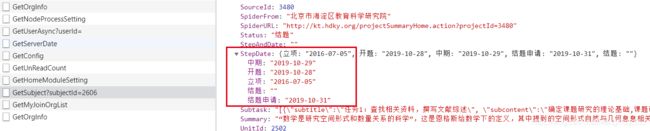
像这种有多个内容,且有顺序的数组应返回结构如下。
StepDate: [
{
name:'立项',
date:'2016-07-05'
},
{
name:'开题',
date:'2019-10-28'
},
{
name:'中期',
date:'2019-10-29'
},
{
name:'结题申请',
date:'2019-10-31'
},
{
name:'结题',
date:null
}
]
贴上目前前端处理的代码,这些不必要的逻辑代码都可以省略的。

2、如果返回值是数组或字符串,转成该结构再返回,避免直接返回字符串等前端处理。

对象数组直接返回了字符串,还有其他的也一样。
![]()
前端现在需自己转成需要的格式,多此一举,这点简单东西后端应该处理好再返回。
3、如果是有逻辑需要增加或者展示的、需要遍历的数据,返回数组。

举例来说,关键词需要区分为每个,后端返回字符串后,前端只能自己进行字符串的拆分,转换为数组结构,重新遍历并渲染,增加了不必要的逻辑,影响性能。
现在前端逻辑部分增加了返回值的重构
![]()
在渲染部分还增加了重新渲染的逗号,等同于多做了很多无用功。
![]()
4、接口中无数据内容的字段,统一返回null(有定义的字段必须返回,不可undefined)
现在的返回值什么状态都有,有空数组,有null,有没返回的,前端做处理很冗余和麻烦。

暂时只发现这些问题,并不是很复杂的数据处理,但是很影响前端性能,本就该是后端处理的,后端稍微用心点就可以规避这些问题,提出了问题可以商讨和解决问题而不是一味地反驳,问题的解决需要充分的沟通。所以综上所述,在每次新接口开发前先对接一下前后端双方都合适的数据结构,磨合成默契的前提后可以不再每次进行对接,从而共同优化项目。
接口对接
万事俱备,只欠东风,虽然上面我们准备了所有我们该准备的,接口定义完美无缺,接口文档也已说明,但在对接时任然可能出现问题,此时我想我们还需注意的细节
1、后端接口需自行进行Junit单元测试
Spring目前集成Junit框架可方便进行单元测试,包括对业务bean的方法测试,以及针对api的mock测试
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
|
2、使用工具测试,推荐PostMan
作为接口调试神器,Postman大名想必大家都已知道
作为后端来说,我们需要学会查看chrome推荐给我们的审查元素的功能,可参看Chrome开发工具介绍
chrome提供了一个可以copy当前接口的url功能,最终生成curl命令行
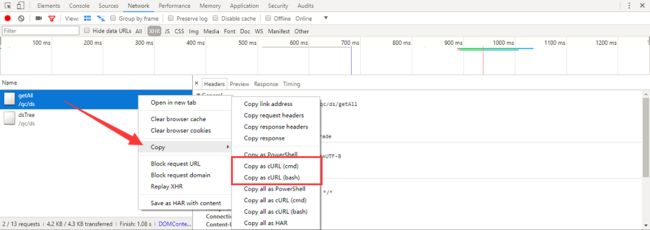
最终通过Copy as cURL(bash)功能可生成curl命令
| 1 |
|
以上命令可以在Linux等各终端直接执行
curl命令是一个利用URL规则在命令行下工作的文件传输工具。它支持文件的上传和下载,所以是综合传输工具,但按传统,习惯称curl为下载工具。作为一款强力工具,curl支持包括HTTP、HTTPS、ftp等众多协议,还支持POST、cookies、认证、从指定偏移处下载部分文件、用户代理字符串、限速、文件大小、进度条等特征。做网页处理流程和数据检索自动化,curl可以祝一臂之力。
postman提供导入curl命令行

3、前后端需心平气和沟通,勿推卸责任,前后端开发人员水平不尽相同,作为同事,需要的是团结合作,努力将事情做好,而非相互推卸责任。
最后希望项目能够越做越好,公司蒸蒸日上。