【DeepLizard】Pytorch神经网络编程学习笔记(第二部分)
视频地址(B站):适用于初学者的PyTorch神经网络编程教学
课程官方博客地址:DEEPLIZARD
个人笔记第一部分:DeepLizard:Pytorch神经网络编程教学(第一部分)
说明:
- 笔记为个人学习笔记,如有错误,欢迎指正。
- 本篇笔记整理的内容为课程的第二部分,对应视频为 P 14 ∼ P 43 P_{14}\sim P_{43} P14∼P43
- DeepLizard课程为全英文授课,B站视频为中文字幕,且每个视频都有配套的博客与课后测试题。
文章目录
- Section 1:数据和数据处理
-
- P14:fashion-mnist数据集
- P15:使用torchvision演示一种简单的提取、转换和加载流程(ETL)
-
- ETL过程
- 使用PyTorch准备数据
-
- PyTorch Dataset Class
- PyTorch DataLoader Class
- P16:使用DataSet和DataLoader
-
- 查看数据
- 访问训练集中的数据
- PyTorch DataLoader:处理成批的数据
- Section 2:神经网络和 PyTorch 设计
-
- P17:构建PyTorch CNN
-
- 一些包和函数
- 构建神经网络
- P18:CNN层,理解构建CNN时使用的参数
-
- CNN层
- CNN层参数
- P19:CNN内部的权重张量
-
- 可学习参数
- 获取实例网络
- 访问层的权重
- 权重张量形状
- 权重矩阵
- P20:PyTorch可调用的神经网络模块,以及网络和层的前向方法是如何调用的
-
- Linear类中的权重
- 特殊的调用方法:__call()__函数
- P21:调试PyTorch源代码
- P22:实现一个卷积神经网络的前向方法
- P23:使用卷积神经网络由数据集的样本输入生成输出预测答案
- P24:将一批图像传递到网络并解释输出
- P25:一个输入张量在通过CNN的过程中的变化
-
- CNN输出尺寸公式(方形)
- CNN输出尺寸公式(非方形)
- Section 3:训练神经网络
-
- P26:训练卷积神经网络(单个批次)
-
- 训练卷积神经网络所需的步骤
- 代码实现
- P27:构建一个卷积神经网络的训练循环
- P28:构建混淆矩阵
- P29:拼接张量和堆叠张量
- P30:使用tensorboard来可视化CNN在网络训练过程中的指标
- P31:神经网络超参数
-
- 每次修改单个超参数值
- 循环遍历不同的超参数值
- 添加更多的参数
- Section 4:神经网络实验#
-
- P32:编写Run Builder类,使不同的参数值生成多个运行
- P33:同步超参数测试
- P34:加速神经网络训练过程
- P35:使用 CUDA 训练神经网络
-
- tensor with CUDA
- network with CUDA
- 检测系统中CUDA能否使用
- GPU vs CPU
- P36:数据集规范化
-
- 均值和标准差
- 归一化和不归一化的效果区别
- P37:调试PyTorch 数据加载器源代码
- P38:使用Sequential类来建立神经网络的顺序
-
- 准备工作
- 建立神经网络的顺序
-
- 方式一
- 方式二
- 方式三
- 使用Sequential类建一个Network类
-
- 原始Network
- 方式一
- 方式二
- 方式三
- 预测image
- P39:PyTorch 中的批处理规范
-
- 创建网络
- 准备数据
- 测试
- Section 5:补充学习
-
- P40:重置reset网络的权重
-
- 重置单个层的权重
- 重置网络中的层的权重
-
- all weights layer by layer
- all weights using snapshot
- all weights using re-initialization
- P41:改进测试框架
- P42:Max Pooling vs No Max Pooling
- P43:结束课程
Section 1:数据和数据处理
对应视频: P 14 ∼ P 16 P_{14}\sim P_{16} P14∼P16
P14:fashion-mnist数据集
略。
P15:使用torchvision演示一种简单的提取、转换和加载流程(ETL)
ETL过程
- Extract data from a data source. 从数据源中提取数据。
- Transform data into a desirable format. 将数据转换为所需的格式。
- Load data into a suitable structure. 将数据加载到合适的结构中。
使用PyTorch准备数据
torchvision包,它可以使我们访问以下资源:Datasets;Models;Transforns;Utils
PyTorch Dataset Class
如要使用torchvision获取FashionMNIST数据集,可以通过以下代码实现:
train_set = torchvision.datasets.FashionMNIST(
root='./data'
,train=True
,download=True
,transform=transforms.Compose([
transforms.ToTensor()
])
)
| 参数 | 说明 |
|---|---|
| root | 磁盘上数据所在的位置 |
| train | 数据集是否是训练集 |
| download | 是否下载数据 |
| transform | 应对数据集元素执行的转换组合 |
当第一次运行完此代码后,FashionMNIST数据集将会下载到本地。
PyTorch DataLoader Class
为训练集创建一个DataLoader包装器:
train_loader = torch.utils.data.DataLoader(train_set
,batch_size=1000
,shuffle=True
)
P16:使用DataSet和DataLoader
查看数据
# 查看训练集中有多少图像
len(train_set) # 6000
# 查看每个图像的标签
train_set.targets # tensor([9, 0, 0, ..., 3, 0, 5])
# 查看数据集中每个标签有多少个
train_set.targets.bincount() # tensor([6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000])
访问训练集中的数据
sample = next(iter(train_set))
len(sample) # 2
为访问训练集中的单个元素,先将train_set传给函数iter(),该函数返回一个表示数据流的对象,之后就可以用Python的内置函数next()来获取数据流中的下一个数据元素。
由函数的输出可知,每个样本(sample)包含两项,这是数据集中包含的图像标签对。可以使用序列解包来分配图像和标签:
image, label = sample
print(type(image)) # 查看元素:
print(image.shape) # torch.Size([1, 28, 28])
print(torch.tensor(label).shape) # torch.Size([])
# 调用squeeze(),删除维度
print(image.squeeze().shape) # torch.Size([28, 28])
绘制图像:
plt.imshow(image.squeeze(), cmap='gray')
print(torch.tensor(label)) # tensor(0)
# 说明:这里sample为train_set[2],也就是第三个元素,它的标签为0,对照上面的train_set.targets输出,可以看到第三个图像的标签就是0

PyTorch DataLoader:处理成批的数据
# 先创建一个批处理大小为10的数据加载程序:
display_loader = torch.utils.data.DataLoader(train_set, batch_size = 10)
# 注意:当shuffle=True时,每个batch都会不同
batch = next(iter(display_loader))
print(len(batch)) # 2
# 查看返回批次的长度
images, labels = batch
print(type(images)) #
print(type(labels)) # 绘制一批图像:
# 绘制一批图像
# 方法一:
grid = torchvision.utils.make_grid(images, nrow=10)
plt.figure(figsize=(15,15))
plt.imshow(np.transpose(grid, (1,2,0)))
# 方法二:
grid = torchvision.utils.make_grid(images, nrow=10)
plt.figure(figsize=(15,15))
plt.imshow(grid.permute(1,2,0))

Section 2:神经网络和 PyTorch 设计
P17:构建PyTorch CNN
一些包和函数
-
nn.Module
PyTorch的神经网络库中包含了构建神经网络所需的所有典型组件。深度神经网络是使用多层构建的,神经网络中每一层都有两个主要组成部分:变换(代码),权重的集合(数据)。PyTorch中的nn.Module是所有包含层的神经网络模块的基类,这意味着PyTorch中的所有层都扩展了nn.Module。
-
forward()
前向传播:当把一个张量传递给我们的网络作为输入,张量通过每个层变换向前流动,直到张量达到输出层。这个通过网络向前流动的张量的过程被称为前向传播。每一层都有它自己的变换,张量向前通过每一层的变换。所有单独的层的前向传播的组合定义了网络本身的整体向前转换。
在PyTorch中,每个nn.module都有一个前向方法来代表前向传输。因此在神经网络中构建层时,必须提供前向方法(forward method)的实现,前向方法就是实际的变换。
-
nn.functional
nn.functional包为我们提供了许多可用于构建层的神经网络操作。
构建神经网络
在 PyTorch 中构建神经网络的大纲:
- 创建一个扩展神经网络模块基类的神经网络类
- 在类构造函数中将网络的层定义为类属性
- 使用网络层属性以及nn.functional API的操作来定义网络的前向传播forward()
import torch.nn as nn
# 基础版
class Network:
def __init__(self):
self.layer = None # 层
def forward(self, t): # 前向传播函数
t = self.layer(t)
return t
# 进阶版
class Netword(nn.Module): # 定义一个扩展基类的神经网络类
def __init__(self):
super().__init__()
# 卷积层
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)
# 线性层
self.fc1 = nn.Linear(in_features=12 * 4 * 4, out_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=60)
self.out = nn.Lineat(in_features=60, out_features=10)
def forward(self, t):
# t = self.layer(t)
return t
P18:CNN层,理解构建CNN时使用的参数
CNN层
在P17中,我们定义了两个卷积层和三个线性层。我们的每一层都扩展了PyTorch的神经网络模块基类。
对于每一层,有两个主要项目封装其中:前向函数定义和权重张量。每层中的权重张量包含了随着我们的网络在训练过程中学习而更新的权重值。在神经网络模块类中,PyTorch可以跟踪每一层的权重张量。由于我们扩展了神经网络模块基类,我们自动继承了这个功能。
CNN层参数
parameter 和 argument
- parameter在函数定义中使用,由于这个原因,我们可以把参数看成是占位符。
- argument是当函数被调用时传递给函数的实际值。
- 或者说,parameter是形参,argument是实参
超参数和数据相关超参数 - 超参数的值是手动设置和任意选择的,主要是根据试错来选择超参数的值,并更多地使用过去已被证明有效的值。e.g. CNN层中的超参数
- kernel_size:内核大小设置了在该层中使用的滤波器的大小。(在DL中,内核kernel和滤波器filter是一个意思,所以卷积核和卷积滤波器是一个东西)
- out_channels:设置滤波器的深度。这是滤波器的内核数。(在一个卷积层中,输入通道与一个卷积滤波器配对来执行卷积运算。滤波器包含输入通道,这个操作的结果是一个输出通道。所以一个包含输入通道的滤波器可以给我们一个相应的输出通道。因此我们在设置输出通道数时,其实是在设置滤波器的数量。)
- out_features:设置输出张量的大小。
- 数据相关超参数是其值依赖于数据的参数。e.g. 第一个卷积层in_channels和输出层out_features。
P19:CNN内部的权重张量
可学习参数
可学习参数是在训练过程中学习的参数。对于可学习参数,通常重一组任意的值开始,当网络学习时,这些值就会以迭代的方式更新。
可学习参数是网络内部的权重,它们存在于每一层中。
获取实例网络
network = Network()
print(network)
# 输出
Network(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 12, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=192, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=60, bias=True)
(out): Linear(in_features=60, out_features=10, bias=True)
)
- kernel_size=(5, 5):当我们传递单个数字时,层构造函数假定我们想要的是一个方形滤波器。
- stride=(1, 1):告诉conc层在每次卷积操作后滤波器应该滑动多远。
访问层的权重
network.conv1.weight
其输出是一个张量,其中的值或标量分量是我们网络的可学习参数。当网络训练时,这些权重值会以一种方式更新,以使损失函数最小化。
权重张量形状
传递给层的参数值将直接影响网络的权重。
对于卷积层,权重值位于滤波器内部,在代码中,滤波器实际上是权重张量本身。层内的卷积操作是层的输入通道与层内的滤波器之间的操作。
network.conv1.weight.shape
# 输出:torch.Size([6, 1, 5, 5])
- 第一个轴的长度为6,这说明有6个滤波器。
- 第二个轴的长度为1,说明只有单个输入通道。
- 第三、四个轴的数值代表滤波器的高度和宽度。
network.conv2.weight.shape
# 输出:torch.Size([12, 6, 5, 5])
- 第二个conv层有12个滤波器,说明有来自前一层的6个输入通道。
- 可以将值6看做是赋予每个滤波器一定的深度,滤波器没有迭代的卷积所有的通道,而是具有与通道数相匹配的深度。
关于这些卷积层的两个要点:滤波器使用一个张量来表示,张量内的每个滤波器也有一个深度来说明正在卷积的输入通道数。
这里的张量是秩为4的张量,第一个轴表示滤波器的数量;第二个轴表示每个滤波器的深度,对应于被卷积的输入通道数量;最后两个轴表示每个滤波器的高和宽。
( 滤波器数量,深度,高度,宽度 ) (滤波器数量,深度,高度,宽度) (滤波器数量,深度,高度,宽度)
权重矩阵
network.fc1.weight.shape # torch.Size([120, 192])
network.fc2.weight.shape # torch.Size([60, 120])
network.out.weight.shape # torch.Size([10, 60])
len(network.out.weight.shape) # 2
每个线性层都有一个秩为2的权重张量。以fc1的权重张量为例,由权重张量的形状可知,row120是输出特征的大小,column192是输入特征的大小,也就是说,权重张量的形状是根据输入特征和输出特征的大小得来的。通过矩阵乘法来直观感受:

线性层使用矩阵乘法来将它们的输入特征转换为输出特征:当输入特征被线性层接收时,它们以一个扁平的一维张量的形式传递,然后乘以权重矩阵,得到的结果就是输出特征。
这就是线性层的工作原理:它们使用一个权重矩阵将一个输入特征空间映射到一个输出特征空间。
P20:PyTorch可调用的神经网络模块,以及网络和层的前向方法是如何调用的
Linear类中的权重
定义输入特征和权重矩阵:
import torch
in_features = torch.tensor([1,2,3,4], dtype=torch.float32)
weight_matrix = torch.tensor([
[1,2,3,4],
[2,3,4,5],
[3,4,5,6]
],dtype=torch.float32)
执行矩阵乘法,由P19的内容可知,得到的输出就是输出特征out_features:
weight_matrix.matmul(in_features)
# 输出:tensor([30., 40., 50.])
定义一个线性层,输入特征大小为4,输出特征大小为3:
fc = nn.Linear(in_features=4, out_features=3)
这一步要注意的是:通过使用权重矩阵将4维空间映射到3维空间。权重矩阵位于PyTorch线性层类中,由PyTorch创造,PyTorch线性层类通过将4和3传递给构造函数,以创建一个3x4的权重矩阵
调用对象实例
fc(in_features)
# 输出:tensor([ 0.2730, -0.4860, -1.7627], grad_fn=)
这里的值[ 0.2730, -0.4860, -1.7627]与[30., 40., 50.]相差甚远,这是因为PyTorch创建了一个权重矩阵,并用随机值来初始化。
权重矩阵中的值定义了一个线性函数( y = A x + b y=Ax+b y=Ax+b)。这表明了在训练过程中,当权重被更新时,网络的映射是如何变化的,当更新权重时,我们在改变函数(更改了 A A A和 b b b)。
再使用新的输入进行测试:
fc.weight = nn.Parameter(weight_matrix)
fc(in_features)
# 输出:tensor([30.4673, 40.0535, 50.3319], grad_fn=)
输出结果更接近[30,40,50]但又不完全相等,这是因为有偏置值的存在。
特殊的调用方法:__call()__函数
如果一个类实现了特殊的__call()__方法,每当调用对象实例时,都会调用__call()__方法。
我们不直接调用前向方法forward(),而是调用对象实例,在调用对象实例之后,__call()__方法会被调用,而__call()__方法又反过来调用forward()方法。
PyTorch在__call()__方法中运行的额外代码是我们从未直接调用forward()方法的原因: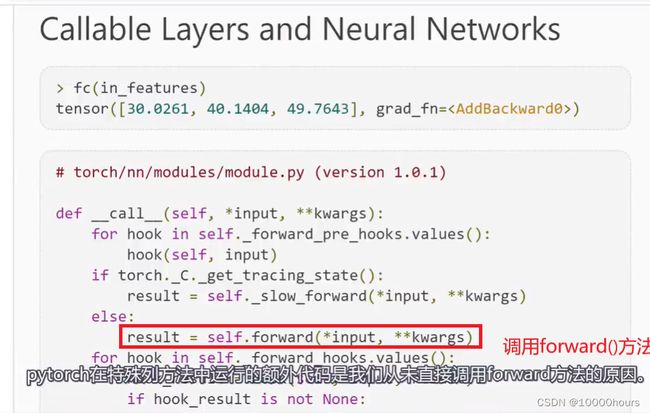
P21:调试PyTorch源代码
略
P22:实现一个卷积神经网络的前向方法
我们的forward()方法接收一个张量作为输入,然后返回一个张量作为输出。
forward()方法的实现将使用我们在构造函数中定义的所有层。forward()方法是输入张量到一个预测的输出张量的映射。
关于input layer:
- 任何神经网络的输入层都是由输入数据决定的。
- 比如,若输入张量中包含三个元素,那网络将有三个节点包含在它的输入层中,因此可将输入层看做恒等转换( f ( x ) = x f(x)=x f(x)=x)
- 输入层通常隐藏。但在以下代码中,将输入层用代码显示表示出来:
t = t
import torch
import torch.nn as nn
import torch.nn.functional as F
class Network(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)
self.fc1 = nn.Linear(in_features=12 * 4 * 4, out_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=60)
self.out = nn.Linear(in_features=60, out_features=10)
def forward(self, t):
# (1)输入层input layer(输入层在代码中通常隐藏)
t = t
# (2)卷积层 hidden conv layer t = self.conv1(t) # 其中封装了权重
t = F.relu(t)
t = F.max_pool2d(t, kernel_size=2, stride=2)
# (3)卷积层 hidden conv layer t = self.conv2(t) # 其中封装了权重
t = F.relu(t)
t = F.max_pool2d(t, kernel_size=2, stride=2)
# 注:每层都由一组权重和一组操作组成。
# 权重被封装在神经网络模块层类实例中:e.g. self.conv1(t)
# relu()和max_pool2d()都是操作
# 在把输入传递给第一个线性层之前,必须重塑张量。每当把卷积层的输出输入到一个线性层时,就会出现这种情况
# (4)线性层 hidden liner layer # 12是由之前的卷积层产生的输出通道数决定的
# 4 * 4是12个输出通道的高和宽
t = t.reshape(-1, 12 * 4 * 4)
t = self.fc1(t)
t = F.relu(t)
# (5)线性层 hidden liner layer t = self.fc2(t)
t = F.relu(t)
# (6)输出层 output layer t = self.out(t)
t = F.softmax(t, dim=1)
return t
P23:使用卷积神经网络由数据集的样本输入生成输出预测答案
再来理解一下前向传播:
- 前向传播是将输入张量转换为输出张量的过程。
- 神经网络是将输入张量映射到输出张量的函数,而前向传播只是将输入张量传递给网络并从网络接收输出的过程的一个特殊名称。
代码实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
torch.set_printoptions(linewidth=120)
# 建立训练集
train_set = torchvision.datasets.FashionMNIST(
root='./data/FashionMNIST'
,train=True
,download=True
,transform=transforms.Compose([
transforms.ToTensor()
])
)
# 建立模型
class Network(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)
self.fc1 = nn.Linear(in_features=12 * 4 * 4, out_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=60)
self.out = nn.Linear(in_features=60, out_features=10)
def forward(self, t):
# (1)输入层input layer(输入层在代码中通常隐藏)
t = t
# (2)卷积层 hidden conv layer
t = self.conv1(t) # 其中封装了权重
t = F.relu(t)
t = F.max_pool2d(t, kernel_size=2, stride=2)
# (3)卷积层 hidden conv layer
t = self.conv2(t) # 其中封装了权重
t = F.relu(t)
t = F.max_pool2d(t, kernel_size=2, stride=2)
# 注:每层都由一组权重和一组操作组成。
# 权重被封装在神经网络模块层类实例中:e.g. self.conv1(t)
# relu()和max_pool2d()都是操作
# 在把输入传递给第一个线性层之前,必须重塑张量。每当把卷积层的输出输入到一个线性层时,就会出现这种情况
# (4)线性层 hidden liner layer
# 12是由之前的卷积层产生的输出通道数决定的
# 4 * 4是12个输出通道的高和宽
t = t.reshape(-1, 12 * 4 * 4)
t = self.fc1(t)
t = F.relu(t)
# (5)线性层 hidden liner layer
t = self.fc2(t)
t = F.relu(t)
# (6)输出层 output layer
t = self.out(t)
t = F.softmax(t, dim=1)
return t
# 关闭PyTorch的梯度跟踪功能
torch.set_grad_enabled(False)
# 创建一个网络实例
network = Network()
# 获取样本并解压
sample = next(iter(train_set))
image, label = sample # image.shape:[1,28,28],一个颜色通道,高度和宽度均为28
# 当把数据传给网络时,网络期待的是一批数据,因此要将这些单张图像转换为一个批次
# 把单个样本图像张量放入一个大小为1的批次中,只需unsqueeze()方法来为张量增加一个额外的维度
image.unsqueeze(0) # [1, 1, 28, 28],批次大小为1
# 预测
pred = network(image.unsqueeze(0)) # 图像的形状应为(batch_size * in_channels * H * W)
# 至此,通过使用前向方法从网络得到了一个预测
# 网络返回一个预测张量,它包含了10个类别的预测值
print(pred) # tensor([[0.1183, 0.1015, 0.0903, 0.0977, 0.1076, 0.1084, 0.0925, 0.0954, 0.0982, 0.0901]])
P24:将一批图像传递到网络并解释输出
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
#torch.set_printoptions(linewidth=120)
# 建立模型
class Network(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)
self.fc1 = nn.Linear(in_features=12 * 4 * 4, out_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=60)
self.out = nn.Linear(in_features=60, out_features=10)
def forward(self, t):
# (1)输入层input layer(输入层在代码中通常隐藏)
t = t
# (2)卷积层 hidden conv layer
t = self.conv1(t) # 其中封装了权重
t = F.relu(t)
t = F.max_pool2d(t, kernel_size=2, stride=2)
# (3)卷积层 hidden conv layer
t = self.conv2(t) # 其中封装了权重
t = F.relu(t)
t = F.max_pool2d(t, kernel_size=2, stride=2)
# 注:每层都由一组权重和一组操作组成。
# 权重被封装在神经网络模块层类实例中:e.g. self.conv1(t)
# relu()和max_pool2d()都是操作
# 在把输入传递给第一个线性层之前,必须重塑张量。每当把卷积层的输出输入到一个线性层时,就会出现这种情况
# (4)线性层 hidden liner layer
# 12是由之前的卷积层产生的输出通道数决定的
# 4 * 4是12个输出通道的高和宽
t = t.reshape(-1, 12 * 4 * 4)
t = self.fc1(t)
t = F.relu(t)
# (5)线性层 hidden liner layer
t = self.fc2(t)
t = F.relu(t)
# (6)输出层 output layer
t = self.out(t)
t = F.softmax(t, dim=1)
return t
# 关闭PyTorch的梯度跟踪功能
torch.set_grad_enabled(False)
# 创建一个网络实例
network = Network()
# 建立训练集
train_set = torchvision.datasets.FashionMNIST(
root='./data/FashionMNIST'
,train=True
,download=False
,transform=transforms.Compose([
transforms.ToTensor()
])
)
# 数据加载器
data_loader = torch.utils.data.DataLoader(
train_set
,batch_size=10
)
batch = next(iter(data_loader)) # 一次返回10张图像
images, labels = batch # image.shape:[10, 1, 28, 28]; labels.shape:[10]
# 预测
preds = network(images)
# preds.shape:[10, 10],有10张图像,对于这10张图,有10个预测类
将预测类别与标签进行比较:
# 将预测值与标签进行比较
preds.argmax(dim=1).eq(labels)
# 输出:tensor([False, False, False, False, False, True, False, True, False, False])
# 只有两个预测正确
P25:一个输入张量在通过CNN的过程中的变化
CNN输出尺寸公式(方形)
- 假设输入尺寸为 n × n n\times n n×n
- 假设滤波器尺寸为 f × f f\times f f×f
- 假设填充padding为 p p p,步长stride为 s s s
输出尺寸 O O O 的计算公式为:
O = n − f + 2 p s + 1 O = \frac{n-f+2p}{s} + 1 O=sn−f+2p+1
以我们之前构建的的CNN为例,输入张量在通过CNN的过程中的尺寸变化如下:
| 操作 | 输出尺寸 |
|---|---|
| 初始输入 | [1,1,28,28] |
| 卷积( 5 × 5 5\times5 5×5) | [1,6,24,24 |
| 最大池化( 2 × 2 2\times2 2×2) | [1,6,12,12] |
| 卷积( 5 × 5 5\times5 5×5) | [1,12,8,8] |
| 最大池化( 2 × 2 2\times2 2×2) | [1,12,4,4] |
| Flatten展平 | [1,192]( 192 = 12 ∗ 4 ∗ 4 192=12* 4* 4 192=12∗4∗4) |
| 线性转换 | [1,120] |
| 线性转换 | [1,60] |
| 线性转换 | [1,10] |
| 可以将值带入计算一下。 |
CNN输出尺寸公式(非方形)
- 假设输出尺寸为 n h × n w n_h\times n_w nh×nw
- 假设滤波器尺寸为 f h × f w f_h\times f_w fh×fw
- 假设填充padding为 p p p,步长stride为 s s s
输出尺寸的高度 O h O_h Oh为:
O h = n h − f h + 2 p s + 1 O_h=\frac{n_h-f_h+2p}{s}+1 Oh=snh−fh+2p+1
输出尺寸的宽度 O w O_w Ow为:
O w = n w − f w + 2 p s + 1 O_w= \frac{n_w-f_w+2p}{s}+1 Ow=snw−fw+2p+1
Section 3:训练神经网络
对应视频: P 26 ∼ P 31 P_{26}\sim P_{31} P26∼P31
P26:训练卷积神经网络(单个批次)
训练卷积神经网络所需的步骤
- 从训练集中得到一批数据
- 将这批数据传递给网络
- 计算损失
- 计算损失函数的梯度和网络的权值
- 更新权重,使用梯度来减少损失
- 重复1~5,直到一个epoch完成
- 重复1~6,以获得所期望的精度
代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
torch.set_printoptions(linewidth=120) # 设置输出行宽
torch.set_grad_enabled(True) # 默认情况下即为True,开启梯度跟踪功能
def get_num_correct(preds, labels):
return preds.argmax(dim=1).eq(labels).sum().item()
class Network(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)
self.fc1 = nn.Linear(in_features=12 * 4 * 4, out_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=60)
self.out = nn.Linear(in_features=60, out_features=10)
def forward(self, t):
t = F.relu(self.conv1(t))
t = F.max_pool2d(t, kernel_size=2, stride=2)
t = F.relu(self.conv2(t))
t = F.max_pool2d(t, kernel_size=2, stride=2)
t = t.reshape(-1, 12 * 4 * 4)
t = F.relu(self.fc1(t))
t = F.relu(self.fc2(t))
t = self.out(t)
return t
train_set = torchvision.datasets.FashionMNIST(
root='./data/FashionMNIST'
,train=True
,download=True
,transform=transforms.Compose([
transforms.ToTensor()
])
)
# 单批次训练
network = Network()
train_loader = torch.utils.data.DataLoader(train_set, batch_size=100)
optimizer = optim.Adam(network.parameters(), lr=0.01)
batch = next(iter(train_loader)) # 获取批次
images, labels = batch
preds = network(images) # 传递批次
loss = F.cross_entropy(preds, labels) # 计算损失
loss.backward() # 计算梯度
optimizer.step() # 更新梯度
# 打印损失和预测正确的图像数
print('loss1:', loss.item())
print('correct1:',get_num_correct(preds, labels))
preds = network(images)
loss = F.cross_entropy(preds, labels)
print('loss2:',loss.item())
print('correct2:',get_num_correct(preds, labels))
输出结果:
loss1: 2.3046135902404785
correct1: 11
loss2: 2.288461208343506
correct2: 11
以上都是针对单个批次的训练
P27:构建一个卷积神经网络的训练循环
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
torch.set_printoptions(linewidth=120) # 设置输出行宽
torch.set_grad_enabled(True) # 默认情况下即为True,开启梯度跟踪功能
def get_num_correct(preds, labels):
return preds.argmax(dim=1).eq(labels).sum().item()
class Network(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)
self.fc1 = nn.Linear(in_features=12 * 4 * 4, out_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=60)
self.out = nn.Linear(in_features=60, out_features=10)
def forward(self, t):
t = F.relu(self.conv1(t))
t = F.max_pool2d(t, kernel_size=2, stride=2)
t = F.relu(self.conv2(t))
t = F.max_pool2d(t, kernel_size=2, stride=2)
t = t.reshape(-1, 12 * 4 * 4)
t = F.relu(self.fc1(t))
t = F.relu(self.fc2(t))
t = self.out(t)
return t
train_set = torchvision.datasets.FashionMNIST(
root='./data/FashionMNIST'
,train=True
,download=False
,transform=transforms.Compose([
transforms.ToTensor()
])
)
# Training Loop
network = Network()
train_loader = torch.utils.data.DataLoader(train_set, batch_size=100)
optimizer = optim.Adam(network.parameters(), lr=0.01)
for epoch in range(5):
total_loss = 0
total_correct = 0
for batch in train_loader:
images, labels = batch
preds = network(images) # 传递批次
loss = F.cross_entropy(preds, labels) # 计算损失
optimizer.zero_grad() # 告诉优化器把梯度属性中的权重的梯度归零,这是因为pytorch会积累梯度,
loss.backward() # 计算梯度
optimizer.step() # 更新梯度
total_loss += loss.item()
total_correct += get_num_correct(preds, labels)
print('epoch:', epoch, 'total_correct:', total_correct, 'loss:', total_loss)
print(total_correct / len(train_set))
输出结果:
epoch: 0 total_correct: 46839 loss: 345.08213037252426
epoch: 1 total_correct: 51307 loss: 234.14958696067333
epoch: 2 total_correct: 51962 loss: 215.7918103337288
epoch: 3 total_correct: 52259 loss: 206.81365805864334
epoch: 4 total_correct: 52613 loss: 198.79174283146858
0.8768833333333333
注:
- 为什么优化器可以更新权重?因为优化器知道网络的权重,我们将权重传递给优化器构造器。
- 在视频的11:00左右,作者进行代码调试,可以清晰的看到梯度和权重的变化。
P28:构建混淆矩阵
要创建混淆矩阵,需要一个预测张量和一个有相应真值或标签的张量。
def get_all_preds(model, loader):
all_preds = torch.tensor([])
for batch in loader:
images, labels = batch
preds = model(images)
all_preds = torch.cat( # 将这些预测连接起来
(all_preds, preds)
, dim=0
)
return all_preds
prediction_loader = torch.utils.data.DataLoader(train_set, batch_size=10000)
train_preds = get_all_preds(network, prediction_loader) # 包含了训练集中每个样本的预测
# 需要在不跟踪梯度的情况下的得到我们的预测,或者不需要创建图表,使用更少的内存
with torch.no_grad():
prediction_loader = torch.utils.data.DataLoader(train_set, batch_size=10000)
train_preds = get_all_preds(network, prediction_loader)
preds_correct = get_num_correct(train_preds, train_set.targets)
print('total correct:',preds_correct)
print('accuracy:', preds_correct / len(train_set))
# 输出
total correct: 51211
accuracy: 0.8535166666666667
接下来,建立混淆矩阵,需要标签以及一个相应的预测张量
print(train_set.targets)
print(train_preds.argmax(dim=1))
# 输出
tensor([9, 0, 0, ..., 3, 0, 5])
tensor([9, 0, 0, ..., 3, 0, 5])
接下来我们需要将这些预测标签和目标标签配对:
stacked = torch.stack(
(
train_set.targets
,train_preds.argmax(dim=1)
)
,dim=1
)
接着,创建一个空的矩阵,并将数据导入空矩阵:
# 创建一个混淆矩阵
cmt = torch.zeros(10,10,dtype=torch.int64) # 10 * 10
for p in stacked:
true_label, pred_label = p.tolist()
cmt[true_label, pred_label] = cmt[true_label, pred_label] + 1 # 实际上是要计算相应类别的出现次数
查看这个混淆矩阵:
tensor([[5626, 0, 35, 55, 14, 2, 231, 0, 36, 1],
[ 80, 5752, 4, 132, 5, 2, 13, 0, 12, 0],
[ 142, 0, 4003, 59, 1086, 1, 667, 1, 41, 0],
[ 537, 9, 6, 5096, 164, 1, 183, 0, 3, 1],
[ 24, 3, 166, 238, 4764, 0, 781, 2, 22, 0],
[ 1, 0, 2, 6, 0, 5347, 0, 496, 36, 112],
[1627, 2, 368, 81, 394, 1, 3440, 0, 87, 0],
[ 0, 0, 0, 0, 0, 5, 0, 5914, 15, 66],
[ 65, 0, 13, 32, 33, 10, 31, 4, 5806, 6],
[ 1, 0, 0, 1, 0, 10, 0, 524, 1, 5463]])
下面展示一种通过调包的方式画出混淆矩阵
# 画一个混淆矩阵,使用包
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
# from plotcm import plot_confusion_matrix
import itertools
import numpy as np
import matplotlib.pyplot as plt
def plot_confusion_matrix(cm, classes, normalize=False, title='Confusion matrix', cmap=plt.cm.Blues):
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print("Normalized confusion matrix")
else:
print('Confusion matrix, without normalization')
print(cm)
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt), horizontalalignment="center", color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
cm = confusion_matrix(train_set.targets, train_preds.argmax(dim=1))
print(type(cm))
print(cm)
# 打印
<class 'numpy.ndarray'>
array([[5626, 0, 35, 55, 14, 2, 231, 0, 36, 1],
[ 80, 5752, 4, 132, 5, 2, 13, 0, 12, 0],
[ 142, 0, 4003, 59, 1086, 1, 667, 1, 41, 0],
[ 537, 9, 6, 5096, 164, 1, 183, 0, 3, 1],
[ 24, 3, 166, 238, 4764, 0, 781, 2, 22, 0],
[ 1, 0, 2, 6, 0, 5347, 0, 496, 36, 112],
[1627, 2, 368, 81, 394, 1, 3440, 0, 87, 0],
[ 0, 0, 0, 0, 0, 5, 0, 5914, 15, 66],
[ 65, 0, 13, 32, 33, 10, 31, 4, 5806, 6],
[ 1, 0, 0, 1, 0, 10, 0, 524, 1, 5463]],
dtype=int64)
names = ('T-shirt','Trouser','Pullover','Dress','Coat','Sandal','Shirt','Sneaker','Bag','Ankel boot')
plt.figure(figsize=(10,10))
plot_confusion_matrix(cm, names)
输出:
Confusion matrix, without normalization
[[5626 0 35 55 14 2 231 0 36 1]
[ 80 5752 4 132 5 2 13 0 12 0]
[ 142 0 4003 59 1086 1 667 1 41 0]
[ 537 9 6 5096 164 1 183 0 3 1]
[ 24 3 166 238 4764 0 781 2 22 0]
[ 1 0 2 6 0 5347 0 496 36 112]
[1627 2 368 81 394 1 3440 0 87 0]
[ 0 0 0 0 0 5 0 5914 15 66]
[ 65 0 13 32 33 10 31 4 5806 6]
[ 1 0 0 1 0 10 0 524 1 5463]]
混淆矩阵:

P29:拼接张量和堆叠张量
拼接是在一个现有的轴上连接一系列张量,堆叠是在一个新的轴上连接一系列的张量。
如何选择拼接还是堆叠?
假设现有三个图像张量,每个都有三个轴,每个张量都是相互独立的:

- 假设我们的任务是将这些张量结合在一起形成一个三个图像的单张量。
在这个例子中,只有三个维度,但对于一批数据,需要四个维度,所以说要沿着一个新的轴将张量堆叠起来,新轴就是批次轴:

如果沿着任何现有的轴将这个张量拼接起来,我们就会把颜色通道、高度或宽度弄乱。 - 假设图像已有了批处理的一个维度,这意味着我们有三个批次,其大小为1:

假设我们的任务是获得一批三张图像。我们可以在批处理维度上进行拼接:

代码演示:
# stack VS cat
import torch
t1 = torch.tensor([1,1,1])
t2 = torch.tensor([2,2,2])
t3 = torch.tensor([3,3,3])
torch.cat(
(t1,t2,t3)
,dim=0
)
# 在现有的轴上进行拼接
tensor([1, 1, 1, 2, 2, 2, 3, 3, 3])
torch.stack(
(t1,t2,t3)
,dim=0
)
# 创建一个新轴,并沿着这个轴将这些张量堆叠起来
tensor([[1, 1, 1],
[2, 2, 2],
[3, 3, 3]])
P30:使用tensorboard来可视化CNN在网络训练过程中的指标
tensorboard是tensorflow的可视化工具,它是一个前端web界面,从一个文件中读取数据,然后显示它。它使我们能跟踪和可视化度量标准,比如我们的损失和准确率,还能可视化我们的网络图。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
torch.set_printoptions(linewidth=120) # 设置输出行宽
torch.set_grad_enabled(True) # 默认情况下即为True,开启梯度跟踪功能
from torch.utils.tensorboard import SummaryWriter
def get_num_correct(preds, labels):
return preds.argmax(dim=1).eq(labels).sum().item()
class Network(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)
self.fc1 = nn.Linear(in_features=12 * 4 * 4, out_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=60)
self.out = nn.Linear(in_features=60, out_features=10)
def forward(self, t):
t = F.relu(self.conv1(t))
t = F.max_pool2d(t, kernel_size=2, stride=2)
t = F.relu(self.conv2(t))
t = F.max_pool2d(t, kernel_size=2, stride=2)
t = t.reshape(-1, 12 * 4 * 4)
t = F.relu(self.fc1(t))
t = F.relu(self.fc2(t))
t = self.out(t)
return t
# train_set = './PyTorchLearning/data/FashionMNIST'
train_set = torchvision.datasets.FashionMNIST(
root='./data/FashionMNIST'
,train=True
,download=False
,transform=transforms.Compose([
transforms.ToTensor()
])
)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=100, shuffle=True)
#------------------------------------------
tb = SummaryWriter()
network = Network()
images, labels = next(iter(train_loader))
grid = torchvision.utils.make_grid(images)
tb.add_image('images', grid)
tb.add_graph(network, images)
tb.close()
#------------------------------------------
-
运行上述代码之后,在根目录下会出现一个名为runs的文件夹:

-
进入终端,并进入根目录,之后执行指令
tensorboard --logdir=runs,将http://localhost:6006/粘贴到浏览器打开,就可以看到界面了。

-
tensorboard界面
(1)首先可以看到IMAEGS界面已经出现了图片:

(2)在GRAPHS界面可以看到我们的网络图:
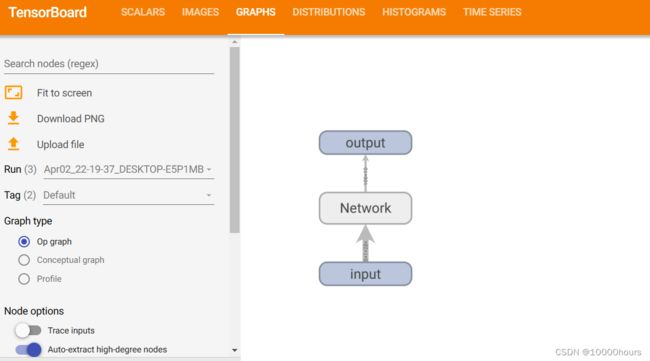
双击可以看到里面的详细结构:

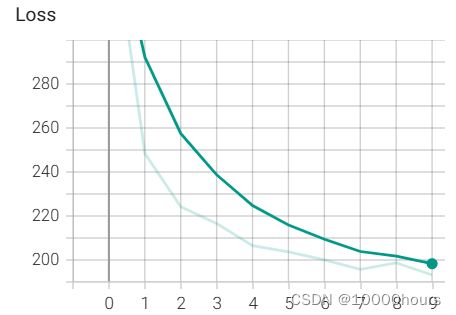
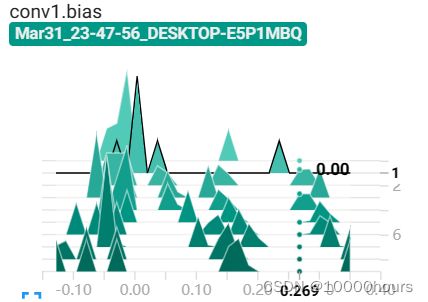
(3)将单批次训练改为循环。循环的代码如下:# LOOP network = Network() optimizer = optim.Adam(network.parameters(), lr=0.01) images, labels = next(iter(train_loader)) grid = torchvision.utils.make_grid(images) tb = SummaryWriter() tb.add_image('images', grid) tb.add_graph(network, images) for epoch in range(5): total_loss = 0 total_correct = 0 for batch in train_loader: images, labels = batch preds = network(images) # 传递批次 loss = F.cross_entropy(preds, labels) # 计算损失 optimizer.zero_grad() # 告诉优化器把梯度属性中的权重的梯度归零,这是因为pytorch会积累梯度, loss.backward() # 计算梯度 optimizer.step() # 更新梯度 total_loss += loss.item() total_correct += get_num_correct(preds, labels) # 添加值 tb.add_scalar('Loss', total_loss, epoch) tb.add_scalar('Number Correct', total_correct, epoch) tb. add_scalar('Accuracy', total_correct / len(train_set), epoch) # 创建直方图 tb.add_histogram('conv1.bias', network.conv1.bias, epoch) tb.add_histogram('conv1.weight', network.conv1.weight, epoch) tb.add_histogram('conv1.weight.grad', network.conv1.weight.grad, epoch) print('epoch:', epoch, 'total_correct:', total_correct, 'loss:', total_loss) tb.close()运行结束后刷新tensorboard界面,可以看到新增的条目:

<1>SCALARS界面:

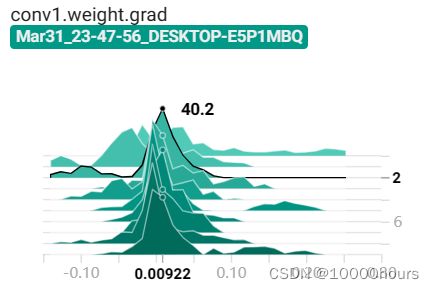
<2>HSITOGRAMS界面:
 |
|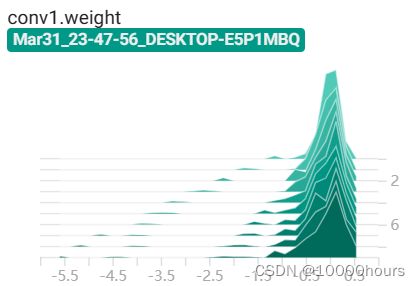 |
|
—|—|—
P31:神经网络超参数
每次修改单个超参数值
batch_size = 100
lr = 0.01
network = Network()
train_loader = torch.utils.data.DataLoader(train_set, batch_size=batch_size, shuffle=True)
optimizer = optim.Adam(network.parameters(), lr=lr)
images, labels = next(iter(train_loader))
grid = torchvision.utils.make_grid(images)
comment = f'batch_size={batch_size} lr={lr}' # 添加注释字符串
tb = SummaryWriter(comment=comment)
tb.add_image('images', grid)
tb.add_graph(network, images)
for epoch in range(5):
total_loss = 0
total_correct = 0
for batch in train_loader:
images, labels = batch
preds = network(images) # 传递批次
loss = F.cross_entropy(preds, labels) # 计算损失
optimizer.zero_grad() # 告诉优化器把梯度属性中的权重的梯度归零,这是因为pytorch会积累梯度,
loss.backward() # 计算梯度
optimizer.step() # 更新梯度
total_loss += loss.item() * batch_size # 调整损失计算
total_correct += get_num_correct(preds, labels)
# 添加值
tb.add_scalar('Loss', total_loss, epoch)
tb.add_scalar('Number Correct', total_correct, epoch)
tb. add_scalar('Accuracy', total_correct / len(train_set), epoch)
# 添加所有参数
for name, weight in network.named_parameters():
tb.add_histogram(name, weight, epoch)
tb.add_histogram(f'{name}.grad', weight.grad, epoch)
print('epoch:', epoch, 'total_correct:', total_correct, 'loss:', total_loss)
tb.close()
循环遍历不同的超参数值
batch_size_list = [100, 1000, 10000]
lr_list = [0.01, 0.001, 0.0001, 0.00001]
for batch_size in batch_size_list:
for lr in lr_list:
network = Network()
train_loader = torch.utils.data.DataLoader(
train_set, batch_size=batch_size
)
optimizer = optim.Adam(
network.parameters(), lr=lr
)
images, labels = next(iter(train_loader))
grid = torchvision.utils.make_grid(images)
comment = f'batch_size={batch_size} lr={lr}' # 添加注释字符串
tb = SummaryWriter(comment=comment)
tb.add_image('images', grid)
tb.add_graph(network, images)
for epoch in range(5):
total_loss = 0
total_correct = 0
for batch in train_loader:
images, labels = batch
preds = network(images) # 传递批次
loss = F.cross_entropy(preds, labels) # 计算损失
optimizer.zero_grad() # 告诉优化器把梯度属性中的权重的梯度归零,这是因为pytorch会积累梯度,
loss.backward() # 计算梯度
optimizer.step() # 更新梯度
total_loss += loss.item() * batch_size # 调整损失计算
total_correct += get_num_correct(preds, labels)
# 添加值
tb.add_scalar('Loss', total_loss, epoch)
tb.add_scalar('Number Correct', total_correct, epoch)
tb.add_scalar('Accuracy', total_correct / len(train_set), epoch)
# 添加所有参数
for name, weight in network.named_parameters():
tb.add_histogram(name, weight, epoch)
tb.add_histogram(f'{name}.grad', weight.grad, epoch)
print('epoch:', epoch, 'total_correct:', total_correct, 'loss:', total_loss)
tb.close()
添加更多的参数
创建一个参数字典,并使用product函数,生成参数
之间的笛卡尔积,然后遍历。
from itertools import product
parameters = dict(
lr = [0.01, 0.001]
,batch_size = [10, 100, 1000]
,shuffle = [True, False]
)
param_values = [v for v in parameters.values()]
for lr, batch_size, shuffle in product(*param_values):
print(lr, batch_size, shuffle)
# comment = f'batch_size={batch_size} lr={lr} shuffle={shuffle}'
network = Network()
train_loader = torch.utils.data.DataLoader(
train_set, batch_size=batch_size
)
optimizer = optim.Adam(
network.parameters(), lr=lr
)
images, labels = next(iter(train_loader))
grid = torchvision.utils.make_grid(images)
comment = f'batch_size={batch_size} lr={lr} shuffle={shuffle}'
tb = SummaryWriter(comment=comment)
tb.add_image('images', grid)
tb.add_graph(network, images)
for epoch in range(5):
total_loss = 0
total_correct = 0
for batch in train_loader:
images, labels = batch
preds = network(images) # 传递批次
loss = F.cross_entropy(preds, labels) # 计算损失
optimizer.zero_grad() # 告诉优化器把梯度属性中的权重的梯度归零,这是因为pytorch会积累梯度,
loss.backward() # 计算梯度
optimizer.step() # 更新梯度
total_loss += loss.item() * batch_size # 调整损失计算
total_correct += get_num_correct(preds, labels)
# 添加值
tb.add_scalar('Loss', total_loss, epoch)
tb.add_scalar('Number Correct', total_correct, epoch)
tb.add_scalar('Accuracy', total_correct / len(train_set), epoch)
# 添加所有参数
for name, weight in network.named_parameters():
tb.add_histogram(name, weight, epoch)
tb.add_histogram(f'{name}.grad', weight.grad, epoch)
print('epoch:', epoch, 'total_correct:', total_correct, 'loss:', total_loss)
tb.close()
刷新tensorboard就可以看到新的输出。
Section 4:神经网络实验#
对应视频: P 32 ∼ P 39 P_{32}\sim P_{39} P32∼P39
P32:编写Run Builder类,使不同的参数值生成多个运行
from collections import OrderedDict
from collections import namedtuple
from itertools import product
# 能让我们在训练过程中尝试不同的值时,拥有更大的控制能力
class RunBuilder():
@staticmethod # 这意味着我们不需要类的实例来调用该方法
def get_runs(params):
Run = namedtuple('Run', params.keys())
runs = []
for v in product(*params.values()): # product函数给了一组定义我们运行的顺序对
runs.append(Run(*v)) # 为每一个都添加一个运行列表
return runs
RunBuilder的运行:
# 如何构建
params = OrderedDict(
lr = [.01, 0.001]
,batch_size = [1000, 10000]
)
runs = RunBuilder.get_runs(params)
runs
输出:
[Run(lr=0.01, batch_size=1000),
Run(lr=0.01, batch_size=10000),
Run(lr=0.001, batch_size=1000),
Run(lr=0.001, batch_size=10000)]
可以看到RunBuilder已经构建并返回了一个四次运行的列表。
如果我们将额外的值添加到测试中,就是将它们添加到原始的参数列表中。如果想要添加一个全新的参数,新参数将自动在运行中被使用,运行输出的字符串也会更新。下图展示了添加新参数后的运行效果:
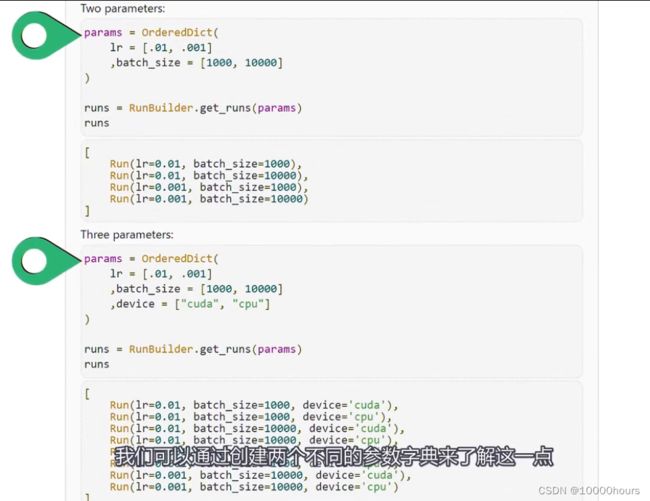
通过这个方法,我们就可以将之前的这种代码:
for lr batch_size, shuffle in product(*param_values):
comment = f'batch_size={batch_size} lr={lr} shuffle={shuffle}'
# 给定参数集的训练过程
修改为以下代码:
for fun in RunBuilder.get_runs(params):
comment = f'-{run}'
# 给定参数集的训练过程
P33:同步超参数测试
在本节中将演示如何轻松地实验大量的超参数值,同时保持训练循环和结果。
我们的目标是能够在顶部添加参数和值,并在多次训练中测试或尝试这些值。另外,我们希望能够添加任意数量的参数和任意数量的参数值,并仍然能推断出结果和组成循环训练的代码,为此我们需要新建类:RunBuilder(上节已经构建),RunManager(它允许我们管理运行循环中的每个运行)。
构建RunManager:
class RunManager():
def __init__(self):
self.epoch_count = 0
self.epoch_loss = 0
self.epoch_num_correct = 0
self.epoch_start_time = None
self.run_params = None
self.run_count = 0
self.run_data = []
self.run_start_time = None
self.network = None
self.loader = None
self.tb = None
def begin_run(self, run, network, loader):
self.run_start_time = time.time()
self.run_params = run
self.run_count += 1
self.network = network
self.loader = loader
self.tb = SummaryWriter(comment=f'-{run}')
images, labels = next(iter(self.loader))
grid = torchvision.utils.make_grid(images)
self.tb.add_image('images',grid)
self.tb.add_graph(self.network, images)
def end_run(self):
self.tb.close()
self.epoch_count = 0
def begin_epoch(self):
self.epoch_start_time = time.time()
self.epoch_count += 1
self.epoch_loss = 0
self.epoch_num_correct = 0
def end_epoch(self):
epoch_duration = time.time() - self.epoch_start_time
run_duration = time.time() - self.run_start_time
loss = self.epoch_loss / len(self.loader.dataset)
accuracy = self.epoch_num_correct / len(self.loader.dataset)
self.tb.add_scalar('Loss', loss, self.epoch_count)
self.tb.add_scalar('Accuracy', accuracy, self.epoch_count)
for name, param in self.network.named_parameters():
self.tb.add_histogram(name, param, self.epoch_count)
self.tb.add_histogram(f'{name}.grad', param.grad, self.epoch_count)
results = OrderedDict()
results['run'] = self.run_count
results['epoch'] = self.epoch_count
results['loss'] = loss
results['accuracy'] = accuracy
results['epoch duration'] = epoch_duration
results['run duration'] = run_duration
for k,v in self.run_params._asdict().items(): results[k] = v
self.run_data.append(results)
df = pd.DataFrame.from_dict(self.run_data, orient='columns')
# 如果在Jupyter notebook中运行,加上下面两句
from IPython.display import clear_output # 提醒我clear_out没定义,于是我import了一下
clear_output(wait=True)
display(df)
def track_loss(self, loss):
self.epoch_loss += loss.item() * self.loader.batch_size
def track_num_correct(self, preds, labels):
self.epoch_num_correct += self._get_num_correct(preds, labels)
@torch.no_grad()
def _get_num_correct(self, preds, labels):
return preds.argmax(dim=1).eq(labels).sum().item()
def save(self, fileName):
pd.DataFrame.from_dict(
self.run_data
,orient='columns'
).to_csv(f'{fileName}.csv')
import json
with open(f'{fileName}.json', 'w', encoding='utf-8') as f:
json.dump(self.run_data, f, ensure_ascii=False, indent=4)
测试运行一下:
params = OrderedDict(
lr = [.01, 0.001]
,batch_size = [1000, 10000]
,shuffle = [True, False]
)
m = RunManager()
for run in RunBuilder.get_runs(params):
network = Network()
loader = torch.utils.data.DataLoader(train_set, batch_size=run.batch_size, shuffle=run.shuffle)
optimizer = optim.Adam(network.parameters(), lr=run.lr)
m.begin_run(run, network, loader)
for epoch in range(5):
m.begin_epoch()
for batch in loader:
images = batch[0]
labels = batch[1]
preds = network(images)
loss = F.cross_entropy(preds, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
m.track_loss(loss)
m.track_num_correct(preds, labels)
m.end_epoch()
m.end_run()
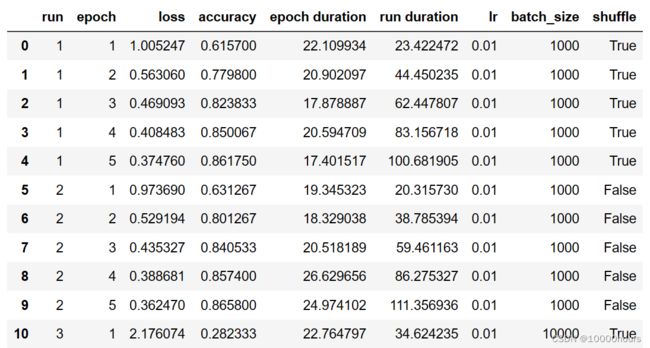
m.save('results')
输出结果如下图所示。我们可以看到不同参数设置下的不同loss和accuracy值,由此能便于我们做进一步的分析。
P34:加速神经网络训练过程
num_worker告诉数据加载器有多少子进程用于数据加载,它的值通常为0,表明在主进程中加载数据,表明训练过程将按顺序进行。
如何知道应该添加多少个工作进程(num_worker=?)?最好是测试:
params = OrderedDict(
lr = [.01,]
,batch_size = [1000, 10000]
, num_workers = [0, 1, 2, 4, 8, 16]
#,shuffle = [True, False]
)
m = RunManager()
for run in RunBuilder.get_runs(params):
network = Network()
loader = torch.utils.data.DataLoader(train_set, batch_size=run.batch_size,num_workers=run.num_workers)
optimizer = optim.Adam(network.parameters(), lr=run.lr)
m.begin_run(run, network, loader)
for epoch in range(5):
m.begin_epoch()
for batch in loader:
images = batch[0]
labels = batch[1]
preds = network(images)
loss = F.cross_entropy(preds, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
m.track_loss(loss)
m.track_num_correct(preds, labels)
m.end_epoch()
m.end_run()
m.save('results')
查看输出结果:
当num_worker从0增加到1时,可以看到epoch duration和run duration都有一定程度的减小:
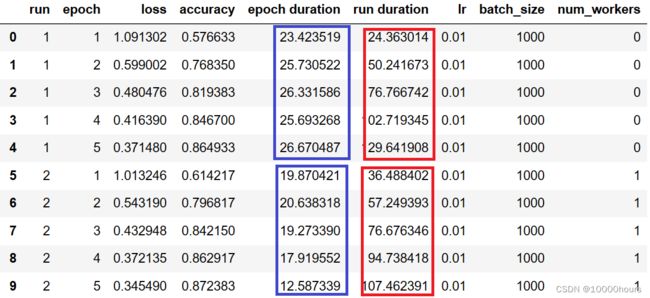
增加到2效果也较为明显,然而继续增加到4,epoch duration和run duration竟增加了,从4到8变化也不大:
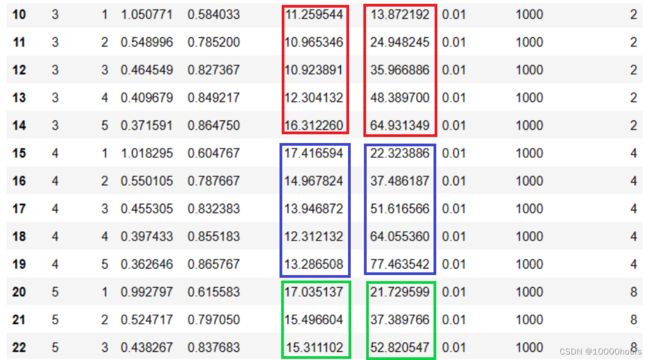
当增加到16时,直接出现错误(如下图所示)。出现死锁,导致程序卡住,线程阻塞:
![]()
可见num_worker的值并非越大越好,需要仔细斟酌后再设定。
P35:使用 CUDA 训练神经网络
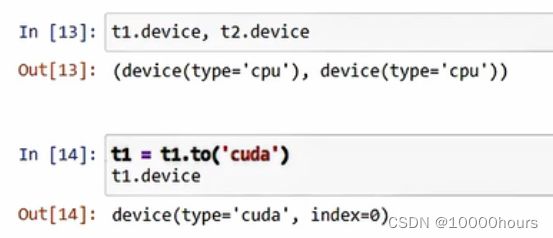
tensor with CUDA
定义张量t1和t2之后,它们的默认计算设备为CPU,使用.to('cuda')可以将计算设备换成GPU,此时t1的计算设备就是GPU了:
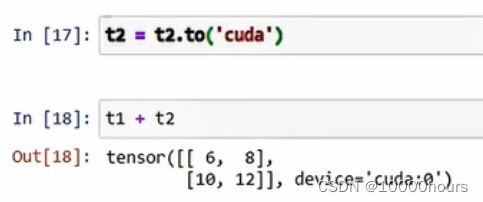
此时,若让两个位于不同计算设备的张量进行计算,会出现下面这样的问题。可以看出,机器希望参与运算的第二个参数拥有与第一个参数相同的计算设备:

将二者的计算设备都改为’cuda’,计算可以顺利执行:
network with CUDA
定义一个网络,输出其参数,以及所在的计算设备:
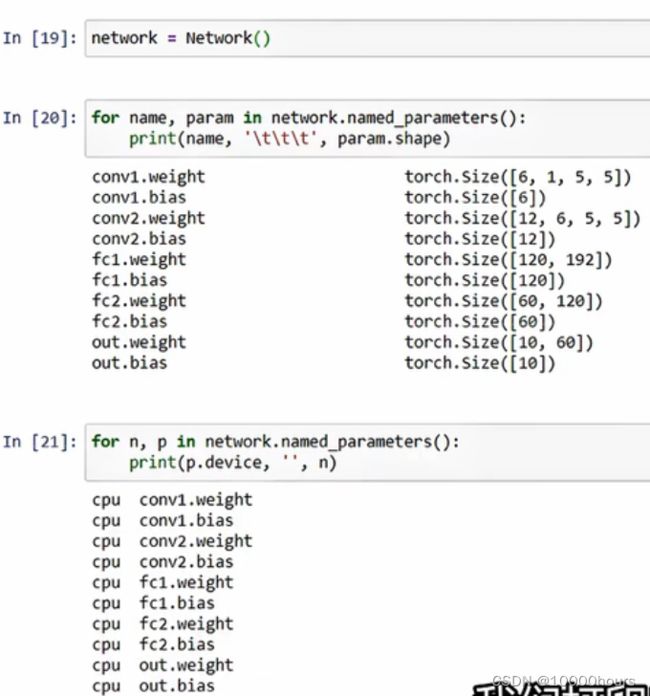
这说明在默认情况下,当我们创建一个pytorch网络,它的所有参数都是在CPU上初始化的。
将网络移动到GPU上:
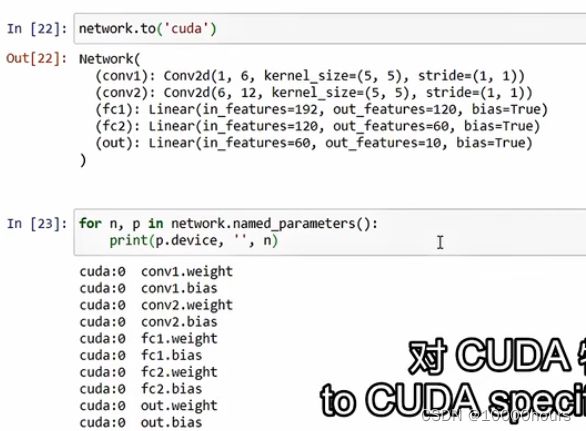
创建一个样本,并将该样本传递给网络(样本在CPU上初始化)捕捉到异常:
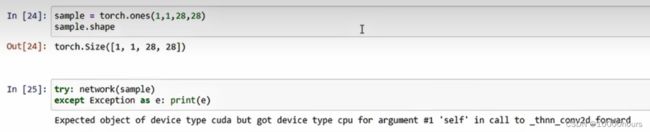
将样本移动到CUDA之后,可以正常计算:

检测系统中CUDA能否使用
可以用以下语句检测:
torch.cuda.is_available()
GPU vs CPU
测试GPU到底加速多少?
首先修改RunManager的begin_run方法:

然后执行以下测试代码:
params = OrderedDict(
lr = [.01,]
, batch_size = [1000, 10000, 20000]
, num_workers = [0, 1]
, device = ['cuda', 'cpu']
)
m = RunManager()
for run in RunBuilder.get_runs(params):
# device
device = torch.device(run.device)
network = Network().to(device)
loader = torch.utils.data.DataLoader(train_set, batch_size=run.batch_size,num_workers=run.num_workers)
optimizer = optim.Adam(network.parameters(), lr=run.lr)
m.begin_run(run, network, loader)
for epoch in range(5):
m.begin_epoch()
for batch in loader:
# to device
images = batch[0].to(device)
labels = batch[1].to(device)
preds = network(images)
loss = F.cross_entropy(preds, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
m.track_loss(loss)
m.track_num_correct(preds, labels)
m.end_epoch()
m.end_run()
m.save('results')
可以看到输出结果:
然后将输出结果按epoch duration排序:
# 排序
pd.DataFrame.from_dict(m.run_data, orient='columns').sort_values('epoch duration')
可以看到cuda遥遥领先:
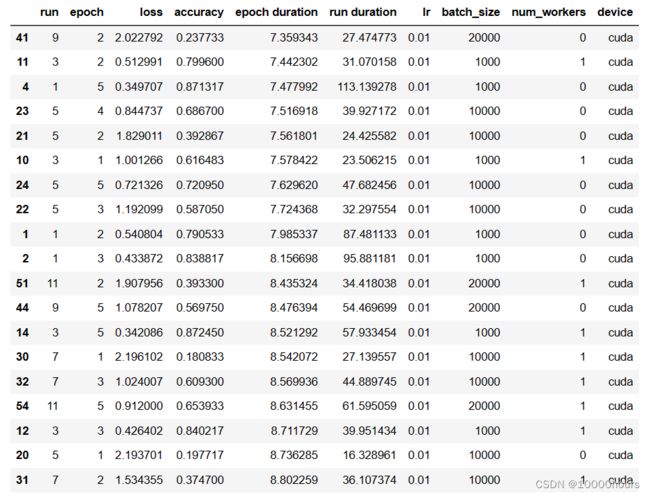
P36:数据集规范化
均值和标准差
先创建数据集:
# 数据集规范化
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
train_set = torchvision.datasets.FashionMNIST(
root='./data/FashionMNIST'
,train=True
,download=True
,transform=transforms.Compose([
transforms.ToTensor()
# normalize
])
)
先用一种简单的方式计算数据集的均值和标准差:
# easy way
loader = DataLoader(train_set, batch_size=len(train_set),num_workers=1)
data = next(iter(loader))
data[0].mean(), data[0].std()
输出
(tensor(0.2860), tensor(0.3530))
另一种方式:
# harder way
# 迭代多批数据。如果数据太大,我们将其分解为多个批次处理
loader = DataLoader(train_set, batch_size=1000, num_workers=1)
num_of_pixels = len(train_set) * 28 * 28 # 图像中总像素数
total_sum = 0
for batch in loader : total_sum += batch[0].sum()
mean = total_sum / num_of_pixels
sum_of_squared_error = 0
for batch in loader : sum_of_squared_error += ((batch[0] - mean).pow(2)).sum()
std = torch.sqrt(sum_of_squared_error / num_of_pixels)
mean, std
输出:
(tensor(0.2860), tensor(0.3530))
可以看到两种方式下的结果是相同的。
数据的直方图如下,中间的竖线就是其均值:

归一化和不归一化的效果区别
创建一个归一化的数据集:
# 使用均值和方差
train_set_normal = torchvision.datasets.FashionMNIST(
root='./data/FashionMNIST'
,train=True
,download=True
,transform=transforms.Compose([
transforms.ToTensor()
, transforms.Normalize(mean, std)
])
)
查看数据集的均值和标准差:
loader = DataLoader(train_set_normal, batch_size=len(train_set),num_workers=1)
data = next(iter(loader))
data[0].mean(), data[0].std()
输出:
(tensor(-9.3670e-08), tensor(1.))
可以看到均值为0,标准差为1,这是归一化的结果。
测试归一化和不归一化的训练效果:
trainsets = {
'not_normal' : train_set
, 'normal' : train_set_normal
}
params = OrderedDict(
lr = [.01]
,batch_size = [1000]
,num_workers = [1]
, device = ['cuda']
, trainset = ['not_normal', 'normal']
)
m = RunManager()
for run in RunBuilder.get_runs(params):
device = torch.device(run.device)
network = Network().to(device)
loader = torch.utils.data.DataLoader(trainsets[run.trainset], batch_size=run.batch_size,num_workers=run.num_workers)
optimizer = optim.Adam(network.parameters(), lr=run.lr)
m.begin_run(run, network, loader)
for epoch in range(10):
m.begin_epoch()
for batch in loader:
images = batch[0].to(device)
labels = batch[1].to(device)
preds = network(images)
loss = F.cross_entropy(preds, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
m.track_loss(loss)
m.track_num_correct(preds, labels)
m.end_epoch()
m.end_run()
m.save('results')
得到的运行结果如下:

按照accuracy对结果进行排序:
pd.DataFrame.from_dict(m.run_data).sort_values('accuracy',ascending=False)

可以看到归一化有利于得到更高的精确度。但是并非每次都要归一化,要针对不同的数据做相应的处理。
P37:调试PyTorch 数据加载器源代码
略。
P38:使用Sequential类来建立神经网络的顺序
准备工作
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import math
from collections import OrderedDict
torch.set_printoptions(linewidth=150)
train_set = torchvision.datasets.FashionMNIST(
root='./data/FashionMNIST'
,train=True
,download=True
,transform=transforms.Compose([
transforms.ToTensor()
])
)
image, label = train_set[0] # image.shape:torch.Size([1, 28, 28])
in_features = image.numel() # 784
out_features = math.floor(in_features / 2) # 392
out_classes = len(train_set.classes) # 10
建立神经网络的顺序
方式一
network1 = nn.Sequential(
nn.Flatten(start_dim=1)
, nn.Linear(in_features, out_features)
, nn.Linear(out_features, out_classes)
)
network1
输出:
Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): Linear(in_features=784, out_features=392, bias=True)
(2): Linear(in_features=392, out_features=10, bias=True)
)
预测iamge:
image = image.unsqueeze(0)
network1(image)
输出:(这些是每个类别的10个预测,这个预测不够准确,因为我们还没有训练网络)
tensor([[-0.1980, -0.0317, 0.2527, 0.2140, -0.0549, -0.0994, -0.0038, -0.1374, 0.1117, 0.1083]], grad_fn=)
方式二
layers = OrderedDict([
('flat', nn.Flatten(start_dim=1))
,('hidden', nn.Linear(in_features, out_features))
,('output', nn.Linear(out_features, out_classes))
])
network2 = nn.Sequential(layers)
network2
输出:
Sequential(
(flat): Flatten(start_dim=1, end_dim=-1)
(hidden): Linear(in_features=784, out_features=392, bias=True)
(output): Linear(in_features=392, out_features=10, bias=True)
)
预测image:
network2(image)
输出:(预测结果不同。虽然network1和network2有着相同的结构,但是两个网络中的权重不同)
tensor([[-0.1359, 0.2879, -0.3738, 0.0343, -0.0800, 0.2685, 0.5197, 0.0467, -0.0519, 0.1609]], grad_fn=)
若想要这两个网络得到相同的预测,需设置随机数种子:
torch.manual_seed(50)
network1 = nn.Sequential(
nn.Flatten(start_dim=1)
, nn.Linear(in_features, out_features)
, nn.Linear(out_features, out_classes)
)
torch.manual_seed(50)
layers = OrderedDict([
('flat', nn.Flatten(start_dim=1))
,('hidden', nn.Linear(in_features, out_features))
,('output', nn.Linear(out_features, out_classes))
])
network2 = nn.Sequential(layers)
network1(image), network2(image)
输出:(这次的预测是相同的)
(tensor([[ 0.1681, 0.1028, -0.0790, -0.0659, -0.2436, 0.1328, -0.0864, 0.0016, 0.1819, -0.0168]], grad_fn=),
tensor([[ 0.1681, 0.1028, -0.0790, -0.0659, -0.2436, 0.1328, -0.0864, 0.0016, 0.1819, -0.0168]], grad_fn=))
方式三
torch.manual_seed(50)
network3 = nn.Sequential()
network3.add_module('flat', nn.Flatten(start_dim=1))
network3.add_module('hidden', nn.Linear(in_features, out_features))
network3.add_module('output', nn.Linear(out_features, out_classes))
network3
输出:
Sequential(
(flat): Flatten(start_dim=1, end_dim=-1)
(hidden): Linear(in_features=784, out_features=392, bias=True)
(output): Linear(in_features=392, out_features=10, bias=True)
)
使用随机数种子后,3个网络的预测是一致的:
network1(image), network2(image), network3(image)
(tensor([[ 0.1681, 0.1028, -0.0790, -0.0659, -0.2436, 0.1328, -0.0864, 0.0016, 0.1819, -0.0168]], grad_fn=),
tensor([[ 0.1681, 0.1028, -0.0790, -0.0659, -0.2436, 0.1328, -0.0864, 0.0016, 0.1819, -0.0168]], grad_fn=),
tensor([[ 0.1681, 0.1028, -0.0790, -0.0659, -0.2436, 0.1328, -0.0864, 0.0016, 0.1819, -0.0168]], grad_fn=))
使用Sequential类建一个Network类
原始Network
class Network(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)
self.fc1 = nn.Linear(in_features=12 * 4 * 4, out_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=60)
self.out = nn.Linear(in_features=60, out_features=10)
def forward(self, t):
t = F.relu(self.conv1(t))
t = F.max_pool2d(t, kernel_size=2, stride=2)
t = F.relu(self.conv2(t))
t = F.max_pool2d(t, kernel_size=2, stride=2)
t = t.reshape(-1, 12 * 4 * 4)
t = F.relu(self.fc1(t))
t = F.relu(self.fc2(t))
t = self.out(t)
return t
创建网络实例:
torch.manual_seed(50)
network = Network()
方式一
torch.manual_seed(50)
sequential1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
,nn.ReLU()
,nn.MaxPool2d(kernel_size=2, stride=2)
,nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)
,nn.ReLU()
,nn.MaxPool2d(kernel_size=2, stride=2)
,nn.Flatten(start_dim=1)
,nn.Linear(in_features=12 * 4 * 4, out_features=120)
,nn.ReLU()
,nn.Linear(in_features=120, out_features=60)
,nn.ReLU()
,nn.Linear(in_features=60, out_features=10)
)
sequential1
输出:
Sequential(
(0): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(6, 12, kernel_size=(5, 5), stride=(1, 1))
(4): ReLU()
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=192, out_features=120, bias=True)
(8): ReLU()
(9): Linear(in_features=120, out_features=60, bias=True)
(10): ReLU()
(11): Linear(in_features=60, out_features=10, bias=True)
)
方式二
torch.manual_seed(50)
layers = OrderedDict([
('conv1',nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5))
,('relu1', nn.ReLU())
,('maxpool1', nn.MaxPool2d(kernel_size=2, stride=2))
,('conv2', nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5))
,('relu2', nn.ReLU())
,('maxpool2', nn.MaxPool2d(kernel_size=2, stride=2))
,('flatten', nn.Flatten(start_dim=1))
,('fc1', nn.Linear(in_features=12 * 4 * 4, out_features=120))
,('relu3', nn.ReLU())
,('fc2', nn.Linear(in_features=120, out_features=60))
,('relu4', nn.ReLU())
,('out', nn.Linear(in_features=60, out_features=10))
])
sequential2 = nn.Sequential(layers)
sequential2
输出:
Sequential(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(relu1): ReLU()
(maxpool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(6, 12, kernel_size=(5, 5), stride=(1, 1))
(relu2): ReLU()
(maxpool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(flatten): Flatten(start_dim=1, end_dim=-1)
(fc1): Linear(in_features=192, out_features=120, bias=True)
(relu3): ReLU()
(fc2): Linear(in_features=120, out_features=60, bias=True)
(relu4): ReLU()
(out): Linear(in_features=60, out_features=10, bias=True)
)
方式三
方式三就是add_module,不再赘述
预测image
network(image), sequential1(image), sequential2(image)
输出:(因为使用了随机数种子,所以预测结果相同)
(tensor([[-0.0957, 0.1053, -0.1055, 0.1547, -0.0366, -0.0132, 0.0749, -0.1152, 0.0426, 0.0639]], grad_fn=),
tensor([[-0.0957, 0.1053, -0.1055, 0.1547, -0.0366, -0.0132, 0.0749, -0.1152, 0.0426, 0.0639]], grad_fn=),
tensor([[-0.0957, 0.1053, -0.1055, 0.1547, -0.0366, -0.0132, 0.0749, -0.1152, 0.0426, 0.0639]], grad_fn=))
P39:PyTorch 中的批处理规范
创建网络
torch.manual_seed(50)
network1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
,nn.ReLU()
,nn.MaxPool2d(kernel_size=2, stride=2)
,nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)
,nn.ReLU()
,nn.MaxPool2d(kernel_size=2, stride=2)
,nn.Flatten(start_dim=1)
,nn.Linear(in_features=12 * 4 * 4, out_features=120)
,nn.ReLU()
,nn.Linear(in_features=120, out_features=60)
,nn.ReLU()
,nn.Linear(in_features=60, out_features=10)
)
# 添加nn.BatchNorm2d()和nn.BatchNorm1d
torch.manual_seed(50)
network2 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
,nn.ReLU()
,nn.MaxPool2d(kernel_size=2, stride=2)
,nn.BatchNorm2d(6) # 6是因为out_channels=6
,nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)
,nn.ReLU()
,nn.MaxPool2d(kernel_size=2, stride=2)
,nn.Flatten(start_dim=1)
,nn.Linear(in_features=12 * 4 * 4, out_features=120)
,nn.ReLU()
,nn.BatchNorm1d(120) # 120是因为out_features=120
,nn.Linear(in_features=120, out_features=60)
,nn.ReLU()
,nn.Linear(in_features=60, out_features=10)
)
准备数据
# train_set
train_set = torchvision.datasets.FashionMNIST(
root='./data/FashionMNIST'
,train=True
,download=True
,transform=transforms.Compose([
transforms.ToTensor()
])
)
loader = DataLoader(train_set, batch_size=len(train_set),num_workers=1)
data = next(iter(loader))
mean = data[0].mean()
std = data[0].std()
train_set_normal = torchvision.datasets.FashionMNIST(
root='./data/FashionMNIST'
,train=True
,download=True
,transform=transforms.Compose([
transforms.ToTensor()
, transforms.Normalize(mean, std)
])
)
trainsets = {
'not_normal' : train_set
, 'normal' : train_set_normal
}
networks = {
'no_batch_norm':network1
,'batch_norm':network2
}
测试
params = OrderedDict(
lr = [.01]
,batch_size = [1000]
,num_workers = [1]
, device = ['cuda']
, trainset = ['normal']
, network = list(networks.keys())
)
m = RunManager()
for run in RunBuilder.get_runs(params):
device = torch.device(run.device)
network = networks[run.network].to(device)
loader = torch.utils.data.DataLoader(trainsets[run.trainset], batch_size=run.batch_size,num_workers=run.num_workers)
optimizer = optim.Adam(network.parameters(), lr=run.lr)
m.begin_run(run, network, loader)
for epoch in range(20):
m.begin_epoch()
for batch in loader:
images = batch[0].to(device)
labels = batch[1].to(device)
preds = network(images)
loss = F.cross_entropy(preds, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
m.track_loss(loss)
m.track_num_correct(preds, labels)
m.end_epoch()
m.end_run()
m.save('results')
将测试结果排序:
pd.DataFrame.from_dict(m.run_data).sort_values('accuracy',ascending=False)
排序后的结果为:

可以看到batch_norm的网络的准确率达到了93.5%(最高),no_batch_norm的网络的准确率达到了91.4%(最高)。batch_norm 的网络能更快收敛。
Section 5:补充学习
对应视频: P 40 ∼ P 43 P_{40}\sim P_{43} P40∼P43
P40:重置reset网络的权重
重置单个层的权重
torch.manual_seed(50)
layer = nn.Linear(2,1) # 创建一个最基本的线性层
查看这个层的权重:
layer.weight
输出:
Parameter containing:
tensor([[ 0.1669, -0.6100]], requires_grad=True)
更新权重:
t = torch.rand(2)
o = layer(t)
o.backward()
optimizer = optim.Adam(layer.parameters(), lr=0.01)
optimizer.step()
再次查看layer.weight,可以看到权重已经更新:
Parameter containing:
tensor([[ 0.1569, -0.6200]], requires_grad=True)
重置layer的权重:
torch.manual_seed(50)
layer.reset_parameters()
再次查看layer.weight,可以看到已经恢复到最初的权重了:
Parameter containing:
tensor([[ 0.1669, -0.6100]], requires_grad=True)
重置网络中的层的权重
all weights layer by layer
创建一个网络:
network = nn.Sequential(nn.Linear(2,1))
查看network[0].weight:
Parameter containing:
tensor([[-0.6500, -0.1395]], requires_grad=True)
采用for循环重置网络内层的权重:
torch.manual_seed(50)
for module in network.children():
module.reset_parameters()
查看network[0].weight,可以看到network[0]的权重成功重置:
Parameter containing:
tensor([[ 0.1669, -0.6100]], requires_grad=True)
为网络增加一层:
# 增加一层
network = nn.Sequential(
nn.Linear(2,1)
,nn.Softmax()
)
network
Sequential(
(0): Linear(in_features=2, out_features=1, bias=True)
(1): Softmax(dim=None)
)
再次使用for循环重置网络内层的权重:
try:
torch.manual_seed(50)
for module in network.children():
module.reset_parameters()
except Exception as e:
print(e)
这时会出现这种情况:
'Softmax' object has no attribute 'reset_parameters'
这是因为子层可能没有参数,因此仅采用for循环重置每一层的参数是有风险的。
all weights using snapshot
snapshot 是一种灵活重置的方式。
创建网络:
torch.manual_seed(50)
network = nn.Sequential(nn.Linear(2,1))
查看network[0].weight:
Parameter containing:
tensor([[ 0.1669, -0.6100]], requires_grad=True)
保存网络当前的状态:
torch.save(network.state_dict(), "./network.pt")
然后更新网络权重:
t = torch.rand(2)
o = network(t)
o.backward()
optimizer = optim.Adam(network.parameters(), lr=0.01)
optimizer.step()
此时再次查看network[0].weight,可以看到权重已经更新:
Parameter containing:
tensor([[ 0.1569, -0.6200]], requires_grad=True)
加载刚刚保存的网络状态:
network.load_state_dict(torch.load("./network.pt"))
然后再次查看network[0].weight:
Parameter containing:
tensor([[ 0.1669, -0.6100]], requires_grad=True)
这种方式,可以在网络训练的任何时候保存权重,然后在想使用的时候加载出来。
all weights using re-initialization
创建网络:
torch.manual_seed(50)
network = nn.Sequential(nn.Linear(2,1))
查看network[0].weight:
Parameter containing:
tensor([[ 0.1669, -0.6100]], requires_grad=True)
更新网络权重:
t = torch.rand(2)
o = network(t)
o.backward()
optimizer = optim.Adam(network.parameters(), lr=0.01)
optimizer.step()
再次查看network[0].weight,可以看到权重已更新:
Parameter containing:
tensor([[ 0.1569, -0.6200]], requires_grad=True)
然后重新初始化网络:
torch.manual_seed(50)
network = nn.Sequential(nn.Linear(2,1))
再次查看network[0].weight,可以看到权重已经恢复:
Parameter containing:
tensor([[ 0.1669, -0.6100]], requires_grad=True)
P41:改进测试框架
在之前的测试中,我们使用RunBuilder和RunManager类来测试不同的网络,但是每结束一个网络的测试并开始下一个新的网络的测试时,这个新网络的测试是以上一个旧网络测试的结束为起点的,如下图所示:(在run1到run2的过渡中,这测试的是两个不同的网络,但是accuracy的值却相差无几)
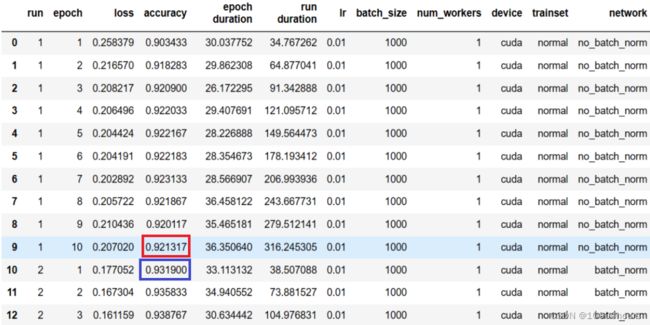
因此,在开始一个新网络的测试时,我们应重置网络的权重。为了达到该目的,写一个NetworkFacory类:
class NetworkFactory():
@staticmethod
def get_network(name):
if name == 'network': # 重置网络权重
torch.manual_seed(50)
return nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
,nn.ReLU()
,nn.MaxPool2d(kernel_size=2, stride=2)
,nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)
,nn.ReLU()
,nn.MaxPool2d(kernel_size=2, stride=2)
,nn.Flatten(start_dim=1)
,nn.Linear(in_features=12 * 4 * 4, out_features=120)
,nn.ReLU()
,nn.Linear(in_features=120, out_features=60)
,nn.ReLU()
,nn.Linear(in_features=60, out_features=10)
)
else:
return None
然后使用该类来进行测试:
params = OrderedDict(
lr = [.01,.001]
,batch_size = [1000]
,num_workers = [1]
, device = ['cuda']
, network = ['network']
)
m = RunManager()
for run in RunBuilder.get_runs(params):
device = torch.device(run.device)
network = NetworkFactory.get_network(run.network).to(device)
loader = torch.utils.data.DataLoader(train_set, batch_size=run.batch_size,num_workers=run.num_workers)
optimizer = optim.Adam(network.parameters(), lr=run.lr)
m.begin_run(run, network, loader)
for epoch in range(10):
m.begin_epoch()
for batch in loader:
images = batch[0].to(device)
labels = batch[1].to(device)
preds = network(images)
loss = F.cross_entropy(preds, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
m.track_loss(loss)
m.track_num_correct(preds, labels)
m.end_epoch()
m.end_run()
m.save('results')
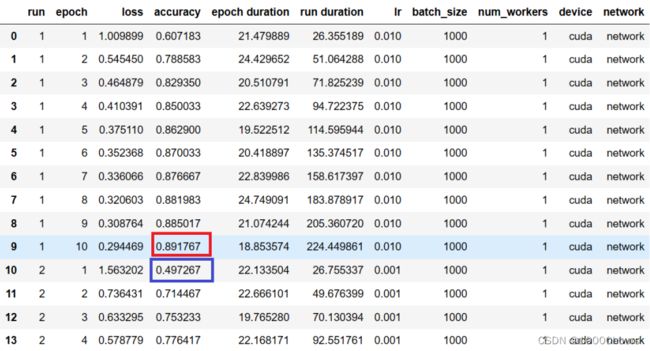
测试结果如,可以看到这次run1向run2过渡时,两个网络的accuracy值就相差很大了,这是因为在测试新的网络时,进行了网络权重重置:
P42:Max Pooling vs No Max Pooling
网络如何在有和没有maxpooling的情况下执行。
修改NetworkFactory类:
class NetworkFactory():
@staticmethod
def get_network(name):
if name == 'max_pool':
torch.manual_seed(50)
return nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
,nn.ReLU()
,nn.MaxPool2d(kernel_size=2, stride=2)
,nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)
,nn.ReLU()
,nn.MaxPool2d(kernel_size=2, stride=2)
,nn.Flatten(start_dim=1)
,nn.Linear(in_features=12 * 4 * 4, out_features=120)
,nn.ReLU()
,nn.Linear(in_features=120, out_features=60)
,nn.ReLU()
,nn.Linear(in_features=60, out_features=10)
)
elif name == 'no_max_pool':
torch.manual_seed(50)
return nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
,nn.ReLU()
# ,nn.MaxPool2d(kernel_size=2, stride=2)
,nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)
,nn.ReLU()
# ,nn.MaxPool2d(kernel_size=2, stride=2)
,nn.Flatten(start_dim=1)
,nn.Linear(in_features=12 * 20 * 20, out_features=120)
,nn.ReLU()
,nn.Linear(in_features=120, out_features=60)
,nn.ReLU()
,nn.Linear(in_features=60, out_features=10)
)
进行测试:
class NetworkFactory():
@staticmethod
def get_network(name):
if name == 'max_pool':
torch.manual_seed(50)
return nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
,nn.ReLU()
,nn.MaxPool2d(kernel_size=2, stride=2)
,nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)
,nn.ReLU()
,nn.MaxPool2d(kernel_size=2, stride=2)
,nn.Flatten(start_dim=1)
,nn.Linear(in_features=12 * 4 * 4, out_features=120)
,nn.ReLU()
,nn.Linear(in_features=120, out_features=60)
,nn.ReLU()
,nn.Linear(in_features=60, out_features=10)
)
elif name == 'no_max_pool':
torch.manual_seed(50)
return nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
,nn.ReLU()
# ,nn.MaxPool2d(kernel_size=2, stride=2)
,nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)
,nn.ReLU()
# ,nn.MaxPool2d(kernel_size=2, stride=2)
,nn.Flatten(start_dim=1)
,nn.Linear(in_features=12 * 20 * 20, out_features=120)
,nn.ReLU()
,nn.Linear(in_features=120, out_features=60)
,nn.ReLU()
,nn.Linear(in_features=60, out_features=10)
)
对测试结果按accuracy排序:
pd.DataFrame.from_dict(m.run_data).sort_values('accuracy',ascending=False)
结果如下:
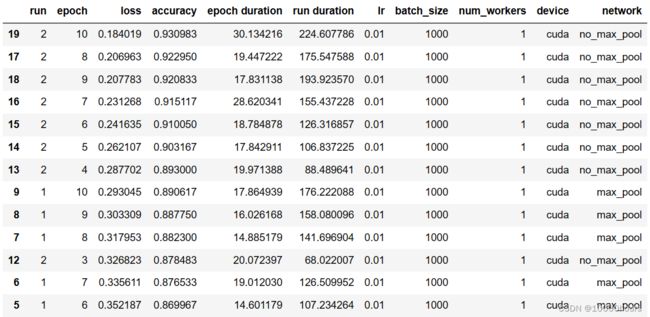
可以看到no_max_pool的精确度是更高的,这种结果的原因可能是,我们的数据已经足够简单,我们再maxpooling,实际上就会丢失很多数据。
可以看下面两个例子,左边是原始输入,右边是执行maxpooling操作后。
尽管右边的输出相对接近原始输入,但是丢失了太多数据,比如衬衫上的方块变成了右边的直线:

下面这张图就更明显了:

P43:结束课程
课程学习路线:

课程结束,借用授课老师最后说的话激励一下自己,以及每个看到这里的屏幕前的你:
No matter what you’re pursuing, it does not matter how slow you go, as long as you do not stop.
个人笔记第一部分:DeepLizard:Pytorch神经网络编程教学(第一部分)