目录
- 爬虫
- 爬虫一:自学内容
- 1 爬虫介绍
- 2 requests模块
- 3 代理
- 4 爬视频
- 5 自动登录网站
- 爬虫二:
- 昨日回顾
- 今日内容
- 1 requests+bs4爬汽车之家新闻
- 2 bs4的使用(遍历文档树和查找文档树)
- 3 带你搭一个免费的代理池
- 4 验证码破解
- 5 爬取糗事百科段子,自动通过微信发给女朋友(老板)
- 爬虫三:
- 昨日回顾
- 今日内容
- 1 css选择器和xpath选择器
- 2 selenium的简单使用
- 3 selenium的高级用法
- 4 爬取京东商品信息
- 爬虫四:
- 昨日回顾
- 今日内容
- 1 scarpy框架的安装和启动
- 2 scrapy架构
- 3 配置文件,目录介绍
- 4 以抽屉为例,爬取数据并解析
- 5 持久化
- 6 动作链,自动登录12306
- 爬虫五:
- 昨日回顾
- 今日内容
- 1 全站爬取cnblogs
- 2 scarpy请求传参
- 3 提高爬取效率
- 4 下载中间件
- 5 集成selenium
- 6 fake-useragent
- 7 去重源码分析
- 8 分布式爬虫
- 补充
- 爬虫一:自学内容
爬虫
爬虫一:自学内容
# 1 爬虫介绍
# 2 requests模块
# 3 爬一个视频网站
# 4 模拟登陆某网站
# 5 bs4
# 6 汽车之家新闻
# 7 selenium
# 8 京东商品信息
# 9 代理池,cookie池
# 10 验证码破解(打码平台)
# 11 自动登陆到12306,拿到cookie
# 12 抓包工具的使用fillder(app爬取)
# 13 scarpy框架,持久化,整站爬取,集成selenium,代理池,UA
# 14 分布式爬虫,scrapy-redis
# 15 Mongodb1 爬虫介绍
# 1 本质:模拟发送http请求(requests)----》解析返回数据(re,bs4,lxml,json)---》入库(redis,mysql,mongodb)
# 2 app爬虫:本质一模一样
# 3 为什么python做爬虫最好:包多,爬虫框架:scrapy:性能很高的爬虫框架,爬虫界的django,大而全(爬虫相关的东西都集成了)
# 4 百度,谷歌,就是个大爬虫 在百度搜索,其实是去百度的服务器的库搜的,百度一直开着爬虫,一刻不停的在互联网上爬取,把页面存储到自己库中
# 5 全文检索:全文检索
# 10 你公司里可以做项目,爬虫爬回来的(律师行业),搭一个搜索网站(app,小程序),
# 11 医疗行业:造药企业,头孢类的
# 12 爬简历:简历库
#面试很重要:http协议(80%被问到)
# 特点
(1)应用层协议(mysql,redis,mongodb:cs架构的软件:Navicat,python代码:pymysql,都是mysql客户端--socket:自己定制的协议----》服务端)(docker,es---》http(resful)---》服务端)
(2)基于请求-响应模式:
客户端主动发起请求---》服务端才能响应 (服务端不能主动推送消息:轮询,长轮询,websocket协议:主动推送消息)
(3)无状态保存(cookie,session,token:)
(4)无连接:发送一次请求,响应完就断开,性能影响(http协议版本:0.9,1.1:多次请求,共用一个socket连接,2.0:
一次请求,可以携带多个http请求)
# http请求:请求首行,请求头,请求体
-127.0.0.1/name=lqz&age=18:请求首行
-post请求请求体中放数据:name=lqz&age=18 放在请求体中
-post请求,可以这样发么:127.0.0.1/name=lqz&age=18,django数据requtes.GET
-放在体中的:request.POST
-请求体的格式(编码格式):
urlencode:name=lqz&age=18 ---》request.POST
json:{name:lqz,age:18} ---->request.POST取不出来(为什么?django框架没有做这个事)
formdata:传文件,5g大文件, ----》request.POST
# http响应:
# 响应首行:状态码:1,2,3,4,5 301和302的区别
# 响应头:key:value:背几个响应头
-cookie:
-cache-control:缓存控制
# 响应体:
html,json
# 浏览器调试
-右键--》调试模式
-elements:响应体,html格式
-console:调试窗口(js输出的内容,在这能看到)
-network:发送的所有请求,all xhr:ajax请求2 requests模块
# 1 模块:可以模拟发送http请求,urlib2:内置库,不太好用,繁琐,封装出requests模块,应用非常广泛(公司,人)
# 2 pip3 install requests
# 3 小插曲:requests作者,众筹换电脑(性能跟不上了),捐钱(谷歌公司捐了),2 万 8 千美元,买了游戏设备,爆料出来,骗捐,辟谣# 1 request模块基本使用
import requests
# # 发送http请求
# # get,delete,post。。本质都是调用request函数
# ret=requests.get('https://www.cnblogs.com')
# print(ret.status_code) # 响应状态码
# print(ret.text) # 响应体,转成了字符串
# print(ret.content) # 响应体,二进制
# ret=requests.post()\
# ret=requests.request("get",)
# ret=requests.delete()
# 2 get 请求带参数
# 方式一
# ret = requests.get('https://www.baidu.com/',
# headers={
# # 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36',
# 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
# })
# print(ret.text)
# 方式2(建议用方式二)中文会自动转码
# ret=requests.get('http://0.0.0.0:8001/',params={'name':"美女",'age':18})
# print(ret.text)
# 3 带headers
# ret = requests.get('http://0.0.0.0:8001/?name=%E7%BE%8E%E5%A5%B3',
# headers={
# # 标志,什么东西发出的请求,浏览器信息,django框架,从哪取?(meta)
# 'User-Agent': 'request',
# # 上一个页面的地址,图片防盗链
# 'Referer': 'xxx'
# })
# print(ret)
# 图片防盗链:如果图片的referer不是我自己的网站,就直接禁止掉
#  # 4 带cookie,随机字符串(用户信息:也代表session),不管后台用的token认证,还是session认证
# 一旦登陆了,带着cookie发送请求,表示登陆了(下单,12306买票,评论)
# 第一种方式
# ret = requests.get('http://0.0.0.0:8001/?name=%E7%BE%8E%E5%A5%B3',
# headers={
# 'cookie': 'key3=value;key2=value',
# })
# 第二种方式
# ret = requests.get('http://0.0.0.0:8001/?name=%E7%BE%8E%E5%A5%B3',
# cookies={"islogin":"xxx"})
# print(ret)
# 5 发送post请求(注册,登陆),携带数据(body)
#data=None, json=None
# data:urlencoded编码
# ret=requests.post('http://0.0.0.0:8001/',data={'name':"lqz",'age':18})
# json:json编码
# import json
# data=json.dumps({'name':"lqz",'age':18})
# ret=requests.post('http://0.0.0.0:8001/',json=data)
# print(ret)
# 注意:编码格式是请求头中带的,所有我可以手动修改,在headers中改
# 6 session对象
# session=requests.session()
# # 跟requests.get/post用起来完全一样,但是它处理了cookie
# # 假设是一个登陆,并且成功
# session.post()
# # 再向该网站发请求,就是登陆状态,不需要手动携带cookie
# session.get("地址")
# 7 响应对象
# print(respone.text) # 响应体转成str
# print(respone.content) # 响应体二进制(图片,视频)
#
# print(respone.status_code) # 响应状态码
# print(respone.headers) # 响应头
# print(respone.cookies) # 服务端返回的cookie
# print(respone.cookies.get_dict()) # 转成字典
# print(respone.cookies.items())
#
# print(respone.url) # 当次请求的地址
# print(respone.history) # 如果有重定向,放到一个列表中
# ret=requests.post('http://0.0.0.0:8001/')
# ret=requests.get('http://0.0.0.0:8001/admin')
# #不要误解
# ret=requests.get('http://0.0.0.0:8001/user')
# print(ret.history)
# print(respone.encoding) # 编码方式
#response.iter_content() # 视频,图片迭代取值
# with open("a.mp4",'wb') as f:
# for line in response.iter_content():
# f.write(line)
# 8 乱码问题
# 加载回来的页面,打印出来,乱码(我们用的是utf8编码),如果网站用gbk,
# ret.encoding='gbk'
# ret=requests.get('http://0.0.0.0:8001/user')
# # ret.apparent_encoding当前页面的编码
# ret.encoding=ret.apparent_encoding
# 9 解析json
# 返回数据,有可能是json格式,有可能是html格式
# ret=requests.get('http://0.0.0.0:8001/')
# print(type(ret.text))
# print(ret.text)
#
# a=ret.json()
# print(a['name'])
# print(type(a))
# 10 使用代理
# 正向代理
# django如何拿到客户端ip地址 META.get("REMOTE_ADDR")
# 如何去获取代理,如何使用(用自己项目验收)
# 使用代理有什么用
# ret=requests.get('http://0.0.0.0:8001/',proxies={'http':'地址'})
# print(type(ret.text))
# print(ret.text)
# 11 异常处理
# 用try except捕获一下 就用它就型了:Exception
# 12 上传文件(爬虫用的比较少,后台写服务,)
# file={'myfile':open("1.txt",'rb')}
# ret=requests.post('http://0.0.0.0:8001/',files=file)
# print(ret.content)
# 认证,处理ssl(不讲了)
# 4 带cookie,随机字符串(用户信息:也代表session),不管后台用的token认证,还是session认证
# 一旦登陆了,带着cookie发送请求,表示登陆了(下单,12306买票,评论)
# 第一种方式
# ret = requests.get('http://0.0.0.0:8001/?name=%E7%BE%8E%E5%A5%B3',
# headers={
# 'cookie': 'key3=value;key2=value',
# })
# 第二种方式
# ret = requests.get('http://0.0.0.0:8001/?name=%E7%BE%8E%E5%A5%B3',
# cookies={"islogin":"xxx"})
# print(ret)
# 5 发送post请求(注册,登陆),携带数据(body)
#data=None, json=None
# data:urlencoded编码
# ret=requests.post('http://0.0.0.0:8001/',data={'name':"lqz",'age':18})
# json:json编码
# import json
# data=json.dumps({'name':"lqz",'age':18})
# ret=requests.post('http://0.0.0.0:8001/',json=data)
# print(ret)
# 注意:编码格式是请求头中带的,所有我可以手动修改,在headers中改
# 6 session对象
# session=requests.session()
# # 跟requests.get/post用起来完全一样,但是它处理了cookie
# # 假设是一个登陆,并且成功
# session.post()
# # 再向该网站发请求,就是登陆状态,不需要手动携带cookie
# session.get("地址")
# 7 响应对象
# print(respone.text) # 响应体转成str
# print(respone.content) # 响应体二进制(图片,视频)
#
# print(respone.status_code) # 响应状态码
# print(respone.headers) # 响应头
# print(respone.cookies) # 服务端返回的cookie
# print(respone.cookies.get_dict()) # 转成字典
# print(respone.cookies.items())
#
# print(respone.url) # 当次请求的地址
# print(respone.history) # 如果有重定向,放到一个列表中
# ret=requests.post('http://0.0.0.0:8001/')
# ret=requests.get('http://0.0.0.0:8001/admin')
# #不要误解
# ret=requests.get('http://0.0.0.0:8001/user')
# print(ret.history)
# print(respone.encoding) # 编码方式
#response.iter_content() # 视频,图片迭代取值
# with open("a.mp4",'wb') as f:
# for line in response.iter_content():
# f.write(line)
# 8 乱码问题
# 加载回来的页面,打印出来,乱码(我们用的是utf8编码),如果网站用gbk,
# ret.encoding='gbk'
# ret=requests.get('http://0.0.0.0:8001/user')
# # ret.apparent_encoding当前页面的编码
# ret.encoding=ret.apparent_encoding
# 9 解析json
# 返回数据,有可能是json格式,有可能是html格式
# ret=requests.get('http://0.0.0.0:8001/')
# print(type(ret.text))
# print(ret.text)
#
# a=ret.json()
# print(a['name'])
# print(type(a))
# 10 使用代理
# 正向代理
# django如何拿到客户端ip地址 META.get("REMOTE_ADDR")
# 如何去获取代理,如何使用(用自己项目验收)
# 使用代理有什么用
# ret=requests.get('http://0.0.0.0:8001/',proxies={'http':'地址'})
# print(type(ret.text))
# print(ret.text)
# 11 异常处理
# 用try except捕获一下 就用它就型了:Exception
# 12 上传文件(爬虫用的比较少,后台写服务,)
# file={'myfile':open("1.txt",'rb')}
# ret=requests.post('http://0.0.0.0:8001/',files=file)
# print(ret.content)
# 认证,处理ssl(不讲了)3 代理
## 代理
# 网上会有免费代理,不稳定
# 使用代理有什么用?
# drf:1分钟只能访问6次,限制ip
# 每次发请求都使用不同代理,random一下
# 代理池:列表,其实就是代理池的一种
import requests
# ret=requests.get('https://www.cnblogs.com/',proxies={'http':'222.85.28.130:40505'})
#高匿:服务端,根本不知道我是谁
#普通:服务端是能够知道我的ip的
# http请求头中:X-Forwarded-For:代理的过程
# ret=requests.get('http://101.133.225.166:8080',proxies={'http':'222.85.28.130:40505'})
# ret=requests.get('http://101.133.225.166:8080',proxies={'http':'114.99.54.65:8118'})
# print(ret.text)4 爬视频
############
# 2 爬取视频
#############
#categoryId=9 分类id
#start=0 从哪个位置开始,每次加载12个
# https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=9&start=0
import requests
import re
ret=requests.get('https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=9&start=0')
# print(ret.text)
# 正则取解析
reg=''
video_urls=re.findall(reg,ret.text)
print(video_urls)
for url in video_urls:
ret_detail=requests.get('https://www.pearvideo.com/'+url)
reg='srcUrl="(.*?)",vdoUrl=srcUrl'
mp4_url=re.findall(reg,ret_detail.text)[0] #type:str
# 下载视频
video_content=requests.get(mp4_url)
video_name=mp4_url.rsplit('/',1)[-1]
with open(video_name,'wb') as f:
for line in video_content.iter_content():
f.write(line)5 自动登录网站
############
# 3 模拟登陆某网站
#############
import requests
ret = requests.post('http://www.aa7a.cn/user.php',
data={
'username': '[email protected]',
'password': 'lqz123',
'captcha': 'f5jn',
'remember': '1',
'ref': 'http://www.aa7a.cn/',
'act': 'act_login',
})
cookie=ret.cookies.get_dict()
print(cookie)
# 如果不出意外,咱么就登陆上了,再向首页发请求,首页返回的数据中就有[email protected]
ret1=requests.get('http://www.aa7a.cn/',cookies=cookie)
# ret1=requests.get('http://www.aa7a.cn/')
print('[email protected]' in ret1.text)
# 秒杀小米手机,一堆小号
# 定时任务:一到时间,就可以发送post请求,秒杀手机
# 以后碰到特别难登陆的网站,代码登陆不进去怎么办?
# 之所以要登陆,就是为了拿到cookie,下次发请求(如果程序拿不到cookie,自动登陆不进去)
# 就手动登陆进去,然后用程序发请求爬虫二:
昨日回顾
# 1 爬虫基本原理:发送http请求(requests)----》拿到数据(html,json)(re,bs4)---》入库(文件,excel,mysql,redis,mongodb)
# 2 爬虫协议:哪部分允许你爬,哪部分不允许:robots.txt,爬数据的时候,一定要注意速度
# 3 http回顾,应用层协议,请求协议和响应协议
# 4 requests模块:基于urlib封装的
# 5 基本使用 requests.get/post----》本质都是调用requests.request 函数
# 6 get请求携带参数(两种方式)
# 7 发送请求携带header(ua,referer,。。。。)
# 8 携带cookie 两种方式(放到头中,cookies={})
# 9 发送post请求,携带数据(data,json)
# 10 响应对象属性和方法 response对象
# 11 返回数据是json格式,json()--》直接转成字典
# 12 代理 ,普通,高匿,使用代理的方式,自己搭一个简单的代理池(列表)
# 13 超时,异常
# 14 上传文件
今日内容
1 requests+bs4爬汽车之家新闻
# 今日头条
# https://www.autohome.com.cn/news/1/#liststart
######
#2 爬取汽车之家新闻
######
import requests
# 向汽车之家发送get请求,获取到页面
ret=requests.get('https://www.autohome.com.cn/news/1/#liststart')
# ret.encoding='gb2312'
# print(ret.text)
# bs4解析(不用re了)
# 安装 pip3 install beautifulsoup4
# 使用
from bs4 import BeautifulSoup
# 实例化得到对象,传入要解析的文本,解析器
# html.parser内置解析器,速度稍微慢一些,但是不需要装第三方模块
# lxml:速度快一些,但是需要安装 pip3 install lxml
soup=BeautifulSoup(ret.text,'html.parser')
# soup=BeautifulSaoup(open('a.html','r'))
# find(找到的第一个)
# find_all(找到的所有)
# 找页面所有的li标签
li_list=soup.find_all(name='li')
for li in li_list:
# li是Tag对象
# print(type(li))
h3=li.find(name='h3')
if not h3:
continue
title=h3.text
desc=li.find(name='p').text
# 对象支持[]取值,为什么?重写了__getitem__魔法方法
# 面试题:你使用过的魔法方法?
img=li.find(name='img')['src']# type:str
url=li.find(name='a')['href']
# 图片下载到本地
ret_img=requests.get('https:'+img)
img_name=img.rsplit('/',1)[-1]
with open(img_name,'wb') as f:
for line in ret_img.iter_content():
f.write(line)
print('''
新闻标题:%s
新闻摘要:%s
新闻链接:%s
新闻图片:%s
'''%(title,desc,url,img))2 bs4的使用(遍历文档树和查找文档树)
# 1 从html或者xml中提取数据的python库,修改xml
# 补充:java,配置文件基本都是xml格式,以后可能会用python修改配置文件(自动化运维平台,devops平台),mycat,自动上线,自动安装软件,配置,查看nginx日志
# 视频,生鲜,crm,鲜果配送,在线教育,cmdb ---》(sugo平台)
# 飞猪 (旅游相关) 毒app 兔女郎遍历文档树
from bs4 import BeautifulSoup
html_doc = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
# pip3 install lxml
soup=BeautifulSoup(html_doc,'lxml')
# 美化
# print(soup.prettify())
# 遍历文档树
#1、用法(通过.来查找,只能找到第一个)
# Tag对象
# head=soup.head
# title=head.title
# # print(head)
# print(title)
# p=soup.p
# print(p)
#2、获取标签的名称
#Tag对象
# p=soup.body
# print(type(p))
from bs4.element import Tag
# print(p.name)
#3、获取标签的属性
# p=soup.p
# 方式一
# 获取class属性,可以有多个,拿到列表
# print(p['class'])
# print(p['id'])
# print(p.get('id'))
# 方式二
# print(p.attrs['class'])
# print(p.attrs.get('id'))
#4、获取标签的内容
# p=soup.p
# print(p.text) # 所有层级都拿出来拼到一起
# print(p.string) # 只有一层,才能去除
# print(list(p.strings)) # 把每次都取出来,做成一个生成器
#5、嵌套选择
# title=soup.head.title
# print(title)
#6、子节点、子孙节点
# p1=soup.p.children # 迭代器
# p2=soup.p.contents # 列表
# print(list(p1))
# print(p2)
#7、父节点、祖先节点
# p1=soup.p.parent # 直接父节点
# p2=soup.p.parents
# print(p1)
# # print(len(list(p2)))
# print(list(p2))
#8、兄弟节点
# print(soup.a.next_sibling) #下一个兄弟
# print(soup.a.previous_sibling) #上一个兄弟
#
# print(list(soup.a.next_siblings)) #下面的兄弟们=>生成器对象
# print(soup.a.previous_siblings) #上面的兄弟们=>生成器对象查找文档树
# 查找文档树(find,find_all),速度比遍历文档树慢
# 两个配合着使用(soup.p.find())
# 五种过滤器: 字符串、正则表达式、列表、True、方法
# 以find为例
#1 字符串查找 引号内是字符串
# p=soup.find(name='p')
# p=soup.find(name='body')
# print(p)
# 查找类名是title的所有标签,class是关键字,class_
# ret=soup.find_all(class_='title')
# href属性为http://example.com/elsie的标签
# ret=soup.find_all(href='http://example.com/elsie')
# 找id为xx的标签
# ret=soup.find_all(id='id_p')
# print(ret)
#2 正则表达式
# import re
# # reg=re.compile('^b')
# # ret=soup.find_all(name=reg)
# #找id以id开头的标签
# reg=re.compile('^id')
# ret=soup.find_all(id=reg)
# print(ret)
# 3 列表
# ret=soup.find_all(name=['body','b'])
# ret=soup.find_all(id=['id_p','link1'])
# ret=soup.find_all(class_=['id_p','link1'])
# and 关系
# ret=soup.find_all(class_='title',name='p')
# print(ret)
#4 True
# 所有有名字的标签
# ret=soup.find_all(name=True)
#所有有id的标签
# ret=soup.find_all(id=True)
# 所有有herf属性的
# ret=soup.find_all(href=True)
# print(ret)
# 5 方法
# def has_class_but_no_id(tag):
# return tag.has_attr('class') and not tag.has_attr('id')
#
# print(soup.find_all(has_class_but_no_id))
# 6 其他使用
# ret=soup.find_all(attrs={'class':"title"})
# ret=soup.find_all(attrs={'id':"id_p1",'class':'title'})
# print(ret)
# 7 拿到标签,取属性,取text
# ret=soup.find_all(attrs={'id':"id_p",'class':'title'})
# print(ret[0].text)
# 8 limit(限制条数)
# soup.find() 就是find_all limit=1
# ret=soup.find_all(name=True,limit=2)
# print(len(ret))
# 9 recursive
# recursive=False (只找儿子)不递归查找,只找第一层
# ret=soup.body.find_all(name='p',recursive=False)
# print(ret)3 带你搭一个免费的代理池
# https://github.com/jhao104/proxy_pool
# 收费的:提供给你一个接口,每掉一次这个接口,获得一个代理
# 免费:用爬虫爬取,免费代理,放到我的库中,flask,django搭一个服务(删除代理,自动测试代理可用性),每次发一个请求,获取一个代理
# 带你配置
# 1 下载,解压,用pycharm打开
# 2 安装依赖 pip install -r requirements.txt
# 3 配置Config/setting.py:
DB_TYPE = getenv('db_type', 'redis').upper()
DB_HOST = getenv('db_host', '127.0.0.1')
DB_PORT = getenv('db_port', 6379)
DB_PASSWORD = getenv('db_password', '')
# 4 本地启动redis-server
# 5 可以在cli目录下通过ProxyPool.py
-python proxyPool.py schedule :调度程序,他会取自动爬取免费代理
-python proxyPool.py webserver:启动api服务,把flask启动起来4 验证码破解
# 1 简单验证码,字母,数字
# 2 高级的,选择,你好,12306选择乒乓球,滑动验证(极验)
# 打码平台(自动破解验证码,需要花钱)云打码,超级鹰(12306)
http://www.yundama.com/
http://www.chaojiying.com/
# 注册账号,(充钱)把demo下载下来,运行即可5 爬取糗事百科段子,自动通过微信发给女朋友(老板)
## 6 爬取拉钩职位
## 7 爬取cnblogs新闻
## 8 爬取红楼梦小说写入txt
```
http://www.shicimingju.com/book/hongloumeng.html
```
## 9 爬取糗事百科段子,自动通过微信发给女朋友(老板)
## 10 肯德基餐厅信息
http://www.kfc.com.cn/kfccda/storelist/index.aspx#####
# 1 爬取糗事百科,微信自动发送
#####
# https://www.qiushibaike.com/text/
# https://www.qiushibaike.com/text/page/1/
import requests
from bs4 import BeautifulSoup
ret=requests.get('https://www.qiushibaike.com/text/page/1/')
# print(ret.text)
ll=[]
soup=BeautifulSoup(ret.text,"lxml")
article_list=soup.find_all(name='div',id=True,class_='article')
for article in article_list:
content=article.find(name='div',class_='content').span.text
# content=article.find(name='div',class_='content').text
# content=article.find(class_='content').text
# print(content)
# 入库
#我们放到列表中
ll.append(content)
print(ll)
# 微信自动发消息
# wxpy:实现了web微信的接口
# pip3 install wxpy
from wxpy import *
# 实例化得到一个对象,微信机器人对象
import random
bot=Bot(cache_path=True)
@bot.register() # 接收从指定好友发来的消息,发送者即recv_msg.sender为指定好友girl_friend
def recv_send_msg(recv_msg):
print('收到的消息:',recv_msg.text) # recv_msg.text取得文本
return random.choice(ll)
embed()爬虫三:
昨日回顾
# 1 requests+beautifulsoup4,汽车之家(find(name="li"))
-汽车资讯类的搜索引擎
# 2 bs4的简单使用:在html/xml中查找元素的模块(查找,修改)
# 3 遍历文档树 . 只能找到一个(速度快)
# 4 获取属性(Tag对象.attrs['href'])(Tag对象['href'])
# 5 text,string,strings
# 6 获取标签名字,子孙,父亲,兄弟
# 7 查找文档树:find和find_all (limit)
# 8 5种过滤器:字符串,列表,true,正则,方法
-find_all(name="字符串",href="字符串",id='',class_="字符串")
-find_all(attrs={'name':'字符串'})
# 9 糗事百科,拉钩,cnblogs文章
# 10 反扒:头信息,ua,referer,当前时间 time.time(),
-请求体中设置加密的东西:xxx:(id+时间戳+xxx)加密算法加密 js:加密算法
-杏树林:app+(前后端分离,后端写一堆接口:json格式)
-抓包工具
# 11 自动化运维平台项目:
资产收集,
监控类,
一条命令自动安装:3,4 mysql5.7(ansiable),修改mysql配置文件今日内容
1 css选择器和xpath选择器
# css选择器
#######
#1 css选择器
#######
# 重点
# Tag对象.select("css选择器")
# #ID号
# .类名
# div>p:儿子 和div p:子子孙孙
# 找div下最后一个a标签 div a:last-child
# css选择器,xpath选择器会用了,它就是个通行证(所有的都可以不会,会粘贴就行)
# bs4:自己的选择器,css选择器
# lxml:css选择器,xpath选择器
# selenium:自己的选择器,css选择器,xpath选择器
# scrapy框架:自己的选择器,css选择器,xpath选择器
# #select('.article')
#该模块提供了select方法来支持css,详见官网:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#id37
html_doc = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie
Lacie and
Tillie;
- Foo
- Bar
- Jay
Foo
- Bar
- Jay
and they lived at the bottom of a well.
...
"""
from bs4 import BeautifulSoup
soup=BeautifulSoup(html_doc,'lxml')
#1、CSS选择器(前端学的css选择)
print(soup.p.select('.sister'))
print(soup.select('.sister span'))
print(soup.select('#link1'))
print(soup.select('#link1 span'))
print(soup.select('#list-2 .element.xxx'))
print(soup.select('#list-2')[0].select('.element')) #可以一直select,但其实没必要,一条select就可以了
# 2、获取属性
print(soup.select('#list-2 h1')[0].attrs)
# 3、获取内容
print(soup.select('#list-2 h1')[0].get_text())# xpath选择
# / 从根节点选取 /a 从根节点开始,往下找a标签(子)
# //从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 //a 从根节点开始找a标签(子子孙孙中所有a)
# . 选取当前节点。
# .. 选取当前节点的父节点。
# @ 选取属性。
########
# 2 xpath选择器
########
# XPath 是一门在 XML 文档中查找信息的语言
# xpath选择
# / 从根节点选取 /a 从根节点开始,往下找a标签(子)
# //从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 //a 从根节点开始找a标签(子子孙孙中所有a)
# 取值 /text()
# 取属性 /@属性名
# //*[@id="auto-channel-lazyload-article"]/ul[1]
# //ul[1]
# //*[@id="focus-1"]/div[1]/ul/li[3]/h2
# #focus-1 > div.focusimg-pic > ul > li:nth-child(3) > h2
doc='''
Example website
'''
from lxml import etree
html=etree.HTML(doc) # 传字符串
# html=etree.parse('search.html',etree.HTMLParser()) # 文件
# 1 所有节点
# a=html.xpath('//*')
# 2 指定节点(结果为列表)
# a=html.xpath('//head')
# 3 子节点,子孙节点
# a=html.xpath('//div/a')
# a=html.xpath('//body/a') #无数据
# a=html.xpath('//body//a')
# 4 父节点
# a=html.xpath('//body//a[@href="image1.html"]/..')
# a=html.xpath('//body//a[@href="image1.html"]')
# a=html.xpath('//body//a[1]/..')
# 也可以这样
# a=html.xpath('//body//a[1]/parent::*')
# 5 属性匹配
# a=html.xpath('//body//a[@href="image1.html"]')
# 6 文本获取 标签后加:/text() ********重点
# a=html.xpath('//body//a[@href="image1.html"]/text()')
# a=html.xpath('//body//a/text()')
# 7 属性获取 标签后:/@href ********重点
# a=html.xpath('//body//a/@href')
# # 注意从1 开始取(不是从0)
# a=html.xpath('//body//a[3]/@href')
# 8 属性多值匹配
# a 标签有多个class类,直接匹配就不可以了,需要用contains
# a=html.xpath('//body//a[@class="li"]')
# a=html.xpath('//body//a[@href="image1.html"]')
# a=html.xpath('//body//a[contains(@class,"li")]')
# a=html.xpath('//body//a[contains(@class,"li")]/text()')
# a=html.xpath('//body//a[contains(@class,"li")]/@name')
# 9 多属性匹配 or 和 and (了解)
# a=html.xpath('//body//a[contains(@class,"li") or @name="items"]')
# a=html.xpath('//body//a[contains(@class,"li") and @name="items"]/text()')
# a=html.xpath('//body//a[contains(@class,"li")]/text()')
# 10 按序选择
# a=html.xpath('//a[2]/text()')
# a=html.xpath('//a[2]/@href')
# 取最后一个(了解)
# a=html.xpath('//a[last()]/@href')
# a=html.xpath('//a[last()]/text()')
# 位置小于3的
# a=html.xpath('//a[position()<3]/@href')
# a=html.xpath('//a[position()<3]/text()')
# 倒数第二个
# a=html.xpath('//a[last()-2]/@href')
# 11 节点轴选择
# ancestor:祖先节点
# 使用了* 获取所有祖先节点
# a=html.xpath('//a/ancestor::*')
# # 获取祖先节点中的div
# a=html.xpath('//a/ancestor::div')
# a=html.xpath('//a/ancestor::div/a[2]/text()')
# attribute:属性值
# a=html.xpath('//a[1]/attribute::*')
# a=html.xpath('//a[1]/@href')
# child:直接子节点
# a=html.xpath('//a[1]/child::*')
# a=html.xpath('//a[1]/img/@src')
# descendant:所有子孙节点
# a=html.xpath('//a[6]/descendant::*')
# following:当前节点之后所有节点(递归)
# a=html.xpath('//a[1]/following::*')
# a=html.xpath('//a[1]/following::*[1]/@href')
# following-sibling:当前节点之后同级节点(同级)
# a=html.xpath('//a[1]/following-sibling::*')
# a=html.xpath('//a[1]/following-sibling::a')
# a=html.xpath('//a[1]/following-sibling::*[2]')
# a=html.xpath('//a[1]/following-sibling::*[2]/@href')
print(a)





2 selenium的简单使用
#1 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题
-可以操作浏览器(火狐,谷歌(建议你用谷歌),ie),模拟人的行为(人可以干啥,代码控制就可以干啥)
#2 测试开发和开发有什么区别
########
# 3 selenium的使用
#######
# pip3 install selenium
# 1 基本使用
from selenium import webdriver
# import time
# # 得到 一个谷歌浏览器对象
# # 代码不能直接操作浏览器,需要有一个浏览器驱动(配套的)
# # 下载谷歌浏览器驱动:http://npm.taobao.org/mirrors/chromedriver/
# # 谷歌浏览器驱动要跟谷歌版本对应
# # http://npm.taobao.org/mirrors/chromedriver/80.0.3987.106/ :80.0.3987.149(正式版本)
# # 指定一下驱动的位置(相对路径/绝对路径)
# bro=webdriver.Chrome(executable_path='./chromedriver')
#
# bro.get("https://www.baidu.com")
#
# # 页面内容
# # ret.text 相当于它,可以使用bs4解析数据,或者用selenium自带的解析器解析
# print(bro.page_source)
# time.sleep(5)
# bro.close()3 selenium的高级用法
# import time
# # 2 常用用法(在输入框中输入美女,搜索)
# bro=webdriver.Chrome(executable_path='./chromedriver')
#
# bro.get("https://www.baidu.com")
# # 在输入框中输入美女(自带的解析器,查找输入框空间)
# # 1、find_element_by_id # id找
# # 2、find_element_by_link_text # a标签上的文字找
# # 3、find_element_by_partial_link_text # a标签上的文字模糊
# # 4、find_element_by_tag_name # 根据标签名字找
# # 5、find_element_by_class_name # 根据类名字找
# # 6、find_element_by_name # name='xx' 根据name属性找
# # 7、find_element_by_css_selector # css选择器找
# # 8、find_element_by_xpath #xpath选择器找
#
# # //*[@id="kw"]
# # input_search=bro.find_element_by_xpath('//*[@id="kw"]')
# input_search=bro.find_element_by_css_selector('#kw')
#
# # 写文字
# input_search.send_keys("美女")
# # 查找搜索按钮
# enter=bro.find_element_by_id('su')
#
# time.sleep(3)
# # 点击按钮
# enter.click()
#
# time.sleep(5)
# bro.close()
# 3 小案例
# import time
# bro=webdriver.Chrome(executable_path='./chromedriver')
# bro.get("https://www.baidu.com")
#
# # 隐士等待(最多等待10s)
# # 只有控件没有加载出来,才会等,控件一旦加载出来,直接就取到
# bro.implicitly_wait(10)
#
# submit_button=bro.find_element_by_link_text('登录')
# submit_button.click()
#
# user_button=bro.find_element_by_id('TANGRAM__PSP_10__footerULoginBtn')
# user_button.click()
#
# user_input=bro.find_element_by_id('TANGRAM__PSP_10__userName')
# user_input.send_keys("[email protected]")
#
# pwd_input=bro.find_element_by_id('TANGRAM__PSP_10__password')
# pwd_input.send_keys("123456")
#
#
# submit_input=bro.find_element_by_id('TANGRAM__PSP_10__submit')
# submit_input.click()
#
# time.sleep(5)
# bro.close()
# 4 获取cookie
# 登陆之后,拿到cookie:就可以自己搭建cookie池(requests模块发请求,携带者cookie)
# # import time
# bro=webdriver.Chrome(executable_path='./chromedriver')
# bro.get("https://www.baidu.com")
# print(bro.get_cookies())
# bro.close()
#
# #搭建cookie池和代理池的作用是什么?封ip ,封账号(弄一堆小号,一堆cookie)
# 5 无界面浏览器(驱动谷歌,驱动其他浏览器)
# from selenium.webdriver.chrome.options import Options
# chrome_options = Options()
# chrome_options.add_argument('window-size=1920x3000') #指定浏览器分辨率
# chrome_options.add_argument('--disable-gpu') #谷歌文档提到需要加上这个属性来规避bug
# chrome_options.add_argument('--hide-scrollbars') #隐藏滚动条, 应对一些特殊页面
# chrome_options.add_argument('blink-settings=imagesEnabled=false') #不加载图片, 提升速度
# chrome_options.add_argument('--headless') #浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败
#
# bro=webdriver.Chrome(executable_path='./chromedriver',options=chrome_options)
# bro.get("https://www.baidu.com")
# print(bro.get_cookies())
# bro.close()
# 6 获取标签属性
# (重点:获取属性)
# print(tag.get_attribute('src'))
# print(tag.get_attribute('href'))
#(重点:获取文本)
# print(tag.text)
#
# #获取标签ID,位置,名称,大小(了解)
# print(tag.id)
# print(tag.location)
# print(tag.tag_name)
# print(tag.size)
# 7 显示等待和隐士等待
# 隐士等待(最多等待10s)
# 只有控件没有加载出来,才会等,控件一旦加载出来,直接就取到
# bro.implicitly_wait(10)
# 显示等待(每个控件,都要写等待),不要使用
# 8 元素交互操作 点击click,清空clear,输入文字send_keys
#9 执行js
import time
# bro=webdriver.Chrome(executable_path='./chromedriver')
#
# bro.get("https://www.cnblogs.com")
# # 执行js代码
# # bro.execute_script('alert(1)')
# # window.scrollTo(0,document.body.scrollHeight)
# bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
# time.sleep(5)
# bro.close()
# 10 模拟浏览器前进后推
# import time
# bro=webdriver.Chrome(executable_path='./chromedriver')
#
# bro.get("https://www.cnblogs.com")
# time.sleep(1)
# bro.get("https://www.baidu.com")
# time.sleep(1)
# bro.get("https://www.jd.com")
#
# #退到上一个
# bro.back()
# time.sleep(1)
# # 前进一下
# bro.forward()
#
# time.sleep(5)
# bro.close()
# 10 选项卡管理
# import time
# from selenium import webdriver
#
# browser=webdriver.Chrome(executable_path='./chromedriver')
# browser.get('https://www.baidu.com')
# browser.execute_script('window.open()')
#
# print(browser.window_handles) #获取所有的选项卡
# browser.switch_to_window(browser.window_handles[1])
# browser.get('https://www.taobao.com')
# time.sleep(2)
# browser.switch_to_window(browser.window_handles[0])
# browser.get('https://www.sina.com.cn')
# browser.close()
# 11 异常处理
# from selenium import webdriver
# from selenium.common.exceptions import TimeoutException,NoSuchElementException,NoSuchFrameException
#
# try:
# browser=webdriver.Chrome(executable_path='./chromedriver')
# browser.get('http://www.baidu.com')
# browser.find_element_by_id("xxx")
#
# except Exception as e:
# print(e)
# finally:
# browser.close()4 爬取京东商品信息
########
# 爬取京东商品信息
#######
from selenium import webdriver
import time
from selenium.webdriver.common.keys import Keys
bro=webdriver.Chrome(executable_path='./chromedriver')
def get_goods(bro):
# find_elements_by_class_name 找所有
# find_element_by_class_name 找一个
li_list=bro.find_elements_by_class_name('gl-item')
# ul_list=bro.find_elements_by_css_selector('.gl-item')
for li in li_list:
url=li.find_element_by_css_selector('.p-img>a').get_attribute('href')
url_img=li.find_element_by_css_selector('.p-img img').get_attribute("src")
if not url_img:
url_img='https:'+li.find_element_by_css_selector('.p-img img').get_attribute("data-lazy-img")
price=li.find_element_by_css_selector('.p-price i').text
name=li.find_element_by_css_selector('.p-name em').text
commit=li.find_element_by_css_selector('.p-commit a').text
print('''
商品名字:%s
商品价格:%s
商品图片地址:%s
商品地址:%s
商品评论数:%s
'''%(name,price,url,url_img,commit))
#查找下一页按钮
next=bro.find_element_by_partial_link_text('下一页')
time.sleep(1)
next.click()
#继续抓取下一页
get_goods(bro)
try:
bro.get('https://www.jd.com')
#隐士等待
bro.implicitly_wait(10)
input_search=bro.find_element_by_id('key')
input_search.send_keys("精品内衣")
#模拟键盘操作(模拟键盘敲回车)
input_search.send_keys(Keys.ENTER)
get_goods(bro)
except Exception as e:
print(e)
finally:
bro.close()爬虫四:
昨日回顾
# 1 css选择器: #id号 .类名 div p div>p
# 2 xpath选择: / // @src /text() . ..
# 3 selenium:自动化测试用,解决不能执行js代码,操作浏览器,模拟人的行为(可见即可爬)
# 4 浏览器驱动(版本,型号对应)
# 5 send_keys,click,clear,键盘操作,执行js(下拉屏幕),获取cookie,打开选项卡,前进后退
# 6 爬取京东商品信息(css选择器和xpath选择器)今日内容
1 scarpy框架的安装和启动
# 1 框架 不是 模块
# 2 号称爬虫界的django(你会发现,跟django很多地方一样)
# 3 安装
-mac,linux平台:pip3 install scrapy
-windows平台:pip3 install scrapy(大部分人可以)
- 如果失败:
1、pip3 install wheel #安装后,便支持通过wheel文件安装软件,wheel文件官网:https://www.lfd.uci.edu/~gohlke/pythonlibs
3、pip3 install lxml
4、pip3 install pyopenssl
5、下载并安装pywin32:https://sourceforge.net/projects/pywin32/files/pywin32/
6、下载twisted的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
7、执行pip3 install 下载目录\Twisted-17.9.0-cp36-cp36m-win_amd64.whl
8、pip3 install scrapy
# 4 在script文件夹下会有scrapy.exe可执行文件
-创建scrapy项目:scrapy startproject 项目名 (django创建项目)
-创建爬虫:scrapy genspider 爬虫名 要爬取的网站地址 # 可以创建多个爬虫
# 5 启动爬虫
-scrapy crawl 爬虫名字
-scrapy crawl 爬虫名字 --nolog
# 6 不在命令行下执行爬虫
-在项目路径下创建一个main.py,右键执行即可
from scrapy.cmdline import execute
# execute(['scrapy','crawl','chouti','--nolog'])
execute(['scrapy','crawl','chouti'])2 scrapy架构
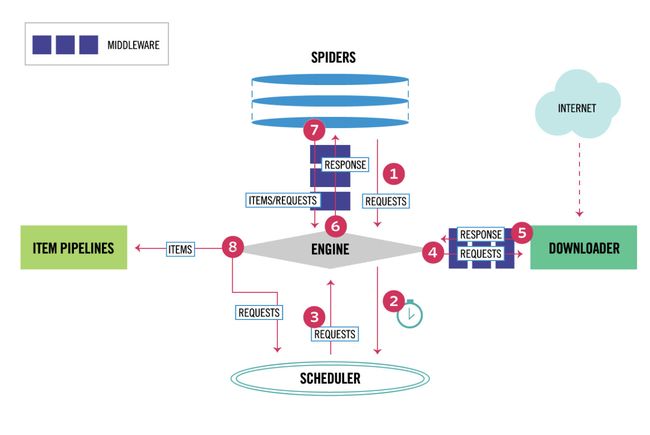
# 引擎(EGINE)(大总管)
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。有关详细信息,请参见上面的数据流部分。
# 调度器(SCHEDULER)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
# 下载器(DOWLOADER)
用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的
# 爬虫(SPIDERS)
SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求
# 项目管道(ITEM PIPLINES)
在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作
# 两个中间件
-爬虫中间件
-下载中间件(用的最多,加头,加代理,加cookie,集成selenium)3 配置文件,目录介绍
-crawl_chouti # 项目名
-crawl_chouti # 跟项目一个名,文件夹
-spiders # spiders:放着爬虫 genspider生成的爬虫,都放在这下面
-__init__.py
-chouti.py # 抽屉爬虫
-cnblogs.py # cnblogs 爬虫
-items.py # 对比django中的models.py文件 ,写一个个的模型类
-middlewares.py # 中间件(爬虫中间件,下载中间件),中间件写在这
-pipelines.py # 写持久化的地方(持久化到文件,mysql,redis,mongodb)
-settings.py # 配置文件
-scrapy.cfg # 不用关注,上线相关的
# 配置文件
ROBOTSTXT_OBEY = False # 是否遵循爬虫协议,强行运行
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36' # 请求头中的ua
LOG_LEVEL='ERROR' # 这样配置,程序错误信息才会打印,
#启动爬虫直接 scrapy crawl 爬虫名 就没有日志输出
# scrapy crawl 爬虫名 --nolog
# 爬虫文件
class ChoutiSpider(scrapy.Spider):
name = 'chouti' # 爬虫名字
allowed_domains = ['https://dig.chouti.com/'] # 允许爬取的域
start_urls = ['https://dig.chouti.com/'] # 起始爬取的位置,爬虫一启动,会先向它发请求
def parse(self, response): # 解析,请求回来,自动执行parser,在这个方法中做解析
print('---------------------------',response)4 以抽屉为例,爬取数据并解析
# 1 解析,可以使用bs4解析
from bs4 import BeautifulSoup
soup=BeautifulSoup(response.text,'lxml')
soup.find_all()
# 2 内置的解析器
# response.css
# response.xpath
# 解析
# 所有用css或者xpath选择出来的都放在列表中
# 取第一个:extract_first()
# 取出所有extract()
# css选择器取文本和属性:
# .link-title::text
# .link-title::attr(href)
# xpath选择器取文本和属性
# .//a[contains(@class,"link-title")/text()]
#.//a[contains(@class,"link-title")/@href]5 持久化
# 方式一(讲完就忘了)
-1 parser解析函数,return 列表,列表套字典
-2 scrapy crawl chouti -o aa.json (支持:('json', 'jsonlines', 'jl', 'csv', 'xml', 'marshal', 'pickle')
# 方式二 pipline的方式(管道)
-1 在items.py中创建模型类
-2 在爬虫中chouti.py,引入,把解析的数据放到item对象中(要用中括号)
-3 yield item对象
-4 配置文件配置管道
ITEM_PIPELINES = {
# 数字表示优先级(数字越小,优先级越大)
'crawl_chouti.pipelines.CrawlChoutiPipeline': 300,
'crawl_chouti.pipelines.CrawlChoutiRedisPipeline': 301,
}
-5 pipline.py中写持久化的类
-spider_open
-spider_close
-process_item(在这写保存到哪)6 动作链,自动登录12306
# 1 生成一个动作练对象
action=ActionChains(bro)
# 2 点击并夯住某个控件
action.click_and_hold(div)
# 3 移动(三种方式)
# action.move_by_offset() # 通过坐标
# action.move_to_element() # 到另一个标签
# action.move_to_element_with_offset() # 到另一个标签,再偏移一部分
# 4 真正的移动
action.perform()
# 5 释放控件(松开鼠标)
action.release()爬虫五:
昨日回顾
# 有没有面试机会,取决于你的简历(简历,是可以润色的)3年工作经验,激进一些,不要那么保守
# 属性python,熟悉oop,熟悉pep8规范
# 熟悉django,flask
# 了解redis,了解linux,能部署项目
# 了解celery,能简单的集成到django中
# 能不能入职,取决于你的面试表现
# 1 scrapy 安装:pip3 install scray
# 2 scrapy startproject 项目名字
# 3 scrapy genspider 爬虫名字 地址
# 4 目录结构
# 5 架构:5大组件,2大中间件
# 6 以抽屉为例:css选择器和xpath选择器
-extract()
-extract_first()
-css文本: ::text
-css属性: ::attr(属性名)
-xpath文本: /text()
-xpath属性: /@属性名
# 7 持久化的两种方案
-用命令 scrapy crawl 爬虫 -o 文件名.json (parser:必须return 列表)
-通过管道方式
-1 写一个模型类
-2 爬虫的parser函数中,把解析出的数据,放到模型类对象中 yield 对象
-3 在setting中配置(数字越小,优先级越高)
-4 piplins中写一个类, open_spider close_spider process_item(是否:return)
# 8 动作链(了解) 自动登录12306(登录不是你的目的)cookie:能自动登录就登陆,不能就手动登陆
-获取到cookie:redis(搭建cookie池)
-只是定时任务(apscheduler)
-celery:定时任务和异步任务
-windows 不支持(明明白白写的,不支持windows)今日内容
1 全站爬取cnblogs
# 1 scrapy startproject cnblogs_crawl
# 2 scrapy genspider cnblogs www.cnblogs.com2 scarpy请求传参
# 1 放 :yield Request(url,callback=self.parser_detail,meta={'item':item})
# 2 取:response.meta.get('item')3 提高爬取效率
- 在配置文件中进行相关的配置即可:(默认还有一套setting)
#1 增加并发:
默认scrapy开启的并发线程为32个,可以适当进行增加。在settings配置文件中修改CONCURRENT_REQUESTS = 100值为100,并发设置成了为100。
#2 提高日志级别:
在运行scrapy时,会有大量日志信息的输出,为了减少CPU的使用率。可以设置log输出信息为INFO或者ERROR即可。在配置文件中编写:LOG_LEVEL = ‘INFO’
# 3 禁止cookie:
如果不是真的需要cookie,则在scrapy爬取数据时可以禁止cookie从而减少CPU的使用率,提升爬取效率。在配置文件中编写:COOKIES_ENABLED = False
# 4禁止重试:
对失败的HTTP进行重新请求(重试)会减慢爬取速度,因此可以禁止重试。在配置文件中编写:RETRY_ENABLED = False
# 5 减少下载超时:
如果对一个非常慢的链接进行爬取,减少下载超时可以能让卡住的链接快速被放弃,从而提升效率。在配置文件中进行编写:DOWNLOAD_TIMEOUT = 10 超时时间为10s4 下载中间件
# 2大中间件:下载中间件,爬虫中间件
# 1 写在middlewares.py中(名字随便命名)
# 2 配置生效()
SPIDER_MIDDLEWARES = {
'cnblogs_crawl.middlewares.CnblogsCrawlSpiderMiddleware': 543,
}
DOWNLOADER_MIDDLEWARES = {
'cnblogs_crawl.middlewares.CnblogsCrawlDownloaderMiddleware': 543,
}
# 2 下载中间件
-process_request:(请求去,走)
# - return None: 继续处理当次请求,进入下一个中间件
# - return Response: 当次请求结束,把Response丢给引擎处理(可以自己爬,包装成Response)
# - return Request : 相当于把Request重新给了引擎,引擎再去做调度
# - 抛异常:执行process_exception
-process_response:(请求回来,走)
# - return a Response object :继续处理当次Response,继续走后续的中间件
# - return a Request object:重新给引擎做调度
# - or raise IgnoreRequest :process_exception
-process_exception:(出异常,走)
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain :停止异常处理链,给引擎(给爬虫)
# - return a Request object: stops process_exception() chain :停止异常处理链,给引擎(重新调度)5 集成selenium
# 在爬虫已启动,就打开一个chrom浏览器,以后都用这一个浏览器来爬数据
# 1 在爬虫中创建bro对象
bro = webdriver.Chrome(executable_path='/Users/liuqingzheng/Desktop/crawl/cnblogs_crawl/cnblogs_crawl/chromedriver')
# 2 中间件中使用:
spider.bro.get(request.url)
text=spider.bro.page_source
response=HtmlResponse(url=request.url,status=200,body=text.encode('utf-8'))
return response
# 3 关闭,在爬虫中
def close(self, reason):
self.bro.close()6 fake-useragent
# 请求头中的user-agent
list=['','']
# pip3 install fake-useragent
# https://github.com/hellysmile/fake-useragent
from fake_useragent import UserAgent
ua=UserAgent(verify_ssl=False)
print(ua.random)7 去重源码分析
# 去重源码分析
# from scrapy.core.scheduler import Scheduler
# Scheduler下:def enqueue_request(self, request)方法判断是否去重
if not request.dont_filter and self.df.request_seen(request):
Requests对象,RFPDupeFilter对象
# 如果要自己写一个去重类
-写一个类,继承BaseDupeFilter类
-重写def request_seen(self, request):
-在setting中配置:DUPEFILTER_CLASS = '项目名.dup.UrlFilter'
# scrapy起始爬取的地址
def start_requests(self):
for url in self.start_urls:
yield Request(url)
-增量爬取(100链接,150个链接)
-已经爬过的,放到某个位置(mysql,redis中:集合)
-如果用默认的,爬过的地址,放在内存中,只要项目一重启,就没了,它也不知道我爬过那个了,所以要自己重写去重方案
-你写的去重方案,占得内存空间更小
-bitmap方案
-BloomFilter布隆过滤器
from scrapy.http import Request
from scrapy.utils.request import request_fingerprint
# 这种网址是一个
requests1=Request(url='https://www.baidu.com?name=lqz&age=19')
requests2=Request(url='https://www.baidu.com?age=18&name=lqz')
ret1=request_fingerprint(requests1)
ret2=request_fingerprint(requests2)
print(ret1)
print(ret2)
# bitmap去重 一个小格表示一个连接地址 32个连接,一个比特位来存一个地址
# https://www.baidu.com?age=18&name=lqz ---》44
# https://www.baidu.com?age=19&name=lqz ---》89
# c2c73dfccf73bf175b903c82b06a31bc7831b545假设它占4个bytes,4*8=32个比特位
# 存一个地址,占32个比特位
# 10个地址,占320个比特位
#计算机计量单位
# 比特位:只能存0和1
# 8个比特位是一个bytes
# 1024bytes=1kb
# 1024kb=1m
# 1024m=1g
# 布隆过滤器:原理和python中如何使用
def request_seen(self, request):
# 把request对象传入request_fingerprint得到一个值:aefasdfeasd
# 把request对象,唯一生成一个字符串
fp = self.request_fingerprint(request)
#判断fp,是否在集合中,在集合中,表示已经爬过,return True,他就不会再爬了
if fp in self.fingerprints:
return True
# 如果不在集合中,放到集合中
self.fingerprints.add(fp)
if self.file:
self.file.write(fp + os.linesep)8 分布式爬虫
# 1 安装pip3 install scrapy-redis
# 源码部分,不到1000行,
# 1 原来的爬虫继承
from scrapy_redis.spiders import RedisSpider
class CnblogsSpider(RedisSpider):
#start_urls = ['http://www.cnblogs.com/']
redis_key = 'myspider:start_urls'
# 2 在setting中配置
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300
}
# 3 多台机器上启动scrapy
# 4 向reids中发送起始url
lpush myspider:start_urls https://www.cnblogs.com补充
# 编译型语言和解释型语言
# python,js,php 解释型: 一定要有个解释器 (全都夸平台,在不同平台装不通平台的解释器即可)
# 编译型语言:c,c++ java(有人说是编译型,有人说是解释型)
-java:jdk,jre,jvm(三个分别是啥)
-jdk:java开发环境(开发人员要装)
-jre:java运行环境(要运行java程序,必须装)
-jvm:java虚拟机,所有的java程序必须运行在虚拟机之上
-java对外发布:跨平台,一处编码,处处运行(1990年)
-java编译----》字节码文件(.class文件)----》字节码文件在jvm上运行---》在不同平台装不通java虚拟---》实现了跨平台
-java:1.5---》古老 1.6 1.7 ---》java 8(用的还比较多)---》java9 ---》java13
-c语言:写完了,想在windwos下运行----》跑到windows机器下编译成可执行文件
-想在linux下运行----》跑到linux机器下编译成可执行文件
-linux上装python环境(源码安装,make,make install)
-go编译型:跨平台编译(在windows上可以编译出linux下可执行文件)---》2009年--》微服务
-所有代码都编译成一个可执行文件(web项目---》编译之后---》可执行文件---》丢到服务器就能执行,不需要安装任何依赖)
-java要运行---》最低最低要跑在java虚拟机之上(光jvm要跑起来,就占好几百m内存)---》
-安卓手机app--java开发的---》你的安卓手机在上面跑了个jvm
-go:就是个可执行文件(go的性能比java高,他俩不相上下),阿里:自己写了jvm
-安卓:谷歌,---->当时那个年代,java程序员多---》java可以快速转过去---》
-谷歌:Kotlin:---》用来取代java---》写安卓---》在国际上排名比go高
-同年ios/mac软件:object-c-----》swift(苹果的一个工程师,没事的时候,写的一个语言)---》过了没几年,跳槽去了facebook----》
-java:sun公司出的,后来被甲骨文收购了,开始恶心人---》把java做成收费---》一门收费
-c#:微软的:一开始收费,比java要好,没人用,免费,开源了,也没人用
-java se java ee java me
-python写的代码,用打包工具,打包成exe----》把代码和解释器统统打包到exe中了
-垃圾回收机制:挺高端# 1 代码发布系统 +cmdb+监控+日志---》devops平台、自动化运维平台
# 2 go挺高级(并发)前端,mysql,redis,mongodb,es 缺了个go的web框架,orm
-beego:中国人写的(跟django很像。orm,中间件。。。。。)https://beego.me/docs/intro/
-gin:老外写的(flask,没有orm ),gorm https://github.com/gin-gonic/gin
-Iris: