基础
浏览器向某个网址发送请求,浏览器底层发生了什么
arp协议
HTTP请求流程
假设在web浏览器的地址栏输入:www.baidu.com,然后回车
## 过程:
1、对www.baidu.com这歌网址进行DNS解析,得到对应的IP地址
DNS域名解析是采用的递归查询的方式,过程是:先去浏览器缓存-》系统缓存(host文件)-》路由器缓存-》缓存找不到就去根域名服务器-》根域名找不到就去下一级。。。这样递归查找后,找到了ip返回给我们的web浏览器
2、根据这个ip,找到对应的服务器,发起TCP的三次握手,建立tcp连接
为什么要基于TCP协议呢?因为TCP是一个端到端的可靠面向连接的协议,HTTP基于传输层TCP协议不用担心数据的各种问题,当发生错误时,会重传
3、通过http协议发起http请求
4、服务器响应HTTP请求,浏览器得到html代码
5、释放tcp连接
浏览器所在主机向服务器发出连接释放报文,然后停止发送数据
服务器接收到释放报文后发出确认报文,然后将服务器上未传送完的数据发送完
服务器数据传输完毕以后,向客户发送连接释放报文
客户机收到报文后,发出确认,然后等一段时间后,释放tcp连接
6、浏览器解析html代码,并请求代码中的资源(如js、css、图片等),(先得到html代码才能去找这些代码)
7、浏览器对页面进行渲染,呈现给用户
内置函数:
__import__('time')
reverse 函数得到一个反向的列表
reversed 得到一个反向的迭代器
zip函数用于将可迭代的对象作为参数,将对象中的元素打包成一个个的元组,然后返回有这些元素组成的列表
abs函数去绝对值
all([可迭代对象]) # 从可迭代对象中取出来的值,全真才是真,一假则为假(特殊的:空迭代器返回True)
any([可迭代对象]) # 全假才是False(特殊的:空迭代器返回False)
callable 判断函数是否可被调用
chr 将十进制数转换成对应的ASCII字符
ord 将字符转换成对应的ASCII十进制数
dir 查看传入的值 可以调用的属性
divmod 传入除数和被除数,以元组的形式返回商和余数
eval 执行一个字符串表达式,返回表达式的值
filter([function],[iterable]) 用于过滤序列,序列的每个元素作为参数传递给函数进行判断,然后返回 True 或 False,最后将返回 True 的元素放到新列表中
bin 将十进制数转化成二进制数
oct 将十进制数转化成八进制数
hex 将十进制转化成十六进制数
enumerate 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列
format 格式化字符串的函数,
frozenset 返回一个冻结的集合
pow 返回x^y(x 的 y 次方) 的值
round(x,[y]) 返回浮点数的四舍五入值,保留y为小数
slice(起始, 终点, 步长) 切片
sorted 从小到大排序,返回列表
sum 对系列进行求和计算
exec 可以执行一段字符串类型的python代码
匿名函数:
没有名字的函数
print(min(dic, key = lambda k:dic[k]))
函数递归
函数在调用另一个函数的过程中又直接或者间接调用了自己
sys.getrecursionlimit() 可以查看最大递归层数
迭代器:
可迭代对象就是内只有__iter__方法的类型
对可迭代对象使用 __iter__方法可以得到迭代器
用__next__方法可以依次得到值
for循环本质上就是对迭代器循环取值
生成器
使用yield关键字自定义的迭代器
函数内出现了yield,调用函数就不会执行函数体代码,会得到一个生成器,挂起函数
生成式
l1 = [i for i in range(10) if i > 6]
s1 = {i for i in range(10)}
dic={f"{i}":i**2 for i in range(5) if i <3}
模块循环导入问题
根本原因在于:python中的模块导入一次以后就不会重新导入,而且只会在第一次导入的时候执行模块内的代码内容
在项目中应该避免出现循环/嵌套导入,如果出现多个模块都需要的数据,可以将共享的数据保存到公共文件夹
模块的搜索路径
内存中已经加载到额模块---》内置模块---》sys.path路径中包含的模块
常用模块
json.dunp(dic,f1) # 序列化
json.load(f2)
pickle只适用于django
hashlib.md5()
time
random
os 与操作系统交互
sys模块
subprocess
shutil 是一种高级的文件、文件夹、压缩包处理模块
xml模块 :实现不同语言或程序之间进行数据交换的协议
configparser模块
logging模块
re模块
类的实例化
先调用一个__new__方法创建一个空对象,
然后调用__init__方法进行初始化,完成空对象的初始化
返回一个初始化好的对象,用赋值符号将对象的内存地址绑定给stu1这种变量名
菱形问题:
子类继承的多个类最终汇集到一个非object类中
python使用了魔法方法__mro__计算出一个列表,将继承顺序放在了这个列表中
# C3算法:(简单一说)
- 每一个类的继承顺序都是从父类向子类中看,
- 形成一个指向关系的顺序[当前类]+[父类的继承顺序]
- 如果一个雷出现在从左到右的第一个顺序上,并且没有出现在后面的排序中,或者出现在后面的顺序中但依旧是第一顺序
- 那么就去这个类提取出来
由上图可知:B类,C类和D类是单继承,所以很容易看出L(B),L(C)和L(D)
L(B) = [BFGO]
L(C) = [CEO] (注:python3中所有类都是新式类,默认继承object类)
L[D] = [DGO]
然后分析多继承的A类的继承顺序:
L(A) = L(B)+L(C)+L(D)
A = [BFGO] + [CEO] + [DGO]
AB = [FGO] + [CEO] + [DGO]
ABF = [GO] + [CEO] + [DGO]
ABFC = [GO] + [EO] + [DGO]
ABFCE = [GO] + [O] + [DGO]
ABFCED = [GO] + [O] + [GO]
ABFCEDG = [O] + [O] + [O]
L(A) = [ABFCEDGO]
结果A类的继承顺序就为A,B,F,C,E,D,G,object.
也可以通过类的__mro__属性来查看当前类的继承顺序
super() 内置函数的寻找顺序也与此顺序相同
元类
类这种对象就是通过调用元类产生的。默认的元类就是type
class关键字在创建类的流程:(细分为四部分)
1、先拿到一个类名
2、拿到类的基类的名字
3、再运行类体代码,将产生的名字放进类的名称空间中
4、调用元类,传入类的三大元素:(类名,基类,类的名称空间)得到一个元类的对象
然后将元类的对象赋值给变量名
关于自定义元类:
先定义一个类(必须继承元类)
class Mymeta(type):
pass
class People(object, metaclass=Mymeta):
def __init__()
经典单例:
方式一:使用模块
单例模式是一种常用的软件设计模式,主要目的就是确保某个类只有一个实例存在
class Singleton(object):
def foo(self):
pass
singleton = Singleton()
# 将上面的代码保存文件a.py中
# ====
from a import singleton
方式二:使用装饰器
def Singleton(cls):
instance = None
def _singleton(*args, **kwargs):
nonlocal instance # 使用上一层的instance
if not instance:
instance = cls(*args, **kwargs)
return instance
return _singleton
@Singleton
class A(object):
def __init__(self, x=0):
self.x = x
a1 = A(2)
a2 = A(3)
print(a1.x) # 2
print(a2.x) # 2
print(a1 is a2) # a1和a2是同一个对象
方式三:使用类方法:
class Singleton(object):
_instance = None
def __init__(self):
pass
@classmethod
def instance(cls, *args, **kwargs):
if not cls._instance:
cls._instance = cls(*args, **kwargs)
return cls._instance
a1 = Singleton.instance()
a2 = Singleton.instance()
print(a1 is a2)
方式四:基于new方法实现
class Singleton(object):
_instance = None
def __init__(self):
pass
def __new__(self):
if not cls._instance:
cls._instance = object.__new__(cls)
return cls._instance
obj1 = Singleton()
obj2 = Singleton()
print(obj1 is obj2)
5、基于metaclass方式实现
class SingletonType(type): # 自定义元类
_instance = None
def __call__(cls, *args, **kwargs):
if not cls._instance:
cls._instance = object.__new__(cls)
cls._instance.__init__(*args, **kwargs)
return cls._instance
class Foo(metaclass=SingletonType):
def __init__(self, name):
self.name = name
obj1 = Foo('cc')
obj2 = Foo('cs')
print(obj2.name) # cc
print(obj1 is obj2)
type 和 isinstance 的区别:
type()不会认为子类的对象是一种父类的类型,
isinstance()会认为子类的对象是一种父类的类型
补充:issubclass()可以判断类是不是父类的子类,用法:issubclass(Sub, Parent)
反射机制:
反射
反射就是通过字符串来操作类或者对象的属性
反射本质就是再使用内置函数,其中反射有以下几个内置函数
hasattr:判断一个方法是否存在于这个类中
getattr:根据字符串中去获取obj对象里的对应的方法的内存地址,加括号就可以执行(只有使用.调用且属性不存在时才会触发)
setattr:通过setattr将外部的一个函数绑定到实例中
delattr:删除一个实例或者类中的方法
反射在模块中的使用
imp = input("模块名:")
cc = __import__(imp)
# cc.f1()
inp_func = input("函数名:")
f1 = getattr(cc, inp_func, None)
f1() # 执行模块中的f1方法
反射机制
反射就是通过字符串的形式,导入模块;通过字符串的形式,去模块中寻找指定的函数,并执行利用字符串的形式去对象中操作(查找/获取/删除/添加)成员,一种基于字符串的事件驱动
getattr,hasattr,setattr,delattr对模块的修改都在内存中进行,并不会影响文件中真实内容。
动态导入模块,并执行其中函数
url = input("url:")
target_module, target_func =url.split('/')
m= __import__('lib.'+target_module, fromlist=True)
inp = url.split('/')[-1]
if hasattr(m, target_func):
target_func = getattr(m, target_func) # 获取inp的引用
target_func() # 执行
else:
print("404")
- getattribute
查找属性,无论属性是否存在,都会执行
当getattribute与getattr同时存在,只会执行getattrbute,除非getattribute在执行过程中抛出异常AttributeError
- 描述符
描述符本质就是一个新式类,在这个新式类中,至少实现了get(),set(),delete()中的一个, 也被称作描述符协议
- get():调用一个属性的时候触发
- set():为一个属性赋值的时候触发
- delete():采用 del 的删除属性的时候触发
# 定义一个描述符:
class Foo:
def __get__(self, instance, owner):
pass
def __set__(self, instance, value):
pass
def __delete__(self, instance):
pass
# 作用:描述符是用来代理 另一个类 的属性的,必须将描述符定义成这个类的属性,不能定义到构造函数中
# 分类:
- 数据描述符:至少实现了get()和set()
- 非数据描述符:没有实现set()
# 注意点:
描述符本身应该定义为新式类,被代理的类也是新式类,
必须将描述符定义成这个类的类属性,不能定义到构造函数中
要严格遵循该优先级,优先级由高到低分别是
- 类属性
- 数据描述符
- 实例属性
- 非数据描述符
- 找不到的属性就会触发getattr()
# 总结:
1、描述符是可以实现大部分python类特性中的底层魔法方法,包括@classmethod/@staticmethod,@property甚至是slots属性
2、描述符是很多高级库和框架的重要工具之一,描述符是使用到装饰器或者元类的大型框架中的一个组件
- setitem、getitem、delitem与delattr
setitem:类的对象,中括号赋值时触发 f1['age']=19
getitem:类的对象,中括号取值时触发 f1['age']
delitem:中括号删除时触发 del f1['age']
delattr:.删除时触发 del f1.age
- slots
字典会占用大量内存,如果你有一个属性很少的类,但是有很多实例,为了节省内存可以使用slots取代实例的dict
当你定义slots后,slots就会为实例使用一种更加紧凑的内部表示。实例通过一个很小的固定大小的数组来构建,而不是为每个实例定义一个字典,这跟元组或列表很类似。在slots中列出的属性名在内部被映射到这个数组的指定小标上。使用slots一个不好的地方就是我们不能再给实例添加新的属性了,只能使用在slots中定义的那些属性名。
对象使用.添加属性会直接报错
# 注意:
slots的很多特性都依赖普通的基于字典的实现。另外,定义了一个slots后的类不再支持一些普通类特性了,比如多继承。大多数情况下,你应该只在那些经常被使用到的用作数据结构的类上定义slots,比如在程序中需要创建某个类的几百万个实例对象。
关于slots一个常见的误区就是他可以作为一个封装工具来防止用户给实例增加新的属性,尽管使用slots可以达到这样的目的,但是这个并不是他的初衷,他更多的用来作为一个内存优化工具
装饰器:
django-drf内置的装饰器:action
# 无参装饰器模板:
def outer():
def wrapper(*args, **kwargs):
res = func(*args, **kwargs)
return res
return wrapper
# 有参装饰器:
def outer2(x,y)a:
def outer1(func):
def wrapper(*args, **kwargs)
res = func(*args, **kwargs)
return res
return wrapper
return outer1
魔法方法:
见 反射机制
进程/线程/协程
进程
windows中使用的是CreateProcess创建进程,负责把正确的程序装进新进程,子进程与父进程的地址空间是不同的(UNIX中子进程的初始空间内的修改都不会影响到另一个进程)
任何进程在其地址空间内的修改都不会影响另一个进程
# 进程的终止
1、 正常退出(自愿,如用户点击交互式页面的叉号,或者程序执行完毕以后调用系统调用正常退出,在linux中用exit,在Windows中用ExitProcess)
2、出错退出(自愿,如python a.py 中a.py不存在)
3、严重错误(非自愿,执行非法指令)
4、被其他进程杀死(非自愿,如kill -9)
# 进程的状态
- 运行态
- 就绪态
- 阻塞态
进程挂起是自身原因,遇到IO阻塞,便要让出CPU让其他进程去执行,这样保证CPU可以一直运行
与进程无关,在操作系统层面,可能会因为一个进程占用时间过多,或者优先级原因,而调用其他的进程去使用CPU
# 进程调度
先来先服务
短时间优先
时间片轮转
多级反馈对列
- 阻塞与同步的区别:
- 阻塞调用是指在调用结果返回之前,当前线程会被挂起(例如遇到IO操作),函数只有得到结果之后才会将阻塞的线程激活
- 同步调用时,很多时候当前线程还是激活的,只是逻辑上当前函数没有返回而已(可能是在等IO,也有可能是在等计算结果),同步调用时,调用会一直等待,但是并未阻塞,即使CPU使用被抢走,当前进程也是处于就绪态,CPU执行权限一旦会开还是立马会进入运行态
- 非阻塞指的是调用在没有立即得到结果之前也会立刻反回,同时该函数不会阻塞当前进程
# 总结:
- 同步和异步针对的是函数/任务的调用方式:
同步就是当一个进程发起一个函数调用的时候,一直等到函数/任务完成,而进程会继续处于激活状态
异步就是当一个进程发起一个函数/任务调动的时候,不会等待函数返回,而是继续往下执行,函数返回的时候通过状态、通知、事件等方式通知进程任务完成
- 阻塞与非阻塞针对的是进程/线程:
阻塞是当请求不能满足的时候就将进程挂起
非阻塞不会阻塞当前进程
- multiprocessing模块
python中的多线程不能利用多核优势,想要充分利用多核CPU的资源,在python中大部分情况需要使用多进程
multiprocessing模块用来开启子进程,并在子进程中执行我们定制的任务(如函数)
multiprocessing模块还支持子进程、通信和共享数据、执行不同形式的同步,提供了Process、Queue、Pipe、Lock等模块
- Process模块
Process([group [, target [, name [, args [, kwargs]]]]]) # 创建进程的类
由该类实例化得到的对象,表示一个子进程的任务(尚未启动)
# 注意:需要用关键字来指定参数,args是为target任务(函数)传的位置参数,是一个元组
p.start():启动进程,并调用该子进程的p.run()
p.run():进程启动时运行的方法,调用target指定的函数
p.terminate():强制终止进程p,不会进行任何清理操作,p的子进程就会变成僵尸进程,p的锁就会变成死锁
p.is_alive():判断进程是否还在运行
p.join([timeout]):主线程会等待start开启的p进程终止,(对run开启的进程无效)
注意:主线程是处于等的状态,而p是处于运行状态,
timeout是可选的超时时间
# 属性介绍:
p.daemon:默认值是None,如果设置成True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止
p.name : 进程名称
p.pid :进程id
# 注意:
p.deamon=True 设置守护进程一定要写在p进程启动之前
- IPC :进程间通信
# multiprocessing支持使用队列和管道:都是使用消息传递的
队列和管道都是将数据放在内存中
队列是基于管道+锁实现的
# 创建队列的类————Queue
创建共享的进程队列,Queue([maxsize]),其中maxsize是队列中允许的最大项数,忽略则没有大小限制
# 方法:
- q.put() # 往队列中插入数据(可选参数有blocked和timeout)
# 如果blocked为True,timeout为正值,该方法会阻塞timeout指定的时间,直到该队列有剩余的空间,如果超时,抛异常queue.Full;
# 如果blocked为False,但是队列已满,也会抛出queue.Full异常
- q.get() # 从队列中读取并删除一个元素,取不到不会报错,会一直夯着,直到队列中有值再取出来
- q.get_nowait() # 等同于q.get(False),如果没有值可取就报错 _queue.Empty
- q.put_nowait() # 等同于q.put(False),如果队列已满,会抛出queue.Full异常
- q.empty() # 判断队列是否为空,不可靠,比如在返回True的过程中,队列又加入了项目
- q.full() # 判断q是否已满,结果同样不可靠,同上
- q.qsize() # 返回列表中的正确数量,结果同样不可靠
- 生产者消费者模式
# 实现方式: 生产者<——>队列<——>消费者
# JoinabkeQueue([maxsize])
就像一个Queue对象,但是队列允许项目的使用者通知生产者项目已经被成功处理,通知进程是使用共享的信号和条件变量实现的
# 除了和Queue对象相同的方法之外的方法:
- q.task_done():使用此方法发出信号,表示q.get()的返回项目已经被处理,如果调用此方法的次数大于从队列中删除项目的数量,将引发ValueError异常
- q.join():生产者调用此方式进行阻塞,直到队列中所有的项目均被处理
阻塞将持续到队列中的每一个项目均调用q.task_done()方法为止
进程互斥锁
- 多个进程之间虽然数据不共享,但是可以共享同一个文件系统,所以同时访问同一个文件或者使用同一个打印终端系统,可能会带来竞争导致错乱
- 多个进程可以加互斥锁(进程同步锁)处理这一问题,同一时间只有一个任务进行修改
缺点:(1)效率低(文件是硬盘上的数据)
(2)需要自己加锁处理
线程
线程是CPU调度的最小单位,每个进程至少要有一个线程
进程是系统资源分配的最小单位
相比进程,线程开销更小,更轻量级
# 在线程内修改全局变量是可以在全局查找到的
- threading模块
from threading import Thread, current_thread, active_count
# Threading模块提供的方法:
current_count():返回当前正在运行的线程数量
# Thread实例对象的方法:
t.isAlive() : 返回线程是否还在运行,推荐使用t.is_alive()
t.getName() : 返回线程名同t.name
t.setName() : 设置线程名
t.ident : 可以当作是线程的id号(线程是没有id号的,此方法主要用于区分不同线程)
守护线程:
# 无论是进程还是线程,都遵循守护进程/线程 会等待主进程/线程运行完毕后被销毁
# 对于主进程来说,运行完毕指的是主进程代码运行完毕
# 对于主线程来说,运行完毕指的是主线程所在的进程内,所有的非守护线程统统运行完毕,主线程才算运行完毕
线程互斥锁
from threading import Lock # 线程互斥锁
1、线程抢的是GIL锁,拿到执行权限后才能拿到互斥锁Lock,其他线程也可以抢到GIL,但是如果发现Lock没有被释放则阻塞,即便是拿到执行权限也要立即交出来
2、join是等待所有,即整体串行,而锁只是锁住修改共享数据的部分,即部分串行,
要想保证数据安全的根本原理在于让并发变成串行,join和互斥锁都可以实现,但是互斥锁的部分串行效率更高
线程Queue
- 线程queue有三种:
Queue(队列,先进先出)
LifoQueue(栈,后进后出)
prioityQueue(存储数据时可以设置成优先级,谁优先级小先出)
- 使用queue的好处
线程间通信,因为共享变量会出现数据不安全问题
用线程queue通信,不需要加锁,内部自带
queue是线程安全的
线程池使用:
from concurrent.futures import ThreadPoolExector
pool = ThreadPoolExecutor(2)
pool.submit(get_pages, url).add_done_callback(call_back)
示例:
from concurrent.futures import ThreadPoolExector
import time, random
def task(name):
print(f'{name}任务开始')
time.sleep(random.randint(1,3))
print('任务结束了')
return f'{name}返回了'
def call_back(f): # 一定要传参
print(f.result())
if __name__ == '__main__':
pool = ThreadPoolExecutor(2)
for i in range(10);
pool.submit(task, f'{i}线程').add_done_callback(call_back)
进程池
# 使用方法与线程池类似
from concurrent.futures import ProcessPoolExecutor
pool = ProcessPoolExecutor(n)
pool.submit(函数名, 参数).add_done_done_callback(call_back)
线程池和进程池的shutdown
主线程/进程 等待所有的任务执行完毕后,再将池子关闭,关闭以后就不能再提交任务了
from concurrent.futures import ProcessPoolExecutor
pool = ProcessPoolExecutor(3)
pool.shutdown(wait=True) # 等待所有的任务结束,并且把池子关闭
线程定时器
设定多长时间之后执行一个任务
使用Timer类
from threading import Timer
def task(name):
print(name)
if __name__ == '__main__':
t = Timer(2, task, args=('cc',)) # 本质是开一个线程
t.start()
协程
单线程的并发
一种用户态的轻量级线程,本质是在单线程下由用户自己控制一个任务遇到了IO阻塞就切换到另一个任务去执行,以此提升效率
协程要做的事情:
1、可以控制多个任务之间的切换,切换之前将任务的状态保存下来,以便重新运行,可以基于暂停的位置继续运行
2、可以检测IO操作,遇到IO操作的情况下发生切换
# 协程的优点:
协程的切换开销更小,属于程序级别的切换,操作体统完全感知不到,更轻量级
单线程内就可以实现并发的效果,最大限度的使用CPU
# 缺点:
协程的本质是单线程下,无法利用多核,可以是一个程序开启多个进程,每个进程内开启多个线程,每个线程内开启多个协程
协程指的是单个线程,因而一旦协程出现阻塞,将会阻塞整个线程
- 总结
必须在只有一个单线程里实现并发
修改共享数据不需要加锁
用户程序里可以保存多个控制流的上下文线
一个协程遇到IO操作自动切换到其他协程(需要使用gevent模块的select机制)
- greenlet模块
from greenlet import greenlet
import time
def eat(name):
print(f"{name}吃了一口")
t1.switch('cc')
print(f'{name}又吃了一口')
t1.switch()
def play(name):
print(f'{name}玩了一会')
t2.switch()
time.sleep()
print(f"{name}又玩了一会")
if __name__ == 'main':
t1 = greenlet(eat)
t2 = greenlet(play)
t1.switch('cc')
- gevent模块
gevent模块是基于greenlet模块写的一个第三方模块,实现了IO自动切换
g1 = gevent.spawn(func, 1,2,3,x=4,y=5)
g2 = gevent.spawn(func2)
g1.join()
g2.join()
# gevent.joinall([g1,g2]) 上面两行可以合并成一行
g1.value
- 猴子补丁
属性在运行时的动态替换
核心在于用自己的代码替换模块的源代码
# 应用场景
使用ujson代替json模块
在入口处加上:
import ujson, json
def monkey_path_json():
json.__name__ = 'ujson'
json.dumps = ujson.dumps
json.loads = ujson.loads
monkey_patch_json()
GIL锁
1、cpython中有一个全局大锁,内调线程要执行,必须先获取这个锁
所以说python的多线程其实还是单线程
2、GIL锁的作用:python的垃圾回收机制可能会将刚定义好但是还没有来得及赋值的变量名直接回收掉
3、某个线程想要执行,必须先拿到GIL这个“通行证”,并且在一个python进程中只有一个GIL,拿不到通行证的线程,就不允许进入CPU执行
# 总结:
cpython解释器中有一个全局锁,线程必须先获得GIL才能执行,
我们开的多线程,不管有几个CPU,同一时刻只有一个线程在执行(python的多线程不能利用多核优势)
针对IO密集型操作:开多线程
针对计算密集型:开多进程
GIL锁与普通互斥锁的区别
GIL锁本质就是一把互斥锁,既然都是互斥锁,都是将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务锁修改,进而保证数据安全
GIL保护的是解释器级别的数据,保护用户自己的数据则需要自己加锁处理
有了GIL的存在,同一时刻同一进程中只有一个线程被执行
死锁与递归锁
- 死锁:
指的是两个或者两个以上的进程或者线程中,因争夺资源而造成的一种永远在互相等待的现象
# 解决办法:
- 递归锁(可重入锁):
指的是同一个进程或者线程可以多次acquire,每acquire一次,内部计数器加一,每release一次,内部计数器减一
**只要计数器不为零,其他进程/线程就不能获得这把锁**
ip协议
IP协议定义的地址叫IP地址,现阶段使用的IPV4,规定的网络地址由32位二进制表示
范围: 0.0.0.0 - 255.255.255.255
IP地址两个部分:
网络部分:标识部分
主机部分:标识主机
单纯的IP地址只是标识了IP地址的种类,从网络部分或者主机部分都无法辨识一个IP所处的子网
子网掩码
就是表示子网特征的一个参数,在形式上等同于IP地址,也是一个32位二进制数字
网络部分全部为1,主机部分全部为0
ARP协议
计算机通信主要靠广播,所有的包最后都要封装上以太网头,然后通过以太网协议发送,
如何获取目标主机的mac就需要arp协议
ARP协议:每台主机的IP都是已知的
tcp协议:
网络层的ip帮助我们区分子网,以太网的mac帮助我们找到主机,然后通过端口找到我们使用的应用程序
0-1023是系统占用端口
tcp是可靠传输,TCP协议数据包没有长度限制,理论上可以无现限长
为了保证网络的效率,通常TCP数据包的长度一般不会超过ip数据包的长度,以确保单个TCP数据包不必再分割
tcp报文:

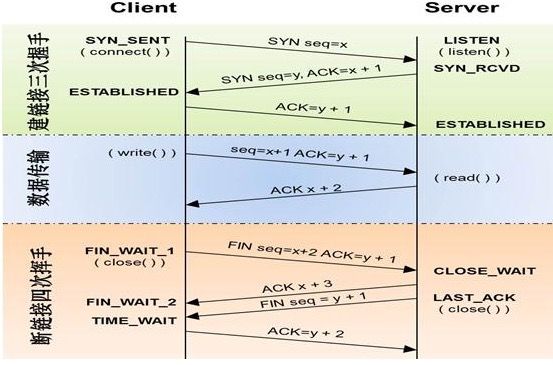
tcp三次握手与四次挥手:
详解:
# 三次握手原理:
TCP位于传输层,作用是提供可靠的字节流服务,为了准确无误的将数据送达目的地,TCP协议采纳三次握手策略
# 原理:
1、服务端首先发送一个带有SYN标志的数据包给接受方
2、服务端接受后,回传一个带有SYN/ACK标志的数据包传递确认信息,表示我收到了(半连接状态)
3、最后,客户端再回传一个ACK标志的数据包,代表我也知道了
握手结束
# 四次挥手:
1、第一次挥手:客户端发送一个FIN,用来关闭客户端到服务端的数据传送,客户端进入FIN_WAIT_1状态
2、第二次挥手:服务端收到FIN后,发送一个ACK给客户端,server进入close_wait状态
3、第三次挥手,服务端发送一个FIN,用来关闭服务端到客户端的数据传送,服务端ast_ack状态
4、第四次挥手:客户端收到FIN后,客户端进入time_wait状态,接着发送一个ack给服务端,确认序号为收到序号+1,服务端进入closed状态,完成第四次挥手
udp协议:
不可靠传输,报头一般只有8个字节,总长度不超过65535个字节
socket通信
唯一标识进程:ip地址+协议+端口号
socket是在应用层和传输层之间的一个抽象层,是一组接口
他把TCP/IP层复杂的操作抽象为几个简单的接口供应层调用已经实现进程在网络中通信
由于socket已经封装好了tcp/ip协议,自然就符合tcp/ip协议
IO模型
四种:
- BIO 阻塞模式IO
- NIO 非阻塞式IO
同一线程同一时刻只能监听一个socket,资源浪费
- IO多路复用(更成熟稳定)
类似BIO,但是找了一个代理,来挂起等待,并能同时监听多个请求
用的是epool模型,select模型最大1024个
- AIO-异步IO模型
发起请求逻辑得到回复,不用挂起等待
数据会由内核进程主动完成拷贝
# 注意:
1、如果处理的连接数不是很高的话,使用select/epool的web server不一定比multithreading+blocking IO的性能好,甚至延迟还更大
select/epool的优势并不是对单个连接能处理的更快,而是在于能处理更多的连接
2.在多路复用的模型中,对于每一个socket,一般设置成non-blocking但是整个用户的process其实都是一直被阻塞的
只不过process是被select这个函数阻塞,而不是被socket IO给block
# 结论:
select的优势就在于处理多个连接,不适用于单个连接
当监管对象只有一个的时候,其实IO多路复用还不如阻塞IO
但是IO对路复用可以一次性监管多个对象
- XSS攻击
XSS 攻击通常指的是通过利用网页开发时留下的漏洞,通过巧妙的方法注入恶意的指令代码到网页
使用户加载并执行攻击者恶意制造的网页程序
这些网页程序通常是JavaScript,甚至是普通的HTML,攻击成功的话攻击者可能会得到包括不限于更高的权限、私密网页内容、会话和cookie等内容
django是如何处理的?
# 1、后台视图或者模板中导入escape方法
from django.utils.html import escape
# 2、前端HTML页面中,对可能会出现攻击的字段增加escape过滤
示例: {{ user.username | escape }}
- sql注入
sql注入就是通过SQL命令插入到web表单提交或者输入域名或者页面请求的查询字符串,注入本质上就是把字符串变成可执行的程序语句最终达到欺骗服务器执行的sql命令,
具体来说它是利用现有的应用程序,将恶意的sql命令注入到后台数据库引擎执行的能力,他可以通过在web表单中输入恶意SQL语句得到一个存在安全漏洞的网站上的数据库,而不是按照设计意图去执行SQL语句
在web应用中,sql注入的风险高于其他所有的漏洞
python解决方案:
- 想要在flaskweb应用里面发现漏洞,不仅要注意get和post请求的参数,有可能出现问题的变量隐含在url中
pythonweb开发中,即使使用orm引擎,也有可能导致sql注入
sqlalchemy使用单引号包裹传进来的字符串变量,并使用\过滤字符串中的单引号
1. execute() 函数本身有接受sql语句参数位的,可以通过python自身的函数处理sql注入问题。
args = (id, type)
cur.execute('select id,name from user_table where id = %s and name = %s', args )
2. rs=c.execute("select * from log where f_UserName=:usr",{"usr":"jetz"})
3. rs=c.execute("select * from log where f_UserName=:1 ",["jetz"])
使用如此参数带入方式,python会自动过滤args中的特殊字符,制止SQL注入的产生。
哈希
散列函数,把任意长度的输入通过散列算法变成固定长度的输出,该输出就是散列值
这种转换是一种压缩映射,也就是散列值的空间通常小于输入的空间,不同的输入可能会导致散列成同样的输出,所以不可能从散列值来确定唯一的输入值。也就是说可能会导致哈希冲突
# 哈希冲突:
1、开放地址方法
(1)线性探测
如果某数据的值已经存在,则在原来的基础上往后在加一个单位,直至不发生哈希冲突
(2)再平方探测
在原来值的基础上加上1的平方个单位,如果还是冲突,随之是2的平方,3的平方
(3)伪随机探测
通过随机函数随机生成一个数,在原来的基础上加上随机数,直至不发生冲突
2、链式地址法
对于相同的值,使用链表进行链接,使用数组存储每一个链表
优点:
没有堆积现象,平均查找存储长度短
各链表上的结点空间空间动态申请,更适合于造表前无法确定表长的现象
删除结点的操作易于实现
缺点:
指针占用较大的空间时,会造成空间浪费
3、建立公共溢出区
存放所有哈希冲突的数据
4、再哈希法
对于冲突的哈希值,再次进行哈希处理,直至没有哈希冲突
哈希表
又称散列表,根据关键码值而直接进行访问的数据结构
也就是说,他通过把关键字码值映射到表中的一个位置来访问记录,以加快查找的速度,
这个映射函数叫做散列函数,存放记录的数组叫做散列表
django的DTL语法
# 模板标签:
{% for %}
{% if %}
{% csrf_token %}
{% static %}
{% with %}
{% url %}
{% include 模板名称 %}
{% extends 模板名称 %}
{% block %}
# 过滤器
ORM语法
auth模块
# django自带的用户认证模块,使用auth_user表存储数据
- authenticate()方法提供了用户认证功能,一般需要传username、passwword两个关键字参数(根据数据库字段名)
- login(request,user)函数实现一个用户登录的功能,本质上会在后端为该用户生成相关的session数据
调用了login函数以后,之后所有的视图函数都可使用request.user,它就是当前的登录用户
- logout函数,当前所有的session信息会被全部清除,即使用户没有登录,调用该功能也不报错
- login_required装饰器,用来给某个视图添加登录校验,没有登录就重定向到django默认的登录url
中介模型(自定义中间表,存储额外的字段)
class Book(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
authors = models.ManyToManyField(to="Author", through="AuthorToBook", through_fields=("book", "author"))
# through_fields接受一个元组('field1','field2'):
# 其中field1是定义当前表对应的外键的名(book),field2是关联目标模型(author)的外键名。
# 自己创建第三张表,并通过ManyToManyField指定关联
class Author(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
class AuthorToBook(models.Model):
author = models.ForeignKey(to="Author", to_field='nid', on_delete=models.CASCADE)
book = models.ForeignKey(to="Book", to_field='nid', on_delete=models.CASCADE)
# 使用这种模式建立多对多的关系,无法使用set、remove、clear、add方法来管理多对多的关系,因为第三张表不一定就只有author和book两个字段
restful规范:
具体的有十条规范:
包括api与用户的通信使用https协议
请求使用的method:get、post、put、patch、delete
过滤条件通过在url上传递搜索条件
状态码
错误处理
。。。
APIView源码分析
- APIVIew中的as_view方法,内部还是使用的VIew的闭包函数view,使用装饰器禁用了csrf,
- 原生View类中的闭包函数view,本质上是执行了self.dispatch方法,就是执行的apiview的dispatch方法,
- 在dispatch函数中,drf将request对象封装成了新的drf的request对象,然后在函数中执行了认证、权限、频率、异常捕获等,最后又将视图函数返回的response对象封装了一下返回出来
黑白名单
forms
django缓存
F/Q查询
F:可以将参数取出来计算
Q:用于合并条件,(与或非)
路由分发、有名分组、无名分组
反向解析
RBAC模式
request请求的生命请求周期
# 具体过程
web服务器--》http拆成字典--》调起可调用对象--》路由匹配--》执行视图函数(数据库取数据,模板文件拿模板渲染)--》生成html页面--》返回
浏览器发起request请求,发送到uwsgi服务器,再进入中间件处理,经过url路由层分发给对应的视图函数处理,处理过程中可能会调用视图层的静态文件或者数据库中处理数据,返回一个结果原路返回
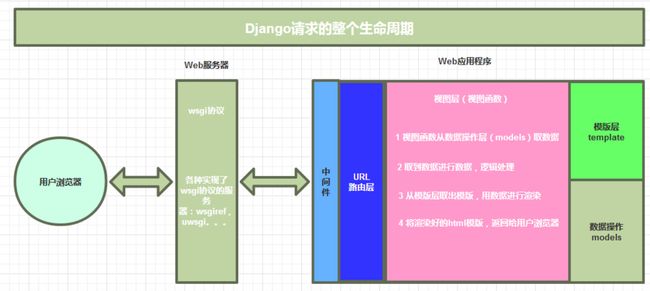
跨域请求
中间件
中间件是介于request与response处理之间的一道处理过程,相对比较轻量级,并且在全局上改变django的输入与输出
由于它影响的是全局,所以需要需要谨慎使用,用不好会影响到性能
如果想修改请求,例如被传送到view中的HTTPResponse对象,或者你想修改httpResponse对象,可以通过中间件实现
# 多个中间件的执行顺序:
请求来的时候从上而下执行
请求走的时候从下往上执行
# process_request的作用:
频率限制
登录认证
记录用户访问日志
# process_response作用:
内部有response对象,统一给所有的路径加上cookie、响应头,一定要返回response,否则后面的中间件执行时找不到response,会报错
# process_view
在路由匹配成功和视图函数执行之前执行
应该返回None或者HTTPResponse对象
- 返回None: django将继续处理这个请求,执行其他中间件的process_view方法,然后执行相应的视图
- 如果返回一个HTTPResponse对象,django将不会调用相应的视图函数,而是直接掉头,倒序执行中间件的process_response方法,最后返回给浏览器
# process_template_response
在视图函数执行完成后立即执行,前提是视图函数必须要返回一个render方法
# process_exception
视图函数出错,会执行它(全局异常捕获,倒序执行),可以记录日志,记录用户的ip地址,是访问的哪个路径出的错
自定义中间件步骤:
1、写一个类,继承MiddlewareMixin
2、在类中写process_request等方法,请求来了一定会触发此方法执行
3、在view.py中定义一个视图函数
4、settings.py中 MIDDLEWARE 中注册自己的中间件,要注意放的位置
CSRF_TOKEN跨站请求伪造
CSRF是一种跨站请求伪造,是一种对网站的恶意利用,与XSS不同,XSS利用站点内的信任用户,
CSRF通过伪造来自受信任用户的请求来利用受信任的网站
# django中解决CSRF攻击的方法
中间件 django.middleware.csrf.CsrfViewMiddleware
每次发送post请求的时候,都需要csrf_token随机字符
form提交时表单中添加{% csrf_token %}
ajax请求中提交:data中写csrfmiddlewaretoken
# 局部禁用csrf
from django.views.decorators.csrf_except
@csrf_exempt
def order(request):
pass
# 局部使用,全局使用
from django.views.decotators.csrf import csrf_project
@csrf_project
def order(request):
pass
jwt
jwt就是一段字符串,有三段信息组成,用.连接在一起使用就构成了jwt字符串
示例:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9.TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ
# 第一部分:头部(header)
- 说明类型,这里是jwt,声明加密算法,有的会在头里加入公司信息(最后使用base64转码)
# 第二部分:荷载(payload)
- 当前用户的信息(用户名:id,token过期时间,手机号),最后使用base64转码
# 第三部分:签证(signature)
签证信息由三部分组成:
- header(base64加密后的)
- payload(base64加密后的)
- secret
这部分需要base64加密后的header和base64加密后的payload使用.连接组成的字符串,然后通过header中声明的加密方式进行加盐secret组合加密,然后就组成了jwt第三部分
cookie
cookie具体指的是一段小信息,它是随着服务器端的响应发出客户端浏览器,存储在浏览器上的一组组键值对,下次访问服务器时,浏览器会自动携带这些键值对,以便服务器提取有用的信息
- 由服务器产生内容,浏览器收到请求后保存在本地
- 这样服务器就能通过cookie的内容来判断这是谁了
session
cookie最大支持4096字节,本身存放在客户端,可能会被拦截或者窃取,
因此产生了session,支持更多的字节,存放在服务器,保存私密的信息以及超过4096字节的文本
session是保存在服务器的键值对
同一个浏览器不允许同时登录多个账户,不同浏览器可以登录同一个账户
# session的工作原理:
1、第一次请求携带request.session['name']=xxx,
2、请求走的时候,中间件干两件事:1、将name=xxx加密写进表(django-session表)中,将随机字符串当做sessionid的value放到cookie中,
3、再次请求的时候,中间件拿随机字符串去数据库查,把数据解密放到request.session中,这样视图中就可以得到name,request.session.get('name')
4、后面再请求时要添加数据,把数据替换加密,放进数据库中
django中的session默认失效时间是14天
token
为了解决session将数据存放服务端造成服务器资源占用过大的情况,又出现了token以及jwt
用户第一次进行访问并登录后,将一段用户信息进行加密处理
把这段加密之久的结果拼接在用户信息之后,将整体的这两段信息返回给浏览器保存
用户第二次访问时,服务端截取第一段信息进行加密,并且与第二段加密信息做对比,对比成功代表登录成功
认证功能源码分析
所有的请求来了都会走APIview的as_view方法中的dispatch,
APIView --> dispatch -->self.initial(request,*args,**kwargs) --> self.perform_authentication(request) --> request.user(不是原生的request.user,是Request对象的user方法) --> self._authenticate(self):(Request类的方法)-->
self.authenticators:(Request类的属性) -->
在Request对象实例化的时候传入(在执行dispatch的时候Request实例化的)
- 自定义认证类
# 使用
- 定义一个类,继承BaseAuthentication
class LoginAuth(BaseAuthentication):
- 重写authenticate方法
def authenticate(self, request):
token = request.GET.get('token')
res = models.UserToken.objects.filter(token=token).first()
if res:
return (元组:有两个值)
else:
raise AuthenticationFailed('没有登录')
- 局部使用和全局使用
- 局部:在视图类中配置(只要配置了,就是登录以后才能访问,没配置就不需要登录就能进行访问)
authtication_classes = [myauthen.LoginAuth,]
- 全局使用:在settings.py中配置:
REST_FRAMEWORK = {
"DEFAULT_AUTHENTICATION_CLASSES":["app01.myauthen.LoginAuth", ]
}
- 局部禁用:在禁用的视图类上将authentication_class配置成空列表
# 注意:
1、认证类,认证通过就能返回一个元组,有两个值,第一个值会给request.user,第二个值就会给request.auth
2、认证类可以配置多个,按照从前往后的顺序执行,如果前面有返回值,认证就不会再继续往下走了
权限源码分析
# 执行流程:
APIView的dispatch方法 --> APIView的initial --> APIView的check_permissions(request)
- 自定义权限功能
# 登录成功以后,超级用户可以干某些事,普通用户不能干--->超级用户可以查看某些接口,普通用户不能查看
# 使用:
- 写一个类继承BasePermission,重写has_permission方法
class SuperPermission(BasePermission):
def has_permission(self, request, view):
# Return `True` if permission is granted, `False` otherwise.
# 超级用户可以访问,除了超级用户以外,都不能访问
if request.user.user_type == 1:
return True
else:
return False
# 局部使用/全局使用
permission_classes = [myauthen.SuperPermission]
# 全局使用,settings文件中配置
REST_FRAMEWORK = {
"DEFAULT_PERMISSION_CLASSES": ["app01.myauthen.SuperPermission",]
}
# 局部禁用:
permission_classes = []
内置频率类使用
# 使用:
- 局部使用
throttle_classes = [auth.MyThrottle,]
- 全局使用:
REST_FRAMEWORK = {
"DEFAULT_THROTTLE_CLASSES":["app01.auth.MyThrottle", ]
}
# 内置频率类
BaseThrottle: 基类
AnonRateThrottle:限制匿名用户的访问频率
SimpleRateThrottle:可以自定义扩写
ScopedRateThrottle:
UserRateThrottle: 限制登录用户访问频率
# 扩展内置频率类
- 写一个类,继承SimpleRateThrottle
class MySimpleThrottle(SimpleRateThrottle):
scope='xxx'
def _get_cache_key(self,request,view);
return self.get_ident(request)
- settings.py中配置:
# 全局使用
REST_FRAMEWORK = {
"DEFAULT_THROTTLE_RATES":{
'xxx':'3/m', # key和scope对应,value是 "单位时间允许访问的次数/时间单位"
}
}
#
内置、第三方过滤功能
# 过滤:筛选查询结果
# 内置筛选的作用:
from rest_framework.filters import BaseFilterBackend, SearchFilter, OrderingFilter
- 在视图类中配置
filter_backends = [SearchFilter,]
search_fields = ('name',) # 表模型中的字段
- 查询的url:
http://127.0.0.1:8000/users/?search=cc
# 注意点:内置的筛选器配置url时查询key必须是search,value的查找是模糊匹配
# 第三方扩展的过滤功能
pip3 install django-filter
- 视图类中配置
filter_backends = [DjangoFilterBackend]
filter_fields = ['name', 'age']
- 查询的url:
http://127.0.0.1:8000/users/?name=cc&age=18
排序功能
# 视图类中配置
filter_backends =[OrderingFilter,]
ordering_fields = ['id','age']
# 查询的url:
http://127.0.0.1:8000/users/?ordering=-age
# 过滤后再排序
- 在视图类中配置:
filter_backends = [OrderingFilter, DjangoFilterBackend]
ordering_fields = ('id', 'age')
filter_fields = ['name', 'age']
- 查询的url:
http://127.0.0.1:8000/users/?name=cc&age=20&ordering=-age.-id
全局异常
from rest_framework import status
from rest_framework.views import exception_handler
def common_exception_handler(exc, content):
response = exception_handler(exc,l content)
if response is None:
response = Response({'code':999, 'detail':'未知错误'}, status=status.HTTP_500_INTERNAL_SERVER_ERROR)
return response
# settings.py中配置:
REST_FRAMEWORK = {
'EXCEPTION_HANDLER': 'app01.utils.commom_exception_handler'
}
django缓存配置
# 缓存是将一些常用的数据保存内存或者memcache中,在一定的时间内有人来访问这些数据时,则不再去执行数据库及渲染等操作,而是直接从内存或memcache的缓存中去取得数据,然后返回给用户.
# 缓存方式:
- 开发调试缓存
- 内存缓存
- 文件缓存
- 数据库缓存(redis)
- Memcache缓存(使用python-memcached模块)
- Memcache缓存(使用pylibmc模块)
经常使用的有文件缓存和Mencache缓存
#配置(设置缓存的位置)
- 以文件缓存为例:
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.filebased.FileBasedCache', # 指定缓存使用的引擎
'LOCATION': '/var/tmp/django_cache', # 指定缓存的路径
'TIMEOUT': 300, # 缓存超时时间(默认为300秒,None表示永不过期)
'OPTIONS': {
'MAX_ENTRIES': 300, # 最大缓存记录的数量(默认300)
'CULL_FREQUENCY': 3, # 缓存到达最大个数之后,剔除缓存个数的比例,即:1/CULL_FREQUENCY(默认3)
}
}
}
django信号
信号的应用场景:
- 记录日志(对象创建时就写入日志)
- 解耦合
- 数据库改动后,将修改改动同步到ES或者redis
- 方式一:
观察者模式,又称 发布/订阅
发生了一些动作以后,发出信号,监听这个信号的函数就会执行
# 使用:
- 导入内置信号
from django.core.signals import request_started
- 写一个函数
def aa(sender, **kwargs):
print(sender)
print(kwargs)
print('请求来了,记录日志')
- 跟内置信号绑定
request_started.content(aa)
方式二:使用receiver装饰器
from django.core.signals import request_finished
from django.dispatch import receiver
@receiver(request_finished)
def my_callback(sender, **kwargs):
print('请求走了')
蓝图
蓝图就是一个类的对象
用来划分项目目录,避免使用app划分的时候出现循环导入的问题
# 使用步骤:
# (1)实例化得到一个蓝图对象
from flask import Blueprint
account = Blueprint('account', __name__)
# (2)像使用app = Flask(__name__)一样使用蓝图,注册路由,但是要多传一个name参数,这里用的是account
@account.route('/login.html', methods=['GET','POST'])
def login():
return render_template('login.html')
# (3)在app中注册蓝图
from .views.account import account
app.register_blueprint(account)
flask请求上下文
请求来了,app()-->app.__call__() ---> app.wsgi_app()
# wsgi_app()源码:(flask执行流程)
ctx = self.request_context(environ)
error = None
try:
try:
# 把ctx对象放到了全局变量_request_ctx_stack中
# _request_ctx_stack全局变量是LocalStack的对象
# 所以ctx.push()就是执行的LocalStack类的push方法
'''
def push(self, obj):
rv = getattr(self._local, "stack", None)
if rv is None:
self._local.stack = rv = []
rv.append(obj)
return rv
'''
ctx.push()
# 执行请求扩展的东西(before_first_request,before_request,after_request)
# 根据路径执行视图函数
response = self.full_dispatch_request()
except Exception as e:
error = e
response = self.handle_exception(e)
except:
error = sys.exc_info()[1]
raise
return response(environ, start_response)
finally:
if self.should_ignore_error(error):
error = None
ctx.auto_pop(error)
MTV与MVC
# MVC
M: 模型:负责任务对象与数据库的映射
V: 视图:负责与用户的交互
C: 控制器:接受用户的输入调用模型和视图完成用户的请求
# MTV
M:代表模型——负责业务对象金额数据库的关系映射(ORM),数据库相关操作
T:代表模板——负责如何把页面展示给用户,(HTML)即mvc的V层
V:代表视图——负责业务逻辑,并在适当的时候调用model,template
drf
钩子函数
面向切片(aop)的一种思想,定义了就执行,没有定义就不执行(本质上用了反射)
校验数据是否符合规定
view家族
jwt认证与签发
内置类重写
各类认证器
全局异常捕获
自动路由
action装饰器
@action()
action装饰器可以接收两个参数:
methods: 声明该action对应的请求方式,列表传递
detail: 声明该action的路径是否与单一资源对应,及是否是xxx/<pk>/action方法名/
True 表示路径格式是xxx/<pk>/action方法名/
False 表示路径格式是xxx/action方法名/
xadmin替换
# 新版本解释器兼容性不好
推荐使用python3.6、django2.x
- 在app中注册xadmin
- 建表模型后要数据迁移
- 配置路由信息
import xadmin
xversion.autodiscover()
# version模块自动注册需要版本控制的Model
from xadmin.plugins import xversion
xversion.register_models()
urlpatterns = [
path('xadmin/', xadmin.site.urls),
]
- 创建超级用户
python manage.py createsuperuser
- 登录访问http://127.0.0.1:8000/xadmin/
自动文档
借助于第三方的插件
coreapi, swagger
- 在路由中加路径
from rest_framework.documentation import include_docs_urls
urlpatterns=[
path('docs/', include_docs_urls(title='系统api文档')),
]
- 在配置文件中配置
REST_FRAMEWORK = {
'DEFAULT_SCHEMA_CLASS':'rest_framework.schemas.coreapi.AutoSchema',
}
- 视图类中需要加注释
class BookListCreateView(ListcreateView):
'''
get:
返回所有的图书信息
...
post:
新建一条图书信息
...
'''
- 只需要在浏览器中输入指定的路径就可以查看
http://127.0.0.1:8000/docs/
SQL

mysql最大连接池的默认值是100,最大可以到16384
所以当连接请求大于默认连接数后,就会出现无法连接数据库的错误
mysql存储引擎
innodb
支持事务
行锁、支持外键
Myisam
不支持事务、表锁设计
支持全文索引
memory
数据放在内存中,数据库重启或者奔溃时,表中的数据都将消失
适合存放OLTP数据库的临时表
NDB
数据全部放在内存中
高可用、高性能、高可扩展性的数据库集群系统
二叉树
二叉树:
(1)若左子树不空,则左子树上所有结点的值均小于它的根结点的值;
(2)若右子树不空,则右子树上所有结点的值均大于它的根结点的值;
(3)左、右子树也分别为二叉排序树;
(4)没有键值相等的结点。
# 数据插入多了,如果不调整可能会所有都放在了左边或者右边,这样性能就会越来越接近顺序查找
平衡二叉树
它是一棵空树或它的左右两个子树的高度差的绝对值不超过1
平衡二叉树是在增删改的时候通过旋转来平衡树。
B树索引和hash索引
innodb默认使用的是B树索引,
当绝大部分需求是查询单条记录时,选择hash索引性能最块;hash索引底层数据结构即使hash表(hash索引只能用于对等比较,可以一次定位数据)
其余场景,建议使用B树索引
B+树
叶子节点是第二层的数据,索引节点是第一层查找时用到的数据。那旋转的情况就是节点页有没有满了:
| 叶子节点 | 索引节点 | 操作 |
|---|---|---|
| × | × | 直接插入 |
| √ | × | 1. 拆分叶子节点; 2. 中间节点值存入索引节点; 3. 小于中间节点的数据放左叶子,大于或等于放入右叶子。 |
| √ | √ | 1. 按照上面情况拆分叶子节点; 2. 然后根据相同的操作再拆分索引节点 |
如果页中有记录被删除呢,怎么去平衡,这时候就有一个东西叫做 计算因子,如果删除后的页的记录数量小于 计算因子*总页数 的时候,B+ 树会去做 合并操作
B+ 树在发生了修改以后,为了保证查询效率,会对某个一部分的节点进行整容
# B树和B+树的区别
- 在B树中将键和值存放在内部节点和叶子节点,但是在B+树中,内部节点都是键,没有值,叶子节点同时存放键和值
- B+树的叶子有一条链相连,而B树的叶子节点各自独立
B树只适合随机检索,
B+树同时支持随机检索和顺序检索,可以减少IO次数,
# hash索引和B+树索引的区别
hash索引底层是hash表,进行查找时,调用一次hash函数就可以获得获取相应的键值,之后进行回表查询获得实际数据。无法进行范围查询。
B+树是多路平衡查找树,每一次查询都是从根节点出发,查找叶子节点可以获得所查键值,然后根据查询判断是否需要回表查询数据
B*树
是B+树的变体,在B+树的非根和非叶子节点在增加指向兄弟的指针
B+树分配新节点的概率比B+树要低,空间使用率更高,将节点的最低使用率从 1/2变成了 2/3
索引原理:
把创建了索引的内容进行排序
对排序结果生成倒排表
在倒排表内容上拼上地址链,
在查询的时候,先拿到倒排表内容,再取出数据地址链,从而拿到具体数据
索引设计原则
1、适合索引的列是出现在 where子句中的列,或者连接子句中指定的列
2、基数比较小的列,索引效果较差
3、使用短索引,如果对长字符串列进行索引,应该指定一个前缀长度,节省大量索引空间
4、不要过度使用索引,索引需要额外的磁盘空间,并降低写操作的性能,修改表内容的时候索引会进行更新甚至重构
# 创建索引的原则:
1、最左前缀原则:mysql会一直向右匹配,知道遇到范围查询就停止匹配
2、在查询频繁的字段上建立索引
3、更新频繁的字段不适合建索引
4、区分度低的字段不适合做索引
5、尽量扩展索引,不要新建索引
6、定义有外键的字段一定要建立索引
7、对于定义为 text 、 image、 bit 的数据类型的字段不要建立索引
# 注意:
删除自增长的主键,需要取消自增长再执行删除操作
alter table user MODIFY id int, drop PRIMARY KEY;
# 创建索引时需要注意:
非空字段
取值离散大的字段
索引字段越小越好
百万级别的数据如何删除
先删除素引
在删除无用数据
删除完成后重新创建索引
redo
重做日志(redo log)用来保证事务的持久性,即事务ACID中的D。
Redo log的主要作用是用于数据库的崩溃恢复
# 实际上它可以分为以下两种类型:
- 物理Redo日志 # 在InnoDB存储引擎中,大部分情况下 Redo是物理日志,记录的是数据页的物理变化
- 逻辑Redo日志;记录修改页面的一类操作,比如新建数据页时,需要记录逻辑日志。
# Redo log可以简单分为以下两个部分:
一是内存中重做日志缓冲 (redo log buffer),是易失的,在内存中
二是重做日志文件 (redo log file),是持久的,保存在磁盘中
# redo的整体流程
第一步:先将原始数据从磁盘中读入内存中来,修改数据的内存拷贝
第二步:生成一条重做日志并写入redo log buffer,记录的是数据被修改后的值
第三步:当事务commit时,将redo log buffer中的内容采用追加写的方式刷新到 redo log file
第四步:定期将内存中修改的数据刷新到磁盘中
undo
undo log主要记录的是数据的逻辑变化,为了在发生错误时回滚之前的操作,需要将之前的操作都记录下来,然后在发生错误时才可以回滚。
# 作用:
-用于事务的回滚
-MVCC (多版本并发控制)
# 写入时机:
DML操作修改聚簇索引前,记录undo日志
二级索引记录的修改,不记录undo日志
# 注意:
undo页面的修改,同样需要记录redo日志
undo也不是对redo的逆过程,只是将数据库逻辑地恢复到原来的样子
聚簇索引
聚簇索引:将数据存储与索引放到了一块,找到索引也就找到了数据
非聚簇索引
innodb中,在聚簇索引之上创建的索引称之为辅助索引,辅助索引访问数据总是需要二次查找,非聚簇索引都是辅助索引,像复合索引、前缀索引、唯一索引,辅助索引叶子节点存储的不再是行的物理位置,而是主键值。
# 与聚簇索引的区别:
区别在于 非聚簇索引 并没有存放整条记录的所有数据,只是存放了 索引列 和 主键 而已。所以当我们通过 非聚簇索引 查询一条数据行的所有列的时候,就需要 回表 去查询其他列的信息了,也就是说需要 两次查询 才完成这个需求。
MVCC
多版本并发控制,主要是为了提高数据库的并发性能
同一行数据平时发生读写请求时,会上锁阻塞住。但mvcc用更好的方式去处理读—写请求,做到在发生读—写请求冲突时不用加锁。
这个读是指的快照读,而不是当前读,
# 当前读
它读取的数据库记录,都是当前最新的版本,会对当前读取的数据进行加锁,防止其他事务修改数据。是悲观锁的一种操作。
# 快照读
快照读的实现是基于多版本并发控制,即MVCC,既然是多版本,那么快照读读到的数据不一定是当前最新的数据,有可能是之前历史版本的数据。
# 总结:
MVCC指的是再使用RC、RR这两种隔离级别的事务在执行普通的select操作时访问记录的版本链的过程,这样可以使不同事务的读—写、写—读操作并发执行,从而提升系统性能。
事务原子性实现
undo日志用于事务的回滚操作进而保障了事务的原子性
使用索引查询一定能提高查询的性能吗
通常来讲是比全表扫描要快,但是必须注意到他的代价
素引需要空间来储存,也需要定期维护。由于索引需要额外的存储空间和处理,那些不必要的索引反而会使查询反应时间变慢。
索引范围查询适用于两种情况:
- 基于一个范围的检索,一般查询返回结果集小于表中记录数的30%
- 基于非唯一性索引的检索
聚簇索引
将数据存储与素引放到了一块,找到索引也就找到了数据
非聚簇索引
将数据存储与索引分开结构,索引结构的叶子节点指向了数据的对应行,
innodb中,在聚簇索引之上创建的索引称之为辅助索引,辅助索引访问总是需要二次查找,非聚簇素引都是辅助索引,辅助素引叶子节点存储的是主键值,不再是行的物理位置
联合索引
mysql可以使用多个字段同时建立一个索引,叫做联合索引。
如果想要命中索引,需要按照建立索引时的字段顺序挨个使用,否则无法命中索引
幻读、脏读、不可重复读
# 脏读
一个事务读取到了另一个事务未提交的数据操作结果。可能造成所有数据一起回滚!
# 幻读
事务在操作过程中进行两次查询,第二次查询的结果包含了第一次查询中未出现的数据或者缺少了第一次查 询中出现的数据(并不要求两次查询的 SQL 语句相同)。这是因为在两次查询过程中有另外一个事务插入数据造 成的。
# 不可重复读
事务 T1 读取某一数据后,事务 T2 对其做了修改,当事务 T1 再次读该数据时得到与前一次不同的 值。这样就发生了在一个事务内两次读到的数据是不一样的,因此称为是不可重复读。
## 不可重复度和幻读区别:
不可重复读的重点是修改,幻读的重点在于新增或者删除。
事务机制
事务是一个不可分割的数据库操作序列,也是数据库并发控制的基本单位,其执行的结果不许使数据库从一种一致性状态变成另一种一致性状态,事务是逻辑上的一组操作,要么都执行,要么都不执行
### 事务的四大特性:
# 原子性:
事务是最小的执行单位,不允许再分割了,(要么都全部完成,要么完全不起作用,没有执行一半的说法)
# 一致性:
执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的
# 隔离性:
并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间的数据库是独立的
# 持久性:
一个事务被提交之后,他对数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响
事务的隔离级别
# RU (读未提交)
最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读、或者不可重复读
# RC (读已提交)
允许读取并发事物已经提交的数据,可防止脏读,但是幻读、不可重复读仍有可能发生
# RR (可重复读)
对同一字段的多次读取结果是一致的,可以防止不可重复读,但是不能防止幻读
# SERIALIZABLE (可串行化)
最高的隔离级别,所有事物依次执行,完全不干扰,防止脏读、不可重复读、幻读
mysql默认的隔离级别
mysql 默认使用的是RR(可重复读)
oracle 默认使用的是RC(读已提交)
django 默认使用的是RC
innodb 在分布式事务下一般会用到 SERIALZABLE(可串行化)
mysql五种锁
MyISAM采用表级锁
innodb 支持行级锁和表级锁,默认为行级锁
### 行级锁、表级锁、页级锁
# 行级锁:
mysql中粒度最细的锁,表示只针对当前操作的行加锁,行级锁可大大减少数据库的数据冲突,开销也最小
select * from tab_with_index where id = 1 for update;
# 表级锁
粒度最大的锁,表示对当前操作的整张表加锁
# 页级锁
页级锁mysql中锁定粒度介于行级锁和表级锁中间的一种锁,
表级锁速度快,但冲突少,行级冲突少,但是速度慢。
一次锁定相邻的一组记录
并发度一般,会出现死锁
# 共享锁 (读锁)
当用户进行数据的读取时,对数据加上共享锁,可以同时加上好几个
# 排他锁 (写锁)
当用户要进行数据的写入时,对数据加上排他锁。只能加一个,和其他的锁相斥
死锁的解决:
两个或者多个事务在同一资源上相互占用,并请求锁定对方的资源
# 解决方案:
不同的程序并发存取多个表,尽量约定以相同的顺序访问表
在同一个事务中尽量做到一次锁定所需要的所有资源
对于容易产生死锁的业务部分,升级锁定粒度,通过表级锁来减少死锁的概率,
使用分布式事务锁或者乐观锁
悲观锁
假设会发生并发冲突,屏蔽一切可能违反数据完整性的操作,在查询完数据的时候就把事务锁起来,直到提交事务
实现方式:通过数据库中的锁机制
# 适合多写场景
乐观锁
假设不会发生并发冲突,只在提交操作时检查是否违反数据完整性
在修改数据的时候将事务锁起来,通过version的方式进行锁定
乐观锁一般会通过使用版本号机制或者CAS算法实现
# 适用于 读操作 比较多的情况,在冲突真的很少发生的情况下,可以减少锁的开销
常用约束
NOT NULL 用于控制字段的内容
UNIQUE 用于字段内容不能重复,可以有多个
PRIMARY KEY 主键,内容不能重复,一个表只能有一个
FOREIGN KEY 用于预防破坏表之间连接的动作
CHECK 用于控制字段的值范围
常用关键字
连表操作
交叉连接 CROSS JOIN
内连接 INNER JOIN
SELECT * FROM A T1 INNER JOIN A T2 ON T1.id=T2.pid
外连接 LEFT JOIN / RIGHT JOIN
联合查询 UNION 、 UNION ALL
SELECT * FROM A UNION SELECT * FROM B UNION ...
全连接 FULL JOIN
子查询
条件:一条SQL语句的查询结果作为另一个查询语句的条件或者查询结果
嵌套: 多个SQL语句嵌套使用,内部的SQL查询语句成为子查询
select * from employee where salary=(select max(salary) from employee);
select * from dept d, (select * from employee where join_date > '2011-1-1') e where e.dept_id = d.id;
select d.*, e.* from dept d inner join employee e on d.id = e.dept_id where e.join_date > '2011-1-1'
SQL优化
# 如何定位及优化SQL语句的性能问题?
最有效的方式就是使用执行计划,用 explain 命令来查看语句的执行计划
- 查询不需要的数据 :使用limit解决
- 多表关联返回全部列 :指定列名
- 总是返回全部列 :避免使用select *
- 重复查询使用的数据 :可以缓存数据,下一次直接读取内存
- 是否在扫描额外的记录 : 使用explain进行分析
超大分页
# 超大的分页一般从两个方向上解决
1、数据库层面,核心思想就是减少load的数据
2、从需求的角度减少这种请求,不做类似的需求,直接跳转几百万页后的具体某一页,只允许逐页查看,或者按照给定的线路走走,防止ID泄露且连续被人恶意攻击
# 解决超大分页,其实主要靠缓存,可预测的提前查到内容,缓存至redis等K-V数据库中,直接返回即可
mysql分页
-LIMIT 子句可以被用于强制 SELECT 语句返回指定的记录数。 LIMIT接受一个或两个数字参数
SELECT * FROM table LIMIT 5,10; // 检索记录行 6-15
SELECT * FROM table LIMIT 95,-1; // 检索记录行 96-最后一行
LIMIT n 等价于 LIMIT 0,n。
慢查询日志
用于记录执行时间超过某个临界值的SQL日志,用于快速定位慢查询,为我们的优化做参考
慢查询的统计主要由运维在做,会定期将业务中的慢查询反馈给我们开发。
优化时要搞明白慢的原因是什么?查询条件没有命中索引还是load了不需要的数据列,还是数据量太大?
密码散列,盐,用户身份证号等固定长度的字符串应该使用 char而不是 varchar来存储,这样可以节省空间且提高检索效率。
数据库优化
# 数据库结构优化
(1)将字段很多的表分解成多个表
(2)增加中间表
(3)合理增加冗余字段
# 注意: 冗余字段的值在一个表中修改了,就要想办法在其他表中更新,否则就会导致数据不一致的问题
# 优化数据库的CRPU性能:
限定数据的范围:务必禁止不带任何限制数据范围条件的查询语句
读/写分离:经典数据库拆分方案,主库负责写,从库负责读
缓存:使用mysql的缓存,另外对重量级、更新少的数据可以考虑使用应用级别的缓存
分库分表
# 垂直分区:
根据数据库里数据表的相关性进行拆分
优点:可以使得行数据变小,查询时减少读取的block数,减少IO次数;简化表的结构,易于维护
缺点:主键会出现冗余,需要管理冗余列,并会引起join操作,会让事务变得更加复杂
# 水平分区:
将数据表行拆分,水平分表最好分库
优点:支持非常大量的数据储存,应用端改造少,
缺点:分片事务难以解决,跨节点join性能较差,尽量选择客户端分片架构,可以减少一次和多次中间件的网络IO
# 分库分表后面临的问题
(1)分布式事务支持,数据库本身的分布式管理功能执行事务,将付出高昂的性能代价;程序控制的话会造成编程方面的负担
(2)跨库join
分两次查询
(3)跨节点的count、order by、group by以及集合函数
多数的代理不会自动处理合并工作
(4)数据迁移,容量规划,扩容问题
mysql主从复制
主从复制:将主数据库中的DDL和DML操作通过二进制日志(BINLOG)传输到从数据库上,然后将这些日志重新执行;从而使得从数据库的数据与主数据库保持一致
pymysql
是python语言与数据库交互的一个API接口
防止SQL注入的方式:
使用execute函数,使用参数化查询,避免SQL语句直接拼接,
内部执行参数化生成的SQL语句,对字符进行了加`\`转义,避免注入语句的生成
使用mysql储存过程中,动态传入sql到存储过程执行语句
严格模式
简单来说就是 MySQL 自身对数据进行严格的校验(格式、长度、类型等),
比如一个整型字段我们写入一个字符串类型的数据,在非严格模式下 MySQL 不会报错,
同样如果定义了 char 或 varchar 类型的字段,当写入或更新的数据超过了定义的长度也不会报错。.
读写分离
# django中读写分离:配置一个写操作库default,一个读操作库db1
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
},
'db1': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db1.sqlite3'),
}
}
DATABASE_ROUTERS = ['db_router.Router1',] # Router1是db_router.py中的类
# db_router.py
# 自动分库操作:
class Router1:
def db_for_read(self, model, **hints):
"""
Attempts to read auth models go to auth_db.
"""
return 'db1'
def db_for_write(self, model, **hints):
"""
Attempts to write auth models go to auth_db.
"""
return 'default'
# 补充更细粒度的:
class Router1:
def db_for_read(self, model, **hints):
"""
Attempts to read auth models go to auth_db.
"""
if model._meta.model_name == 'usertype':
return 'db1'
else:
return 'default'
def db_for_write(self, model, **hints):
"""
Attempts to write auth models go to auth_db.
"""
return 'default'
双写一致性
理论上讲,给缓存设置过期时间,是保证最终一致性的解决方案,这种方案下,我们就可以对存入缓存的数据设置过期时间,所有的写操作一数据库为准,对缓存只是尽最大努力即可
也就是说,缓存更新失败,那么只要达到过期时间,后面的请求自然会从数据库中读取新值然后回填缓存
Flask
模块语法
wtforms
wtforms是一款支持多种web框架的form组件,主要用于对用户请求数据的进行验证,其的验证流程与django中的form表单验证由些许类似
sqlachemy
SQLAlchemy是一个基于python实现的orm框架,该框架建立在DB API之上,使用关系对象映射进行数据库操作,
简而言之是:将类和对象转换成SQL,然后使用数据API执行SQL并获取执行结果
# 单独使用sqlalchemy需要考虑线程安全问题
from sqlalchemy.orm import scoped_session,sessionmaker
from sqlalchemy import create_engine
engine = create_engine("mysql+pymysql://root:[email protected]:3306/aaa", max_overflow=0, pool_size=5)
conn = sessionmaker(bind=engine)
session = scoped_session(conn)
爬虫
requests模块
# 爬虫
模拟浏览器发送http请求---(请求库)(频率,cookie,浏览器头,js反扒,app逆向)(抓包工具) ---》从服务器取回数据--》解析数据---》解析库---》入库
# 内置库:
作用:发动http请求,不太好用,requests是基于此库写的
# requests模块
post请求携带数据
session对象,自动处理cookie,不需要人为处理cookie
一旦登录成功,不需要手动携带cookie,直接用session对象发送请求,会自动携带
# 收费代理,稳定
# 高匿和透明代理
- 高匿:服务端取不到真实的ip
- 透明代理:服务端可以取到真实的ip地址,
# 代理池,搞一堆代理,放到列表中,每次发请求,随机出一个(使用开源代理池)
bs4模块
# bs4模块用来解析爬回来的数据文档
from bs4 import BeautifulSoup
soup=BeautifulSoup(res.text,'html.parser')
selenium模块
自动化测试工具,控制浏览器,模拟人的行为,解决requests模块无法执行ajax获取数据
# 使用selenium+半人工登录,获取cookie --》给requests模块使用
scrapy框架
爬虫界的django
# 五大组件:
- spiders
-py文件
- egine
大总管,负责各个组件的沟通
引擎负责控制系统所有组件之间的数据流,并在某些动作发生的时候触发事件
- item pipelines
解析入库(py文件,存数据库,存文件,存redis)
在item被提取后负责处理他们,主要包括清理、验证、持久化等操作
- scheduler
调度谁先被爬取,谁后爬取
用来接收引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回,
- downloader
真正爬取数据的
# 中间件
爬虫中间件(一般不写)
下载中间件(写的多)
# 提高爬虫的效率:
增加并发
降低日志级别
禁止cookie(如果不是真的需要cookie)
禁止重试
减少下载超时
# 去重原理:集合去重
高级部分:将url中 `?` 后面的部分打散了再排序,得到一个指纹,以便排除查询条件顺序不同引起的重复
布隆过滤器
是一个通过多哈希函数映射到一张表的数据结构,能够快速的判断一个元素一个集合内是否存在,具有很好的空间和时间效率
优点:不需要存key值,节省空间
缺点:无法删除、有一定的误差概率
数组:连续存储的内存空间:取值,改值效率高
链表:不连续的内存地址,可变长,取值、改值效率低;插入值效率高
re/bs4/css/xpath选择器
xpath使用路径表达式在xml文档中选择节点
vue
生命周期函数
axios请求
组件嵌套与传参
router跳转
监听器
事件委托
vue-cookies
vue-echarts
过滤器
计算器
ui引用
redis
redis基本数据类型
字符串、哈希、列表、集合、有序集合
为什么这么快?
redis是纯内存数据库
IO多路复用,epool模型,非阻塞式IO
单线程、单进程,避免了线程间切换(6.0版本之后就是多线程了)
- 普通连接
from redis import Redis
conn = Redis()
conn.set('age', 18)
print(conn.get('age'))
conn.close()
- 写成with上下文管理
import redis
class myRedis:
def __enter__(self):
self.conn = redis.Redis()
return self.conn
def __exit__(self, exc_type, exc_val, exc_tb):
self.conn.close()
with Myredis() as conn:
conn.set('sex', 'male')
- 连接池(写成单例模式)
import redis
pool = redis.ConnectionPool(host='127.0.0.1', port=6379, max_connections=100)
# 另一个文件中使用下面的代码
conn = redis.Redis(connection_pool=pool)
conn.set('foo', 'Bar')
print(conn.get('foo'))
conn.close()
pipeline机制
redis-py默认是执行每次请求都会创建和断开 一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipeline实现一次请求指定多个命令,并且默认情况下一次pipeline是原子性操作
但是pipeline每次只能作用在一个redis节点上,如果做了集群,就没有pipeline了
# redis是非关系型数据库,不支持事务,可以使用pipeline实现事务
import redis
pool = redis.ConnectionPool(host='127.0.0.1', port=6379)
conn.redis.Redis(connection_pool=pool)
# 开启一个管道
pipe = conn.pipeline(transaction=True)
pipe.multi()
pipe.set('name','cc')
pip.set('age',18)
pipe.execute() # 这条命令才能一次性执行管道中命令
conn.close()
模拟乐观锁
# 开启事务之前,先watch
watch age
multi
decr age
exec
# 另一个机器
multi
decr age
exec
# 限制上,上面的执行就会失败(悲观锁,被watch的事务就不会执行成功)
发布订阅
# bitmap位图
# hyperloglog:极小的空间完成独立的数据统计
- pfadd key element # 增加(重复了不会增加)
- pfcount key # 统计个数
- 去重,独立用户统计,有错误率
# GOE(redis, ES)
# 插入数据
geoadd cities:locations 106.14.60.93 beijing # 把北京地理信息天津到cites:location中
geoadd cities:locations 117.12 39.08 tianjin
geoadd cities:locations 114.29 38.02 shijiazhuang
geoadd cities:locations 118.01 39.38 tangshan
geoadd cities:locations 115.29 38.51 baoding
# 计算北京到天津的距离
geodist cities:locations beijing tianjing km
# 计算北京方圆150km内的城市
georadiusbymember cities:locations beijing 150 km
缓存更新策略
(1)LRU/LFU/FIFO算法剔除:Redis使用maxmemory-policy,即Redis中的数据占用的内存超过设定的最大内存时的操作策略
(2)超时剔除:对缓存的数据设置过期时间,超过过期时间自动删除缓存数据,然后再次进行缓存,保证与数据库中的数据一致
(3)主动更新:开发者控制key的更新周期,当key在后端数据库中发生更新时,向Redis主动发送消息,Redis接收到消息对key进行更新或删除
持久化储存策略
- RDB方案
# 两种方案:
rdb: RDB持久化主要是通过SAVE和BGSAVE两个命令对Redis数据库中当前的数据做snapshot并生成rdb文件来实现的。其中SAVE是阻塞的,BGSAVE是非阻塞的,通过fork了一个子进程来完成的。在Redis启动的时候会检测rdb文件,然后载入rdb文件中未过期的数据到服务器中
aof: 对数据准确性要求高一些,通过将存储每次执行的客户端命令,然后由一个伪客户端来执行这些命令将数据写入到服务器中的方式实现的。一共分为命令追加(append)、文件写入、文件同步(sync)三个步骤完成的
- RDB可以理解为一种全量数据的更新机制,AOF可以理解为一种增量的更新机制,AOF重写可以理解为一种全量+增量的更新机制(第一次是全量,后面都是增量)
# 两者的区别:
- RDB持久化原理是将redis在内存中的数据库记录定时dump到磁盘上的RDB持久化,如果系统持久化之前出现宕机现象,没来得及写入磁盘的数据都将丢失;fork子进程完成持久化会影响性能
- AOF持久化原理是将redis的操作日志以追加的方式写进文件,
AOF文件通常大于RDB文件,恢复慢,效率往往慢于RDB
更多的是两种方式结合使用
# rdb(三种触发方式)
手动save、手动bgsave
配置文件示例:
配置 seconds changes
save 900 1
save 300 10
save 60 10000
# 最佳配置
save 900 1
save 300 10
save 60 10000
dbfilename dump-3306.rdb # 以端口号作为文件名,一台机器上启动很多redis服务也不会乱
dir /bigdiskpath # 保存路径放到一个大硬盘位置目录
stop-writes-on-bgsave-error yes # 出现错误停止
rdbcompression yes # 压缩
rdbchecksum yes # 校验
- AOF方案
# 原理
客户端每写一个命令,都记录一个日志,放到日志文件中,如果出现宕机,可以将数剧完整恢复
# AOF重写 如何实现?
本质上就是把过期的、无用的、重复的、可以优化的命令,来做命令
这样,可以减少磁盘的占用量,加快恢复速度
# aof的最佳配置
appendonly yes # 将该选项设置成yes,打开
appendfilename "appendonly-3396.aof" # 文件保存的名字
appendfsnyc everysec # 采用第二种策略
dir /data # 存放的路径
no-appendfsync-on-rewrite yes
规避缓存风险
配置文件中禁用
keys *
flushdb
flushall
config
等命令
主从复制
# 手动配置
在6380上执行(去从库上配置主库)
slaveof 127.0.0.1
# 127.0.0.1 6379 主库
# 127.0.0.1 6380 从库
# 在从库上执行,就建立了主从
# 取消主从:
slaveof no one # 取消复制,不会吧之前的数据清除
# 配置文件配置
daemonize no
pidfile redis.pid
bind 0.0.0.0
protected-mode no
port 6379
timeout 0
logfile redis.log
dbfilename dump.rbd
dir /data
# 指定主库为 10.0.0.101 6379
slaveof 10.0.0.101
# 配置从库只读
slave-read-only yes
主从同步
主库:只负责写数据
从库:只负责读数据
主库只要发生更改,数据就会立马同步到从库
# redis主从同步的原理:
副本库中通过slaveof 127.0.0.1 6379命令,连接主库,并发送SYNC给主库
主库收到SYNC,会立即触发BGSAVE,后台保存RDB,发送给副本库
副本库接受后会应用RDB快照
主库会陆续将中间件产生的新的操作,保存并发送给副本库
到此,主从复制集就正常工作了
在此之后,主库只要发生新的操作,都会以命令传播的形式自动发送给副本库
所有复制相关信息,从info信息中都可以查到,即使重启任何节点,他的主从关系依然存在
如果发生主从关系断开时,从库数据没有任何损坏,在下次重连之后,从库发送PSYNC给主库
主库只会将从库缺失部分的数据同步给从库应用,达到快速恢复主从的目的
哨兵监控
# 1、主从复制存在的问题
- 主从复制,主节点发生故障,需要做故障转移,可以手动转移:让其中一个slave变成master(哨兵)
- 主从复制,只能主写数据,所以写能力和存储能力有限(集群)
# 2、原理
1 多个sentinel发现并确认master有问题
2 选举出一个sentinel作为领导
3 选取一个slave作为新的master
4 通知其余slave成为新的master的slave
5 通知客户端主从变化
6 等老的master复活,就会成为新master的slave
# 搭建步骤:
- 第一步:先搭建一主多从
- 第二步:配置哨兵(也是一个特殊的redis服务端,客户端可以连接)
配置:
port 26379
daemonize yes
dir /root/redis/data
bind 0.0.0.0
logfile "redis_sentinel.log"
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
分布式集群
# 配置
port 7000
daemonize yes
dir "/root/redis/data7000/"
logfile "7000.log"
# masterauth 集群搭建时,主的密码
cluster-enabled yes # 开启cluster
cluster-node-timeout 15000 # 故障转移,超时时间 15s
cluster-config-file nodes-7000.conf # 给cluster节点增加一个自己的配置文件
cluster-require-full-coverage no #只要集群中有一个故障了,整个就不对外提供服务了,这个实际不合理,假设有50个节点,一个节点故障了,所有不提供服务了;需要设置成no
缓存穿透
# 是指缓存和数据库中都没有的数据,用户不断地发起请求,导致数据库压力过大这时的用户可能是攻击者
# 解决方案:
1、接口层增加校验,(拦截类似于 id<=0的请求)
2、从缓存中取不到的数据,数据库中也没有找到,这时将key-value对写成key-null,把空对象缓存起来,缓存有效时间设置短一些,这样可以防止攻击用户反复使用同一个id暴力攻击
3、通过布隆过滤器实现,针对大数据量的、有规律的键值对进行处理,一条数据是否存在本质上是一个bool值,只需要使用1bt就能储存
缓存击穿
# 是指在缓存中没有,但是数据库中有的数据,(一般是因为缓存时间到期),这时候并发用户特别多,同时读缓存还没有读到缓存,又同时去数据库中取数据,引起数据库压力瞬间增大,造成压力过大
# 解决方案:
设置热点数据永不过期
缓存雪崩
缓存中大批量数据过期,而查询数据量又特别大,引起数据库的压力过大甚至宕机,
# 与缓存击穿不同的是,缓存击穿是查同一条数据,而缓存雪崩是指不同的数据都过期了,很多数据都查不到,从而查数据库
# 解决方案:
1、缓存数据的过期时间设置成随机,防止同一时间发生大量的数据过期现象
2、如果缓存数据库是分布式的,将热点数据均匀分布在不同的缓存数据库中
3、设置热点数据永不过期
分布式id生成订单号
- uuid:可能会重复
- 时间戳:重复概率高,分布式系统中不同机器同一时刻生成的订单号重复
- 关系型数据库的自增:性能不高
- redis的自增:性能高(当前时间+自增)
- mongodb的id:object
- 雪花算法: 64 位大小的整数,因为机器的原因会发生时间回拨,我们的雪花算法是强依赖于时间的,如果时间回拨,有可能会生成重复的id
1bit:一般是符号位,不作处理
41bit:用来记录时间戳,可以记录69年
10bit:用来记录机器id,总共可以记录1024台机器,一般用前5位代表数据中心,后面5位是某个数据中心的机器id
12bit:循环位,用来对同一个毫秒内产生的不同的id,12位最多记录4095个,多于的需要等到下一毫秒,
# python写的雪花算法执行效率低:
可以使用go语言写的雪花算法,打包成so文件
celery
异步任务/延时任务/定时任务 的创建和执行
- 异步任务
# 写一个t_celery文件,
import celery
broker = 'redis://127.0.0.1:6379/1' # 使用本机的redis的db1
backend = 'redis://127.0.0.1:6379/2'
# 实例化得到对象,指定中间件和结果储存
app = celery.Celery('test', broker=broker, backend=backend)
@ app.task
def add(a,b):
return a+b
@app.task
def mul(a,b):
return a*b
# 提交任务
from t.celery import add, mul
res = add.delay(4,5)
print(res) # id号
# 启动work
from celery -A t-celery -l info -P eventlet
# get_res.py 查看执行结果
from t_celery import app
from celery.result import AsyncResult
id = 'd6a5a7b6-0166-4267-a4ca-82fb7d8d9a5c'
if __name__ == '__main__':
res = AsyncResult(id=id,app=app)
if res.successful():
result = res.get()
print(result)
elif res.failed():
print('任务执行失败')
- 延时任务
# 方式一:设定未来的时间发送短信
from datetime import datetime
t1 = datetime(2021, 2, 14, 0, 0, 0)
t2 = datetime.utcfromtimestamp(t1.timestamp())
print(t2)
res = user_task.send_sms.apply_async(args=['13788888888'], eta=t2) # 在utc时间提交任务
# 方式二:以当前utc时间往后延迟时间执行
from datetime import datetime, timedelta
ctime = datetime.now()
utc_ctime = datetime.utcfromtimestamp(ctime.timestamp())
time_delay = timedelta(seconds=10)
task_time = utc_ctime + time_delay
res = user_task.send_sms.apply_async(args=['12312312312'],eta=task_time)
- 定时任务
app.conf.timezone = 'Asia/Shanghai'
# 是否使用utc时间
app.conf.enable_ut = False
# 任务的定时配置
from datetime import timedelta
from celery.schedules import crontab
app.conf.beat_schedule = {
'send-msg': {
'task': 'celery_task.user_task.send_sms',
'schedule': timedelta(hour=24*10), # 每隔10天执行一次
# 'schedule': crontab(hour=8, day_of_week=1), # 每周一早八点
'args': ('13788888888',),
}
}
# 启动beat,负责定时提交任务
celery beat -A celery_task -l info
# 启动worker
celery worker -A celery_task -l info -P eventlet
django中使用celery
celery是独立的,跟框架没有关系
django-celery第三方模块,兼容性不好
目录:
celery_task
__init__.py
celery.py
home_task.py
order_task.py
uesr_task.py
luffyapi
包结构封装与使用
rabbitMQ
IPC机制
ack模式
消息持久化
发布订阅模式
信道匹配
docker
常用命令
docker image
docker pull
docker export
docker import
docker save
docker load
docker search
docker ps
docker start
docker stop
docker run
docker exec -it nginx /bin/bash
docker nsenter
docker rm 删除容器
网络模式
host模式
container模式
none 模式
bridge模式
dockerfile编写
由一行行命令语句组成,从下而上运行
FROM
MAINTAINER
RUN
ADD
WORKDIR
VOLUME
EXPORT
RUN
CMD
# 示例:
FROM centos7
RUN pip3 install django=2.2.2 -i https://pypi.douban.com/simple/
RUN django-admin startproject app
RUN cd /app/ && django-admin startapp docker
ADD BBS_11_09.zip /root/
CMD cd /app && python3 manage.py runserver 0.0.0.1:8000
Golang
常用变量类型
函数与包的使用
逻辑语句
go文件编译打包
数组与切片
map类型
指针类型
结构体
接口
goroutine
缓存信道与工作池
协程锁
defer/panic/recover
elasticsearch
分词插件
可视化操作
倒排索引
常用映射类型与参数
排序查询
范围查询
过滤查询
混查询
wildcard查询
集群与数据分片
规避脑裂
打分机制
dynamic三状态
列表底层实现:
cpython的list其实是一个可变长数组,数组里面存放的是对象的引用
字典底层的实现
通过哈希表实现,字典也叫哈希数组或者关联数组
本质是数组,每个bucket有两部分:一个是键对象的引用,一个是值对象的引用
python对哈希冲突的解决办法是开放地址法
drf相对django增加了什么?
序列化器、路由自动生成、分页、api版本控制、缓存、限流
常用ui
layui
element-ui
ant-ui
# 后台管理:
xadmin
vue-admin
django框架下从requests请求发起到收到response的整个过程:
首先,用户在浏览器中输入url,发送一个GET方法的request请求。
Django中封装了socket的WSGi服务器,监听端口接受这个request 请求,
再进行初步封装,然后传送到中间键中,这个request请求再依次经过中间键,
对请求进行校验或处理,再传输到路由系统中进行路由分发,匹配相对应的视图函数(FBV),
再将request请求传输到views中的这个视图函数中,进行业务逻辑的处理,
调用modles中表对象,通过orm拿到数据库(DB)的数据。
同时拿到templates中相应的模板进行渲染,然后将这个封装了模板response响应传输到中间键中,
依次进行处理,最后通过WSGi再进行封装处理,响应给浏览器展示给用户
分解质因数
while 1:
n = int(input('请输入一个整数:'))
print('%d=' % n, end='')
while n > 1:
for i in range(2, n + 1):
if n % i == 0:
n = int(n / i)
if n == 1:
print('%d' % i, end='')
else:
print('%d*' % i, end='')
break
print()
难点:
hyperloglog 统计用户
接口幂等性
每周一早八点
'args': ('13788888888',),
}
}
启动beat,负责定时提交任务
celery beat -A celery_task -l info
启动worker
celery worker -A celery_task -l info -P eventlet
django中使用celery
```python
celery是独立的,跟框架没有关系
django-celery第三方模块,兼容性不好
目录:
celery_task
__init__.py
celery.py
home_task.py
order_task.py
uesr_task.py
luffyapi
包结构封装与使用
rabbitMQ
IPC机制
ack模式
消息持久化
发布订阅模式
信道匹配
docker
常用命令
docker image
docker pull
docker export
docker import
docker save
docker load
docker search
docker ps
docker start
docker stop
docker run
docker exec -it nginx /bin/bash
docker nsenter
docker rm 删除容器
网络模式
host模式
container模式
none 模式
bridge模式
dockerfile编写
由一行行命令语句组成,从下而上运行
FROM
MAINTAINER
RUN
ADD
WORKDIR
VOLUME
EXPORT
RUN
CMD
# 示例:
FROM centos7
RUN pip3 install django=2.2.2 -i https://pypi.douban.com/simple/
RUN django-admin startproject app
RUN cd /app/ && django-admin startapp docker
ADD BBS_11_09.zip /root/
CMD cd /app && python3 manage.py runserver 0.0.0.1:8000
Golang
常用变量类型
函数与包的使用
逻辑语句
go文件编译打包
数组与切片
map类型
指针类型
结构体
接口
goroutine
缓存信道与工作池
协程锁
defer/panic/recover
elasticsearch
分词插件
可视化操作
倒排索引
常用映射类型与参数
排序查询
范围查询
过滤查询
混查询
wildcard查询
集群与数据分片
规避脑裂
打分机制
dynamic三状态
列表底层实现:
cpython的list其实是一个可变长数组,数组里面存放的是对象的引用
字典底层的实现
通过哈希表实现,字典也叫哈希数组或者关联数组
本质是数组,每个bucket有两部分:一个是键对象的引用,一个是值对象的引用
python对哈希冲突的解决办法是开放地址法
drf相对django增加了什么?
序列化器、路由自动生成、分页、api版本控制、缓存、限流
常用ui
layui
element-ui
ant-ui
# 后台管理:
xadmin
vue-admin
django框架下从requests请求发起到收到response的整个过程:
首先,用户在浏览器中输入url,发送一个GET方法的request请求。
Django中封装了socket的WSGi服务器,监听端口接受这个request 请求,
再进行初步封装,然后传送到中间键中,这个request请求再依次经过中间键,
对请求进行校验或处理,再传输到路由系统中进行路由分发,匹配相对应的视图函数(FBV),
再将request请求传输到views中的这个视图函数中,进行业务逻辑的处理,
调用modles中表对象,通过orm拿到数据库(DB)的数据。
同时拿到templates中相应的模板进行渲染,然后将这个封装了模板response响应传输到中间键中,
依次进行处理,最后通过WSGi再进行封装处理,响应给浏览器展示给用户
分解质因数
while 1:
n = int(input('请输入一个整数:'))
print('%d=' % n, end='')
while n > 1:
for i in range(2, n + 1):
if n % i == 0:
n = int(n / i)
if n == 1:
print('%d' % i, end='')
else:
print('%d*' % i, end='')
break
print()
难点:
hyperloglog 统计用户
接口幂等性