FLOWPRINT: Semi-Supervised Mobile-App Fingerprinting on Encrypted Network Traffic
一种从加密的网络流量中提取移动app指纹的方法
NDSS2020
原型和数据集: GitHub - Thijsvanede/FlowPrint: Original implementation of FlowPrint as in the NDSS '20 paper
一、介绍
1. 背景
移动设备上的APP之间通过网络进行通信。为了防止恶意APP或有漏洞的APP造成危害,网络安全工作者需要识别网络中有哪些app。
移动流量的大部分都是加密的,80%的安卓应用都采用传输层安全协议(TLS)。
安全运营商需要通过分析加密网络流量,来识别移动应用指纹。
2. 现有方案
现有识别应用方法的共同点:需要事先知道哪些app会出现在网络中,才能识别app。
新应用安装、更新、卸载都很容易,仅google play就有近250万个应用,所以很难事先了解所有的应用。
即使是预装的应用程序在每个设备上也有很大差异。
特别当公司采用BYOD政策时,提前知道哪些应用会出现在网络上是不可行的。
因此,未知应用要么被错误分类,要么被捆绑成归到一大类未知的app。
3. 本文工作
与现有的解决方案不同,FLOWPRINT不需要先验知识来生成指纹。
本文目标是生成指纹,用来识别已知的app,并自动检测和隔离未知的app。
移动网络流量的特点:
- 同质:许多应用使用相同的第三方库、相同的应用层协议、部分内容通过内容分发网络(CDN)或云服务商托管。因此,不同app共享许多网络流量特征。
- 动态:app产生的数据可能取决于用户的行为(如导航数据)。
- 演变:apps在不断的卸载、更新、安装,当新or更新的应用被引入网络时,可能导致指纹系统变得不那么准确。
针对上述特点的解决思路:
- 我们的工作通过利用应用通信的不同网络目的地来处理同质流量。
- 通过利用用户行为影响有限的网络目的地的信息,创建对用户互动具有鲁棒性的指纹。
- 基于被监控设备之间的网络流和它们交互的目的地之间的时间相关性来创建指纹。因此,方法产生的指纹会随着网络流量的变化而自动演变
为了应对这些挑战,我们引入了一种半监督的方法来为移动应用生成指纹。
移动应用由不同的模块组成,这些模块通常与一组静态目的地通信。我们利用这一特性来发现与这些不同模块所对应的网络流量模式(pattern)。在较高的层次上,我们根据TCP/UDP流的目的地将其分组,并查找经常一起访问的目的地的关联性。然后,我们将这些模式组合成指纹,指纹可以用于应用识别和未被发现的应用检测。
二、初步分析
为了研究移动网络流量,并确定可用于识别移动应用的强指标,本文在一个小数据集上进行了初步分析。
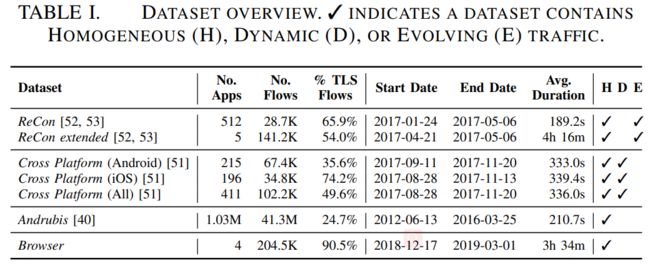
数据集
特征选择
经过一系列的打分、评估,选出了分高排名前十的特征。
AMI的范围从0(完全不相关)到1(观察特征X完全映射到已知app标签Y)

- 时间特征:Inter-flow timing 流间时间间隔 & Packet interarrival time (incoming) 数据包到达的间隔时间
- 设备特征:源ip地址
- 目的地特征:目的地ip&各种TLS证书特性,每个应用程序都由一组独特的不同模块组成,这些模块都提供了应用程序的部分功能。每个模块与一组服务器通信,从而产生一组独特的网络目的地,以区分应用程序
- 大小特征:传入和传出的数据包大小特征都显示了较高的AMI。这意味着每个流发送和接收的数据量可以很好地指示哪个应用程序处于活动状态。
三、方法简述

定期将移动设备的网络流量作为输入,并生成映射到APP的指纹。上图介绍了指纹的创建和匹配的过程。
A. Feature extraction :从网络流量中提取特征
特征选择:提取每个设备的目的IP和端口号、时间戳(用于计算流之间的时间)、流中所有包的大小和方向,如果适用,还提取该流的TLS证书。根据这些特性,我们在集群阶段使用目标IP和端口号以及TLS证书。浏览器隔离还需要有关通过网络发送的数据量的信息。最后,相关步骤使用包的时间戳来确定不同流在多大程度上是时间相关的。
B. Clustering:对每个网络目的地的每个设备的流量进行聚类
根据TCP/UDP流的网络目的地将它们聚在一起。(1)这些流包含相同的(目的IP地址、目的端口)元组。(2)流中包含相同的TLS证书。

图2显示了生成的集群示例,其中目标集群随机分布。每个集群的大小与分配给它的流的数量成比例。注意,有些集群是由多个应用程序生成的,我们称之为共享集群。进一步的检查显示,这些共享集群对应于第三方服务,如崩溃分析、移动广告(广告)网络、社交网络和cdn。这些服务通常嵌入到许多应用程序使用的库中:例如,googleads.g.doubleclick.net, lh4.googleusercontent.com和android.clients。- google.com是提供这些服务的共享集群。我们在V-E节的同质性分析中讨论了共享聚类对指纹的影响程度。除了共享集群外,应用程序经常会产生特定应用程序特有的集群,例如s.yimg.com和infoc2.duba.net集群只出现在com.rhmsoft.fm应用程序的流量中。这些特定于应用程序的集群通常指向应用程序开发者的目的地,即第一方,或者是前面提到的跨应用服务的小提供商。最后,请注意,获得的集群由来自整个输入批处理的流组成。然而,被监控的设备只能与每个目的地进行零星的通信。因此,当消息发送到或从群集表示的目的地接收时,我们将群集称为活动的,否则称为不活动的。
C. Browser isolation:检测和隔离浏览器。
浏览器的行为模式相比于其他应用要更难以检测,为此,本文提出一种单独的技术来检测和隔离浏览器流量:
Features:
(1) 活动集群的相对变化
(2) 上传字节的相对变化
(3) 下载字节的相对变化
(4) 上传/下载比例的相对变化
D. Cross-correlation:发现网络目的地之间的相关性。
既然浏览器被隔离了,我们就可以利用剩余的集群来进行应用指纹识别。然而,仅使用目的地集群不足以对应用进行指纹识别,因为网络目的地在应用之间是共享的,并且可能在应用的不同执行过程中发生变化。因此,为了对应用进行指纹识别,我们还利用了活动目的地集群之间的时间相关性。我们这里的基本原理是,应用程序持续地与相同的网络目的地通信。我们假设活动目的地的结合集群在每个时间点上是独一无二的,为每个应用程序相对稳定。这意味着,随着时间的推移,每个人都应该能观察到强相关性属于同一应用程序的目的地。

利用每个集群之间的互相关度量,我们构造一个相关图,图中的每个节点代表一个集群。集群通过加权边连接,每条边的权值定义了两个集群之间的互相关关系。图3显示了所选三个应用程序的关联图。我们看到,属于同一应用程序的集群显示出很强的相关性。此外,共享集群显示所有应用之间的相关性较弱,而大多数独特集群根本不相关。
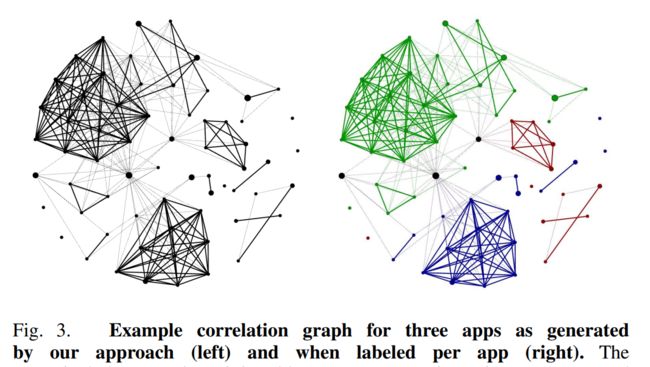
用我们的方法生成的三个应用程序的相关图示例(左)和每个应用程序的标签(右)。这些应用包括com.rhmsoft.fm(蓝色)、com.steam.photoeditor(绿色)和au.com.penguinapps.android. babyfeeds .client.android(红色)或共享目的地集群(黑色)。节点越大,指向目标集群的流就越多。每条边的厚度取决于互相关。
E. Fingerprinting:基于强相关性创建指纹
为了构造应用指纹,我们在相关图中确定强相关簇的最大群,即完整子图。为了发现这样的群,我们首先去除所有具有弱互相关的边。
然后从图中提取所有最大团,并将每个团转化为指纹。由于所有的极大团都是完全子图,因此团中的边不添加任何附加信息。这意味着我们可以将clique转换为网络目的地集,方法是从clique中的每个节点提取所有(目的IP、目的端口)元组和tls证书,并将它们组合成一个集合。通过对每个小团体执行这种转换,我们获得了所有的指纹。简而言之,我们将应用指纹定义为在关联图中形成最大派系的网络目的地集合
F. Matching/updating:将新发现的指纹与已知指纹数据库进行匹配,并相应地进行更新。
不幸的是,应用程序在不同的时间与不同的目的地进行通信,要么是因为流量是基于用户交互的,这是动态的,要么是因为应用程序为不同的功能产生不同的流量。因此,同一款应用的“指纹”可能会出现不同程度的差异。为了解释这一事实,我们并不将指纹作为精确匹配进行比较,而是将它们的比较基于Jaccard相似性[35]。因为我们的指纹是集合,所以Jaccard相似性是一个自然的度量标准。为了检验两个指纹是否相似,我们计算两个指纹Fa和Fb的Jaccard相似度(如公式5所示),并检查其是否大于阈值τ相似度。如果是这样,我们认为这两个指纹是相同的。

四、实验
我们在Python中使用Scikit-learn[47]和NetworkX[33]库实现了我们的方法的原型,称为FLOWPRINT,用于机器学习和图计算。我们评估中的第一个实验确定了我们方法的最佳参数。然后,我们分析通过我们的方法生成的指纹在多大程度上可以用来精确识别应用程序。在这里,我们将我们的方法与AppScanner[62]进行了比较。AppScanner是一种最先进的监控技术,可以在网络流量中识别应用。之后,我们会通过更新或新安装的应用来评估我们的方法处理之前未被发现的应用的效果。然后,我们详细介绍了我们的方法的具体方面,如浏览器检测器的性能,我们的指纹的置信度水平,以及每个应用程序产生的指纹数量。我们进一步研究了我们的方法如何很好地处理同构的,动态的,和进化的移动网络流量性质。最后,我们讨论了设备上安装的应用程序数量的影响,并通过评估FLOWPRINT的执行时间来证明我们的方法能够实时运行。
在Android和iOS的应用识别设置中评估了FLOWPRINT,达到了89.2%的准确率,显著超过了最先进的解决方案AppScanner。此外,本文方法可以检测出之前未被发现的应用,这是现有技术无法实现的,准确率为93.5%,能够连接建立的前5分钟内检测出72.3%的应用,在一定程度上具有实时性。
五、总结
贡献
- 提出了一种结合 基于目的地的聚类、浏览器隔离和模式识别 的半监督指纹识别方法。
- 在原型FLOWPRINT中实现了这种方法,这是第一个构建移动应用程序指纹的实时系统,能够在不需要先验知识的情况下处理未知的应用程序。
- 对于Android和iOS应用,我们的方法检测已知应用的准确率为89.2%,显著优于最先进的监督应用识别系统AppScanner。此外,我们的方法能够处理应用程序更新,并能够检测之前未见过的应用程序,精确度为93.5%。
FLOWPRINT:一个从移动设备的加密网络流量中创建实时应用指纹的新方法
- 不需要先验知识
- 能够检测未知应用
- 准确率优于现有方法
- 性能高,能够实时运行