Python入门篇(九)---网络编程
目录
网络编程的概念和应用领域
套接字(socket)编程
简介
创建一个 socket
连接一个 socket
发送和接收数据
urllib库的使用
发送HTTP请求
解析URL
编码和解码
下载文件
equests库的使用
GET请求
POST请求
网络编程的概念和应用领域
Python网络编程是指使用Python语言编写网络应用程序的过程,包括客户端和服务器端的编写。网络编程可以用于实现各种应用场景,比如网络爬虫、聊天应用、实时通讯等等。Python作为一种通用的高级编程语言,拥有丰富的标准库和第三方库,可以方便地进行网络编程。
Python网络编程涉及到多种网络协议和通信方式,比如TCP、UDP、HTTP等协议,以及socket、HTTP协议库、Scrapy等通信方式和框架。Python的网络编程主要使用socket套接字来实现,也可以使用第三方库如Twisted、Tornado等来进行异步编程。
Python网络编程的应用领域广泛,涉及到网络安全、大数据、人工智能等多个领域。比如,在网络安全领域,可以使用Python进行漏洞扫描、入侵检测等操作;在大数据领域,可以使用Python进行数据采集和处理;在人工智能领域,可以使用Python进行图像识别、自然语言处理等操作。
套接字(socket)编程
简介
Python 中的 socket 编程是通过 socket 模块实现的。socket 模块提供了一种网络通信的方式,使得程序可以通过 TCP 或 UDP 协议与远程计算机进行通信。
创建一个 socket
在 Python 中创建 socket 可以使用 socket.socket() 方法。下面是一个创建 TCP socket 的示例:


连接一个 socket
使用 socket.connect() 方法连接一个远程服务器。下面是一个 TCP 客户端的示例:
发送和接收数据
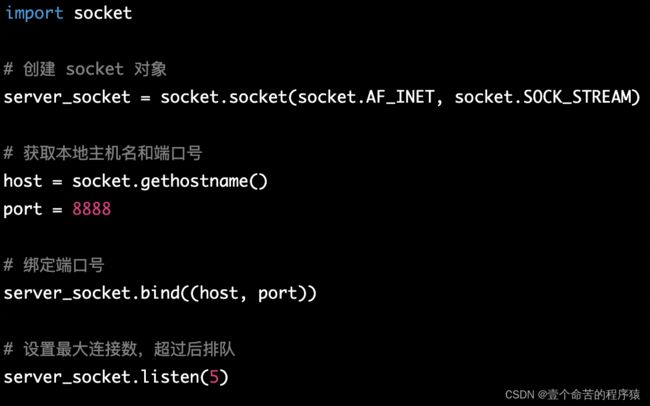
在 Python 中,发送和接收数据是通过 socket 对象的 send() 和 recv() 方法实现的。下面是一个 TCP 客户端和服务端交互的示例:
服务端:

客户端:

这个示例中,服务端首先创建了一个 socket 对象,然后绑定本地主机名和端口号,并开始监听连接。当客户端连接时,它向客户端发送一条欢迎消息,然后等待客户端发送消息。客户端连接到服务端,接收到欢迎消息并向服务端发送一条感谢消息。最后,客户端关闭连接。
urllib库的使用
Python的urllib库提供了一组用于处理URL(Uniform Resource Locator)的模块。其中,urllib.request模块提供了访问URL的方法,urllib.parse模块提供了解析URL的方法,urllib.error模块提供了处理异常的方法。
下面将对urllib库的常用方法进行简单介绍,并附上代码示例。
发送HTTP请求
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)方法可以向指定的URL发送HTTP请求,并返回一个文件对象。该方法支持的参数包括:
下面是一个简单的示例,使用urlopen()方法向指定的URL发送GET请求,并打印响应内容:
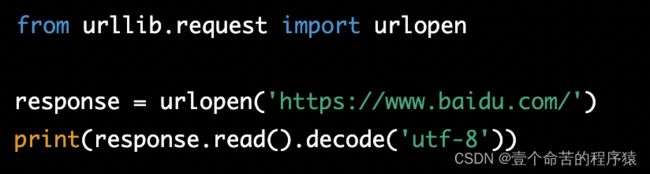
url:请求的URL地址,可以是字符串或Request对象。data:POST请求时要发送的数据,必须是bytes类型。timeout:请求超时时间,单位是秒。cafile:CA证书文件路径。capath:CA证书目录路径。cadefault:是否使用默认的CA证书。context:SSL上下文。
解析URL
urllib.parse模块提供了解析URL的方法,包括urlparse()、urlsplit()、urlunparse()、urljoin()、urlencode()等。其中,urlparse()方法用于解析URL,并返回一个包含6个元素的元组,分别为协议、域名、端口、路径、参数和查询字符串。
下面是一个示例,使用urlparse()方法解析URL:

运行结果如下:
ParseResult(scheme='https', netloc='www.baidu.com', path='/s', params='', query='wd=python', fragment='')
编码和解码
urllib.parse模块还提供了编码和解码URL的方法,包括quote()、unquote()、quote_plus()、unquote_plus()、urlencode()等。
下面是一个示例,使用quote()方法将字符串编码为URL安全的格式:

运行结果如下:
https://www.baidu.com/s?wd=%E4%B8%AD%E6%96%87
下载文件
urllib.request模块还提供了下载文件的方法,包括urlretrieve()和urlcleanup()。urlretrieve()方法用于下载文件,可以指定保存路径和文件名;urlcleanup()方法用于清理由urlretrieve()方法下载的临时文件。
下面是一个示例,使用urlretrieve()方法下载文件:
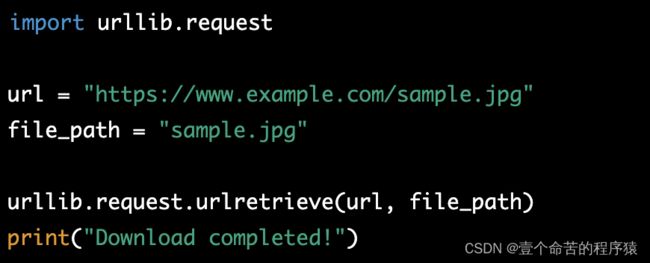
在上述代码中,我们首先指定要下载的文件的 URL 和要保存到本地的文件路径。然后使用 urlretrieve() 方法来执行下载操作。下载完成后,我们会打印一条消息来通知用户下载已经完成。
equests库的使用
Python 中的 requests 库是一个常用的 HTTP 请求库,可以发送 HTTP/1.1 请求,包括 GET、POST、PUT、DELETE、HEAD 和 OPTIONS 等。
GET请求
以下是使用 requests 库发送 GET 请求的基本示例:
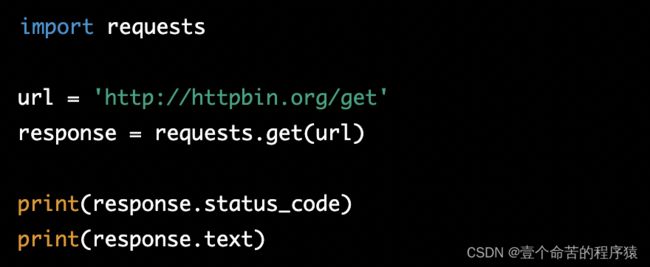
代码解释:
-
首先导入 requests 库。
-
接着定义请求的 URL。
-
发送 GET 请求并将响应结果赋值给
response对象。 -
打印响应的状态码和内容。
在以上示例中,requests.get() 方法接受一个 URL 作为参数,并返回一个响应对象。响应对象包含请求的状态码、响应头和响应内容等信息。可以使用响应对象的 .status_code 属性获取状态码,使用 .text 属性获取响应内容。
POST请求
以下是使用 requests 库发送 POST 请求的示例:

代码解释:
-
首先导入 requests 库。
-
接着定义请求的 URL。
-
定义请求的数据,这里使用字典类型。
-
发送 POST 请求并将响应结果赋值给
response对象。 -
打印响应的状态码和内容。
在以上示例中,requests.post() 方法接受两个参数:URL 和请求的数据。可以使用响应对象的 .status_code 属性获取状态码,使用 .text 属性获取响应内容。
除了以上两种方法,requests 库还提供了其他 HTTP 请求方法和参数,可以根据具体需求进行选择和配置。