hadoop集群搭建之运行环境准备以及群启HDFS,YARN集群
hadoop入门-运行环境的搭建
前期准备工作:制作了一模拟机hadoop101,然后在hadoop101的基础上,进行克隆,制作了一台hadoop102的服务器,配置好了jdk1.8以及hadoop3的环境变量
hadoop安装目录介绍
[atguigu@hadoop102 hadoop-3.1.3]$ ll
drwxr-xr-x. 2 atguigu atguigu 4096 9月 12 2019 bin
drwxr-xr-x. 3 atguigu atguigu 4096 9月 12 2019 sbin
drwxr-xr-x. 3 atguigu atguigu 4096 9月 12 2019 etc
drwxr-xr-x. 2 atguigu atguigu 4096 9月 12 2019 include
drwxr-xr-x. 3 atguigu atguigu 4096 9月 12 2019 lib
drwxr-xr-x. 4 atguigu atguigu 4096 9月 12 2019 libexec
-rw-rw-r--. 1 atguigu atguigu 147145 9月 4 2019 LICENSE.txt
-rw-rw-r--. 1 atguigu atguigu 21867 9月 4 2019 NOTICE.txt
-rw-rw-r--. 1 atguigu atguigu 1366 9月 4 2019 README.txt
drwxr-xr-x. 4 atguigu atguigu 4096 9月 12 2019 share
重要目录
(1)bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
hadoop运行模式
- Local(Standalone) Mode 本地模式,测试使用
- Pseudo-Distributed Mode 伪分布式模式,一台服务器
- Fully-Distributed Mode 完全分布式模式,多台服务器
本地模式
hadoop默认安装后启动的就是本地模式,就是将来的数据存在Linux本地,并且运行MR程序的时候也是在本地机器上运行
伪分布式模式
伪分布式其实就是在一台机器上启动HDFS集群,启动YARN集群,并且数据存在HDFS集群以及运行MR程序也是在YARN上运行,计算后的结果也是输出到HDFS上
完全分布式模式
完全分布式其实就是多台机器上分别启动HDFS集群,启动YARN集群,并且数据存在HDFS集群上的以及运行RM程序也是在YARN上运行,计算后的结果也是输出到HDFS上
运行本地模式
在hadoop-3.1.3文件下面创建一个wcinput文件夹
mkdir wcinput
在该目录下创建一个hello.txt文件
vim hello.txt
然后随便写点数据:
ss ss
cls cls
jiao
banzhang
xue
hadoop
sgg sgg sgg
nihao nihao
bigdata
laiba
回到/opt/module/hadoop-3.1.3目录
# 执行
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput ./wcoutput
# 参数解释
hadoop-mapreduce-examples-3.1.3.jar # hadoop内置的jar包,
wordcount # 内置方法,用于计算单词的数量
wcinput # 数据输入目录
wcoutput # 数据输出目录
# 运行的结果,查看生成的文件
[atguigu@hadoop102 wcoutput]$ cat part-r-00000
atguigu 2
banzhang 1
bigdata0111 1
cls 2
hadoop 1
jiao 1
laiba 1
nihao 2
sgg 3
ss 2
xue 1
至此,本地模式运行OK
运行完全分布式模式
前提概要:参照上篇文章hadoop102的制作过程,分别制作从hadoop101克隆出两台服务器hadoop103,hadoop104,分别修改主机名为hadoop103,hadoop104,并且固定ip地址,关系如下:
主机名 ip地址
hadoop102 192.168.12.102
hadoop103 192.168.12.103
hadoop104 192.168.12.104
完全分布式-同步分发内容
将102上的jdk安装包发送到103上(都是在102上操作),在102机器上的hadoop的解压目录里面有个share/doc目录,这个doc里面的文件太多,影响发送效率,先把它删除掉
[atguigu@hadoop102 share]$ ls
doc hadoop
[atguigu@hadoop102 share]$ rm -rf doc/
102主动发送数据到103
# 在102的module目录下发送文件到103,先确保103中有这个/opt/module
scp -r ./* atguigu@hadoop103:/opt/module
# 第一次连接输入yes,然后再输入密码,atguigu这个是登入的用户,发送完毕
104从102上拉取数据
# 在104上的module/目录下执行
scp -r atguigu@hadoop102:/opt/module/jdk1.8.0_212 ./
103让102的数据发送到104
# 在103上执行,让102上的hadoop-3.1.3发送到104上
scp -r atguigu@hadoop102:/opt/module/hadoop-3.1.3 atguigu@hadoop104:/opt/module
rsync主要用于备份和镜像,具有速度快,避免复制相同内容和支持符号链接的优点。
rsync做文件复制要比scp快,rsync只对差异文件做更改,注意rsync不支持登入两个机器的登入
# 用于测试,将102上的jdk安装包发送到103上,在102上执行,-av规约
[atguigu@hadoop102 software]$ ls
hadoop-3.1.3.tar.gz jdk-8u212-linux-x64.tar.gz
[atguigu@hadoop102 software]$ rsync -av ./* atguigu@hadoop103:/opt/software
# 用于测试,104从102上拉去数据,在104上执行
rsync -av atguigu@hadoop102:/opt/software/* ./
手写分发脚本
由于上种文件文件分发的局限性,不能一步到位,不能一键完成分发。所以有必要手写分发脚本,使得一台机器的文件同时分发到多台机器
这个脚本是工具,以后会经常执行,所以这个脚本的目录必须配置到环境变量中
# 在102机器上查看已有的环境变量,发现有个/home/atguigu/bin,而这个/bin目录我们还没有创建呢
[atguigu@hadoop102 ~]$ pwd
/home/atguigu
[atguigu@hadoop102 ~]$ echo $PATH
/usr/local/bin:
/usr/bin:
/usr/local/sbin:
/usr/sbin:
/opt/module/jdk1.8.0_212/bin:
/opt/module/hadoop-3.1.3/bin:
/opt/module/hadoop-3.1.3/sbin:
/home/atguigu/.local/bin:
/home/atguigu/bin # 这是linux默认为我们写的,在这个目录下的脚本就已经配置到环境变量中了
[atguigu@hadoop102 ~]$ mkdir bin
[atguigu@hadoop102 bin]$ touch my_rsync.sh
[atguigu@hadoop102 bin]$ ll
-rw-rw-r--. 1 atguigu atguigu 0 9月 19 23:53 my_rsync.sh
# 给予执行权限
[atguigu@hadoop102 bin]$ chmod 744 my_rsync.sh
[atguigu@hadoop102 bin]$ vim my_rsync.sh
编写如下脚本
#!/bin/bash
# 入参校验
if [ $# -lt 1 ]
then
echo '参数不能为空'
exit
fi
# 遍历集群中的机器一次分发内容
for host in hadoop103 hadoop104
do
#依次分发
for file in $@
do
# 判断当前文件是否存在
if [ -e $file ]
then
#存在
#1.获取当前文件的目录结构
pdir=$(cd -P $(dirname $file); pwd)
#2.获取当前的文件名
fname=$(basename $file)
#3.登入目标机器创建统一的目录结构
ssh $host "mkdir -p $pdir"
#4.依次把要分发的文件或目录进行分发
rsync -av $pdir/$fname $host:$pdir
else
#不存在
echo "$file 文件不存在"
exit
fi
done
done
# 测试my_rsync.sh脚本(在102上执行)
[atguigu@hadoop102 software]$ vim /home/atguigu/bin/my_rsync.sh
[atguigu@hadoop102 software]$ my_rsync.sh ./jdk-8u212-linux-x64.tar.gz
atguigu@hadoop103's password:
atguigu@hadoop103's password:
sending incremental file list
sent 84 bytes received 12 bytes 38.40 bytes/sec
total size is 195,013,152 speedup is 2,031,387.00
atguigu@hadoop104's password:
atguigu@hadoop104's password:
sending incremental file list
jdk-8u212-linux-x64.tar.gz
sent 195,060,887 bytes received 35 bytes 35,465,622.18 bytes/sec
total size is 195,013,152 speedup is 1.00
[atguigu@hadoop102 software]$ 测试成功!!!
分发102配置的环境变量
该环境变量是之前创建102机器时配置的,配置了jdk以及hadoop环境变量,在 /etc/profile.d/my_env.sh
分析:该环境变量能使用my_rsync.sh脚本去分发嘛?
# 由于该配置所有用户和用户组都是root(我们操作账号是atguigu),所以我们的账号并没有权限去写
# 不能使用我们编写的脚本进行分发
[atguigu@hadoop102 profile.d]$ ll
...
...
-rw-r--r--. 1 root root 420 9月 19 17:08 my_env.sh
我们可以使用系统自带的scp进行分发,注意登入目标用户使用root,这就有权限了
[atguigu@hadoop102 profile.d]$ pwd
/etc/profile.d
[atguigu@hadoop102 profile.d]$ scp -r ./my_env.sh root@hadoop103:/etc/profile.d/
root@hadoop103's password:
my_env.sh
[atguigu@hadoop102 profile.d]$ scp -r ./my_env.sh root@hadoop104:/etc/profile.d/
root@hadoop104's password:
my_env.sh
[atguigu@hadoop102 profile.d]$ 发送成功
分别在103,104机器上执行 source /etc/profile 让配置生效
测试 :
java -version
hadoop version
ok,配置成功!
搭建集群,修改配置文件
hadoop集群规划
hadoop102 namenode datanode nodemanager
hadoop103 resourcemanager datanode nodemanager
hadoop104 secondarynamenode datanode nodemanager
集群配置
hadoop中加载配置文件的顺序,会先加载默认的配置文件,然后再加载自定义配置文件,自定义的配置信息会覆盖默认配置
hadoop默认的配置文件
- core-default.xml
- hdfs-default.xml
- mapread-default.xml
- yarn-default.xml
hadoop提供可自定义的配置文件
- core-site.xml
- hdfs-site.xml
- mapread-site.xml
- yarn-site.xml
修改core-site.xml
[atguigu@hadoop102 ~]$ cd $HADOOP_HOME/etc/hadoop
[atguigu@hadoop102 hadoop]$ vim core-site.xml
# 在中添加如下配置
<property>
<name>fs.defaultFSname>
<value>hdfs://hadoop102:9820value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/module/hadoop-3.1.3/datavalue>
property>
<property>
<name>hadoop.http.staticuser.username>
<value>atguiguvalue>
property>
<property>
<name>hadoop.proxyuser.atguigu.hostsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.atguigu.groupsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.atguigu.groupsname>
<value>*value>
property>
修改hdfs-site.xml
[atguigu@hadoop102 hadoop]$ vim hdfs-site.xml
# 在中添加如下配置
<property>
<name>dfs.namenode.http-addressname>
<value>hadoop102:9870value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>hadoop104:9868value>
property>
修改yarn-site.xml
[atguigu@hadoop102 hadoop]$ vim yarn-site.xml
# 在中添加如下配置
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>hadoop103value>
property>
<property>
<name>yarn.nodemanager.env-whitelistname>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOMEvalue>
property>
<property>
<name>yarn.scheduler.minimum-allocation-mbname>
<value>512value>
property>
<property>
<name>yarn.scheduler.maximum-allocation-mbname>
<value>4096value>
property>
<property>
<name>yarn.nodemanager.resource.memory-mbname>
<value>4096value>
property>
<property>
<name>yarn.nodemanager.pmem-check-enabledname>
<value>falsevalue>
property>
<property>
<name>yarn.nodemanager.vmem-check-enabledname>
<value>falsevalue>
property>
修改mapread-site.xml
[atguigu@hadoop102 hadoop]$ vim mapread-site.xml
# 在中添加如下配置
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
好的,现在在102机器上已经修改了上述的四个配置,在把这四个配置同步分发103,104机器上即可
[atguigu@hadoop102 hadoop-3.1.3]$ pwd
/opt/module/hadoop-3.1.3
[atguigu@hadoop102 hadoop-3.1.3]$ my_rsync.sh etc/hadoop/
至此,hadoop集群的配置已经ok
搭建集群-单点启动集群
1.namenode格式化
在启动集群之前,先对namenode进行格式化
# 我们的namenode规划在102机器上,在102执行
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
# 格式化之后会发现/opt/module/hadoop-3.1.3目录下多了 data 和logs两个目录
2.单点启动namenode
[atguigu@hadoop102 hadoop-3.1.3]$ pwd
/opt/module/hadoop-3.1.3
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs --daemon start namenode
[atguigu@hadoop102 hadoop-3.1.3]$ jps # 查看进程,检验namenode是否启动成功
1269 NameNode
1338 Jps
[atguigu@hadoop102 hadoop-3.1.3]$
也可以通过网页访问 hadoop102:9870 访问,检验namenode是否启动成功
3.单点启动datanode
由于datanode在三台机器上都需要启动,可以使用xshell自带的工具来执行
hdfs --daemon start datanode

启动成功,发现各自的目录下面多了 /data目录: /data/dfs/data

4.单点启动secondarynamenode
2nn规划在104机器上
# 在104执行
[atguigu@hadoop104 dfs]$ hdfs --daemon start secondarynamenode
[atguigu@hadoop104 dfs]$ jps
7200 DataNode
7313 SecondaryNameNode # 启动成功
7349 Jps
[atguigu@hadoop104 dfs]$
5.单点启动resourcemanager
resourcemanager规划在103上
# 在103上执行,resourcemanager是yarn的
[atguigu@hadoop103 hadoop-3.1.3]$ yarn --daemon start resourcemanager
[atguigu@hadoop103 hadoop-3.1.3]$ jps
7315 ResourceManager # 启动成功
7204 DataNode
7358 Jps
[atguigu@hadoop103 hadoop-3.1.3]$
6.启动nodemanager
nodemanager规划在每台机器上都要启动,选择全部会话执行
yarn --daemon start nodemanager
启动成功后可以访问yarn的默认web页面 : hadoop103:8088
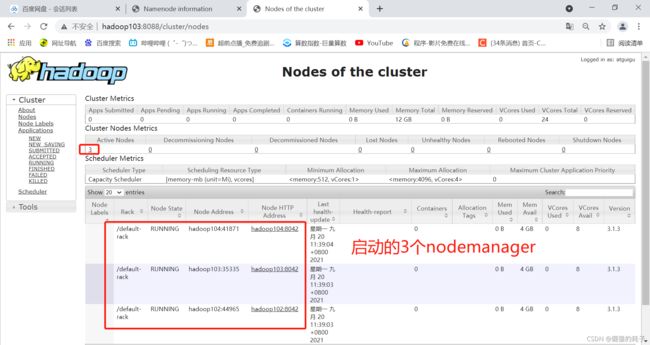
大功告成,现在hadoop的完全分布式集群就启动成功
搭建集群-集群的关闭
# 停止HDFS集群
-- 102停止namenode
hdfs --daemon stop namenode
-- 102,103,104分别停止datanode
hdfs --daemon stop datanode
-- 104停止secondarynamenode
hdfs --daemon stop secondarynamenode
# 停止yarn集群
-- 103停止resourcemanager
yarn --daemon stop resourcemanager
-- 102,103,104分别停止nodemanager
yarn --daemon stop nodemanager
还有一个问题需要注意:
集群只有首次搭建后才需要对NameNode进行格式化操作
如果集群在后期使用过程中需要重新格式化,一定要先删除hadoop安装目录下的data,logs文件夹
群起集群
经过上面上面的单点启动,我们发现有很多的不足,比如修改配置后总要输入密码,以及单台机器依次启动某个服务,nn,2nn等等,那么我们就有必要来整一个群起集群的脚本了
配置SSH免密登入

生成密钥对
[atguigu@hadoop102 hadoop-3.1.3]$ ssh-keygen -t rsa # 然后四次回车
[atguigu@hadoop102 ~]$ pwd
/home/atguigu
[atguigu@hadoop102 ~]$ ls -a # 生成的位置在.ssh
. .. .bash_logout .bash_profile .bashrc bin .ssh .viminfo
[atguigu@hadoop102 .ssh]$ ll
-rw-------. 1 atguigu atguigu 1679 9月 20 15:23 id_rsa # 私钥
-rw-r--r--. 1 atguigu atguigu 399 9月 20 15:23 id_rsa.pub # 公钥
-rw-r--r--. 1 atguigu atguigu 372 9月 19 23:28 known_hosts # 访问记录的文件
[atguigu@hadoop102 .ssh]$
将公钥拷贝到每个机器
注意:这里有个坑,自己也要拷贝一份
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop102
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop103
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop104
# 在各自的.ssh目录下都会生成一个authorized_keys授权文件
# 现在,在102上如登入103就不用密码了
[atguigu@hadoop102 .ssh]$ ssh hadoop103
Last login: Mon Sep 20 11:03:39 2021 from 192.168.12.1
[atguigu@hadoop103 ~]$ # 直接登入到了103上
分别在103,104机器上做同样的操作,免密配置完毕
hadoop自带的群启脚本
先来看看hadoop自带的群启脚本
[atguigu@hadoop102 sbin]$ pwd
/opt/module/hadoop-3.1.3/sbin
[atguigu@hadoop102 sbin]$ ll
-rwxr-xr-x. 1 atguigu atguigu 5170 9月 12 2019 start-dfs.sh # 启动hdfs
-rwxr-xr-x. 1 atguigu atguigu 3342 9月 12 2019 start-yarn.sh
-rwxr-xr-x. 1 atguigu atguigu 3898 9月 12 2019 stop-dfs.sh # 启动yarn
-rwxr-xr-x. 1 atguigu atguigu 3083 9月 12 2019 stop-yarn.sh
-rwxr-xr-x. 1 atguigu atguigu 1982 9月 12 2019 workers.sh
...
[atguigu@hadoop102 sbin]$
注意:使用start-dfs.sh命令的话,除了回去读取我们自定义的配置文件,还会去读取
/opt/module/hadoop-3.1.3/etc/hadoop目录下的works文件,这里面可以指定需要在哪些机器上启动datanode,nodemanager这里面默认的是localhost,修改配置如下
# 意思是在这些机器上都要启动datanode,nodemanager,不能有空格空行,不然启动报错
hadoop102
hadoop103
hadoop104
将works文件分发到其他机器
[atguigu@hadoop102 hadoop-3.1.3]$ pwd
/opt/module/hadoop-3.1.3
[atguigu@hadoop102 hadoop-3.1.3]$ my_rsync.sh etc/hadoop/workers
sending incremental file list
workers
sent 141 bytes received 41 bytes 364.00 bytes/sec
total size is 30 speedup is 0.16
sending incremental file list
workers
sent 141 bytes received 41 bytes 364.00 bytes/sec
total size is 30 speedup is 0.16
[atguigu@hadoop102 hadoop-3.1.3]$ 免密登入,发送成功
测试启动hdfs
# 在102上执行
[atguigu@hadoop104 hadoop-3.1.3]$ start-dfs.sh
Starting namenodes on [hadoop102]
Starting datanodes
Starting secondary namenodes [hadoop104]
[atguigu@hadoop104 hadoop-3.1.3]$ jps
8893 SecondaryNameNode
9054 Jps
8734 DataNode
测试启动yarn
# 在103上执行
[atguigu@hadoop103 hadoop-3.1.3]$ start-yarn.sh
Starting resourcemanager
Starting nodemanagers
[atguigu@hadoop103 hadoop-3.1.3]$ jps
8953 Jps
8524 ResourceManager
8335 DataNode
8655 NodeManager
[atguigu@hadoop103 hadoop-3.1.3]$
至此,群起hadoop集群成功!!!
总结:利用hadoop提供的 群启/群停 脚本完成集群操作
群起: start-dfs.sh start-yarn.sh
群停: stop-dfs.sh stop-yarn.sh
注意事项: 修改安装目录下的/etc/hadoop/works文件
启动hdfs的时候要在NameNode所在的机器执行脚本
启动yarn的时候要在resourcemanager所在的机器执行脚本
封装群启/群停脚本
思考:上述利用hadoop自带的群起命令,还是要在两次机器上执行两次命令,我能不能仅在一台机器上执行一次命令就实现群起功能呢?
自己编写脚本实现一键搭建集群
[atguigu@hadoop102 bin]$ pwd
/home/atguigu/bin
[atguigu@hadoop102 bin]$ touch my_cluster.sh
[atguigu@hadoop102 bin]$ chmod 744 my_cluster.sh
[atguigu@hadoop102 bin]$ vim my_cluster.sh
# 编写如下脚本
#!/bin/bash
if [ $# -lt 1 ]
then
echo '参数不能为空,start or stop ?'
exit
fi
case $1 in
"start")
#启动集群
echo "==========启动HDFS集群==========="
ssh hadoop102 /opt/module/hadoop-3.1.3/sbin/start-dfs.sh
echo "==========启动YAEN集群==========="
ssh hadoop103 /opt/module/hadoop-3.1.3/sbin/start-yarn.sh
echo "==========启动成功==========="
;;
"stop")
#关闭集群
echo "==========关闭HDFS集群==========="
ssh hadoop102 /opt/module/hadoop-3.1.3/sbin/stop-dfs.sh
echo "==========关闭YAEN集群==========="
ssh hadoop103 /opt/module/hadoop-3.1.3/sbin/stop-yarn.sh
echo "==========关闭成功==========="
;;
*)
echo '参数错误'
exit
;;
esac
my_cluster.sh脚本测试
前面我们已经把集群启动了,现在我们利用自己的脚本来实现一键关闭集群
[atguigu@hadoop102 bin]$ ls
my_cluster.sh my_rsync.sh
[atguigu@hadoop102 bin]$ my_cluster.sh stop
==========关闭HDFS集群===========
Stopping namenodes on [hadoop102]
Stopping datanodes
Stopping secondary namenodes [hadoop104]
==========关闭YAEN集群===========
Stopping nodemanagers
Stopping resourcemanager
==========关闭成功===========
[atguigu@hadoop102 bin]$ jps
9235 Jps
[atguigu@hadoop102 bin]$
my_jps.sh
小脚本,一键查看各个机器的集群启动情况
#!/bin/bash
echo "hadoop102,hadoop103,hadoop104进程启动情况"
for host in hadoop102 hadoop103 hadoop104
do
echo "=================$host jps情况================="
ssh $host /opt/module/jdk1.8.0_212/bin/jps
done