前K个高频单词(Java详解)
一、题目描述
给定一个单词列表 words 和一个整数 k ,返回前 k 个出现次数最多的单词。
返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率, 按字典顺序 排序。
示例1:
输入: words = ["i", "love", "leetcode", "i", "love", "coding"], k = 2
输出: ["i", "love"]
解析: "i" 和 "love" 为出现次数最多的两个单词,均为2次。
注意,按字母顺序 "i" 在 "love" 之前。
示例2:
输入: ["the", "day", "is", "sunny", "the", "the", "the", "sunny", "is", "is"], k = 4
输出: ["the", "is", "sunny", "day"]
解析: "the", "is", "sunny" 和 "day" 是出现次数最多的四个单词,
出现次数依次为 4, 3, 2 和 1 次。
二、题解
题目分析:
题目要求我们找到前k个出现次数最多的单词,因此我们首先要统计每个单词出现的次数,再根据每个单词出现的次数找到前k个出现次数最多的单词。
思路分析:
(1)统计每个单词出现的次数
如何统计每个单词出现的次数?
我们可以使用哈希表来统计单词出现的次数,遍历数组,若单词未出现过,则将其放入哈希表中,且次数为1;若单词已出现过,则将其次数+1
代码实现:
//统计单词出现次数
//创建哈希表
Map map = new HashMap<>();
//遍历数组
for(String str: words){
//若单词未出现过,则将其放入哈希表中,并将次数置为1
if(map.get(str) == null){
map.put(str,1);
}else{
//若单词已在哈希表中,则将其次数+1
int val = map.get(str);
map.put(str,val+1);
}
} (2)找出前k个出现次数最多的单词
如何找出前k个出现次数最多的单词?
我们可以创建一个大小为k的小根堆,来找出前k个出现次数最多的单词。遍历哈希表,若堆中的单词个数小于k,则将其放入小根堆中,但当堆中的单词数等于k时,就要判断是否需要更新小根堆中的元素。
由于我们创建的是小根堆,因此堆顶元素是最小的的,我们只需判断,当前遍历到的单词的出现次数是否比堆顶单词的出现次数大,
若当前单词的出现次数大于堆顶单词的出现次数,则将堆顶元素弹出,并将当前元素放入小根堆中;
若当前单词的出现次数小于堆顶单词的出现次数,则继续遍历;
由于题目要求:当有不同的单词有相同出现频率,按照字典顺序排序,因此在当前单词的出现次数等于堆顶单词的出现次数时,我们则需要根据单词的字母顺序来判断,若当前单词的字母顺序在堆顶单词之前,则将堆顶元素弹出,并将当前元素放入小根堆中;反之,则继续遍历。
堆中的单词个数始终为k个,在遍历完成后,堆中的元素即为前k个出现次数最多的单词
具体实现:
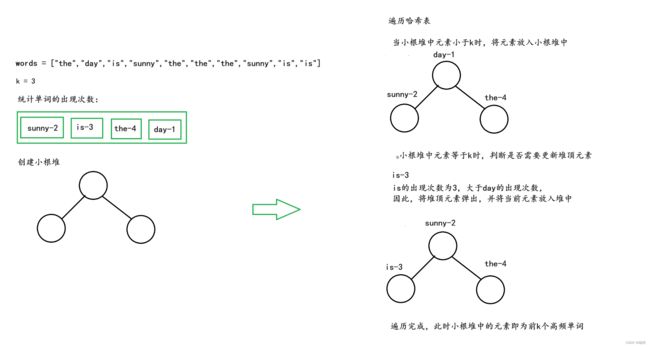
由于我们创建的是小根堆,从堆顶弹出的元素顺序是从小到大的,因此我们在将堆中的单词放入集合后,还需要将集合反转
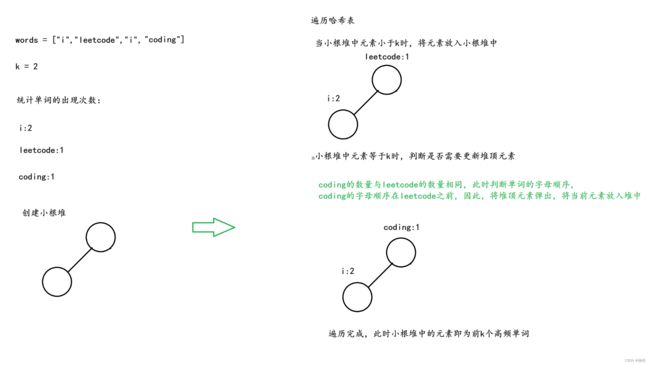
然而,在上述情况中,我们只考虑了堆中元素大于k时,出现两个次数相同的单词,未考虑当堆中元素小于k时,出现两个次数相同的单词
若在堆中元素小于k时出现了两个次数相同的单词,我们则需要将单词字母顺序大的元素放在堆顶,即按照单词的字母顺序创建大根堆(字母顺序大的在上,字母顺序小的在下)
为什么要将单词字母顺序大的放在堆顶?
因为我们创建的是小根堆,在弹出堆顶元素进行比较时,应将字母顺序大的元素弹出,与当前元素进行比较,且在遍历完成后,弹出元素创建集合时,应先弹出字母顺序大的,后弹出字母顺序小的,这样,在反转集合后,才能得到正确的顺序
因此,我们在堆中元素小于k时,若两元素次数不相同,根据出现次数创建小根堆,若两元素次数相同,则根据单词的字母顺序创建大根堆
代码实现:
//找出前K个出现次数最多的单词
//创建小根堆
PriorityQueue> minHeap = new PriorityQueue<>(new Comparator>() {
@Override
public int compare(Map.Entry o1, Map.Entry o2) {
//按照出现次数创建小根堆
//若次数相同,则按照字典顺序创建大根堆
if(o1.getValue().compareTo(o2.getValue()) == 0) {
return o2.getKey().compareTo(o1.getKey());
}
return o1.getValue().compareTo(o2.getValue());
}
});
//遍历map,将前k个高频单词放入小根堆
for(Map.Entry entry: map.entrySet()){
//若堆中元素小于k,将元素放入堆中
if(minHeap.size() < k){
minHeap.offer(entry);
}else {
//若堆中元素等于k,判断是否需要更新堆中元素
Map.Entry top = minHeap.peek();
if(top.getValue().compareTo(entry.getValue()) < 0){
minHeap.poll();
minHeap.offer(entry);
}else if(top.getValue().compareTo(entry.getValue()) == 0){
if(top.getKey().compareTo(entry.getKey()) > 0){
minHeap.poll();
minHeap.offer(entry);
}
}
}
}
//创建集合
List ret = new ArrayList<>();
//将堆中元素弹出,并将单词放入集合中
for (int i = 0; i < k; i++) {
Map.Entry top = minHeap.poll();
ret.add(top.getKey());
}
//反转集合
Collections.reverse(ret); 完整代码:
class Solution {
public List topKFrequent(String[] words, int k) {
//统计单词出现次数
//创建哈希表
Map map = new HashMap<>();
//遍历数组
for(String str: words){
//若单词未出现过,则将其放入哈希表中,并将次数置为1
if(map.get(str) == null){
map.put(str,1);
}else{
//若单词已在哈希表中,则将其次数+1
int val = map.get(str);
map.put(str,val+1);
}
}
//找出前K个出现次数最多的单词
//创建小根堆
PriorityQueue> minHeap = new PriorityQueue<>(new Comparator>() {
@Override
public int compare(Map.Entry o1, Map.Entry o2) {
//按照出现次数创建小根堆
//若次数相同,则按照字典顺序创建大根堆
if(o1.getValue().compareTo(o2.getValue()) == 0) {
return o2.getKey().compareTo(o1.getKey());
}
return o1.getValue().compareTo(o2.getValue());
}
});
//遍历map,将前k个高频单词放入小根堆
for(Map.Entry entry: map.entrySet()){
//若堆中元素小于k,将元素放入堆中
if(minHeap.size() < k){
minHeap.offer(entry);
}else {
//若堆中元素等于k,判断是否需要更新堆中元素
Map.Entry top = minHeap.peek();
if(top.getValue().compareTo(entry.getValue()) < 0){
minHeap.poll();
minHeap.offer(entry);
}else if(top.getValue().compareTo(entry.getValue()) == 0){
if(top.getKey().compareTo(entry.getKey()) > 0){
minHeap.poll();
minHeap.offer(entry);
}
}
}
}
//创建集合
List ret = new ArrayList<>();
//将堆中元素弹出,并将单词放入集合中
for (int i = 0; i < k; i++) {
Map.Entry top = minHeap.poll();
ret.add(top.getKey());
}
//反转集合
Collections.reverse(ret);
return ret;
}
} 题目来自:
692. 前K个高频单词 - 力扣(LeetCode)