【APUE】并发 — 线程
目录
一、线程的概念
1.1 定义
1.2 POSIX 线程标准
1.3 线程标识
1.4 相关函数
1.5 一些补充
二、线程的创建、终止与取消
2.1 创建
2.2 终止
2.2.1 return
2.2.2 pthread_exit
2.3 取消
2.3.1 函数介绍
2.3.2 禁止线程被取消
2.3.3 线程取消方式
2.4 清理
2.4.1 线程清理程序栈
2.4.2 pthread_cleanup_push
2.4.3 pthread_cleanup_pop
2.5 线程收尸
2.5.1 pthread_join
2.5.2 pthread_detach
2.6 代码示例
三、线程同步
3.1 互斥量
3.1.1 类型 pthread_mutex_t
3.1.2 pthread_mutex_init
3.1.3 pthread_mutex_lock
3.1.4 pthread_mutex_destroy
3.1.5 代码示例
3.2 线程池实现
3.3 令牌桶实现
3.4 条件变量
3.4.1 类型 pthread_cond_t
3.4.2 pthread_cond_init
3.4.3 pthread_cond_signal
3.4.4 pthread_cond_wait
3.4.5 pthread_cond_destroy
3.4.6 代码示例
3.5 令牌桶的非忙等版本
3.6 线程池的非忙等版本
3.7 信号量
3.8 读写锁
四、线程属性
4.1 pthread_attr_t 类型
4.2 pthread_attr_init
4.3 pthread_attr_destroy
4.4 设置属性的函数
4.5 代码示例
五、线程的同步属性
5.1 互斥量属性
5.1.1 pthread_mutexattr_t 类型
5.1.2 pthread_mutexattr_init
5.1.3 pthread_mutexattr_destroy
5.1.4 设置属性的函数
5.2 条件变量属性
5.2.1 pthread_condattr_t 类型
5.2.2 pthread_condattr_init
5.2.3 pthread_condattr_destroy
5.2.4 设置属性的函数
五、知识重构
5.1 重入
5.2 线程与信号
5.3 线程与 fork
六、线程模式
七、openmp 标准
后续学习中,时不时会提到进程。注意进程和线程的对比学习
一、线程的概念
1.1 定义
进程:加载到内存的程序,一个正在运行的程序
线程:一个正在运行的函数
- 一个进程中至少会有一个正在运行的函数,即一个进程中至少包含一个线程
- 进程是操作系统分配资源的单位,而线程是调度的基本单位。一个进程中的多个线程共享内存资源,因为它们位于同一进程的地址空间中
可以通过如下命令查看进程与线程的关系
ps axm 

可以看出这样一个关系:进程就是容器,用来装线程
如下命令可以换种方式查看进程线程的关系,这里不再赘述
ps ax -L1.2 POSIX 线程标准
多线程的实现有多套标准,POSIX 线程是一套目前最常用的标准,也是我们后续主要所学习的标准
何谓标准?可以这么理解:POSIX 线程标准给厂商规定了所需要实现的接口,但是接口具体如何实现厂商可以自由发挥
POSIX 线程标准以 pthread.h 头文件和一个线程库实现,因此,利用 gcc 编译和链接的时候需要加上 -pthread 选项。该标准下大约共有 100 个函数调用,全都以 pthread_ 开头,并可以分为四类:
- 线程管理,例如创建线程,等待(join)线程,查询线程状态等。
- 互斥锁(Mutex):创建、摧毁、锁定、解锁、设置属性等操作
- 条件变量(Condition Variable):创建、摧毁、等待、通知、设置与查询属性等操作
- 使用了互斥锁的线程间的同步管理
1.3 线程标识
就像每个进程有一个进程 ID 一样,每个线程也有一个线程 ID,用于标识线程的身份。进程 ID 在整个系统中是唯一的,而线程 ID 只有在它所属的进程中是唯一的。归属于不同进程的两个线程可能有相同的线程 ID
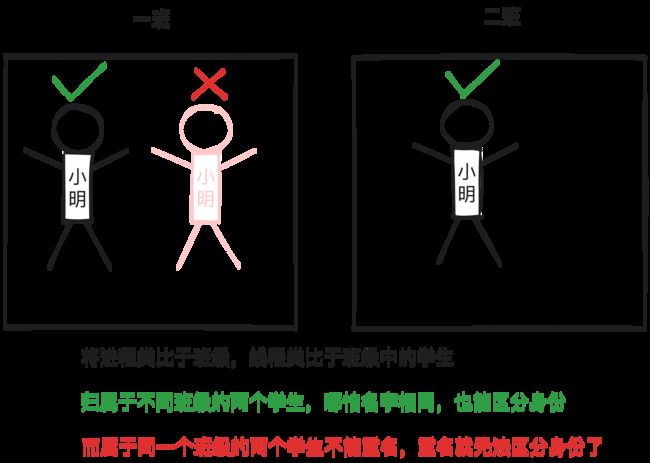
进程 ID 是用 pid_t 数据类型来表示的,是一个非负整数。线程 ID 是用 pthread_t 数据类型来表示的(p 代表 POSIX 线程标准,thread 代表线程,_t 代表其是某种类型的 typedef)。不同系统下的 pthread_t 可能是由不同类型 typedef 来的(毕竟 POSIX 只规定了接口而未规定接口的实现,有些厂商开发的系统下的 pthread_t 可能是结构体类型),因此不能想当然地以为线程 ID 是一个整数!
1.4 相关函数
#include
int pthread_equal(pthread_t t1, pthread_t t2); 功能:比较两个线程 ID
- 如果两个线程 ID 相等,返回非 0;否则返回 0
- 为什么不用 == 比较?因为 pthread_t 类型不确定!万一 pthread_t 的实际类型并不支持 == 运算符呢?
#include
pthread_t pthread_self(void); 功能:获取自身线程 ID
- 返回调用该函数的线程的 ID
1.5 一些补充
- 之前我们关注的问题都是以进程为最小单位进行思考的,以后要试试以线程为最小单位进行思考
- 在操作系统发展史上,多线程这一部分是先有标准化,再有应用的;而之前信号部分是先被应用,后面慢慢标准化的。因此,多线程这个部分学起来会感觉更规范,更容易学习
- 不建议将之前讲的信号机制和多线程机制大范围混用!因为太难啦
- 同个进程中的多个线程之间是兄弟关系,不分主次的
- 因为标准化的约束,其实之前我们用到的很多库都是支持多线程并发的
二、线程的创建、终止与取消
创建容易理解,那终止与取消有什么区别呢?
答:终止指的是线程执行完自己的使命然后结束;取消指的是线程工作做到一半被中途取消
2.1 创建
man 3 pthread_create
#include
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg); 功能:创建一个新线程
- thread — 参数作为返回值,将所创建新线程的标识回填至 thread 所指空间
- attr — 指定线程的属性,默认属性则传入 NULL
- start_routine — 指向某函数的入口地址,新创建的线程就是“正在运行的该函数”。该函数的参数和返回值都是 void* 类型,这样设计的目的是为了让我们能够将任何类型(尤其是结构体类型)的地址作为函数参数或返回值
- arg — 将 arg 作为参数传递给 start_routine 所指定的函数
- 创建成功返回 0;失败返回非 0 的 errno,此时 *thread 为未定义
之前都是成功返回 0, 失败设置 errno 的。这里为什么不一样了?
答:失败返回 errno 而非设置 errno 是考虑到了多线程的特点。多个线程中的函数如果都去设置同一个全局的 errno,岂不是就乱套了?
代码示例:创建一个线程,线程打印正在运行
#include
#include
#include
#include
static void * func(void * p) {
puts("Thread is working!");
return NULL;
}
int main() {
pthread_t tid;
puts("Begin!");
int err = pthread_create(&tid, NULL, func, NULL); // 创建线程,即创建一个运行的函数
// func为运行的函数
if (err) {
fprintf(stderr, "pthread_create():%s\n",strerror(err));
exit(1);
}
puts("End!");
exit(0);
} 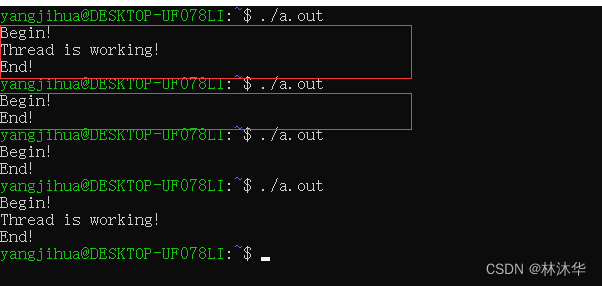
嗯嗯?为什么运行结果不一样?
答:因为线程的调度取决于调度器策略!如果先调度 func 线程,则会成功打印 Thread is working;如果先调度了 main 线程,main 线程调用 exit(0) 结束了当前进程,那么 Thread is working 就无法打印了,因为进程已经终止了
2.2 终止
2.2.1 return
立即(不会执行清理程序)终止线程。如果是 main 线程调用 return,则直接终止整个进程
2.2.2 pthread_exit
man 3 pthread_exit
#include
void pthread_exit(void *retval); 功能:终止一个线程
- retval — 终止线程并通过 retval 返回一个值
在多线程编程中,建议用 pthread_exit 替换 return
static void * func(void * p) {
puts("Thread is working!\n");
pthread_exit(NULL);
// return NULL;
}
为什么?有如下几个原因:
- pthread_exit() 函数只会终止当前线程,不会影响进程中其它线程的执行;而 return,比如说在 main 线程中调用 return 语句相当于调用 exit,会终止整个进程,当然也会影响到该进程的所有线程
- pthread_exit() 可以自动执行线程清理程序,而 return 不会
2.3 取消
2.3.1 函数介绍
man pthread_cancel
#include
int pthread_cancel(pthread_t thread); 功能:取消线程
- thread — 指定希望取消掉哪个线程
- 取消成功返回 0,失败返回非 0
线程取消有什么意义?比如用多个线程在某一个树的不同分支中查找某个节点。只要其中一个线程找到了指定节点,其他线程哪怕没有找完,也可以取消查找了
2.3.2 禁止线程被取消
禁止线程被取消是一个非常重要的机制。毕竟如果一个线程始终允许被取消,会出现如下问题

故一个线程一定有允许取消和不允许被取消两种状态,可以通过以下函数设置是否允许被取消
man pthread_setcancelstate
#include
int pthread_setcancelstate(int state, int *oldstate); 功能:设置线程是否允许被取消
2.3.3 线程取消方式
当一个线程允许被取消,又有如下两种取消方式
- 推迟取消(默认且常用):推迟至 cancel 点(POSIX 定义的 cancel 点包含可能引发阻塞的系统调用)再取消
- 异步取消(鲜有应用):可在任意点取消
可以通过如下函数设置取消方式
man pthread_setcanceltype
#include
int pthread_setcanceltype(int type, int *oldtype); 功能:设置线程的取消方式
#include
void pthread_testcancel(void); 功能:人为设置 cancel 点
2.4 清理
2.4.1 线程清理程序栈
线程会维护这样一个栈,栈中存放了一些函数(指针),这些函数代表了线程的一个个清理程序。当遇到如下情况时,栈中的清理函数会出栈并执行:
- 当线程被取消,栈中所有的函数都会依次出栈,并按出栈顺序执行
- 当线程调用 pthread_exit 终止时,栈中所有的函数都会依次出栈,并按出栈顺序执行
- 当线程通过非零的 execute 参数调用 pthread_cleanup_pop 时,栈顶函数会出栈并执行
2.4.2 pthread_cleanup_push
man pthread_cleanup_push
#include
void pthread_cleanup_push(void (*routine)(void *),
void *arg); 功能:向线程清理程序栈添加函数
- routine — 用于指定待入栈的线程清理函数
- arg — 当该线程清理函数被调用时,将 arg 用作调用参数
2.4.3 pthread_cleanup_pop
man pthread_cleanup_pop
#include
void pthread_cleanup_pop(int execute); 功能:从线程清理程序栈出栈栈顶的函数
- execute — 当 execute 为 0,仅出栈函数;当 execute 非 0,出栈函数的同时会还会调用该函数
补充一下,pthread_cleanup_push 与 pthread_cleanup_pop 有一个限制:它们实现为宏,pthread_cleanup_push 的宏定义包含一定量的字符 {,在 pthread cleanup_pop 的定义中有与之对应的匹配字符 }。所以这两个函数必须在与线程相同的作用域中以匹配对的形式使用
代码示例:向线程清理程序栈添加函数,并出栈
#include
#include
#include
#include
static void cleanup_func(void *p) {
puts(p);
}
static void *func(void *p) {
puts("Thread is working!");
pthread_cleanup_push(cleanup_func, "cleanup:1");
pthread_cleanup_push(cleanup_func, "cleanup:2");
pthread_cleanup_push(cleanup_func, "cleanup:3"); // 依次入栈
puts("push over!");
// 成对出现
pthread_cleanup_pop(1); // 出栈并执行,栈顶函数会打印:cleanup:3
pthread_cleanup_pop(0); // 仅出栈
pthread_exit(NULL); // 出栈并执行,打印:cleanup:1
pthread_cleanup_pop(0); // 虽然执行不到,但是为了括号匹配,必须写
}
int main(void) {
pthread_t tid; // thread id
int err;
puts("Begin!");
err = pthread_create(&tid, NULL, func, NULL);
if(err) {
fprintf(stderr, "pthread_create(): %s\n", strerror(err));
exit(1);
}
pthread_join(tid, NULL); // 等待,直到tid所标识的线程终止,后面会介绍
puts("End!");
exit(0);
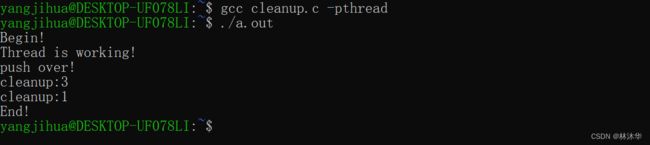
} 
2.5 线程收尸
当一个线程终止或取消,还需要想办法为其“收尸”,从而将线程所占据的资源归还给系统
有人会问:不是可以手动通过线程清理程序释放资源吗,为什么还需要通过“收尸”让线程归还资源?
答:线程清理程序中释放的资源是受线程控制的一些资源,比如堆内存、文件描述符等等,这些资源在线程中申请,也理应在线程终止或取消前通过清理程序释放。而操作系统为记录线程的一些必要信息,还使用了额外的资源,这些资源需要通过“收尸”归还给系统(当然,进程终止肯定会统一释放所有资源的,但是我们不能寄希望于进程的终止,毕竟万一是个长时间运行的进程怎么办?)
2.5.1 pthread_join
man pthread_join
#include
int pthread_join(pthread_t thread, void **retval); 功能:阻塞等待,直到特定线程终止或被取消,并为其收尸
- thread — 用于标识等待哪一个线程终止或被取消
- retval — 终止的线程的返回值将会被回填至 retval 所指空间;被取消的线程 PTHREAD_CANCELED 将会被回填至 retval 所指空间
2.5.2 pthread_detach
man pthread_detach
#include
int pthread_detach(pthread_t thread); 功能:不阻塞,显式要求特定线程自动收尸
- thread — 用于标识希望哪一个线程终止或取消后进行自动收尸
- 成功返回 0;失败返回非 0 的 errno
使用这两个函数的几个注意点:从 man 手册截取的
- Either pthread_join(3) or pthread_detach() should be called for each thread that an application creates, so that system resources for the thread can be released.
- Once a thread has been detached, it can't be joined with pthread_join(3) or be made joinable again.
- Attempting to detach an already detached thread results in unspecified behavior.
2.6 代码示例
需求:找出 30000000~30000200 之间的所有质数。要求创建 201 个线程来判断每个数是不是质数
最开始写出来的代码如下
#include
#include
#include
#include
#include
#define LEFT 30000000
#define RIGHT 30000200
#define THRNUM (RIGHT-LEFT+1) // 线程总数
static void * thr_primer(void *p) {
int mark = 1;
int num = *(int*)p; // void*转化为int*才能解引用
for (int j = 2; j < num/2; ++j)
{
if (num % j == 0)
{
mark = 0;
break;
}
}
if (mark)
printf("%d is a primer\n",num);
pthread_exit(NULL);
}
int main() {
pthread_t tid[THRNUM];
int err;
for (int i = LEFT; i <= RIGHT; ++i) {
// 针对每个数,都创建一个线程去判断其是否为质数
err = pthread_create(tid + i - LEFT, NULL, thr_primer, &i);
if (err)
{
fprintf(stderr, "pthread_create():%s\n", strerror(err));
exit(1);
}
}
for (int i = LEFT; i <= RIGHT; ++i)
pthread_join(tid[i - LEFT], NULL);
exit(0);
} 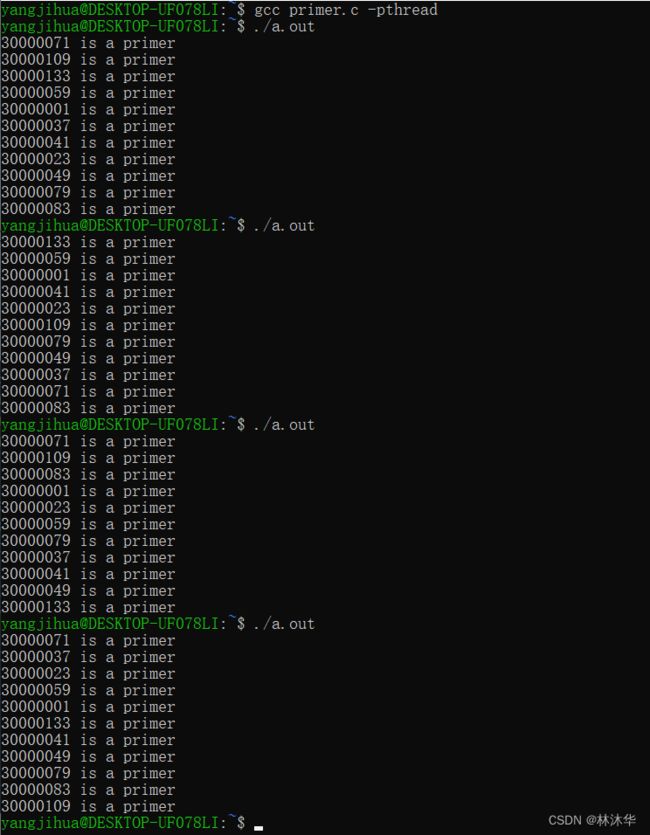
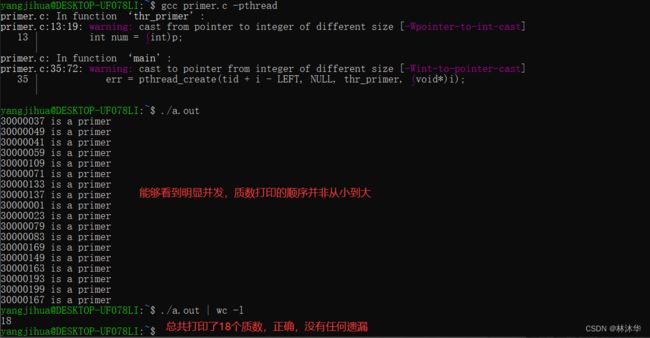
居然每一次的运行结果都不一样!!原因在哪里?
答:产生了线程之间的竞争与冲突!
问题出现在如下语句
err = pthread_create(tid + i - LEFT, NULL, thr_primer, &i);int num = *(int*)p;对于每一个线程,都是从同一个地址去取 i 的值,会有如下问题
这样一来,30000000、30000001 都被漏判断了......

既然问题出在传同一个地址给别的线程,而地址中的值可能会被 main 线程改变。一种比较丑陋的解决办法如下:我们直接传值!
#include
#include
#include
#include
#include
#define LEFT 30000000
#define RIGHT 30000200
#define THRNUM (RIGHT-LEFT+1) // 线程总数
static void * thr_primer(void *p) {
int mark = 1;
int num = (int)p; // p其实就是i,强转回int
for (int j = 2; j < num/2; ++j)
{
if (num % j == 0)
{
mark = 0;
break;
}
}
if (mark)
printf("%d is a primer\n",num);
pthread_exit(NULL);
}
int main() {
pthread_t tid[THRNUM];
int err;
for (int i = LEFT; i <= RIGHT; ++i) {
// 针对每个数,都创建一个线程去判断其是否为质数
err = pthread_create(tid + i - LEFT, NULL, thr_primer, (void*)i); // 我们就直接将i的值传过去,为了类型匹配强转一下
if (err)
{
fprintf(stderr, "pthread_create():%s\n", strerror(err));
exit(1);
}
}
for (int i = LEFT; i <= RIGHT; ++i)
pthread_join(tid[i - LEFT], NULL); // 对一个个线程收尸
exit(0);
} 
虽然结果是对了,但是太丑陋了,gcc 给了那么多警告⚠!
警告是因为奇奇怪怪的强转太多了。换种思路,我们还是传地址给别的线程,只不过传给不同线程的是不同的地址
#include
#include
#include
#include
#include
#define LEFT 30000000
#define RIGHT 30000200
#define THRNUM (RIGHT-LEFT+1) // 线程总数
static void * thr_primer(void *p) {
int mark = 1;
int num = *(int*)p;
for (int j = 2; j < num/2; ++j)
{
if (num % j == 0)
{
mark = 0;
break;
}
}
if (mark)
printf("%d is a primer\n",num);
pthread_exit(p); // 将地址返回,为了free
}
int main() {
pthread_t tid[THRNUM];
int err;
for (int i = LEFT; i <= RIGHT; ++i) {
int * p = malloc(sizeof(int));
*p = i; // 针对每个数,都开辟一片内存存放这个数,然后将这片内存传给线程
// 针对每个数,都创建一个线程去判断其是否为质数
err = pthread_create(tid + i - LEFT, NULL, thr_primer, (void*)p);
if (err)
{
fprintf(stderr, "pthread_create():%s\n", strerror(err));
exit(1);
}
}
void * ptr;
for (int i = LEFT; i <= RIGHT; ++i) {
pthread_join(tid[i - LEFT], &ptr); // 对一个个线程收尸
free(ptr); // 用ptr接受线程返回的地址,然后free
}
exit(0);
} 
上面的代码创建了 201 个线程。这不由地使我们思考一个问题:一个进程最多能容纳多少线程?
每个线程的都需要一个独立的栈空间......
64 位系统意味着用户空间的虚拟内存最大值是 128T,这个数值是很大的,一个线程需占用 8M 栈空间的情况来算,那么理论上可以创建 128T/8M 个线程,也就是 1000 多万个线程,感觉可以放心使用
但是如果是 32 位系统,那么能够创建的线程数就有很有限了。我们需要限制线程的数量,并将任务合理分配给有限数量的线程,这将在后续展开讨论

三、线程同步
来看一个现象:我们创建 200 个线程,每个线程都对全局量 count 执行 5000 次自增加,按道理来说应该总共会对 count 自增 200 * 5000 = 1000000 次
结果发现,count 并没有增加到 1000000!原因如下
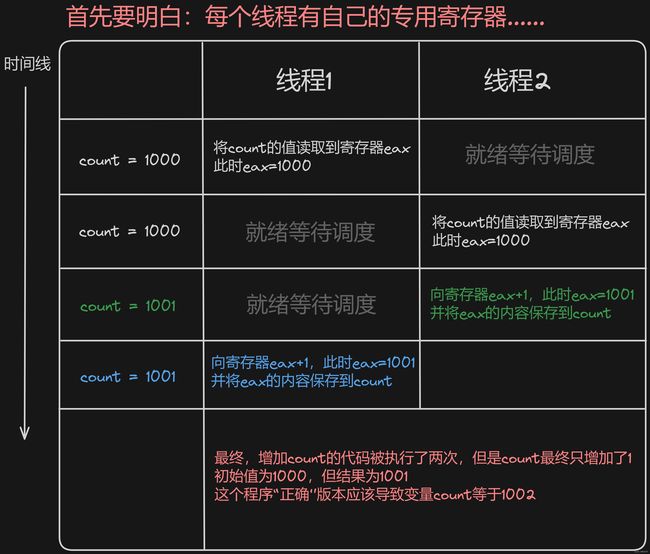
因此,在我们的代码里,虽然总共会对 count 自增 200 * 5000 = 1000000 次,但是其实 count 的增加量可能无法达到 1000000
这种现象本质原因是:当其中一个线程在执行 count++ 这段代码时,有别的线程也在同时执行这段相同的代码
线程同步就是希望能够解决上述的竞争故障问题

3.1 互斥量
3.1.1 类型 pthread_mutex_t
这个类型的变量代表一把锁,用来锁住一段代码,被锁住的这段代码称为临界区。当一个线程在临界区,它能够阻止其他线程进入直到本线程离开临界区

3.1.2 pthread_mutex_init
man pthread_mutex_init
#include
// 按照指定方式初始化锁mutex
int pthread_mutex_init(pthread_mutex_t *restrict mutex,
const pthread_mutexattr_t *restrict attr);
// 默认初始化锁mutex
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER; 功能:初始化一把锁
- mutex — 指定待初始化的锁
- attr — 用于指定如何初始化该锁
注意:初始化一把锁相当于“指定锁的行为”,未被初始化的锁是无效的。若是要想定制锁的行为,或者想将锁存在堆中,必须要用到 pthread_mutex_init
通常情况下,我们默认初始化锁(采取默认的锁的行为)即可
3.1.3 pthread_mutex_lock
#include
int pthread_mutex_lock(pthread_mutex_t *mutex);
// 对一把锁上锁
int pthread_mutex_trylock(pthread_mutex_t *mutex);
// 尝试对一把锁上锁
int pthread_mutex_unlock(pthread_mutex_t *mutex);
// 对一把锁解锁 功能:针对一把锁进行上锁与解锁
- 当锁 mutex 已经被别的线程上锁时,调用 pthread_mutex_lock 会发生阻塞直到 mutex 被解锁
- 当锁 mutex 已经被别的线程上锁时,调用 pthread_mutex_trylock 不会发生阻塞,立即返回
3.1.4 pthread_mutex_destroy
#include
int pthread_mutex_destroy(pthread_mutex_t *mutex); 功能: 清除一把锁的初始化状态,使其无效
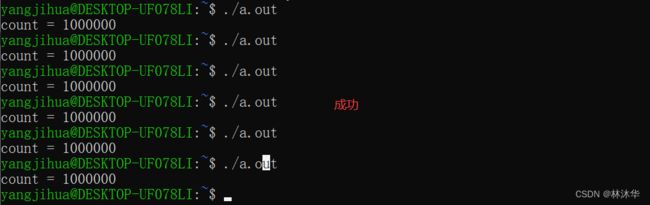
接下来我们练习一下这套函数的基本用法,通过互斥量,尝试修改上述对 count 自增 1000000 次的代码
#include
#include
#include
#include
#include
#define THRNUM 200 // 创建200个线程
static int count = 0;
static pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER; // 默认行为的锁,默认初始化
// 注意mutex需要定义在所有线程都能看到的全局位置
static void *thr_add(void *p) {
for (int i = 0; i < 5000; ++i)
{
pthread_mutex_lock(&mutex); // 上锁
count++; // 这样一来这部分代码仅能同时被单一线程执行
pthread_mutex_unlock(&mutex); // 解锁
}
pthread_exit(NULL);
}
int main() {
pthread_t tid[THRNUM];
int err;
for (int i = 0; i < THRNUM; ++i) {
err = pthread_create(tid + i, NULL, thr_add, NULL);
if (err) {
fprintf(stderr, "pthread_create():%s\n",strerror(err));
exit(1);
}
}
for (int i = 0; i < THRNUM; ++i) {
pthread_join(tid[i], NULL); // 对一个个线程收尸
}
printf("count = %d\n", count);
pthread_mutex_destroy(&mutex); // destroy一把锁mutex
exit(0);
} 
3.1.5 代码示例
需求:创建四个线程,其中
- 第一个线程往终端不断打印字符 a
- 第二个线程往终端不断打印字符 b
- 第三个线程往终端不断打印字符 c
- 第四个线程往终端不断打印字符 d
我们希望最终打印出来的顺序是 abcdabcdabcdabcd........
一种想法是搭建一个循环锁链
- 四个线程在分别执行四个打印不同字母的代码段。首先将所有打印字母的代码段上锁,然后再对打印 a 的代码段解锁(保证第一个打印的是 a)
- 对打印 a 的代码段上锁,打印 a,然后对打印 b 的代码段解锁
- 对打印 b 的代码段上锁,打印 b,然后对打印 c 的代码段解锁
- 对打印 c 的代码段上锁,打印 c,然后对打印 d 的代码段解锁
- 对打印 d 的代码段上锁,打印 d,然后对打印 a 的代码段解锁
- 回到 1,对打印 a 的代码段上锁,打印 a,然后对打印 b 的代码段解锁
- 回到 2,......
#include
#include
#include
#include
#include
#define THRNUM 4
static pthread_mutex_t mut[THRNUM]; // 需要四把锁,构成锁链
void * thr_func(void *p) {
int n = (int)p;
int c = 'a' + n;
while (1) {
pthread_mutex_lock(mut+n); // 上锁打印本字母的线程
write(1, &c, 1);
pthread_mutex_unlock(mut+(n+1)%THRNUM); // 解锁打印下一个字母的线程
}
pthread_exit(NULL);
}
int main() {
pthread_t tid[THRNUM];
for (int i = 0; i < THRNUM; ++i) {
pthread_mutex_init(mut + i, NULL); // 初始化锁
pthread_mutex_lock(mut+i); // 上锁
int err = pthread_create(tid+i, NULL, thr_func, (void*)i);
if (err)
{
fprintf(stderr, "pthread_create():%s\n", strerror(err));
}
}
pthread_mutex_unlock(mut+0); // 解锁打印a的线程
alarm(5);
for (int i = 0; i < THRNUM; ++i) {
pthread_join(tid[i], NULL);
}
exit(0);
} 3.2 线程池实现
回到 2.6 讲解的求质数部分。我们需要限制线程的数量,并将任务合理分配给有限数量的线程。在进程章节的 3.3 我们介绍了一些将任务分配给不同进程的方式,当时说过用池内算法涉及到竞争,因此暂时没有实现。而在线程部分,我们似乎可以实现池内算法了,原因如下:
- 我们学习了互斥量,对于多个线程在同一个“池”中抢任务这种情况,能够很好地处理竞争
- 多个线程可以共用进程的全局区,若将“池”放在全局区,每个线程都能够很方便地访问到“池”
基本思路如下

代码实现如下
#include
#include
#include
#include
#include
#include
#define LEFT 30000000
#define RIGHT 30000200
#define THRNUM 10 // 线程总数限定为10
static int pool = 0; // 池
// >0表示池中有任务
// =0表示池中没有任务
// =-1表示任务完成
static pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER; // 多个线程操作同一个池,需要加锁
static void * thr_primer(void *p) {
int num;
int mark;
while (1) {
mark = 1;
pthread_mutex_lock(&mutex); // 访问pool前,先上锁
while (pool == 0) // 一定要用while:因为并不保证从别的线程回来之后,pool一定不为0!
{
pthread_mutex_unlock(&mutex); // 一定要先解锁
sched_yield(); // 将cpu让给别的线程
pthread_mutex_lock(&mutex); // 回来需要上锁。然后再去看看pool
}
if (pool == -1)
{
pthread_mutex_unlock(&mutex); // 注意临界区中的任何跳转语句,跳出临界区之前一定要解锁
break;
}
num = pool; // 从池中获取
pool = 0;
pthread_mutex_unlock(&mutex);
for (int j = 2; j < num/2; ++j)
{
if (num % j == 0)
{
mark = 0;
break;
}
}
if (mark)
printf("thread[%d]: %d is a primer\n",(int)p, num);
}
pthread_exit(NULL);
}
int main() {
pthread_t tid[THRNUM];
int err;
for (int i = 0; i < THRNUM; ++i) { // 创建10个线程
err = pthread_create(tid + i, NULL, thr_primer, (void*)i);
if (err)
{
fprintf(stderr, "pthread_create():%s\n", strerror(err));
exit(1);
}
}
for (int i = LEFT; i <= RIGHT; ++i) { // 不断发任务
pthread_mutex_lock(&mutex);
while (pool != 0)
{
pthread_mutex_unlock(&mutex);
sched_yield(); // 将cpu让给别的线程
pthread_mutex_lock(&mutex);
}
pool = i; // 下发任务
pthread_mutex_unlock(&mutex);
}
pthread_mutex_lock(&mutex);
while (pool != 0) // 确保待完成的任务已经完成
{
pthread_mutex_unlock(&mutex);
sched_yield();
pthread_mutex_lock(&mutex);
}
pool = -1; // 相当于告知线程任务完成
pthread_mutex_unlock(&mutex);
for (int i = 0; i < THRNUM; ++i) {
pthread_join(tid[i], NULL); // 对一个个线程收尸
}
pthread_mutex_destroy(&mutex); // 使mutex不可用
exit(0);
} 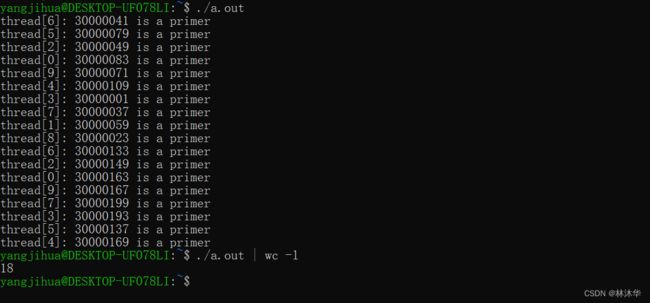
从上述代码中学到的几个点:
- 凡是需要读或者写公共资源 pool 的代码段,最好都用锁使其变成临界区
- 从线程的临界区跳出线程的代码记得一定要先释放锁,否则会出现死锁
3.3 令牌桶实现
我们在并发的信号部分通过信号的机制实现了令牌桶,并将其封装成库。在这里,我们希望不使用任何信号机制,改用多线程的办法实现相同的功能
具体而言:

就是上面所创建的线程造成了并发的可能!
- 因为始终有一个线程在读写 job 数组,而我们设计的供用户调用的接口函数内也有读写 job 数组的操作,因此我们需要将函数中读写 job 数组的代码段加锁,使该代码段变为临界区
- 因为始终有一个线程在读写结构体中的 token 成员,而我们设计的供用户调用的接口函数内也有读写结构体中 token 的操作,因此我们需要将函数中读写结构体中 token 的代码段加锁,使其变为临界区。因为不同的结构体实例代表着不同的流控方案,彼此之间互不关联。因此,对于每一个结构体实例,都需要一把针对于该结构体实例的锁,这把锁用于将读写该结构体中的 token 的代码段变为临界区
在实现之前,我们需要了解一个函数:pthread_once
man pthread_once
#include
int pthread_once(pthread_once_t *once_control,
void (*init_routine)(void));
pthread_once_t once_control = PTHREAD_ONCE_INIT; 功能: 保证某函数只能被调用一次
- 进程内的 pthread_once 第一次被某个线程传入参数 once_control 进行调用时,将调用函数 init_routine。在此之后,该进程内的任何线程只要还使用 once_control 调用 pthread_once,都不会再去调用 init_routine 了
现在开始代码实现。注意,仅需更改接口函数的具体实现的部分!main.c 和 mytbf.h 都不用改
mytbf.c
#include
#include
#include
#include
#include
#include
#include "mytbf.h"
static pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
static struct mytbf_st* job[MYTBF_MAX]; // 用于存放令牌桶的数组。最多存放MYTBF_MAX个桶
// 表示最多存在MYTBF_MAX套方案
static pthread_t tid; // 往job中的结构体里不断添加token的线程
static pthread_once_t init_once;
struct mytbf_st {
int aps; // 每秒增加的令牌数
int burst; // 每个桶中的令牌个数上限
int token; // 令牌个数
int pos; // 这个桶存放在数组的哪个位置
pthread_mutex_t mutex; // 每个桶都需要一个锁
};
static int get_free_pos_unlocked() { // 工具函数,获取数组中的空位置来存放令牌桶
// 这个函数本身未上锁,但是他应该在临界区被调用
for (int i = 0; i < MYTBF_MAX; ++i)
if (job[i] == NULL)
return i;
return -1;
}
static int min(int lhs, int rhs) { // 工具函数,求最小值
return lhs < rhs ? lhs : rhs;
}
static void* thr_alrm(void* p) {
while (1) {
pthread_mutex_lock(&mutex); // 读写job数组前上锁
for (int i = 0; i < MYTBF_MAX; ++i) {
if (job[i] != NULL) {
pthread_mutex_lock(&job[i]->mutex); // 读写结构体实例前上锁
job[i]->token += job[i]->aps;
if (job[i]->token > job[i]->burst)
job[i]->token = job[i]->burst;
pthread_mutex_unlock(&job[i]->mutex); // 读写结构体实例后解锁
}
}
pthread_mutex_unlock(&mutex); // 读写job数组后解锁
sleep(1); // 每隔一秒往桶中增加一次令牌
}
}
static void module_unload() { // 模块卸载
// 为什么叫模块?一个好的编程习惯是,将我们写的代码看成一个软件项目下的一个子模块......
// 模块卸载是为了使调用我们的模块后,环境能够恢复到和调用模块前一样
pthread_cancel(tid);
pthread_join(tid, NULL);
// 此时,往job的中的结构体不断添加token的线程终止了,并发结束
// 可以快快乐乐无需上锁读写job了
for (int i = 0; i < MYTBF_MAX; ++i)
{
if (job[i] != NULL)
{
mytbf_destroy(&job[i]);
}
}
pthread_mutex_destroy(&mutex);
}
static void module_load(void) { // 模块加载
// 模块加载表示做进入我们的模块之前的预处理。只能调用一次
// 创建线程,线程用于每隔一秒往桶中增加一次令牌
int err = pthread_create(&tid, NULL, thr_alrm, NULL);
if (err) {
fprintf(stderr, "pthread_create():%s\n", strerror(err));
}
}
// 创建令牌桶,返回一套令牌桶参数来表征一个桶
mytbf_t * mytbf_init(int aps, int burst) {
struct mytbf_st * me;
pthread_once(&init_once, module_load); // 如果main中创建多个桶,也只会调用一次load
me = malloc(sizeof(*me));
if (me == NULL)
return NULL;
me->token = 0;
me->aps = aps;
me->burst = burst;
pthread_mutex_init(&me->mutex, NULL);
pthread_mutex_lock(&mutex); // 读写job,上锁
int pos = get_free_pos_unlocked();
if (pos < 0) {
pthread_mutex_unlock(&mutex);
free(me);
return NULL;
}
me->pos = pos;
job[pos] = me; // 将创建的桶放进数组的空位置
pthread_mutex_unlock(&mutex); // 解锁
return me;
}
// 在特定令牌桶中中获取令牌token
int mytbf_fetchtoken(mytbf_t *ptr, int size) {
if (size <= 0)
return -EINVAL; // 这样做的好处是为了:用户可以通过EINVAL获取对应的错误提示字符串
struct mytbf_st *me = ptr; // 别忘了mytbf_t*是void*,struct mytbf_st*才是结构体指针
pthread_mutex_lock(&me->mutex); // 读写某个结构体实例中的token,上锁
while (me->token <= 0)
{
pthread_mutex_unlock(&me->mutex); // 从临界区跳出线程的代码记得一定要先释放锁
sched_yield(); // 主动让出cpu,让别的线程有机会抢到
pthread_mutex_lock(&me->mutex);
}
int n = min(me->token, size); // 希望获取size个令牌,但是桶中令牌个数是me->token
// 能获取到的应该是size与me->token中的最小值
me->token -= n;
pthread_mutex_unlock(&me->mutex); // 解锁
return n;
}
// 在特定令牌桶中归还令牌token
int mytbf_returntoken(mytbf_t *ptr, int size) {
if (size <= 0)
return -EINVAL;
struct mytbf_st *me = ptr;
pthread_mutex_lock(&me->mutex); // 读写某个结构体实例中的token,上锁
me->token += size;
if (me->token > me->burst)
me->token = me->burst;
pthread_mutex_unlock(&me->mutex); // 解锁
return size;
}
// 删除桶
int mytbf_destroy(mytbf_t *ptr) {
struct mytbf_st * me = ptr;
pthread_mutex_lock(&mutex);
job[me->pos] = NULL;
pthread_mutex_unlock(&mutex);
pthread_mutex_destroy(&me->mutex);
free(ptr);
return 0;
} 
从上述代码中学到的几个点:
- 因为临界区的代码无法由多个线程并发执行,为了提高代码运行效率,临界区应该越短越好
- 要明确因为什么造成的并发?上述代码中是因为我们创建了一个不断往位于 job 数组中的结构体实例增加 token 的线程,同时用户在别的线程也可能操作 job 数组及结构体实例,因此才造成的并发
- 读写公共资源 job 和结构体实例的代码段都需要上锁,使代码段成为临界区
- 可以看出将接口与实现分离的一个优点:只要接口定义明确,接口的具体实现对于在 main 中调用接口实现业务的用户来说是透明的
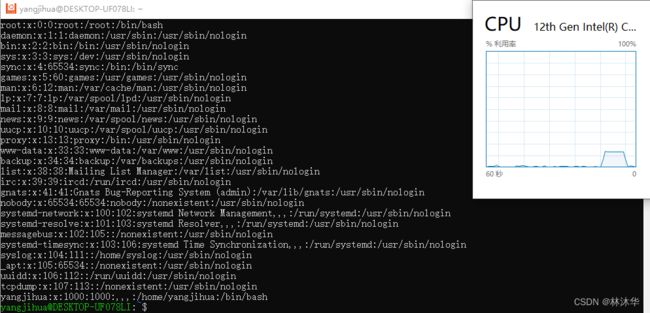
此外,如果我们看一看 CPU 使用率,可以发现
这是由于
while (me->token <= 0) { pthread_mutex_unlock(&me->mutex); sched_yield(); // 主动让出cpu,但是回来后未必token就大于0了 pthread_mutex_lock(&me->mutex); }上述代码造成了忙等现象。假如 token 一直小于等于 0,则该循环会不断重复执行解锁、取消调度、被调度、上锁、判断 token、解锁、......,比较耗 CPU。这相当于是查询法,线程不断去查询 token 是否大于 0,CPU 资源全都花费在查询上了。如果能用通知法,将会节省很多 CPU 资源。下面的机制将能够实现通知法
3.4 条件变量
3.4.1 类型 pthread_cond_t
这个类型的变量为条件变量,可以理解为一个“条件”。线程可以等待一个“条件”的满足,并休眠;也可以告知别的线程“条件已满足”,从而唤醒别的休眠的线程

这种思想最开始也称为“私有信号量”
3.4.2 pthread_cond_init
man pthread_cond_init
#include
int pthread_cond_init(pthread_cond_t *restrict cond,
const pthread_condattr_t *restrict attr);
pthread_cond_t cond = PTHREAD_COND_INITIALIZER; - cond — 待初始化的条件变量
- attr — 用于指定如何初始化条件变量
功能:初始化一个条件变量
注意:初始化一个条件变量相当于“指定条件变量的行为”,未被初始化的条件变量是无效的。若是要想定制条件变量的行为,或者想将条件变量存在堆中,必须要用到 pthread_cond_init
通常情况下,我们默认初始化条件变量(采取默认的条件变量的行为)即可
3.4.3 pthread_cond_signal
#include
int pthread_cond_signal(pthread_cond_t *cond); 功能:唤醒某一等待特定条件满足的线程
- cond — 指定条件,唤醒的是等待条件 cond 满足的线程
注意:所谓“唤醒”并不是指马上调度线程,而是使线程解除阻塞,加入就绪队列等待调度。如果有多个等待条件 cond 满足的线程,那么唤醒哪个等待特定条件满足的线程也是不确定的,反正只能唤醒一个。这个语句拟人化的比喻是“告知某个线程:条件 cond 被满足了”。如果没有等待唤醒的线程,将无事发生(毕竟压根都没人睡觉,就算闹钟响了也叫不醒任何人)
3.4.4 pthread_cond_broadcast
#include
int pthread_cond_broadcast(pthread_cond_t *cond); 功能:唤醒所有等待条件 cond 满足的线程
3.4.4 pthread_cond_wait
#include
int pthread_cond_timedwait(pthread_cond_t *restrict cond,
pthread_mutex_t *restrict mutex,
const struct timespec *restrict abstime);
int pthread_cond_wait(pthread_cond_t *restrict cond,
pthread_mutex_t *restrict mutex); 功能:等待特定条件并休眠
- cond — 指定条件,表明等到条件 cond 满足才可能被唤醒
- mutex — 指定已被上锁的互斥量,wait 假定在被调用时,互斥量已是上锁状态
- abstime — 指定最长休眠时间,当超过这段时间,线程被自动唤醒
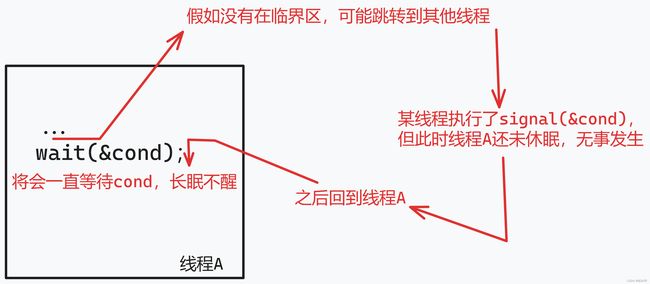
为何 wait 规定一定要在临界区内被调用?
因此,wait 假定在被调用时,互斥量已是上锁状态。wait 的职责是释放锁,并让调用线程休眠(原子地)。当线程被唤醒时(在另外某个线程告知它条件被满足后),它必须重新获取锁,再返回调用者。所以我们才需要将锁传入 wait,方便 wait 对锁进行一系列操作
3.4.5 pthread_cond_destroy
#include
int pthread_cond_destroy(pthread_cond_t *cond); 功能: 清除一个条件变量的初始化状态,使其无效
3.4.6 代码示例
引入条件变量,而不使用锁链,实现同 3.1.4 相同的需求:创建四个线程,其中
- 第一个线程往终端不断打印字符 a
- 第二个线程往终端不断打印字符 b
- 第三个线程往终端不断打印字符 c
- 第四个线程往终端不断打印字符 d
我们希望最终打印出来的顺序是 abcdabcdabcdabcd........
#include
#include
#include
#include
#include
#define THRNUM 4
static pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
static pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
static int pre = 3; // 上一个打印的字母
// 0-a
// 1-b
// 2-c
// 3-d
void * thr_func(void *p) {
int n = (int)p;
int c = 'a' + n;
while (1) {
pthread_mutex_lock(&mutex);
while (n != (pre+1)%4) // 当前线程打印的非我们希望打印的
pthread_cond_wait(&cond, &mutex); // 释放锁,休眠
write(1, &c, 1);
pre = n; // 更新“上一个打印的字母”
pthread_cond_broadcast(&cond); // 让别的线程醒醒
pthread_mutex_unlock(&mutex);
}
pthread_exit(NULL);
} 3.5 令牌桶的非忙等版本
通过条件变量的机制,能够避免忙等情况的出现
#include
#include
#include
#include
#include
#include
#include "mytbf.h"
static pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
static struct mytbf_st* job[MYTBF_MAX]; // 用于存放令牌桶的数组。最多存放MYTBF_MAX个桶
// 表示最多存在MYTBF_MAX套方案
static pthread_t tid; // 往job中的结构体里不断添加token的线程
static pthread_once_t init_once;
struct mytbf_st {
int aps; // 每秒增加的令牌数
int burst; // 每个桶中的令牌个数上限
int token; // 令牌个数
int pos; // 这个桶存放在数组的哪个位置
pthread_mutex_t mutex; // 每个桶都需要一个锁
pthread_cond_t cond; // 每个桶都需要维护一个条件,用于通知“该桶的token还有剩余”
};
static int get_free_pos_unlocked() { // 工具函数,获取数组中的空位置来存放令牌桶
// 这个函数本身未上锁,但是他应该在临界区被调用
for (int i = 0; i < MYTBF_MAX; ++i)
if (job[i] == NULL)
return i;
return -1;
}
static int min(int lhs, int rhs) { // 工具函数,求最小值
return lhs < rhs ? lhs : rhs;
}
static void* thr_alrm(void* p) {
while (1) {
pthread_mutex_lock(&mutex); // 读写job数组前上锁
for (int i = 0; i < MYTBF_MAX; ++i) {
if (job[i] != NULL) {
pthread_mutex_lock(&job[i]->mutex); // 读写结构体实例前上锁
job[i]->token += job[i]->aps;
if (job[i]->token > job[i]->burst)
job[i]->token = job[i]->burst;
pthread_cond_broadcast(&job[i]->cond); // 发出一个通知
pthread_mutex_unlock(&job[i]->mutex); // 读写结构体实例后解锁
}
}
pthread_mutex_unlock(&mutex); // 读写job数组后解锁
sleep(1); // 每隔一秒往桶中增加一次令牌
}
}
static void module_unload() { // 模块卸载
// 为什么叫模块?一个好的编程习惯是,将我们写的代码看成一个软件项目下的一个子模块......
// 模块卸载是为了使调用我们的模块后,环境能够恢复到和调用模块前一样
pthread_cancel(tid);
pthread_join(tid, NULL);
// 此时,往job的中的结构体不断添加token的线程终止了,并发结束
// 可以快快乐乐无需上锁读写job了
for (int i = 0; i < MYTBF_MAX; ++i)
{
if (job[i] != NULL)
{
mytbf_destroy(&job[i]);
}
}
pthread_mutex_destroy(&mutex);
}
static void module_load(void) { // 模块加载
// 模块加载表示做进入我们的模块之前的预处理。只能调用一次
// 创建线程,线程用于每隔一秒往桶中增加一次令牌
int err = pthread_create(&tid, NULL, thr_alrm, NULL);
if (err) {
fprintf(stderr, "pthread_create():%s\n", strerror(err));
}
}
// 创建令牌桶,返回一套令牌桶参数来表征一个桶
mytbf_t * mytbf_init(int aps, int burst) {
struct mytbf_st * me;
pthread_once(&init_once, module_load); // 如果main中创建多个桶,也只会调用一次load
me = malloc(sizeof(*me));
if (me == NULL)
return NULL;
me->token = 0;
me->aps = aps;
me->burst = burst;
pthread_mutex_init(&me->mutex, NULL);
pthread_cond_init(&me->cond, NULL);
pthread_mutex_lock(&mutex); // 读写job,上锁
int pos = get_free_pos_unlocked();
if (pos < 0) {
pthread_mutex_unlock(&mutex);
free(me);
return NULL;
}
me->pos = pos;
job[pos] = me; // 将创建的桶放进数组的空位置
pthread_mutex_unlock(&mutex); // 解锁
return me;
}
// 在特定令牌桶中中获取令牌token
int mytbf_fetchtoken(mytbf_t *ptr, int size) {
if (size <= 0)
return -EINVAL; // 这样做的好处是为了:用户可以通过EINVAL获取对应的错误提示字符串
struct mytbf_st *me = ptr; // 别忘了mytbf_t*是void*,struct mytbf_st*才是结构体指针
pthread_mutex_lock(&me->mutex); // 读写某个结构体实例中的token,上锁
while (me->token <= 0)
{
// 等待条件满足。收到满足条件的通知前会阻塞,不会一直循环忙等
pthread_cond_wait(&me->cond, &me->mutex);
}
int n = min(me->token, size); // 希望获取size个令牌,但是桶中令牌个数是me->token
// 能获取到的应该是size与me->token中的最小值
me->token -= n;
pthread_mutex_unlock(&me->mutex); // 解锁
return n;
}
// 在特定令牌桶中归还令牌token
int mytbf_returntoken(mytbf_t *ptr, int size) {
if (size <= 0)
return -EINVAL;
struct mytbf_st *me = ptr;
pthread_mutex_lock(&me->mutex); // 读写某个结构体实例中的token,上锁
me->token += size;
if (me->token > me->burst)
me->token = me->burst;
pthread_mutex_unlock(&me->mutex); // 解锁
return size;
}
// 删除桶
int mytbf_destroy(mytbf_t *ptr) {
struct mytbf_st * me = ptr;
pthread_mutex_lock(&mutex);
job[me->pos] = NULL;
pthread_mutex_unlock(&mutex);
pthread_mutex_destroy(&me->mutex);
pthread_cond_destroy(&me->cond);
free(ptr);
return 0;
} 
原代码如下:假如 token 一直小于等于 0,原循环会不断重复执行解锁、取消调度、被调度、上锁、判断 token、解锁、......,比较耗 CPU。这相当于是查询法,线程不断去查询 token 是否大于 0,CPU 资源全都花费在查询上了
while (me->token <= 0) { pthread_mutex_unlock(&me->mutex); sched_yield(); // 主动让出cpu,但是回来后未必token就大于0了 pthread_mutex_lock(&me->mutex); }优化后的代码如下:只要 token 小于等于 0,线程就会开始阻塞。直到有通知告诉它 token 被增加了,才会被唤醒。这样不会循环执行无意义的代码,能够节约 CPU 资源
while (me->token <= 0) { // 等待条件满足。收到满足条件的通知前会阻塞,不会一直循环忙等 pthread_cond_wait(&me->cond, &me->mutex); }
3.6 线程池的非忙等版本
同理,修改 3.2 代码如下
#include
#include
#include
#include
#include
#include
#define LEFT 30000000
#define RIGHT 30000200
#define THRNUM 10 // 线程总数限定为10
static int pool = 0; // 池
// >0表示池中有任务
// =0表示池中没有任务
// =-1表示任务完成
static pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER; // 多个线程操作同一个池,需要加锁
static pthread_cond_t cond_full = PTHREAD_COND_INITIALIZER; // 用于通知所有下游线程:池满了,干活!
static pthread_cond_t cond_empty = PTHREAD_COND_INITIALIZER; // 用于通知main线程:池空了,派活儿!
static void * thr_primer(void *p) {
int num;
int mark;
while (1) {
mark = 1;
pthread_mutex_lock(&mutex); // 访问pool前,先上锁
while (pool == 0) // 一定要用while
{
pthread_cond_wait(&cond_full, &mutex); // 等待条件:池变满
}
if (pool == -1)
{
pthread_mutex_unlock(&mutex); // 注意临界区中的任何跳转语句,跳出临界区之前一定要解锁
break;
}
num = pool; // 从池中获取
pool = 0;
pthread_cond_signal(&cond_empty); // 告诉main线程:池空了
pthread_mutex_unlock(&mutex);
for (int j = 2; j < num/2; ++j)
{
if (num % j == 0)
{
mark = 0;
break;
}
}
if (mark)
printf("thread[%d]: %d is a primer\n",(int)p, num);
}
pthread_exit(NULL);
}
int main() {
pthread_t tid[THRNUM];
int err;
for (int i = 0; i < THRNUM; ++i) { // 创建20个线程
err = pthread_create(tid + i, NULL, thr_primer, (void*)i);
if (err)
{
fprintf(stderr, "pthread_create():%s\n", strerror(err));
exit(1);
}
}
for (int i = LEFT; i <= RIGHT; ++i) { // 不断发任务
pthread_mutex_lock(&mutex);
while (pool != 0)
{
pthread_cond_wait(&cond_empty, &mutex); // 等待条件:池变空
}
pool = i; // 下发任务
pthread_cond_broadcast(&cond_full); // 告诉所有下游线程:池满了
pthread_mutex_unlock(&mutex);
}
pthread_mutex_lock(&mutex);
while (pool != 0) // 确保任务完成
{
pthread_cond_wait(&cond_empty, &mutex);
}
pool = -1;
pthread_cond_signal(&cond_full);
pthread_mutex_unlock(&mutex);
for (int i = 0; i < THRNUM; ++i) {
pthread_join(tid[i], NULL); // 对一个个线程收尸
}
pthread_cond_destroy(&cond_empty);
pthread_cond_destroy(&cond_full);
pthread_mutex_destroy(&mutex); // 使mutex不可用
exit(0);
} 3.7 信号量
信号量是有一个整数值的对象,可以用两个函数操作它
void mysem_post(mysem_t * s);
// 将信号量中的整数值加1
// 如果信号量中整数的值大于0,则唤醒一个线程void mysem_wait(mysem_t * s);
// 如果信号量中的整数值小于等于0,则休眠等待
// 否则将信号量中的整数值减1通过将信号量中整数的初始值设置成 0,可以实现条件变量的功能;将信号量中整数的初始值设置成 1,可以实现互斥量的功能;将信号量中整数的初始值设置成一个正整数,则能够表示“资源数目”
代码需求:
- 使用互斥量和条件变量实现信号量的功能,并封装成库
- 通过我们实现的信号量来完成线程数量的调控:我们希望始终维护筛选质数的线程最多为 N 个。当线程数不足 N 个,可以创建新线程;当线程数等于 N 个,则无法再创建更多线程了;当其中的某个线程结束,就又可以创建新线程
mysem.h,主要定义了接口
#ifndef MYSEM_H__
#define MYSEM_H__
typedef void mysem_t;
// 初始化一个信号量中的整型值,返回该信号量
mysem_t * mysem_init(int initval);
// 加一、若满足条件则唤醒
void mysem_post(mysem_t * s);
// 休眠,直到满足条件,再减一
void mysem_wait(mysem_t * s);
// 销毁信号量
void mysem_destroy(mysem_t * s);
#endifmysem.c,主要实现了接口
#include
#include
#include
#include "mysem.h"
struct mysem_t
{
int value;
pthread_mutex_t mutex;
pthread_cond_t cond;
};
mysem_t * mysem_init(int initval) {
struct mysem_t *me;
me = malloc(sizeof(*me));
if (me == NULL)
return NULL;
me->value = initval;
pthread_mutex_init(&me->mutex, NULL); // 操作信号量中value应该是原子的
pthread_cond_init(&me->cond, NULL);
return me;
}
void mysem_post(mysem_t * s) {
struct mysem_t * me = s;
pthread_mutex_lock(&me->mutex);
me->value += 1; // 加一
if (me->value > 0) // 若满足条件则唤醒
pthread_cond_broadcast(&me->cond);
pthread_mutex_unlock(&me->mutex);
}
void mysem_wait(mysem_t * s) {
struct mysem_t * me = s;
pthread_mutex_lock(&me->mutex);
while (me->value <= 0) { // 休眠,直到满足value>0的条件
pthread_cond_wait(&me->cond, &me->mutex);
}
me->value -= 1; // 再减一
pthread_mutex_unlock(&me->mutex);
}
void mysem_destroy(mysem_t * s) {
struct mysem_t * me = s;
pthread_mutex_destroy(&me->mutex);
pthread_cond_destroy(&me->cond);
free(me);
} main.c,主要模拟用户,通过信号量实现线程数量调控
#include
#include
#include
#include
#include
#include "mysem.h"
#define LEFT 30000000
#define RIGHT 30000200
#define THRNUM (RIGHT-LEFT+1)
#define N 4 // 希望始终维护筛选质数的线程为4个
static mysem_t *sem;
// 如何调控线程个数?将信号量中的整型值看成某个资源的数目!
// 假设每创建一个线程都需要消耗一个资源
// 只要我们设定这个资源的初始数目为4,就可以保证创建的线程数目不会超过4
// 每创建一个线程,资源数目减一
// 当线程结束,资源数目加一
static void *thr_prime(void *p) {
int i, j, mark;
i = (int)p;
mark = 1;
for(j = 2; j < i/2; j++) {
if(i % j == 0) {
mark = 0;
break;
}
}
if(mark)
printf("%d is a primer.\n", i);
// 假定每个线程需要2s完成
sleep(2);
// 增加信号量,归还这个线程消耗的资源
mysem_post(sem);
pthread_exit(NULL);
}
int main(void) {
int i, err;
pthread_t tid[THRNUM];
sem = mysem_init(N);
if(sem == NULL) {
fprintf(stderr, "mysem_init() failed!\n");
exit(1);
}
for(i = LEFT; i <= RIGHT; i++) {
// 减少信号量,消耗一个资源个数以创建线程
mysem_wait(sem);
err = pthread_create(tid+(i-LEFT), NULL, thr_prime, (void *)i);
if(err) {
fprintf(stderr, "pthread_create(): %s\n", strerror(err));
exit(1);
}
}
for (i = LEFT; i <= RIGHT; i++) {
pthread_join(tid[i-LEFT], NULL);
}
mysem_destroy(sem);
exit(0);
} 
3.8 读写锁

具体实现需要同时用到信号量与互斥锁,是个综合应用,暂略
四、线程属性
在创建线程的那个函数里面,注意到有个 pthread_attr_t 类型的 attr
#includeint pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine) (void *), void *arg); 之前都是设置的 NULL 表示选用默认属性创建线程。这部分将着重关注这个 attr
4.1 pthread_attr_t 类型
线程具有属性,一个 pthread_attr_t 类型的对象能够代表一个线程的属性。可以往 pthread_create 函数的 attr 形参传入特定的 pthread_attr_t 类型的对象的指针,来创建具有特定属性的线程。注意:在使用 pthread_attr_t 类型对象前需要对其初始化,使用后需要对其去除初始化
4.2 pthread_attr_init
#include
int pthread_attr_init(pthread_attr_t *attr); 功能:初始化 pthread_attr_t 类型的对象
- attr — 指向待初始化的对象。经过初始化后,被初始化的 pthread_attr_t 类型的对象代表“线程的默认属性”
- 成功返回 0;失败返回非 0 的 errno
4.3 pthread_attr_destroy
#include
int pthread_attr_destroy(pthread_attr_t *attr); 功能:去除初始化 pthread_attr_t 类型的对象
- attr — 指向待去除初始化的对象。去除初始化后,该 pthread_attr_t 类型的对象不再可用,不代表任何含义
- 成功返回 0;失败返回非 0 的 errno
4.4 设置属性的函数
通过下面函数可以设置 attr 所指对象代表的线程属性。详见 man 手册
int pthread_attr_setstack(pthread_attr_t *attr, void *stackaddr, size_t stacksize);
int pthread_attr_getstack(const pthread_attr_t * restrict attr, void ** restrict stackaddr, size_t * restrict stacksize);
int pthread_attr_setstacksize(pthread_attr_t *attr, size_t stacksize);
int pthread_attr_getstacksize(const pthread_attr_t *attr, size_t *stacksize);
int pthread_attr_setguardsize(pthread_attr_t *attr, size_t guardsize);
int pthread_attr_getguardsize(const pthread_attr_t *attr, size_t *guardsize);
int pthread_attr_setstackaddr(pthread_attr_t *attr, void *stackaddr);
int pthread_attr_getstackaddr(const pthread_attr_t *attr, void **stackaddr);
int pthread_attr_setdetachstate(pthread_attr_t *attr, int detachstate);
int pthread_attr_getdetachstate(const pthread_attr_t *attr, int *detachstate);
int pthread_attr_setinheritsched(pthread_attr_t *attr, int inheritsched);
int pthread_attr_getinheritsched(const pthread_attr_t *attr, int *inheritsched);
int pthread_attr_setschedparam(pthread_attr_t *attr, const struct sched_param *param);
int pthread_attr_getschedparam(const pthread_attr_t *attr, struct sched_param *param);
int pthread_attr_setschedpolicy(pthread_attr_t *attr, int policy);
int pthread_attr_getschedpolicy(const pthread_attr_t *attr, int *policy);
int pthread_attr_setscope(pthread_attr_t *attr, int contentionscope);
int pthread_attr_getscope(const pthread_attr_t *attr, int *contentionscope);4.5 代码示例
- 打印一个进程所能创建的线程个数上限
- 改变一个线程创建时所需的栈大小,并使其具有自动收尸的属性,并验证
首先打印进程创建的线程个数上限
#include
#include
#include
#include
#include
void* thr(void * p) {
sleep(10000);
}
int main() {
int i;
pthread_t tid;
int err;
for (i = 0; ; ++i) {
err = pthread_create(&tid, NULL, thr, NULL);
if (err) {
fprintf(stderr, "pthread_create():%s\n", strerror(err));
break;
}
}
fprintf(stdout, "threads capacity:%d\n", i);
exit(0);
}
可以看到上限是 4743 个
然后再通过 pthread_attr_t 类型的对象定制一个线程创建时所需的栈大小,并使其具有自动收尸的属性。验证定制成功
#include
#include
#include
#include
#include
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
static int cur_thread = 0; // 希望按照线程创建的顺序打印线程地址
void* thr(void * p) {
pthread_mutex_lock(&mutex);
while (cur_thread != (int)p) // 如果当前线程不符合希望打印的线程号顺序,休眠
pthread_cond_wait(&cond, &mutex);
fprintf(stdout, "thread[%d] stack address: %p\n",cur_thread, &p);
pthread_cond_broadcast(&cond);
++cur_thread; // 下一个希望打印的线程号
pthread_mutex_unlock(&mutex);
sleep(10);
}
int main() {
int i;
pthread_t tid;
int err;
pthread_attr_t attr;
pthread_attr_init(&attr);
// 使每个线程所需占栈空间大小为1024*1024B=1024kB=1MB
err = pthread_attr_setstacksize(&attr, 1024 * 1024);
if (err)
fprintf(stderr, "pthread_attr_setstacksize():%s\n", strerror(err));
// 使每个线程创建后,默认选择“自动收尸”
err = pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED);
if (err)
fprintf(stderr, "pthread_attr_setdetachstate():%s\n", strerror(err));
for (i = 0; ; ++i) {
err = pthread_create(&tid, &attr, thr, (void*)i)// i作为线程编号
if (err) {
fprintf(stderr, "pthread_create():%s\n", strerror(err));
break;
}
}
pthread_attr_destroy(&attr);
puts("main thread end!");
pthread_exit(0); // 用pthread_exit不会终止进程,用来验证detach的作用
} 我们设置的每个线程所占栈空间大小为 1024 * 1024B = 1048576B,而测试出来两个紧挨着创建的线程中首个变量的地址相差 1114112 字节,约等于 1048576 字节,说明设置成功
五、线程的同步属性
5.1 互斥量属性
在初始化互斥量的那个函数里面,注意到有个 pthread_mutexattr_t 类型的 attr
#includeint pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t *restrict attr); 之前都是设置的 NULL 表示选用默认属性初始化互斥量。这部分将着重关注这个 attr
5.1.1 pthread_mutexattr_t 类型
互斥量具有属性,一个 pthread_mutexattr_t 类型的对象能够代表一个互斥量的属性。可以往 pthread_mutex_init 函数的 attr 形参传入特定的 pthread_mutexattr_t 类型的对象的指针,来创建具有特定属性的互斥量。注意:在使用 pthread_mutexattr_t 类型对象前需要对其初始化,使用后需要对其去除初始化
5.1.2 pthread_mutexattr_init
#include
int pthread_mutexattr_init(pthread_mutexattr_t *attr); 功能:初始化 pthread_mutexattr_t 类型的对象
- attr — 指向待初始化的对象。经过初始化后,被初始化的 pthread_mutexattr_t 类型的对象代表“互斥量的默认属性”
- 成功返回 0;失败返回非 0 的 errno
5.1.3 pthread_mutexattr_destroy
#include
int pthread_mutexattr_destroy(pthread_mutexattr_t *attr); 功能:去除初始化 pthread_mutexattr_t 类型的对象
- attr — 指向待去除初始化的对象。去除初始化后,该 pthread_mutexattr_t 类型的对象不再可用,不代表任何含义
- 成功返回 0;失败返回非 0 的 errno
5.1.4 设置属性的函数
通过下面函数可以设置 attr 所指对象代表的互斥量属性。详见 man 手册
int pthread_mutexattr_setprioceiling(pthread_mutexattr_t *attr, int prioceiling);
int pthread_mutexattr_getprioceiling(pthread_mutexattr_t *attr, int *prioceiling);
int pthread_mutexattr_setprotocol(pthread_mutexattr_t *attr, int protocol);
int pthread_mutexattr_getprotocol(pthread_mutexattr_t *attr, int *protocol);
int pthread_mutexattr_settype(pthread_mutexattr_t *attr, int type);
int pthread_mutexattr_gettype(pthread_mutexattr_t *attr, int *type);
int pthread_mutexattr_setpolicy_np(pthread_mutexattr_t *attr, int policy);
int pthread_mutexattr_getpolicy_np(pthread_mutexattr_t *attr, int *policy);5.2 条件变量属性
在初始化条件变量的那个函数里面,注意到有个 pthread_condattr_t 类型的 attr
#includeint pthread_cond_init(pthread_cond_t *restrict cond, const pthread_condattr_t *restrict attr); 之前都是设置的 NULL 表示选用默认属性初始化条件变量。这部分将着重关注这个 attr
5.2.1 pthread_condattr_t 类型
条件变量具有属性,一个 pthread_condattr_t 类型的对象能够代表一个条件变量的属性。可以通过往 pthread_cond_init 函数的 attr 形参传入特定的 pthread_condattr_t 类型的对象的指针,来创建具有特定属性的条件变量。注意:在使用 pthread_condattr_t 类型对象前需要对其初始化,使用后需要对其去除初始化
5.2.2 pthread_condattr_init
#include
int pthread_condattr_init(pthread_condattr_t *attr); 功能:初始化 pthread_condattr_t 类型的对象
- attr — 指向待初始化的对象。经过初始化后,被初始化的 pthread_condattr_t 类型的对象代表“条件变量的默认属性”
- 成功返回 0;失败返回非 0 的 errno
5.2.3 pthread_condattr_destroy
#include
int pthread_condattr_destroy(pthread_condattr_t *attr); 功能:去除初始化 pthread_condattr_t 类型的对象
- attr — 指向待去除初始化的对象。去除初始化后,该 pthread_condattr_t 类型的对象不再可用,不代表任何含义
- 成功返回 0;失败返回非 0 的 errno
5.2.4 设置属性的函数
通过一些函数可以设置 attr 所指对象代表的条件变量属性。详见 man 手册
五、知识重构
5.1 重入
在信号章节,我们曾强调过重入现象(从某函数跳出,再跳回)带来的隐患。但是多线程这部分明明更容易跳来跳去的,为什么我们不再强调重入带来的隐患了呢?
例如三个线程,分别用 puts 向标准输出终端打印连续字符 aaa、bbb 和 ccc,可能出现的情况有:
aaabbbccc aaacccbbb cccbbbaaa // ...但绝对不会出现下面这些情况:
abcabcabc aabbccabc // ...
因为我们用到的很多函数本身就支持多线程并发!比如标准 IO 中的很多函数内部其实都对操作缓冲区的代码段上了锁,因此我们可以放心地在并发代码中使用这些标准 IO 函数。我们称这种函数是线程安全的
当然,也存在线程不安全的 IO 调用,当考虑到效率问题(省去加锁和解锁的时间),并且确保只有单线程操作缓冲区时,可以使用下面的这些函数,这些函数在后面都加上了 _unlocked,表示内部实现不加锁
#include
int getc_unlocked(FILE *stream);
int getchar_unlocked(void);
int putc_unlocked(int c, FILE *stream);
int putchar_unlocked(int c);
void clearerr_unlocked(FILE *stream);
int feof_unlocked(FILE *stream);
int ferror_unlocked(FILE *stream);
int fileno_unlocked(FILE *stream);
int fflush_unlocked(FILE *stream);
int fgetc_unlocked(FILE *stream);
int fputc_unlocked(int c, FILE *stream);
size_t fread_unlocked(void *ptr, size_t size, size_t n,
FILE *stream);
size_t fwrite_unlocked(const void *ptr, size_t size, size_t n,
FILE *stream);
char *fgets_unlocked(char *s, int n, FILE *stream);
int fputs_unlocked(const char *s, FILE *stream); 5.2 线程与信号
这部分我们对并发—信号的一些知识进行重构
对多线程的进程而言,有进程级别的未决信号集 pending,但没有进程级别的信号屏蔽字 mask。而每个线程都有自己的 pending 和 mask(线程级别)
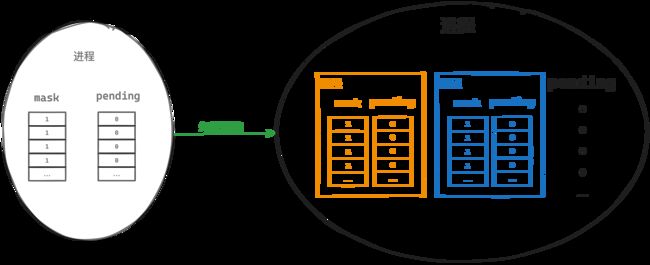
进程向进程发送信号,改变的是进程级别的 pending;线程向线程发送信号,改变的是线程级别的 pending。对于线程级别的信号响应,使用当前线程的 pending 和 mask 进行按位与;对于进程级别的信号响应,使用当前工作线程的 mask 和进程级别的 pending 进行按位与
此前讨论了进程如何使用 sigprocmask 函数来设置信号屏蔽字。然而,sigprocmask 的行为在多线程的进程中并没有定义,线程必须使用 pthread_sigmask 来设置当前线程的信号屏蔽字
#include
// 修改线程级别的信号屏蔽字
int pthread_sigmask(int how, const sigset_t *set, sigset_t *oldset);
// 向指定线程发送信号
int pthread_kill(pthread_t thread, int sig); 虽然我们建议尽量不要在多线程编程阶段大范围混用信号机制,但是这里有一个结合了这两个机制的函数还是挺方便的
man 3 sigwait
#include
int sigwait(const sigset_t *set, int *sig); 功能:等待一个信号
The sigwait() function suspends execution of the calling thread until one of the signals specified in the signal set set becomes pending. The function accepts the signal (removes it from the pending list of signals), and returns the signal number in sig.
5.3 线程与 fork
fork 通过复制进程创建子进程。有些标准下的 fork 是连进程内的所有线程一起复制的;而有些标准下的 fork 仅将调用 fork 的线程复制
这里补充一个函数,也是创建子进程的,但是可以控制子进程复制父进程的哪些部分,哪些又和父进程共享
man 2 clone
#include
int clone(int (*fn)(void *), void *stack, int flags, void *arg, ...
/* pid_t *parent_tid, void *tls, pid_t *child_tid */ ); 与 fork(2) 相比,这些系统调用对调用进程和子进程之间共享哪些执行上下文提供了更精确的控制。例如,通过 clone 系统调用,调用者可以控制两个进程是否共享虚拟地址空间、文件描述符表和信号处理程序等等
六、线程模式
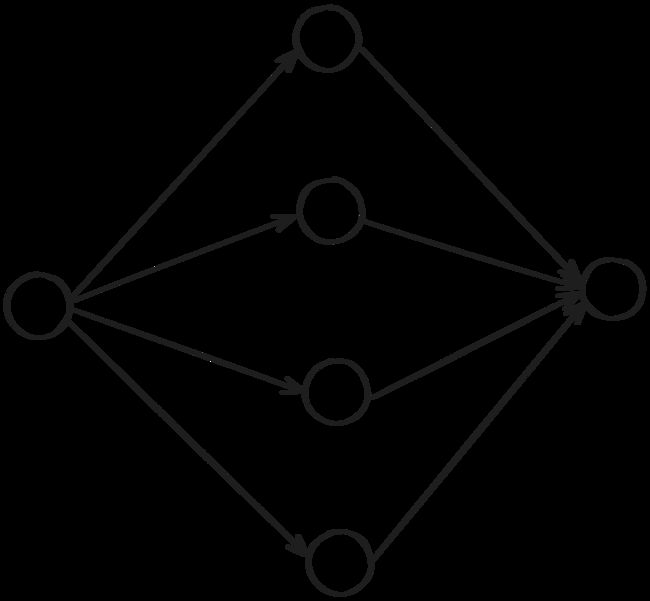
流水线模式:第一个线程做完后第二个线程做,然后第三个线程做......排队做

工作组模式:任务分配,大伙儿一起做,最后任务汇总
C/S 客户端服务器模式:客户端提交任务,服务器执行任务,然后将任务结果返给客户端

七、openmp 标准
openmp 标准不同于 POSIX 线程标准,是一套指导性编译处理方案。OpenMP 支持的编程语言包括 C、C++ 和 Fortran;而支持 OpenMp 的编译器包括 Sun Compiler,GNU Compiler 和 Intel Compiler 等。OpenMp 提供了对并行算法的高层的抽象描述,程序员通过在源代码中加入专用的 pragma 来指明自己的意图,由此编译器可以自动将程序进行并行化,并在必要之处加入同步互斥以及通信。当选择忽略这些 pragma,或者编译器不支持 OpenMp 时,程序又可退化为通常的程序(一般为串行),代码仍然可以正常运作,只是不能利用多线程来加速程序执行
详见 www.openmp.org
示例



真就每章字数越写越多......日均 6000 字了 TAT
今天蓉城主场收官战!!!
准备去看看,毕竟下赛季可能抢不到套票了,就没这么好的位置了
