nodejs+puppeteer爬取淘宝电商产品信息
nodejs+puppeteer爬取电商网站
-
- 1.需求
- 2.实现思路
- 3.安装puppeteer
- 4.实现过程
- 5.遇到的一些问题
- 6.总结
- 7.参考博客
1.需求
需求:前台根据用户从aliexpress关注的产品列表,实时的从1688爬取当前用户关注产品的同款信息。
技术栈: nodeJs,puppeteer
2.实现思路
首先,想要爬取同款商品第一步要知道怎么去找同款,去哪里找。由于我们的项目是针对Aliexpress/1688 的外贸开发人员而设计的,大多数开发人员会从aliexpress上物色产品然后转去1688查找货源。那这要怎么实现?先去爬ali然后再通过爬到的图片自动化按图搜索?那也太麻烦了,要是有一个地方可以输入aliexpress输出1688那就好了。在我头疼的时候师傅仅用了几分钟就丢给我一个网站 : 神秘链接.完美符合我的需求。仔细一想,两家网站都是ali的,做一个这样的平台服务开发人员也是情理之中的。
有了同款,接下来要做的就是去使用puppeteer来抓取同款产品信息了。
3.安装puppeteer
在几个月前才知道强大的js也可以爬虫了,除了puppeteer还有Nightware等,在比较之下还是选择了自己更熟悉一点的puppeteer。
安装有两个选择,puppeteer/puppeteer-core ,前者是基于后者构建的,功能更强大一点。我这里使用的是puppeteer-core,不用重新安装Chromium,会调取本地的Chrome(如果chrom版本太旧不支持会导致无法使用)。
安装方式用npm或者yarn: npm i puppeteer-core
4.实现过程
1.启动无头浏览器
const chromePaths = require('chrome-paths');
const puppeteer = require('puppeteer-core');
puppeteer提供了启动Chromium的方法:
const browser = await puppeteer.launch({
headless: false,//使无头浏览器可见,便于开发过程中观察
args: ['--disable-infobars'],
executablePath: chromePaths.chrome,
});
const page = await browser.newPage();//打开新的空白页
await page.goto('searchUrl', { waitUntil: 'domcontentloaded', timeout: 5000 })//访问页面
进入页面之后更改一下页面的webdriver
阿里云人机检测通过puppeteer的navigator.webdriver,若为true,则判定你为机器人,那么你重复登陆一百遍都不会让你进去。
await page.evaluate(() => {
Object.defineProperty(navigator, 'webdriver', { get: () => false })
})
2.自动登陆
由于大多数网站的登陆框都是iframe内嵌页面,通过当前页去拿iframe里的元素就要先拿到登陆的iframe
const frame = await page.frames().find(frame => !!~frame.url().search("login.taobao"))
提取之后就可以进行自动登陆。
登陆过程:
await page.waitFor("#J_LoginBox")
//由于默认是二维码登陆,这里切换到用密码登录
await frame.click('#J_LoginBox .login-switch')
await frame.waitFor('#J_Form #TPL_username_1')
await frame.type('#J_Form #TPL_username_1', '你的名字', { delay: 50 })
await page.waitFor(500)
await frame.type('#J_Form #TPL_password_1', '你的密码', { delay: 50 })
我们需要对滑块模拟滑动:
let isShow = await frame.$eval('#nocaptcha', el => window.getComputedStyle(el).display != 'none')
console.log('1688 login, verify block show=' + isShow)
if (isShow) {
const verifyBlock = await frame.$('#nc_1_n1z');
if (verifyBlock) {
const box = await verifyBlock.boundingBox()
const initialX = Math.floor(box.x + box.width / 2);
const initialY = Math.floor(box.y + box.height / 2);
for (let i = 0; i < 4; i++) {
await page.waitFor(1000)
this.move(page, initialX, initialY, 310) //自定义的move方法,310可设置随机数,(大于滑动条-滑动框)就好
await page.waitFor(1000)
let errEl = await frame.$('#nocaptcha > div > span')
if (errEl) {
//出错, 将错误重置
await frame.click('#nocaptcha > div > span > a')
await frame.waitFor('#nc_1_n1z')
} else {
let slideEl = await frame.$('#nocaptcha > div')
if (!slideEl) {
//即没有错误, 也没有滑块
break
}
}
}
}
//验证成功
await frame.waitFor('#nocaptcha span[data-nc-lang="_yesTEXT"]')
}
}
await frame.click('#J_SubmitStatic')
}
move方法:
async move(page, initialX, initialY, xlength = 0, ylength = 0) {
const mouse = page.mouse
await mouse.move(initialX, initialY)
await mouse.down()
await mouse.move(initialX + xlength, initialY + ylength, { steps: 20 })
await page.waitFor(2000)
await mouse.up()
}
滑动成功:
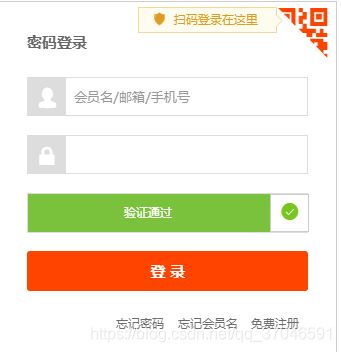
3.爬取页面信息:
const result = await page.evaluate(() => {
const arrList = []
// let i=0
let itemList = document.querySelectorAll('#app > div > div.page-content-wrapper > div.data-wrapper > div > div > div > div:nth-child(1) > ul > li')
for (var element of itemList) {
// if(i>4){
// break;
// }
const List = {}
const name = element.querySelector('div.pull-left > a').innerText
const price = element.querySelector('div.cr-price > em').innerText
const url = element.querySelector('div.image-cell > a').href
const picUrl = element.querySelector('img').src
List.name = name;
List.price = price
List.picUrl = picUrl
List.url = url
arrList.push(List)
}
return arrList;
})
可以看到前台已经抓到了数据(图不对码)
![]()
这样一来就完成了对1688的产品信息的抓取。
5.遇到的一些问题
1.页面加载慢慢慢慢慢慢慢慢慢慢慢慢慢慢慢慢慢慢慢慢慢的问题
也不知道是网速原因还是人品原因,访问太多此后,打开页面就会变得奇卡无比,如果一直卡着就会等啊等啊等,虽然默认30s就会报错推出,但那也是令人折磨的。
解决方案: 更改访问页参数waitUntil,设置timeout时长
await page.goto(searchUrl,{ waitUntil: 'domcontentloaded', timeout: 8000 })
waitUntil有三个参数(API),根据不同的需求选择,我这里用到了domcontentloaded,在dom加载完之后停止页面加载,执行后面的代码。
2.淘宝登陆人机验证
可以说这次研究爬虫一半以上的时间给了这一部分,它也确确实实占了爬虫代码执行时间的一半以上。
首先,要了解阿里登陆人机验证的方式。刚开始几次的模拟登陆不会出现验证码,操作频繁了就会出现滑动滑块也进不去的结果。最初猜测可能和滑动鼠标,输入密码的时间或是轨迹有关,尝试增加鼠标键盘模拟人操作,发现并没有什么用,最重要的是连人工拖动也是一样的结果,那么原因就出来了:问题出现在发送请求的时候。
解决方案
默认的chrome webdriver打开后,navigator.webdriver为true,淘宝人机验证根据这一属性判断你是不是机器人,所以打开页面后手动更改就好。
await frame.evaluate(() => {
Object.defineProperty(navigator, 'webdriver', { get: () => false })
})
除此之外,在输入账户和密码的时候同样得注意等待和延迟,如果太快,一样会被判别为机器人
3.找到/获取frame内元素
关于寻找嵌入页面的iframe,大多数人提供的方式的通过iframe的name:
const frame = await page.frames().find(f => f.name() === 'name');
但是大多数你想找的frame并没有name属性,这时可以通过找到页面其他属性代替name完成定位
const frame = await page.frames() .find(frame => !!~frame.url().search('login.taobao'))//通过frame的url字段搜索
除此之外,还可以通过索引方式定位到你要的frame
const frame = await page.frames()[0]
6.总结
没想到第一次写 “正经” 博客是关于自己不熟悉的爬虫的,但通过这段时间的学习和尝试,也对这一领域有了一定的了解和兴趣。
功能实现过程中还有一些奇奇怪怪的问题,暴露了自己代码不规范,不喜欢读API的毛病,以后一定得多多注意!
7.参考博客
https://juejin.im/post/5c2b201e5188257f9242cf5b
https://yrq110.me/post/front-end/some-tips-of-using-puppetter/
https://github.com/AwesomeCrawler/taobao_login/blob/master/taobao_login.py