几类SQL练习题
目录
- 数据源
- mysql基础语法
-
- 1. 经典用法
- 2. 字段不为空如何表示
- 3. 查同名人数
- 查询日期
-
- 1. 生日算年龄
- 2. 查询下月过生日的学生
- 3. 本周的通用表示
-
- 一类题-下周直接 + 7
- 列转行
-
- 按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
-
- 方法1:group_concat()
- 方法2:拆字段
- 方法3:加字段
- 查询百分比
-
- 查询各科成绩各分数段人数及百分比
- 查询排名
-
- 1. 学生总成绩及排名——成绩一样排名有问题
- 2. 查询所有课程的成绩第2名到第3名的学生信息及该课程成绩——成绩一样会有问题
-
- hive开窗函数——思路对结果未验证
- 小结
- 最值-topN
-
- 1. 查询各科成绩前三名的记录
- 2. 查询选修"张三"老师所授课程的学生中,成绩最高的三个学生信息及其成绩
- others
-
- 1. 查询学过编号为"01"但是没有学过编号为"02"的课程的同学的信息
- 2. 查询和"01"号的同学学习的课程完全相同的其他同学的信息。
- 3. 查询"01"课程比"02"课程成绩高的学生的信息及课程分数
- 4. 查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩——不会
- 总结
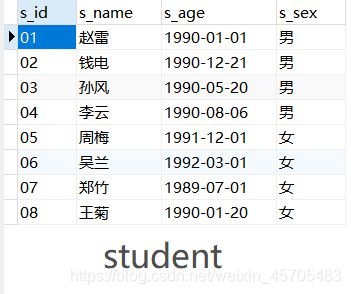
数据源
-- 创建数据库
create database school;
use school;
-- 创建四张表
create table student(
s_id varchar(10),
s_name varchar(20),
s_age date,
s_sex varchar(10)
);
create table course(
c_id varchar(10),
c_name varchar(20),
t_id varchar(10)
);
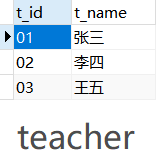
create table teacher(
t_id varchar(10),
t_name varchar(20)
);
create table score(
s_id varchar(10),
c_id varchar(10),
score varchar(10)
);
-- 插入数据
insert into student (s_id, s_name, s_age, s_sex)
values ('01' , '赵雷' , '1990-01-01' , '男'),
('02' , '钱电' , '1990-12-21' , '男'),
('03' , '孙风' , '1990-05-20' , '男'),
('04' , '李云' , '1990-08-06' , '男'),
('05' , '周梅' , '1991-12-01' , '女'),
('06' , '吴兰' , '1992-03-01' , '女'),
('07' , '郑竹' , '1989-07-01' , '女'),
('08' , '王菊' , '1990-01-20' , '女');
insert into course (c_id, c_name, t_id)
values ('01' , '语文' , '02'),
('02' , '数学' , '01'),
('03' , '英语' , '03');
insert into teacher (t_id, t_name)
values ('01' , '张三'),
('02' , '李四'),
('03' , '王五');
insert into score (s_id, c_id, score)
values ('01' , '01' , 80),
('01' , '02' , 90),
('01' , '03' , 99),
('02' , '01' , 70),
('02' , '02' , 60),
('02' , '03' , 80),
('03' , '01' , 80),
('03' , '02' , 80),
('03' , '03' , 80),
('04' , '01' , 50),
('04' , '02' , 30),
('04' , '03' , 20),
('05' , '01' , 76),
('05' , '02' , 87),
('06' , '01' , 31),
('06' , '03' , 34),
('07' , '02' , 89),
('07' , '03' , 98);


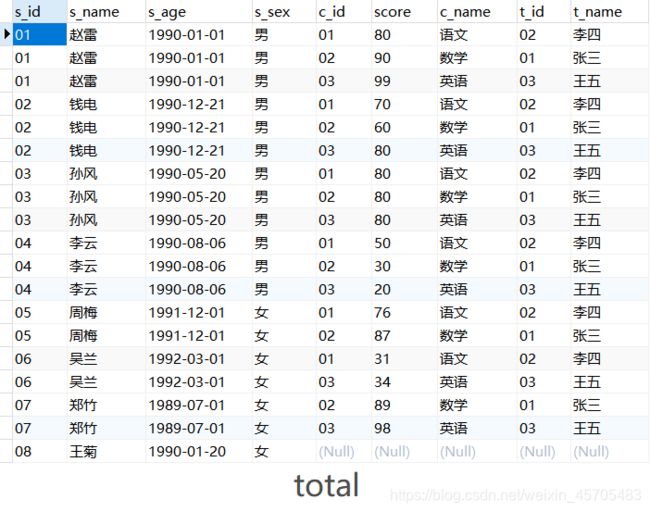
-- 创建一张总表
create table total(
select a.s_id as s_id,a.s_name as s_name,a.s_age as s_age,a.s_sex as s_sex,
b.c_id as c_id,b.score as score,c.c_name as c_name,c.t_id as t_id,d.t_name as t_name
from student a
left join
score b on a.s_id=b.s_id
left join
course c on b.c_id=c.c_id
left join
teacher d on c.t_id=d.t_id
);

mysql基础语法
查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩,结果按平均成绩降序排列,平均成绩相同时,按课程编号,并且只要前三名
1. 经典用法
select
s_id,
s_name,
cast(avg(score) as decimal(5,2)) as avg_score # 注意平均数精确度
from
total
where # 行级过滤
score < 60
group by # 分组
s_id
having # 组级过滤
count(c_id) >= 2
order by # 多字段排序
avg_score desc,
c_id asc
limit
3
;
+------+--------+-----------+
| s_id | s_name | avg_score |
+------+--------+-----------+
| 04 | 李云 | 33.33 |
| 06 | 吴兰 | 32.50 |
+------+--------+-----------+
2 rows in set (0.00 sec)
2. 字段不为空如何表示
-- varchar/char类型的字段不为空的3种表示
where
# c_id is not null
# c_id <> ''
c_id != ''
-- int类型的字段不为空的表示
where
3. 查同名人数
查询同名同姓学生名单,并统计同名人数
-- 方法1
select
s_name,
count(s_id) -1 as 同名人数
from
student
group by
s_name
;
+--------+----------+
| s_name | 同名人数 |
+--------+----------+
| 吴兰 | 0 |
| 周梅 | 0 |
| 孙风 | 0 |
| 李云 | 0 |
| 王菊 | 0 |
| 赵雷 | 0 |
| 郑竹 | 0 |
| 钱电 | 0 |
+--------+----------+
8 rows in set (0.01 sec)
-- 方法2
select
s_name,
s_id,
count(s_id) as 同名人数
from
student
group by
s_name
having
count(s_id) > 1 # 分组后至少有2个人才是同名
;
-- Empty set (0.00 sec)
查询日期
1. 生日算年龄
查询各学生的年龄
-- timestampdiff()
select
s_id,
s_name,
timestampdiff(year,s_age,curdate()) as age
from
student
;
+------+--------+------+
| s_id | s_name | age |
+------+--------+------+
| 01 | 赵雷 | 31 |
| 02 | 钱电 | 30 |
| 03 | 孙风 | 31 |
| 04 | 李云 | 30 |
| 05 | 周梅 | 29 |
| 06 | 吴兰 | 29 |
| 07 | 郑竹 | 32 |
| 08 | 王菊 | 31 |
+------+--------+------+
8 rows in set (0.00 sec)
-- 生日算年龄函数
mysql> help timestampdiff;
Name: 'TIMESTAMPDIFF'
Description:
Syntax:
TIMESTAMPDIFF(unit,datetime_expr1,datetime_expr2)
# 2个日期表达式作差,按照单位unit展示结果
Returns datetime_expr2 - datetime_expr1, where datetime_expr1 and
datetime_expr2 are date or datetime expressions. One expression may be
a date and the other a datetime a date value is treated as a datetime
having the time part '00:00:00' where necessary. The unit for the
result (an integer) is given by the unit argument. The legal values for
unit are the same as those listed in the description of the
TIMESTAMPADD() function.
Examples:
mysql> SELECT TIMESTAMPDIFF(MONTH,'2003-02-01','2003-05-01')
-> 3
mysql> SELECT TIMESTAMPDIFF(YEAR,'2002-05-01','2001-01-01')
-> -1
mysql> SELECT TIMESTAMPDIFF(MINUTE,'2003-02-01','2003-05-01 12:05:55')
-> 128885
URL:mysql日期函数
2. 查询下月过生日的学生
-- way1
select * from student
where month(s_age) = (month(now()) + 1);
-- way2
select * from student
where date_format(s_age,'%m') = (date_format(now(),'%m') + 1);
mysql> select curdate();
+------------+
| curdate() |
+------------+
| 2021-04-28 |
+------------+
1 row in set (0.01 sec)
+------+--------+------------+-------+
| s_id | s_name | s_age | s_sex |
+------+--------+------------+-------+
| 03 | 孙风 | 1990-05-20 | 男 |
+------+--------+------------+-------+
1 row in set (0.00 sec)
3. 本周的通用表示
查询本周过生日的学生
/*
解题思路
本周是?本周通用表示
过生日与否与生日中年份无关,所以生日格式为‘2021-%m-%d’
*/
select
*
from
student
where
date_format(s_age,'2021-%m-%d')
# 一周是周日-周六即0-6
# between and是闭区间,等价于 >= and <=
between adddate(curdate(), -date_format(curdate(),'%w')) # 现在日期 - 现在周几(表示距离周日过了几天)= 周日对应日期
and
adddate(curdate(),6 - date_format(curdate(),'%w')) # 现在日期 + (周日到周六间隔6天,现在周几表示距离周日过了几天,所以现在距离周六还有6 - 周几)
;
-- 插入数据验证,验证之后删除
insert into
student
values
('09','name09','1993-07-11','男'),
('10','name10','1993-07-15','男'),
('12','name12','1993-07-17','woman')
;
+------+--------+------------+-------+
| s_id | s_name | s_age | s_sex |
+------+--------+------------+-------+
| 09 | name09 | 1993-07-11 | 男 |
| 10 | name10 | 1993-07-15 | 男 |
| 12 | name12 | 1993-07-17 | woman |
+------+--------+------------+-------+
3 rows in set (0.01 sec)
一类题-下周直接 + 7
查询下周过生日的学生
/* 解题思路
this week is 2021-04-17 and 2021-04-23
next week is 2021-04-24 and 2021-05-30
*/
select
*
from
student
where
date_format(s_age,'2021-%m-%d')
between adddate(curdate(),7 - date_format(now(),'%w'))
and
adddate(curdate(),13 - date_format(now(),'%w'));
列转行
按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
方法1:group_concat()
-- 显示出学生相关的信息
select
student.*,
group_concat(c_id) as c_id, -- 返回组内非空记录
group_concat(score) as score,
cast(avg(score) as decimal(5,2)) as avg_score
from
student
left join
score
on
student.s_id = score.s_id
group by
student.s_id
order by
avg_score desc
;
+------+--------+------------+-------+----------+----------+-----------+
| s_id | s_name | s_age | s_sex | c_id | score | avg_score |
+------+--------+------------+-------+----------+----------+-----------+
| 07 | 郑竹 | 1989-07-01 | 女 | 02,03 | 89,98 | 93.50 |
| 01 | 赵雷 | 1990-01-01 | 男 | 01,03,02 | 80,99,90 | 89.67 |
| 05 | 周梅 | 1991-12-01 | 女 | 02,01 | 87,76 | 81.50 |
| 03 | 孙风 | 1990-05-20 | 男 | 03,02,01 | 80,80,80 | 80.00 |
| 02 | 钱电 | 1990-12-21 | 男 | 03,02,01 | 80,60,70 | 70.00 |
| 04 | 李云 | 1990-08-06 | 男 | 03,02,01 | 20,30,50 | 33.33 |
| 06 | 吴兰 | 1992-03-01 | 女 | 03,01 | 34,31 | 32.50 |
| 08 | 王菊 | 1990-01-20 | 女 | NULL | NULL | NULL |
+------+--------+------------+-------+----------+----------+-----------+
8 rows in set (0.01 sec)
方法2:拆字段
-- 拆字段
-- 问题:科目用SQL写出来
select
student.*,
sum(case when c_id = '01' then score else 0 end) as '语文', -- 此处'语文'字段的值只能是一个,我判断完之后会有三个值:判断语文拿到80 ==> 判断数学拿到0 ==> 判断英语拿到0
sum(case when c_id = '02' then score else 0 end) as '数学',
sum(case when c_id = '03' then score else 0 end) as '英语',
cast(avg(score) as decimal(5,2)) as avg_score
from
student
left join
score
on student.s_id = score.s_id
group by
student.s_id
order by
avg_score desc
;
+------+--------+------------+-------+------+------+------+-----------+
| s_id | s_name | s_age | s_sex | 语文 | 数学 | 英语 | avg_score |
+------+--------+------------+-------+------+------+------+-----------+
| 07 | 郑竹 | 1989-07-01 | 女 | 0 | 89 | 98 | 93.50 |
| 01 | 赵雷 | 1990-01-01 | 男 | 80 | 90 | 99 | 89.67 |
| 05 | 周梅 | 1991-12-01 | 女 | 76 | 87 | 0 | 81.50 |
| 03 | 孙风 | 1990-05-20 | 男 | 80 | 80 | 80 | 80.00 |
| 02 | 钱电 | 1990-12-21 | 男 | 70 | 60 | 80 | 70.00 |
| 04 | 李云 | 1990-08-06 | 男 | 50 | 30 | 20 | 33.33 |
| 06 | 吴兰 | 1992-03-01 | 女 | 31 | 0 | 34 | 32.50 |
| 08 | 王菊 | 1990-01-20 | 女 | 0 | 0 | 0 | NULL |
+------+--------+------------+-------+------+------+------+-----------+
8 rows in set (0.00 sec)
方法3:加字段
-- 方法3:加字段
select
s.*,
a.score_01 as score_01,
b.score_02 as score_02,
c.score_03 as score_03,
d.avg_score as avg_score
from
student s
left join -- 给student表加01成绩
(
select
s_id,
score as score_01
from
score
where
c_id = '01'
) a
on
s.s_id = a.s_id
left join -- 给student表加02成绩
(
select
s_id,
score as score_02
from
score
where
c_id = '02'
) b
on
s.s_id = b.s_id
left join -- 给student表加03成绩
(
select
s_id,
score as score_03
from
score
where
c_id = '03'
) c
on
s.s_id = c.s_id
left join -- 给student表加平均成绩
(
select
s_id,
cast(avg(score) as decimal(5,2)) as avg_score
from
score
group by
s_id
) d
on
s.s_id = d.s_id
order by
avg_score desc
;
+------+--------+------------+-------+----------+----------+----------+-----------+
| s_id | s_name | s_age | s_sex | score_01 | score_02 | score_03 | avg_score |
+------+--------+------------+-------+----------+----------+----------+-----------+
| 07 | 郑竹 | 1989-07-01 | 女 | NULL | 89 | 98 | 93.50 |
| 01 | 赵雷 | 1990-01-01 | 男 | 80 | 90 | 99 | 89.67 |
| 05 | 周梅 | 1991-12-01 | 女 | 76 | 87 | NULL | 81.50 |
| 03 | 孙风 | 1990-05-20 | 男 | 80 | 80 | 80 | 80.00 |
| 02 | 钱电 | 1990-12-21 | 男 | 70 | 60 | 80 | 70.00 |
| 04 | 李云 | 1990-08-06 | 男 | 50 | 30 | 20 | 33.33 |
| 06 | 吴兰 | 1992-03-01 | 女 | 31 | NULL | 34 | 32.50 |
| 08 | 王菊 | 1990-01-20 | 女 | NULL | NULL | NULL | NULL |
+------+--------+------------+-------+----------+----------+----------+-----------+
8 rows in set (0.00 sec)
查询百分比
查询各科成绩各分数段人数及百分比
以如下形式显示:课程ID,课程name,最高分,最低分,平均分,
及格为>=60,中等为:70-80,优良为:80-90,优秀为:>=90
-- 做标记-统计个数-算百分比
select
a.c_id as '课程ID',
a.c_name as '课程name',
max(a.score) as 最高分,
min(a.score) as 最低分,
cast(avg(a.score) as decimal(5,2)) as 平均分,
-- 执行sum之前已经分组,所以sum是组内sum;同理,count是组内count
sum(a.pass) as '>=60',
concat(cast(sum(a.pass) / count(a.score) * 100 as decimal(5,2)),'%') as '及格率',
sum(a.medium) as '70-80',
concat(cast(sum(a.medium) / count(a.score) * 100 as decimal(5,2)),'%') as '中等率',
sum(a.good) as '80-90',
concat(cast(sum(a.good) / count(a.score) * 100 as decimal(5,2)),'%') as '优良率',
sum(a.excellent) as '>=90',
concat(cast(sum(a.excellent) / count(a.score) * 100 as decimal(5,2)),'%') as '优秀率'
from
(-- 对score做标记
select
*,
case when score >= 60 then 1 else 0 end as pass,
case when score >= 70 and score < 80 then 1 else 0 end as medium,
case when score >= 80 and score < 90 then 1 else 0 end as good,
case when score >= 90 then 1 else 0 end as excellent
from
total
) a
where
a.c_id is not null
group by
a.c_id
;
-- 字符串函数 CONCAT(str1,str2,...) 返回连接的字符串
Examples:
mysql> SELECT CONCAT('My', 'S', 'QL')
-> 'MySQL'
mysql> SELECT CONCAT('My', NULL, 'QL')
-> NULL
mysql> SELECT CONCAT(14.3)
-> '14.3'
SELECT CONCAT(CAST(int_col AS CHAR), char_col)
CONCAT() returns NULL if any argument is NULL.
URL: mysql字符串函数
+--------+----------+--------+--------+--------+------+--------+-------+--------+-------+--------+------+--------+
| 课程ID | 课程name | 最高分 | 最低分 | 平均分 | >=60 | 及格率 | 70-80 | 中等率 | 80-90 | 优良率 | >=90 | 优秀率 |
+--------+----------+--------+--------+--------+------+--------+-------+--------+-------+--------+------+--------+
| 01 | 语文 | 80 | 31 | 64.50 | 4 | 66.67% | 2 | 33.33% | 2 | 33.33% | 0 | 0.00% |
| 02 | 数学 | 90 | 30 | 72.67 | 5 | 83.33% | 0 | 0.00% | 3 | 50.00% | 1 | 16.67% |
| 03 | 英语 | 99 | 20 | 68.50 | 4 | 66.67% | 0 | 0.00% | 2 | 33.33% | 2 | 33.33% |
+--------+----------+--------+--------+--------+------+--------+-------+--------+-------+--------+------+--------+
3 rows in set (0.00 sec)
查询排名
1. 学生总成绩及排名——成绩一样排名有问题
/* 变量格式 @变量名:=
Examples:
@rank:=
或
@asdf:=
*/
select
a.s_name as s_name,
a.s_id as s_id,
a.s_age as s_age,
a.s_sex as s_sex,
a.sum_score as sum_score,
@rank:= @rank + 1 as rank -- 将a表中的排序显示出排名
from
(-- 排序,只不过是没有显示排名
select
*,
sum(score) as sum_score
from
total
group by
s_id
order by
sum_score desc
) a,
(-- a表加字段@rank:= 0;该列都是0
select
@rank:= 0
) b
;
+--------+------+------------+-------+-----------+------+
| s_name | s_id | s_age | s_sex | sum_score | rank |
+--------+------+------------+-------+-----------+------+
| 赵雷 | 01 | 1990-01-01 | 男 | 269 | 1 |
| 孙风 | 03 | 1990-05-20 | 男 | 240 | 2 |
| 钱电 | 02 | 1990-12-21 | 男 | 210 | 3 |
| 郑竹 | 07 | 1989-07-01 | 女 | 187 | 4 |
| 周梅 | 05 | 1991-12-01 | 女 | 163 | 5 |
| 李云 | 04 | 1990-08-06 | 男 | 100 | 6 |
| 吴兰 | 06 | 1992-03-01 | 女 | 65 | 7 |
| 王菊 | 08 | 1990-01-20 | 女 | NULL | 8 |
+--------+------+------------+-------+-----------+------+
8 rows in set (0.00 sec)
2. 查询所有课程的成绩第2名到第3名的学生信息及该课程成绩——成绩一样会有问题
-- 没有分组,可以直接内层加变量。
select student.*,b.c_id,b.score
from
(
select sc.*,@rank:= @rank + 1 as rank
from score sc,(select @rank:= 0) a
where sc.c_id = '01'
order by score desc
) b
left join student
on student.s_id = b.s_id
where rank between 2 and 3
union
select student.*,b.c_id,b.score
from
(
select sc.*,@rank:= @rank + 1 as rank
from score sc,(select @rank:= 0) a
where sc.c_id = '02'
order by score desc
) b
left join student
on student.s_id = b.s_id
where rank between 2 and 3
union
select student.*,b.c_id,b.score
from
(
select sc.*,@rank:= @rank + 1 as rank
from score sc,(select @rank:= 0) a
where sc.c_id = '03'
order by score desc
) b
left join student
on student.s_id = b.s_id
where rank between 2 and 3
;
+------+--------+------------+-------+------+-------+
| s_id | s_name | s_age | s_sex | c_id | score |
+------+--------+------------+-------+------+-------+
| 03 | 孙风 | 1990-05-20 | 男 | 01 | 80 |
| 05 | 周梅 | 1991-12-01 | 女 | 01 | 76 |
| 07 | 郑竹 | 1989-07-01 | 女 | 02 | 89 |
| 05 | 周梅 | 1991-12-01 | 女 | 02 | 87 |
| 07 | 郑竹 | 1989-07-01 | 女 | 03 | 98 |
| 02 | 钱电 | 1990-12-21 | 男 | 03 | 80 |
+------+--------+------------+-------+------+-------+
6 rows in set (0.00 sec)
-- 肯定没问的写法:外层加变量
select c_id,rank,score,s_name,c.s_id,s_age,s_sex
from
(select c_id,s_id,score,@rank:= @rank + 1 rank
from
(select *
from score
where c_id = '01'
order by score desc) a,
(select @rank:= 0) b) c
left join student on c.s_id = student.s_id
where rank between 2 and 3
union
select c_id,rank,score,s_name,c.s_id,s_age,s_sex
from
(select c_id,s_id,score,@rank:= @rank + 1 rank
from
(select *
from score
where c_id = '02'
order by score desc) a,
(select @rank:= 0) b) c
left join student on c.s_id = student.s_id
where rank between 2 and 3
union
select c_id,rank,score,s_name,c.s_id,s_age,s_sex
from
(select c_id,s_id,score,@rank:= @rank + 1 rank
from
(select *
from score
where c_id = '03'
order by score desc) a,
(select @rank:= 0) b) c
left join student on c.s_id = student.s_id
where rank between 2 and 3
;
+------+------+-------+--------+------+------------+-------+
| c_id | rank | score | s_name | s_id | s_age | s_sex |
+------+------+-------+--------+------+------------+-------+
| 01 | 2 | 80 | 孙风 | 03 | 1990-05-20 | 男 |
| 01 | 3 | 76 | 周梅 | 05 | 1991-12-01 | 女 |
| 02 | 2 | 89 | 郑竹 | 07 | 1989-07-01 | 女 |
| 02 | 3 | 87 | 周梅 | 05 | 1991-12-01 | 女 |
| 03 | 2 | 98 | 郑竹 | 07 | 1989-07-01 | 女 |
| 03 | 3 | 80 | 钱电 | 02 | 1990-12-21 | 男 |
+------+------+-------+--------+------+------------+-------+
6 rows in set (0.00 sec)
hive开窗函数——思路对结果未验证
-- hive开窗函数
select
student.*,
c_id,
score
from
student
left join
(
select
s_id,
c_id,
score,
dense_rank() over (partition by c_id order by score desc) as rank
from
score
) a
on student.s_id = a.s_id
where
rank between 2 and 3
;
小结
查排名
- 排序
- 关联变量表
- 变量自加一显示出排名
并列成绩排名未解决
最值-topN
1. 查询各科成绩前三名的记录
-- 求top3——用topN万能公式
select
a.c_name,
a.c_id,
a.s_id,
a.score
from
total a
where
3 >
(
select
count(distinct(score))
from
score
where
score > a.score and c_id = a.c_id
)
and c_name <> ''
order by #为了查看方便
c_id,
score desc
;
+--------+------+------+-------+
| c_name | c_id | s_id | score |
+--------+------+------+-------+
| 语文 | 01 | 01 | 80 |
| 语文 | 01 | 03 | 80 |
| 语文 | 01 | 05 | 76 |
| 语文 | 01 | 02 | 70 |
| 数学 | 02 | 01 | 90 |
| 数学 | 02 | 07 | 89 |
| 数学 | 02 | 05 | 87 |
| 英语 | 03 | 01 | 99 |
| 英语 | 03 | 07 | 98 |
| 英语 | 03 | 02 | 80 |
| 英语 | 03 | 03 | 80 |
+--------+------+------+-------+
11 rows in set (0.00 sec)
2. 查询选修"张三"老师所授课程的学生中,成绩最高的三个学生信息及其成绩
-- 方法1——topN公式
select
*
from
total a
where
a.t_name = '张三'
and
3 >
(
select
count(distinct(score))
from
total
where
t_name = a.t_name
and score > a.score
)
order by #为了查看方便
score desc
;
+------+--------+------------+-------+------+-------+--------+------+--------+
| s_id | s_name | s_age | s_sex | c_id | score | c_name | t_id | t_name |
+------+--------+------------+-------+------+-------+--------+------+--------+
| 01 | 赵雷 | 1990-01-01 | 男 | 02 | 90 | 数学 | 01 | 张三 |
| 07 | 郑竹 | 1989-07-01 | 女 | 02 | 89 | 数学 | 01 | 张三 |
| 05 | 周梅 | 1991-12-01 | 女 | 02 | 87 | 数学 | 01 | 张三 |
+------+--------+------------+-------+------+-------+--------+------+--------+
3 rows in set (0.00 sec)
others
1. 查询学过编号为"01"但是没有学过编号为"02"的课程的同学的信息
select
*
from
student
where
s_id in (select s_id from score where c_id = '01')
and
s_id not in (select s_id from score where c_id = '02')
;
+------+--------+------------+-------+
| s_id | s_name | s_age | s_sex |
+------+--------+------------+-------+
| 06 | 吴兰 | 1992-03-01 | 女 |
+------+--------+------------+-------+
1 row in set (0.00 sec)
2. 查询和"01"号的同学学习的课程完全相同的其他同学的信息。
-- 方法1
select
s_id,
s_name,
s_age,
s_sex
from
total
where
s_id <> '01'
and
c_id in
(
select
c_id
from
score
where
s_id = '01'
)
# 以上是和"01"号的同学学习的课程至少一门相同的其他同学的信息
# 以下过滤出与01号同学门数相同的其他同学
group by
s_id
having
count(c_id) = (select count(c_id) from score where s_id = '01')
;
-- 方法2
select
*
from
student
where
s_id in
(select s_id from # 学过01号同学课程的s_id
(
select
score.s_id,
a.c_id
from
(select c_id from score where s_id='01') a -- 只有c_id一个字段
inner join score -- 内连接加入了score表中所有字段
on a.c_id=score.c_id
) b
where
s_id<>'01' # 去掉01号自己
group by
s_id
having # 学过的门数相同
count(c_id) = (select count(c_id) from score where s_id='01'))
;
+------+--------+------------+-------+
| s_id | s_name | s_age | s_sex |
+------+--------+------------+-------+
| 02 | 钱电 | 1990-12-21 | 男 |
| 03 | 孙风 | 1990-05-20 | 男 |
| 04 | 李云 | 1990-08-06 | 男 |
+------+--------+------------+-------+
3 rows in set (0.00 sec)
3. 查询"01"课程比"02"课程成绩高的学生的信息及课程分数
select
student.*,
a.c_id as c_01,
a.score as score,
b.c_id as c_02,
b.score as score
from
(-- 01分数
select
s_id,
c_id,
score
from
score
where
c_id = '01'
) a
inner join
(-- 02分数
select
s_id,
c_id,
score
from
score
where
c_id = '02'
) b
on a.score > b.score
inner join
student
on a.s_id = student.s_id
;
+------+--------+------------+-------+------+-------+------+-------+
| s_id | s_name | s_age | s_sex | c_01 | score | c_02 | score |
+------+--------+------------+-------+------+-------+------+-------+
| 01 | 赵雷 | 1990-01-01 | 男 | 01 | 80 | 02 | 60 |
| 01 | 赵雷 | 1990-01-01 | 男 | 01 | 80 | 02 | 30 |
| 02 | 钱电 | 1990-12-21 | 男 | 01 | 70 | 02 | 60 |
| 02 | 钱电 | 1990-12-21 | 男 | 01 | 70 | 02 | 30 |
| 03 | 孙风 | 1990-05-20 | 男 | 01 | 80 | 02 | 60 |
| 03 | 孙风 | 1990-05-20 | 男 | 01 | 80 | 02 | 30 |
| 04 | 李云 | 1990-08-06 | 男 | 01 | 50 | 02 | 30 |
| 05 | 周梅 | 1991-12-01 | 女 | 01 | 76 | 02 | 60 |
| 05 | 周梅 | 1991-12-01 | 女 | 01 | 76 | 02 | 30 |
| 06 | 吴兰 | 1992-03-01 | 女 | 01 | 31 | 02 | 30 |
+------+--------+------------+-------+------+-------+------+-------+
10 rows in set (0.00 sec)
4. 查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩——不会
-- step1
select a.s_id as s_id_a,b.s_id as s_id_b,
a.c_id as c_id_a,b.c_id as c_id_b,b.score as score_b
from score a,score b
where a.score = b.score and a.c_id != b.c_id
order by b.s_id
;
+--------+--------+--------+--------+---------+
| s_id_a | s_id_b | c_id_a | c_id_b | score_b |
+--------+--------+--------+--------+---------+
| 03 | 01 | 03 | 01 | 80 |
| 03 | 01 | 02 | 01 | 80 |
| 02 | 01 | 03 | 01 | 80 |
| 03 | 02 | 02 | 03 | 80 |
| 03 | 02 | 01 | 03 | 80 |
| 01 | 02 | 01 | 03 | 80 |
| 01 | 03 | 01 | 03 | 80 |
| 02 | 03 | 03 | 02 | 80 |
| 03 | 03 | 02 | 01 | 80 |
| 03 | 03 | 02 | 03 | 80 |
| 03 | 03 | 03 | 02 | 80 |
| 01 | 03 | 01 | 02 | 80 |
| 02 | 03 | 03 | 01 | 80 |
| 03 | 03 | 01 | 03 | 80 |
| 03 | 03 | 01 | 02 | 80 |
| 03 | 03 | 03 | 01 | 80 |
+--------+--------+--------+--------+---------+
16 rows in set (0.00 sec)
-- step2
select distinct(b.s_id) as s_id_b,
b.c_id as c_id_b,b.score as score_b
from score a,score b
where a.score = b.score and a.c_id <> b.c_id
;
| s_id_b | c_id_b | score_b |
+--------+--------+---------+
| 01 | 01 | 80 |
| 02 | 03 | 80 |
| 03 | 01 | 80 |
| 03 | 02 | 80 |
| 03 | 03 | 80 |
+--------+--------+---------+
5 rows in set (0.00 sec)
总结
查询排名有问题
查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩——不会
hive开窗函数——思路对结果未验证