正点原子嵌入式linux驱动开发——Linux C编程入门
这一章,主要是利用Ubuntu自带的vi来编写简单代码,这一章如果对原理不是很感兴趣,可以自己直接搜一搜,配一个VSCode写代码就可以了。
1.编写简单代码
Hello World!
可以先mkdir一个C_Program的文件夹,来管理所有的代码;然后每一次编写的代码可以再次编写在一个C_Program文件夹中的子文件夹,方便管理。
可以通过以下命令,打开文件 /etc/vim/vimrc设置tab为4格,以及让VIM显示行号:
| sudo gedit /etc/vim/vimrc.local |
| set ts=4 |
| set nu |
以上设置之后,就可以书写经典代码“Hello World!”,用vi创建一个main.c,内容如下所示:
#include 然后可以用cat命令来查看,如下图所示:

编译代码
Ubuntu下的 C语言编译器是 GCC,Ubuntu18默认没有安装 GCC工具,因此需要我们手动安装 gcc、 g++、 make等工具,这里我们直接安装 build-essential软件包即可, build-essential提供了编译程序所需的所有软件包,输入如下命令:
| sudo apt-get install build-essential |
| gcc -v |
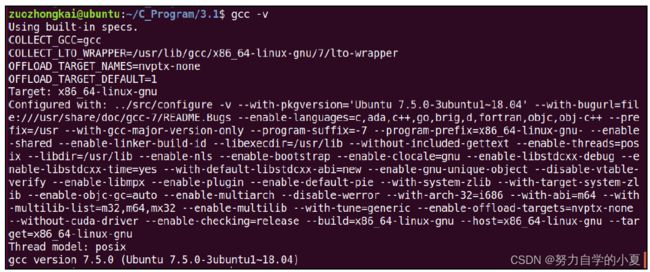
最后下面的“ gcc version 7.5.0”说明本机的 GCC编译器版本为 7.5.0的。注意观察在图中有“ Target: x86_64-linux-gnu”一行,这说明这个GCC编译器是针对X86架构的,因此只能编译在X86架构CPU上运行的程序。如果想要编译在 ARM上运行的程序就需要针对 ARM的GCC编译器,也就是交叉编译器!当前我们需要知道的就是不同的目标架构,其 GCC编译器是不同的。
如何使用GCC编译器来编译 main.c文件呢? GCC编译器是命令模式的,因此需要输入命令来使用 gcc编译器来编译文件,输入如下命令:
| gcc main.c |

2.GCC编译器
gcc命令
gcc命令格式如下:
| gcc [选项 ] [文件名字 ] |
- -c:只编译不链接为可执行文件,编译器将输入的 .c文件编译为 .o的目标文件;
- -o:<输出文件名 > 用来指定编译结束以后的输出文件名,如果使用这个选项的话GCC默认编译出来的可执行文件名字为 a.out;
- -g 添加调试信息,如果要使用调试工具 (如GDB)的话就必须加入此选项,此选项指示编译的时候生成调试所需的符号信息;
- -O:对程序进行优化编译,如果使用此选项的话整个源代码在编译、链接的的时候都会进行优化,这样产生的可执行文件执行效率就高;
- -O2 比 -O更幅度更大的优化,生成的可执行效率更高,但是整个编译过程会很慢。
编译错误警告
我们可以编写一段示例代码来展示GCC的错误警告:

在上述代码中有两处错误:
- 第8行、第一处是“ b=4”少写了个一个“;”号;
- 第9行、第二处应该是 printf(“a+b=%d\n”, a + b)。
编译后就会发现gcc编译器会有错误提示如下:

根据编译后的结果,找到对应的错误并修改就可以了。
编译流程
GCC编译器的编译流程是:预处理、编译、汇编和链接。预处理就是展开所有的头文件、替换程序中的宏、解析条件编译并添加到文件中;编译是将经过预编译处理的代码编译成汇编代码,也就是我们常说的程序编译;汇编就是将汇编语言文件编译成二进制目标文件;链接就是将汇编出来的多个二进制目标文件链接在一起,形成最终的可执行文件,链接的时候还会涉及到静态库和动态库等问题。
3.Makefile基础
如果有多个文件,那么全部手动gcc是不现实的。**如果我们能够编写一个文件,这个文件描述了编译哪些源码文件、如何编译那就好,每次需要编译工程的时只需要使用这个文件就行了。**为此提出了一个解决大工程编译的工具:make,描述哪些文件需要编译、哪些需要重新编译的文件就叫Makefile。
Makefile就跟脚本文件一样, Makefile里面还可以执行系统命令。使用的时候只需要一个make命令即可完成整个工程的自动编译,极大的提高了软件开发的效率。在Linux下用的最多的是 GCC编译器,这是个没有UI的编译器,因此 Makefile就需要我们自己来编写了。作为一个专业的程序员,是一定要懂得Makefile的,一是因为在 Linux下你不得不懂 Makefile,再就是通过 Makefile你就能了解整个工程的处理过程。
Makefile引入
我们完成这样一个小工程,通过键盘输入两个整形数字,然后计算他们的和并将结果显示在屏幕上,在这个工程中我们有 main.c、 input.c和 calcu.c这三个 C文件和 input.h、 calcu.h这两个头文件。其中 main.c是主体, input.c负责接收从键盘输入的数值, calcu.h进行任意两个数相加,文件内容如下:





通过gcc也可以直接手动编译,但是会碰到如下问题:
有一个文件经过修改,如果在按照命令编译,就会使得这些全部再次编译,极度耗时;
当然也可以先单独编译再链接,如下所示:
| gcc main.c gcc -c input.c gcc -c calcu.c gcc main.o input.o calcu.o -o main |
| gcc -c calcu.c gcc main.o input.o calcu.o -o main |
为此我们需要这样一个工具:
- 如果工程没有编译过,那么工程中的所有 .c文件都要被编译并且链接成可执行程序;
- 如果工程中只有个别C文件被修改了,那么只编译这些被修改的C文件即可;
- 如果工程的头文件被修改了,那么我们需要编译所有引用这个头文件的C文件,并且链接成可执行文件。
这就是Makefile的作用,在工程目录下创建名为 “Makefile”的文件,**文件名一定要叫做“Makefile”!!!区分大小写!**如图所示:

Makefile需要和C文件在一个文件夹下:

Makefile写完之后,直接在命令行中输入“make”就可以编译了,如下所示:

当然也有可能编译失败,如下图所示:
![]()
图中的错误来源一般有两点 :
- Makefile中命令缩进没有使用 TAB键!
- VI/VIM编辑器使用空格代替了TAB键,修改文件 /etc/vim/vimrc,在文件最后面加上如
下所示代码:set noexpandtab 即可完成。
如果修改input.c,然后重新编译,就会如下图所示:

可以看出,除了修改过的input.c,另外两个文件就没有在重复编译了。
4. Makefile语法
Makefile语法规则
Makefile里面是由一系列的规则组成的,这些规则格式如下:
| 目标 ……... : 依赖文件集合 命令 1 命令 2 …… |
比如下面这条规则:
| main : main.o input.o calcu.o gcc -o main main.o input.o calcu.o |
这条规则的目标是main,main.o、input.o和calcu.o是生成main的依赖文件,如果要更新目标 main,就必须先更新它的所有依赖文件,如果依赖文件中的任何一个有更新,那么目标也必须更新,“更新”就是执行一遍规则中的命令列表。
命令列表中的每条命令必须以TAB键开始,不能使用空格!
make命令会为Makefile中的每个以 TAB开始的命令创建一个 Shell进程去执行。
例如如下的Makefile代码:

上述代码中一共有5条规则,1-2行为第一条规则,3-4行为第二条规则, 5-6行为第三条规则,7-8行为第四条规则,10-12为第五条规则, make命令在执行这个 Makefile的时候其执行步骤如下:
首先更新第一条规则中的main,第一条规则的目标成为默认目标,只要默认目标更新了那么就认为Makefile的工作,完成了整个Makefile就是为了完成这个工作。在第一次编译的时候由于main还不存在,因此第一条规则会执行,第一条规则依赖于文件main.o、input.o和 calcu.o这个三个.o件,这三个.o文件目前还都没有,因此必须先更新这三个文件。make会查找以这三个 .o文件为目标的规则并执行。
最后一个规则目标是clean,它没有依赖文件因此会默认为依赖文件都是最新的,所以其对应的命令不会执行,当我们想要执行 clean的话可以直接使用命令“ make clean”,执行以后就会删除当前目录下所有的 .o文件以及main,因此clean的功能就是完成工程的清理。
总结一下 Make的执行过程:
- make命令会在当前目录下查找以 Makefile(makefile其实也可以 )命名的文件;
- 当找到 Makefile文件以后就会按照 Makefile中定义的规则去编译生成最终的目标文件;
- 当发现目标文件不存在,或者目标所依赖的文件比目标文件新 (也就是最后修改时间比目标文件晚 )的话就会执行后面的命令来更新目标。
make工具就是在Makefile中一层一层的查找依赖关系,并执行相应的命令,编译出最终的可执行文件。 Makefile的好处就是**“自动化编译”,一旦写好了 Makefile文件,以后只需要一个 make命令即可完成整个工程的编译**,极大的提高了开发效率。正点原子的文档之中有一个非常形象的比喻图,如下所示:
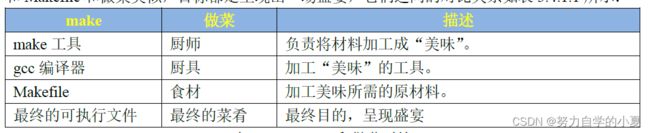
总结一下, Makefile中规则用来描述在什么情况下使用什么命令来构建一个特定的文件,这个文件就是规则的“目标”,为了生成这个“目标”而作为材料的其它文件称为“目标”的依赖,规则的命令是用来创建或者更新目标的。
除了 Makefile的“终极目标”所在的规则以外,其它规则的顺序在 Makefile中是没有意义的,“终极目标”就是指在使用 make命令的时候没有指定具体的目标时, make默认的那个目标,它是Makefile文件中第一个规则的目标,如果 Makefile中的第一个规则有多个目标,那么这些目标中的第一个目标就是 make的“终极目标”。
Makefile变量
如上面的例子,出于简化的目的,可以改成如下所示:

第1行是注释,Makefile中可以写注释,注释开头要用符号“ “#”;第 2行我们定义了一个变量 objects,并且给这个变量进行了赋值,其值为字符串“ main.o input.o calcu.o”,第3和4行使用到了变量 objects,Makefile中变量的引用方法是“ “$(变量名)”,比如本例中的 “$(objects)”就是使用变量objects。
赋值赋“=”
使用“=”在给变量的赋值的时候,不一定要用已经定义好的值,也可以使用后面定义的值。如下所示:

以上代码,第1行定义了一个变量name,变量值为“zzk”,第2行也定义
了一个变量curname,curname的变量值引用了变量name;第3行将变量name的值改为了“zuozhongkai”,第 5、6行是输出变量curname的值。在 Makefile要输出一串字符的话使用“ echo”,就和C语言中的“printf”一样,第6行中的“ echo”前面加了个 “@”符号,因为Make在执行的过程中会自动输出命令执行过程,在命令前面加上““@”的话就不会输出命令执行过程。使用命令“make print”来执行上述代码,结果如图:

可以看出,对于“=”而言,变量的真实值取决于它所引用的变量的最后一 次有效值。
赋值符“:=”
赋值符“:=”不会使用后面定义的变量,只能使用前面已经定义好的,这就是“:=”和“=”的区别。
赋值符“?=”
使用此赋值符“?=”,如果变量前面没有被赋值,那么此变量就是现在所给的值;如果前面已经赋过值了,那么就使用前面赋的值。
变量追加“+=”
这个就跟C中的是一样的使用方法。
Makefile模式规则
如果.c文件很多,用之前的一行一行来转换就很麻烦,这时候就可以用之前的替代方法来进行编译,通过模式规则我们就可以使用一条规则来将所有的 .c文件编译为对应的 .o文件。
模式规则中,至少在规则的目标定定义中要包涵“ “%”,否则就是一般规则,目标中的“%”表示对文件名的匹配,“%”表示长度任意的非空字符串,比如 “%.c”就是所有的以 .c结尾的文件,类似与通配符, a.%.c就表示以 a.开头,以 .c结束的所有文件。
当“%”出现在目标中的时候,目标中“%”所代表的值决定了依赖中的 “%值。
Makefile自动化变量
所谓自动化变量就是这种变量会把模式中所定义的一系列的文件自动的挨个取出,直至所有的符合模式的文件都取完,自动化变量只应该出现在规则的命令中,常用的自动化变量如下图所示:

7个自动化变量中,常用的三种:$@、 $<和 $^,我们使用自动化变量来完成之前的Makefile就会变成如下所示:

Makefile伪目标
Makefile有一种特殊的目标:伪目标,一般的目标名都是要生成的文件,而伪目标不代表真正的目标名,在执行make命令的时候通过指定这个伪目标来执行其所在规则的定义的命令。
使用伪目标的主要是为了避免 Makefile中定义的只执行命令的目标和工作目录下的实际文件出现名字冲突,有时候我们需要编写一个规则用来执行一些命令,但是这个规则不是用来创建文件的。
就比如我们之前的clean,上述规则中并没有创建文件clean的命令,因此工作目录下永远都不会存在文件 clean,*当我们输入“make clean”以后,后面的 rm .o”和 rm main”总是会执行。可是如果我们“手贱”,在工作目录下创建一个名为“ clean”的文件,那就不一样了,当执行 make clean”的时候,规则因为没有依赖文件,所以目标被认为是最新的,因此后面的rm命令也就不会执行,我们预先设想的清理工程的功能也就无法完成。为了避免这个问题,我们可以将 clean声明为伪目标,声明方式如下:
| .PHONY:clean |
声明 clean为伪目标以后不管当前目录下是否存在名为“clean”的文件,输入"make clean”的话规则后面的 rm命令都会执行。
Makefile条件判断
Makefile也支持条件判断,语法有两种如下:
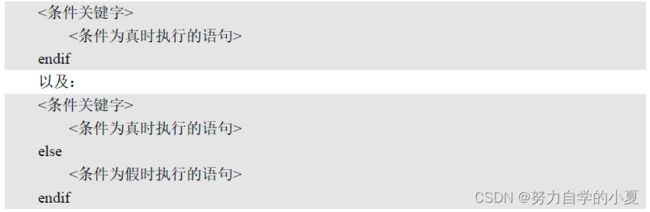
其中条件关键字有4个: ifeq、ifneq、ifdef和ifndef,这四个关键字其实分为两对,ifeq与ifneq、 ifdef与 ifndef;其中,ifeq用来判断是否等, ifneq就是判断是否不相等, ifeq用法如下:

上述用法中都是用来比较“参数1”和 “参数2”是否相同,如果相同则为真,“参数1”和“参数2”可以为函数返回值。 ifneq的用法类似,只不过 ifneq是用来了比较“参数1”和“参数2”是否不相等,如果不相等的话就为真。
ifdef和ifndef的用法如下:
| ifdef <变量名> |
Makefile函数使用
Makefile中的函数是已经定义好的,我们直接使用,不支持我们自定义函数。 make所支持的函数不多,但是绝对够我们使用了,函数的用法如下:
| $(函数名 参数集合) |
| ${函数名 参数集合} |
可以看出,调用函数和调用普通变量一样,使用符号“$”来标识。参数集合是函数的多个参数,参数之间以逗号“,”隔开,函数名和参数之间以“空格”分隔开,函数的调用以“$”开头。接下来我们介绍几个常用的函数。
subst
函数subst用来完成字符串替换,调用形式如下:
| $(subst |
patsubst
用来完成模式字符串替换,使用方法如下:
| $(patsubst |
| $(patsubst %.c,%.o,a.c b.c c.c) |
dir
用来获取目录,使用方法如下:
| $(dir |
notdir
此函数式用来去除文件中的目录部分,也就是提取文件名,用法如下:
| $(notdir |
foreach
foreach函数用来完成循环,用法如下:
$(foreach ,
|
- 中的单词逐一取出来放到参数中,然后再执行
wildcard
通配符“%”只能用在规则中,只有在规则中它才会展开,如果在变量定义和函数使用时通配符不会自动展开,这个时候就要用到函数wildcard,使用方法如下:
| $(wildcard PATTERN……) |
总结
本章节讲的就是在linux中怎么写一个基础简单的C文件,然后经过gcc和Makefile进行编译,变成可执行文件然后执行。看一遍过一过就可以了,具体的还是在使用中会更加有感觉,现在就是打一个基础留一个印象。