快速灵敏的 Flink1
一、flink单机安装
1、解压
tar -zxvf ./flink-1.13.2-bin-scala_2.12.tgz -C /opt/soft/2、改名字
mv ./flink-1.13.2/ ./flink11323、profile配置
#FLINK
export FLINK_HOME=/opt/soft/flink1132
export PATH=$FLINK_HOME/bin:$PATH4、查看版本
flink --version5、启动关闭flink
start-cluster.sh
stop-cluster.sh6、登录网页 http://192.168.91.11:8081

二、flink开发
1、步骤
创建运行环境--> 加载数据源--> 转换--> 下沉
2、案例
(1)学习数据源加载
package nj.zb.kb23.source
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
object AA {
def main(args: Array[String]): Unit = {
//1、创建环境变量
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//设置并行步 1
env.setParallelism(1)
//2、加载数据源
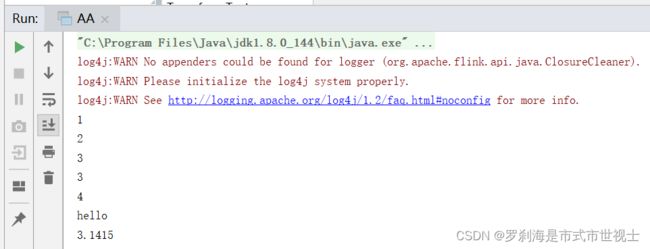
val stream: DataStream[Any] = env.fromElements(1,2,3,3,4,"hello",3.1415)
//3、下沉
stream.print()
env.execute("sourcetest")
}
}
(2)样例类加载数据源
package nj.zb.kb23.source
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import scala.util.Random
//定义样例类
case class SensorReading(id:String,timestamp:Long,temperature:Double)
object AA {
def main(args: Array[String]): Unit = {
//1、创建环境变量
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//设置并行步 1
env.setParallelism(1)
//2、加载数据源
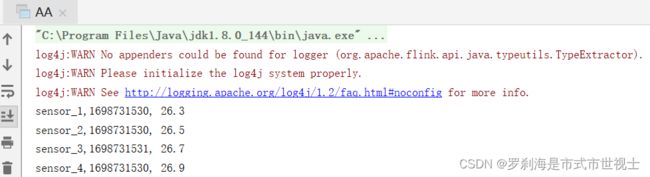
val stream: DataStream[SensorReading] = env.fromCollection(List(
SensorReading("sensor_1", 1698731530, 26.3),
SensorReading("sensor_2", 1698731530, 26.5),
SensorReading("sensor_3", 1698731531, 26.7),
SensorReading("sensor_4", 1698731530, 26.9),
))
//3、输出,又叫下沉
stream.print()
env.execute("sourcetest")
}
}

(3)指定文件加载数据
package nj.zb.kb23.source
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
object AA {
def main(args: Array[String]): Unit = {
//1、创建环境变量
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//设置并行步 1
env.setParallelism(1)
//2、加载数据源
val stream: DataStream[String] = env.readTextFile("D:\\caozuo\\ideal\\flinkstu\\resources\\sensor")
//3、输出,又叫下沉
stream.print()
env.execute("sourcetest")
}
}
(4)指定端口,实时处理数据源
package nj.zb.kb23.source
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
//定义样例类
case class SensorReading(id:String,timestamp:Long,temperature:Double)
object AA {
def main(args: Array[String]): Unit = {
//1、创建环境变量
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//设置并行步 1
env.setParallelism(1)
//2、加载数据源
//(1)真实时处理 nc -lk 7777
val stream: DataStream[String] = env.socketTextStream("192.168.91.11",7777)
stream.print()
//3、转换拼接
val stream1: DataStream[(String, Int)] = stream
.map(x=>x.split(","))
.flatMap(x=>x)
.map(x=>(x,1))
stream1.print()
//①sum
val value: DataStream[(String, Int)] = stream
.map(x=>x.split(","))
.flatMap(x=>x).map(x=>(x,1))
.keyBy(x=>x._1)
.sum(1)
value.print()
// ⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇相等
//②reduce
val value: DataStream[(String, Int)] = stream
.map(x => x.split(","))
.flatMap(x => x).map(x => (x, 1))
.keyBy(x => x._1)
.reduce((x, y) => (x._1 + "#" + y._1, x._2 + y._2))
value.print()
//4、输出,又叫下沉
env.execute("sourcetest")
}
}
(5)kafka加载数据
package nj.zb.kb23.source
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.kafka.clients.consumer.ConsumerConfig
//定义样例类
case class SensorReading(id:String,timestamp:Long,temperature:Double)
object AA {
def main(args: Array[String]): Unit = {
//1、创建环境变量
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//设置并行步 1
env.setParallelism(1)
//2、加载数据源
val prop = new Properties()
prop.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.91.11:9092")
prop.setProperty(ConsumerConfig.GROUP_ID_CONFIG,"sensorgroup1")
prop.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer")
prop.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer")
prop.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"latest")
val stream: DataStream[String] = env.addSource(
new FlinkKafkaConsumer[String]("sensor", new SimpleStringSchema(), prop)
)
val value: DataStream[(String, Int)] = stream.flatMap(x => x.split(" "))
.map(x => (x, 1))
.keyBy(x => x._1)
.reduce((x: (String, Int), y: (String, Int)) => (x._1, x._2 + y._2))
//4、输出,又叫下沉
stream.print()
env.execute("sourcetest")
}
}
(6)自定义数据源加载数据
package nj.zb.kb23.source
import org.apache.flink.streaming.api.functions.source.SourceFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import scala.util.Random
//定义样例类
case class SensorReading(id:String,timestamp:Long,temperature:Double)
object AA {
def main(args: Array[String]): Unit = {
//1、创建环境变量
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//设置并行步 1
env.setParallelism(1)
//2、加载数据源
val stream: DataStream[SensorReading] = env.addSource(new MySensorSource)
//4、输出,又叫下沉
stream.print()
env.execute("sourcetest")
}
}
//模拟自定义数据源
class MySensorSource extends SourceFunction[SensorReading]{
override def run(ctx: SourceFunction.SourceContext[SensorReading]): Unit = {
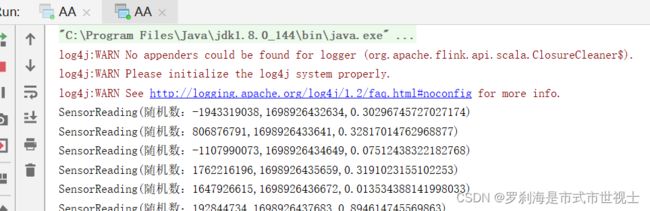
//(1)随机数,true一直生成随机数
val random = new Random()
while (true){
val d: Double = Math.random()
ctx.collect(SensorReading("随机数:"+random.nextInt(),System.currentTimeMillis(),d))
Thread.sleep(1000)
}
}
override def cancel(): Unit = {
}
}
三、flink运行四大组件
1、作业管理器jobmanager
应用程序执行的主过程中,执行应用程序会被jobmanager最先接收,这个应用程序会包括:作业图(jobGraph),逻辑数据流图(logical dataflow graph)和打包了所有的类, 库和其他资源的jar包。jobmanager会向资源管理器请求执行任务必要的资源,也就是任务管理器上的插槽(slot)。一旦它获取了足够的资源,就会将执行图分发到真正运行它们的taskmanager上。在实际运行中,由jobmanager负责协调各项中央操作。
2、任务管理器taskmanager
taskmanager是指工作进程。Flink中包含了多个taskmanager,每个taskmanager中又存在着一定数量的插槽(slots),插槽的数量限制了TaskManager能够执行的任务数量。开始运行后,taskmanager中的插槽会被注册给资源管理器,在收到指令后,taskmanager会提供多个插槽任jobmanager调用。jobmanager通过给插槽分配tasks来执行。运行同一应用程序的taskmanager可以子啊执行过程中互相交换数据。
3、资源管理器resourcemanager
资源管理器在作业管理器申请插槽资源时,会将空闲插槽的任务管理器分配给作业管理器。如果没有足够的插槽来满足作业管理器的请求时,它会向资源提供平台发起会话,以提供启动taskmanager进程的容器。
4、分发器 dispatcher
- 提供了REST接口,在应用提交时可以跨作业运行。
- 在应用被提交执行的情况下,分发器启动将应用提交给jobmanager。
- Webui会由dispatcher启动,以便展示和监控作业的执行信息。
- 这取决于应用提交运行的方式取决于是否需要dispatche