C语言文件操作(详细、好理解、图文结合)
文章目录
- 1为什么要使用文件呢
- 2什么是文件呢
-
- 2.1文本文件和二进制文件
- 2.2举个例子
- 2.3在我们的程序设计中的文件
-
- 2.3.1 程序文件
- 2.3.2数据文件
- 2.4 文件名
- 3文件的打开与关闭
-
- 3.1流
- 3.2文件指针
- 3.3文件的打开与关闭
- 4.文件的顺序读写
-
- 4.1 fgetc
- 4.2fputc
- 4.3 fgetc和fputc联合使用
- 4.4 fgets
- 4.5fputs
- 4.6fscanf
- 4.7sprintf
- 4.8 分析两组函数
- 4.9fread
- 4.10 fwrite
- 4.11 注意
- 5.文件的随机读写
-
- 5.1fseek
- 5.2ftell
- 5.3rewind
- 6.文件读取结束的判断
-
- 6.1被错误使用的feof
- 7.文件缓存区
1为什么要使用文件呢

一些程序在运行时输入的数据,希望在下次运行的时候这些数据依旧还在——通讯录
如果不适用文件存储,每次运行时都没有之前的数据,那这个通讯录就不能存储信息,也就没有什么用了。
为解决此种问题,C语言引入文件操作
文件是将内容放在电脑的硬盘中,当程序结束时信息会被放在用硬盘上,这样就可以防止内容的丢失了。
2什么是文件呢
放在磁盘(硬盘)上的文件就叫做文件
如:我们所下载的APP其实都是放在硬盘上的可执行文件。
文件又可以分为:文本文件和二进制文件
2.1文本文件和二进制文件
文本文件:在文本文件中,字节表示字符,这使得人们可以检查或者编译文件(人可以看懂的文件)
二进制文件:在二进制文件中,字节不一定表示字符,字节组还可以表示其他数据类型是数据(比如:整型,浮点型)
而且二进制文件,我们是看不懂的,打开后是一堆乱码,但是机器可以看懂
2.2举个例子
相信有些人和我一样,听完后云里雾里,举个例子就明白了

看到这个图片应该就会明白两个文件的差异了吧。
注:我们使用的记事本之类的是读不懂二进制文件的所以显示的是乱码,这些乱码如果经过转换一样可以变回二进制。
从这幅图中我们也可以看出,都是存12345但是文本文件用来5个字节而二进制文件只用了2个字节,这也可以告诉我们,相同的内存文本文件占用的空间>=二进制文件的。
2.3在我们的程序设计中的文件
在程序设计中,我们一般谈的文件有两种(从文件功能的角度来分类的):
程序文件(二进制文件)
数据文件 (既可以是文本文件又可以是二进制文件)
2.3.1 程序文件
包括源程序文件(后缀为.c),目标文件(windows环境后缀为.obj),可执行程序(windows环境
后缀为.exe)。
2.3.2数据文件
文件的内容不一定是程序,而是程序运行时读写的数据,比如程序运行需要从中读取数据的文件,
或者输出内容的文件。
2.4 文件名
一个文件要有一个唯一的文件标识,以便用户识别和引用。
文件名包含3部分:文件路径+文件名主干+文件后缀
例如: c :\code\test.txt
为了方便起见,文件标识常被称为文件名。
3文件的打开与关闭
3.1流
在C语言中,流表示任意输入的源或任意输出的目的地
许多小的程序都是通过一个流获得全部的输入,并通过一个流写出全部的输出
比如:键盘-----是任意的输入源 键盘是一种流,我们叫它为标准输入流
scanf(“%c”,&a)这就是从键盘输入
显示器(屏幕) ----是任意的输出目的地 屏幕也是一种流,我们叫它为标准输出流
printf(“%c\n”,a)这就是从屏幕输出
我们现在写的这些小代码是用不到其他流的,只要键盘和屏幕就够了。
但是在规模较大的程序中可能会需要额外的流,这些流通常存储在不同的介质中(如硬盘驱动器、CD、DVD)上的文件
由此可知文件也是一种流。
流的类型有许多,比如:打印机
我们在这里只需要了解文件。
3.2文件指针
每个被使用的文件都在内存中开辟了一个相应的文件信息区,用来存放文件的相关信息(如文件的名
字,文件状态及文件当前的位置等)。这些信息是保存在一个结构体变量中的。该结构体类型是有系统
声明的,取名FILE.
例如:在VS2013的编译环境中
struct _iobuf
{
char* _ptr;
int _cnt;
char* _base;
int _flag;
int _file;
int _charbuf;
int _bufsiz;
char* _tmpfname;
};
typedef struct _iobuf FILE
每当打开一个文件的时候,系统会根据文件的情况自动创建一个FILE结构的变量,并填充其中的信息,
使用者不必关心细节。
一般都是通过一个FILE的指针来维护这个FILE结构的变量,这样使用起来更加方便。
FILE* pf;
定义pf是一个指向FILE类型数据的指针变量。可以使pf指向某个文件的文件信息区(是一个结构体变
量)。通过该文件信息区中的信息就能够访问该文件。也就是说,通过文件指针变量能够找到与它关联的文件
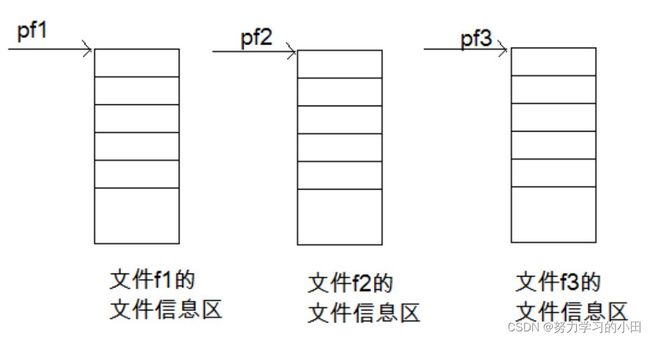
C程序中对流的访问是通过文件指针来实现的。此类指针的类型FILE* (FILE是定义在
用文件指针表示的特定流具有标准的名字(对文件操作就要知道文件名)
读到这里,肯定有人疑惑:既然键盘和显示器都是流我们写程序也没有使用文件指针啊?
想到这里,你就很棒了
C语言中有三个标准流
| 文件指针 | 流 | 默认含义 |
|---|---|---|
| stdio | 标准输入 | 键盘 |
| stdout | 标准输出 | 屏幕 |
| stderr | 标准误差 | 屏幕 |
着三种流在你打开程序的时候就默认打开了,就相当于开机的时候你的键盘和屏幕就可以用。
这三种流是不需要文件指针来实现的,其他的都要。
3.3文件的打开与关闭
前面都不是重点,只是告诉一些常识,只要了解就够
下面的这些,一定要认真学会,这些是要用的。
文件在读和写之前要打开文件
就比如:你在读信时需要打开信封才可以看见内容

在写完后需要关闭文件
就比如:写完信后你要把信放进信封在关掉信封,不然你写的东西可能就丢了
我们知道我们打开和关闭信封是通过手完成。
那么打开文件和关闭文件是如何完成呢?
我们是程序员,当然是通过函数完成,只不过这个函数,有人给我们写好了,我们直接用就好.
打开文件
头文件
FILE * fopen ( const char * filename, const char * mode );
返回值是文件指针(打开成功返回一个地址,打开失败则返回NULL)
第一个参数是文件名
第二个参数是打开方式
关闭文件
头文件
int fclose ( FILE * stream );
返回值是int类型(关闭成功返回0,关闭失败返回EOF)
参数只有一个是文件指针
打开文件的第二个变量,打开方式有哪些呢?
文本文件
| 文件使用方法 | 含义 | 如果文件不存在 |
|---|---|---|
| “r”(只读) | 为了输入数据,打开一个已经存在的文本文件 | 出错 |
| “w”(只写) | 为了输出数据,打开一个文本文件 | 建立一个新的文件 |
| “a”(追加) | 向文本文件尾添加数据 | 建立一个新的文件 |
| “r+”(读写) | 为了读和写,打开一个文本文件 | 出错 |
| “w+”(读写) | 为了读和写,建议一个新的文件 | 建立一个新的文件 |
| “a+”(读写) | 打开一个文件,在文件尾进行读写 | 建立一个新的文件 |
二进制文件
| 文件使用方法 | 含义 | 如果文件不存在 |
|---|---|---|
| “rb”(只读) | 为了输入数据,打开一个二进制文件 | 出错 |
| “wb”(只写) | 为了输出数据,打开一个二进制文件 | 建立一个新文件 |
| “ab”(追加) | 向一个二进制文件尾添加数据 | 建立一个新文件 |
| “rb+”(读写) | 为了读和写打开一个二进制文件 | 出错 |
| “wb+”(读写) | 为了读和写,新建一个新的二进制文件 | 建立一个新文件 |
| “ab+”(读写) | 打开一个二进制文件,在文件末尾追加 | 建立一个新文件 |
直接上代码:
#include这便是打开文件与关闭文件了。
4.文件的顺序读写
文件的顺序读写,就是按顺序向文件中写东西或者读东西
这里我们需要靠一些函数来为我们完成这些操作。
| 功能 | 函数名 | 适用于 |
|---|---|---|
| 字符输入函数 | fgetc | 所有输入流 |
| 字符输出函数 | fputc | 所有输出流 |
| 文本行输入函数 | fgets | 所有输入流 |
| 文本行输出函数 | fputs | 所有输出流 |
| 格式化输入函数 | fscanf | 所有输入流 |
| 格式化输出函数 | fprintf | 所有输出流 |
| 二进制输入 | fread | 文件 |
| 二进制输出 | fwrite | 文件 |
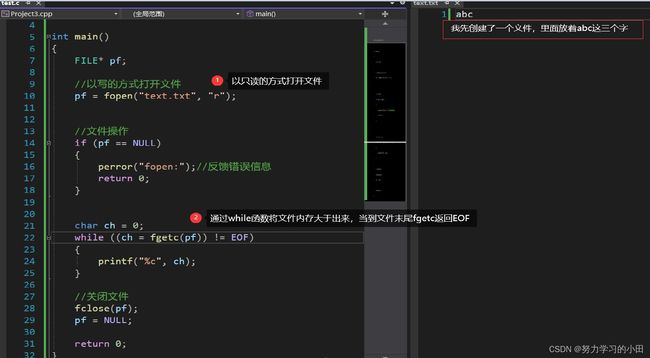
4.1 fgetc



仔细看看这三个函数
getchar是从标准输入流读取一个字符(从键盘获得一个字符),所以不需要文件指针,因为标准输入流一直开着。
fgetc和getc函数从任意流中读取一个字符:
ch = fgetc(fp);
ch = getc(fp);
看看如何使用吧
4.2fputc



putchar函数向标准输出流写一个字符(屏幕上显示一个字符),所以不需要文件指针,因为标准输出流一直开着。
fpuc和putc函数从任意流中输出一个字符
fputc (ch , fp);
putc (ch , fp);
现在我们将上面两个文件操作函数一块使用一下吧。
4.3 fgetc和fputc联合使用
向文件中写内容
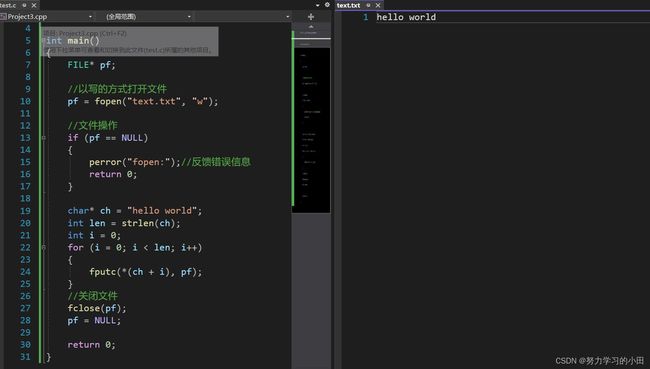
从文件中读内容
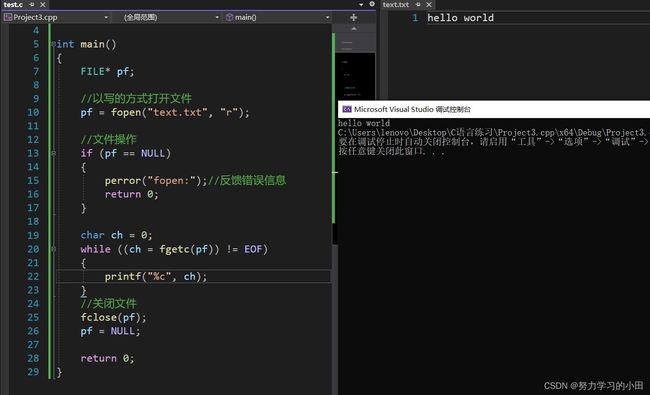
这便是这两个函数来向文件中写内容与读内容
4.4 fgets

第一个参数str:表示你读取的字符串所放的地方
第二个参数num:表示你读取多少个字节的内容
第三个参数stream:表示从那个流中去读(这里我们理解为文件就好)
先简单看看如何使用吧
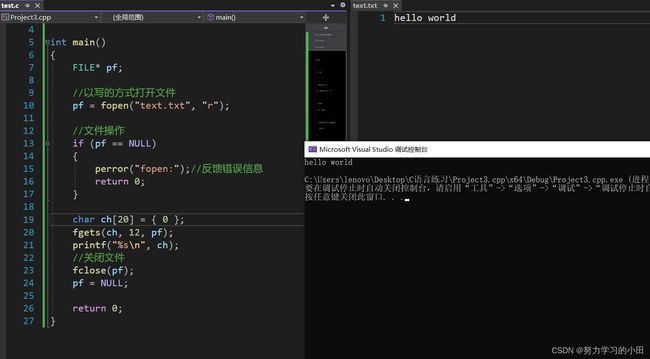
不要读到这你就觉得你懂了————继续看看
fgets叫文本行输入函数,是什么意思呢?
fgets这个函数在文件中读到’\n’时就会结束(一个换行符代表一行的结束)
有人就问了要是读不到’\n’就不结束了吗?
也不是,它的第二个参数控制了它最多读取多大的内存
当读到sizeof(str)-1时如果没有’\n’则自动退出
又有人不理解为什么时读到sizeof(str)-1,我明明要读10个字节大小的空间,你怎么就给我读9个呢?
因为读的都是字符(文本文档都是由字符组成的)
你读10个字节大小的内容
如果确实给你从文件读取了10个字节,而你用一个10个字节大小的数组来接收
你在将他打印出来,就会出现乱码, ----- 假设
因为没有结束标志’\0’
所以现在知道了吧,他会用你最后一个字节大小的空间去存放’\0’。
所以你要读10个,他只会只给你9个内容
有人说:你说的就对吗,万一你只是口嗨呢?上面只是巧合呢?
下面我会用代码给你们看看
第一个问题:读到’\n’函数结束
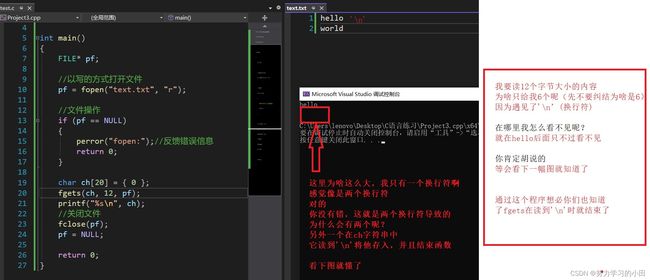
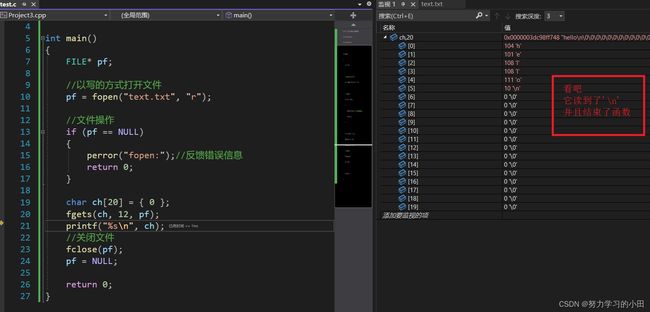
第二个问题:读不到’\n’呢?
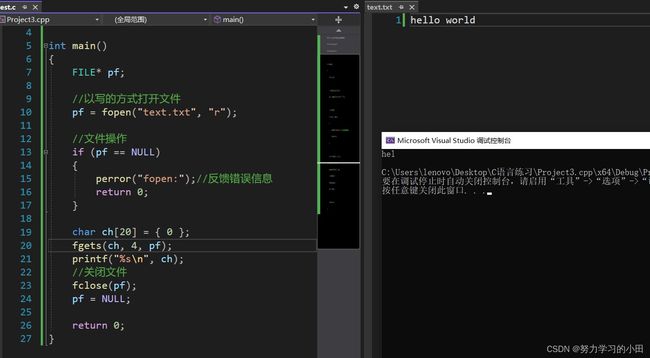
读不到’\n’则读到sizeof(str)-1结束
对这个就是读到第三个字符结束,也就是读出hel
第三个问题:为啥最多读sizeof(str)-1而不是sizeof(str)呢?
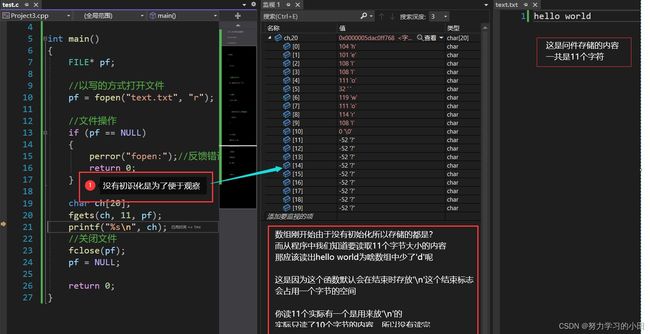
读完后应该就了解的差不多了。
4.5fputs

第一个参数str:是你要存放的内容
第二个参数stream:是要写入到那个流(这里就理解为文件)
看看如何使用吧。
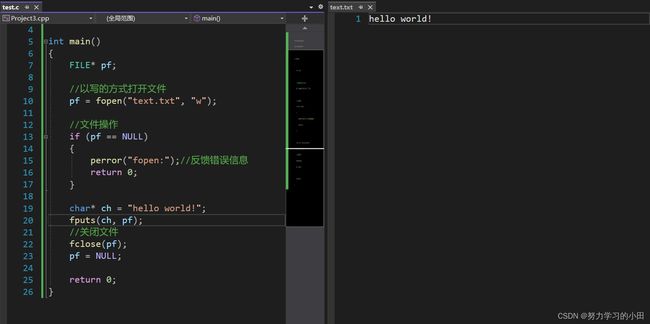
很简单,将字符串写入文件中
4.6fscanf


scanf(“%d”,&a)相信这个函数大家都不陌生,它是从键盘输入一个整数储存在a中。由于键盘是标准输入流,一直是打开状态,所以直接使用就好。
scanf(“%d”,&a) == fscanf(stdio,“%d”,&a)
这个两个函数可以达到相同的效果,可以认为scanf是由fscanf演变而来,专门针对标准输入
fscanf
第一个参数:文件指针 从哪里读取
第二个参数:格式化字符串
第三个参数:存放到变量中 和scanf用法一样
fscanf和scanf基本一样,只不过不是从键盘读取,需要在第一个参数写出文件指针的名字
话不多说,看看如何使用吧
4.7sprintf


和上面scanf和fscanf的用法基本差不多
屏幕也相当与一个流(文件),将内存中的数据写入屏幕中(文件)。
只不过printf函数不需要指定文件,默认是屏幕(标准输出流)
而sprintf需要指定写入那个文件中
第一个参数:文件指针 写入哪里
第二个参数:格式化字符串
第三个参数:把那些变量的内容写入 和printf函数差不多
话不多说看看如何使用吧
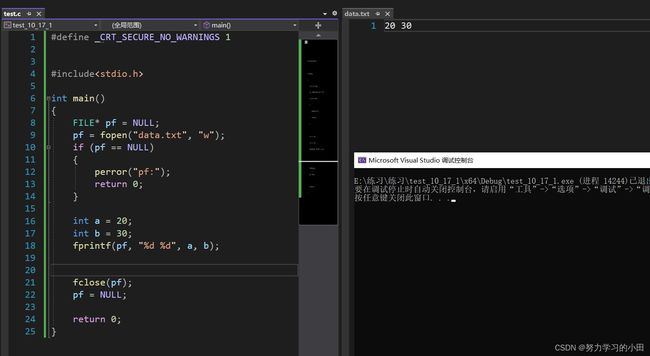
将20,30写入文件data.txt中
4.8 分析两组函数
![]()


这三个函数,看起来是不是特别的像。
scanf函数是从标准输入流中读取内容,写入内存中
fscanf函数是从所有输入流中读取内容,写入内存中
sscanf函数是从一个字符串中读取内容,写入内存中



这三个函数也是特别相似的
printf函数是从内存中读取内容,写入标准输出流中
fprintf函数是从内存中读取内容,写入所有输出流中
sprintf函数是从内存中读取内容,写入字符串中
4.9fread
第一个参数:需要用来存放从文件中读取出来的信息, 是一个地址
第二个参数:一次读多少(字节)
第三个参数:一共要读多少次
第四个参数:从哪里读 文件指针
有了上面的经验,应该都知道怎么写了
看看代码吧
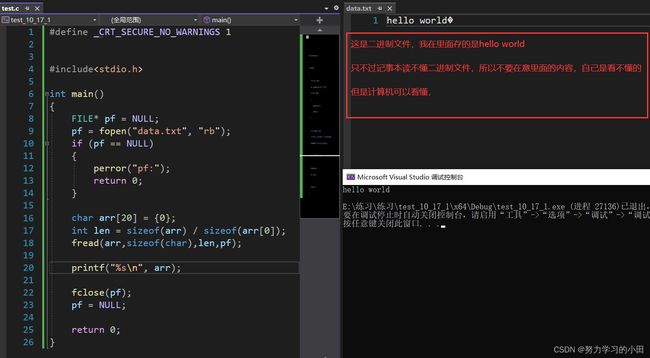
注意: fread函数是读取二进制文件,养成一个好的习惯,用rb(二进制打开文件)。
用法大概就这样。
一定要多使用这些函数,不要觉得看一遍就会了,一定要多用你就会发现一些问题。
4.10 fwrite

第一个参数:需要写入的内存 是一个地址
第二个参数:一次写入多少 (字节)
第三个参数:一共要写多少次
第四个参数:写入到哪里 文件指针
上代码
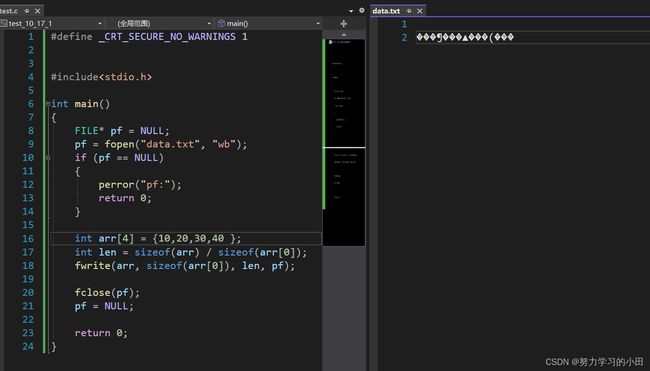
这里的文本,咋们肉眼是看不懂的,因为是二进制文件,但是机器可以看懂。

这个都不重要,你用二进制写入,用二进制读取,就会得到你想要的内容,自己不需要知道文件里面存的是什么。
4.11 注意
养成一个良好的编程习惯
1.这些函数两两一对,按对使用,不要混合使用,这样是不好的。
2.读二进制文件就按二进制文件的打开形式,读文本文件就按文本文件的打开形式
3.打开文件一定要判断打开是否成功
4.一定要关闭文件。将文件指针置为NULL
5.文件的随机读写
5.1fseek

这个函数的作用是:设置文件指针的位置
第一个参数:文件指针
第二个参数:偏移量(正数表示正向偏移,负数表示负向偏移)
第三个参数:开始偏移的位置
第三个参数开始偏移的位置,有三个(固定的)
| Constant | Reference position |
|---|---|
| SEEK_SET | Beginning of file(文件开始处) |
| SEEK_CUR | Current position of the file pointer(文件指针当前的位置) |
| SEEK_END | End of file (文件结尾) |
看例子就懂了,不废话了。
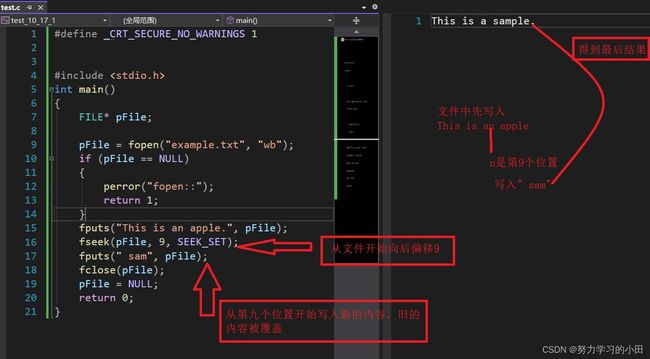
想必看到这就都懂了。
5.2ftell

这个函数的作用:返回文件指针相对于起始位置的偏移量
一个参数:文件指针
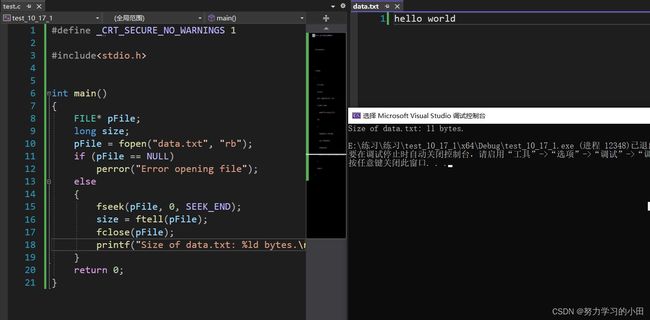
将文件指针指向文件末尾
在判断文件末尾到文件起始位置的偏移量(文件有多大空间(字节))
5.3rewind

这个函数的作用:使文件指针回到其实位置
一个参数:文件指针
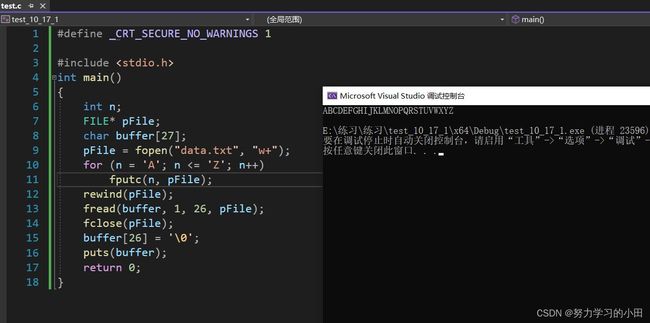
将‘A’ - ‘Z’写入文件中,再使文件指针回到起始位置,将文件内容读出,最终打印出来
6.文件读取结束的判断
6.1被错误使用的feof
牢记:在文件读取过程中,不能用feof函数的返回值直接用来判断文件的是否结束。
而是应用于当文件读取结束的时候,判断是读取失败结束,还是遇到文件尾结束。
- 文本文件读取是否结束,判断返回值是否为 EOF ( fgetc ),或者 NULL ( fgets )
例如:
fgetc 判断是否为 EOF .
fgets 判断返回值是否为 NULL .
- 二进制文件的读取结束判断,判断返回值是否小于实际要读的个数。
例如:
fread判断返回值是否小于实际要读的个数。
文本文件的例子:
#include 二进制文件的例子:
#include 7.文件缓存区
ANSIC 标准采用**“缓冲文件系统”**处理的数据文件的,所谓缓冲文件系统是指系统自动地在内存中为程序 中每一个正在使用的文件开辟一块“文件缓冲区”。从内存向磁盘输出数据会先送到内存中的缓冲区,装 满缓冲区后才一起送到磁盘上。如果从磁盘向计算机读入数据,则从磁盘文件中读取数据输入到内存缓 冲区(充满缓冲区),然后再从缓冲区逐个地将数据送到程序数据区(程序变量等)。缓冲区的大小根 据C编译系统决定的。
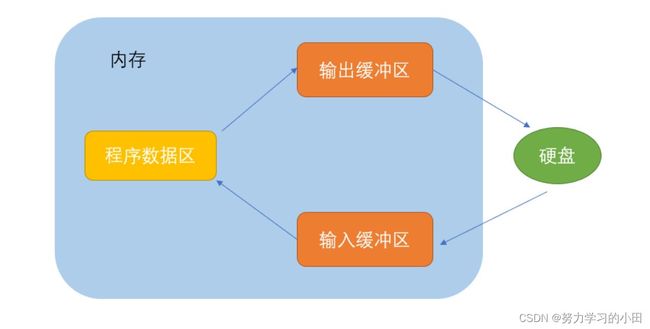
#include 大家可以根据这段代码在自己电脑上试试,就可以清楚的感觉到文件缓存区的存在了。
结论:
因为有缓冲区的存在,C语言在操作文件的时候,需要做刷新缓冲区或者在文件操作结束的时候关闭文件。这两种方法都可以刷新文件缓存区
如果不做,可能导致读写文件的问题。所以每次写完后都要关闭文件,不然可能导致信息丢失