JavaEE平台技术——预备知识(Web、Sevlet、Tomcat)
JavaEE平台技术——预备知识(Web、Sevlet、Tomcat)
- 1. Web基础知识
- 2. Servlet
- 3. Tomcat并发原理

![]()
1. Web基础知识
上个CSDN我们讲的是JavaEE的这个渊源,实际上讲了两个小时的历史课,给大家梳理了一下,这二三十年来,JavaEE的规范,和Spring的规范如何是相生相克的。
我们在整个课程设计中间或这门课中间,会用到一些什么样的相关知识,有一部分的知识可能很简单,大家就当听听过去了,有一部分知识可能大家没有接触到,可能听不懂也没关系,知道我们会用到它,然后知道它用的目的是,为了什么之后的话,大家在课后或者用到它的时候,再去深入的去了解这些相关的预备知识。
引出HTTP
我们首先从最简单最基础的开始讲起啊,我们知道JavaEE的规范主要是用来做后台服务器系统的,后台的服务器系统基本上都是现在是HTTP协议的一统天下,基本上我们不会再用其它的协议去实现我们的后台的服务器系统。
引出统一资源定位符URL
在HTTP的这样的一个协议上头,它就是它依赖的是,我们的统一资源定位符(Uniform Resource Locator),大家都很熟悉了它其实是由这么几个部分构成。
资源定位符URL的构成
- 协议,我们主要用的是HTTP的协议,所以这个部分是HTTP或者HTTPS;
- 服务器的域名,那域名实际上对应的是IP,我们会用域名服务域名去查那个IP,所以IP是什么其实是没有关系的,这里看到的是一个DNS的域名,我们在用的时候其实我们,往往不会用DNS的域名,而是用我们自己的一个名字,DNS域名是到DNS服务器上去查,我们自己的名字其实就是到我们的服务器上,去查那个名字所对应的IP,所以后面会看到我们的程序,其实可以任意装在任何一个地方,只要我们给它提供了查名服务,用名字去查到这个IP,这个问题就能够解决,这是第二个部分。
DNS(Domain Name System)域名系统是互联网的一项基础设施技术。它的主要功能是将易于记忆的域名(例如www.example.com)转换为IP地址(例如192.0.2.1),以便在网络上定位和识别计算机服务和设备。DNS域名系统可以看作是互联网的电话簿,它通过将域名映射到相应的IP地址来帮助用户定位所需的网络资源。
在实际应用中,当您在浏览器中键入网址时,浏览器首先会向DNS服务器发送查询请求,以获取相应域名所对应的IP地址,然后才能建立连接并加载所需的网页内容。这个过程使得用户无需记住复杂的数字地址,而是能够使用更易于记忆的域名来访问网站。
- 端口号,因为在同一台服务器上可以装多个应用,所以每个应用需要自己的一个端口号,你才会知道说你访问这个服务器的时候,是访问的是这个应用,而不是其它的应用,这是端口号。
- 后面的东西是路径,路径通常是用来在一个应用里头去标识,说这个部分是什么样的东西,这个路径其实它并不代表说在这台服务器上的,某个文件的目录,它就是用来去标识去区分,在我们的应用之间去区分说,这是应用的这半部分,还是这是应用的另外一个部分,比如说我们以后在用到路径的时候,通常是用来区分什么,区分模块,我们会有若干个模块,那就会用路径去区分这个模块,这是路径。
- 最后则是资源,就是我们真正提供的东西,这个不是一个文件,往往可能是我们在服务器上头的一段代码。
现在我们拿到应该网址,我们可以清楚的看到以下部分是什么!
我们会描述了,我们用什么样的协议,访问哪台服务器的哪个端口,在这台服务器的端口的应用里头,我们要访问哪一部分,以及这一部分的什么东西,构成了这样的一个URL。

![]()
应该大家都熟悉,在web的服务中间访问的过程这样子,我们前端不一定是人,也可能是另外一台服务器,它通过一个URL的地址,发送到一台服务器上,它中间会有比较复杂的查名过程,所以它查到这个服务器的IP,然后把这个请求发到服务器上,然后服务器就根据端口,根据路径,然后根据资源就是后面的三个部分,去找到对应的东西,去执行它,得到一个结果,这个结果再返回给前端,然后前端去用这个结果,我们在图上看到是HTML,我们现在在这个过程里面,很多的时候是一段数据,就是发一个请求,向服务器去执行一个什么样的东西,然后服务器通过这个端口,知道是什么样的应用,通过后面的路径知道是应用的哪一块部分,通过资源知道说我在这块部分要执行什么,然后执行它得到一个结果,把这个结果再返回给前端,这就是这样的一个访问过程,我想这个应该大家都很熟悉。

其中HTTP协议或者HTTPS协议,是这个里头最基本的部分,最上面一层应用层的协议,对吧,所以它这种协议是要基于底层的TCP/IP来实现的,所以它是一层一层的啊,网络的7层协议。

我们这里讨论的,就是它这个http协议的特点在于说——它是一对的,一问一答,发出一个请求,我们称之为HTTP的Request,然后它返回一个HTTP的Response,不问不答,如果我不发HTTP Request,它不会回来一个HTTP Response,而且我不会记录之前问过什么,所以它的每一个相关的内容,都应该是基于它的HTTP的Request,去返回HTTP的Response。

HTTP之后我们会引出Request Response
当然我们在应用中间,我们会发现HTTP的协议的这个特性,其实挺挺恼火的,因为我们确实是需要知道它之前干了什么,但是HTTP协议本身来说,它只提供一问一答的这样一个机制,所以我们要靠其它的部分来完成这个东西。
HTTPS是在这个协议上做了加密, HTTP协议是明文的,所以我们如果说,想要对我们在网络上头传输的内容,无论是Request的内容,还是Response内容,进行加密的话,进行保密处理的话,都应该使用HTTPS的协议。
原来Google警告这么来的!
所以大家现在可以看到,基本上所有的应用都是用的,HTTPS不是HTTP,甚至极端情况下的比如像谷歌的浏览器,你用HTTP它要警告,你说这个服务器用的是HTTP是不安全的,你确定要不要用,你用才能继续访问它。
虽然我们在课上一直是,用HTTP的协议来举例子,但真实在用的时候其实是用HTTPS,但是无论是HTTP还是HTTPS,对于我们的程序来说其实没差别的,它是一个网络传输层的问题,它是用了加密还是没有用加密的传输对于我们程序来说,我们其实是不关心,它是用HTTP还是HTTPS的。
只是在配置上如果说,要用HTTPS的话,在Web服务器的配置上,是要做些很特别的配置,不管是HTTP还是HTTPS的协议,它都是HTTP的Request和Response的过程,所有的协议都是分为包头和正文的部分,就是Head和Body的部分,Head是控制信息。
我们为什么要把这个协议的,控制信息拿出来讲——因为我们有很多重要的数据,都在控制信息里头
控制信息其实我们在写程序的时候,我们也会人为的在Head里头 ,在头里头插入我们所需要的控制信息,我们在服务和服务之间调用的时候,我们也会在转发 HTTP协议时候,加入我们所需要的头的信息。
所以每年在做课程设计的时候,同学们在做微服务体系结构的时候,会犯错的一个主要的地方,就是这个协议的头没控制好,调进来的时候是ok的,然后再去调别人就不ok了,出现这种情况你首先就,应该怀疑说这个头有问题,你要看看它进来的头ok的头是什么,你再去调别的时候你应该保持一样的头,才能保证整个的调用是连贯的,所以头的格式大家应该都很清楚,它描述了请求的方法。
![]()
HTTP Request 部分

Head的大致论述
我们后面讲HTTP有若干种请求的方法,也是跟我们的设计有关,因为我们后面会讲RestFul的API,其实它就利用 HTTP的请求的方法,去做 API的设计,然后是URL,然后是它的协议的版本号,然后是它的主机然后后面它的控制字符,我们在里头会要用到其中的一些控制字符,或者要去加一些控制字符,就是它的变量它的头里头所放的这些字段名和值,这是我们要用到的东西。
Body的大致论述
Body里头放的就是内容,在Body里头通常放的,就是一个JSON的字串,一个JSON的内容放在里面,对于这个请求的方法,就是HTTP的Request方法,这个也应该知道,我们一共有OPTIONS GET,POST PUT DELETE,CONNECT和TRACE这些方法。
| 请求方法 | 描述 |
|---|---|
| OPTIONS | 返回服务器针对特定资源所支持的HTTP请求方法, |
| GET | 向特定的资源发出请求。请求体中无内容 |
| POST | 向指定资源提交数据进行处理请求。数据被包含在请求体中。 |
| PUT | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| DELETE | 请求服务器删除指定的页面。 |
| CONNECT | HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。 |
| TRACE | 回显服务器收到的请求,主要用于测试或诊断。 |
我们其中会用到的部分来说,主要是前面的5个,就是OPTIONS GET POST PUT ,DELETE这五种方法,这5种方法在RestFul API中间,它是有特别的定义的,就是我们会利用HTTP的请求,针对同一个URL的,不同的请求的方式,去做不同的语义,然后去设计说,这是用来去实现什么样特定的功能。
![]()
HTTP Response部分

Response部分,跟Request的部分一样,仍然分为包头和正文。
包头依然是控制信息,所以我们在Response的包头部分,也会要插入一些,我们所要的东西。
而Body的部分主要是JSON的数据,我们会以JSON的格式,把数据放到正文里头,放到Body的部分,这是HTTP的协议。

最后是它的状态码,状态码是在HTTP的,Response里头的字段,大家应该知道在头里头,它应该会返回它的状态码是什么。
这个状态码表示了什么?
表示了服务器端向客户端返回,说服务器端的你发的请求它的结果是什么。
成功
我们最常见到的结果是200和201,200和210都是ok,说明服务器一切正常,你无论是一个请求,还是一个POST的请求, GET请求都是200,POST的请求的返回的ok是201,这是它的规范所决定的。
400系列小解读
其它的这些值就代表特别的含义,比如说我们说400开头的这些东西,通常是你发过来的东西有问题,比如说你发过来的 Request,它的正文的值我解释不出来,不符合我的格式,所以就会以400的方式:
- 你发过来的请求要访问的这个程序,是需要登录的,但是你没有登录就会返回401
- 你如果登录了你来访问它这个部分,如果你没有权限,它就会返回403;
- 如果你要请求的 URL根本就是错的,在我这里头就不知道这是个什么东西,我就会给你返回404
所以400系列的状态,基本上是跟你的请求有关的,就是你请求有问题,说到底你请求有问题,就会返回400类的错误码,这些错误都是会用程序去完成的,比如说我们在解析它的一个Request的时候,发现它对不到我们的一个参数上,那就会返回400。
500系列小解读
500开头的错误,通常就是我们服务器本身有问题。
- 比如说你的服务器崩掉了,你就会返回500。
- 比如说你的服务器阻塞了,就是我服务器没崩,但是我服务器已经响应不过来了,就会返回503。
所以400的系列的错误,是表示说Request本身有问题,500的错误是表示说Request,没问题,但是我服务器有问题,Response返回里头,值是没有意义的,就会返回500的错误,这是我们主要的状态码
对于所有的状态码都是有定义的,就是我们除了这里所看到的,400和500的状态码以外,我们在这个基础上头,针对比如说200 201的状态码上头,我们还有新的错误码去定义,表示说更新的含义,但是状态码我们还是符合,HTTP协议所规定的状态码,在它这个语义上头去扩充,我们需要返回的更多的值,这是这个状态码。
![]()
2. Servlet
简单来个小导读:
这个部分我们要讲的就是,关于Servlet,它是一个有着悠久历史,JavaEE的第一版的规范Servlet就出现了,然后到JavaEE的最后一版规范,它还在它!
为什么会这么长的时间,存在于JavaEE的规范中间,Spring中也有这个规范?
因为它是我们目前一个,非常重要的技术规范,也是重要基础的规范。在Spring的框架中间的,Servlet Stack的所有的技术,都是基于Servlet规范来实现的。
我们略微讲一下Servlet规范的定义是什么,以及它的实现机制是什么?
虽然我们今天已经很少有机会,去直接来写这部分的Servlet的代码,但是因为它是我们整个Servlet Stack的,一个最基础的东西,所以我们还是有必要去,了解它的实现的机理,这样的话会方便我们去理解,后面的东西是怎样,在这个机制上头去实现的,以及我们如何去调优我们的服务器,特别是Servlet Stack的这个调优,其实跟Servlet的机制是有密切的关系的。
Servlet这样的一个机制,我们在JavaEE的规范中间其实有提到,它是用来去做服务器的表现层的,最开始是出于这样的一个目的,它接收的是HTTP的Request。
- 根据这个HTTP的Request,它把服务器端分成了容器和组件两个部分。
- 容器叫做Servlet容器,用规范去定义了这个容器该做什么。
- 组件叫做Servlet,规范去定义了Servlet要做什么。
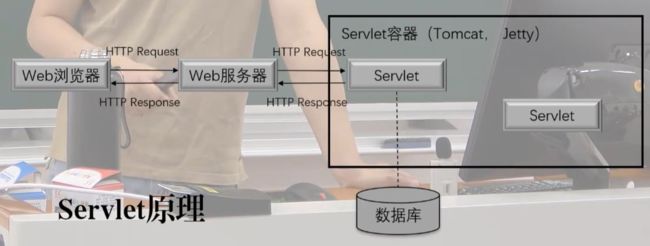
- 当一个HTTP的Request过来的时候,它是发到容器;
- 容器则会根据这个HTTP的,Request去运行Servlet,执行一些逻辑;
- 这个逻辑就是用Java代码写的你爱做什么做什么,比如说我们这里看到的是访问数据库,然后得到数据,产生你的HTTP Response,里头要放的那些数据,给它送回来这样的一个机制。
我们要稍微深入讨论的是内部发生了什么?
这就是JavaEE的Servlet的规范里头所定义的东西

JavaEE的Servlet的规范里头定义了一系列的接口和一系列的类,我们这个里头这张图上头,只有第一个接口,是有写了包名的

其它的没写,不是说它没有包名,它的包名跟第一个都是一样的,全在javax.servlet的包里头,这个就是JavaEE的Servlet的规范,定义了一系列的接口和基类。
这一个接口里头定义了什么?
你要去实现一个Servlet,你首先要去实现一个叫做javax.servlet.Servlet的接口,这个接口里头有很多的方法,其实它最重要的一个方法,就是service方法,service方法有两个参数,一个是ServletRequest,一个是ServletResponse,就这张图上的这个东西,我要实现一个这样的对象,这个对象必须实现Servlet的接口,这个接口里头有service的方法,这个方法接收过来的是,HTTP的Request,返回的是HTTP的response,送过来的Request,返回去的response,作为接口的两个参数。

但它在这个接口上没有写HTTP两个字,原因是它在设定规范的时候,它想Servlet其实还可以在其它的网络协议上去实现,但事实30年过去了,Servlet也没有在其它的网络协议上去实现,但是它是想这么来做的。

这左右两个接口又有子接口,这个子接口才是HTTP协议的,HttpServletRequest,和HttpServletResponse,这就具体到我们真正的HTTP协议上了。

对于Servlet的接口来说,它有实现了基类,但是基类做了两层。

一个是GenericServlet,一个是HttpServlet,大家知道,这个HttpServlet就是用来去实现HTTP协议的Servlet,在这个基类中间大家可以看到,它实现了一系列的do的方法,这些do的方法全是两个参数,分别是HttpServletRequest,和HttpServletResponse,全是这两个参数,这两个参数是这个(ServletRequest和ServletResponse)的子类。
这张图就画的是我刚才所说的这样的一个事情,对于Servlet容器来说,它接到HTTP的Request以后,它把Request变成Request对象,然后创建了一个response的对象。
然后把Request对象和Response对象,(Servlet是一个对象,实例化成一个对象)通过一个线程去调Servlet的service的方法, service的方法会根据请求的类型,去调doGet还是doPost,doPut还是doDelete,然后把传过来的 HTTP的Request对象和HTTP的response对象传给它,里头你自己去写代码,就这样的一个过程。
JavaEE规范的特征——就是它针对我们在JavaEE规范中间所定义的接口和基类。
你去继承或者实现这些接口和基类,在它的规范下去写代码,你就是符合它的规范的!!
符合它的规范有什么样的好处,Servlet它的容器是可以替换的,我们目前常见的Servlet的容器有两种,Tomcat、Jetty。
Tomcat是大家最熟悉的,我们一般在写程序的时候,可能优选就用Tomcat,用Tomcat以后,你会发现说有时候它特别慢,然后你就想说我能不能换一个容器,它的速度会更快一点,Jetty就是一个比Tomcat更加高效的容器,但是它用的比较少。
![]()
我们有一段演示的代码,如何在JavaEE规范上去写一个Servlet,当然这个代码的主要的作用,只是说给大家演示一下代码怎么写,然后大家去理解,Servlet的这样一个机制,我们今天基本上是不会去手写Servlet代码了,但是我觉得还是有必要,大家看一下那个代码怎么写的,在这里我们之所以给大家来讲,这个Servlet的代码,目的并不让大家去学习,如何基于JavaEE的Servlet的规范,来写代码,因为这个部分的技术其实已经过时了,今天我们是不会再来写Servlet代码的,主要的目的就是让大家去了解,Servlet的原理,因为它到今天依然是我们Servlet Stack的一个最基础的部分,这个代码非常的简单。
![]()
我们一共写了三个,Servlet第一个Servlet,是WelcomeServlet

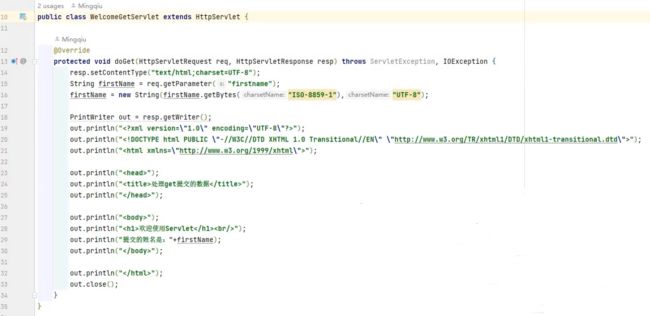
我们可以看到就像我们前面在课上所说的,一个Servlet的代码,是需要实现一个特定的基类的,所以我们可以看到我们的,WelcomeServlet类,extends了HTTPServlet,就是我们前面所说的,实现了HTTP协议的Servlet基类。

在WelcomeServlet的,代码中间其实非常的简单,里头只写了一个方法,就是我们重写了它的doGet的方法,这意味着说我们会去响应它的get的请求。doGet的方法里头两个参数,大家可以看到HttpServletRequest,HttpServletResponse。

既没有从HttpServletRequest拿到任何的数据

从HttpServletResponse中间,获得它的Writer,这个Writer的目的,就是向Http Response中间,写入数据,当然这我们写的数据是一串的HTML,这个HTML就是为了打印出来一个欢迎使用Servlet这样的一个欢迎语,所以把这一堆的,HTML的东西,通过out,把它输出到Http Response里头去,那它就会被送到前端浏览器,就会解析这一堆送过去的HTML,然后就把它呈现出来
![]()
第二个例子我们就稍微复杂一点,我们写了一个HTML,把一些数据传过去,Servlet的工程中HTML其实是,放在,另外一个目录里头的,我们把它叫做webapp目录,在这个目录底下,我们放了一个get.html的文件

当然还有我们后面要讲的,post.html文件,所有的HTML文件,包括图片等等,静态文件,都是放在webapp的目录底下,我们看一下get.html,其实非常的简单,它里头就是一个form action,在 form action中间,我们主要是提供了一个input框,这个input框是要向前端,去提交一个你的姓名的

回到Servlet代码,我们回来看,WelcomeGetServlet,同样继承的是HttpServlet的,它也是个get请求,所以同样重载了这个doGet的方法,它从Http Resquest中间用它的getParameter的方法去获得了我们从前端传过来的值。

然后把这个值输出到了,Http Response里去,当然作为HTML输出,到Http Response里去,这就是一个非常简单的get,但是跟我们前面那个例子相比,它从Http Resquest中间去拿到了一些值。
![]()

最后我们看一下,HTTP的post的这种请求,是怎样实现的,post通常是用来传更多的值,当然这个例子中间我们其实就传了一个,非常少的两个值,依然是依赖于 HTML,post.html,来把两个值把它送过来,对于Servlet的这一端来说,它依然还是一个HTTP的,Servlet,但是我们重载了doPost的方法,依然是两个参数HTTP的,Request,HTTP的response,无论是 get的请求,还是post的请求,其实它的值都放到了,HttpServletRequest里头,所以我们依然从HTTP的,Request里头去获得,我们从前端传过来的两个值,然后又把它写到了,Http Response去,然后把它送回前端。
![]()
我们看一下这些代码和HTML,是怎样能够合起来,被Servlet的容器知道说我有多少Servlet的它依赖的是一个叫做web.xml的配置文件,在webapp/WEB-INF的目录下,当然这个是约定在这个目录下,它才会去认web.xml文件,在 web.xml中间其实主要是两个部分。

一个部分是Servlet的mapping,就是我们看到的下面这个部分,这个部分主要是把我们的请求,映射到对应的Servlet上头,所以我们可以看到,映射到了名字叫做Welcome的Servlet的上头。

一个部分都是关于Servlet的定义,我们可以看到它定义了三个Servlet,对应的就是我们说的Servlet层的名字,还有我们的代码中间的Servlet的类,所以这样的话Servlet的容器,才会根据请求去,从线程池里头去拿到线程去,执行对应的Servlet的类。
![]()
3. Tomcat并发原理
这样跑的一个过程,我们再要讨论一下它的细节,它是用多线程来跑的,我们做的是服务器端的一个应用,服务器端一个应用,同时都要响应很多的请求,就是有不同的客户端,会同时发过来,很多的HTTP的Request,针对每一个HTTP的Request,在Servlet的容器中间,都是以一个独立的线程去跑。

就我们这张图上其实有看到,它是用一个独立的线程去跑的,会起一个线程里头去调Servlet,对象的service的方法,Servlet的对象是唯一的,因为我们在代码中间,会写很多的Servlet的对象,然后这些Servlet的对象会被很多的请求来调。
如果说Servlet的对象不唯一的话,内存吃得太厉害,所有的对象就只有一个。
另外一个问题:Servlet的对象是不能有属性的,线程和进程的差异,线程是共享Java虚拟机的内存空间的,a线程和b线程,如果说它去用一个Servlet的对象,它们俩是同一个对象,它们俩的属性就是同一个属性,如果a线程改了b线程就会受影响,就会出现这样的问题为了避免这样的问题,简单的方法就是Servlet对象是没有属性的,没有属性你就不存在改的问题,它在不同的线程里头去调的话也不会打架。
在比如说service方法或者doGet方法中间的局域变量,局域变量是不会有问题的,在Java虚拟机里头,不同的线程是有线程栈的,不同的线程它的局域变量全是分开的,分别保存在自己的线程栈里头,这里就会带来另外一个调优的问题,如果当线程很多的时候,线程栈占的空间也会很大,所以你要适当调整线程栈的大小,才能容纳更多的线程,不是说你简单的把线程调到1万,它就能够跑的调到1万,线程栈不够了它也跑不了。
所以 线程与线程栈 是有对映关系的。
为了避免这个问题,我们对象通通不写属性,凡是会有存在的线程冲突的这些对象,我们都不写属性这样的话它,线程就是安全了就没有问题。
每一个请求用一个线程去执行,这个线程里头会去调Servlet的service方法,其实在这个容器中间,在执行线程的时候,它是分成了5步,哪5步?

Read的重要性——读为什么还要单独写一个?
因为网络的特性,它并不是一个可靠的稳定的,你永远是一个匀速的在读一个东西,你的网络会受到各种各样的因素影响,比如说你从美国发一个请求过来,Request读起来可能从头读到到完整的读完,大家知道HTTP是应用层协议,底下的TCP/IP协议可能一个Request,会被分成了若干个TCP/IP的包,所以说你拿到第一个包到最后一个包完整读完,最后拼成一个HTTP的Request,可能是要不知道多少时间,完全是看对面发过来的有多远,网络的状况是怎么样,会不会丢包会不会重发都不知道,read的过程其实是完整的读完HTTP的Request的过程,这个是要时间的。
Decode的重要性
读完以后读到的是一个Head和Body的这样的一个协议,然后它要转成一个HTTP的Request的对象(实现了一个接口的对象),所以它要做decode,就是把网络协议读到的数据,变成我们的一个Java的对象,这叫做decode。
Compute的重要性
decode的主要是指 Request的对象,拿到这个对象以后,创建一个Response对象一起传给了service的方法。
Service方法中间会去根据你的请求的,类型去调doGet还是doPost,还是doDelete等等,这就是我们说的compute过程,因为那个方法是你自己写的,就数据已经拿到了你去做逻辑,然后产生结果这个都是compute的过程。
Encode的重要性
拿到这个结果以后,你把它丢到 Response里头返回回去,它要把它变成Response的协议,那是encode的过程。
send的重要性
变成协议以后再传回给客户端,那是send的过程同样传回去的数据.
在TCP/IP上有可能如果比较大的话,可能会分成若干个包,然后一个包中间会有丢包,所以send的过程也是不可控的,整个这个过程,都是在一个线程中间去完成的,这样的话它用多线程的方式,就是多少个请求开一个线程,我们Servlet对象的不写属性大家相互不打架,所有的局域变量都在自己的线程栈里头,所有的读写decode encode,都各自在线程中间去处理,这样就能做到并发。
这样的话会有一定的问题,我们其实对于一台具体的物理机上,是没有办法无限制的增加线程的,为什么没办法无限制增加线程?
- 我们已经说到每个线程要占一定的,内存空间,针对一台特定的物理机内存是有限的,你不可能无限制的1万 2万 3万, 4万的线程上去内存就没有了。
- 第二个是你的计算资源是有限的,因为你任何一台物理机的,CPU就是那么多核,或者就是那么多个CPU,你中间这个计算过程就要靠CPU来完成。
如果你无限制的增加线程的话,我们在操作系统中间会讲到,说CPU会忙不过来, CPU就会要不断的分片轮转,然后CPU就会把大量的时间,花在这个轮转上头,其实它并不是一个高效的方式,我们会根据一台物理机器的,实际状况它有多少内存,它的CPU的计算能力,再结合我们任务的这样一个情况,去制定一个线程池。
线程池是什么?
- 就是我们最多允许你跑多少个线程。
- 如果多于这个线程的话怎么办,就让它去等待。
- 如果在多于等待数的时候我就拒绝,这就是线程池的概念。
有了这个线程池以后,我们实际上是预先创建了若干个线程,放到线程池里头,因为孵化线程是需要消耗时间的,要用代码来消耗时间的,比如说内存中间开一些空间等等,所以我们把线程事先孵化出来,把它放到线程池里头,当请求过来的时候,我们是从线程池里头,拿空闲的线程,拿出来直接去用的,这样可以加快它的响应时间,而且可以管理整个服务器上,对于内存和CPU的消耗,不会出现说它的请求多了,它的内存不够,它的服务器崩溃的这样的一种情况,因为它用线程池卡住了它的上限。
其实我们现在如果在做是Servlet Stack,这一条技术线的时候,我们始终会关心这么4个参数
#最大工作线程数、默认200
server.tomcat.max-threads = 200
#最大连接数默认是10000
server.tomcat.max-connections = 10000
#等待队列长度,默认100
server.tomcat.accept-count = 100
#最小工作空闲线程数,默认10
server.tomcat.min-spare-threads = 100
- max-threads,这个就是线程池的上限,这个就是因为你的服务器的特性,你的物理性能决定的你有多少内存,你的CPU计算能力是多少,所以你要定一个上限,上限不能超过你的物理资源所提供的能力,
- accept-count,这个是排队队列的长度,对如果说发来的请求,超过了你的处理的上限的话,我还可以让它排队等待不是直接拒绝它,我现在定的是100,就意味着说上限是200,它最多可以同时处理多少,300个请求,其中200是在处理的,100是在等待的,如果超过300以后就会怎么样,就会拒绝,就是我们刚才看到的503, server unavailable,就直接就拒绝了,发挥503的错误码回去,这是根据你的服务器的能力来决定的,
- max-connections,最大连接数通常我们不会动,因为它默认值是1万,我们现在基本上,我们的服务器很难达到,1万的这样的一个东西,1万是代表什么意思,是max-threads加上accept-count,这些连接全部都在的,就是你正在处理的最大数,和你让它等待的最大数,加起来就是它最大连接数,所以我们现在是300,它默认值是1万还远的了,所以一般来说我们不会去动它
- min-spare-threads,这个是在说线程池的问题,当然我们可以说线程池有200,我们一起来就占200,占200你觉得有点浪费了,有些时候因为占了200以后,它其实会占一定的内存空间,但其实很多时候我们其实还没有到200,所以我们会定一个min-spare-threads,就是线程在启动的时候,它只有100个线程在里头,如果说超过了100个线程,它就开始孵化线程放进去,上限是200。然后如果说它的压力下来了,就是没有200个请求慢慢下来了,它又会把孵化的线程给它释放掉,释放出我们物理机的一些内存空间,下限又会降到慢慢最后降到100,少于100请求以后,它就一直保持100个线程,线程在里头少于100个线程,它也不会再去释放线程池里的线程了,所以这是一个下限。
这4个参数是我们之后会特别是在用Tomcat时候,会频繁去调的参数,这个参数其实不是一个恒定的值,这个值其实除了跟你的服务器的物理的性能有关以外,还跟你的应用有关,你的应用到底是io密集型的,还是计算密集型的。
如果说你的应用,是io密集型的意味着什么,因为这在read和send的,过程中间是需要消耗尽量多的时间的,计算的时间其实是比较少的,意味着如果你内存足够大的话,你可以尽量多开线程,就是max-threads可以开很高,开1000 ,2000都没问题,因为对CPU压力不大,只要内存够你就尽量的开到顶。
如果说你是计算型的,就是你主要会消耗它的CPU的资源,意味着说CPU就是你的上限,你不能说内存足够,你就开很多的线程那个没用,因为CPU只算那么快,你开到1000 2000它也算不过来。
所以到底会开多少线程数,你其实要去分析说你的应用,到底是io密集型的,还是计算密集型的,去综合决定说,你的线程数是一个什么样的值,这个是多线程管理。
![]()
什么是NIO的模式和APR的模式
它们都是异步io的模式,差别在于NIO用的是Java来实现的,APR用的是原生库,大家知道Java的字节码的运行效率是低于原生库的,APR利用的是阿帕奇的,HTTP的原生库,来实现的异步io 这个就,意味着说你不能单纯的,装一个Tomcat就好了,你还需要先装阿帕奇的原生库,再装Tomcat才能跑出它的APR模式,所以它装起来会稍微麻烦一点,NIO的话还是基于Java来做的,所以说就不需要去装原生库,我们现在的新的版本的,默认方式是NIO。

Compute
BIO和NIO的差别
所谓"BIO"即我们前文所述的,指的是在线程中进行的I/O操作。因此,在其内部代码实现过程中,正如我们刚才所观察到的那个过程,客户端发出请求,在其Servlet容器的代码中,首先是一个名为"Acceptor"的对象。

该"Acceptor"对象接收到客户端的请求后,随即创建一个"SocketProcessor"。

大家应该对这个名字有所了解,它与网络通信有关,它打开了一个Socket,并将此对象传递给从线程池中获取的一个线程。

正如我们所提到的,我们使用线程池来控制线程数量的上限和下限。因此,它从线程池中取出一个空闲线程,并将"SocketProcessor"交给该线程,然后开始读取网络数据。
整个读取过程都在线程范围内完成。如果读取速度很慢,它将一直占用线程。当读取完成后,线程才会调用Servlet对象的service方法,然后根据请求类型调用其doDelete、doPut或doGet方法。读取完成后,它会生成一个HTTP响应,并依靠"SocketProcessor"将HTTP响应传回给前端。
无论是产生HTTP请求还是获取HTTP响应,整个过程都是在线程中进行的。直到最后完成并将其放回线程池,供下一个请求使用。因此,它被称为阻塞式I/O方式,也就是所谓的"Blocked IO"。之所以如此命名,是因为在线程的I/O过程中,该线程一直被占用。这是传统模式,默认情况下仍采用这种模式。
![]()

这种模式与传统模式的不同之处在于,I/O不在线程范围内。它是如何实现的呢?
前面提到,请求仍然由一个"Acceptor"处理,当请求到达时,也仍然是一个"Acceptor"。然而,在这种情况下,它不是创建一个"SocketProcessor",而是创建一个名为"NioChannel"的对象。

这是什么呢?它同样能够接收来自客户端的数据,并将其放入缓冲区中。关键是,当传输完成后,"NioChannel"将产生一个事件,表示数据已经读取完成。
因此,它会将"NioChannel"放入一个事件列表或队列中。无论前面有多少个请求过来,它都会为每一个请求产生一个"NioChannel",并将其放入列表中。此时与线程无关,它只是将其放入列表中。
然后,使用一个独立的"Poller"线程来轮询列表。这个轮询的作用是查看哪个通道已经读取完成。

一旦某个通道读取完成,后续操作与我们之前所描述的"BIO"相同。它仍然会创建一个"SocketProcessor",将读取完成的数据交给"SocketProcessor",然后将其交给一个线程。接下来的步骤与之前相同。
![]()
首先是读取过程。当线程获得"SocketProcessor"时,将数据从读取状态转换为HTTP请求时,此时没有延迟,因为数据已经准备好并放入缓冲区,所以可以直接进行解码,并将其转换为HTTP请求对象。然后执行后续操作,如调用service方法,根据请求类型调用doGet、doPut或doDelete方法。在获得HTTP响应后,它仍然会将其返回给"SocketProcessor",然后将其传回"NioChannel"。线程就完成了其使命,然后再次回到线程池中。
"NioChannel"会负责将数据传回给前端。整个I/O过程都发生在这个过程中,而不是在线程的范围内。线程中只有我们前面提到的部分,或者是这个部分,或者是那个部分,具体取决于实现方式。总之,前面的读取和后面的发送都不在该线程的范围内。

Compute
进入NIO时代或者APR时代。
APR也是异步的,只不过与NIO的异步方式不同。它是使用原生代码来实现的,因此速度更快,I/O速度也会更快。进入这个时代之后,当我们考虑线程池时,我们只考虑其中间部分的计算消耗。无论是在Tomcat的NIO还是APR上,我们实际上无法进行优化,因为当您进行数据库读写时,I/O会阻塞。
对于计算部分来说,它仍然会阻塞。如果想要进一步提高效率,我们只能放弃Servlet这种架构,转而使用Reactive Stack,完全采用函数式编程。通过将与数据库交互的这些慢速操作从代码中分离出来,您才有可能将这些慢速操作转换为事件响应方式。
将非慢速操作转换为可以直接在CPU上调度的方式,才能进一步提高性能。
技术的发展已经很明显,它是一步一步地将代码中与I/O相关的部分分离出来,无论是网络I/O还是本地I/O部分。只有在将这些部分从代码中分离出来之后,它才可能在多线程上进行更进一步的优化。如果不进行分离,实际上是不可能的。就目前而言,对于命令式编程来说,最优化的方式就是采用APR。其中实际上还包括了一些本地数据库的I/O操作。由于命令式编程,即Servlet堆栈,并未将这部分代码分离出来。