如何使用AMR M分析rtp流中的amr语音
进行媒体服务器开发,经常要分析RTP中的媒体流,用来确定通话中是否存在问题。通过tcpdump抓取网卡包,用wireshark可以打开网卡包,对于pcma或pcmu的语音包可以播放,但是对于amr格式的抓包却无法播放。
笔者分享最近找到一款amr工具amr master。该工具结合wireshark可以网卡包中的amr语音流转出.amr文件,采用vlc player可以进行播放。
具体步骤如下:
1.用wireshark将网卡包中的语音流剥离出来,保存为.raw格式文件。
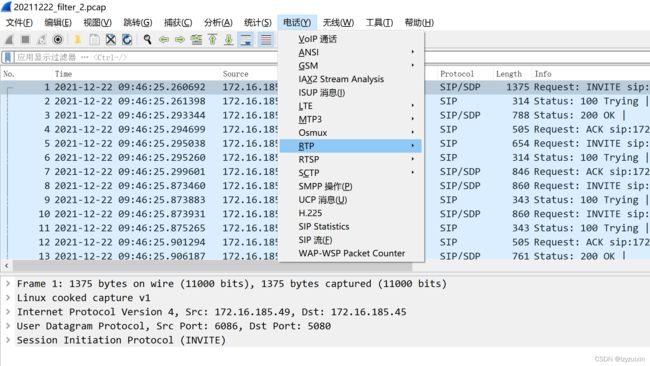
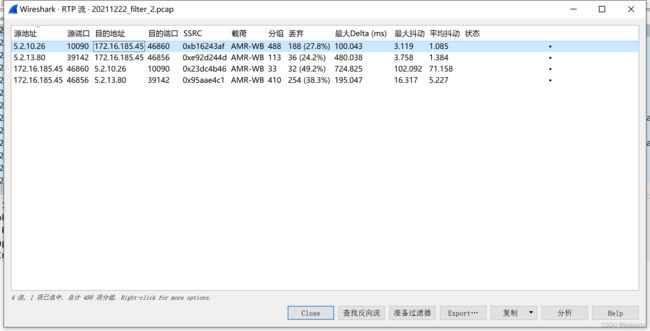

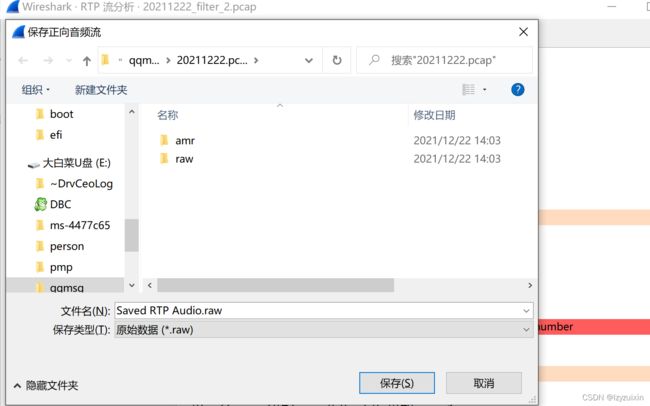
2.关于amr master
amr master是用pyton编写的工具,它的下载链接如下 GitHub - suma12/amr: Conversion of raw AMR RTP payload packets to .amr storage format。
它的实际代码如下:
#
# Conversion of raw AMR RTP payload packets to .amr storage format
#
# Petr Tobiska
# License: LGPL 2.1
VERSION="2016-11-17"
import argparse
import unittest
from struct import pack
from binascii import unhexlify
class BitIterator:
"""Read consequently n-bit bitstreams from bitstream in data"""
def __init__(self, data):
self.data = data + '\0' # stop mark
self.offset = 0
def read(self, n):
if n < 0 or n + self.offset > 8 * len(self.data) - 8:
raise IndexError
if n == 0:
return ""
i = self.offset >> 3 # the first byte of data to process
sh = self.offset % 8 # shift data -> output
x = ord(self.data[i])
dataout = []
for _ in xrange((n + 7) >> 3): # number of bytes to output
val = (x << sh) & 0xFF
i += 1
x = ord(self.data[i])
val |= x >> (8 - sh)
dataout.append(val)
self.offset += n
nb = 8 - n % 8 # number of bits to mask out
if nb < 8:
mask = 0x100 - (1 << nb)
dataout[-1] &= mask
return ''.join([chr(val) for val in dataout])
def byte_align(self):
"""Align offset forward to byte boundary"""
self.offset = (self.offset + 7) >> 3 << 3
def notEnd(self):
return self.offset < 8 * len(self.data) - 8
def __str__(self):
i = self.offset >> 3
sh = self.offset % 8
s = ''
s = ' '.join([ "{0:08b}".format(ord(c)) for c in self.data[:i]])
if sh > 0:
s += " {0:08b}".format(ord(self.data[i]))[:1+sh]
s += ' | '
if sh > 0:
s += "{0:08b} ".format(ord(self.data[i]))[sh:]
i += 1
s += ' '.join([ "{0:08b}".format(ord(c)) for c in self.data[i:-1]])
return s
class BitMerger:
"""Merges fragments into one bitstream."""
def __init__(self):
self.offset = 0 # 0 <= offset < 8
self.complete = []
self.lastVal = 0 # valid only if offset > 0
def bitlen(self):
return 8*len(self.complete) + self.offset
def put(self, data, bitlen):
"""Append bit fragment"""
datalen = 8*len(data)
if bitlen < datalen-7 or bitlen > datalen:
raise IndexError
if bitlen == 0:
return
for x in [ord(c) for c in data]:
if self.offset == 0:
self.complete.append(x)
else:
self.complete.append(self.lastVal | (x >> self.offset))
self.lastVal = (x << (8-self.offset)) & 0xFF
bitlen = self.offset + bitlen % 8
if 0 < bitlen < 8:
self.lastVal = self.complete.pop()
self.offset = bitlen % 8
mask = (0xFF << (8-self.offset)) & 0xFF
self.lastVal &= mask
def result(self):
res = ''.join([chr(val) for val in self.complete])
if self.offset > 0:
res += chr(self.lastVal)
return (res, self.bitlen())
def __str__(self):
s = ' '.join([ "{0:08b}".format(i) for i in self.complete])
s += " {0:08b}".format(self.lastVal)[:1+self.offset]
return s
###########
# AMR class for raw -> .amr conversion
###########
class AMR:
"""Representation of AMR storage format
Neither interleaving nor CRC are supported."""
# indexed by zWB; see 3GPP TS 26.101 (AMR) and 26.201 (AMR-WB)
SPEECHBITS = {False: (95, 103, 118, 134, 148, 159, 204, 244, 39),
True: (132, 177, 253, 285, 317, 365, 397, 461, 477, 40)}
NMODES = {False: 8, True: 9}
NODATA = {False: 15, True: 14}
def __init__(self, zWB=True, zOctetAlign=True, nCHAN=1):
self.zWB = zWB # AMR: False, AMR-WB: True
self.zOctetAlign = zOctetAlign # octet-align
self.nCHAN = nCHAN # number of channels
self.fileOut = None
assert 1 <= nCHAN <= 6, "Wrong nCHAN"
self.invalidMode = (AMR.NMODES[self.zWB], AMR.NODATA[self.zWB])
self.sample = 0
def round(self, n):
"Round n up to multiple of 8 if zOctetAlign, otherwise do not modify"
if self.zOctetAlign:
n = (n + 7) >> 3 << 3
return n
def process(self, data):
"""Read frames from data stream and process them"""
b = BitIterator(data)
while b.notEnd():
header = b.read(self.round(4))
# dirty hack to skip inserted '0'
while header == '\0':
header = b.read(self.round(4))
toc = []
while True:
t = ord(b.read(self.round(6)))
toc.append(t & 0x7C) # mask F and R bits
if t & 0x80 == 0: # break for the last entry
break
for t in toc:
mode = t >> 3
assert mode <= self.invalidMode[0] or \
mode >= self.invalidMode[1]
self.fileOut.write(chr(t))
self.sample += 1
if mode <= self.invalidMode[0]:
nbits = AMR.SPEECHBITS[self.zWB][mode]
speechf = b.read(self.round(nbits))
self.fileOut.write(speechf)
b.byte_align()
def processFile(self, fileName):
with open(fileName, "rb") as f:
self.process(f.read())
def openOutput(self, fileName):
"""Open output file and write magick"""
if self.nCHAN == 1:
magick = self.zWB and "#!AMR-WB\n" or "#!AMR\n"
else:
magick = self.zWB and "#!AMR-WB_MC1.0\n" or "#!AMR_MC1.0\n"
magick += pack(">I", self.nCHAN)
self.fileOut = open(fileName, "wb")
self.fileOut.write(magick)
def closeOutput(self):
if self.fileOut:
self.fileOut.close()
self.fileOut = None
##############
# unittest for BitMerger & BitIterator
# to run:
# $ python -m unittest amr.TestBit
##############
class TestBit(unittest.TestCase):
def template(self, fragList, result):
m = BitMerger()
b = BitIterator(result[0])
for frag in fragList:
m.put(*frag)
d = b.read(frag[1])
norm = BitMerger() # normalized string - with masked bits
norm.put(*frag)
self.assertEqual(d, norm.result()[0])
self.assertEqual(m.result(), result)
def test1(self):
fragList = ((unhexlify('AA'), 8),
(unhexlify('55'), 8))
bitlen = sum([frag[1] for frag in fragList])
result = unhexlify('AA55'), bitlen
self.template(fragList, result)
def test2(self):
fragList = ((unhexlify('AA'), 8),
(unhexlify('55'), 6))
bitlen = sum([frag[1] for frag in fragList])
result = unhexlify('AA54'), bitlen
self.template(fragList, result)
def test3(self):
fragList = ((unhexlify('AA'), 3),
(unhexlify('55'), 4))
bitlen = sum([frag[1] for frag in fragList])
result = unhexlify('AA'), bitlen
self.template(fragList, result)
def test4(self):
fragList = ((unhexlify('AA'), 3),
(unhexlify('5B'), 5))
bitlen = sum([frag[1] for frag in fragList])
result = unhexlify('AB'), bitlen
self.template(fragList, result)
def test5(self):
fragList = ((unhexlify('AA'), 6),
(unhexlify('5B'), 7))
bitlen = sum([frag[1] for frag in fragList])
result = unhexlify('A968'), bitlen
self.template(fragList, result)
################
# main program
################
if __name__ == '__main__':
parser = argparse.ArgumentParser(prog='amr.py',
description="Convert raw AMR RTP stream to .amr")
parser.add_argument("-w", "--wideband", action='store_true',
help="raw is AMR-WB (AMR if False)")
parser.add_argument("-a", "--octet-align", action='store_true',
help="raw is octet-align (bandwidth eff. if False)")
parser.add_argument("-n", "--n-chan", help="number of channels (1-6)",
type=int, action='store', default=1)
parser.add_argument("raw", help="raw file")
parser.add_argument("amr", help="amr file", nargs='?')
parser.add_argument("-v", "--verbose", action='store_true')
parser.add_argument("-V", '--version', action='version',
version='%(prog)s ver=' + VERSION)
args = parser.parse_args()
assert 1 <= args.n_chan <= 6, "number of channels shall be 1-6"
if args.amr is None:
i = args.raw.rfind('.raw')
if i > 0:
args.amr = args.raw[:i] + '.amr'
else:
args.amr = args.raw + '.amr'
if args.verbose:
print args.wideband and "AMR-WB," or "AMR,",
print args.octet_align and "octet-align," or "bandwidth efficient,",
print "%d channel(s)" % args.n_chan
print "Files: %s -> %s" % (args.raw, args.amr)
a = AMR(zWB=args.wideband, zOctetAlign=args.octet_align, nCHAN=args.n_chan)
a.openOutput(args.amr)
a.processFile(args.raw)
a.closeOutput()
if args.verbose:
print "Done, %d samples converted" % a.sample
3.执行环境
CentOS 7.4
#python -V
Python 2.7.5
4.命令执行用例
# python ./amr.py -w -n 1 -v a_upwb.raw
AMR-WB, bandwidth efficient, 1 channel(s)
Files: a_upwb.raw -> a_upwb.amr
Done, 1088 samples converted
假设a_upwb.raw为保存的AMR-WB rtp raw包, bandwidth efficent模式
5.采用vlc 播放
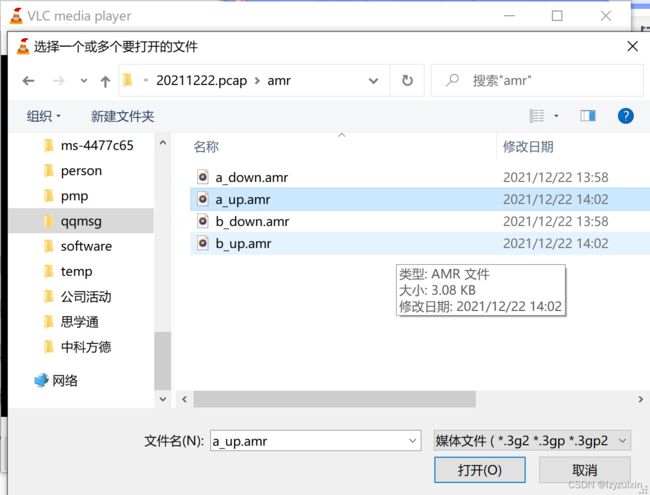
总结
采用wireshark剥离出raw文件,用amr master的pyton脚本工具将raw文件转出amr文件,用vlc player进行播放。这是目前为止发现的一个比较有效播放amr的工具组合。希望该文对于从事媒体通信的同行有起到帮助。