2020/05/12 dashboard插件详解及k8s实战交付1
4.1 回顾1
K8S核心资源的管理方法,三种方法:
陈述式管理,基于kubectl命令
声明式管理,基于k8s资源配置清单,yaml或者json(pod,pod控制器,service对象,ingress对象,都抽象成一个个机构化文件,yaml或者json)
GUI式管理,基于k8s仪表盘(dashboard)

k8s还有4个核心附件,真正要搭建k8s集群,除了2进制方法去交付master组件和node组件以外,还必须有4个核心附件:CNI网络插件,服务发现插件,服务暴露的插件,gui图形管理插件。
只有这4个辅助插件,才能让k8s更好工作
clico这个网络插件,适合大的k8s集群,用flannel集群不大,选择host-gw,因为走的是内核,效率还是比较高的,但是vxlan就不行,要反复在用户空间过滤,效率比较低。
flannel在100台左右就足够用了
现在做个flannel实验,用之前的半成品k8s,并不用实操
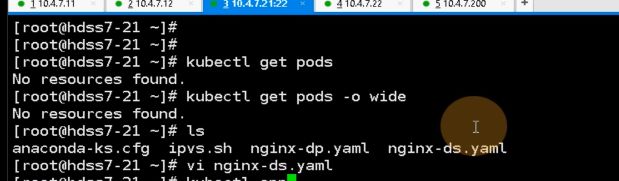
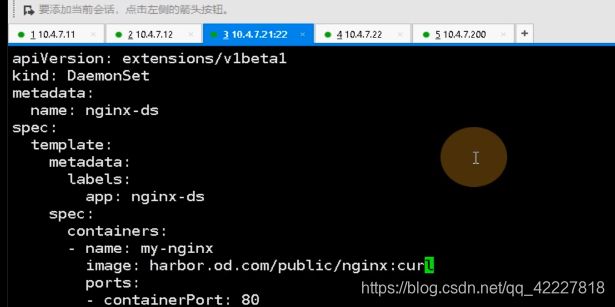


没有,需要pull一个镜像下来,放到harbor里


给这个镜像打一个tag,push到自己的harbor仓库


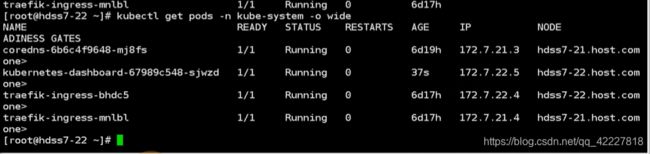
把这个pod删除了
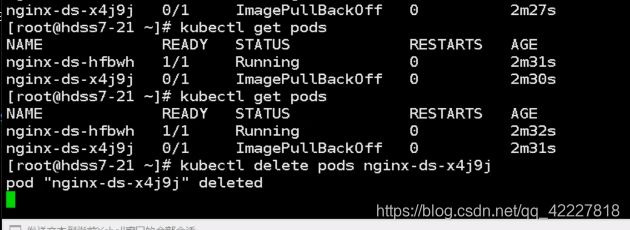
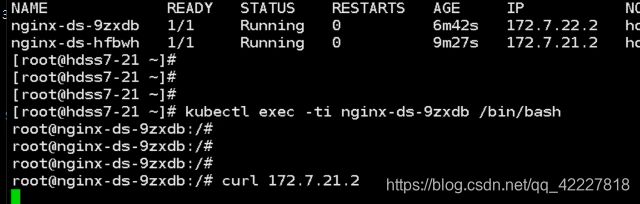
看一下是否有自愈的功能,已经running起来了,两个podip是172.7/22.2/172.7.21.2,k8s有三条网络,节点网络用10段的私有IP,pod用172.0,clusterip用的时候192

ping本机的肯定通,ping对端的,现在没有flannel肯定不通,flannel最简单的host-gw模型就是加路由,其他什么也没做
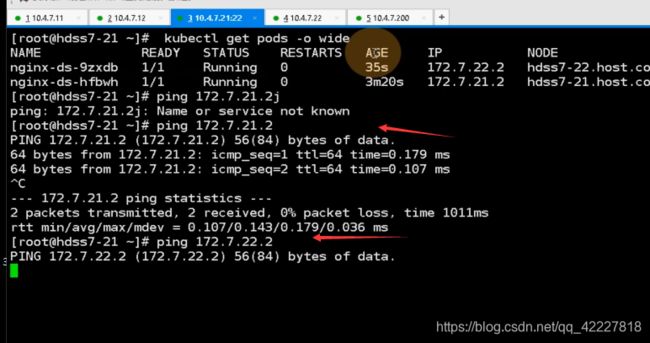
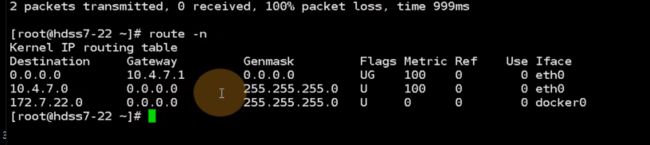

不仅要加路由,还有优化一条iptables规则,想让10.4.7.21这台主机代理docker的172.7.21.0/24这个网段,要加一条iptables规则,应该在filter表的forward的上去加,目的地址是172.7.21.0/24
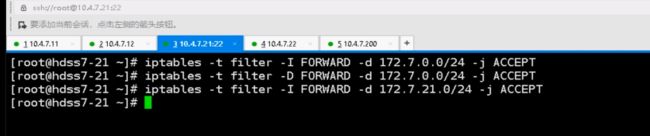
现在就ping通了
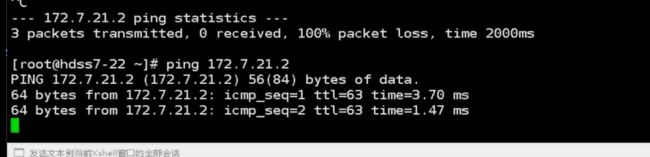
在21上也加一下


现在就通了


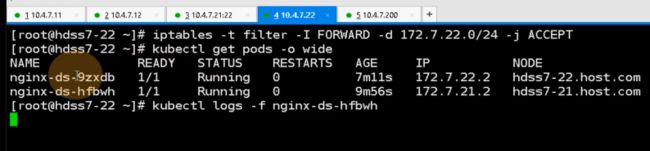
这边日志就进来了

flannel真正要用就取优化snat规则,不能在集群内部pod访问,还要经过snat转换,否则宿主机效率就低了,所以k8s集群如果小,不用装flannel,自己就实现了。
用CNI网络插件就是实现pod和pod之间互相网络通信。
flannel好处就是,本身有监控状态检查接口,2041,委托给supervisor,进程异常退出,supervisor还能拉起来
4.2 回顾2
把之前的环境退出
flannel,三种工作模式,host-gw,vxlan,混合模式

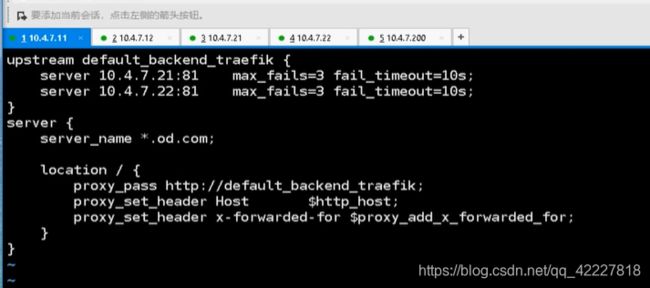
服务发现,3个比较重要的概念,k8s本身抽象出了两种资源(集群网络,不在宿主机上真实存在,只在集群里存在交互使用,用kube-proxy把集群网络和pod网络关联起来。kube-proxy不给pod提供网络承载环境,pod的ip可能宕机,扩容,pod是动态变换的,podip是不能作为服务接口的唯一的接入点,抽象出一种资源,固定的资源去指向对应的pod,也就是service,service借助标签选择器找到对应pod,把流量指到这一组pod上)
服务发现就是把这两个关联起来,使用了coredns软件,go语言写的,就是把集群网络和service名字关联起来,在使用服务的时候就不用记录cluster ip了,只要记录service名字就可以了,自动关联的

服务暴露有非常抽象的概念,ingress资源,专属暴露7层应用到k8s集群外的一种核心资源(http/https,很少用https(把https放到生一层,去卸证书,这样回来也是http))
ingress控制器,简化版的nginx(根据域名和url来调度流量)+go脚(动态识别资源配置清单yaml)
用traefik软件去实现了ingress控制器

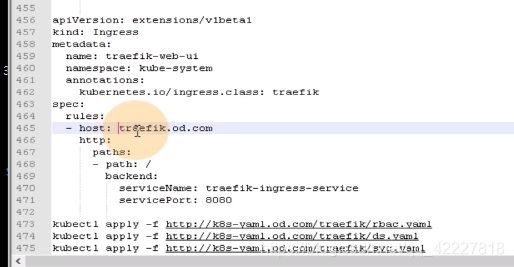
去前端域名进来,找到了后端两个real server真实提供服务的pod,起traefik是以daemonset来起的,每一个运算节点上起一份,所以能看到的两个是podip
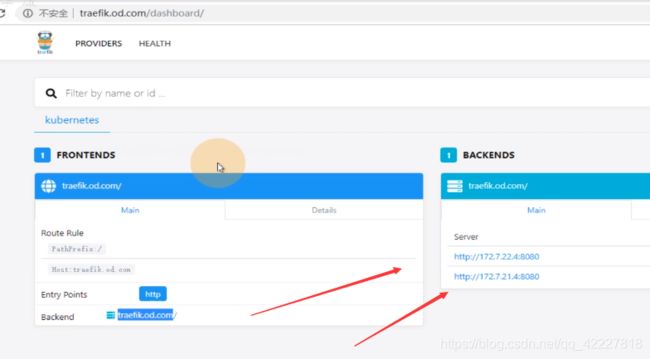
host是从traefik.od.com进来的,path:/,backend抛给traefik-ingress-service
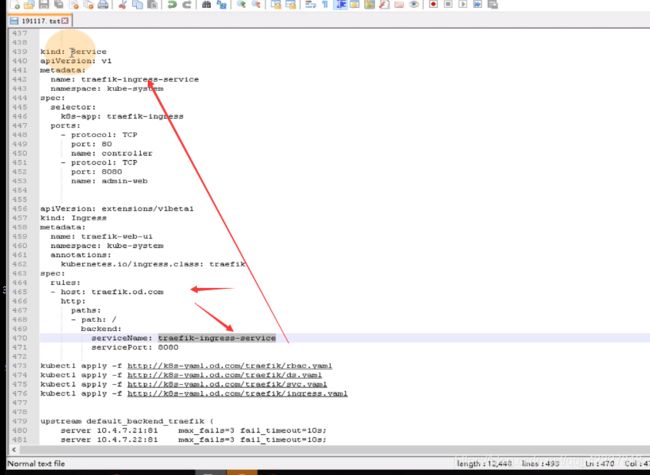
service又通过标签选择器selector,到k8s-app:traefik-ingress,这一个标签
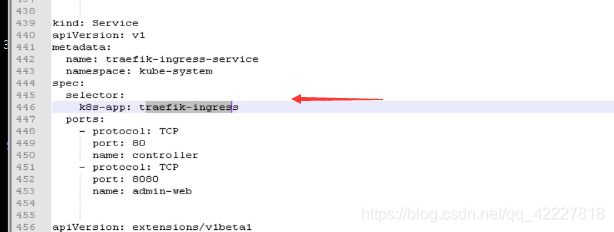
再看daemonset,daemonset是每一个节点都要起一个pod的,这样才能决定怎么把traefik的流量怎么帮你真正调度到pod里。
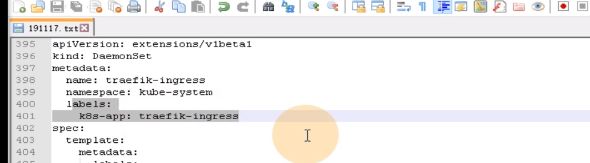
traefik软件主要实现两个功能,ingress控制器,有hostport:81这个配置,就是ingress控制器部分是和你宿主机共享网络名称空间。
还有一个pod是admin-web,跑的是8080端口
**docker有4种网络模式,none,NAT,host,combine两个容器用一个网络名称空间,边车模式
**
这个traefik.od.com实际上是一个admin-web的接入点,借助treafik本身的ingress控制器,帮你找到172.7.21/22.4:8080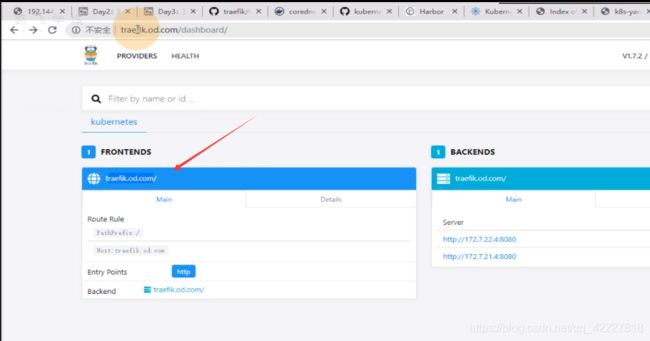
traefik软件的dashboard,是用了自己的ingress controller实现了自己,这里是用的和宿主机一样的网络名称空间,8080是admin-web

建立一个ingress资源,从traefik。od.com进来是找下面ingress-service的8080端口你。
80是ingress控制器,8080是admin-web,traefik是两个功能
4.3 dashboar插件安装部署
最后一个核心插件,dashboard,仪表盘
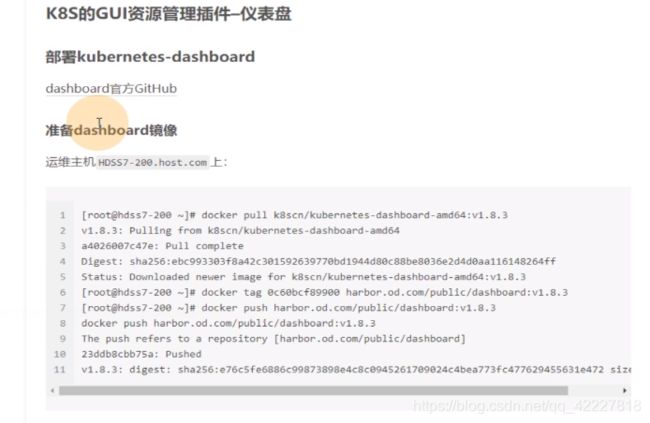
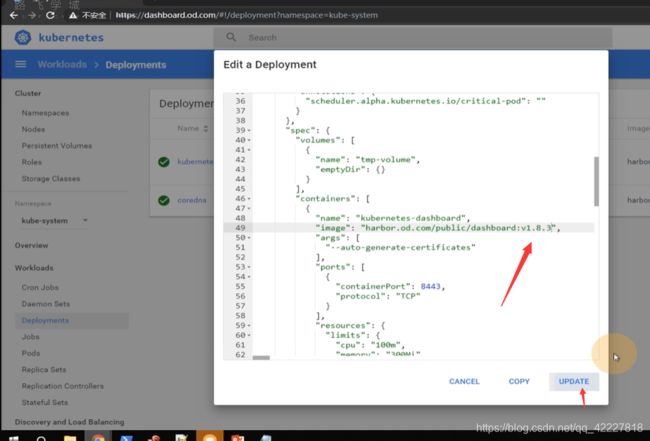
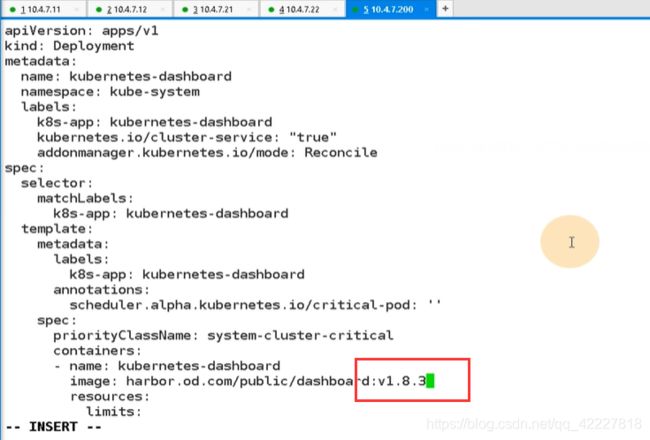
先交付1.8.3,再去交付1.10.1,要把dashboard作为一个容器注入到k8s里面去(第一步下载镜像,第二步准备资源 配置清单,依次应用到集群里)

打tag,推到harbor仓库里

名字写错了

现在完成了一个dashboard的镜像,下一步准备dashboard的资源配置清单
资源配置清单也是在官方上找的,到google官方kubernetes仓库
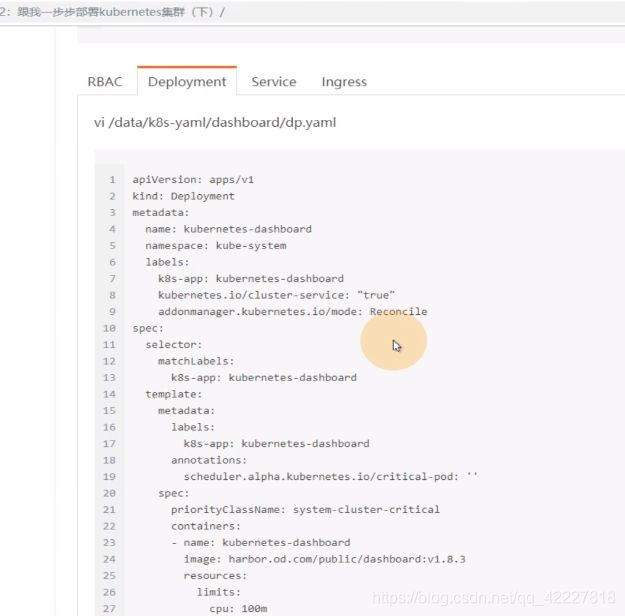
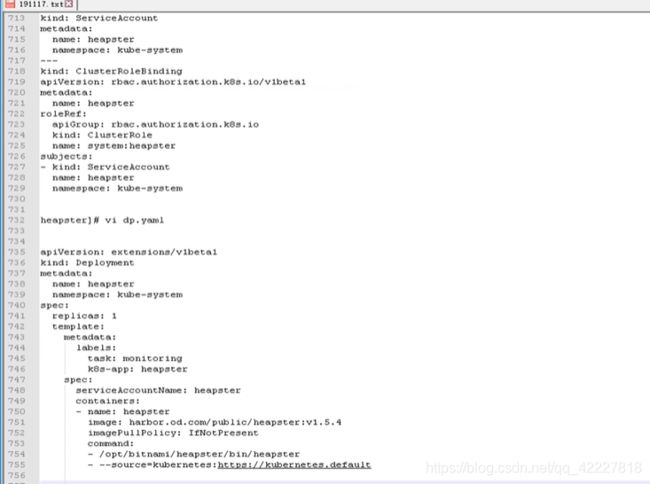
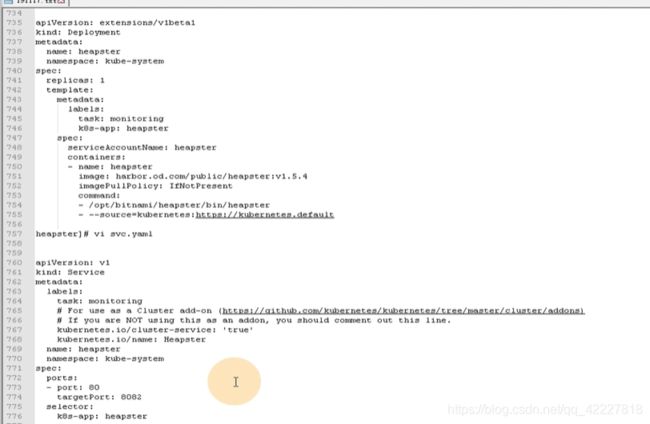
dp.yaml
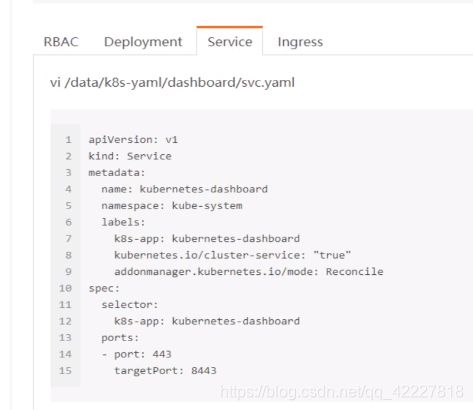
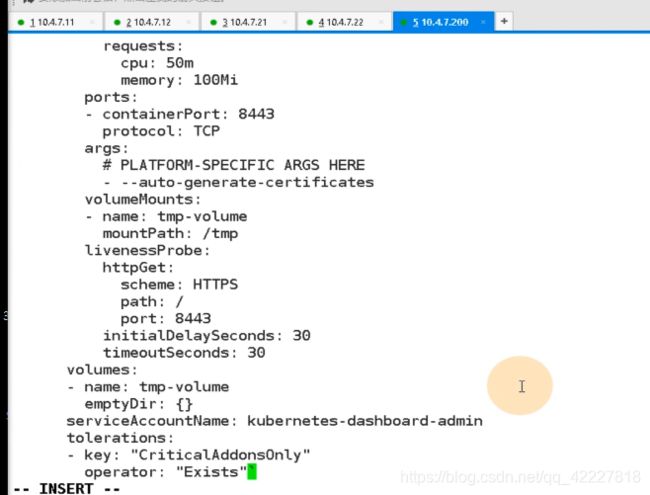
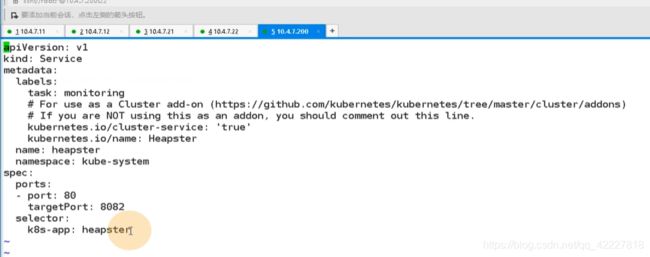
svc.yaml
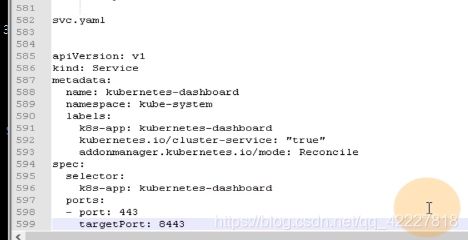
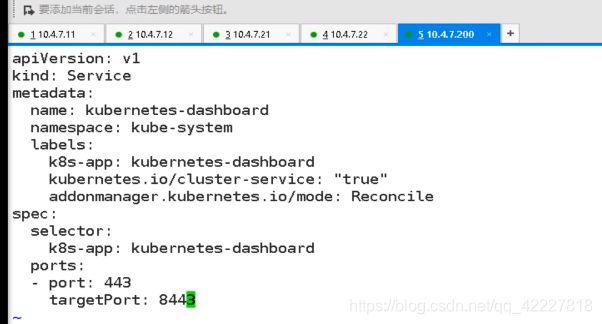
ingress.yaml
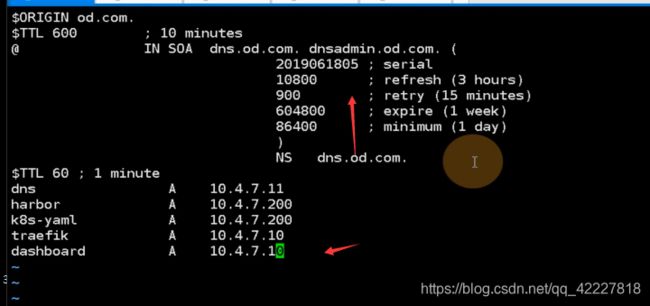
暴露给集群外面,就要起个名字dashboard.od.com,通过访问这个域名就能访问dashboard容器 
放到yaml仓库里

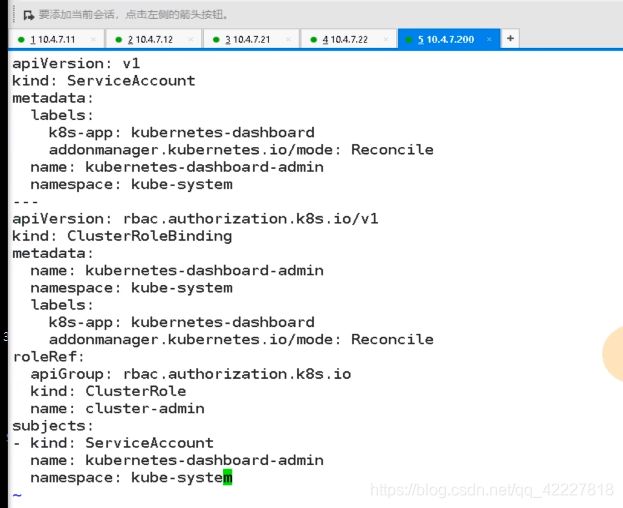
dp.yaml
![]()

svc.yaml

ingress.yaml
![]()
dashboard里有四个文件,这就是为什么kubelet可以指定网络文件
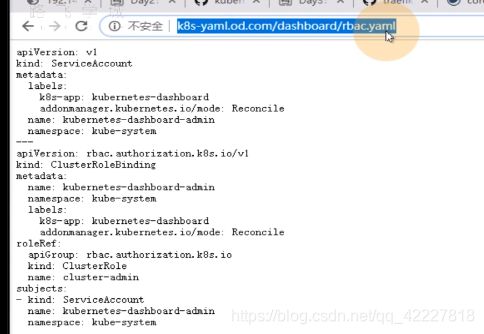
如果想直接apply -f文件,点击raw
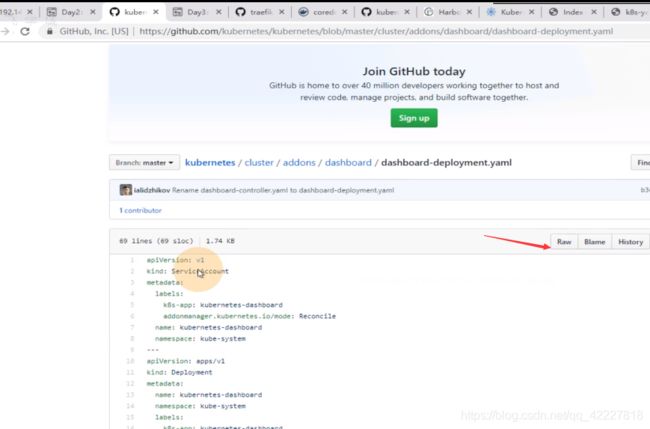
就可以直接复制上面的地址
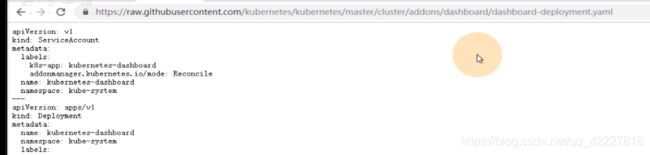
任选一个运算节点去应用这个dashboard配置清单,把用户权限创建好
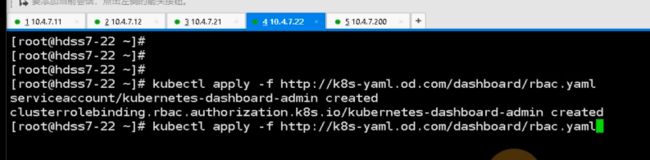
容器应用进来

把service资源创建出来

应用ingress.yaml

官方的是用的pod控制器是deployment,默认放在kube-system命名空间
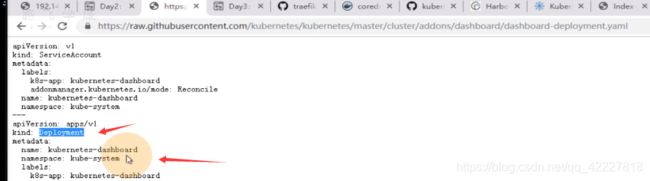
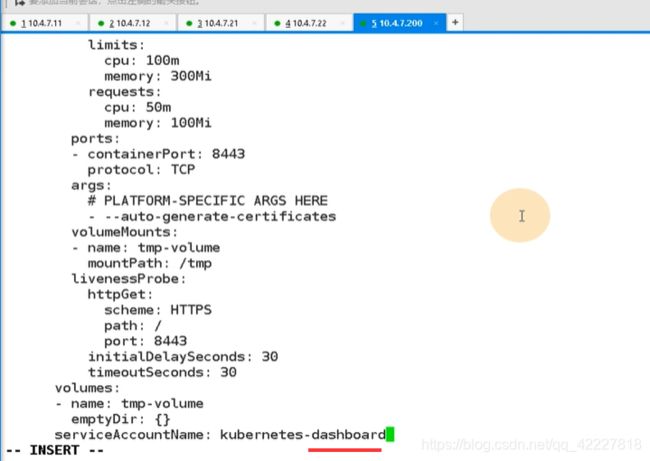
给了个limit,相当于限制容器启动资源,request指的就是容器起来就要吃多少资源,资源不满足,容器起不来,limits,最多容器吃多少资源
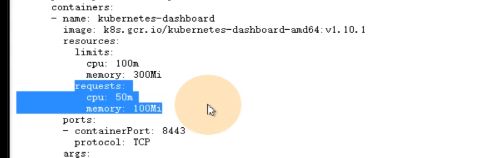
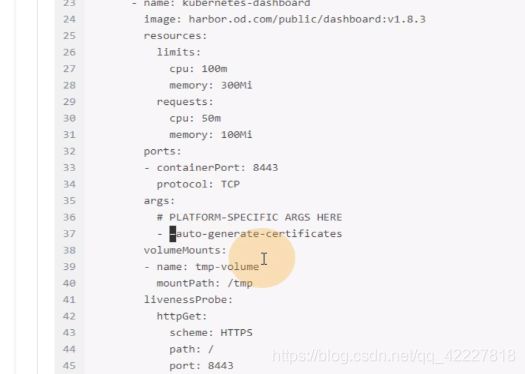
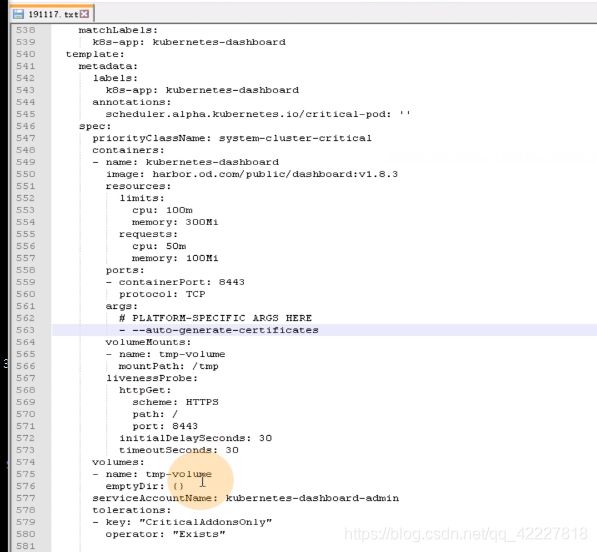
这里相当于启动dashboard的运行参数,自动生成证书,挂在两个目录,certs和tmp目录
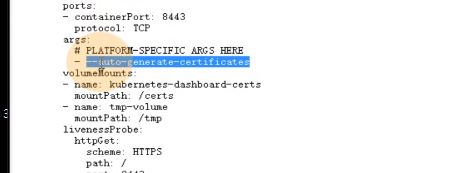
容器的存活性探针,在k8s里,给容器两个探针,存活性探针,就绪性探针,
存活性探针:判断你的容器在k8s环境下是否正常启动,或是在运行中,是否有异常退出。
就绪性探针:就是容器被k8s拉起来以后,先用就绪性探针去探测直到满足要求,才认为是就绪状态 running,才认为是running状态,
livenssprobe:在容器不断运行的过程中,不断的探测你是否存活,就是存活性探针。
schema协议,去探测容器里的8443端口,只要8443端口活着就认为你是容器活的,如果死了,就启动自愈机制,

volume就是定义的存储卷

containers 的name是给容器起一个名字

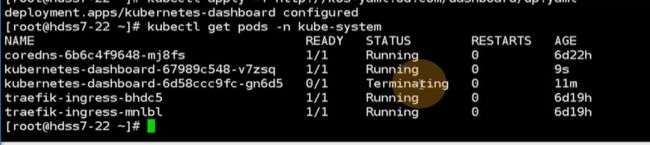
dashboard已经起来了
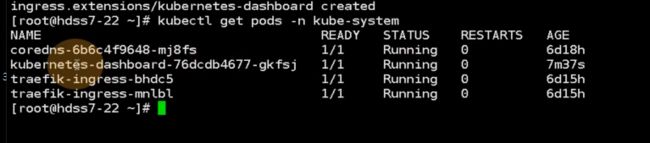

现在浏览器访问直接访问域名即可

需要做dns解析,滚动版本号
前面的nginx其实是7层的总入口,只要符合匹配.od.com这个域名,都要从7层进来,负载均衡抛到ingress controller上*
生产中有点粗鲁直接restart,其实可以用rndc,去reload named里的值,所有区域的数据应该加载内存里,resatrt相当于把内存清空,区域多,这个restart就伤了,所以一般用rncd去指定reload的指定区域


coredns指向forward的上一级dns是非常有必要的,自建的coredns和上一级dns有forward关系

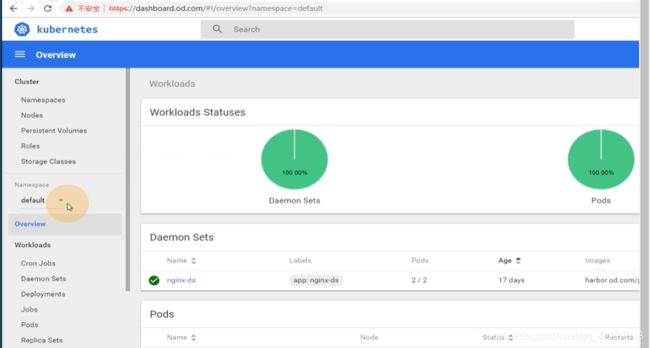
dashboard页面现在是,1.8.3
4.4 K8S的RBAC原理详解
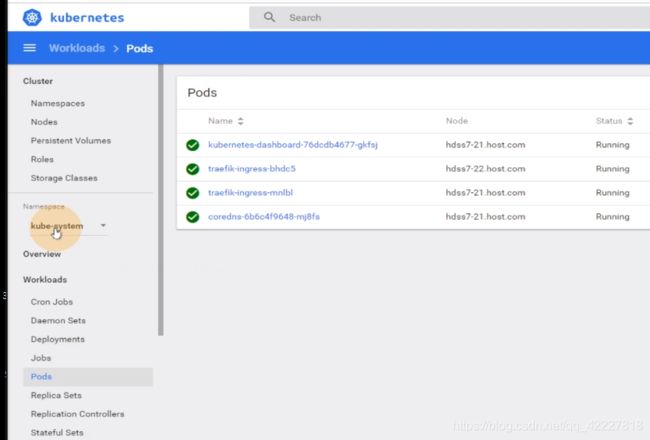
kube-system下实例了两个deployment,核心资源,一个是coredns,一个是dashboard
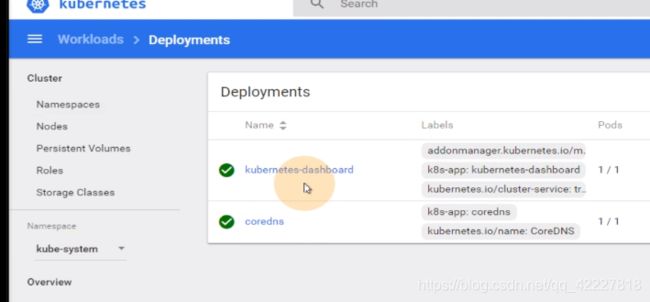
traefik在daemonset里,两个pod控制器需要掌握,daemonset,deployment

这里使用json格式来展示的yaml
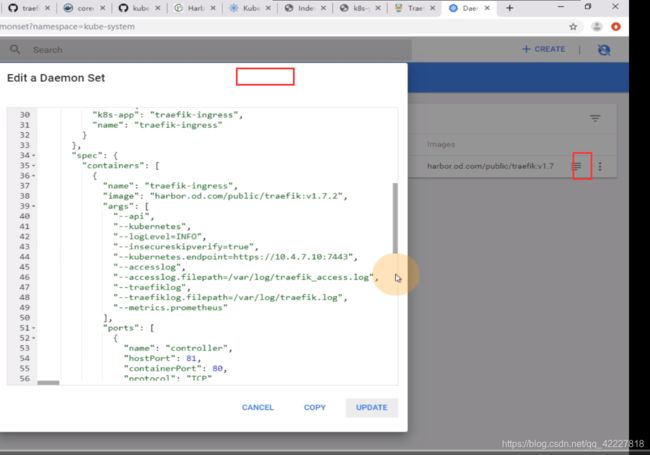
spec就是真正定义pod控制器的属性,selector就是标签选择器,
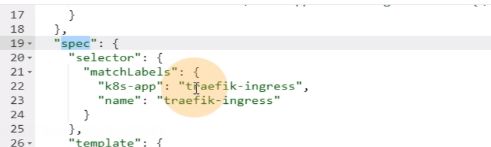
下面就是定义一个template模版,实际上是pod的模版,pod的一些特性就被定义到了pod控制器里,pod资源本身是一组对象,启动参数,内容,挂载,存活性探针都可以定义到pod控制器里
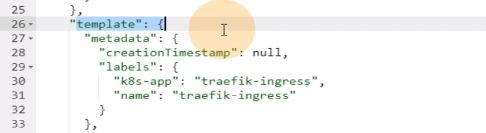
里面有一堆启动参数
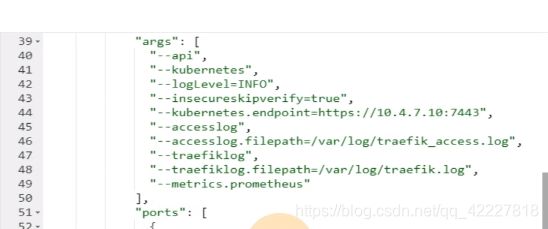
一个是暴露81端口,一个是用nat的网络8080
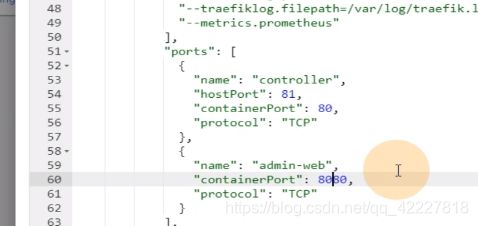
resource是限制你pod的资源的
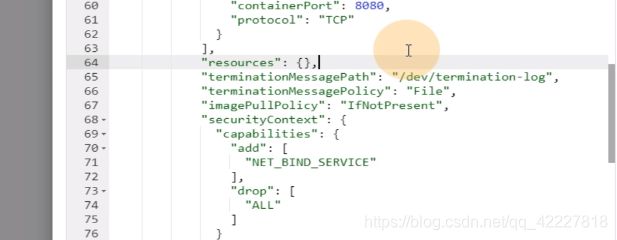
从spec到这都是pod特性,可以用explain来看显示的意思
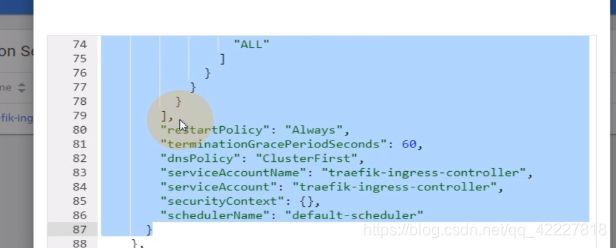
serviceaccount服务账号,牵扯到了k8s的核心理念,rbac
![]()
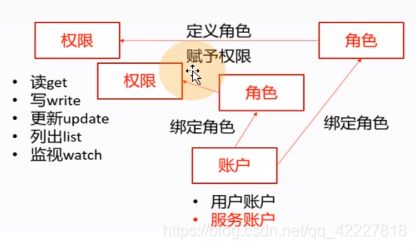
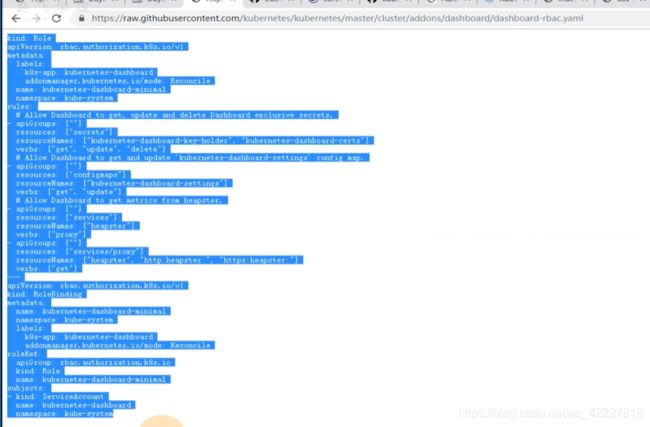
基于角色的访问控制,RBAC(role basic access control)

对一些资源有一些权限(读get,写wirte,更新update,列出list,监视watch),用户就有用户账户,在k8s里有两种账户(用户账户user accoun UA,服务账户 service account SA)。
之前启动kubelet的时候做了一个kubeconfig配置文件,这个kubeconfig配置文件就是用户的配置文件
这个名字就是k8s集群里的一个用户账户,用户账户的名字就叫k8s的node
什么样的账户什么样的权限,这个就是授权的过程,k8s基于角色的访问控制下,无法直接给账户赋予权限,只能通过中间的一个角色,先给用户账户和服务账号先去绑定响应的角色,然后给相应的角色赋予相应的权限,也就是等于中间收个过路费
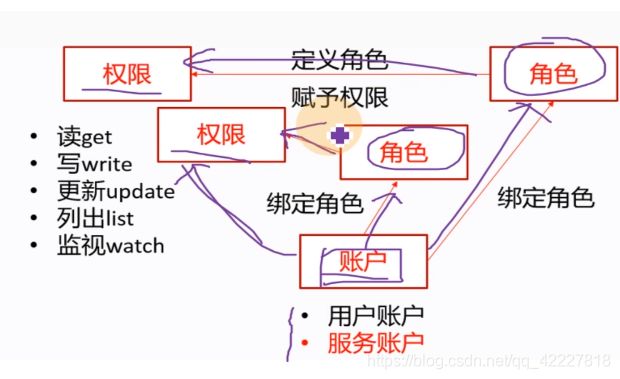
角色就完美充当了,账户要想获得集群里相应权限的中间人,无法给账户赋予直接的权限。
**
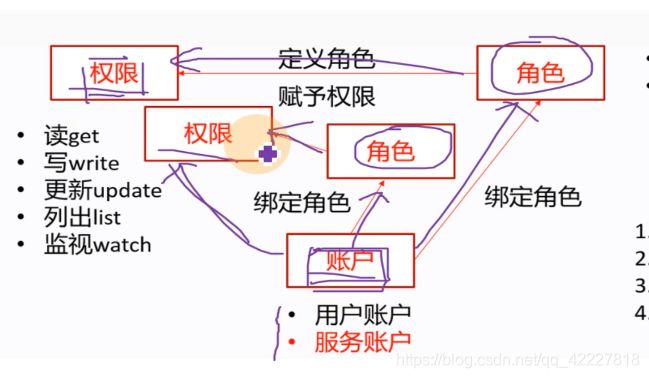
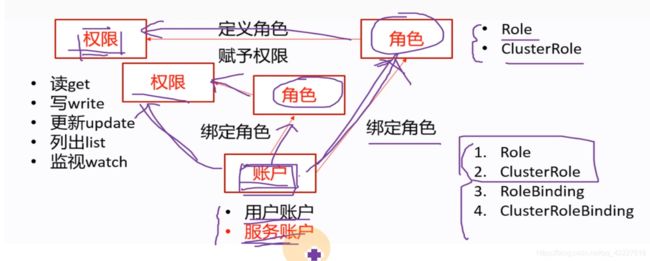
在k8s里有两种角色(role普通角色(只能应用在某一个特定的名称空间下,比如kube-system名称空间,就可以给kube-system里创建相应的角色,如果create一个role资源指定了-n namespace=kube-system,name这个角色只对本名称空间有效),clusterRole集群角色,对集群整个有效)
**
所以绑定角色操作就有2种,role binding,clusterrolebinding,把账户绑定角色,就称为绑定角色,也是一种资源,也有对应的yaml文件
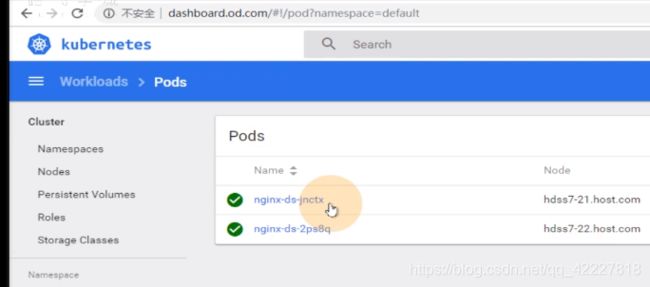
服务账户是所有在k8s里面运行的pod,是k8s最小的运行单元,所有的pod都必须有一个服务用户service account
default名称空间,有两个起来的pod
对应的镜像是nginx;curl
只要运行在k8s集群里的pod,就一定有一个服务账户,如果没有显示指定的服务账户,就给你一个默认的服务账户
traefik的rbac的yaml文件最好看
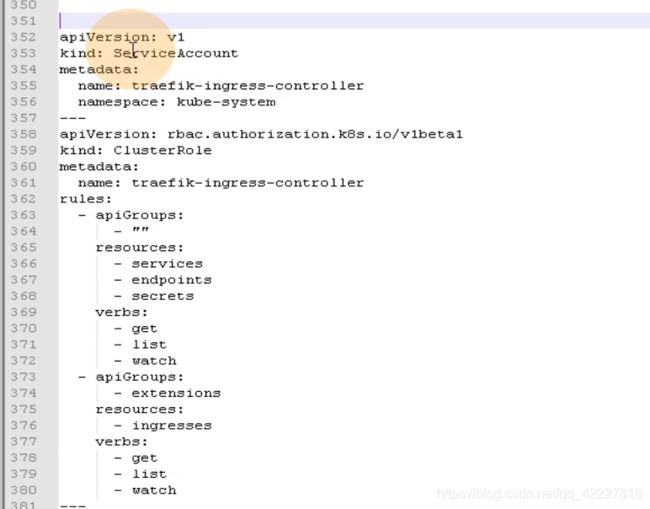
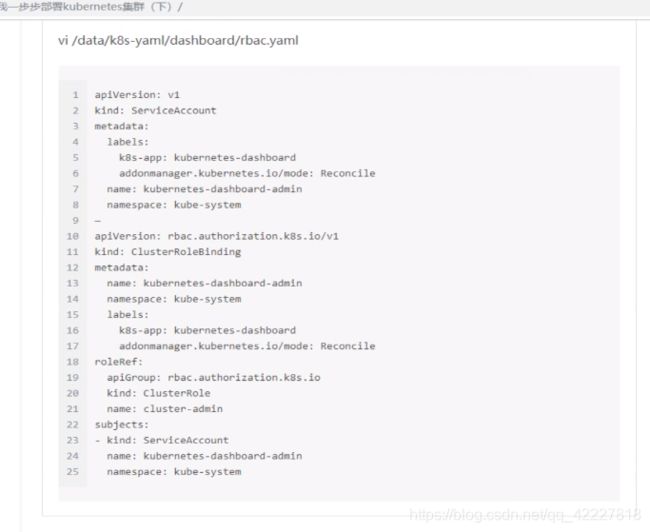
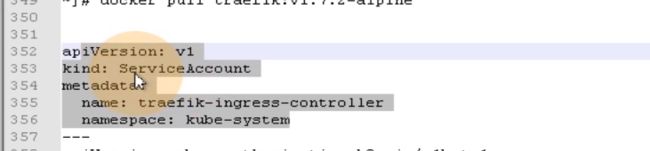
第一段配置声明了一个叫service account的服务用户,这个服务用户的名字叫traefik-ingress-controller。名称空间在kube-system。
实际上这段就创建了服务用户
这一段其实在做clusterRole,相当于去声明一个集群角色,名字叫traefik-ingress-controller。然后定义了一组规则rules:定义角色的同时赋予权限
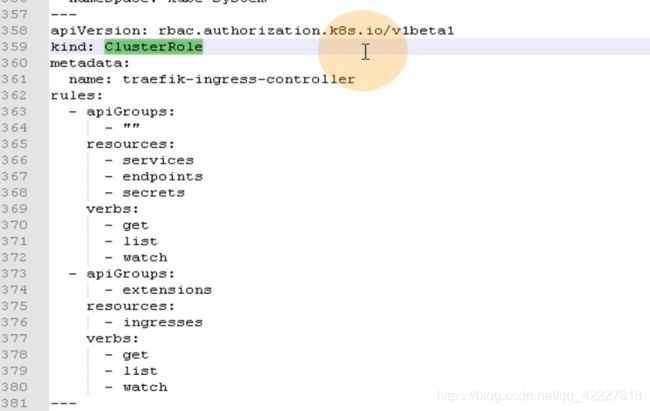
clusterRolebinding集群角色绑定,说白了就是把之前定义的角色和traefik-ingress-controller服务账号关联起来

metadata是name是集群角色绑定的名字,roleref是参考哪个集群角色是traefik-ingress-controller。
subjects就是集群角色给哪个用户使用,类型是服务用户,和集群角色通过clusterrolebinding这种资源,关联起来了
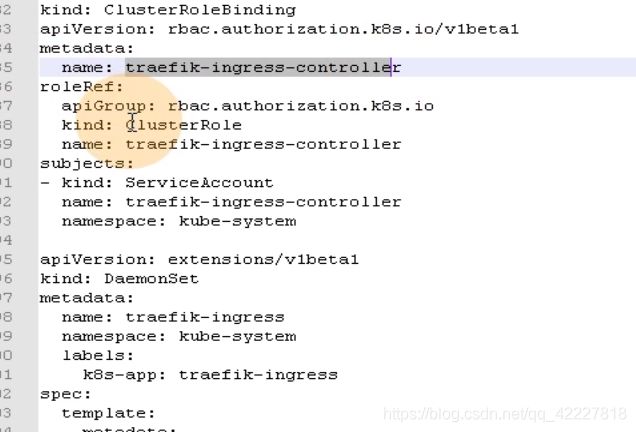
所有的rbac文件,无外乎这几步,创建账户,比如traefik是以pod身份在k8s集群工作,所以只能用服务账号。kubelet就不是工作在k8s里的,是在宿主机上二进制部署的,就不能用服务账户,而是用户账户,只能给kubelete做kubeconfig,kubecetl 4部,setuser,set creditals,seyt context ,use context,创建用户账户就需要这四步,实际上就是去创建一个用户账户的配置文件
traefik是通过pod的方式,交付在k8s里,pod要去取得一定的权限,必须给它创建一个服务账户,第二步就是定义角色去赋予角色相应的权限,就是创建一个clusterRole,就是traefike-ingress-clusterRole。
第三步是绑定角色(账户和角色绑定起来)
这就是RBAC的本质
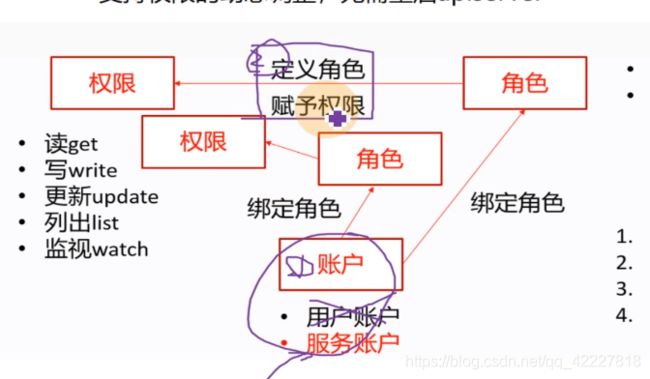
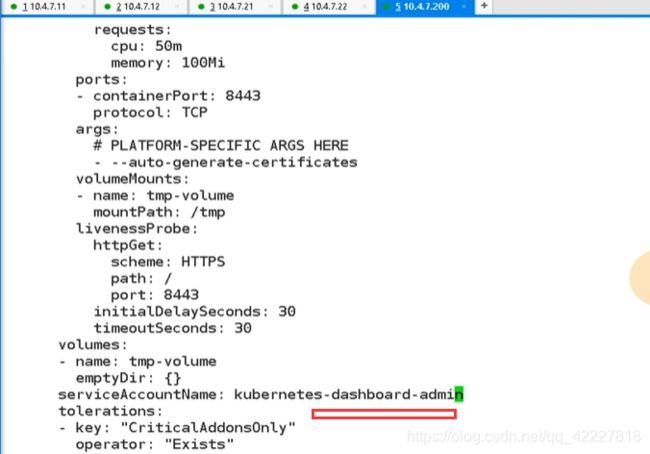
traefik里的daemonset一定就指定你的service accountname就是你刚才创建的serviceaccount。既然有RBAC,就是让pod具有能够调度k8s里相应资源的能力,相当于创建一个serviceaccount账户,然后给这个账户赋予相应的权限,然后要对这个账户做角色绑定。
在声明traefik控制器 的时候,要显示的指令,serviceaccountname就是traefik-ingress-controller
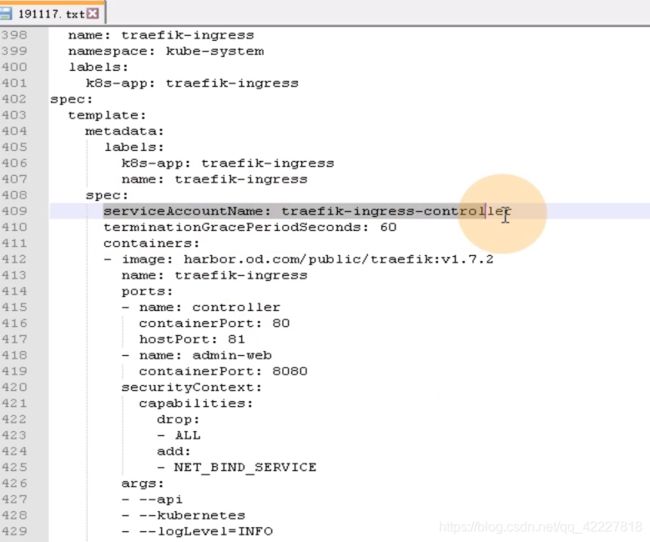
dashboard比traefik稍微复杂点
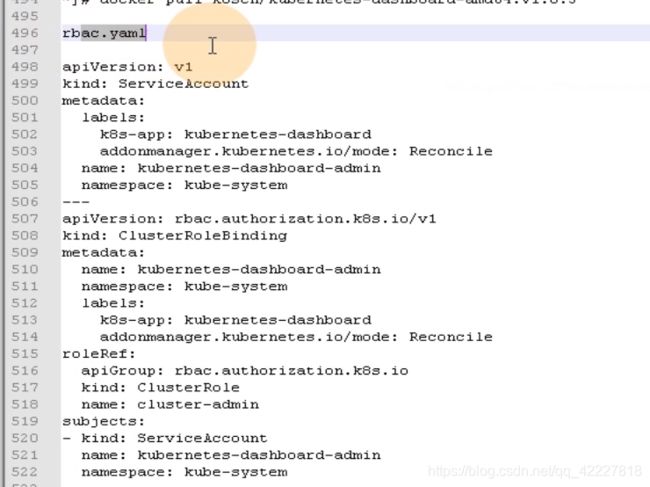
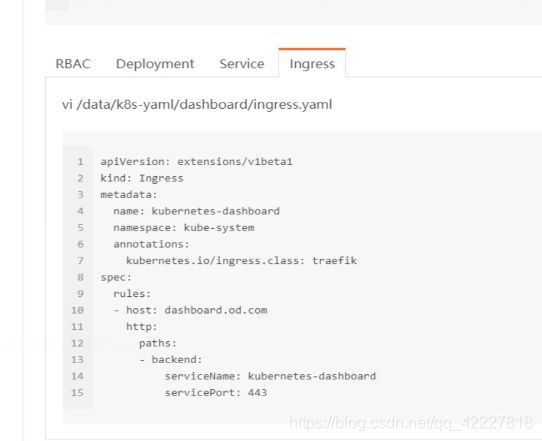
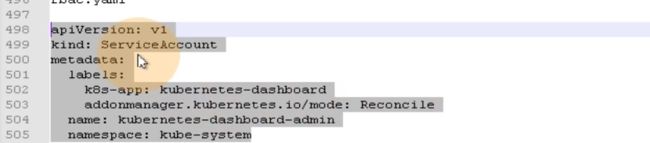
声明了一个服务账户,叫做kubernetes-dashboard-admin
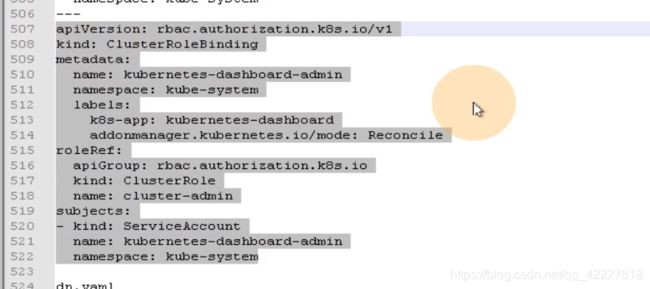
下面做了角色绑定,没有做定义角色并赋予权限。做了一个clutserRolbinding的name是kubernetes-dashboard-admin。
roleRef是参考哪个角色,这里参考了默认集群里带有的集群角色cluster-admin,集群管理员
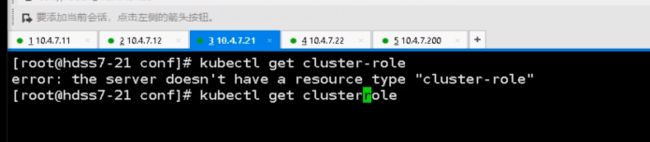
默认带有一堆集群角色,有一个默认的集群角色叫cluster-admin
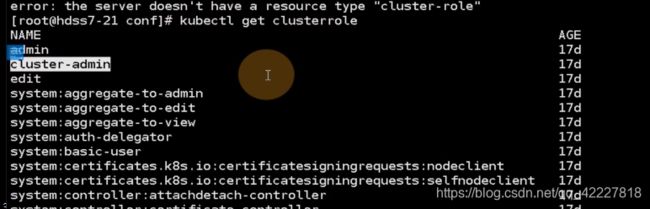
这个yaml就是定义角色并赋予权限
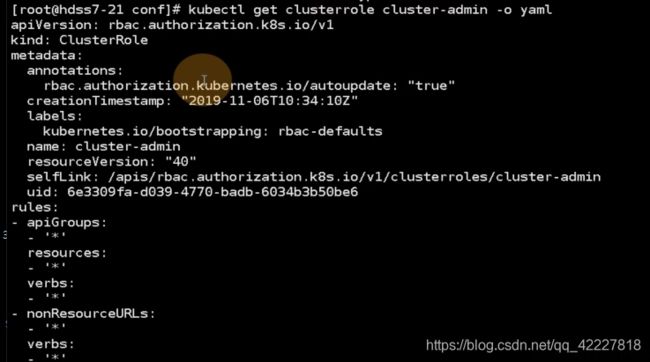
名字是cluster-admin

权限是对所有api组,所有资源,所有权限,也就是具有k8s集群的最高权限
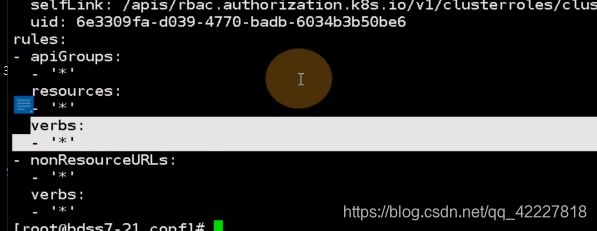
在dashboard的rbac.yaml里,只做了两件事情,
1.创建了一个新的服务账户service account
2.把创建好的账号和集群中默认的clsuterRole角色,绑定起来
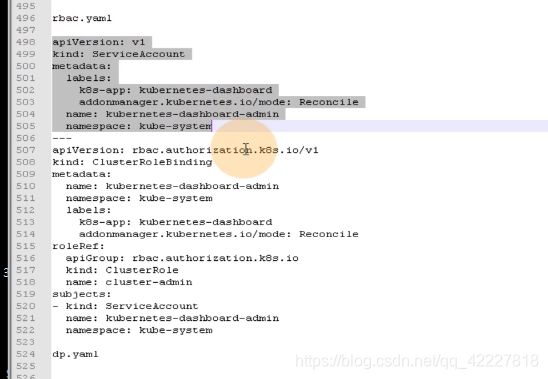
默认的集群角色,名字是system:node
对api组里的哪些资源有哪些权限,对哪个资源组里的什么资源有什么权限


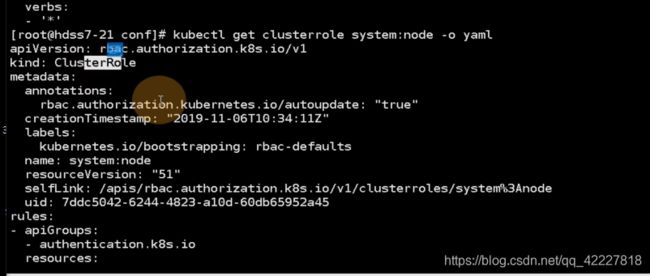
这个用户是k8s-node,给这个用户账户,去绑定一个集群角色,叫system:node(集群角色)。
真正绑定的时候cluter-node和user之间 关系
这个dashboard的pod,它的用户账户就是k8s的最高权限
看一下官方的rbac文件
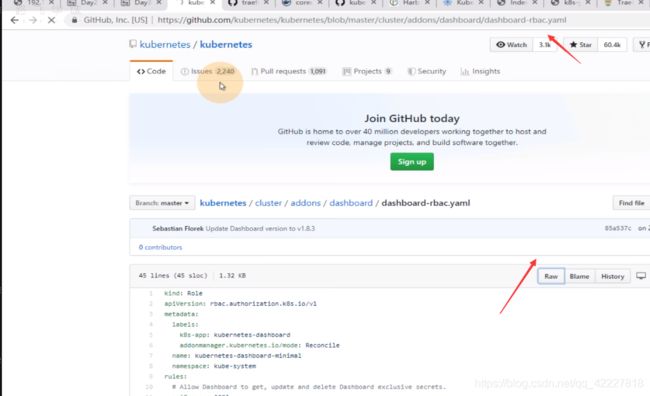
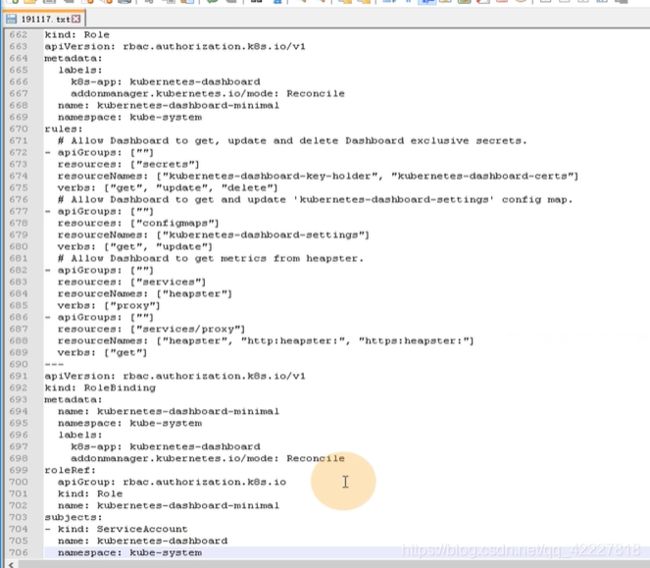
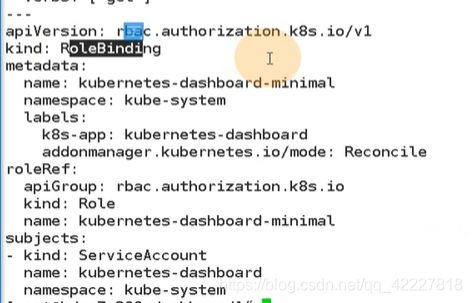
声明了一种role资源,这个role资源称为kubernetes-dashboard。名字是kubernetes-dashboard-minimal,说明我们要给dashboard最小化权限
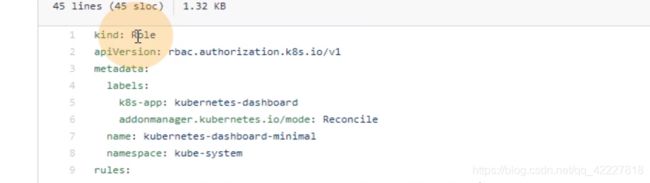
给了一堆角色的权限
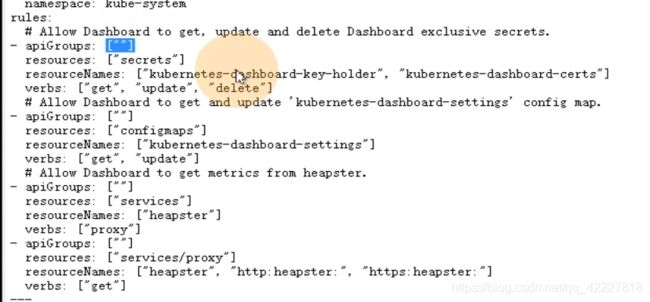
做了一个roleBinding
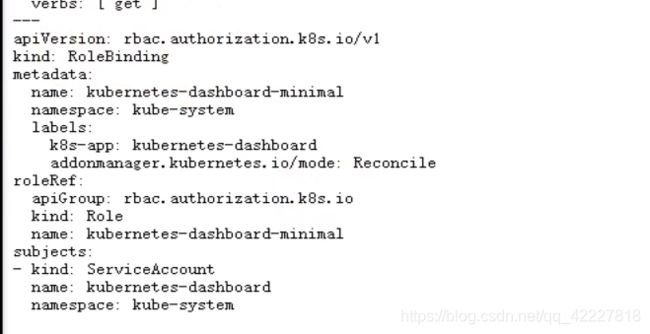
官方的service account写在deployment里了
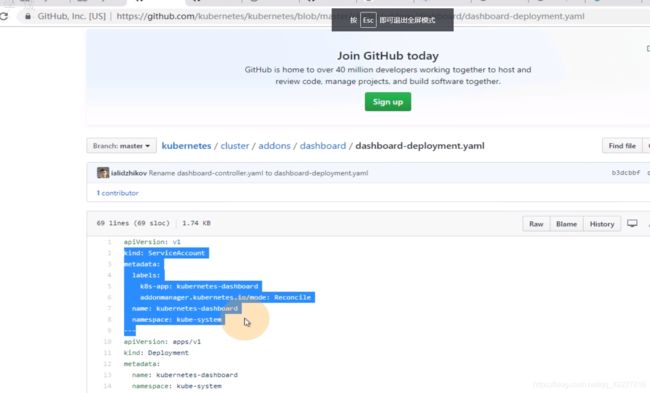
官方也是三步,1.定义service account,2.定义一个普通角色并授予最小化权限,3.把普通角色和最小化权限做了绑定
其实告诉我们dashboard,可以不用集群管理员的形式运行
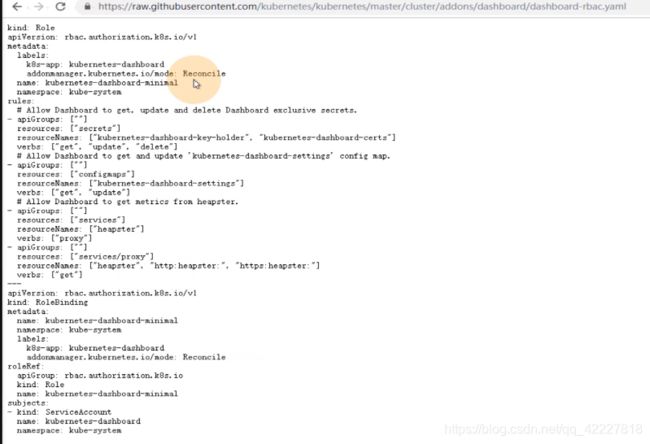
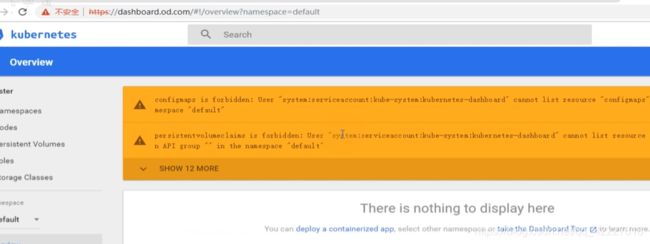
kubenetes dashboard可以接受两种配置文件,kubeconfig是普通用户的配置文件(把普通用户做出来,然后把普通用户绑定一个集群角色,这个集群角色可以是自定义的具有某些权限的角色或者集群角色,也可能是用默认的集群角色)
dashboard就要看你登录上来 人具有什么权限
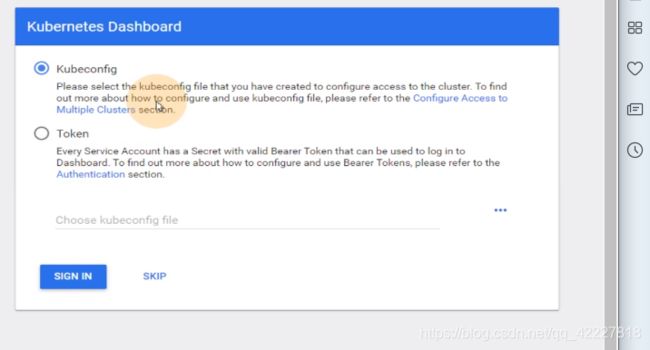
第二种方法就是用token方式,一个服务账户service account默认会产生一个资源serect
在default名称空间里可以看secrect
这就是默认service account的secret
这就是默认default service的令牌

如果到kube-system名称空间去,serect其实有很多,有default,有coredns(也声明了serviceaccount,对应一个secret,这个serect里有自己的一个令牌)
在dashboard-admin这个serviceaccount用户里也有令牌
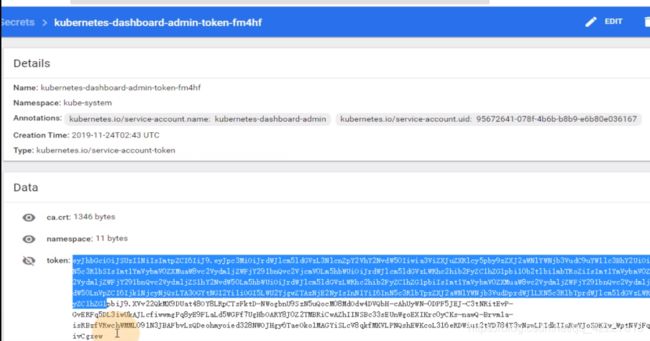
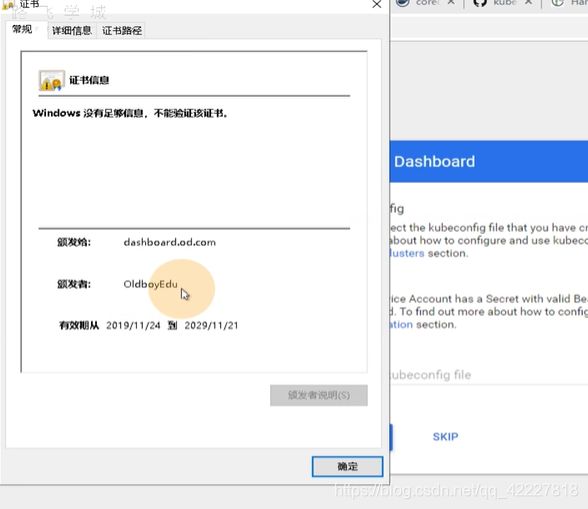
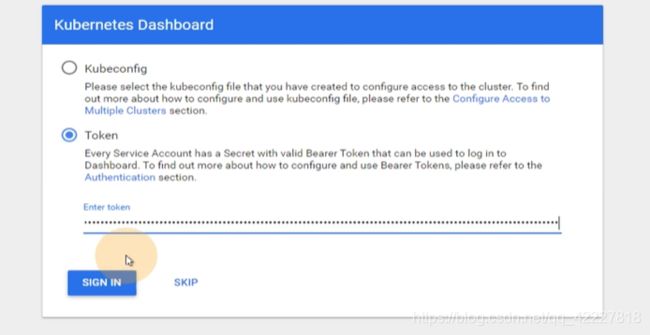
把令牌拷贝就可以进来的,现在还不行,因为是不安全的链接,所以需要去手撕证书

4.5 K8S仪表盘鉴权方式详解
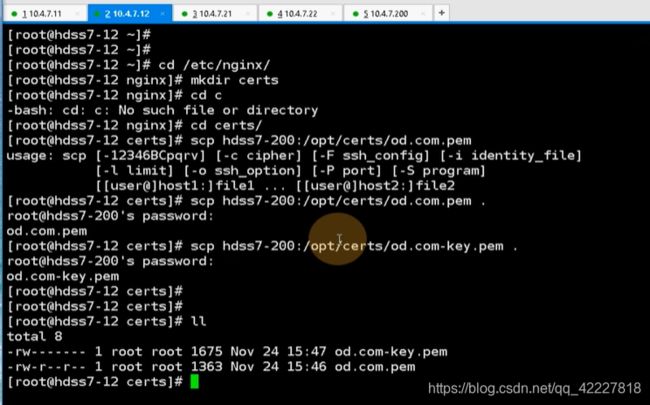
现在去创建证书,要去运维主机

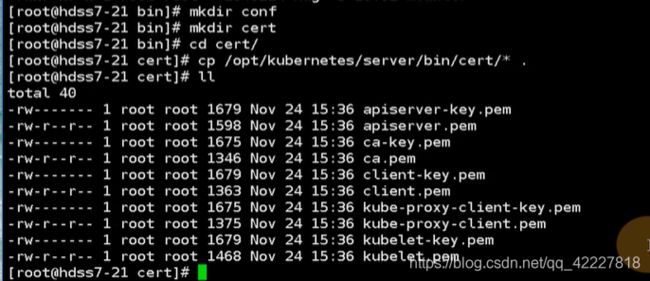
cfssl可能更加简单些,现在用openssl试试,先去创建dashboard网站的私钥,权限是600,私钥弄出来,加密算法用2048位
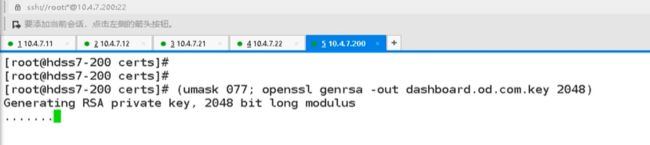
第二步用openssl做证书签发的请求文件csr,-subj主题,要给这个域签发,cn就必须对应域名,之前对k8s签发的时候,都是对于k8s组件的名字,或者是对应集群角色
![]()
创建了证书签发的请求文件csr

用openssl去签发证书,,-CA 指定ca,-out是真正要配置在nginx里的证书,days时间给个10年
![]()
一个证书一个私钥

用cfssl查一下证书


这些证书和私钥只需要拷贝到nginx里

这里把所有od.com的域全都引到了traefik的ingress控制器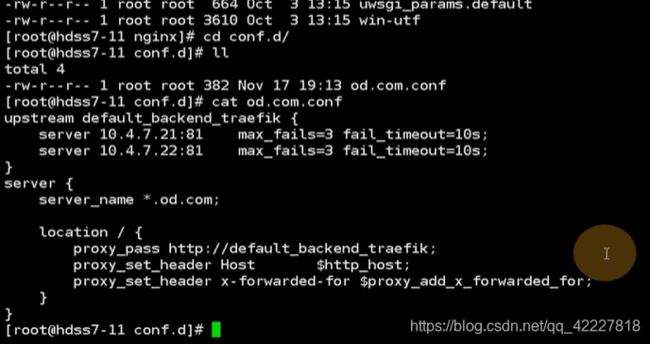
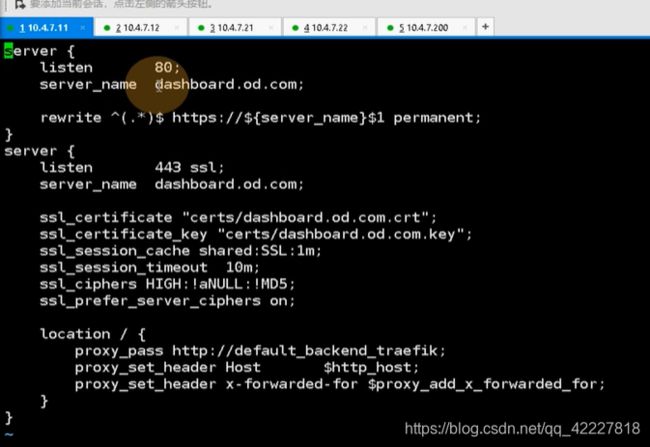
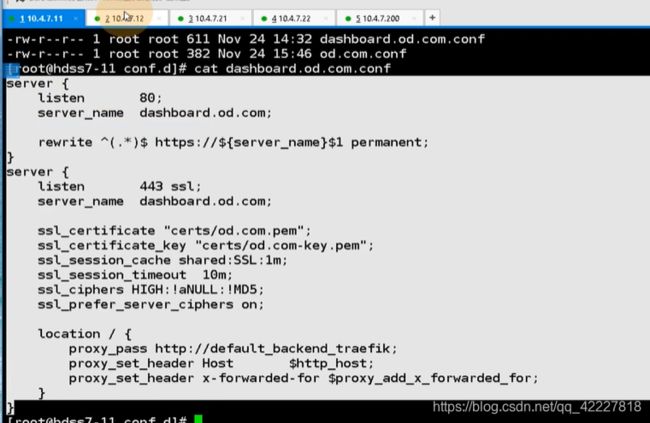
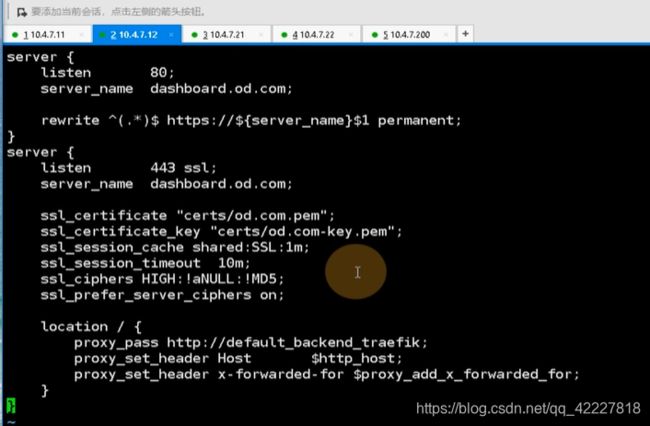
现在有特殊需求,dashboard.od.com域,要走443,走https,直接抛到ingress,必须在上层负载均衡里把证书里卸载

监听了server_name dashboard.od.com,把所有请求直接rewrite给了https,监听了443端口,server_name依然是dashboard.od.com。
证书地址,在path给 traefike-ingress-controller,就是把证书卸载了,还是用http去请求dashboard

在kube-system里有若干 secret
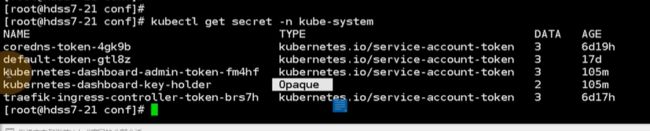
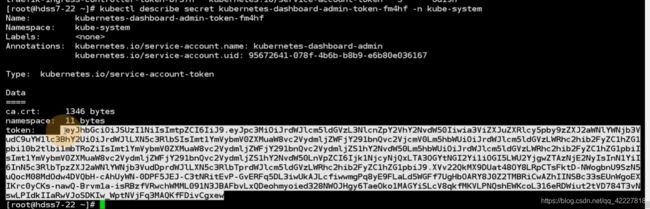
这就是dashboard令牌
![]()
令牌就出来了
如果不成功,可以换成1.10.1的dashboard
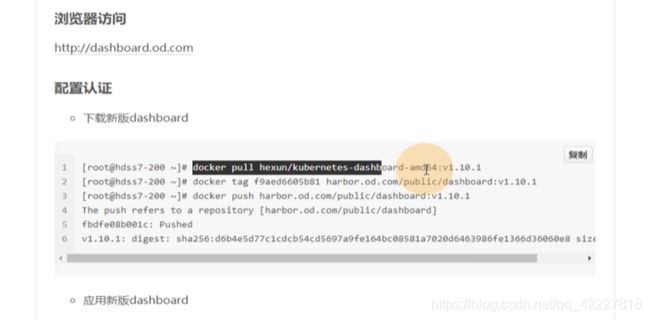
换镜像就比较简单了

打标签,push到harbor仓库
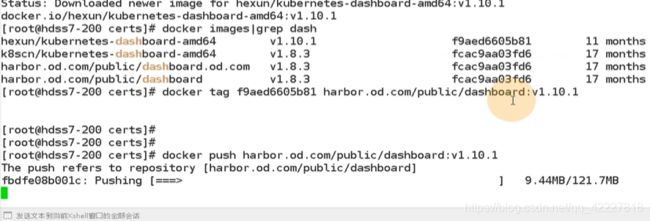

改一下版本
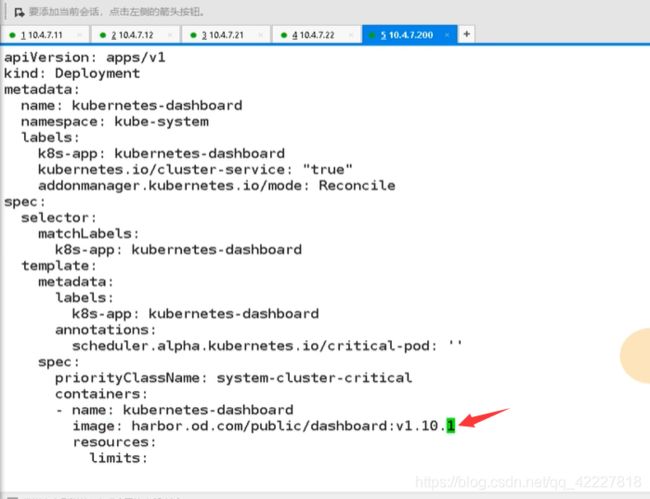
到22节点上启动应用也可以直接在dashboard改
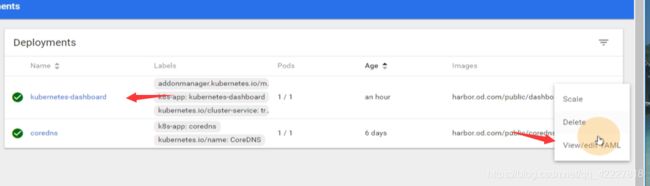
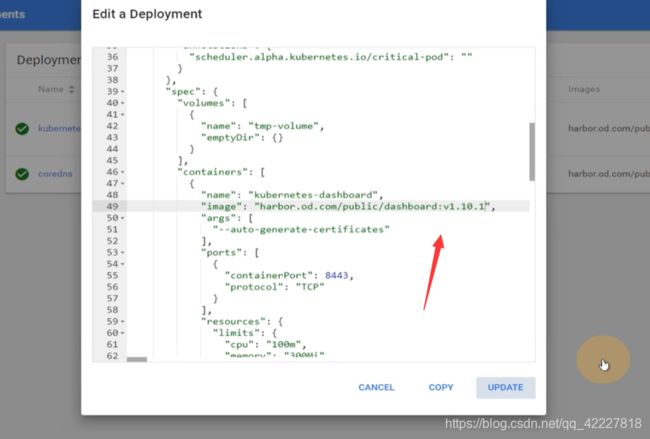
就会自己去更新镜像,新的已经起来了

1。10就强制你去登陆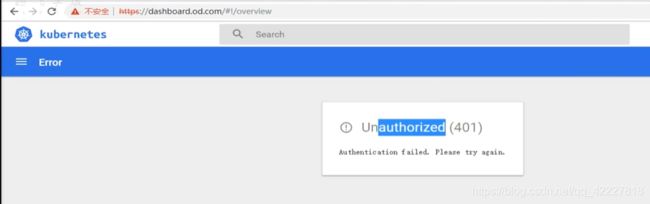
拷贝令牌

这就是1.10的dashboard 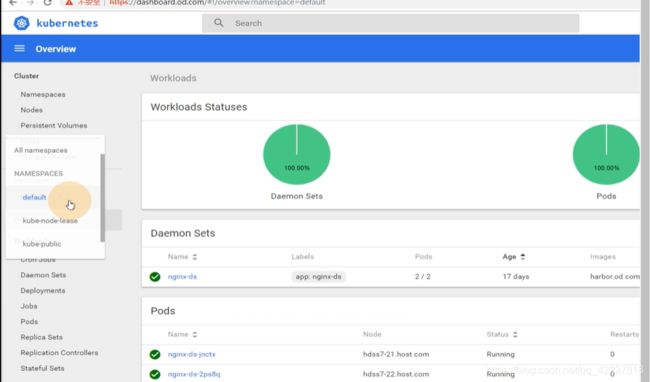
4.6 dashboard分权举例
dashboard可以用令牌的方式进行登陆
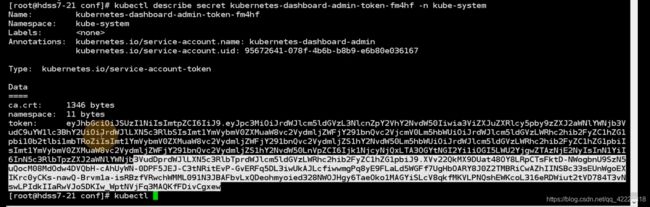
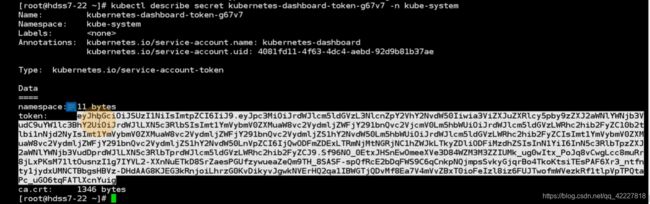
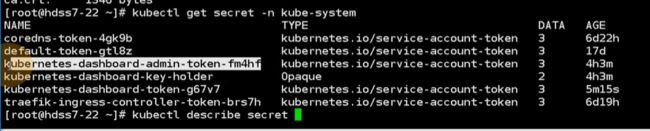
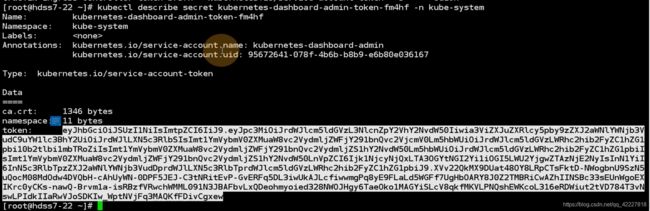
用令牌登陆就需要kubectl describe secret,获得这个令牌
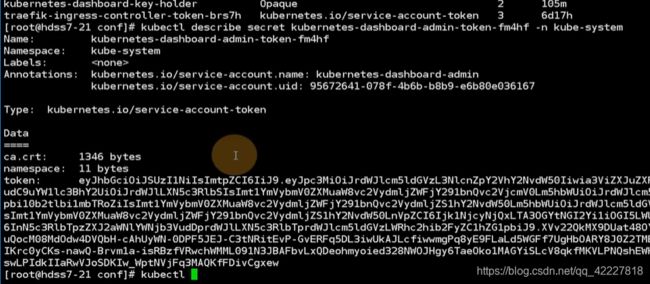
实际上是kubernetes-dashboard-admin这个service account 服务账号产生的
一个服务账号一定是对应唯一的服务账号的secret,secret秘密配置
![]()
kubernetes-dashboard-admin这个service account 服务账号产生的,这个服务账号里就有令牌复制出来
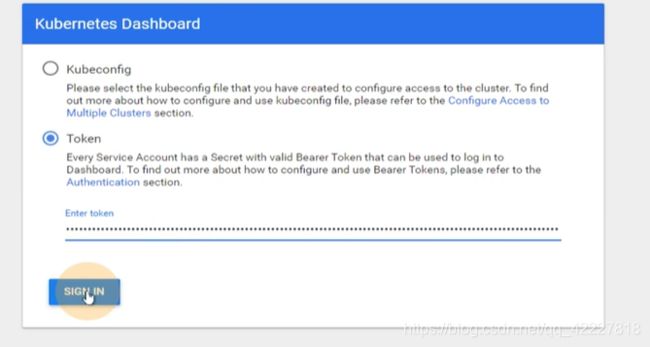
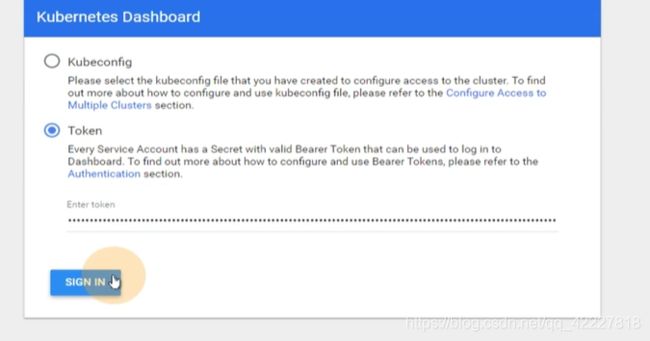
令牌复制到这里来登陆

就获得了kubernetes-dashboard-admin这个service account对应的角色,角色是cluster admin,cluster-admin所绑定的权限是集群管理员 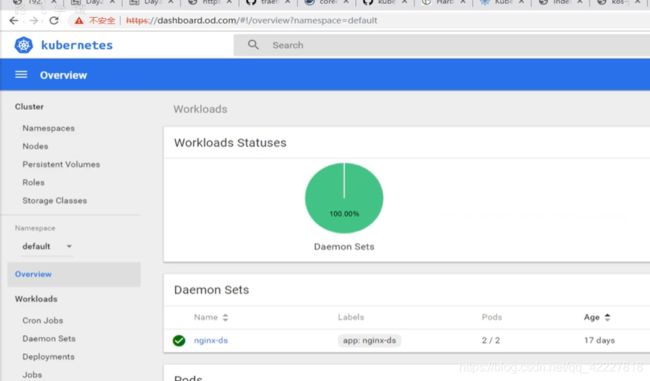
官方给了role和rolebinding,拷贝一下
在运维主机上
还有一个service account
复制到最上面

先去执行rbac-minimal.yaml
里面其实创建了一个service account ,名字是 kubernetes-dashboard

定义了一个role,叫做kubernetes-dashboard-minimal,给了一堆比较小的权限rules 
最后做了角色绑定,这个权限相对比较小
先创建出来


修改使用的服务账户
再去apply dp.yaml,相当于重新配置一下了

滚动升级,先拉起一个正常了,再把原来的干掉

现在有两个service account,两个令牌一个 kubernetes-dashboard account, kubernetes-dashboard-admin的account

这张令牌
权限不够就各种报错,也就是官方给的dashboard-minimal权限是非常小的
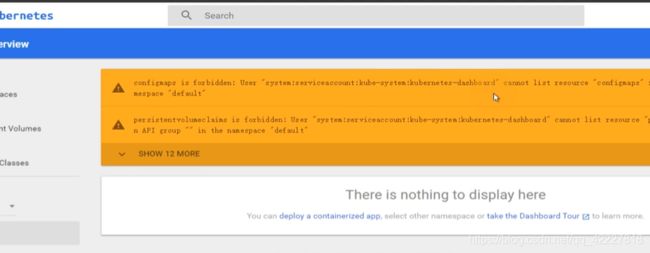
去拿admin的令牌,试试能否登陆进去
能够登陆进来,你有令牌就调整根据这个service进来的account的角色,默认给的是最小minimal的角色

换成1.8.3可能更加清楚
1.8.3的镜像也在harbor仓库里,等它起来就行
skip就是用dashboard的pod默认的服务账户(现在用的是minimal)
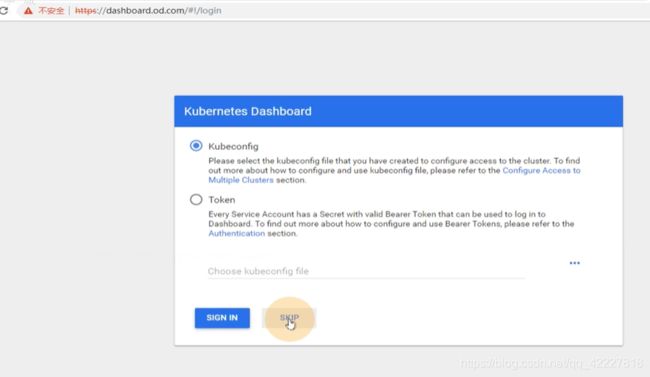
所以skip进去以后没有权限
dashboard这样 规定权限,可以开发使用,测试使用,也就是不光运维可以用
这个是集群管理员的权限
这张令牌就需要你好好保管,说白了就是集群管理员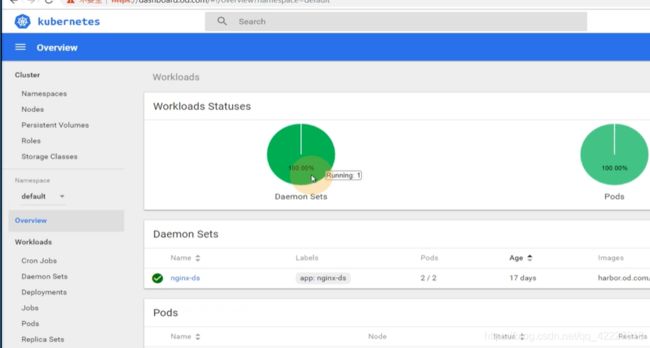
如果要限制权限,就需要做一个service account clusterRole或者role都行,用service account和cluster role做一个绑定。K8S控制权限就是基于访问控制来控制的
一个pod起来只能对应一个service account,但是这个service account可以对应不同的权限。
pod实际上是承载了service account,service account可以对应不同的角色(既可以是集群管理员,又可以是观察者的角色)rbac就是账户和权限不产生直接关系,而是角色和权限产生关系。通过角色这个中间层,把账户和权限隔离开了

这里改回admin,后面方便做集群管理
![]()
生产中建议把skip按钮去掉
 】重新configure、
】重新configure、
![]()

现在直接skip进去就是用的集群管理员admin,什么权限都有,这样非常不好
4.7 dashboard小彩蛋–heapster
dashboard 也有小插件,dashboard本身是k8s的插件,但是dashboard本身也有个插件,现在heapster地位比较尴尬,只能称为菜单
是dashboard下面的一个小插件
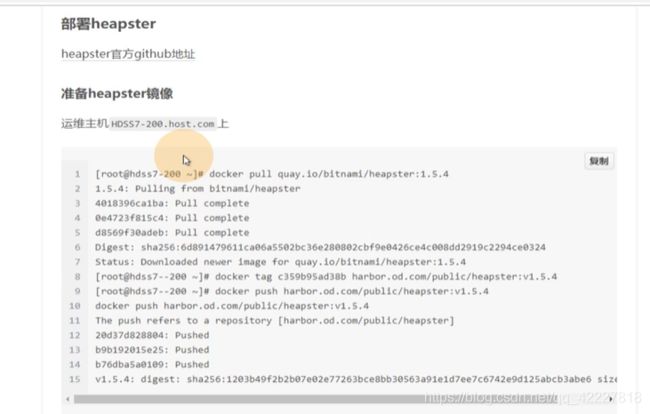
quay.io和dockerhub都是仓库

打镜像,push到harbor里
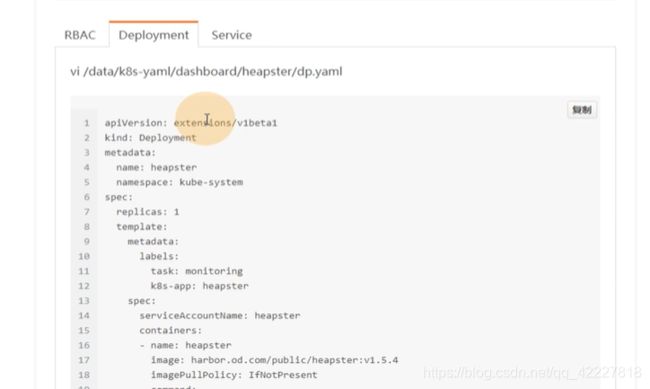
deployment就是用heapster起来的pod控制器
serivce
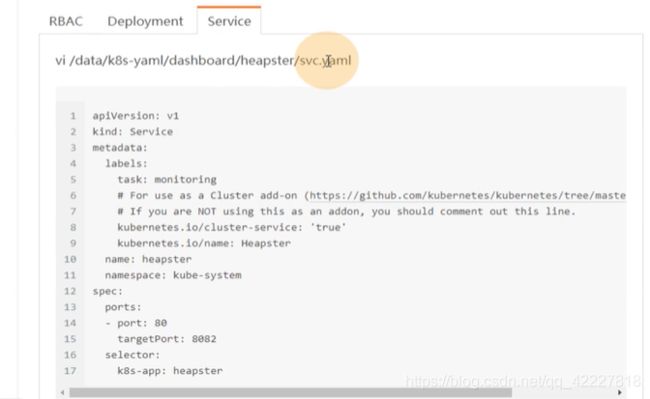

创建一个service account,名字叫heapster,在kube-system名称空间里,rolebinding到一个默认的集群角色,system:heapstr
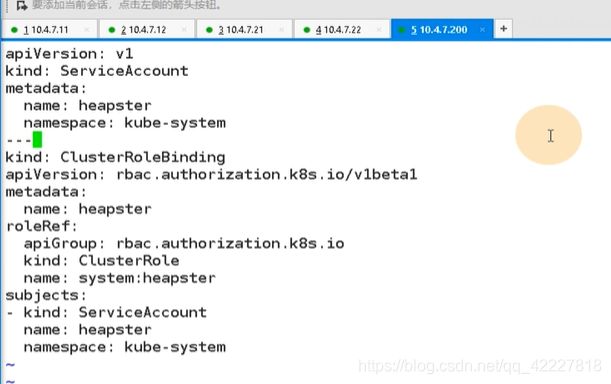
command 就是cmd指令,后面的source,省略了svc.cluster,kubernetes在内部使用可以用service名字来调用,因为coredns指向了192.169.0.1 443集群地址
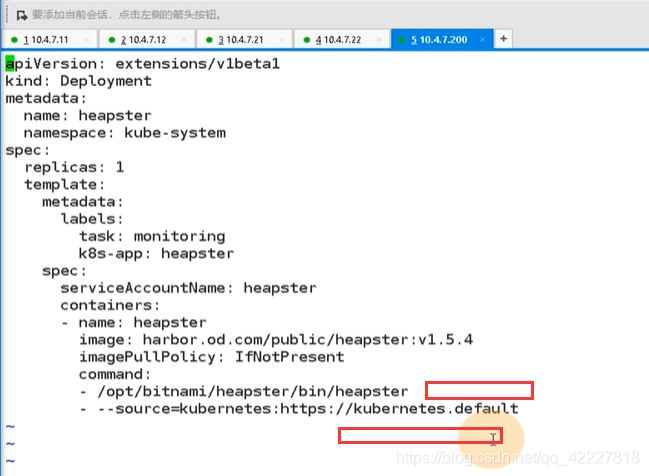

把8082整到80端口
先去创建rbac
![]()

正在创建中

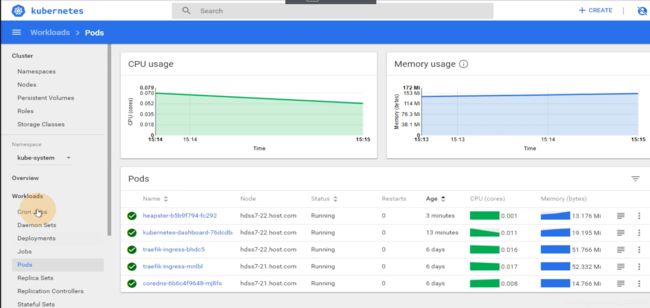
不保存数据,只是提供一个可以参考的监控指标

仅供参考,真正去监控资源的还是普罗米修斯
进入到某个pod里,由scheduler帮你决定一个节点,7-22.host.com
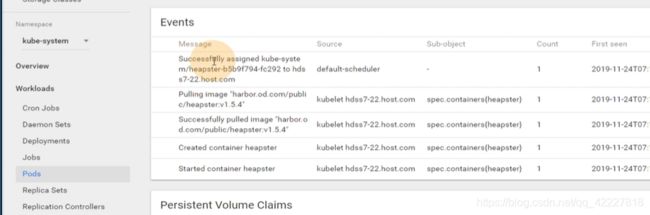
拉了一个镜像

启动镜像

logs还可以看容器日志

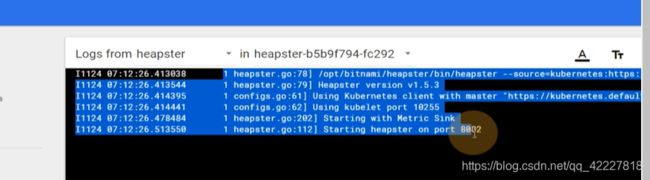
这里是针对名称空间的,traefik现在消耗比较多
exec进去就是kubectl exec
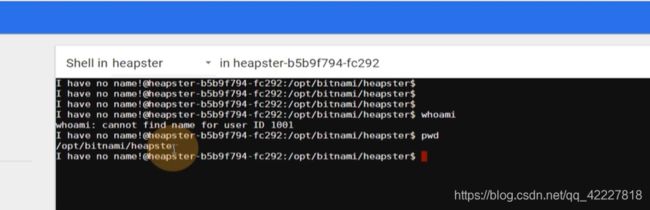
所以k8s分权限给dashboard
4.8 K8S集群平滑升级技巧
现在版本是1.15.4,,太高了可以回退版本
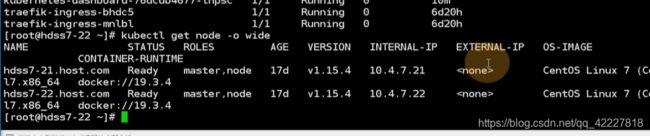
两个节点都是1.15.4,升级k8s的时候,要在流量低谷的时候做
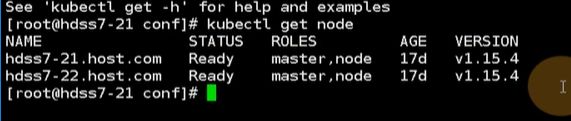
现在集群了有不少pod,因为scheduler帮你去做平衡,先去升级21
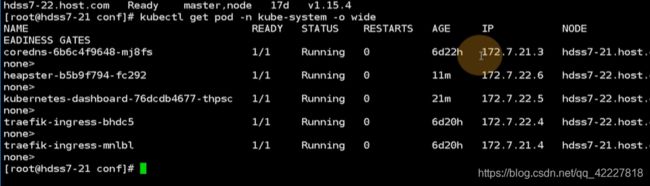
先把node从k8s集群里摘出来

就剩一个节点了

原来在21上的coredns就跑到22节点上了
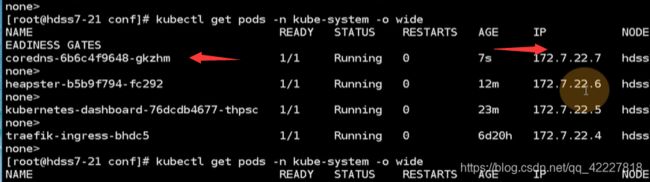
coredns完全没受影响,尽管从一个节点到了另外一个节点,这就是容器编排的特性

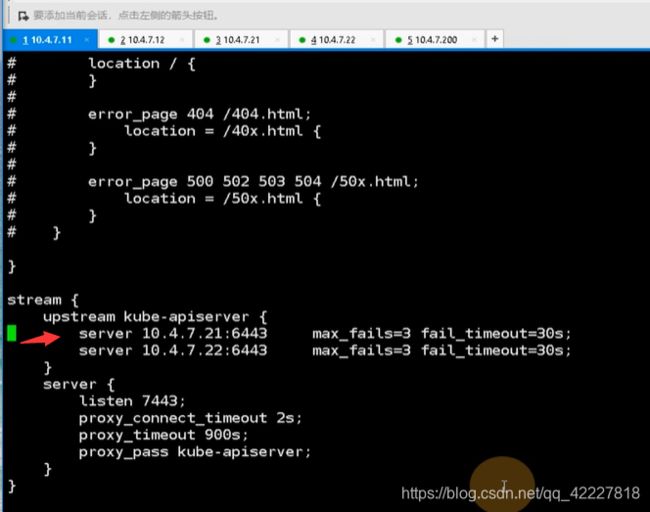
做的好一点,就把11上的nginx,把21的upstream注释掉
![]()
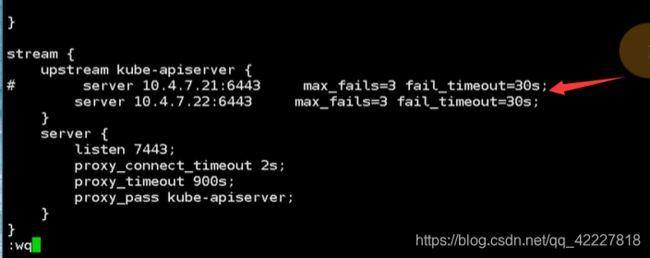

7层的负载均衡也注释掉

现在上1.15.4回退到1.15.2
![]()

生产中解压,还是需要慎重一点

这时候就有两个版本,1.15.2和1.15.4
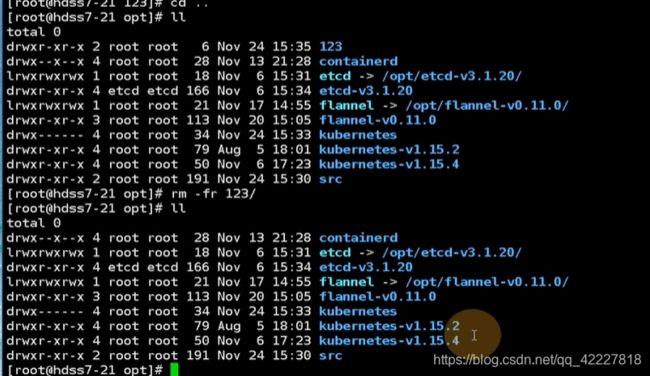
原来kubernetes是一个软连接
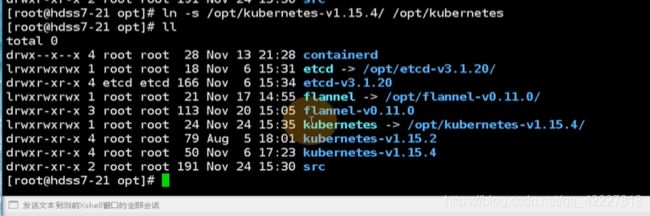
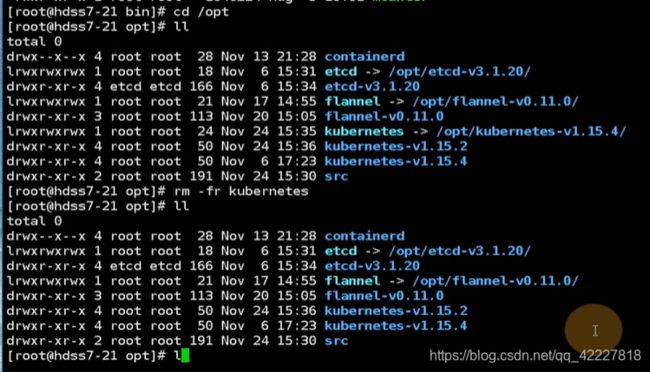
要把源码包先删除
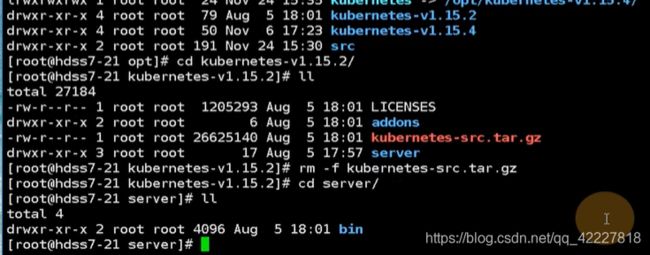

把这些都删除了
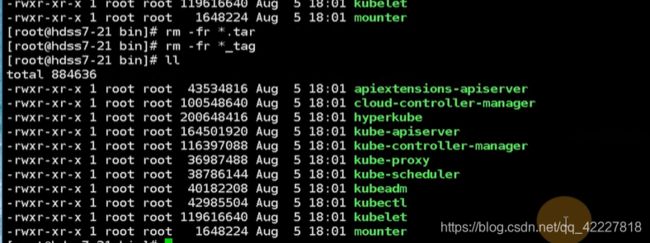
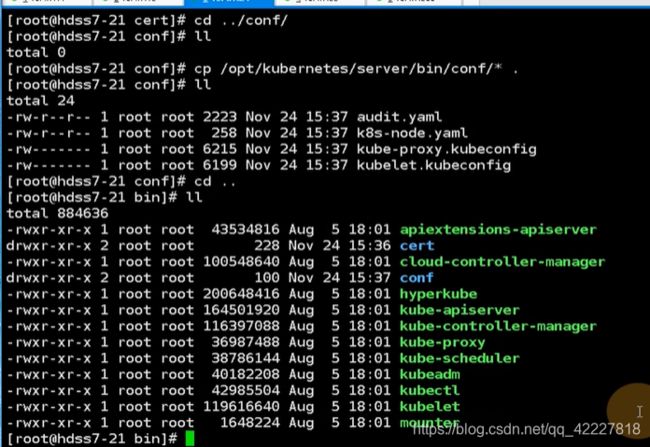
把所有的.sh拷贝一下
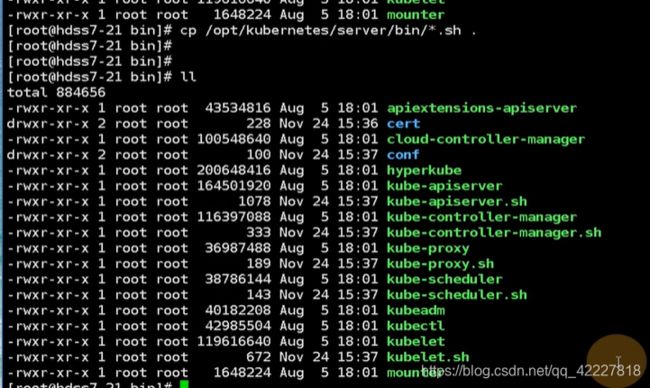
现在只要把软连接删除,指向1.15.2,启动即可
把软连接重建

重启这个进程就是新的软连接
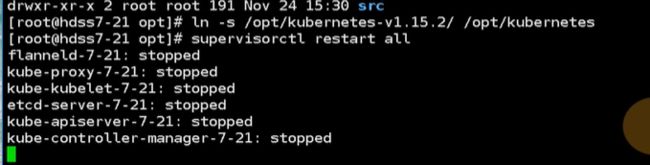
只要kubelet一重启,就帮你加到集群里了
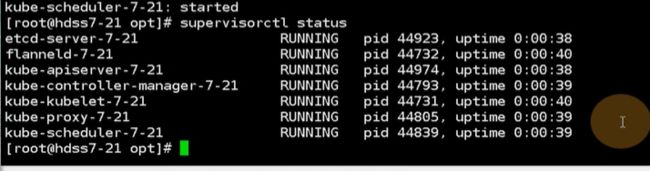
现在的版本就升级到2了

要换成1.15.4就把这个软连接继续删除

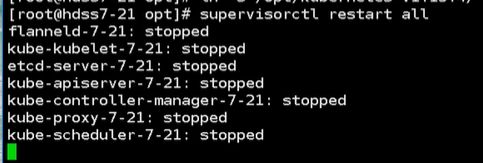
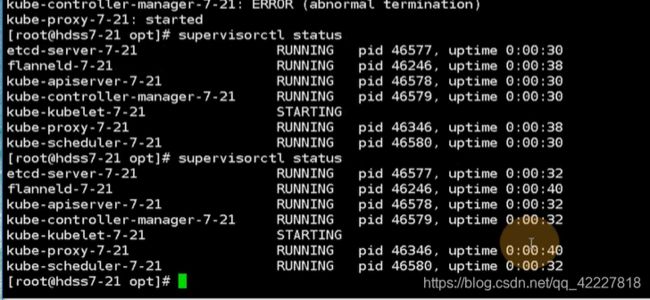
生产上不建议 kill -9
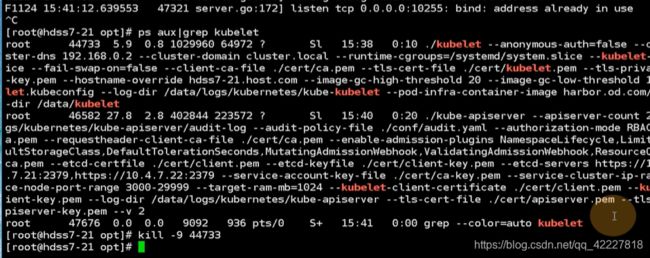

再启动一下

生产上平滑升级就这么做,把集群流量先断掉,node节点摘掉,新的软件包准备好,软连接也准备好,挨个重启服务

treafik只是daemonset,再21上起了一个
4.9 实战交付dubbo服务到K8S集群、开场
现在把nginx的流量调度恢复
![]()
4层的也进行恢复
![]()
两台nginx上跑了一个keepalive,把另外一台也配置上
把配置黏贴过来
这样nginx也都好了

完全是用traefik-ingress控制器来对流量进行分发,也就是ingress的资源就是一个可视化的nginx
把容器删了,自己会钻到21上了
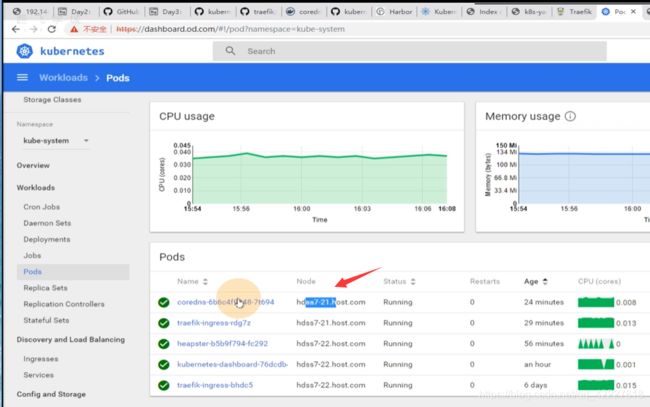
dashboard现在就一个副本,想要2个

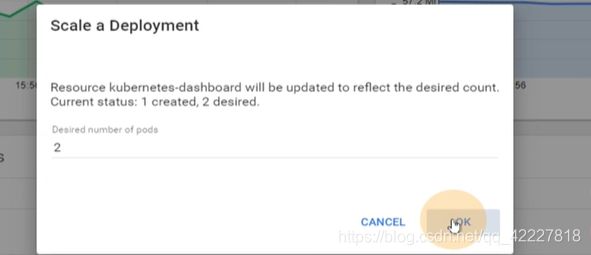
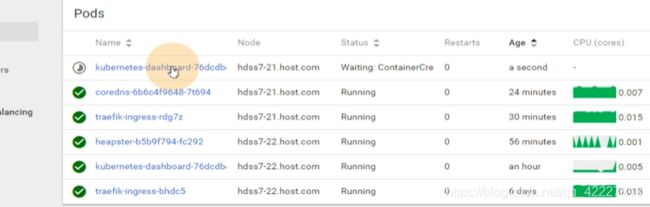
就会给你起来一个,这样就很方便对容器横向扩容
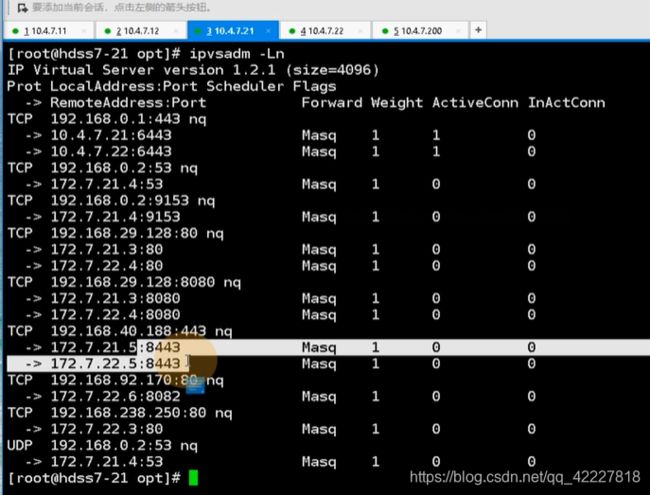
小人输入dashboard.od.com,流量是从笔记本浏览器经过dns解析到vip 10.4.7.10上(也就是10.4.7.11/12),进入到11节点上的7层负载均衡nginx里,nginx看到你请求的域名是dashboard.od.com,于是匹配到了自定义的dashboard.od.com,rewrite 443,卸载到了证书,然后帮你抛到了ingress上,ingress监听在了每个宿主机运算节点的81端口,把dashboard.od.com抛到了ingress,ingress控制器就会根据你的ingress资源配置找到host:dashboard.od.com,路径 /给你抛到dashboard的service上,相当于kubelet 把service和pod链接起来了,帮你找到了pod,pod在不同的节点,由kube-proxy的轮询算法,ipvs
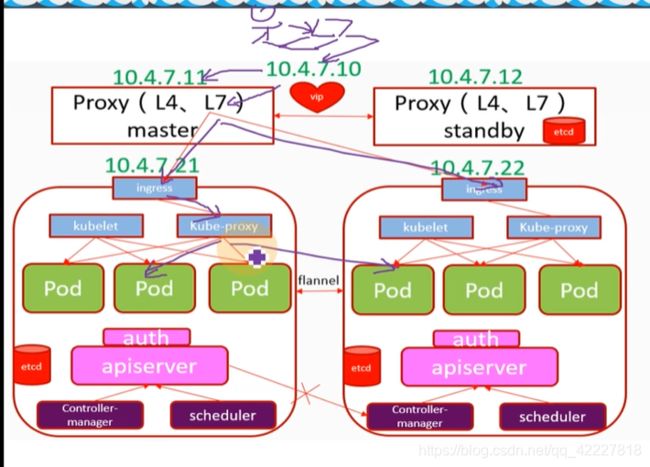
这里就是dashboard,kube-proxy找到了192.168.40.188:443,用永不排队的NQ,lvs的轮询算法,轮询到172.7.21.5:8443,让两个dashboard能够交替给你服务。
跨宿主机能够通信,是因为装了CNI网络插件
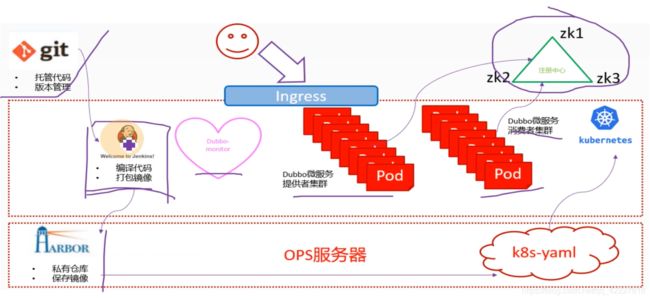
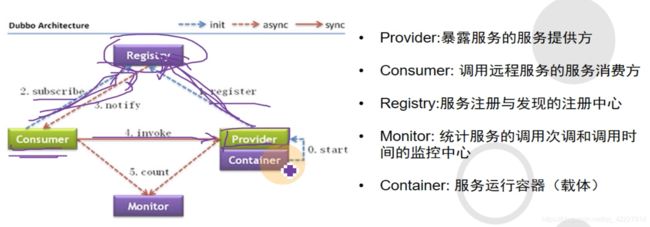
Dubbo是一个阿里开源的微服务框架,基于java开发


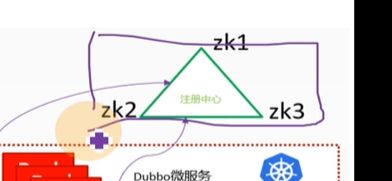
Dubbo的架构,最主要的组件是registry(注册中心,服务发现就依赖这个注册中心,不管是消费者还是提供者都需要去链接注册中心,提供者provider到注册中心是注册地过程,消费者consumer到registry是订阅subscribe)
consumer 调用invoke provider提供者,是通过rpc协议去调用的,也就是远程过程调用,就好像在调用本地方法一样
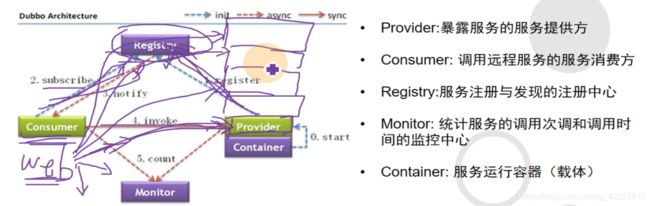
这样就可以一些服务拆开了,consumer是web工程(各种页面调用的方法是后台不同的provider)

consumer是web工程(各种页面调用的方法是后台不同的provider),以前是调用本地方法,消耗本地资源 ,服务器就需要升级,不利于横向扩容,调用这些服务的时候,都可以让他们独立的一个个写成单独的服务,web服务区调用服务的时候,就好像在调用本地方法一样,实际上是资源不重叠的
真正交付Dubbo,要交付registry,provider,然后monitor和consumer
实验架构图,右上角是注册中心,Dubbo微服务的注册中心是依赖于zookeeper来做的,中间段是k8s集群,有DUbbo微服务提供者集群和Dubbo微服务消费者集群,都是封装pod,交付到k8s里,把能够动态扩容的服务都放到k8s里,把微服务的消费者和提供者交付到k8s集群里,同时把Dubbo-monitor交付到k8s集群里。
开发会把代码放到版本控制中心,运维使用恰当工具持续集成部署
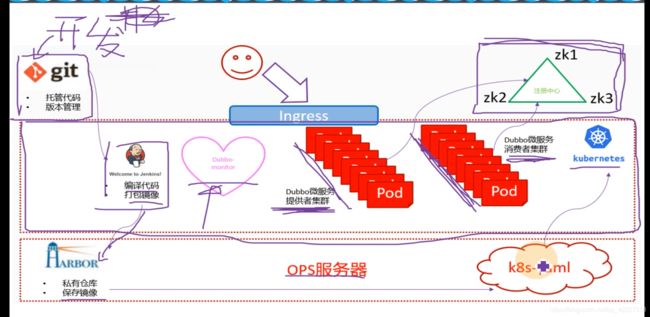
编译代码,打包成docker镜像,放到harbor仓库里,ops服务器就是hdss7-200,做一个k8s的资源配置清单,应用到k8s里,就把代码变成了pod
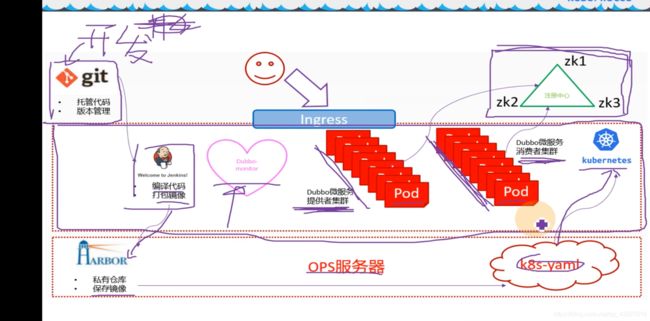
用户访问找ingress,ingress配置好规则daemon.od.com,然后到消费者集群,消费者集群是一个web服务
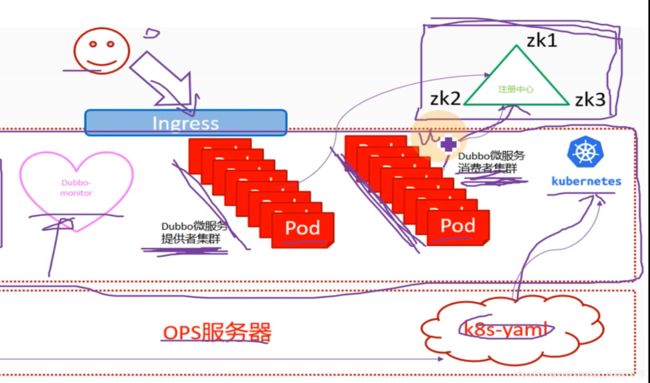
这里需要把zk放在k8s外面,原因是zk是典型的有状态服务,不适宜放到k8s里进行管理
k8s具有很强的动态性,pod是可以漂移的,所以pod管理的一定是不能有状态的,无状态的意思就是这个容器死了就死了,无所谓,随便扩容,随便死。
有状态服务,是要有数据持久化下来,很不适合放在k8s里管理,k8s也有专门管理有状态服务的,叫是StatefulSet,这个pod控制器来管理有状态服务

ES MYSQL,ZK这种有状态服务,最好放到k8s外面去