k8s部署及管理
kubernetes
概述
linux命令查询网址:https://man.linuxde.net
中文社区:https://www.kubernetes.org.cn/doc-14
官网地址:https://kubernetes.io/zh/docs/concepts/overview
—kubernetes名字来自希腊语,意思是舵手(领航员),k8s是将k和s之间的8个字母ubernete替换成8的缩写
—Kubernetes的创造者是行业巨头Google
—Kubernetes是基于Borg的大规模容器管理的开源版本
—2014年6月Google正式公布并宣布开源
—编配,管理,调度等各方面集成的一套管理容器的系统
—Kubernetes 是一个开源容器管理工具,负责容器部署,容器扩缩容以及负载平衡等功能
—Kubernetes 不是一个容器化平台,而是一个多容器管理解决方案

kubernetes适用场景
—有大量跨主机的容器需要管理
—快速部署应用
—快速扩张应用
—无缝对接的应用功能
—节省资源,优化硬件资源的使用
kubernetes架构
核心角色: master(管理节点), node(计算节点),image(镜像仓库)

master节点
—Master提供集群的控制
—对集群进行决策
—检测和影响集群事件
—Master主要由 apiserver schedule controllermanager etcd组成
1 API Server 提供 REST 操作和到集群共享状态的前端,所有其他组件通过它进行交互,端口6443。
2 Schedule 监视那些新创建的未指定运行节点的 Pod,并选择节点让 Pod 在上面运行,端口10251。
3 controller-manager 主节点上运行控制器的组件,负责管理控制器,端口10252.
节点控制器(Node Controller): 负责在节点出现故障时进行通知和响应。
副本控制器(Replication Controller): 负责为系统中的每个副本控制器对象维护正确数量的 Pod。
端点控制器(Endpoints Controller): 填充端点(Endpoints)对象(即加入 Service 与 Pod)。
服务帐户和令牌控制器(Service Account & Token Controllers): 为新的命名空间创建默认帐户和 API 访问令牌.
4 etcd 是兼具一致性和高可用性的键值数据库,可以作为保存 Kubernetes 所有集群数据的后台数据库,用户无需手动干预,集群自动管理,端口2379-2380。
node节点
—kubernetes的计算节点
—维护运行pod,并提供具体应用的环境
—计算节点设计成水平扩展,该组件在多个节点上运行
—node由kubelet,kube-proxy,和docker组成
1 pod:最小部署单元,一组容器的集合,共享网络,生命周期是短暂的
2 kubelet 一个在集群中每个节点上运行的代理。它保证容器都运行在 Pod 中
3 kuber-proxy 是集群中每个节点上运行的网络代理,实现 Kubernetes Service 概念的一部分,维护节点上的网络规则。这些网络规则允许从集群内部或外部的网络会话与 Pod 进行网络通信。
4 Container Runtime 容器运行环境是负责运行容器的软件 支持多个容器运行环境: docker、 containerd、CRI-O 以及任何实现 Kubernetes CRI (容器运行环境接口)。
插件(Addons) 。
5 docker:是一个开源的应用容器引擎,基于Go语言实现,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的 Linux或Windows 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。
Addons插件
插件使用 Kubernetes 资源(DaemonSet、 Deployment等)实现集群功能。 因为这些插件提供集群级别的功能,插件中命名空间域的资源属于 kube-system 命名空间。
1 DNS:集群 DNS 是一个 DNS 服务器,和环境中的其他 DNS 服务器一起工作,它为 Kubernetes 服务提供 DNS 记录。
2 Web 界面:Dashboard 是K ubernetes 集群的通用的、基于 Web 的用户界面。 它使用户可以管理集群中运行的应用程序以及集群本身并进行故障排除。
3 容器资源监控 :容器资源监控 将关于容器的一些常见的时间序列度量值保存到一个集中的数据库中,并提供用于浏览这些数据的界面。
4 集群层面日志 :机制负责将容器的日志数据 保存到一个集中的日志存储中,该存储能够提供搜索和浏览接口。
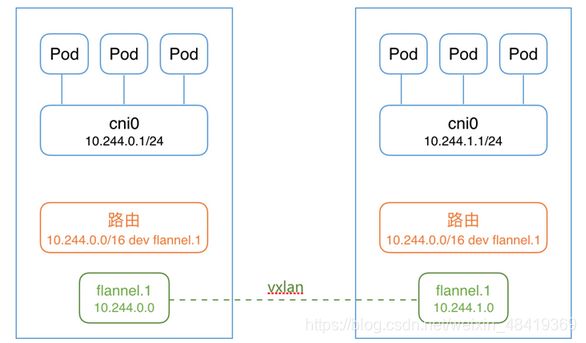
5 网络插件:flannel是一个可以用于 Kubernetes 的 overlay 网络提供者,实质上是一种“覆盖网络”也就是将TCP数据包装在另一种网络里面进行路由转发和通信,目前支持UDP,VxLAN,AWS VPC和GCE路由数据转发方式。不同主机的内容实现互通互联。https://github.com/coreos/flannel/blob/master/Documentation/kube-flannel.yml
总结k8s概念
- cluster
cluster是 计算、存储和网络资源的集合,k8s利用这些资源运行各种基于容器的应用。
2.master
master是cluster的大脑,他的主要职责是调度,即决定将应用放在那里运行。master运行linux操作系统,可以是物理机或者虚拟机。为了实现高可用,可以运行多个master。
3.node
node的职责是运行容器应用。node由master管理,node负责监控并汇报容器的状态,同时根据master的要求管理容器的生命周期。node运行在linux的操作系统上,可以是物理机或者是虚拟机。
4.pod
pod是k8s的最小工作单元。每个pod包含一个或者多个容器。pod中的容器会作为一个整体被master调度到一个node上运行。
5.kube-controller-manager
k8s通常不会直接创建pod,而是通过controller来管理pod的。controller中定义了pod的部署特性,比如有几个剧本,在什么样的node上运行等。为了满足不同的业务场景,k8s提供了多种controller,包括deployment、replicaset、daemonset、statefulset、job等。
6.deployment
是最常用的controller(控制器)。deployment可以管理pod的多个副本,并确保pod按照期望的状态运行,滚动升级和回滚应用,扩容和缩容。
7.replicaset
实现了pod的多副本管理。使用deployment时会自动创建replicaset,也就是说deployment是通过replicaset来管理pod的多个副本的,我们通常不需要直接使用replicaset。
8.daemonset
用于每个node最多只运行一个pod副本的场景。正如其名称所示的,daemonset通常用于运行daemon。
9.statefuleset
能够保证pod的每个副本在整个生命周期中名称是不变的,而其他controller不提供这个功能。当某个pod发生故障需要删除并重新启动时,pod的名称会发生变化,同时statefulset会保证副本按照固定的顺序启动、更新或者删除。、
10.job
用于运行结束就删除的应用,而其他controller中的pod通常是长期持续运行的。
11.service
deployment可以部署多个副本,每个pod 都有自己的IP,外界如何访问这些副本那?
答案是service
k8s的 service定义了外界访问一组特定pod的方式。service有自己的IP和端口,service为pod提供了负载均衡。
k8s运行容器pod与访问容器这两项任务分别由controller和service执行。
12.namespace
可以将一个物理的cluster逻辑上划分成多个虚拟cluster,每个cluster就是一个namespace。不同的namespace里的资源是完全隔离的。
13.kubeadm
用来初始化集群的指令。
14.kubelet
在集群中的每个节点上用来启动 pod 和容器等
15.kubectl
用来与集群通信的命令行工具。通过 kubectl 可以部署和管理应用,查看各种资源,创建、删除和更新各种组件。
16.API Server
提供 REST 操作和到集群共享状态的前端,所有其他组件通过它进行交互。
17.kube-scheduler
主节点上的组件,该组件监视那些新创建的未指定运行节点的 Pod,并选择节点让 Pod 在上面运行。调度决策考虑的因素包括单个 Pod 和 Pod 集合的资源需求、硬件/软件/策略约束、亲和性和反亲和性规范、数据位置、工作负载间的干扰和最后时限。
18 kube-proxy
是集群中每个节点上运行的网络代理,实现 Kubernetes Service 概念的一部分。
19.知名标签(Label)、注解(Annotation)和 污点(Taint)
Kubernetes 保留了 kubernetes.io 命名空间下的所有标签和注解。
20 metadata 元数据
metadata - 帮助唯一性标识对象的一些数据,包括一个 name 字符串、UID 和可选的 namespace等
kubernetes安装
官方文档安装https://kubernetes.io/docs/setup/independent/install-kubeadm/
安装 kubeadm、kubelet 和 kubectl
官网安装: sudo apt-get update && sudo apt-get install -y apt-transport-https curl
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
cat <
EOF
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl
华为云主机
master 192.168.1.21 2CPU,2G内存
node-0001 192.168.1.31 2CPU,2G内存
node-0002 192.168.1.32 2CPU,2G内存
node-0003 192.168.1.33 2CPU,2G内存
registry 192.168.1.100 1CPU,1G内存


kube-master安装 :方法一
1 优化系统服务
禁用 selinux,禁用 swap,卸载 firewalld-*
[root@master ~]# systemctl stop postfix
[root@master ~]# yum remove -y postfix firewalld-*
[root@master ~]# yum install chrony
[root@master ~]# vim /etc/chrony.conf
#注释掉 server 开头行,添加下面的配置
server ntp.myhuaweicloud.com minpoll 4 maxpoll 10 iburst
[root@master ~]# systemctl enable --now chronyd
[root@master ~]# chronyc sources -v
#验证配置结果 ^* 代表成功
[root@master ~]# vim /etc/cloud/cloud.cfg
#manage_etc_hosts: localhost 注释掉这一行
[root@master ~]# sed -i '/SELINUX/s/enforcing/permissive/' /etc/selinux/config
[root@master ~]# swapoff -a 临时
[root@master ~]# sed -ri 's/ .* /#&/' /etc/fstab
仓库初始化
1.1删除原有云主机,重新购买
主机名称 IP地址 最低配置
registry 192.168.1.100 1CPU,1G内存
1.2、安装仓库服务
[root@registry ~]# yum makecache
[root@registry ~]# yum install -y docker-distribution
[root@registry ~]# systemctl enable --now docker-distribution
1.3、使用脚本初始化仓库
拷贝云盘 kubernetes/v1.17.6/registry/myos目录 到 仓库服务器
[root@registry ~]# cd myos
[root@registry ~]# chmod 755 init-img.sh
[root@registry ~]# ./init-img.sh
[root@registry ~]# curl http://192.168.1.100:5000/v2/myos/tags/list
{"name":"myos","tags":["nginx","php-fpm","v1804","httpd"]}
2、配置yum仓库
跳板机,配置提供yum源
[root@ecs-proxy ~]# cp -a v1.17.6/k8s-install /var/ftp/localrepo/
[root@ecs-proxy ~]# cd /var/ftp/localrepo/
[root@ecs-proxy localrepo]# createrepo --update .
3、安装工具软件包
安装kubeadm、kubectl、kubelet、docker-ce
[root@master ~]# yum makecache
[root@master ~]# yum install -y kubeadm kubelet kubectl docker-ce
[root@master ~]# mkdir -p /etc/docker
[root@master ~]# vim /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": ["https://hub-mirror.c.163.com"],
"insecure-registries":["192.168.1.100:5000", "registry:5000"]
}
[root@master ~]# systemctl enable --now docker kubelet
[root@master ~]# docker info |grep Cgroup
Cgroup Driver: systemd
[root@master ~]# vim /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
[root@master ~]# modprobe br_netfilter
[root@master ~]# sysctl --system
4、镜像导入私有仓库
把云盘 kubernetes/v1.17.6/base-images 中的镜像拷贝到 master
[root@master ~]# cd base-images/
[root@master base-image]# for i in *.tar.gz;do docker load -i ${i};done
[root@master base-image]# docker images
[root@master base-image]# docker images |awk '$2!="TAG"{print $1,$2}'|while read _f _v;do
docker tag ${_f}: ${_v} 192.168.1.100:5000/ ${_f##*/}: ${_v};
docker push 192.168.1.100:5000/ ${_f##*/}: ${_v};
docker rmi ${_f}: ${_v};
done
#查看验证
[root@master base-image]# curl http://192.168.1.100:5000/v2/_catalog
5、Tab键设置
[root@master ~]# kubectl completion bash >/etc/bash_completion.d/kubectl
[root@master ~]# kubeadm completion bash >/etc/bash_completion.d/kubeadm
[root@master ~]# bash
6、安装IPVS代理软件包
[root@master ~]# yum install -y ipvsadm ipset
7、系统初始化,排错
[root@master ~]# vim /etc/hosts
192.168.1.21 master
192.168.1.31 node-0001
192.168.1.32 node-0002
192.168.1.33 node-0003
192.168.1.100 registry
[root@master ~]# kubeadm init --dry-run
8、使用kubeadm部署
应答文件在云盘的 kubernetes/v1.17.6/config 目录下
[root@master ~]# mkdir init;cd init
#拷贝 kubeadm-init.yaml 到 master 云主机 init 目录下
[root@master init]# kubeadm init --config=kubeadm-init.yaml |tee master-init.log
创建日志 tee master-init.log
#根据提示执行命令
[root@master init]# mkdir -p $HOME/.kube
[root@master init]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master init]# sudo chown $(id -u): $(id -g) $HOME/.kube/config
9、验证安装结果
[root@master ~]# kubectl version
[root@master ~]# kubectl get componentstatuses
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health":"true"}
node计算节点安装
1、获取token
删除原有token
[root@master ~]# kubeadm token list
[root@master ~]# kubeadm token delete XXXX(上面list查找到的)
创建token
[root@master ~]# kubeadm token create --ttl=0 --print-join-command
[root@master ~]# kubeadm token list
#获取token_hash
[root@master ~]# openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt |openssl rsa -pubin -outform der |openssl dgst -sha256 -hex
2、node安装
拷贝云盘上 kubernetes/v1.17.6/node-install 到跳板机
[root@ecs-proxy ~]# cd node-install/
[root@ecs-proxy node-install]# vim files/hosts
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
192.168.1.21 master
192.168.1.31 node-0001
192.168.1.32 node-0002
192.168.1.33 node-0003
192.168.1.100 registry
[root@ecs-proxy node-install]# vim node_install.yaml
---
- name:
hosts:
- nodes
vars:
master: '192.168.1.21:6443'
token: 'ye99yg.gv866warn6067oox'
token_hash: 'sha256:9fa1341dfce3815cffd64d77968f35cac773ada4f7a71fb73eb28f62ee990002'
tasks:
- name: disable swap
lineinfile:
path: /etc/fstab
regexp: 'swap'
state: absent
notify: disable swap
- name: Ensure SELinux is set to disabled mode
lineinfile:
path: /etc/selinux/config
regexp: '^SELINUX='
line: SELINUX=disabled
notify: disable selinux
- name: remove the firewalld
yum:
name:
- firewalld
- firewalld-filesystem
state: absent
- name: install k8s node tools
yum:
name:
- kubeadm
- kubelet
- docker-ce
- ipvsadm
- ipset
state: present
update_cache: yes
- name: Create a directory if it does not exist
file:
path: /etc/docker
state: directory
mode: '0755'
- name: Copy file with /etc/hosts
copy:
src: files/hosts
dest: /etc/hosts
owner: root
group: root
mode: '0644'
- name: Copy file with /etc/docker/daemon.json
copy:
src: files/daemon.json
dest: /etc/docker/daemon.json
owner: root
group: root
mode: '0644'
- name: Copy file with /etc/sysctl.d/k8s.conf
copy:
src: files/k8s.conf
dest: /etc/sysctl.d/k8s.conf
owner: root
group: root
mode: '0644'
notify: enable sysctl args
- name: enable k8s node service
service:
name: "{{ item }}"
state: started
enabled: yes
with_items:
- docker
- kubelet
- name: check node state
stat:
path: /etc/kubernetes/kubelet.conf
register: result
- name: node join
shell: kubeadm join '{{ master }}' --token '{{ token }}' --discovery-token-ca-cert-hash '{{ token_hash }}'
when: result.stat.exists == False
handlers:
- name: disable swap
shell: swapoff -a
- name: disable selinux
shell: setenforce 0
- name: enable sysctl args
shell: sysctl --system
[root@ecs-proxy node-install]# ansible-playbook node_install.yaml
3、验证安装
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master NotReady master 130m v1.17.6
node-0001 NotReady 2m14s v1.17.6
node-0002 NotReady 2m15s v1.17.6
node-0003 NotReady 2m9s v1.17.6
网络插件安装配置
拷贝云盘 kubernetes/v1.17.6/flannel 目录到 master 上
1、上传镜像到私有仓库
[root@master ~]# cd flannel
[root@master flannel]# docker load -i flannel.tar.gz
[root@master flannel]# docker tag quay.io/coreos/flannel:v0.12.0-amd64 192.168.1.100:5000/flannel:v0.12.0-amd64
[root@master flannel]# docker push 192.168.1.100:5000/flannel:v0.12.0-amd64
2、修改配置文件并安装
[root@master flannel]# vim kube-flannel.yml
128: "Network": "10.244.0.0/16",
172: image: 192.168.1.100:5000/flannel:v0.12.0-amd64
186: image: 192.168.1.100:5000/flannel:v0.12.0-amd64
227-结尾: 删除
[root@master flannel]# kubectl apply -f kube-flannel.yml
3、验证结果
[root@master flannel]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready master 26h v1.17.6
node-0001 Ready 151m v1.17.6
node-0002 Ready 152m v1.17.6
node-0003 Ready 153m v1.17.6
kube-master安装 :方法二
1 安装kubelet、kubeadm 和 kubectl docker-ce
[root@master ~]# wget http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
[root@master ~]# yum -y install docker-ce
[root@ken ~]# mkdir /etc/docker
[root@ken ~]# cat /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": ["https://XXX.mirror.aliyuncs.com"]
}
[root@master ~]# systemctl restart docker
[root@master ~]# systemctl enable docker
[root@master ~]# vim /etc/yum.repos.d/k8s.repo
[k8s]
name=k8s
enabled=1
gpgcheck=0
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
[root@master ~]# yum -y install kubelet kubeadm kubectl
暂时还不能启动服务
2 用 kubeadm 创建 Cluster
各个节点都需要执行下面的操作master,node
[root@master ~]# vim /etc/hosts
192.168.1.21 master
192.168.1.31 node-0001
192.168.1.32 node-0002
192.168.1.33 node-0003
192.168.1.100 registry
要保证打开内置的桥功能,这个是借助于iptables来实现的
[root@master ~]# echo "1" >/proc/sys/net/bridge/bridge-nf-call-iptables
禁止各个节点启用swap,如果启用了swap,那么kubelet就无法启动
[root@ken ~]# swapoff -a && sysctl -w vm.swappiness=0
vm.swappiness = 0
[root@master ~]# free -m
total used free shared buff/cache available
Mem: 991 151 365 7 475 674
Swap: 0 0 0
关闭防火墙和selinux
[root@master ~]# yum remove -y postfix firewalld-*
[root@master ~]# sed -i '/SELINUX/s/enforcing/permissive/' /etc/selinux/config
3 初始化master
[root@master ~]# kubeadm init --image-repository registry.aliyuncs.com/google_containers
--kubernetes-version v1.17.1
--apiserver-advertise-address 192.168.1.21
--pod-network-cidr=10.244.0.0/16 |tee master-init.log
–image-repository string:这个用于指定从什么位置来拉取镜像(1.13版本才有的),默认值是k8s.gcr.io,我们将其指定为国内镜像地址:registry.aliyuncs.com/google_containers
–kubernetes-version string:指定kubenets版本号,默认值是stable-1,会导致从https://dl.k8s.io/release/stable-1.txt下载最新的版本号,我们可以将其指定为固定版本(最新版:v1.19.2)来跳过网络请求。
–apiserver-advertise-address 指明用 Master 的哪个 interface 与 Cluster 的其他节点通信。如果 Master 有多个 interface,建议明确指定,如果不指定,kubeadm 会自动选择有默认网关的 interface。
–pod-network-cidr指定 Pod 网络的范围。Kubernetes 支持多种网络方案,而且不同网络方案对 --pod-network-cidr有自己的要求,这里设置为10.244.0.0/16 是因为我们将使用 flannel 网络方案,必须设置成这个 CIDR。
service-cidr是svc网络,–service-cidr=2.2.2.1/16
创建 日志 tee master-init.log
(推荐)如果计划将单个控制平面 kubeadm 集群升级成高可用, 你应该指定 --control-plane-endpoint 为所有控制平面节点设置共享端点。 端点可以是负载均衡器的 DNS 名称或 IP 地址。
看到下面的输出就表示你的集群创建成功了
.....
Your Kubernetes master has initialized successfully!
.......
mkdir -p $ HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u): $(id -g) $HOME/.kube/config
......
kubeadm join 172.20.10.2:6443 --token rn816q.zj0cdlksganmdfkr --discovery-token-ca-cert-hash sha256:e339e4dbf6bd3683c13e794760fff3cbeb7a3f6f42b71d4cb3cffdde72176658
如果初始化失败,请使用如下代码清除后重新初始化
[root@master ~]# kubeadm reset
[root@master ~]# ifconfig cni0 down
[root@master ~]# ip link delete cni0
ifconfig flannel.1 down
ip link delete flannel.1
[root@master ~]# rm -rf /var/lib/cni/
[root@master ~]# rm -rf /var/lib/etcd/*
docker初始化成功下载的镜像
[root@ken ~]# docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
registry.aliyuncs.com/google_containers/kube-proxy v1.17.1 fdb321fd30a0 6 weeks ago 80.2MB
registry.aliyuncs.com/google_containers/kube-controller-manager v1.17.1 26e6f1db2a52 6 weeks ago 146MB
registry.aliyuncs.com/google_containers/kube-apiserver v1.17.1 40a63db91ef8 6 weeks ago 181MB
registry.aliyuncs.com/google_containers/kube-scheduler v1.17.1 ab81d7360408 6 weeks ago 79.6MB
registry.aliyuncs.com/google_containers/coredns 1.2.6 f59dcacceff4 2 months ago 40MB
busybox latest 59788edf1f3e 3 months ago 1.15MB
registry.aliyuncs.com/google_containers/etcd 3.2.24 3cab8e1b9802 4 months ago 220MB
registry.aliyuncs.com/google_containers/pause 3.1 da86e6ba6ca1 13 months ago 742kB
配置kubectl
[root@master ~]# mkdir -p $HOME/.kube
[root@master ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master ~]# chown $(id -u): $(id -g) $HOME/.kube/config
为了使用更便捷,启用 kubectl 命令的自动补全功能。
[root@master ~]# echo "source <(kubectl completion bash)" >> ~/.bashrc
[root@master ~]# kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health": "true"}
安装pod网络
要让 Kubernetes Cluster 能够工作,必须安装 Pod 网络,否则 Pod 之间无法通信。
[root@master ~]# kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
每个节点启动kubelet
[root@master ~]# systemctl restart kubelet
等镜像下载完成以后,看到node的状态是ready了
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
ken Ready master 17m v1.13.2
此时,就可以看到pod信息了
[root@master ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-78d4cf999f-dbxpc 1/1 Running 0 19m
coredns-78d4cf999f-q9vq2 1/1 Running 0 19m
etcd-ken 1/1 Running 0 18m
kube-apiserver-ken 1/1 Running 0 18m
kube-controller-manager-ken 1/1 Running 0 18m
kube-flannel-ds-amd64-fd8mv 1/1 Running 0 3m26s
kube-proxy-gwmr2 1/1 Running 0 19m
kube-scheduler-ken 1/1 Running 0 18m
添加 k8s-node1 和 k8s-node2 k8s-node3
第一步:环境准备
1.node节点关闭防火墙和selinux
2.禁用swap
3. 解析主机名
4.启动内核功能
第二步:添加nodes
这里的–token 来自前面kubeadm init输出提示,如果当时没有记录下来可以通过kubeadm token list 查看。
[root@host2 ~]# kubeadm join 172.20.10.2:6443 --token rn816q.zj0cdlksganmdfkr --discovery-token-ca-cert-hash sha256:e339e4dbf6bd3683c13e794760fff3cbeb7a3f6f42b71d4cb3cffdde72176658
第三步:查看nodes
根据上面最后一行的输出信息提示查看nodes
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
node-0001 NotReady 2m54s v1.17.2
node-0002 NotReady 2m16s v1.17.2
node-0003 NotReady 2m16s v1.17.2
master Ready master 38m v1.17.2
过了一会查看节点状态
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
node-0001 Ready 2m54s v1.17.2
node-0002 Ready 2m16s v1.17.2
node-0003 Ready 2m16s v1.17.2
master Ready master 38m v1.17.2
补充:移除NODE节点的方法
第一步:先将节点设置为维护模式(node-0001是节点名称)
[root@master ~]# kubectl drain node-0001 --delete-local-data --force --ignore-daemonsets
node/node-0001 cordoned
WARNING: Ignoring DaemonSet-managed pods: kube-flannel-ds-amd64-ssqcl, kube-proxy-7cnsr
node/node-0001 drained
第二步:然后删除节点
[root@master ~]# kubectl delete node node-0001
node "node-0001" deleted
第三步:查看节点
发现node1节点已经被删除了
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
node-0002 Ready 13m v1.17.2
master Ready master 49m v1.17.2
如果这个时候再想添加进来这个node,需要执行两步操作
第一步:停掉kubelet(需要添加进来的节点操作)
[root@node-0001 ~]# systemctl stop kubelet
第二步:删除相关文件
[root@node-0001 ~]# rm -rf /etc/kubernetes/*
第三步:添加节点
[root@node-0001 ~]#kubeadm join 172.20.10.2:6443 --token rn816q.zj0crlasganmrzsr --discovery-token-ca-cert-hash sha256:e339e4dbf6bd1323c13e794760fff3cbeb7a3f6f42b71d4cb3cffdde72179903
第四步:查看节点
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
node-0001 Ready 13s v1.17.2
node-0002 Ready 17m v1.17.2
node-0003 Ready 17m v1.17.2
ken Ready master 53m v1.17.2
忘掉token再次添加进k8s集群
第一步:主节点执行命令
获取token
[root@ken-master ~]# kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
ojxdod.fb7tqipat46yp8ti 10h 2020-010-28T04:55:42+08:00 authentication,signing The default bootstrap token generated by 'kubeadm init'. system:bootstrappers:kubeadm:default-node-token
第二步: 获取ca证书sha256编码hash值
[root@ken-master ~]# openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
6845488cdb01191ff6dbca0edb02dbb21a14469028e4ff511323114a4544c5fa5465
第三步:从节点执行如下的命令
[root@node-0001 ~]# systemctl stop kubelet
第四步:删除相关文件
[root@node-0001 ~]# rm -rf /etc/kubernetes/*
第五步:加入集群
指定主节点IP,端口是6443
在生成的证书前有sha256:
[root@node-0001 ~]# kubeadm join 192.168.64.10:6443 --token ojxdod.fb7tqipat46yp8ti --discovery-token-ca-cert-hash sha256:6845488cdb01191ff6dbca0edb02dbb21a14469028e4ff511323114a4544c5fa5465
系统服务
命名空间
系统命名空间:namespace
—default 默认的命名空间,不声明命名空间的pod都在这个命名空间里
—kube-node-lease 为高可用提供心跳监视的命名空间
—kube-system 系统服务对象所使用的命名空间
—kube-public 公共数据,所有用户都可以读取
kubectl 命令
kubectl是用于控制kubernetes集群的命令行工具
格式:kubectl [command] [TYPE] [NAME] [flags]
command: 子命令,如create,get,describe,delete
type: 资源类型,可以表示为单数,复数或缩写形式
name: 资源的名称,如省略,则显示所有资源信息
flags: 指定可选标志,或附加的参数
kubectl run资源名称 -i -t -d --image=镜像名称:标签 创建资源对象,常用参数-i交互,-t终端 -d 后台运行
kubectl get 查询资源 可选参数 -o wide 显示主机信息 常用查询的资源 node(节点)|deployment(资源)|pod
kubectl get pod -o yml 显示资源文件的yml格式
kubectl exec -it 容器id 执行的命令 同 docker exec 指令,进入容器内
kubectl describe 资源类型 资源名称 查询资源的详细信息(常用于排错)
kubectl attach 同 docker attach 指令,连接容器
kubectl logs 容器id 查看容器控制台的标准输出
kubectl delete 资源类型 资源名称 删除指定的资源
kubectl create|apply -f 资源文件 执行指定的资源文件
kubectl describe deployment 获取 Deployment 描述信息
回顾docker命令
容器管理软件docker,创建删除容器
镜像:———>镜像的编排使用——>启动容器———>集群
docker images #查看镜像
docker push 镜像名称:标签 #上传镜像
docker pull 镜像名称:标签 #下载镜像
docker rmi 镜像名称:标签 #删除镜像
docker history 镜像名称:标签 #查看镜像历史
docker inspect 容器id #容器的详细信息
docker search 镜像名称:标签 #查找镜像
docker save 镜像名称:标签 -o 备份镜像名称.tar #备份镜像(导出镜像)
eg:docker save http:latest -o http.tar
docker tag 镜像名称:标签 新的镜像名称:新的标签 #定义新的镜像名称
docker load -i 备份文件名称 #恢复镜像(导入镜像)
eg:docker load -i http.tar
docker run -itd 镜像名称:标签 #后台运行容器
docker ps #已经运行的容器
docker start/stop/restart 容器id #容器的启动,停止,重启
docker rm -f
docker cp 本机文件路径 容器id:容器内路径 (上传)
docker cp 容器id:
docker exec -it 容器id 启动命令 #进入容器 退出exit容器不关闭
docker attach #进入容器 退出exit容器关闭 ctrl+p ctrl+q退出不关闭容器
docker commit && Dockerfile #自定义镜像
eg:docker commit 02fd1719c038 myos:latest
docker bulid -t 镜像名称 Dock而file所在目录
eg:docker build -t myos:httpd .
docker rm $(docekr ps -aq) #删除所有容器
Dockerfile语法
—FROM: 基础镜像
—RUN: 制作镜像时执行的命令,可以有多个
—ADD: 复制文件到镜像,自动解压
—COPY: 复制文件到镜像,不解压
—EXPOSE 声明开放的端口
—ENV: 设置容器启动后的环境变量
—WORKDIR: 定义容器启动后的环境变量
—CMD: 容器启动时执行的命令,仅可以有一条CMD
POD
pod概述:
—pod是最小的管理元素不是一个个独立的容器,而是Pod,Pod是最小的,管理,创建,计划的最小单元.
—pod支持横向扩展和复制
—每个pod都有一个特殊的被称为“根容器”的Pause容器
—它可能包含一个或者多个紧密相连的应用,这些应用可能是在同一个物理主机或虚拟机上
—Pod 的context可以理解成多个linux命名空间的联合
PID 命名空间(同一个Pod中应用可以看到其它进程)
网络 命名空间(同一个Pod的中的应用对相同的IP地址和端口有权限)
IPC 命名空间(同一个Pod中的应用可以通过VPC或者POSIX进行通信)
UTS 命名空间(同一个Pod中的应用共享一个主机名称)
—pod对象自从其创建开始至终止退出的时间范围称为其生命周期
—pod的生命周期是短暂的,用后即焚的实体:重启pod中的容器和重启pod是不同的,pod只提供容器的运行环境并保持容器的运行状态,启动容器不会造成pod重启
—pod不会自愈,如果pod运行的Node故障,或者是调度器本身故障,这个pod就会被删除
—控制器(Deployment/RC/RS)可以自动创建和管理多个pod提供副本管理,滚动升级和集群级别的自愈能力
 pod的启动过程
pod的启动过程
创建主容器 main container
初始化容器 init container
容器启动后钩子 post start hook
容器存活性探测 liveness probe
就绪性探测 readiness probe
以及容器终止前钩子 pre stop hook

pod phase(pod的相位状态)
pending 容器创建中,但是尚未被调度完成
Running 所有容器都已经被kubelet创建完成
Succeeded 所有容器已经成功终止并不被重启
Failed Pod 中的所有容器中至少有一个容器退出是非0状态
Unknown 无法正常获取到pod对象的状态信息
 pod的创建过程
pod的创建过程
 pod创建过程 :
pod创建过程 :
master:
1 用户发送请求创建pod给API Server (API Server平台的接口,所有组件都与之交互),APIserver将客户端请求传送etcd(数据库),etcd此时记录数据后回复apiserver数据已记录完成,apiserver告知用户创建中,用户看到的信息是pending状态。
2 apiserver 此时通知schedule(调度决策)并告知apiserver在那台node节点上创建pod,ipaserver再次通知etcd更新数据,etcd数据更新完成后通知apiserver数据已更新,apiserver此时通知schedule数据已经更新。
node:
3,apiserver 通知kubelet创建pod,kubelet调用docker创建容器,docker容器创建完成告知kubelet容器已创建完成,kubelet回复apiserverpod创建完成,apiserver再次通知etcd更新数据,数据跟新完成后etcd回复apiserver数据已经更新,apiserver回复已经kubelet数据已经更新,pod创建完成。
注:这个过程就像是公司的一个流程,
角色:user充当顾客 apiserver充当业务员, etcd充当财务 schedule充当生产总监 kubelet充当生产主管 docker充当产线员 pod相当于产品
master:
1,客户跟业务员进行交互,生产pod,业务员将生产pod的数据给到财务记录签字,财务记录完成后告知业务员已经记录,此时业务员告知客户,可以数据已经提交财务等待生产
2.业务员将财务签字的记录的单给到生产总监审批生产pod,生产总监同意,并告知在哪个工厂生产,业务员拿到总监签字的单子再次递交财务跟新数据,财务确认完成数据更新完成后给到业务员,业务员此时告知总监数据已再次经更新。
node:
3.业务员此时拿着财务和总监签字的单到指定的工厂,找到生产主管需要创建一批pod,生产主管调度员工生产,员工生产完后将通知主管已经完成,主管跟业务员对接,已经生产完成,此时业务员最后一次到财务更新数据,财务将数据跟新完成后通知业务员已经记录更新数据,此时业务员通知财务已经签字确认,出库pod,整个流程创建pod完毕。
pod的部署策略
—DaemonSet会调度到除master以外所有的节点
—master节点除了一些系统服务以外不会有在有其他的pod
- 污点和容忍度
污点和容忍度(Toleration)相互配合,可以用来避免 Pod 被分配到不合适的节点上
节点亲和性是 Pod 的一种属性,它使 Pod 被吸引到一类特定的节点。 这可能出于一种偏好,也可能是硬性要求。 Taint(污点)则相反,它使节点能够排斥一类特定的 Pod。
—NoSchedule 不会被调用
—PreferNoSchedule 尽量不调用
—NoExecute 驱逐节点
[root@master ]# kubectl describe node master 查看污点标签
[root@master ]# kubectl taint node node-0001 key=value:NoSchedule 设置污点标签
[root@master ]# kubectl taint node node-0001 key- 删除污点
[root@master ]# pods/pod-with-toleration.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent # 镜像下载策略:默认值,本地有则使用本地镜像,不拉取
tolerations: #容忍
- key: "example-key"
operator: "Exists" #operator 的默认值是 Equal
effect: "NoSchedule"
```
如果 operator 是 Exists (此时容忍度不能指定 value),或者
如果 operator 是 Equal ,则它们的 value 应该相等
如果一个容忍度的 key 为空且 operator 为 Exists, 表示这个容忍度与任意的 key 、value 和 effect 都匹配,即这个容忍度能容忍任意 taint。
如果 effect 为空,则可以与所有键名 key 的效果相匹配。
资源文件
资源对象文件
—kubernetes通过 RC/RS管理pod,在RC中定义如何启动pod,如何运行,启动几个副本等功能
—可以创建,删除,管理资源对象
—ReplicaSet (RS)是RC的升级版
—Deployment 为pods和RS提供描述性的更新方式
—一般由用户来编写 格式包含yml 和json
POD资源文件格式
[root@master ]# vim pod-example.yaml
--- 资源定义的起始标志
apiVersion: v1 格式的版本
kind: Pod 创建资源的类型
metadata: 资源的元数据
name: pod-example 资源的名称
labels: 资源的标签
app: myos 定义当前资源的标签
spec: 资源的详细定义
containers: 定义容器
- name: myos 容器名称,多个容器在一个pod中名称不能重复
image: myos:v1804 启动容器的镜像地址
stdin: true 交互式,相当于-i 后台服务不需要
tty: true 分配终端,相当于-t 后台服务不需要
restartPolicy: Always 资源重启策略[Always,OnFailure,Never] Always是默认策略
[root@master]# kubectl apply -f pod-example.yaml
pod/pod-example created
[root@master]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pod-example 1/1 Running 0 6s
[root@master]# kubectl delete -f pod-example.yaml
pod "pod-example" deleted
deployment资源文件格式
集群中运行过程中动态调整pod的数量
1. kubectl edit deployments.apps web-example #编辑replicas值调整副本数量
2. kubectl scale deployment.apps web-example --replicas=3 #scale命令调整
为了建立控制器和pod间的关联,kubernetes献给每个pod打上一个标签label,然后再给相应的位置定义标签选择器label selector
......
selector: #声明标签选择器
app:http #为服务的后端仙子标签
......
metadata:
labels: #声明标签
app:http #定义标签名称(上下标签必须一致)
[root@master ~]# vim web-example.yaml
--- 资源定义的起始标志
apiVersion: apps/v1 格式的版本
kind: Deployment 创建资源的类型
metadata: 资源的元数据
name: http-example 资源的名称
spec: 资源的详细定义
selector: 资源选择器
matchLabels: 匹配标签
app: my-http 定义标签名称
replicas: 3 定义pod的副本数量
template: 资源模板(需要包含至少一个pod的定义)
metadata: 定义pod的元数据
labels: 定义pod的标签
app: my-http 定义pod的标签名称
spec: 定义标签选择器
# nodeName: node-0001
nodeSelector:
disktype: ssd
containers:
- name: myos
image: 192.168.1.100:5000/myos:httpd
ports:
- protocol: TCP
containerPort: 80
restartPolicy: Always
[root@master ~]# kubectl label nodes node-0002 disktype=ssd
[root@master ~]# kubectl get nodes --show-labels
[root@master ~]# kubectl apply -f web-example.yaml
[root@master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
apache-example-xxx 1/1 Running 0 3m49s 10.244.3.9 node-0002
apache-example-xxx 1/1 Running 0 3m 10.244.2.9 node-0003
#删除标签
[root@master ~]# kubectl label nodes node-0002 disktype-
nodeSelector选择
是节点选择约束的最简单推荐形式。nodeSelector 是 PodSpec 的一个字段。它指定键值对的映射。为了使 pod 可以在节点上运行,节点必须具有每个指定的键值对作为标签(它也可以具有其他标签)。最常用的是一对键值对
标签选择器:node selector 是节点选择约束的最简单推荐形式
—查看标签:kubectl get node --show-lables
—设置标签:kubectl label nodes =
eg:kubectl label nodes kubernetes-foo-node-1.c.a-robinson.internal disktype=ssd
—删除标签: kubectl label nodes -
[root@master ~]# vim nginx.yml
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
nodeSelector:
disktype: ssd
亲和与反亲和
亲和功能包含两种类型的亲和,即“节点亲和”和“pod 间亲和/反亲和”。节点亲和就像现有的 nodeSelector(但具有上面列出的前两个好处),然而 pod 间亲和/反亲和约束 pod 标签而不是节点标签
节点亲和
概念:上类似于 nodeSelector,它使你可以根据节点上的标签来约束 pod 可以调度到哪些节点。
两种节点亲和的类型
requiredDuringSchedulingIgnoredDuringExecution 硬
preferredDuringSchedulingIgnoredDuringExecution 软
节点亲和
pods/pod-with-node-affinity.yaml
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/e2e-az-name
operator: In
values:
- e2e-az1
- e2e-az2
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
containers:
- name: with-node-affinity
image: k8s.gcr.io/pause:2.0
此节点亲和规则表示,pod 只能放置在具有标签键为 kubernetes.io/e2e-az-name 且 标签值为 e2e-az1 或 e2e-az2 的节点上。另外,在满足这些标准的节点中,具有标签键为 another-node-label-key 且标签值为 another-node-label-value 的节点应该优先使用
pod亲和
两种类型的 pod 亲和与反亲和,硬性”与“软性
requiredDuringSchedulingIgnoredDuringExecution
亲和的一个示例是“将服务 A 和服务 B 的 pod 放置在同一区域,因为它们之间进行大量交流
preferredDuringSchedulingIgnoredDuringExecution
反亲和的示例将是“将此服务的 pod 跨区域分布”(硬性要求是说不通的,因为你可能拥有的 pod 数多于区域数
pods/pod-with-pod-affinity.yaml
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: failure-domain.beta.kubernetes.io/zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: failure-domain.beta.kubernetes.io/zone
containers:
- name: with-pod-affinity
image: k8s.gcr.io/pause:2.0
pod 亲和规则表示,仅当节点和至少一个已运行且有键为“security”且值为“S1”的标签的 pod 处于同一区域时,才可以将该 pod 调度到节点上。
更确切的说:如果节点 node-0001 具有带有键 failure-domain.beta.kubernetes.io/zone 和某个值 V 的标签,则 pod 有资格在节点 node-0001 上运行,以便集群中至少有一个节点具有键 failure-domain.beta.kubernetes.io/zone 和值为 V 的节点正在运行具有键“security”和值“S1”的标签的 pod。
pod 反亲和规则表示,如果节点已经运行了一个具有键“security”和值“S2”的标签的 pod,则该 pod 不希望将其调度到该节点上
如果 topologyKey 为 failure-domain.beta.kubernetes.io/zone,则意味着当节点和具有键“security”和值“S2”的标签的 pod 处于相同的区域,pod 不能被调度到该节点上
deployment创建
Deployment 可确保在更新时仅关闭一定数量的 Pods。默认情况下,它确保至少 75%所需 Pods 运行(25%最大不可用)。 Deployment 还确保仅创建一定数量的 Pods 高于期望的 Pods 数。默认情况下,它可确保最多增加 25% 期望 Pods 数(25%最大增量)。
注意:
仅当 Deployment Pod 模板(即 .spec.template)时,才会触发 Deployment 展开,例如,如果模板的标签或容器镜像已更新,其他更新(如扩展 Deployment )不会触发展开。
matchLabels 字段是 {key,value} 的映射。单个 {key,value}在 matchLabels 映射中的值等效于 matchExpressions 的元素,其键字段是“key”,运算符为“In”,值数组仅包含“value”。所有要求,从 matchLabels 和 matchExpressions,必须满足才能匹配
[root@master ~]# vim controllers/nginx-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
[root@master ~]# kubectl apply -f https://k8s.io/examples/controllers/nginx-deployment.yaml
kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 0 0 0 1s
* `NAME` 列出了集群中 Deployments 的名称。
* `DESIRED` 显示应用程序的所需 _副本_ 数,在创建 Deployment 时定义这些副本。这是 _期望状态_。
* `CURRENT`显示当前正在运行的副本数。
* `UP-TO-DATE`显示已更新以实现期望状态的副本数。
* `AVAILABLE`显示应用程序可供用户使用的副本数。
* `AGE` 显示应用程序运行的时间量。
查看 Deployment 展开状态,运行
[root@master ~]#kubectl rollout status deployment.v1.apps/nginx-deployment
Waiting for rollout to finish: 2 out of 3 new replicas have been updated...
deployment.apps/nginx-deployment successfully rolled out
等待几秒查看deployment的
[root@master ~]# kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 3 3 3 18s
Deployment 创建的 ReplicaSet (rs)
[root@master ~]# kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-75675p5896 3 3 3 18s
查看每个 Pod 自动生成的标签
[root@master ~]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-deployment-75675p5896-7li7o 1/1 Running 0 18s app=nginx,pod-template-hash=3133191458
nginx-deployment-75675p5896-koszj 1/1 Running 0 18s app=nginx,pod-template-hash=3133191458
nginx-deployment-75675p5896-qqcnp 1/1 Running 0 18s app=nginx,pod-template-hash=3133191458
查看deployment的描述信息
[root@master ~]# kubectl describe deployment nginx-deployment
**deployment更新**
deployment.spec.strategy支持两种策略:
—Recreate 重建更新,就是删除一个建一个
—rollingUpdate 滚动更新,可以指定个跟新几个pod
rollingUpdate两个参数
—maxSurge 指定超出副本数有几个(指定数量或百分比)
—maxUnavailable 最多有几个不可用
—deploy.spec.revisionHistoryLimit 保留版本数量
更新方法1
[root@master ~]# kubectl --record deployment.apps/nginx-deployment set image deployment.v1.apps/nginx-deployment nginx=nginx:1.9.1
更新方法2
[root@master ~]# kubectl edit deployment.v1.apps/nginx-deployment
.spec.template.spec.containers[0].image 从 nginx:1.7.9 更改至 nginx:1.9.1
[root@master ~]# kubectl rollout status deployment.v1.apps/nginx-deployment 查看展开状态
Deployment 可确保在更新时仅关闭一定数量的 Pods。默认情况下,它确保至少 75%所需 Pods 运行(25%最大不可用)。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.9.1
ports:
- containerPort: 80
回滚 Deployment
当 Deployment 不稳定时,例如循环崩溃。默认情况下,所有 Deployment 历史记录都保留在系统中,以便可以随时回滚(可以通过修改修改历史记录限制来更改该限制)。
如果将nginx:1.9.1-----》写错nginx:1.91
查看更新历史版本,回滚
[root@master ~]# kubectl rollout history deployment.v1.apps/nginx-deployment 检查 Deployment 修改历史
REVISION CHANGE-CAUSE
1 kubectl apply --filename=https://k8s.io/examples/controllers/nginx-deployment.yaml --record=true
2 kubectl set image deployment.v1.apps/nginx-deployment nginx=nginx:1.9.1 --record=true
3 kubectl set image deployment.v1.apps/nginx-deployment nginx=nginx:1.91 --record=true
[root@master ~]# kubectl rollout undo deployment nginx-deployment --to-revision=2 回滚到版本2
[root@master ~]# kubectl rollout undo deployment.v1.apps/nginx-deployment 撤消当前展开并回滚到以前的版本
[root@master ~]# kubectl get deployment nginx-deployment 检查回滚是否成功
`kubectl annotate deployment.v1.apps/nginx-deployment kubernetes.io/change-cause="image updated to 1.9.1"` Deployment 对 Deployment 进行分号。* 追加 `--record` 以保存正在更改资源的 `kubectl` 命令。
缩放 Deployment
[root@master ~]# kubectl scale deployment.v1.apps/nginx-deployment --replicas=5
DaemonSet控制器
DaemonSet 确保全部(或者某些)节点上运行一个 Pod 的副本。当有节点加入集群时, 也会为他们新增一个 Pod 。当有节点从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。
—DaemonSet会调度到除master以外所有的节点
—当有Node加入集群时,也会为他新增pod副本,当Node从集群移除时,这些pod也会被收回
—删除DaemonSet时将删除所有他创建的pod副本
—典型应用:ceph节点 ,监控点, filebeat日志收集等
—系统服务kube-proxy和flannel 就是典型类型
—DaemonSet与deployment相似但是不需要设置replicas,因为DaemonSet是每个节点启动的
格式:
[root@master ~]# vim controllers/daemonset.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
# this toleration is to have the daemonset runnable on master nodes
# remove it if your masters can't run pods
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
Job单任务控制器
Job 会创建一个或者多个 Pods,并确保指定数量的 Pods 成功终止。 随着 Pods 成功结束,Job 跟踪记录成功完成的 Pods 个数。 当数量达到指定的成功个数阈值时,任务(即 Job)结束。 删除 Job 的操作会清除所创建的全部 Pods
[root@master ~]# vim controllers/job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4
CronJob重复多次任务控制器
—基于时间管理的job,是在特定的时间自动创建Job
—典型用法:周期性计划任务
[root@master ~]# vim application/job/cronjob.yaml
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
StatefulSets控制器
StatefulSet 是用来管理有状态应用的工作负载 API 对象,StatefulSet 用来管理 Deployment 和扩展一组 Pod,并且能为这些 Pod 提供序号和唯一性保证。
StatefulSet 为它们的每个 Pod 维护了一个固定的 ID。这些 Pod 是基于相同的声明来创建的,但是不能相互替换:无论怎么调度,每个 Pod 都有一个永久不变的 ID。
稳定的、唯一的网络标识符。
稳定的、持久的存储。
有序的、优雅的部署和缩放。
有序的、自动的滚动更新
稳定意味着 Pod 调度或重调度的整个过程是有持久性的
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx # has to match .spec.template.metadata.labels
serviceName: "nginx"
replicas: 3 # by default is 1
template:
metadata:
labels:
app: nginx # has to match .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx
image: k8s.gcr.io/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "my-storage-class"
resources:
requests:
storage: 1Gi
Horizontal pod Autoscaling控制器
自动扩展,(默认值为 15 秒)可以根据业务的高峰和低谷自动水平扩展pod节点,提高资源利用率
Pod 自动扩缩不适用于无法扩缩的对象,比如 DaemonSet。以使得 Pod 的平均 CPU 利用率与用户所设定的目标值匹配
Pod 自动扩缩特性由KubernetesAPI资源和控制器实现,资源决定了控制器的行为,控制器会周期性的获取平均利用率,并与目标值相比较后来调整副本数量
启动 Deployment 来运行镜像并发布一个服务
kubectl run php-apache --image=k8s.gcr.io/hpa-example --requests=cpu=200m --expose --port=80
创建 Horizontal Pod Autoscaler,Pod 的副本数量维持在 1 到 10 之间,HPA 将通过增加或者减少 Pod 副本的数量(通过 Deployment)以保持所有 Pod 的平均 CPU 利用率在 50% 以内(由于每个 Pod 通过 kubectl run 请求 200 毫核的 CPU) ,这意味着平均 CPU 利用率为 100 毫核)
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
算法细节
期望副本数 = ceil[当前副本数 * (当前指标 / 期望指标)
当前度量值为 200m,目标设定值为 100m,那么由于 200.0/100.0 == 2.0, 副本数量将会翻倍。 如果当前指标为 50m,副本数量将会减半,因为50.0/100.0 == 0.5
查看状态
kubectl get hpa
kubectl get hpa.v2beta2.autoscaling -o yaml > /tmp/hpa-v2.yaml
[root@master ~]# vim /tmp/hpa-v2.yaml
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
status:
observedGeneration: 1
lastScaleTime:
currentReplicas: 1
desiredReplicas: 1
currentMetrics:
- type: Resource
resource:
name: cpu
current:
averageUtilization: 0
averageValue: 0
Metrics API 资源指标管道
metrics(度量资源用量)是一个监控系统资源使用的插件,可以监控node节点上的cpu,内存的使用率,或pod对资源的占用率,通对资源的了解,可以更加合理的部署容器的应用
metrics从kubernetes1.8开始,资源使用情况的监控可以通过metrics API的形式获取,具体的组件为Metrics Server,用来替换之前的heapster
metric-server是扩展的apiserver,依赖于kube-aggregator,因此需要在apiserver中开启相关参数,开启聚合API --enable-aggregator-routing=true
部署metrics-server
开启apiserver聚合服务
[root@master ~]# vim /etc/kubernetes/manifests/kube-apiserver.yaml
#spec.containers.command 最下面手动添加如下一行
- --enable-aggregator-routing=true
[root@master ~]# systemctl restart kubelet
[root@master ~]# kubectl -n kube-system get pod kube-apiserver-master -o yaml |grep enable-aggregator-routing
- --enable-aggregator-routing=true
证书的申请与签发
在所有节点执行(master,node-0001,node-0002,node-0003)
[root@node-0001 ~]# vim /var/lib/kubelet/config.yaml
#在文件的最后一行添加
serverTLSBootstrap: true
[root@node-0001 ~]# systemctl restart kubelet
#-------------------------签发证书必须在 master 上执行 ------------------------------------
[root@master ~]# kubectl get certificatesigningrequests
NAME AGE REQUESTOR CONDITION
csr-wsfz7 8s system:node:master Pending
[root@master ~]# kubectl certificate approve csr-wsfz7
[root@master ~]# kubectl get certificatesigningrequests
NAME AGE REQUESTOR CONDITION
csr-wsfz7 86s system:node:master Approved,Issued
安装mertics插件
拷贝 云盘的kubernetes/v1.17.6/metrics 目录到 master 上
[root@master metrics]# docker load -i metrisc-server.tar.gz
[root@master metrics]# docker tag gcr.io/k8s-staging-metrics-server/metrics-server:master 192.168.1.100:5000/metrics-server:master
[root@master metrics]# docker push 192.168.1.100:5000/metrics-server:master
[root@master metrics]# vim deployment.yaml
29: image: 192.168.1.100:5000/metrics-server:master
[root@master metrics]# kubectl apply -f rbac.yaml 授权控制器
[root@master metrics]# kubectl apply -f pdb.yaml 终断控制器
[root@master metrics]# kubectl apply -f deployment.yaml 主进程metrics
[root@master metrics]# kubectl apply -f service.yaml 后端metrics主进程的服务
[root@master metrics]# kubectl apply -f apiservice.yaml 注册集群API
#-------------------------------- 查询验证 ----------------------------------------------
[root@master metrics]# kubectl -n kube-system get pod
NAME READY STATUS RESTARTS AGE
metrics-server-78dfb54777-4dcjl 1/1 Running 0 116s
[root@master metrics]# kubectl -n kube-system get apiservices
NAME SERVICE AVAILABLE AGE
v1beta1.metrics.k8s.io kube-system/metrics-server True 2m20s
[root@master metrics]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
master 95m 4% 840Mi 48%
node-0001 24m 1% 266Mi 15%
node-0002 24m 1% 270Mi 15%
node-0003 26m 1% 280Mi 16%
Dashboard
—Dashboard是基于网页的kubernetes用户界面
—使用Dashboard将容器应用部署到kubernetes集群中,也可以对容器应用配错及管理资源
—Dashboard获取运行在集群中的应用的概述信息,还可创建或修改kubernetes资源(如Deployment Job DaemonSet等)
—Dashboard同时展示kubernetes集群中的资源状态信息和所有报错信息
官网镜像https://github.com/kubernetes/dashboard
部署Dashboard
拷贝 云盘的kubernetes/v1.17.6/dashboard 目录到 master 上
上传镜像到私有仓库
#上传 dashboard 镜像
[root@master dashboard]# docker load -i dashboard.tar.gz
[root@master dashboard]# docker tag kubernetesui/dashboard:v2.0.0 192.168.1.100:5000/dashboard:v2.0.0
[root@master dashboard]# docker push 192.168.1.100:5000/dashboard:v2.0.0
#上传 metrics-scraper 镜像
[root@master dashboard]# docker load -i metrics-scraper.tar.gz
[root@master dashboard]# docker tag kubernetesui/metrics-scraper:v1.0.4 192.168.1.100:5000/metrics-scraper:v1.0.4
[root@master dashboard]# docker push 192.168.1.100:5000/metrics-scraper:v1.0.4
安装dashboard
[root@master dashboard]# vim recommended.yaml
# 43 行新添加
nodePort: 30090
# 46 行新添加
type: NodePort
# 191 行修改为
image: 192.168.1.100:5000/dashboard:v2.0.0
# 275 行修改为
image: 192.168.1.100:5000/metrics-scraper:v1.0.4
[root@master dashboard]# kubectl apply -f recommended.yaml
#---------------------------------- 查询验证 --------------------------------------
[root@master dashboard]# kubectl -n kubernetes-dashboard get pod
NAME READY STATUS RESTARTS AGE
dashboard-metrics-scraper-57bf85fcc9-vsz74 1/1 Running 0 52s
kubernetes-dashboard-7b7f78bcf9-5k8vq 1/1 Running 0 52s
[root@master dashboard]# kubectl -n kubernetes-dashboard get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S)
dashboard-metrics-scraper ClusterIP 10.254.76.85 8000/TCP
kubernetes-dashboard NodePort 10.254.211.125 443:30090/TCP
在华为云上为 node 节点绑定弹性公网IP [ https://弹性公网IP:30090/ ]
token认证登录
[root@master dashboard]# kubectl apply -f admin-token.yaml
[root@master ~]# kubectl -n kubernetes-dashboard get secrets
NAME TYPE DATA AGE
admin-user-token-bxjlz kubernetes.io/service-account-token 3 23s
[root@master ~]# kubectl -n kubernetes-dashboard describe secrets admin-user-token-bxjlz
Name: admin-user-token-bxjlz
... ...
ca.crt: 1025 bytes
namespace: 20 bytes
token: 这里这个很长的字符串就是你要找的认证 token


Prometheus
官网https://prometheus.io/ :prometheus是由谷歌研发的一款开源的监控软件
prometheus特点:
—自定义多为数据模型
—非常高效的存储平均一个采样数据占3.5bytes左右
—在多维度上灵活且强大的查询语言(PromQl)
—不依赖分布式存储,支持单节点工作通过基于HTTP的pull方式采集数据可以通过push Gateway进行时序列数据推送,可以通过服务发现或者静态配置去获取要采集的目标服务器多种可视化图标及仪表盘
镜像以及资源文件网址:https://github.com/coreos/kube-promtheus
prometheus组成:
—Prometheus server:对监控数据的获取,存储以及查询
—Exporters:采集node节点的数据提供prom server
—metrics-state:获取各种资源的最新状态(pod,deploy)
—adapter:获取APIserver的资源指标提供给Prom server
—AlertManager:Prometheus体系中的告警处理中心
—Grafana:支持多种图形和Dashboard的展示
—operator:以扩展kubernetes api的形式,帮助用户创建配置和管理复杂的有状态的应用程序

部署Prometheus
导入镜像
kubernetes/v1.17.6/prometheus/images/ 下所有镜像导入到私有仓库
拷贝所有镜像到 master 的 images 目录下
[root@master images]# for i in *.gz;do docker load -i ${i};done
[root@master images]# img="prom/node-exporter v1.0.0
quay.io/coreos/prometheus-config-reloader v0.35.1
quay.io/coreos/prometheus-operator v0.35.1
quay.io/coreos/kube-state-metrics v1.9.2
grafana/grafana 6.4.3
jimmidyson/configmap-reload v0.3.0
quay.io/prometheus/prometheus v2.11.0
quay.io/prometheus/alertmanager v0.18.0
quay.io/coreos/k8s-prometheus-adapter-amd64 v0.5.0
quay.io/coreos/kube-rbac-proxy v0.4.1"
[root@master images]# while read _f _v;do
docker tag ${_f}: ${_v} 192.168.1.100:5000/ $ {_f##*/}: ${_v}
docker push 192.168.1.100:5000/ ${_f##*/}: ${_v}
docker rmi ${_f}: ${_v}
done <<<" ${img}"
[root@master images]# curl http://192.168.1.100:5000/v2/_catalog
{"repositories":["alertmanager","configmap-reload","coredns","dashboard","etcd","flannel","grafana","k8s-prometheus-adapter-amd64","kube-apiserver","kube-controller-manager","kube-proxy","kube-rbac-proxy","kube-scheduler","kube-state-metrics","metrics-scraper","metrics-server","myos","nginx-ingress-controller","node-exporter","pause","prometheus","prometheus-config-reloader","prometheus-operator"]}
operator安装
拷贝prometheus/setup 目录到 master 下
[root@master prometheus]# curl http://192.168.1.100:5000/v2/configmap-reload/tags/list
{"name":"configmap-reload","tags":["v0.3.0"]}
[root@master prometheus]# curl http://192.168.1.100:5000/v2/prometheus-config-reloader/tags/list
{"name":"prometheus-config-reloader","tags":["v0.35.1"]}
[root@master prometheus]# curl http://192.168.1.100:5000/v2/prometheus-operator/tags/list
{"name":"prometheus-operator","tags":["v0.35.1"]}
[root@master prometheus]# vim setup/prometheus-operator-deployment.yaml
27: - --config-reloader-image=192.168.1.100:5000/configmap-reload:v0.3.0
28: - --prometheus-config-reloader=192.168.1.100:5000/prometheus-config-reloader:v0.35.1
29: image: 192.168.1.100:5000/prometheus-operator:v0.35.1
#验证安装
[root@master prometheus]# kubectl apply -f setup/
[root@master prometheus]# kubectl -n monitoring get pod
NAME READY STATUS RESTARTS AGE
prometheus-operator-75b4b59b74-72qhg 1/1 Running 0 47s
Prometheus server安装
拷贝 prometheus/prom-server 目录到 master 下
[root@master prometheus]# curl http://192.168.1.100:5000/v2/prometheus/tags/list
{"name":"prometheus","tags":["v2.11.0"]}
[root@master prometheus]# vim prom-server/prometheus-prometheus.yaml
14: baseImage: 192.168.1.100:5000/prometheus
34: version: v2.11.0
[root@master prometheus]# kubectl apply -f prom-server/
[root@master prometheus]# kubectl -n monitoring get pod
NAME READY STATUS RESTARTS AGE
prometheus-k8s-0 3/3 Running 1 45s
prometheus-k8s-1 3/3 Running 1 45s
prom-adapter安装
拷贝 prometheus/prom-adapter 目录到 master 下
[root@master prometheus]# curl http://192.168.1.100:5000/v2/k8s-prometheus-adapter-amd64/tags/list
{"name":"k8s-prometheus-adapter-amd64","tags":["v0.5.0"]}
[root@master prometheus]# vim prom-adapter/prometheus-adapter-deployment.yaml
28: image: 192.168.1.100:5000/k8s-prometheus-adapter-amd64:v0.5.0
[root@master prometheus]# kubectl apply -f prom-adapter
[root@master prometheus]# kubectl -n monitoring get pod
NAME READY STATUS RESTARTS AGE
prometheus-adapter-856854f9f6-knqtq 1/1 Running 0 6s
metrics-state安装
拷贝 prometheus/metrics-state 目录到 master 下
[root@master prometheus]# curl http://192.168.1.100:5000/v2/kube-state-metrics/tags/list
{"name":"kube-state-metrics","tags":["v1.9.2"]}
[root@master prometheus]# curl http://192.168.1.100:5000/v2/kube-rbac-proxy/tags/list
{"name":"kube-rbac-proxy","tags":["v0.4.1"]}
[root@master prometheus]# vim metrics-state/kube-state-metrics-deployment.yaml
24: image: 192.168.1.100:5000/kube-rbac-proxy:v0.4.1
41: image: 192.168.1.100:5000/kube-rbac-proxy:v0.4.1
58: image: 192.168.1.100:5000/kube-state-metrics:v1.9.2
[root@master prometheus]# kubectl apply -f metrics-state/
[root@master prometheus]# kubectl -n monitoring get pod
NAME READY STATUS RESTARTS AGE
kube-state-metrics-5894f64799-krvn6 3/3 Running 0 4s
node-exporter安装
拷贝 prometheus/node-exporter 目录到 master 下
[root@master prometheus]# curl http://192.168.1.100:5000/v2/node-exporter/tags/list
{"name":"node-exporter","tags":["v1.0.0"]}
[root@master prometheus]# curl http://192.168.1.100:5000/v2/kube-rbac-proxy/tags/list
{"name":"kube-rbac-proxy","tags":["v0.4.1"]}
[root@master prometheus]# vim node-exporter/node-exporter-daemonset.yaml
27: image: 192.168.1.100:5000/node-exporter:v1.0.0
57: image: 192.168.1.100:5000/kube-rbac-proxy:v0.4.1
[root@master prometheus]# kubectl apply -f node-exporter/
[root@master prometheus]# kubectl -n monitoring get pod
NAME READY STATUS RESTARTS AGE
node-exporter-7h4l9 2/2 Running 0 7s
node-exporter-7vxmx 2/2 Running 0 7s
node-exporter-mr6lw 2/2 Running 0 7s
node-exporter-zg2j8 2/2 Running 0 7s
alertmanager安装
拷贝 prometheus/alertmanager 目录到 master 下
[root@master prometheus]# curl http://192.168.1.100:5000/v2/alertmanager/tags/list
{"name":"alertmanager","tags":["v0.18.0"]}
[root@master prometheus]# vim alertmanager/alertmanager-alertmanager.yaml
09: baseImage: 192.168.1.100:5000/alertmanager
18: version: v0.18.0
[root@master prometheus]# kubectl apply -f alertmanager/
[root@master prometheus]# kubectl -n monitoring get pod
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 16s
alertmanager-main-1 2/2 Running 0 16s
alertmanager-main-2 2/2 Running 0 16s
grafana安装
拷贝 prometheus/grafana 目录到 master 下
[root@master prometheus]# curl http://192.168.1.100:5000/v2/grafana/tags/list
{"name":"grafana","tags":["6.4.3"]}
[root@master prometheus]# vim grafana/grafana-deployment.yaml
19: - image: 192.168.1.100:5000/grafana:6.4.3
[root@master prometheus]# kubectl apply -f grafana/
[root@master prometheus]# kubectl -n monitoring get pod
NAME READY STATUS RESTARTS AGE
grafana-647d948b69-d2hv9 1/1 Running 0 19s
发布服务
grafana服务
[root@master prometheus]# cp grafana/grafana-service.yaml ./
[root@master prometheus]# vim grafana-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: grafana
name: grafana
namespace: monitoring
spec:
type: NodePort
ports:
- name: http
port: 3000
nodePort: 30002
targetPort: http
selector:
app: grafana
[root@master prometheus]# kubectl apply -f grafana-service.yaml
[root@master prometheus]# kubectl -n monitoring get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S)
grafana NodePort 10.254.79.49 3000:30002/TCP
服务发布以后可以通过华为云弹性公网IP直接访问即可
grafana 第一次默认登录的用户名/密码(admin/admin)
 web监控
web监控
 添加数据源地址
添加数据源地址
—数据源就是Prometheus service的地址
—可以填写prometheus的service内部DNS名称
[root@master~]# kubectl -n monitoring get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(s)
....
prometheus-k8s NodePort 10.254.45.77 9090:30001/TCP
配置数据源





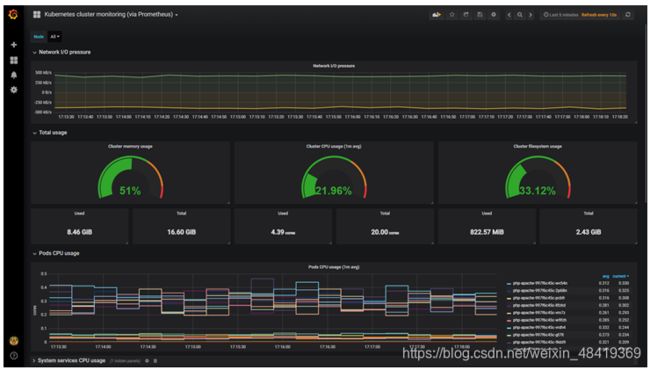
在这里插入图片描述 可以下载不同的页面展示效果
可以下载不同的页面展示效果