性能分析工具介绍
本文作者:The Performance,原文发布于:Android Performance。
原文首发于知识星球:The Performance。

Paul Graham 在其著作 <黑客与画家> 中断言:“不同语言的执行效率差距正变得越来越大,所以性能分析器(profiler)将变得越来越重要。目前,性能分析并没有受到重视。许多人好像仍然相信,程序运行速度提升的关键在于开发出能够生成更快速代码的编译器。代码效率与机器性能的差距正在不断加大,我们将会越来越清楚地看到,应用软件运行速度提升的关键在于有一个好的性能分析器帮助指导程序开发。”
by Paul Graham 黑客与画家
谷歌搜索 「Android 优化工具」,你会找到很多与此相关的内容。他们的问题在于要么是内容高度重复、要么是直接讲使用方法,很少会给你介绍整体性的架构,一不小心就会让人会种「一个工具搞定一切」的错误认知。以笔者团队的多年经验来看,在性能分析领域这种银弹级别的工具是不存在的。工具在发展,老问题会以新的方式变样出现,不掌握核心逻辑的话始终会让你浮于技术的表面。
本文首先系统性的梳理性能分析中的可观测性技术,它涵盖数据类型、抓取方法以及分析方法等三部分内容,之后是介绍谷歌提供的「三大件」分析工具。目的是想让你了解不变的理论性的知识,以及与之对应的在安卓环境中可用的工具,这些可以让你少走一些弯路,直接复用前辈们的经验。
需要特别说明的是,对于性能优化肯定不止有这三个工具可用,但这个三个工具是我们平时用到的「第一手工具」。进行进一步分析之前,你都需要依赖这三个工具进行瓶颈定位,之后才应不同领域特性选择对应的工具进行下钻分析。
1 性能分析中的可观测性技术
- 这个操作到底有没有被执行?执行时间有多长?
- 为什么两个版本的前后差异这么大?
- 当 CPU 使用量变高的时候系统都在执行什么操作?
- 为什么启动速度变慢了?
- 为什么这个页面滑动总是会卡一下?
相信你不止一次被同事、被老板问到过类似的问题。最原始的想法应该是,首先是拿到相关的日志进行逐个分析。根据以往经验,通过查找关键字寻找蛛丝马迹。如果没有想看的信息,那就加上日志尝试本地复现。费时费力不说,也还费研发资源。但你有没有想过行业里有没有更高效的方法?可以提高一个数量级的那种,把我们的时间花在问题解决上而不是无聊的重复性体力活儿上?
答案当然是有的(否则就不会有这篇文章了),我们称他为可观测性技术。
计算机行业发展至今,计算机前辈们捣鼓出了所谓的「可观测性技术」的类别。它研究的是通过工具,来观测复杂系统的运行细节,内容越细越好。 移动操作系统之前是由嵌入式发展而来的,现在的中高端安卓手机算力都能赶得上二十几年前的一个主机的算力,在此算力基础上所带来的软件复杂度也是非常巨大的。
如果你的程序部署了一个精心设计且运行良好的可观测性技术,可以大大加快研发软件的效率,因为即使我们使用了各种各样的前置性静态代码检测、人工代码审查,也无法 100% 拦截软件的问题。只有在真实环境里运行之后才知道是否真正发生了问题,即使这个环境可能是一个你的自动化测试用例。即使这样,你还需要翻阅你的日志,重读代码来找出问题。出于这些原因,每个工程团队都需要有一个功能完备的可观测性工具作为他们的基础设施之一。
可观测性技术是一个系统性工程,它能够让你更深入的了解软件里发生的事情。可用于了解软件系统内部运行过程(特别是对于业务逻辑或者交互关系复杂的系统)、排查问题甚至通过寻找瓶颈点优化程序本身。对于复杂的系统来说,你通过阅读代码来了解整个运行过程其实是很困难的事情,更高效的方法就是借助此类工具,以最直观的的方式获取软件运行的状态。
下面将从 数据类型、数据获取方法、分析方法 这三个主题来帮助你了解可观测性技术。
1.1 数据类型
日志的形式可能是键值对(key=Value),JSON、CSV,关系型数据库或者其他任何格式。其次我们通过日志还原出系统当时运行的整个状态,目的是为了解决某个问题,观察某个模块的运行方式,甚至刻画系统使用者的行为模式。在可观测性技术上把日志类型分类为 Log 类型、Metric 类型,以及 Trace 类型。

Log 类型
Log 是最朴素的数据记录方式,一般记录了什么模块在几点发生了什么事情,日志等级是警告还是错误。 绝大部分系统,不管是嵌入式设备还是汽车上的计算机,他们所使用的日志形式几乎都是这种形式。这是最简单,最直接也最好实现的一种方式。几乎所有的 Log 类型是通过 string 类型的方式存储,数据呈现形式是一条一条的文本数据。Log 是最基本的类型,因此通过转换,可以将 Log 类型转换成 Metric 或者 Trace 类型,当然成本就是转换的过程,当数据量非常巨大的时候这可能会成为瓶颈。
为了标识出不同的日志类型等级,一般使用错误、警告、调试等级别来划分日志等级。显然,错误类型的是你首要关注的日志等级。不过实践中也不会严格按照这种方式划分,因为很多工程师不会严格区分他们之间的差异,这可能是他们的工程开发环境中不太会对不同等级的日志进行分类分析有关。总之,你可以根据你的目的,将 Log 类型进行等级划分,它就像一个索引一样,可以进一步可以提高分析问题、定位目标信息的效率。
Metric 类型
Metric 类型相比 Log 类型使用目的上更为聚焦,它记录的是某个维度上数值的变化。知识点是「维度」与「数值」的变化。维度可能是 CPU 使用率、CPU Cluster 运行频率,或者上下文切换次数。数值变化既可以是采样时候的瞬时值(成为快照型)、与前一次采样时的差值(增或减)、或者某个时段区间的统计聚合值。实践中经常会使用统计值,比如我想看问题发生时刻前 5 分钟的 CPU 平均使用量。这时候需要将这五分钟内的所有数值做算数平均计算,或者是加权平均(如: 离案发点越近的样本它的权重就越高)。Log 类型当然可以实现 Metric 类型的效果,但是操作起来非常麻烦而且其性能损耗可能也不小。
聚合是非常有用的工具,因为人不可能逐个分析所有的 Metric 值,因此借助聚合的方式判断是否出了问题之后再进行详细的分析是更为经济高效的方法。
Metric 类型的另外一个好处是它的内容格式是比较固定的,因此可以通过预编码的方式进行数据存储,空间的利用率会更紧凑进而占用的磁盘空间就更少。最简单的应用就是数据格式的存储上,如果使用 Log 类型,一般采用的是 ASCII 编码,而 Metric 使用的是整数或者浮点等固定 byte 数的数据,当存储较大数值时显然 ASCII 编码需要的字节数会多于数字型数据,并且在进行数据处理的时候你可以直接使用 Metric 数据,而不需要把 Log 的 ASCII 转换成数字型后再做转换。
除了是具体的数值之外,也可以存储枚举值(某种程度上它的本质就是数值)。不同的枚举值代表不同的意义,可能是开和关、可能是不同的事件类型。
Trace 类型
Trace 类型标识了事件发生的时间、名称、耗时。多个事件通过关系,标识出了是父与子还是兄弟。当分析多个线程间复杂的调用关系时 Trace 类型是最方便的数据分析方式。
Trace 类型特别适用于 Android 应用与系统级的分析场景,因为用它可以诊断:
- 函数调用链
- Binder 调用时的调用链
- 跨进程事件流跟踪
Android 的应用程序运行环境的设计中,一个应用程序是无法独自完成所有的功能的,它需要跟 SystemServer 有大量的交互才能完成它的很多功能。与 SystemServer 间的通讯是通过 Binder 完成,它的通讯方式后面的文章再详细介绍,到目前为止你只需要知道它的调用关系是跨进程调用即可。这需要本端与远端的数据才能准确还原出调用关系,Trace 类型是完成这种信息记录的最佳方式。
Trace 类型可以由你手动添加开始与结束点,在一个函数里可以添加多个这种区间。通过预编译技术或者编程语言的特性,在函数的开头与结尾里自动插桩 Trace 区间。理想情况下后者是最好的方案,因为我们能知道系统中运行的所有的函数是哪些、执行情况与调用关系是什么。可以拿这些信息统计出调用次数最多(最热点)的函数是什么,最耗时的函数又是什么。可想而知这种方法带来的性能损耗非常大,因为函数调用的频次跟量级是非常大的,越是复杂的系统量级就越大。
因此有一种迂回的方法,那就通过采样获取调用栈的方式近似拟合上面的效果。采样间隔越短,就越能拟合真实的调用关系与耗时,但间隔也不能太小因为取堆栈的操作本身的负载就会变高因为次数变多了。这种方法,业界管他叫 Profiler,你所见过的绝大部分编程语言的 Profiler 工具都是基于这个原理实现的。
1.2 数据获取方法
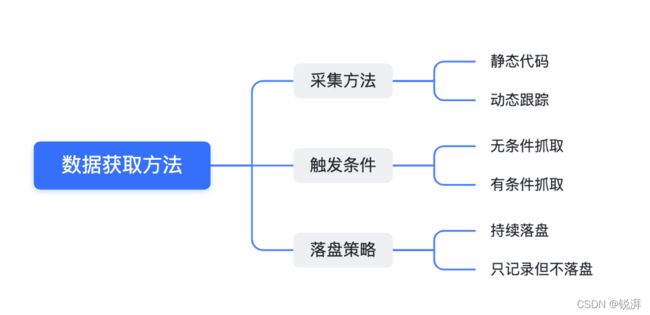
静态代码与动态跟踪
静态代码的采集方式是最原始的方式,优点是实现简单缺点是每次新增内容的时候需要重新编译、安装程序。当遇到问题之后你想看的信息恰好没有的话,就没有任何办法进一步定位问题,只能重新再来一遍整个过程。更进一步的做法是预先把所有可能需要的地方上加入数据获取点,通过动态判断开关的方式选择是否输出,这既可以控制影响性能又能够在需要日志的时候可以动态打开,只不过这种方法的成本非常高。
动态跟踪技术其实一直都存在,只是它的学习成本比较高,被誉为调试跟踪领域里的屠龙刀。它需要你懂比较底层的技术,特别是编译、ELF 格式、内核、以及熟悉代码中的预设的探针、动态跟踪所对应的编程语言。对,你没看错,这种技术甚至还有自己的一套编程语言用于「动态」的实现开发者需求。这种方式兼具性能、灵活性,甚至线上版本里遇到异常后可以动态查看你想看的信息。
Android 应用开发、系统级开发中用的比较少,内核开发中偶尔会用一些。只有专业、专职的性能分析人员才可能会用上这类工具。它有两个关键点,探针与动态语言,程序运行过程中需要有对应的探针点将程序执行权限交接到动态跟踪框架,框架执行的逻辑是开发者使用动态语言来编写的逻辑。
所以,你的程序里首先是要有探针,好在 Linux 内核等框架埋好了对应的探针点,但是 android 应用层是没有现成的。所以目前 Android 上能用动态框架,如 eBPF 基本都是内核开发者在使用。
无条件式抓取与有条件式抓取
无条件式抓取比较好理解,触发抓取之后不管发生任何事情,都会持续抓取数据。缺点是被观测对象产生的数据量非常大的时候可能会对系统造成比较大的影响,这种时候只能通过降低数据量的方式来缓解。需要做到既能满足需求,性能损失又不能太大。
有条件式抓取经常用在可以识别出的异常的场景里。比如当系统的某个观测值超过了预先设定的阈值时,此时触发抓取日志并且持续一段时间或者达到另外一种阈值之后结束抓取。这相比于前面一个方法稍微进步了一些,仅在出问题的时候对系统有影响,其他时候没有任何影响点。但它需要你能够识别出异常,并且这种异常是不需要异常发生之前的历史数据。当然你可以通过降低阈值来更容易达到触发点,这可能会提高触发数据抓取的概率,这时候会遇到前面介绍的无条件式抓取遇到的同样的问题,需要平衡性能损失。
落盘策略
持续落盘是存储整个数据抓取过程中的所有数据,代价是存储的压力。如果能知道触发点,比如能够检测到异常点,这时候可以选择性的落盘。为了保证历史数据的有效性,因此把日志先暂存储到 RingBuffer 中,只有接受到落盘指令后再进行落盘存储。这种方式兼顾了性能与存储压力,但成本是运行时内存损耗与触发器的准确性。
1.3 分析方式

数据可视化分析
随着问题分析的复杂化,出现了要解决多个模块间交互的性能问题需求,业界就出现了以时间为横轴把对应事件放到各自泳道上的数据可视化分析方法,可以方便的看到所关心事件什么时候发生、与其他系统的交互信息等等。在 Android 里我们常用的 Systrace/Perfetto 以及更早之前的 KernelShark 等工具本质上都是这一类工具。在「数据类型」提到的 「Trace 类型」,经常采用这种可视化分析方法。
Systrace 的可视化框架是基于 Chrome 的一个叫 Catapult 的子项目构建。Trace Event Format 讲述了 Catapult 所支持的数据格式,如果你有 Trace 类型的数据,完全可以使用此框架来展示可视化数据。AOSP 编译系统,安卓应用的编译过程,也都有相应的 Trace 文件输出,它们也都基于 Catapult 实现了可视化效果。
数据库分析
面对大量数据分析的分析,通过对数据进行格式化,把他们转换成二维数据表,借助 SQL 语言可实现高效的查询操作。在服务器领域中 ELK 等技术栈可以实现更为灵活的格式化搜索与统计功能。借助数据库与 Python,你甚至可以实现一套自动化数据诊断工具链。
从上面的讨论可知,从文本分析到数据库分析他们要面对的分析目的是不一样的。单纯的看一个模块的耗时用文本分析就够用了,多个系统间的交互那就要用可视化工具,复杂的数据库分析就要用到 SQL 的工具。无论哪种分析方式,本质上都是针对数据的分析,在实战中我们经常会通过其他工具对数据进行转换以支持不同的分析方式,比如从文本分析方式改成数据库分析方式。
根据自己的目的,选择合适的分析方式才会让你的工作事倍功半。
对于 Android 开发者来说,Google 提供了几个非常重要的性能分析工具,帮助系统开发者、应用开发者来优化他们的程序。
2 谷歌提供的 Andorid 性能分析工具
从实践经验来看最常用的工具有 Systrace,Perfetto 与 Android Studio 中的 Profiler 工具。通过他们定位出主要瓶颈之后,你才需要用到其他领域相关工具。因此,会重点介绍这三个工具的应用场景,它的优点以及基本的使用方法。 工具之间的横向对比,请参考下一个「综合对比」这一章节的内容。
2.1 初代系统性能分析工具 - Systrace
Systrace 是 Trace 类型的可视化分析工具,是第一代系统级性能分析工具。Trace 类型所支持的功能它都有支持。在 Perfetto 出现之前,基本上是唯一的性能分析工具,它将 Android 系统和 App 的运行信息以图形化的方式展示出来,与 Log 相比,Systrace 的图像化方式更为直观;与 TraceView 相比,抓取 Systrace 时候的性能开销基本可以忽略,最大程度地减少观察者效应带来的影响。

Systrace 的设计思路
在系统的一些关键操作(比如 Touch 操作、Power 按钮、滑动操作等)、系统机制(input 分发、View 绘制、进程间通信、进程管理机制等)、软硬件信息(CPU 频率信息、CPU 调度信息、磁盘信息、内存信息等)的关键流程上,插入类似 Log 的信息,我们称之为 TracePoint(本质是 Ftrace 信息),通过这些 TracePoint 来展示一个核心操作过程的执行时间、某些变量的值等信息。然后 Android 系统把这些散布在各个进程中的 TracePoint 收集起来,写入到一个文件中。导出这个文件后,Systrace 通过解析这些 TracePoint 的信息,得到一段时间内整个系统的运行信息。

Android 系统中,一些重要的模块都已经默认插入了一些 TracePoint,通过 TraceTag 来分类,其中信息来源如下
- Framework Java 层的 TracePoint 通过 android.os.Trace 类完成
- Framework Native 层的 TracePoint 通过 ATrace 宏完成
- App 开发者可以通过 android.os.Trace 类自定义 Trace
这样 Systrace 就可以把 Android 上下层的所有信息都收集起来并集中展示,对于 Android 开发者来说,Systrace 最大的作用就是把整个 Android 系统的运行状态,从黑盒变成了白盒。全局性和可视化使得 Systrace 成为 Android 开发者在分析复杂的性能问题的时候的首选。
实践中的应用情况
解析后的 Systrace 由于有大量的系统信息,天然适合分析 Android App 和 Android 系统的性能问题, Android 的 App 开发者、系统开发者、Kernel 开发者都可以使用 Systrace 来分析性能问题。
- 从技术角度来说,Systrace 可覆盖性能涉及到的 响应速度 、卡顿丢帧、 ANR 这几个大类。
- 从用户角度来说,Systrace 可以分析用户遇到的性能问题,包括但不限于:
- 应用启动速度问题,包括冷启动、热启动、温启动
- 界面跳转速度慢、跳转动画卡顿
- 其他非跳转的点击操作慢(开关、弹窗、长按、选择等)
- 亮灭屏速度慢、开关机慢、解锁慢、人脸识别慢等
- 列表滑动卡顿
- 窗口动画卡顿
- 界面加载卡顿
- 整机卡顿
- App 点击无响应、卡死闪退
在遇到上述问题后,可以使用多种方式抓取 Systrace ,将解析后的文件在 Chrome 打开,然后就可以进行分析
2.2 新一代性能分析全栈工具 - Perfetto
谷歌在 2017 年开始了第一笔提交,随后的 4 年(截止到 2021.12)内总共有 100 多位开发者提交了近 3.7W 笔提交,几乎每天都有 PR 与 Merge 操作,是一个相当活跃的项目。 除了功能强大之外其野心也非常大,官网上号称它是下一代面向可跨平台的 Trace/Metric 数据抓取与分析工具。应用也比较广泛,除了 Perfetto 网站,Windows Performance Tool 与 Android Studio,以及华为的 GraphicProfiler 也支持 Perfetto 数据的可视化与分析。 我们相信谷歌还会持续投入资源到 Perfetto 项目,可以说它应该就是下一代性能分析工具了,会完全取代 Systrace。
提供的亮点功能
Perfetto 相比 Systrace 最大的改进是可以支持长时间数据抓取,这是得益于它有一个可在后台运行的服务,通过它实现了对收集上来的数据进行 Protobuf 的编码并存盘。从数据来源来看,核心原理与 Systrace 是一致的,也都是基于 Linux 内核的 Ftrace 机制实现了用户空间与内核空间关键事件的记录(ATRACE、CPU 调度)。Systrace 提供的功能 Perfetto 都支持,由此才说 Systrace 最终会被 Perfetto 替代。

Perfetto 所支持的数据类型、获取方法,以及分析方式上看也是前所未有的全面,它几乎支持所有的类型与方法。数据类型上通过 ATRACE 实现了 Trace 类型支持,通过可定制的节点读取机制实现了 Metric 类型的支持,在 UserDebug 版本上通过获取 Logd 数据实现了 Log 类型的支持。
你可以通过 Perfetto.dev 网页、命令行工具手动触发抓取与结束,通过设置中的开发者选项触发长时间抓取,甚至你可以通过框架中提供的 Perfetto Trigger API 来动态开启数据抓取,基本上涵盖了我们在项目上能遇到的所有的情境。
在数据分析层面,Perfetto 提供了类似 Systrace 操作的数据可视化分析网页,但底层实现机制完全不同,最大的好处是可以支持超大文件的渲染,这是 Systrace 做不到的(超过 300M 以上时可能会崩溃、可能会超卡)。在这个可视化网页上,可以看到各种二次处理的数据、可以执行 SQL 查询命令、甚至还可以看到 logcat 的内容。Perfetto Trace 文件可以转换成基于 SQLite 的数据库文件,既可以现场敲 SQL 也可以把已经写好的 SQL 形成执行文件。甚至你可以把他导入到 Jupyter 等数据科学工具栈,将你的分析思路分享给其他伙伴。
比如你想要计算 SurfaceFlinger 线程消耗 CPU 的总量,或者运行在大核中的线程都有哪一些等等,可以与领域专家合作,把他们的经验转成 SQL 指令。如果这个还不满足你的需求, Perfetto 也提供了 Python API,将数据导出成 DataFrame 格式近乎可以实现任意你想要的数据分析效果。
这一套下来供开发者可挖掘的点就非常多了,从笔者团队的实践来看,他几乎可以覆盖从功能开发、功能测试、CI/CD 以及线上监控、专家系统等方方面面。本星球的后续系列文章中,也会重点介绍 Perfetto 的强大功能与基于它开发的专家系统,可以帮助你「一键解答」性能瓶颈。
实践中的应用情况
性能分析首要用到的工具就是 Perfetto,使用 Systrace 的场景是越来越少了。所以,你首要掌握的工具应该是 Perfetto,学习它的用法以及它提供的指标。
不过 Perfetto 也有一些边界,首先它虽然提供了较高的灵活性但本质上还是静态数据收集器,不是动态跟踪工具,跟 eBPF 还是有本质上的差异。其次运行时成本比较高,因为涉及到在手机中实现 Ftrace 数据到 Perfetto 数据的转换。最后他不提供文本分析方式,只能通过网页可视化或者操作 SQLite 来进行额外的分析了。综合来看 Perfetto 是功能强大,几乎涵盖了可观测性技术的方方面面,但是使用门槛也比较高。值得挖掘与学习的知识点比较多,我们后续的文章中也会重点安排此部分的内容。
2.3 Android Studio Profiler 工具
Android 的应用开发集成环境(官方推荐)是 Android Studio (之前是Eclipse,不过已经淘汰了) ,它自然而然也需要把开发和性能调优集成一起。非常幸运的是,随着 Android Studio 的迭代、演进,到目前,Android Studio 有了自己的性能分析工具 Android Profiler,它是一个集合体,集成了多种性能分析工具于一体,让开发者可以在 Android Studio 做开发应用,也不用再下载其它工具就能让能做性能调优工作。
目前 Android Studio Profiler 已经集成了 4 类性能分析工具: CPU、Memory、Network、Battery,其中 CPU 相关性能分析工具为 CPU Profiler,也是本章的主角,它把 CPU 相关的性能分析工具都集成在了一起,开发者可以根据自己需求来选择使用哪一个。可能很多人都知道,谷歌已经开发了一些独立的 CPU 性能分析工具,如 Perfetto、Simpleperf、Java Method Trace 等,现在又出来一个 CPU Profiler,显然不可能去重复造轮子,CPU Profiler 目前做法就是:从这些已知的工具中获取数据,然后把数据解析成自己想要的样式,通过统一的界面展示出来。
提供的亮点功能
CPU Profiler 集成了性能分析工具:Perfetto、Simpleperf、Java Method Trace,它自然而然具备了这些工具的全部或部分功能,如下:
- System Trace Recording,它是用 Perfetto 抓取的信息,可用于分析进程函数耗时、调度、渲染等情况,但是它一个精简版,只能显示进程强相关的信息且会过滤掉耗时短的事件,建议将 Trace 导出文件后在 Perfetto UI 上进行分析。
- Java Method Trace Recording,它是从虚拟机获取函数调用栈信息,用于分析 Java 函数调用和耗时情况。
- C/C++ Function Trace,它是用 Simpleperf 抓取的信息,Simpleperf 是从 CPU 的性能监控单元 PMU 硬件组件获取数据。 C/C++ Method Trace 只具备 Simpleperf 部分功能,用于分析 C/C++ 函数调用和耗时情况。
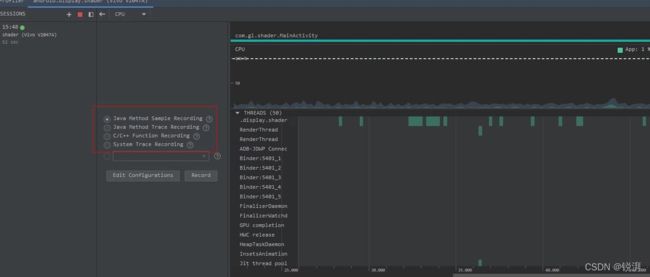
实践中的应用情况
应用的性能问题主要分为两类:响应慢、不流畅。
- 响应慢问题常有:应用启动慢、页面跳转慢、列表加载慢、按钮响应慢等
- 不流畅问题常有:列表滑动不流畅、页面滑动不跟手、动画卡顿等
CPU Profiler 在这些场景中要如何使用呢?基本的思路是:首先就要抓 System Trace,先用System Trace 分析、定位问题,如果不能定位到问题,再借助 Java Method Trace 或 C/C++ Function Trace 进一步分析定位。
以一个性能极差的应用为例,在系统的关键位置插了 Systrace TracePoint,假设对代码不熟悉,那要怎么找到性能瓶颈呢?我们先把应用跑起来,通过 CPU Profiler 录制一个 System Trace (后面文章会介绍工具的使用方法)如下:
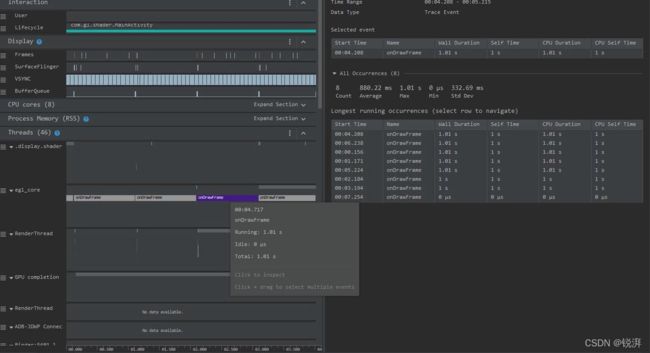
通过上面 Trace 可以知道是在 egl_core 线程中的 onDrawFrame 操作耗时,如果发现不了问题,建议导出到 Perfetto UI 进一步分析,可以查找源代码看看 onDrawFrame 是什么东西, 我们通过查找发现 onDrawFrame 是 Java 函数 onDrawFrame 的耗时,要分析 Java 函数耗时情况,我们要录制一个 Java Method Trace,如下:
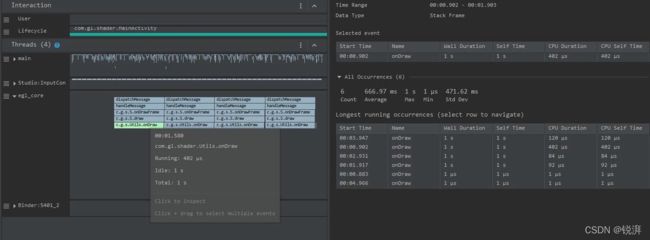
通过上面 Trace 很容易发现是一个叫做 Utils.onDraw 的 native 函数耗时,因为涉及到C/C++ 代码,所以要再录制一个 C/C++ Function Trace 进一步分析,如下:

可以发现在 native 的 Java_com_gl_shader_Utils_onDraw 中代码执行了 sleep,它就是导致了性能低下的罪魁祸首!
AS 中的 CPU Profiler 最大优势是集成了各种子工具,在一个地方就能操作一切,对应用开发者来说是非常方便的,不过对系统开发者来说可能没那么幸运。
2.4 综合对比
| 工具名称 | 应用场景 | 数据类型 | 获取方法 | 分析方式 |
|---|---|---|---|---|
| Systrace | Android 系统与应用性能分析 | Trace 类型 | 无条件抓取 持续落盘 | 可视化分析 |
| Perfetto | Android 系统与应用性能分析 | Metric 类型 Trace 类型 | 无条件抓取 持续落盘 | 可视化分析 数据库分析 |
| AS Profiler | Android 系统与应用性能分析 | Trace 类型 | 无条件抓取 持续落盘 | 可视化分析 |
| SimplePerf | Java/C++ 函数执行耗时 分析 PMU 计数器 | Trace 类性 | 无条件抓取 持续落盘 | 可视化分析 文本分析 |
| Snapdragon Profiler Tools & Resources | 主要是高通 GPU 性能分析器 | Trace 类型 Metric 类型 | 无条件抓取 持续落盘 | 可视化分析 |
| Mali Graphics Debugger | ARM GPU 分析器(MTK、麒麟芯片) | Trace 类型 Metric 类型 | 无条件抓取 持续落盘 | 可视化分析 |
| Android Log/dumpsys | 综合分析 | Log 类型 | 有条件抓取 持续抓取但不落盘 | 文本分析 |
| AGI(Android GPU Inspector) | Android GPU 分析器 | Trace 类型 Metric 类型 | 无条件抓取 持续落盘 | 可视化分析 |
| eBPF | Linux 内核行为动态跟踪 | Metric 类型 | 动态跟踪 有条件抓取 持续抓取但不落盘 | 文本分析 |
| FTrace | Linux 内核埋点 | Log 类型 | 静态代码 有条件抓取 持续抓取但不落盘 | 文本分析 |
3 关于「器、术、道」
技术上的变革、改进更多是体现在「器」层面,Linux 社区以及谷歌所开发的工具发展方向朝着提高工具的集成化使得在一个地方可以方便查到所需的信息、或者是朝着获取更多信息的方向发展。总之,器层面他们的发展轨迹是可寻的,可总结出发展规律。 我们需要在工具快速迭代的时候准确的认识到他们能力以及应用场景,其目的是提高解决问题的效率,而不是把时间花在学习新工具上。
「术」层面依赖具体的业务知识,知道一帧是如何被渲染的、CPU 是如何选择进程调度的、IO 是如何被下发的等等。只有了解了业务知识才能正确的选择工具并正确的解读工具所提供的信息。随着经验的丰富,有时候你都不需要看到工具提供的详细信息,也可以查到蛛丝马迹,这就是当你业务知识丰富到一定程度,大脑里形成了复杂的关联性信息之后凌驾于工具之上的一种能力。
「道」层面思考的是要解决什么问题,问题的本质是什么?做到什么程度以及需要投入什么样的成本达成什么样的效果。为了解决一个问题,什么样的路径的「投入产出比」是最高的?整体打法是什么样?为了完成一件事,你首先要做什么其次是做什么,前后依赖关系的逻辑又是什么?
后续的文章中,会依照「器、术、道」方式讲解一个技术、一个功能,我们不止想让你学习到一个知识点,更想激发你举一反三的能力。遇到类似的工具或者类似的问题、更进一步是完全不同的系统,都能够从容应对。牢牢抓住本质,通过评估「投入产出比」选择合适的工具或信息,高效解决问题。
附录
- Perfetto 项目地址
- 官方使用文档: Perfetto - System profiling, app tracing and trace analysis - Perfetto Tracing Docs
- Github 代码库 https://github.com/google/perfetto ,可以提 bug 或者需求,当然也可以提 PR 贡献你的力量。
- Android GPU Inspector
- 官方使用文档: https://developer.android.com/agi
- 其他大厂的性能分析工具
- Windows Performance Toolkit
原文作者:Gracker
原文链接:Android 性能优化的术、道、器 · Android Performance