利用 Python 自动抓取微博热搜,并定时发送至邮箱

 作者:F
作者:F
来源:早起Python
最近微博的瓜一个接一个,本文就将介绍如何用Python自动抓取微博热搜,并定时发送到QQ邮箱。主要分为三部分:
爬取微博热搜
整理数据与发送邮箱
定时执行

一、抓取热搜数据
进入微博热搜榜https://s.weibo.com/top/summary后,整体页面如下:

可以看到,我们需要的热搜榜单信息在页面的正中央(总共50条热搜),这里我们需要爬取的信息有热搜标题、话题搜索量、以及话题指数。按F12进入网页源代码页面,点击element内容如下:

选中鼠标选项,点击你要爬取的信息,就可以看到对应的html源码。这里我们爬取的分为三个部分:标题、数量、指数、网址四个信息,而我们可以从网页源代码发现如下规律:
| 信息 | 源代码规律 | |
|---|---|---|
| 标题 | 标题 | |
| 数量 | 数量 | |
| 指数 | 指数 | |
| 指数1 | (.*?) | |
| 连接 | 标题 |
注意:这里之所以有指数和指数1源代码是因为前者获取到的数据是有杂音的,所以需要再次用到指数1获得最终的信息。
之后我们运用requests包爬取网页源代码并通过re模块对爬取内容进行正则提取,因为每天仅执行一次,也就不用考虑请求头什么的,Python代码如下:
import requests
import re
url = 'https://s.weibo.com/top/summary?cate=realtimehot' #微博网址
ret = requests.get(url)
test = ret.text
u_href = '.*?'
u_title = '(.*?)'
u_amount = '(.*?)'
u_category = '(.*?)'
u_href = '.*?'
title = re.findall(u_title,test)
amount = re.findall(u_amount,test)
category = re.findall(u_category,test)
href = re.findall(u_href,test)
二、数据清洗
上面获取到的title、amount、category、href四个指标是未经处理的话题、话题搜索量、话题指数、话题连接。接下来我们对其进行处理,先上代码
import pandas as pd
title = title[:-2]
title = title[1:]
href = href[:-2]
href = href[1:]
for j in range(len(href)):
href[j] = 'https://s.weibo.com/' + href[j]
while '' in amount:
amount.remove('')
for i in range(len(category)):
if category[i] != '':
category[i] = re.findall('(.*?)',category[i])[0]
if category[i] == '':
category[i] = '空'
category = category[1:]
while '荐' in category:
category.remove('荐')
df = pd.DataFrame()
df['关键词'] = title
df['amount'] = amount
df['category'] = category
df['href'] = href
df = df.sort_values('amount')
df2 = df[df['category']=='爆']
df3 = df[df['category']=='沸']
df4 = df[df['category'] == '热']
df5 = df[df['category'] == '新']
df6 = df[df['category'] == '空']
df = pd.concat([df2,df3,df4,df5,df6],ignore_index = True)
df.to_csv('微博热搜.csv',encoding = 'gbk')#输出为csv文本格式
下面对title进行处理,第一节爬取到的title是这样的。
总共只有50条热搜,怎么多出来3条?可以看到最后的两条是不需要的,所以用列表提取的方法提取前50行。还有一个元素多出来?就是我们的第一个元素,即是title[0],title[0]是没有序号与热搜搜索量的,如图:
“天问一号成功着陆”这一话题有指数无搜索量,是属于缺失数据,这里我们删除它,同样用到列表提取元素方法。
对href连接的处理与title的处理相同。
接着对搜索量做处理,采用了删除空格的语句。原因是热搜榜中会出现推荐的话题,而推荐的话题是没有搜索量的,故我们删除它。
最后轮到指数处理,先看未处理前的指数。

上面显而易见我们要提取的指数信息就在每个元素里面,同样利用re模块正则提取,提取出来后做三件事:
去除第一个元素(原因已在title处理上讲解)
空字符串部分以中文空子代替
去除推荐的话题
上面三步的代码已附上。代码里最后的步骤就是运用pandas模块对数据进行整理得到美观的数据框形式。效果如下:
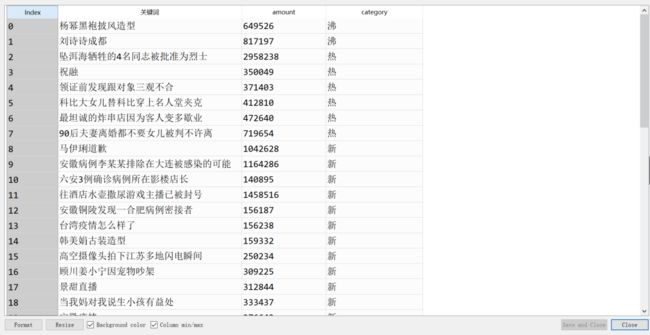
三、发邮箱与设置定时
用Python可以模拟许多大厂的邮箱发送,本文选择常用的腾讯QQ邮箱。在此之前需要做一个准备(获取SMTP授权码):
登录QQ邮箱并单击设置按钮,然后进入账户这个页面

进入之后向下拖动来到POP3/IMAP/SMTP/Exchange/CardDAV/CalDAV服务这栏,这里单击POP3/SMTP服务右侧的开启,单击后会有一个验证密保的过程,按照提示即可。最终会弹出一个框,里面包含SMTP授权码,这里可以找个地方记录起来,Python代码就可以用到。
先上发送QQ邮箱的代码模板:
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
number = '你的QQ邮箱号码'
smtp = '邮箱对应的STMP授权码'
to = '需要发送到的QQ邮箱号码' # 可以是非QQ的邮箱
mer = MIMEMultipart()
# 设置邮件正文内容
head = '''
微博热搜榜信息
最热门词条为
{}
排名前五的热搜
{}
{}
{}
{}
{}
'''.format(df.iloc[0,:]['href'],df.iloc[0,:]['关键词'],
df.iloc[1,:]['href'],df.iloc[1,:]['关键词'],
df.iloc[2,:]['href'],df.iloc[2,:]['关键词'],
df.iloc[3,:]['href'],df.iloc[3,:]['关键词'],
df.iloc[4,:]['href'],df.iloc[4,:]['关键词'],
df.iloc[5,:]['href'],df.iloc[5,:]['关键词'])
mer.attach(MIMEText(head, 'html', 'utf-8'))
fujian = MIMEText(open('微博热搜.csv', 'rb').read(), 'base64', 'utf-8')
fujian["Content-Type"] = 'application/octet-stream' #附件内容
fujian.add_header('Content-Disposition', 'file', filename=('utf-8', '', '微博热搜.csv'))
mer.attach(fujian)
mer['Subject'] = '每日微博热搜榜单' #邮件主题
mer['From'] = number #发送人
mer['To'] = to #接收人
# 5.发送邮件
s = smtplib.SMTP_SSL('smtp.qq.com', 465)
s.login(number, smtp)
s.send_message(mer) # 发送邮件
s.quit()
print('成功发送')
代码框架基本如此,你需要更改的地方有如下,其余的内容可以不改:
邮件主题
发送人
接收人
SMTP授权码
附件内容
运行成功后,输出框会有“成功发送”打印,如果你的微信绑定了你的发送QQ邮箱,那么你就可以点击其中的附件,也就是csv文件。
按照我们设置的格式,把最热门的词条和排名前五的词条放入head正文内容中,效果如下:

(这里存在延时,所以热搜榜和上面不一)
最后就是设置定时执行这个代码也即是发送微博热搜榜信息,利用Schedule库可以实现。
schedule模块设置定时的模板只需改2个地方,一个是schedule.every().day.at("18:00").do(email)中的时间,一个是def函数里面运行的内容。While True的作用就是让程序不停止。
我们定每晚6点进行自动发送,代码如下:
import schedule
import time
def email():
number = '你的QQ邮箱号码'
smtp = '邮箱对应的STMP授权码'
to = '需要发送到的QQ邮箱号码' # 可以是非QQ的邮箱
mer = MIMEMultipart()
# 设置邮件正文内容
head = '''
微博热搜榜信息
最热门词条为
{}
排名前五的热搜
{}
{}
{}
{}
{}
'''.format(df.iloc[0,:]['href'],df.iloc[0,:]['关键词'],
df.iloc[1,:]['href'],df.iloc[1,:]['关键词'],
df.iloc[2,:]['href'],df.iloc[2,:]['关键词'],
df.iloc[3,:]['href'],df.iloc[3,:]['关键词'],
df.iloc[4,:]['href'],df.iloc[4,:]['关键词'],
df.iloc[5,:]['href'],df.iloc[5,:]['关键词'])
mer.attach(MIMEText(head, 'html', 'utf-8'))
fujian = MIMEText(open('微博热搜.csv', 'rb').read(), 'base64', 'utf-8')
fujian["Content-Type"] = 'application/octet-stream' #附件内容
fujian.add_header('Content-Disposition', 'file', filename=('utf-8', '', '微博热搜.csv'))
mer.attach(fujian)
mer['Subject'] = '每日微博热搜榜单' #邮件主题
mer['From'] = number #发送人
mer['To'] = to #接收人
# 5.发送邮件
s = smtplib.SMTP_SSL('smtp.qq.com', 465)
s.login(number, smtp)
s.send_message(mer) # 发送邮件
s.quit()
print('成功发送')
schedule.every().day.at("18:00").do(email)
while True:
schedule.run_pending()
time.sleep(5)
这样,我们就完成了利用 Python 自动爬取微博热搜,并在每天指定时间自动发送整理后的结果至邮箱。当然你也可以自已更改逻辑,例如 当出现指定关键词、指定tag时发送邮箱,感兴趣的读者可以来一波三连~


往
期
回
顾
技术
如何跟蜻蜓的大脑学习计算?
新闻
鲲鹏应用创新大赛山西区域赛圆满落幕
排行
TIOBE 8月编程语言排行榜
转载
终于有人站出来为程序员说话了

分享
![]()
点收藏

点点赞

点在看