JAVA面经整理(10)
一)MyBatis有什么优缺点?
Mybatis是⼀种典型的半自动化的ORM 框架,所谓的半自动,因为还需要⼿动的写 SQL 语句在XML文件里面,再由框架根据SQL以及传入数据来进行组装成要执行的SQL,所谓的ORM框架,就是对象关系映射框架,就是让JAVA程序中的类里面的属性直接映射到数据库中的表里面的列,在Java中操作这个类的时候,就相当于直接操作数据库中的表和字段;
1)更灵活:支持自定义SQL映射,结果集映射,来满足不同的需求
2)更好的性能控制:SQL都是自己写的,可以加索引,可以进行SQL优化,不像Hibernate那样SQL是由程序自动生成的,Hibernate是自己调用API生成SQL语句,万一性能不好没有办法
3)可读性很好:将SQL查询和映射配置分离到XML文件中,使得代码更有可读性,便于维护和调试
4)二级缓存:MyBatis支持二级缓存,可以缓存查询结果提升查询性能,减少数据库访问次数
5)动态SQL:MyBatis会根据条件自动生成SQL语句
6)支持多种数据库:MYBATIS支持多种数据库,可以灵活的切换数据库供应商
缺点:成也萧何,败也萧何
1)繁杂的XML配置:处理大量SQL查询的时候比较麻烦;
2)手动写SQL:虽然手动编写SQL可以更好地进行性能控制,但是也需要更多的时间和精力来手动维护和优化SQL,如果有一天更换数据库,SQL都是需要重写的,移植性很差;
Hibernate是⼀种典型的全⾃动 ORM 框架,所谓的全⾃动,是 SQL 语句都不⽤在编写,基于框架的 API,可以将对象⾃动的组装为要执⾏的 SQL 语句,简单的SQL连SQL语句都不用编写,底层会提供一个Insert方法,只需要将对象的属性设置进去,将这个对象放到方法的参数里面,就可以进行使用了,最终调用save方法


二)MyBatis和Hibernate和Spring Data JPA有什么区别?
1)MYBatis是一个典型的半自动ORM框架,Hibernate和SpringDataJPA是全自动的ORM框架
2)MyBatis自己写比较灵活,但是MyBatis不能反向的生成表结构,但是Hibernate和Spring Data JPA对于SQL的要求没有那么高,只需要熟练使用API即可,他们俩都可以生成表结构
3)Mybatis在国内用的比较多,剩下这俩在国外用的比较多
4)Spring Data JPA底层是基于Hibernate来实现的,SDJ是一个SPI;
5)对于MyBatis来说,更换数据库的重新写SQL代价很大,但是对于剩下那两个不需要更换API
1)全⾃动 ORM 框架,调用固定的方法,⾃动的组装为 SQL 语句,单表查询比较简单;
2)可以跨数据库,底层框架提供了多套主流数据库的 SQL ⽣成规则,数据库从MYSQL转变成SQLServer基本上不需要改一行代码,因为你的是HQL语法,是中间语法,相当于是门面模式;
Hibernate的缺点:
1)学习⻔槛更⾼,要学习框架 API 与 SQL 之间的转换关系,况且如果实现一个简单的增删改查是非常简单的,但是说如果写一些复杂的SQL调用API就会很麻烦,Hibernate提供了一些自己复杂的语法进行复杂SQL查询,提供的HQL语法是一个中间语法,况且最终生成的SQL也不知道,Hibernate提供一些特殊的API来实现更复杂的SQL语句,使用精通非常难;
2)对数据库模型依赖⾮常⼤,在软件需求变更频繁的系统中,会导致⾮常难以调整及维护。可能数据库中随便改⼀个表或字段的定义,Java代码中要修改⼏⼗处
3)很难定位问题,也很难进⾏性能优化,需要精通框架,对数据库模型设计也⾮常熟悉
三)数据库属性名和类中的字段名冲突咋解决?
在MyBatis中,属性名和字段名如果不一致的话会出现查询和其他操作的时候是NULL,如果进行映射的话,那么查询和映射都不会出现为NULL的情况
1)更改属性或者是字段名让二者保持一致
2)查询的时候使用as重映射字段名,能够在查询的时候也能够找到相应的值
3)使用结果集映射,使用resultMap来映射相应的字段,要映射全部映射,否则多表联查会出现NULL值
4)使用MyBatis-plus中的@TableField字段来进行映射,再类中属性上面加上@TableField("数据库中的属性名")
四)MyBatis是如何实现对象映射?
1)MyBatis底层是基于JDBC实现的,返回查询的结果集
2)每一个查询结果集就是一个ResultSet,循环ResultSet将行数据赋值给返回对象
3)每一行数值赋值的流程如下:
3.1)先进行判断返回类型是否是ResultMap,如果是,那么就以ResultMap中设置的映射关系为主进行赋值
3.2)如果没有设置ResultMap那么就使用数据库的字段名和表中的字段名进行对比并完成赋值
4)遍历完成ResultMap将结果返回给用户
五)MyBatis的执行流程:
1)加载配置文件:MyBatis的执行流程首先从加载配置文件开始,通常MyBatis的配置文件是一个XML文件,其中包含了数据源配置,SQL映射配置和连接池配置等信息;
2)构建sqlSessionFactory对象:在配置文件进行加载以后,MyBatis使用配置信息来构建sqlSessionFactory对象,这是MyBatis的核心工厂类,SqlSessionFactory是线程安全的,他是用来创建sqlSession对象;
3)创建sqlSession对象:应用程序会通过SqlSeessionFactory来创建SqlSession对象,SqlSession代表一次数据库会话,它提供了SQL执行的方法,通常情况下,每一个线程都是有着自己的SqlSession对象;
4)执行SQL查询:在SqlSession中,开发人员可以执行SQL查询,可以通过两种方式来实现
4.1)使用注解来加SQL:MyBatis使用了注解+SQL的执行方式,MyBatis会为Mapper接口,生成代理对象,实际来执行SQL查询;
4.2)使用XML映射文件:开发人员可以通过XML来自定义SQL查询语句和映射关系,然后通过sqlSession来执行SQL查询,将结果集映射到JAVA对象上;
5)SQL解析和执行:MYBatis会解析SQL执行,进行SQL查询,并获取到执行结果,如果是select操作,就返回一个ResultSet,如果是DML操作,就返回一个数字
6)结果集映射:MyBatis将使用配置的结果映射规则,将查询结果映射成JAVA对象上面,将数据库的列映射到JAVA对象的属性上面,并来处理关联关系等等
7)返回结果:查询结果返回给应用程序,开发人员可以针对于接过来做进一步处理
8)sqlSession:关闭SqlSession释放资源
六)#和$有什么区别?
#和$都是MyBatis用来替换参数的,但是两者的区别主要体现在以下方面:
1)含义不同:#{}是预处理,$是直接替换
2)使用场景不同:普通参数使用#{}来进行处理,程序会认为你传递的参数都是一个值,会自动加双引号,但是$如果传递的是SQL命令或者是SQL中的关键字,但是需要做好安全验证
3)安全性不同
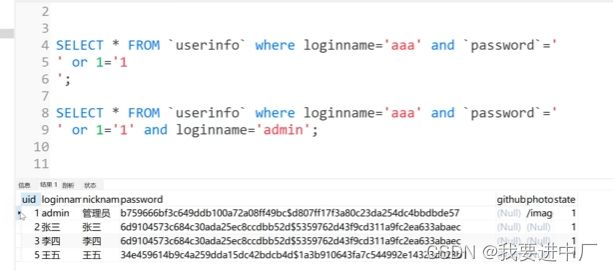
SQL注入:SQL注入指的是应用程序对于用户的输入的合法性数据没有判断或者说是过滤不严,攻击者可以在应用程序中实现定义好的查询语句的末尾加上额外的SQL语句,在管理员不知情的条件下进行非法的查询操作,以此来欺骗数据库服务器执行的非授权查询,从而进一步来得到用户的数据信息;
由此可以看出以上程序在应用程序不知情的情况下进行非法操作,以此来实现欺骗数据库服务器执行非授权的敏感数据的查询操作;
七)MyBatis是如何实现分页的?
MyBatis分页实现有两种方式
1)物理分页:物理分页是通过SQL查询语句,在数据库引擎层实现的,比如说使用MYSQL的limit语法实现分页
1.1)通过XML中直接拼接SQL来实现分页,传入limit和offset
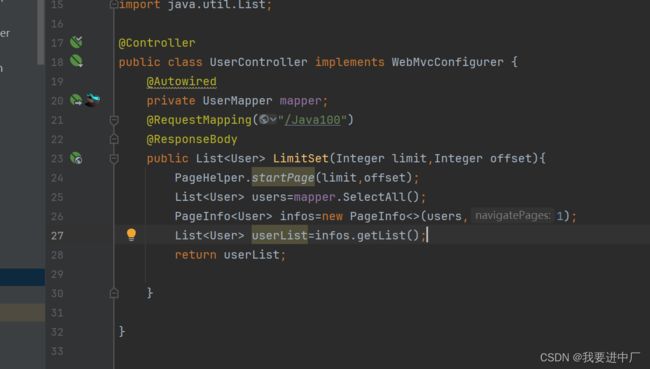
1.2)通过pageHelper来实现物理分页
注意:这里面的数据库的属性名和表中的字段名必须要相同
com.github.pagehelper pagehelper 5.1.2 #pagehelper分页插件配置 # pagehelper: helperDialect: mysql reasonable: true supportMethodsArguments: true params: count=countSql
2)逻辑分页:逻辑分页是在应用程序方面实现的分页,通常是先查询出所有符合条件的数据,然后在内存中,然后在内存中针对于数据进行查询操作,在内存效率很低;
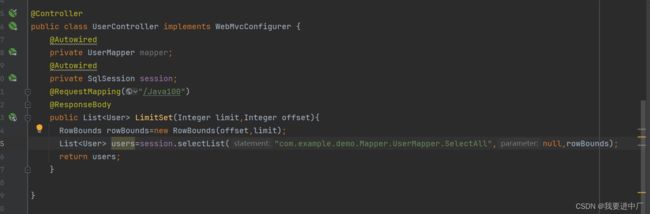
2.1)注入SqlSession对象
2.2)新创建RowBounds对象,里面指定分页的规则
2.3)调用SqlSession对象的selectList方法,里面传入三个参数,mapper中的方法名对应的路径,第二个参数是传递的参数,第三个参数是rowBounds
在MyBatis中,为什么可以将Mapper接口直接进行注入使用?
为什么只在UserService里面写了一个@Resource就可以把标记了@Mapper的接口直接注入使用?
表面上是一个接口,但实际上咱们的程序时不会进行new这个接口的,而是使用代理的方式来进行实现的(调用动态代理子类)
八)RowBounds是一次性查询所有数据吗?
RowBounds表面上是在所有数据中进行检索数据,但是其实本质上并非是一次性查询出所有数据,因为MyBatis是基于对JDBC的封装,在JDBC驱动中有一个fetch-Size中的属性,规定了每一次最多从数据库中拉取多少数据,在select标签中可以指定fetchSize属性



Synchronized常见面试题:
1)synchronized在JVM从JDK1.6是有锁升级的一个过程的,况且是靠监视器锁来实现的,在方法进入之前加上一个moniterenter,离开监视器锁是moniterexit,监视器就类似于是一个房间,只能由同一个线程进去,无锁,偏向锁,轻量级锁,重量级锁
2)锁在在对象头里面有一个标识,用来标识当前有没有锁,是属于哪一个线程里面的,当有线程尝试获取这把锁的时候,会进行判断线程ID和我们对象头中的线程ID是不是一致的,如果是一致的,那么代表我是可以重入的,你已经拥有这把锁了,我就可以重新获取到这把锁,说明我是可重入的;
3)如果ID不同,当前锁已经被其他线程占有了,就会一直尝试获取锁,使用自旋锁,这是自适应的;
九)什么是动态SQL
根据查询条件的不同来动态的生成最终查询的SQL,是一种动态构建查询查询语句的机制,允许在SQL查询中根据不同的条件来生成不同的SQL语句来满足查询的需求,动态SQL里面包含条件判断,循环,参数替换等功能,使得SQL查询更加的具有灵活性和可重用性
填写条件,查询的是特定条件的值,如果不填写条件,那么查询的是所有的值
1)if标签,有一个test属性,就是类似于JAVA中的if判断
2)trim标签,prefix,suffix,prefixOverrides,suffixOverrides
3)where标签,自动加where条件,并且会自动去除最前面的and
4)set标签,自动加上set条件,并且会自动去除最前面的逗号
5)forEach标签:循环迭代集合,collection,seperator,open,close
十)MyBatis的二级缓存:不适用于多写少读的问题,多写经常更新缓存的问题
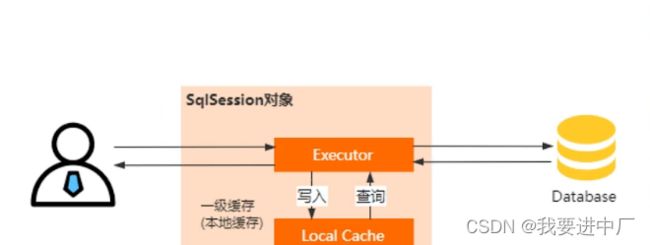
MyBatis的缓存机制属于本地缓存,适用于单机系统,他的目的就是为了减少数据库的查询次数,从而来提升系统的查询性能;
MyBatis中一共包含着两级缓存:
1)SqlSession级别的,是MyBatis自带的缓存功能,默认情况下是开启的,并且无法进行关闭,但是当两个SqlSession访问同一条SQL语句的时候,,一级缓存也不会生效,需要查询两次数据库;
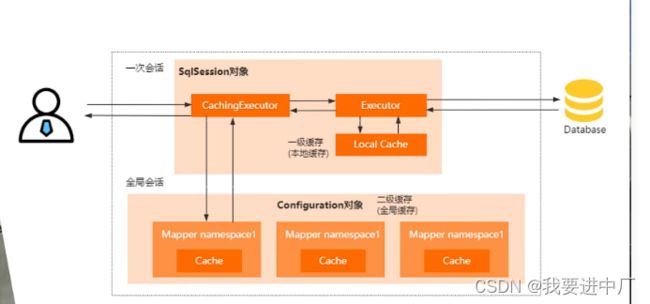
2)二级缓存是Mapper级别的,只要是同一个Mapper,无论使用多少个SqlSession来进行操作,数据都是共享的,也就是说多个不同的SqlSession可以共用二级缓存,MyBatis的二级缓存默认是关闭的,需要的时候需要手动开启,二级缓存也可以使用第三方的缓存,比如说使用Ehance作为二级缓存;
1)一级缓存是SqlSession级别的缓存,它的作用域就是同一个SqlSession,同一个SqlSession的多次查询会共享同一个缓存,二级缓存是Mapper级别的缓存,它的作用域就是同一个Mapper,同一个Mapper的多次查询会共享同一个缓存;
2)一级缓存是不需要手动开启的,不需要手动配置,二级缓存需要手动配置,需要在Mapper.xml文件中进行手动配置
3)一级缓存的生命周期是和SqlSession一样长的,当SqlSession关闭的时候,一级缓存也会被清空,二级缓存的生命周期适合MapperFactory是一样长的,当应用程序关闭的时候,二级缓存也会被清空;
4)一级缓存只能用于同一个SqlSession的多次查询,不能用于跨SqlSession的查询,二级缓存可以用于跨Sql之间的查询,多个SqlSession可以共享同一个二级缓存
5)一级缓存是线程私有的,不同的SqlSession之间的缓存数据不会受到干扰,二级缓存是线程之间共享的,多个SqlSession可以共享同一个二级缓存,就需要考虑到线程安全问题
总结:MyBatis的缓存机制属于本地缓存,适用于单机系统,他的目的就是为了减少数据库的查询次数,来提升系统性能,MyBatis本地缓存一共分成两类,一级缓存SqlSession级别,默认开启不能关闭,二级缓存Mapper级别,默认关闭,可以在XML配置中手动开启useCatche=true;
1)在mapper.xml添加catche标签
2)在需要使用查询数据的select标签上添加useCache等于true
也就是说多个用户,也就是多个sqlSession中只要有一个sqlSession拿到了缓存,就会把缓存存放到二级缓存中,那么以后其他的sqlSession就可以直接从二级缓存中来获取到数据
有了二级缓存,先查询二级缓存,再来查询一级缓存,最后再来查询数据库
十一)为什么MyBatis不默认开启二级缓存?
1)内存占用问题:开启二级缓存以后,缓存的数据可能占用一定的内存空间,如果没有合适的策略来管理缓存,那么很有可能造成内存占用过多的问题
2)并发性问题:在多线程环境下,开启二级缓存可能会引起并发性问题,如果多个线程或者是用户同时更新了数据,而没有及时的更新和刷新缓存,可能会造成内存占用过多的问题
3)复杂性和配置问题:二级缓存的配置需要考虑很多问题,包括缓存的刷新策略,缓存的清理策略,这就增加了配置的复杂性和可能引入配置错误的风险
十二)MyBatis有哪些缓存清除策略?
加上标签以后
1)映射语句文件中的所有的select查询操作都会被缓存
2)映射语句文件中的所有insert,delete和update会刷新缓存\
3)缓存会默认使用最近最少使用算法LRU算法来清除不需要的缓存
4)缓存会不定时进行刷新,没有刷新间隔,缓存默认会保存1024个引用
这个更高级的配置了一个FIFO缓存,每隔60S刷新,最多只能存储结果对象的或者是列表的512个引用,并且返回的对象默认是只读的,因此针对于他们进行修改可能在不同线程的调用者产生冲突;
1)LRU:最近最少使用算法,移除最长时间不使用的对象
2)FIFO:先进先出,按照对象进入缓存的顺序来清除他们
3)SOFT:软引用
4)WEAK:虚引用


十三)MyBatis中使用到了那些设计模式?
1)单例模式:异常的输出类ErrorContext,错误的上下文对象,用于打印线程执行的错误信息
2)工厂模式:工厂模式在MyBatis的典型设计模式是SqlSession,可以通过该接口来执行SQL命令,SqlSessionFactory是用来产生sqlSession对象的;
3)装饰器模式:
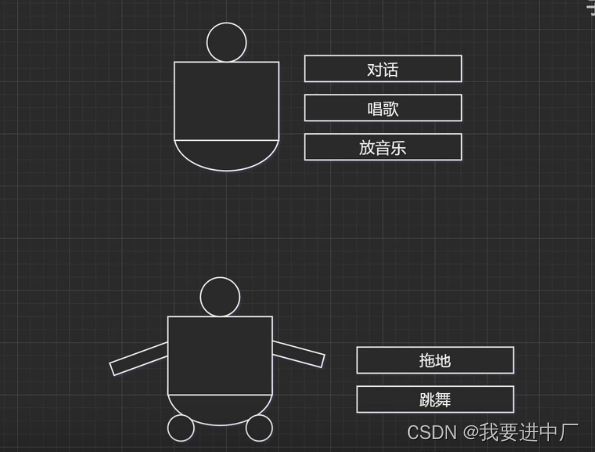
比如说我现在买了一个机器人,他有三个功能对话,唱歌,放音乐,但是有一天我希望这个机器人能够扫地,跳舞,打游戏,希望它有更多的功能,我于是开始打电话给厂商,这个厂商就直接回答说,现在这个机器人设计的时候就只有这三个功能,当然可以扩展新的功能,这个厂商承诺开始研制一个新的产品,他说会在第一代的产品中进行扩展,最终厂家针对于第一代产品的升级修改最终研制出了第二代产品,就好像下面这样他拥有了两条胳膊两条腿,他就可以跳舞和打游戏了,最终厂家邮寄了一个给我们,最后厂家开始销售第二代产品,这个厂家的所有客户拿到了新的产品以后,他就有了拖地和跳舞的功能;
但是现在李四是一个手工狂人,他觉得根本没有必要等待第二代产品,他就可以对第一代产品进行升级改造
这个时候张三只是在原来的机器人上面加了一个箱子,然后自己加上胳膊和大腿,自己就实现了跳舞和扫地的功能,她是自己扩展原有的功能,而不是需要等待厂家重新研发设计,他就可以瞬间将这个机器人进行改造,总而言之上面这两种方式可以实现给一个类或者是对象添加新的功能,第一种方式称之为是继承模式,继承机制就是在一个现有类的基础上,在子类进行扩展功能,第二种方式称之为是关联机制,把一个对象嵌入到另一个对象中,相当于是给它套一个壳子,来扩展功能,那么这个壳子就是装饰器,这种方式就称之为是装饰器模式

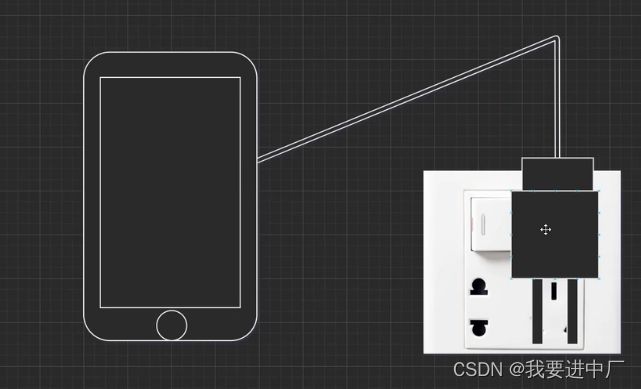
4)适配器模式:
电源适配器:将交流电变成直流电,中国的电源用的是交流电,而手机的使用的电流是直流电,那么需要使用适配器来整流,滤波和稳压转化成所需要的直流电,从而来给手机进行充电,就是手机本来是没有办法使用交流电的,那么就通过电源适配器,也就是手机的插头,通过充电线直接连到手机上,那么电源适配器就是一个桥梁,将两个不兼容的东西兼容到一起,就是将一个类的接口变成另一个客户端所期望的一种接口,从而使得原本接口不匹配的而无法工作在一起的两个类进行相互工作
Spring里面的适配器模式用在DispatcherServlet前端控制器里面有一个doDispatcher方法,在调度方法里面会根据用户输入的url地址来进行匹配相应的Handler方法,方法是被HandlerAdpter控制适配器来执行的,MyBatis中的适配器的是logging;