Hadoop集群搭建(超级详细)
感谢评论区大佬们指出文章中的一些错误,已经进行修改。如果还存在其他错误,希望大佬们指出!
需要的安装包:jdk-8u162-linux-x64.tar.gz( 提取码:6k1i )、hadoop-3.1.3.tar.gz( 提取码:07p6 )
1 集群规划
安装VMware,使用三台Ubuntu18.04虚拟机进行集群搭建,下面是每台虚拟机的规划:
| 主机名 | IP | 用户 | HDFS | YARN |
|---|---|---|---|---|
| hadoopMaster | 待定 | rmc0924 | NameNode、DataNode | NodeManager、ResourceManager |
| hadoopSlave0 | 待定 | rmc0924 | DataNode、SecondaryNameNode | NodeManager |
| hadoopSlave1 | 待定 | rmc0924 | DataNode | NodeManager |
上面表格备用,还需要确定每台虚拟机的IP地址
2 网络配置
首先在VMware中新建一台4G内存(后期会进行修改),20G硬盘空间的Ubuntu虚拟机。新建完成后进行下面操作。
2.1 修改主机名
sudo vim /etc/hostname
其中的vim文本编辑器需要自己安装,具体的安装步骤也很简单,大家伙可以去看别人的博客安装一下。执行上面的命令打开“/etc/hostname”这个文件,将其中内容删除,并修改为“hadoopMaster”,保存退出vim编辑器,重启Linux即可看到主机名发生变化。下面是修改前的主机名:
下面是修改后的主机名:
2.2 设置虚拟机IP地址
- 查看VMware虚拟机的虚拟网络编辑器

- 点击VMnet8网络,点击NAT设置

记录上面图中子网IP、子网掩码、网关三个属性,这些在后面的步骤有用,不同的电脑会有不同。
- 获取Ubuntu虚拟机的网卡编号
ifconfig
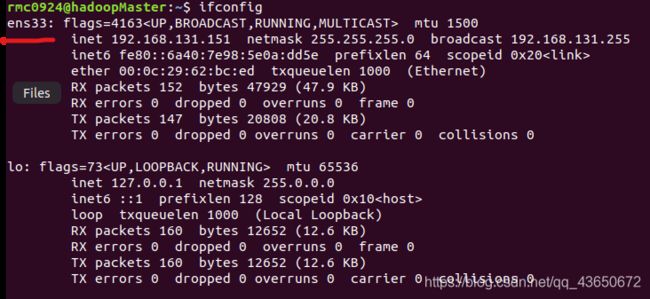
- 设置静态网络
sudo vim /etc/network/interfaces
在原有的内容上添加
auto ens33 # 网卡编号,我这里是ens33
iface ens33 inet static # 设置为静态IP
address 192.168.131.151 # 该机器的IP,根据我们刚才获取到的VMware的子网IP进行选取
netmask 255.255.255.0 # 子网掩码,刚才获取VMware的子网掩码
gateway 192.168.131.2 # 网关,也是刚才获取的网关
dns-nameserver 192.168.131.2 # DNS,和网关一样即可
上面的内容根据各自的电脑进行设置,一定要和VMware中的子网IP、子网掩码、网关保持一致,不然会上不了网。保存退出vim编辑器,重启Ubuntu即可生效。
- 主机IP映射
sudo vim /etc/hosts
打开hosts文件,新增三条IP与主机的映射关系:
192.168.131.151 hadoopMaster
192.168.131.152 hadoopSlave0
192.168.131.153 hadoopSlave1
修改结果如下图所示:

一般情况下,hosts文件中只有一个127.0.0.1,其对应的主机名为localhost,如果存在多余的127.0.0.1,应删除,同时127.0.0.1不能与hadoopMaster这样的主机名进行映射关系。修改后重启Ubuntu。
2.3 关闭防火墙
使用下面命令查看防火墙状态,inactive状态是防火墙关闭状态 active是开启状态。
sudo ufw status
使用下面命令关闭防火墙:
sudo ufw disable
3 安装SSH服务端
sudo apt-get install openssh-server
安装后,使用下面命令登录本机:
ssh localhost
SSH首次登录会有提示,输入yes即可,然后按照提示输入本机密码即可。但是这样每次登录都要输入密码,现在设置SSH无密码登录。首先退出SSH,利用ssh-keygen生成密钥,并将密钥加入到授权中。
exit # 退出ssh localhost
cd ~/.ssh/
ssh-keygen -t rsa # 会有提示,都按回车就行
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
现在再使用"ssh localhost",就可以不用输入密码登录ssh

4 安装Java环境
Hadoop3.1.3需要JDK版本在1.8及以上,jdk-8u162-linux-x64.tar.gz在文首给出,可以进行下载。将文件放在一个目录中后,打开一个终端,执行下面命令。
cd /usr/lib
sudo mkdir jvm # 创建目录来存放JDK文件
# 进入jdk-8u162-linux-x64.tar.gz所在的文件夹
sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm
上面将JDK文件解压之后,进入/usr/lib/jvm目录下会有个jdk1.8.0_162文件
下面开始设置环境变量
sudo vim ~/.bashrc
在打开的文件首部添加下面内容
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
保存退出vim编辑器,执行下面命令让.bashrc文件的配置生效:
source ~/.bashrc
接下来使用下面命令查看是否安装成功:
java -version
如果显示java的版本信息,则表示安装成功:

5 安装Hadoop3.1.3
hadoop-3.1.3.tar.gz文件在文首已经给出,将其下载并放到相应的位置上,使用下面命令安装:
sudo tar -zxf ./hadoop-3.1.3.tar.gz -C /usr/local # 解压到/usr/local中
sudo mv ./hadoop-3.1.3/ ./hadoop # 将文件名改为hadoop
sudo chown -R rmc0924 ./hadoop # 修改权限,当前是什么用户登录,就给他赋予用户的权限
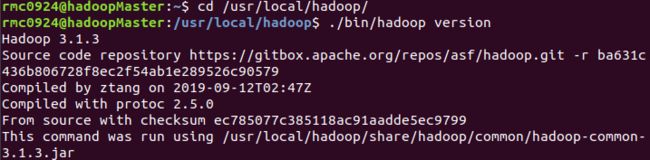
解压后使用下面命令看是否安装成功,安装成功会显示Hadoop的版本信息。
cd /usr/local/hadoop
./bin/hadoop verison
6 克隆虚拟机
经过上面步骤,名称为hadoopMaster的Ubuntu已经配置完成,现在退出该虚拟机。将该虚拟机克隆出另外两台虚拟机,分别命名为hadoopSlave0和hadoopSlave1。

在后面的提示框中依次选择“虚拟机中的当前状态”、“创建完整克隆”、对克隆的虚拟机命名、选择位置,等待克隆完成。最后的虚拟机如下所示:
将hadoopSlave0和hadoopSlave1两台虚拟机按照2.1和2.2中步骤,修改主机名以及各自的静态IP,备用。最后我们可以把最初的那张表补全:
| 主机名 | IP | 用户 | HDFS | YARN |
|---|---|---|---|---|
| hadoopMaster | 192.168.131.151 | rmc0924 | NameNode、DataNode | NodeManager、ResourceManager |
| hadoopSlave0 | 192.168.131.152 | rmc0924 | DataNode、SecondaryNameNode | NodeManager |
| hadoopSlave1 | 192.168.131.153 | rmc0924 | DataNode | NodeManager |
7 安装SecureCRT
由于使用一台电脑来搭建集群,电脑的内存就8G,带不动三台带有图形化界面的虚拟机同时运行,所以使用SecureCRT进行远程连接。SecureCRT安装教程在这位大佬的博客中有详细的教程,大家伙自己过去看就好了,我就不再赘述。
8 集群搭建
好了,前面说了那么多都是铺垫,现在正式搭建Hadoop集群。首先我们还是需要打开VMware中的三台虚拟机,但是打开之前,我们要把它们的内存进行修改,由原先的4G改为1.5G就行了。硬件原因,不在这三台的图形化界面上进行操作,而是使用SecureCRT远程连接,只在终端上进行操作。将三台虚拟机的内存大小改为1.5G后,就可以将三台机子打开。仅仅打开就行,登录界面出现就够了,不需要登录进去。
这样开了三台,内存还都是1.5G的,我的内存就干到了85%,所以不用在图形化界面上进行操作。使用SecureCRT就可以直接登录三台机子。

三台机子之间互相ping,看是否能ping通。

- SSH无密码登录节点
必须要让hadoopMaster节点可以SSH无密码登录到各个hadoopSlave节点上。首先生成hadoopMaster节点公钥,如果之前已经生成,必须删除,重新生成一次。在hadoopMaster上进行下面操作:
cd ~/.ssh
rm ./id_rsa* # 删除之前生成的公钥
ssh-keygen -t rsa # 遇到信息,一直回车就行
再让hadoopMaster节点能够无密码SSH登录本机,在hadoopMaster节点上执行下面命令:
cat ./id_rsa.pub >> ./authorized_keys
使用下面命令进行测试:
ssh hadoopMaster
接下来将hadoopMaster上的公钥传给各个hadoopSlave节点:
scp ~/.ssh/id_rsa.pub hadoopSlave0:/home/rmc0924
其中scp是secure copy的简写,在Linux中用于远程拷贝。执行scp时会要求输入hadoopSlave1用户的密码,输入完成后会显示传输完毕:

接着在hadoopSlave0节点上,将接收到的公钥加入授权:
mkdir ~/.ssh # 如果不存在该文件夹,先创建
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
rm ~/id_rsa.pub # 加完就删除
在hadoopSlave1节点中也执行上的命令。执行完了之后,在hadoopMaster节点上就可以无密码登录代各个hadoopSlave节点,在hadoopMaster节点上执行下面命令:
ssh hadoopSlave0

输入exit即可退出。
- 配置集群环境
配置集群模式时,需要修改“/usr/local/hadoop/etc/hadoop”目录下的配置文件,包括workers、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml。
A. 修改workers文件
vim workers
该文件内容可以指定某几个节点作为数据节点,默认为localhost,我们将其删除并修改为hadoopSlave0和hadoopSlave1.当然也可以将hadoopMaster加进去,让hadoopMaster节点既做名称节点,也做数据节点,本文将hadoopMaster一起加进去作为数据节点。
hadoopMaster
hadoopSlave0
hadoopSlave1
B.修改core-site.xml文件
vim core-site.xml
fs.defaultFS:指定namenode的hdfs协议的文件系统通信地址,可以指定一个主机+端口
hadoop.tmp.dir:hadoop集群在工作时存储的一些临时文件存放的目录
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://hadoopMaster:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>file:/usr/local/hadoop/tmpvalue>
property>
configuration>
C.修改hdfs-site.xml文件
vim hdfs-site.xml
dfs.namenode.name.dir:namenode数据的存放位置,元数据存放位置
dfs.datanode.data.dir:datanode数据的存放位置,block块存放的位置
dfs.repliction:hdfs的副本数设置,默认为3
dfs.secondary.http.address:secondarynamenode运行节点的信息,应该和namenode存放在不同节点
<configuration>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>hadoopSlave0:50090value>
property>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/usr/local/hadoop/tmp/dfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/usr/local/hadoop/tmp/dfs/datavalue>
property>
configuration>
D.修改mapred-site.xml文件
vim mapred-site.xml
mapreduce.framework.name:指定mapreduce框架为yarn方式
mapreduce.jobhistory.address:指定历史服务器的地址和端口
mapreduce.jobhistory.webapp.address:查看历史服务器已经运行完的Mapreduce作业记录的web地址,需要启动该服务才行
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>hadoopMaster:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>hadoopMaster:19888value>
property>
<property>
<name>yarn.app.mapreduce.am.envname>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoopvalue>
property>
<property>
<name>mapreduce.map.envname>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoopvalue>
property>
<property>
<name>mapreduce.reduce.envname>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoopvalue>
property>
configuration>
E.修改yarn-site.xml文件
vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>hadoopMastervalue>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>
- 分发文件
修改完上面五个文件后,将hadoopMaster节点上的hadoop文件复制到各个结点上。在hadoopMaster节点上执行下面命令:
cd /usr/local
sudo rm -r ./hadoop/tmp # 删除 Hadoop 临时文件
sudo rm -r ./hadoop/logs/* # 删除日志文件
tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先压缩再复制
cd ~
scp ./hadoop.master.tar.gz hadoopSlave0:/home/hadoop

在其他hadoopSlave节点将接收的压缩文件解压出来,并授予权限,命令如下:
sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在)
sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
sudo chown -R rmc0924 /usr/local/hadoop
- Hadoop初始化
HDFS初始化只能在主节点上进行
cd /usr/local/hadoop
./bin/hdfs namenode -format

在初始化过程中,只要看到上面红框里面的信息,有个successfully formatted说明初始化成功。
- Hadoop集群启动
在hadoopMaster节点上执行下面命令:
cd /usr/local/hadoop
./sbin/start-dfs.sh
./sbin/start-yarn.sh
./sbin/mr-jobhistory-daemon.sh start historyserver
通过jps可以查看各个节点所启动的进程,如果按照本文的设置,正确启动的话,在hadoopMaster节点上会看到以下进程:

hadoopSlave0节点的进程:

hadoopSlave1节点的进程:

另外还可以在hadoopMaster节点上使用下面命令查看数据节点是否正常启动。本文中使用三个节点作为数据节点,所以会有以下的信息:


当然我们也可以在浏览器中查看:
HDFS:http://192.168.131.151:9870/
YARN:http://192.168.131.151:8088/cluster
HDFS界面
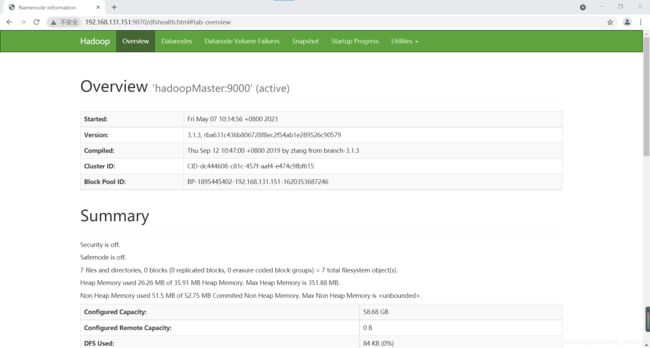
点击DataNodes可以查看三个节点:

YARN界面

点击左侧导航栏Nodes可以查看结点

至此,Hadoop集群搭建完成,撒花!!!!!
9 执行分布式实例
在HDFS上创建一个文件夹/test/input
cd /usr/local/hadoop
./bin/hdfs dfs -mkdir -p /test/input
查看创建的文件夹
./bin/hdfs dfs -ls /

创建一个word.txt测试文件
vim word.txt
输入以下文本(我从《傲慢与偏见》里面抽出来两段话)
Be not alarmed, madam, on receiving this letter, by the apprehension of its containing any repetition of those
sentiments or renewal of those offers which were last night so disgusting to you. I write without any intention of
paining you, or humbling myself, by dwelling on wishes which, for the happiness of both, cannot be too soon
forgotten; and the effort which the formation and the perusal of this letter must occasion, should have been spared,
had not my character required it to be written and read. You must, therefore, pardon the freedom with which I
demand your attention; your feelings, I know, will bestow it unwillingly, but I demand it of your justice.
My objections to the marriage were not merely those which I last night acknowledged to have the utmost required
force of passion to put aside, in my own case; the want of connection could not be so great an evil to my friend as to
me. But there were other causes of repugnance; causes which, though still existing, and existing to an equal degree
in both instances, I had myself endeavored to forget, because they were not immediately before me. These causes
must be stated, though briefly. The situation of your mother's family, though objectionable, was nothing in
comparison to that total want of propriety so frequently, so almost uniformly betrayed by herself, by your three
younger sisters, and occasionally even by your father. Pardon me. It pains me to offend you. But amidst your
concern for the defects of your nearest relations, and your displeasure at this representation of them, let it give you
consolation to consider that, to have conducted yourselves so as to avoid any share of the like censure, is praise no
less generally bestowed on you and your eldersister, than it is honorable to the sense and disposition of both. I will
only say farther that from what passed that evening, my opinion of all parties was confirmed, and every inducement
heightened which could have led me before, to preserve my friend from what I esteemed a most unhappy
connection. He left Netherfield for London, on the day following, as you, I am certain, remember, with the design of
soon returning.
将word.txt上传到HDFS的/test/input文件夹中
./bin/hdfs dfs -put ~/word.txt /test/input
运行一个mapreduce的例子程序:wordcount
./bin/hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /test/input /test/output
执行成功后如下所示,输出相关信息:

在YARN Web界面也可以查看:
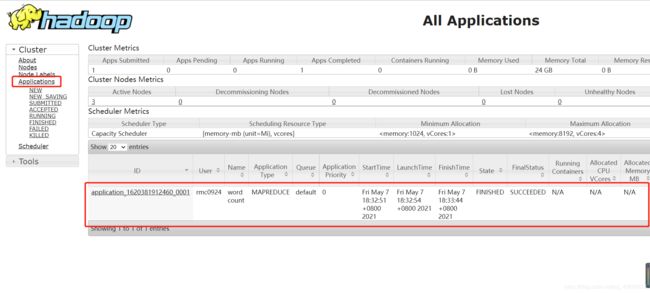
查看运行结果:
./bin/hdfs dfs -cat /test/output/*
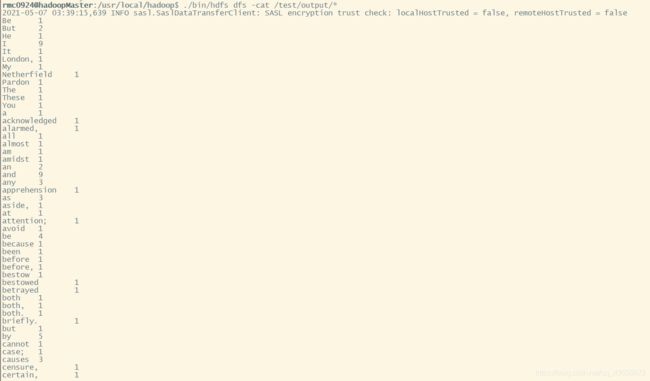
由于只是进行词频统计,我没有对测试数据进行其他处理,所以有些单词会带逗号,这些都是小事,重点是,Hadoop集群搭建起来了,还能跑,这就舒服了,嘻嘻嘻嘻嘻嘻。
10 关闭集群
接下来就是关闭集群,输入以下命令:
cd /usr/local/hadoop
./sbin/stop-yarn.sh
./sbin/stop-dfs.sh
./sbin/mr-jobhistory-daemon.sh stop historyserver