Pandas数据结构分析
一、pandas的基本数据结构
1、pandas中有两个主要的数据结构,分别是:Series和DataFrame。
2、Series:它是一个类似一维数组的对象,它能够保存任何类型的数据,主要由一组数据(各种Numpy数据类型)和与之相关的数据标签(索引)两部分构成。仅由一组数据也可以产生简单的Series对象。注意:Series的索引位于左边,数据位于右边,且索引值可以重复。

3、DataFrame:是一个类似于二维数组或表格(如excel)的对象,包含一组有序的列,它每列的数据可以是不同的数据类型(数值、字符串、布尔型等)。注意:DataFrame的索引不仅有行索引,还有列索引,数据可以有多列,因此可以看做是由Series组成的字典。
二、Series
1、创建Series
(1)创建Series类对象

(2) 创建Series类对象,并指定索引

(3)通过字典的方式创建:
通过字典创建 Series 时,字典中的 key 组成 Series 中的索引,字典中的 values 组成 Series 中的 values。

2、Series的属性
为了能方便地操作Series对象中的索引和数据,所以该对象提供了两个属性index和values分别进行获取。
(1)获取s2的索引: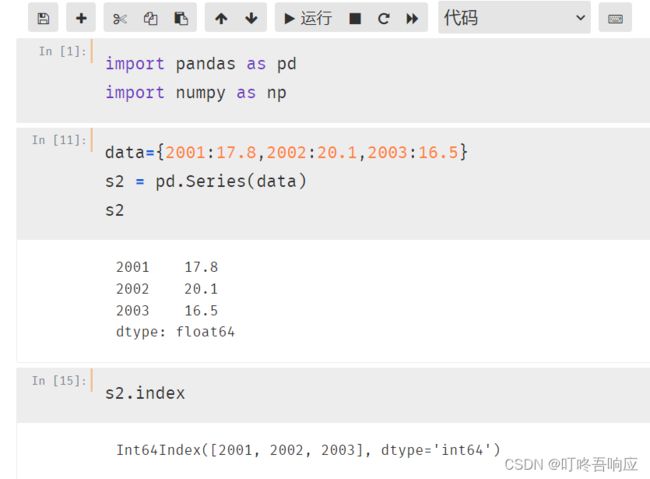
(2)获取s2的数据
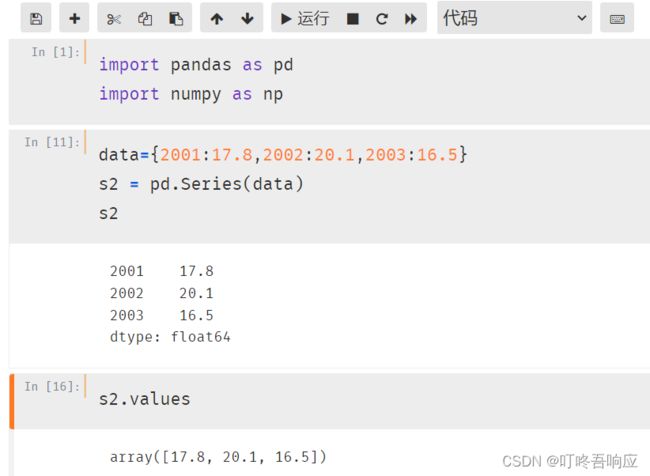
(3)直接使用位置索引来获取数据
Series对象的属性有:dtype, index, values, name
Series.index有属性:name
三、DataFrame
1、DataFrame的创建
(1)通过二维数组创建
数据帧(DataFrame)是二维数据结构,即数据以行和列的表格方式排列。
数据帧(DataFrame)的功能特点:潜在的列是不同的类型,大小可变,可以对行和列执行算术运算。
pandas 中的 DataFrame 可以使用以下构造函数创建:
pandas.DataFrame(data, index, columns, dtype, copy)
| 编号 | 参数 | 简介 |
| 1 | data | 数据采取各种形式,如:ndarray,series,map,lists,dict,constant和另一个 DataFrame。 |
| 2 | index | 对于行标签,要用于结果帧的索引是可选缺省值np.arrange(n),如果没有传递索引值。 |
| 3 | columns | 对于列标签,可选的默认语法是--np.arrange(n)。这只有在没有索引传递的情况下才是这样。 |
| 4 | dtype | 每列的数据类型。 |
| 5 | copy | 如果默认值为False,则此命令(或任何它)用于复制数据。 |

2、DataFrame的数据获取
(1)可以直接通过列索引获取指定列的数据。
a、列选择

b、列添加
c、列修改
d、列删除
直接采用drop函数,设置axis=1,参数axis为1表示在行上面搜索对象并删除
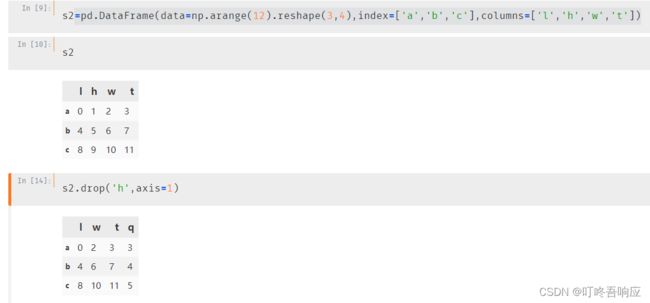
采用del的方法

(2)如果需要获取指定行的的数据的话,需要通过 ix 方法来获取对应行索引的行数据。
a、行选择
b、行添加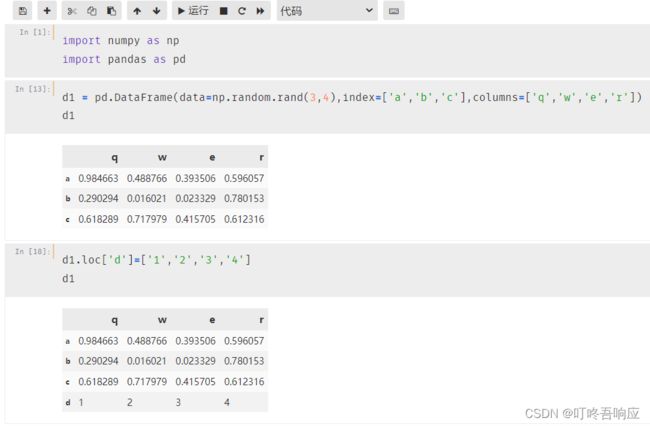
c、行修改

d、行删除
四、索引对象
1、 Pandas中的索引都是Index类对象,又称为索引对象,该对象是不可以进行修改的,以保障数据的安全。Pandas还提供了很多Index的子类,常见的有如下几种:
(1)Int64Index:针对整数的特殊Index对象。
(2)MultiIndex:层次化索引,表示单个轴上的多层索引。
(3)DatetimeIndex:存储纳秒寄时间戳。
2、不管是 Series 还是 DataFrame 对象,都有索引对象。
3、索引对象负责管理轴标签和其他元数据(eg:轴名称等等)。
4、通过索引可以从 Series、DataFrame 中获取值或者对某个索引值进行重新赋值。
5、Series 或者 DataFrame 的自动对齐功能是通过索引实现的。