4 Tensorflow图像识别模型——数据预处理
上一篇:3 tensorflow构建模型详解-CSDN博客
本篇开始介绍识别猫狗图片的模型,内容较多,会分为多个章节介绍。模型构建还是和之前一样的流程:
- 数据集准备
- 数据预处理
- 创建模型
- 设置损失函数和优化器
- 训练模型
本篇先介绍数据集准备&预处理。
1、了解监督学习
开始前,需要先了解什么是监督学习。机器学习基于学习方式的分类,可分为:
- 监督学习
- 无监督学习
- 强化学习
百度百科对监督学习的定义是使用标记数据集来训练算法,以便对数据进行分类或准确预测结果。
我们要构建的图片识别模型就属于监督学习的方式,模型的输入是“特征-标签”对,特征就是输入的图片,标签是标记该图片的预期结果(比如该图片是猫还是狗)。
2、训练数据集介绍
网上有很多公开的数据集可以用来学习,初学者不用花很多的时间在数据准备上面。下面是猫狗的数据集下载地址:
https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip
下载后,可以将解压的文件夹放在自己项目的根目录,方便后面读取。
(1)数据集的目录结构

数据集下面有两个子目录,一个训练集(train),一个是验证集(validation),训练集和验证集下面都有猫狗的文件夹,里面是收集好的猫、狗照片。
划分train和validation两个子集,主要是用于训练和评估模型,validation的数据可以看看模型在没有训练过的图片效果如何。
(2)查看数据集数量
本人把数据集放在了当前pycharm项目的根目录,读者可以根据自己实际放的位置替换路径。
import os
# 获取训练集和验证集目录
train_dir = os.path.join('cats_and_dogs_filtered/train')
validation_dir = os.path.join('cats_and_dogs_filtered/validation')
# 获取训练集猫、狗的目录
train_cats_dir = os.path.join(train_dir, 'cats')
train_dogs_dir = os.path.join(train_dir, 'dogs')
# 获取验证集猫、狗的目录
validation_cats_dir = os.path.join(validation_dir, 'cats')
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
# 查看训练集猫狗的图片数量
print('训练集猫的图片数量:')
print(len(os.listdir(train_cats_dir)))
print('训练集狗的图片数量:')
print(len(os.listdir(train_dogs_dir)))
# 查看验证集猫狗的图片数量
print('验证集猫的图片数量:')
print(len(os.listdir(validation_cats_dir)))
print('验证集狗的图片数量:')
print(len(os.listdir(validation_dogs_dir)))运行结果:
训练集猫的图片数量:
1000
训练集狗的图片数量:
1000
验证集猫的图片数量:
500
验证集狗的图片数量:
500
从运行结果可以了解到训练集一共2000张图片,验证集有1000张。
(3)了解RGB图像
根据百度百科对RGB的定义,RGB是工业界的一种颜色标准,是通过对红(R)、绿(G)、蓝(B)三个颜色通道的变化以及它们相互之间的叠加来得到各式各样的颜色的,RGB即是代表红、绿、蓝三个通道的颜色,这个标准几乎包括了人类视力所能感知的所有颜色,是运用最广的颜色系统之一。
可以用下面的草图辅助理解,比如一张3 X 3 大小的图片,可以解析成由红绿蓝三色通道叠加成的三维数组(图片信息数值仅用于辅助理解,不是该照片的真实值)
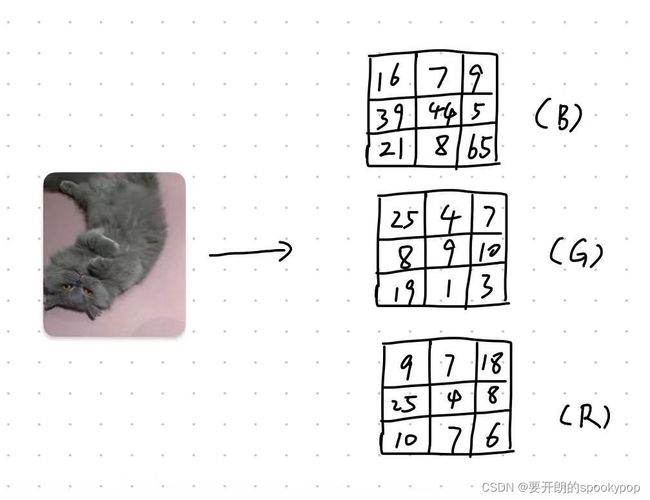
大多数彩色图像可以分为RGB三色通道,我们可以选取训练集的其中一张图片看看:
import os
import cv2
# 获取训练集和验证集目录
train_dir = os.path.join('cats_and_dogs_filtered/train')
validation_dir = os.path.join('cats_and_dogs_filtered/validation')
# 获取训练集猫、狗的目录
train_cats_dir = os.path.join(train_dir, 'cats')
train_dogs_dir = os.path.join(train_dir, 'dogs')
# 获取验证集猫、狗的目录
validation_cats_dir = os.path.join(validation_dir, 'cats')
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
# 获取训练集-猫文件的所有文件名称
train_cats_name = os.listdir(train_cats_dir)
# 获取其中一张图片的路径
picture_1 = os.path.join(train_cats_dir, train_cats_name[0])
# 打印该图片名称
print('图片名称:'+train_cats_name[0])
# 读取图片的信息值
picture_1 = cv2.imread(picture_1)
# 打印该图片的形状
print(picture_1.shape)
运行结果:
图片名称:cat.952.jpg
(375, 499, 3)
可以看到图片cat.952.jpg的尺寸大小是375 X 499,深度是3,即该图片解析为RGB三色通道叠加的三维数组。
再选取另外一张,只需更改下面两句代码:
# 获取其中一张图片的路径
picture_1 = os.path.join(train_cats_dir, train_cats_name[0])
# 打印该图片名称
print('图片名称:'+train_cats_name[0])运行结果:
图片名称:cat.946.jpg
(374, 500, 3)
可以看到两张图片的尺寸不一样,神经网络输入需要相同的尺寸大小,所以这些数据集不能直接拿来训练,还需要做数据预处理。
(4)数据预处理
主要有两部分内容:
统一图片大小、按比例缩放
可以先看单张图片的效果,图片尺寸调整为150*150,按1/255比例缩放:
import os
import cv2
# 获取训练集和验证集目录
train_dir = os.path.join('cats_and_dogs_filtered/train')
validation_dir = os.path.join('cats_and_dogs_filtered/validation')
# 获取训练集猫、狗的目录
train_cats_dir = os.path.join(train_dir, 'cats')
train_dogs_dir = os.path.join(train_dir, 'dogs')
# 获取验证集猫、狗的目录
validation_cats_dir = os.path.join(validation_dir, 'cats')
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
# 获取训练集-猫文件的所有文件名称
train_cats_name = os.listdir(train_cats_dir)
# 获取其中一张图片的路径
picture_1 = os.path.join(train_cats_dir, train_cats_name[0])
# 打印该图片名称
print('图片名称:'+train_cats_name[0])
# 读取图片的信息值
picture_1 = cv2.imread(picture_1)
# 打印该图片的信息值
print(picture_1)
picture_2 = cv2.resize(picture_1, (150, 150))
print('调整后的图片形状为:')
print(picture_2.shape)
# 除以255缩放图片
picture_2 = picture_1 / 255
print('缩放后的图片信息值矩阵:')
print(picture_2)运行结果:
图片名称:cat.946.jpg
[[[158 157 143]
[128 126 115]
[103 97 92]
...
[ 71 70 66]
[ 71 70 66]
[ 71 70 66]]
[[158 157 143]
[128 126 115]
[103 97 92]
...
[ 74 73 69]
[ 74 73 69]
[ 74 73 69]]
[[157 156 142]
[128 126 115]
[103 97 92]
...
[ 77 76 72]
[ 77 76 72]
[ 77 76 72]]
...
[[128 123 125]
[126 121 123]
[124 119 121]
...
[ 40 61 83]
[ 38 59 81]
[ 37 58 80]]
[[135 132 134]
[132 129 131]
[130 127 129]
...
[ 39 60 82]
[ 38 59 81]
[ 37 58 80]]
[[140 137 139]
[138 135 137]
[135 132 134]
...
[ 39 60 82]
[ 38 59 81]
[ 37 58 80]]]
调整后的图片形状为:
(150, 150, 3)
缩放后的图片信息值矩阵:
[[[0.61960784 0.61568627 0.56078431]
[0.50196078 0.49411765 0.45098039]
[0.40392157 0.38039216 0.36078431]
...
[0.27843137 0.2745098 0.25882353]
[0.27843137 0.2745098 0.25882353]
[0.27843137 0.2745098 0.25882353]]
[[0.61960784 0.61568627 0.56078431]
[0.50196078 0.49411765 0.45098039]
[0.40392157 0.38039216 0.36078431]
...
[0.29019608 0.28627451 0.27058824]
[0.29019608 0.28627451 0.27058824]
[0.29019608 0.28627451 0.27058824]]
[[0.61568627 0.61176471 0.55686275]
[0.50196078 0.49411765 0.45098039]
[0.40392157 0.38039216 0.36078431]
...
[0.30196078 0.29803922 0.28235294]
[0.30196078 0.29803922 0.28235294]
[0.30196078 0.29803922 0.28235294]]
...
[[0.50196078 0.48235294 0.49019608]
[0.49411765 0.4745098 0.48235294]
[0.48627451 0.46666667 0.4745098 ]
...
[0.15686275 0.23921569 0.3254902 ]
[0.14901961 0.23137255 0.31764706]
[0.14509804 0.22745098 0.31372549]]
[[0.52941176 0.51764706 0.5254902 ]
[0.51764706 0.50588235 0.51372549]
[0.50980392 0.49803922 0.50588235]
...
[0.15294118 0.23529412 0.32156863]
[0.14901961 0.23137255 0.31764706]
[0.14509804 0.22745098 0.31372549]]
[[0.54901961 0.5372549 0.54509804]
[0.54117647 0.52941176 0.5372549 ]
[0.52941176 0.51764706 0.5254902 ]
...
[0.15294118 0.23529412 0.32156863]
[0.14901961 0.23137255 0.31764706]
[0.14509804 0.22745098 0.31372549]]]
下面是数据集预处理的代码:
# 模型参数设置
BATCH_SIZE = 100
# 图片尺寸统一为150*150
IMG_SHAPE = 150
# 处理图像尺寸
train_image_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1. / 255)
validation_image_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1. / 255)
train_data_gen = train_image_generator.flow_from_directory(directory=train_dir,
batch_size=BATCH_SIZE,
target_size=(IMG_SHAPE, IMG_SHAPE),
class_mode='binary')
val_data_gen = validation_image_generator.flow_from_directory(directory=validation_dir,
batch_size=BATCH_SIZE,
target_size=(IMG_SHAPE, IMG_SHAPE),
class_mode='binary')- target_size=(IMG_SHAPE, IMG_SHAPE), IMG_SHAPE设为150,即读取数据时统一调整尺寸为150*150
- tf.keras.preprocessing.image.ImageDataGenerator(rescale=1. / 255) 是按1/255比例缩放。因为图片信息的数值矩阵类型为unit8型,在0~255范围内,缩放后将像素值标准化为0-1之间
数据准备好就是成功的一半,后续介绍构建图像识别模型。