上帝视角学JAVA- 基础15-集合02【2021-08-30】
1、Map 接口
map即映射,存储一一对应关系。key-value形式。key必须唯一。value可以相同。
public interface Map {
int size();
boolean isEmpty();
boolean containsKey(Object key);
boolean containsValue(Object value);
V get(Object key);
V put(K key, V value);
V remove(Object key);
void putAll(Map m);
void clear();
Set keySet();
Collection values();
Set> entrySet();
interface Entry {
K getKey();
V getValue();
V setValue(V value);
boolean equals(Object o);
int hashCode();
public static , V> Comparator> comparingByKey() {
return (Comparator> & Serializable)
(c1, c2) -> c1.getKey().compareTo(c2.getKey());
}
public static > Comparator> comparingByValue() {
return (Comparator> & Serializable)
(c1, c2) -> c1.getValue().compareTo(c2.getValue());
}
public static Comparator> comparingByKey(Comparator cmp) {
Objects.requireNonNull(cmp);
return (Comparator> & Serializable)
(c1, c2) -> cmp.compare(c1.getKey(), c2.getKey());
}
public static Comparator> comparingByValue(Comparator cmp) {
Objects.requireNonNull(cmp);
return (Comparator> & Serializable)
(c1, c2) -> cmp.compare(c1.getValue(), c2.getValue());
}
}
boolean equals(Object o);
int hashCode();
default V getOrDefault(Object key, V defaultValue) {
V v;
return (((v = get(key)) != null) || containsKey(key))
? v
: defaultValue;
}
default void forEach(BiConsumer action) {
Objects.requireNonNull(action);
for (Map.Entry entry : entrySet()) {
K k;
V v;
try {
k = entry.getKey();
v = entry.getValue();
} catch(IllegalStateException ise) {
// this usually means the entry is no longer in the map.
throw new ConcurrentModificationException(ise);
}
action.accept(k, v);
}
}
default void replaceAll(BiFunction function) {
Objects.requireNonNull(function);
for (Map.Entry entry : entrySet()) {
K k;
V v;
try {
k = entry.getKey();
v = entry.getValue();
} catch(IllegalStateException ise) {
// this usually means the entry is no longer in the map.
throw new ConcurrentModificationException(ise);
}
// ise thrown from function is not a cme.
v = function.apply(k, v);
try {
entry.setValue(v);
} catch(IllegalStateException ise) {
// this usually means the entry is no longer in the map.
throw new ConcurrentModificationException(ise);
}
}
}
default V putIfAbsent(K key, V value) {
V v = get(key);
if (v == null) {
v = put(key, value);
}
return v;
}
default boolean remove(Object key, Object value) {
Object curValue = get(key);
if (!Objects.equals(curValue, value) ||
(curValue == null && !containsKey(key))) {
return false;
}
remove(key);
return true;
}
default boolean replace(K key, V oldValue, V newValue) {
Object curValue = get(key);
if (!Objects.equals(curValue, oldValue) ||
(curValue == null && !containsKey(key))) {
return false;
}
put(key, newValue);
return true;
}
default V replace(K key, V value) {
V curValue;
if (((curValue = get(key)) != null) || containsKey(key)) {
curValue = put(key, value);
}
return curValue;
}
default V computeIfAbsent(K key,
Function mappingFunction) {
Objects.requireNonNull(mappingFunction);
V v;
if ((v = get(key)) == null) {
V newValue;
if ((newValue = mappingFunction.apply(key)) != null) {
put(key, newValue);
return newValue;
}
}
return v;
}
default V computeIfPresent(K key,
BiFunction remappingFunction) {
Objects.requireNonNull(remappingFunction);
V oldValue;
if ((oldValue = get(key)) != null) {
V newValue = remappingFunction.apply(key, oldValue);
if (newValue != null) {
put(key, newValue);
return newValue;
} else {
remove(key);
return null;
}
} else {
return null;
}
}
default V compute(K key,
BiFunction remappingFunction) {
Objects.requireNonNull(remappingFunction);
V oldValue = get(key);
V newValue = remappingFunction.apply(key, oldValue);
if (newValue == null) {
// delete mapping
if (oldValue != null || containsKey(key)) {
// something to remove
remove(key);
return null;
} else {
// nothing to do. Leave things as they were.
return null;
}
} else {
// add or replace old mapping
put(key, newValue);
return newValue;
}
}
default V merge(K key, V value,
BiFunction remappingFunction) {
Objects.requireNonNull(remappingFunction);
Objects.requireNonNull(value);
V oldValue = get(key);
V newValue = (oldValue == null) ? value :
remappingFunction.apply(oldValue, value);
if(newValue == null) {
remove(key);
} else {
put(key, newValue);
}
return newValue;
}
} 以上为Map在JDK8.0的源码。可以看到,里面有内部接口 Entry,还有很多默认方法。默认方法是JDK8 中接口的新特性。接口的实现类没有要求一定实现默认方法。这就解决了接口升级,而实现类又没有实现的问题,因为默认方法不要求一定实现了
Entry 是Map的基本组成单元。就是存储一对键值对的。
Map中的key:无序、不可重复。可用set存储
Map中的value:无序、可重复,可用List存储
一个键值对就是一个Entry实例化对象。Map中的entry是无序的、不可重复的。可用set存储entry
因此,当key是自定义类时,需要重写 equals 和 hashCode方法。
下面介绍Map 常用方法:以HashMap 为例
-
put(K key, V value) 方法 添加键值对、修改已有键的值。
HashMap map = new HashMap<>();
map.put(17, "AA");
map.put(10, "BB");
// 已存在 key 为 17,此时再put相同的key,变成修改value值
map.put(17, "CC");
System.out.println(map);
// {17=CC, 10=BB} -
putAll(Map m) 方法: 将另一个map 的全部键值对添加到调用方。注意:当key相同时,后面的会覆盖前面的value。
HashMap map = new HashMap<>();
map.put(17, "AA");
map.put(10, "BB");
HashMap map1 = new HashMap<>();
map1.put(0, "CC");
map1.put(17,"dd");
map.putAll(map1);
System.out.println(map);
// {0=CC, 17=dd, 10=BB} -
remove(Object key) 按照指定的键 移除键值对,返回被移除的 value,不存在则返回null
remove(Object key, Object value) 按照 键值对进行移除,返回移除成功true或者失败false
HashMap map = new HashMap<>();
map.put(17, "AA");
map.put(10, "BB");
map.put(15, "cc");
// 移除 key = 17 的键值对,返回value
Object remove = map.remove(17);
// 上一步已经移除了,再次移除一个不存在的key,返回null
Object remove1 = map.remove(17);
boolean d = map.remove(10, "dd");
boolean b = map.remove(10, "BB");
System.out.println(map); // {15=cc}
System.out.println(remove); // AA
System.out.println(remove1); // null
System.out.println(d); // false
System.out.println(b); // true -
clear() 清空 map中的 所有键值对。即元素个数为0,但是 底层数组还是在的。
HashMap map = new HashMap<>();
map.put(17, "AA");
map.put(10, "BB");
map.put(15, "cc");
map.clear();
System.out.println(map); // {} -
get(Object key) 获取指定 key的value值 ,如果key不存在,返回null
HashMap map = new HashMap<>();
map.put(17, "AA");
map.put(10, "BB");
map.put(15, "cc");
Object o = map.get(1);
Object o1 = map.get(10);
System.out.println(o); // null
System.out.println(o1); // BB -
containsKey(Object key) 判断某个 key 是否存在,返回Boolean值
HashMap map = new HashMap<>();
map.put(17, "AA");
map.put(10, "BB");
map.put(15, "cc");
boolean b = map.containsKey(10);
System.out.println(b); // true -
containsValue(Object value) 判断某个value 是否存在,返回Boolean值。
HashMap map = new HashMap<>();
map.put(17, "AA");
map.put(18, "AA");
map.put(10, "BB");
map.put(15, "cc");
// 只要存在一个value 与传入的相同,就返回true
boolean aa = map.containsValue("AA");
System.out.println(aa); // true -
size() 获取当前 map的 键值对个数
HashMap map = new HashMap<>();
map.put(17, "AA");
map.put(18, "AA");
map.put(10, "BB");
map.put(15, "cc");
int size = map.size();
System.out.println(size); // 4 -
isEmpty() 判断 map 是否没有键值对
HashMap map = new HashMap<>();
map.put(17, "AA");
map.put(10, "BB");
map.put(15, "cc");
// 实际是看 size是否为 0
boolean empty = map.isEmpty();
System.out.println(empty); // false // isEmpty 源码
public boolean isEmpty() {
return size == 0;
}-
equals(Object o) 判断2个map对象是否相等,实际上是Object中的方法。Map是调用的父类 AbstractMap 中的方法。
下面是源码:
public boolean equals(Object o) {
if (o == this)
return true;
if (!(o instanceof Map))
return false;
Map m = (Map) o;
if (m.size() != size())
return false;
try {
Iterator> i = entrySet().iterator();
while (i.hasNext()) {
Entry e = i.next();
K key = e.getKey();
V value = e.getValue();
if (value == null) {
if (!(m.get(key)==null && m.containsKey(key)))
return false;
} else {
if (!value.equals(m.get(key)))
return false;
}
}
} catch (ClassCastException unused) {
return false;
} catch (NullPointerException unused) {
return false;
}
return true;
} 例子:
HashMap map = new HashMap<>();
map.put(17, "AA");
map.put(10, "BB");
map.put(15, "cc");
HashMap map1 = new HashMap<>();
map1.put(10, "BB");
boolean b = map.equals(map1);
System.out.println(b); // false -
map的遍历
1、map的 key是一个set,set是Collection ,可以使用Collection的遍历方法
2、map的 value 是一个List,也是Collection ,可以使用Collection的遍历方法
3、map在内部维护了一个 键值对 set,即EntrySet,也是一个Collection
随便拿到这3个东西,都可以使用Collection的遍历方法。
HashMap map = new HashMap<>();
map.put(17, "AA");
map.put(10, "BB");
map.put(15, "cc");
// 1、获取 keySet
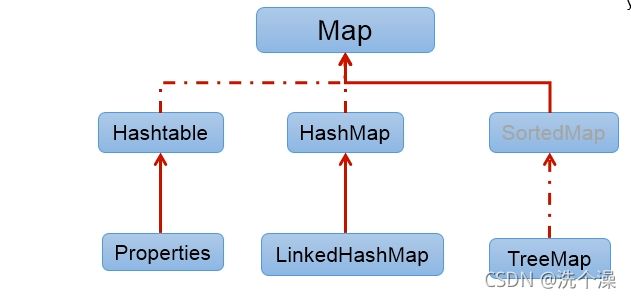
Set 1.1 HashMap 主要实现类
线程不安全的、效率高
底层:数组+链表(JDK7及以前);数组+链表+红黑数(jdk8)
HashMap的源码 去除掉注释还有 1800 行左右。不适合在这里贴出。只讲一些关键的
以JDK8为例:
当我们使用无参构造器实例化 HashMap 对象时:
HashMap map = new HashMap<>(); 调用的构造函数为:
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}// 默认加载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 哈希表的加载因子
final float loadFactor;可以看到,只是设置了一下默认的 哈希表加载系数。
当我们调用 put方法时
map.put(1, "AA");执行的是:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
// 调用 putVal 时,传参之前 会调用 hash()方法计算 key的hash值,作为第一个参数给 putVal 方法
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}以上说明了,真正计算hash值的是 key 而不是 value
transient Node[] table; // Node 类型的table 变量 transient 关键字暂时忽略,它的作用是修饰的变量不可被序列化
// 树型阈值
static final int TREEIFY_THRESHOLD = 8;
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
// 定义了一个 Node 类型的数组 tab
Node[] tab;
// 一个 Node 类型的 p
Node p;
// 2个变量,n和i; 默认初始化是 0
int n, i;
// 当 使用空参构造器实例化对象时,table会默认初始化为null
if ((tab = table) == null || (n = tab.length) == 0)
// 调用 resize 方法 调整 Map容器的容量大小。 resize的源码见下面。
// 执行完 resize 方法,如果是空参初始化方式,tab 就会得到 容量为16的 Node类型数组
n = (tab = resize()).length;
// n = 16, (n-1) & hash 即 -1与 key的hash值按位与 得到一个下标
// n-1 就是Node数组的最大下标,按位与操作只有 都是1,才是1,不管怎么与都不会超过最大下标。
// 实时上,15 & 不超过15的数 是 这个数本身。 超过15的数 也有点意思,看看下面的例子你就明白了。
// 如15&14=14 15&15=15 15&16 = 0 15&17=1 15&18=2 15&19=3 ... 15&30=14 15&31=15 15&32=0 15&33=1
if ((p = tab[i = (n - 1) & hash]) == null)
// 如果这个位置上没有数据,直接放在这个位置上
// 调用 newNode 方法 创建一个 Node 对象,保存到 tab[i]
tab[i] = newNode(hash, key, value, null);
else {
// 如果这个位置上有数据,就需要比较 key的hash值与已经存在的数据都不相同,就还需要添加。以链表存储
// key的hash值与已经存在的数据某一个相同,就还需要调用equals方法比较
// 如果 比较结果不相同,还是要添加,以链表存储;如果比较结果相同,就不会添加新的key-value键值对,而是替换key对应的value值
Node e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
// 使用 树 来存储值
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {
// p位置上所有链表的元素都要比较
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
// 发现 没有相同的,就新建一个Node作为p的next。即新的元素作为原有元素的下一个
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// 当 链表的长度大于等于 TREEIFY_THRESHOLD - 1 = 7时,改为使用红黑树存储
// 替换给定散列的索引处bin中的所有链接节点,除非表太小,在这种情况下改为调整大小。
treeifyBin(tab, hash);
break;
}
// 如果发现 新的元素的key的哈希值和原有的某个节点一致
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
// 当前节点与新元素不一样
p = e;
}
}
if (e != null) {
// 如果这个key已经存在了,就替换原有值
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
// 创建常规(非树)节点
Node newNode(int hash, K key, V value, Node next) {
return new Node<>(hash, key, value, next);
} Node类型源码:
static class Node implements Map.Entry {
// 常量 hash 值
final int hash;
// 常量 key 值
final K key;
// value 值
V value;
// Node 类型的 next
Node next;
// 有参构造函数
Node(int hash, K key, V value, Node next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
// 公共的方法 获取 Node 的属性 key 和 value 的值
public final K getKey() { return key; }
public final V getValue() { return value; }
// 重写了 toString 方法
public final String toString() { return key + "=" + value; }
// 重写了 hashCode 方法
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
// 刚刚的 修改 value 的方法
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
// 重写了 equals 方法
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry e = (Map.Entry)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
} 这个Node类十分简单。
可以看到Node类 是 实现了 Map 接口中的内部 接口 Entry,即Node 是Entry的一个实现类
Node 类里面有4个属性,分别是常量 hash 值,常量 key 以及 value 和Node 类型的 next
这里也说明了 key 值是不可变的,因为是使用final定义的常量。而 value 就是普通的变量。Node 类型的next 是用来记录下一个 键值对的。即指向下一个的指针。
下面是 resize方法的源码:
// 临界值:要调整大小的下一个大小值(容量*负载系数)。 表示当容量达到多少时,需要进行扩容操作
int threshold; // 翻译为:临界值
// 默认初始容量 1 左移 4位,左移1位等于乘以2 左移4位即乘以2的4次方,为16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 16
// 最大容量 2的30次方
static final int MAXIMUM_CAPACITY = 1 << 30;
final Node[] resize() {
// table 就是 旧的 Node[] 数组
Node[] oldTab = table;
// 当空参构造实例化对象 oldTab 就是 null ,那么 oldCap 旧容量就是 0;否则就是原始 旧容量的大小
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// threshold 开始默认初始化为 0,所有oldThr = 0
int oldThr = threshold;
int newCap, newThr = 0;
// 根据 旧容量判断
if (oldCap > 0) {
// 旧容量 比0大,说明不是空参初始化
if (oldCap >= MAXIMUM_CAPACITY) {
// 旧容量比 最大容量要大 临界值变成 2的31次方-1
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 默认扩容为 原来的2倍
newThr = oldThr << 1; // double threshold
}
// 如果 旧容量是 空的,可能有值被清空了,也可能是 无参初始化状态
else if (oldThr > 0)
// 旧容量是 空的,但是 旧临界值 大于0,说明是以前有值,被清空了
newCap = oldThr;
else {
// 旧容量是 0, 旧临界值 也是 0,这是 刚刚初始化状态。 新容量 为默认初始容量为 16
newCap = DEFAULT_INITIAL_CAPACITY;
// 新临界值 = (int) 默认加载系数 * 默认初始容量 = (int) 0.75f * 1 << 4 = 12
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
// 得到了 新临界值 覆盖 threshold
threshold = newThr;
// 创建一个 新容量大小的 Node类型的数组
@SuppressWarnings({"rawtypes","unchecked"})
Node[] newTab = (Node[])new Node[newCap];
// table 就记录这个新的 数组
table = newTab;
// 当 旧的 Node 数组不是空时,就要进行一系列的 拷贝操作
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode)e).split(this, newTab, j, oldCap);
else { // preserve order
Node loHead = null, loTail = null;
Node hiHead = null, hiTail = null;
Node next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
// 返回新的 Node数组
return newTab;
} resize方法 就是对 HashMap的扩容方法。这里面就有当 使用 无参构造器创建 HashMap对象时,什么都不会干,只是会得到一个 加载系数值。只有第一次添加 键值对时,才会检查容量。会默认初始化一个 容量大小为16的Node类型数组来存储元素。Node 类型是 Map接口的内部Entry接口的实现类。
下面是生成 二叉红黑树的代码:
final void treeifyBin(Node[] tab, int hash) {
int n, index; Node e;
// 当前 数组不是nll 而且长度小于64 进行扩容
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
// 计算的位置不是空,而且长度大于64
TreeNode hd = null, tl = null;
do {
TreeNode p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
} 1.1.1 LinkedHashMap
保证在遍历元素时,可以按照添加的顺序进行遍历。原因是 在父类HashMap 的继承上,添加了一对指针,指向前一个以及后一个元素。
对于频繁的遍历操作,建议使用这个类。
这是 HashMap的一个子类。
public class LinkedHashMap
extends HashMap
implements Map
{
static class Entry extends HashMap.Node {
Entry before, after;
Entry(int hash, K key, V value, Node next) {
super(hash, key, value, next);
}
}
private static final long serialVersionUID = 3801124242820219131L;
transient LinkedHashMap.Entry head;
transient LinkedHashMap.Entry tail;
final boolean accessOrder;
private void linkNodeLast(LinkedHashMap.Entry p) {
LinkedHashMap.Entry last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
private void transferLinks(LinkedHashMap.Entry src,
LinkedHashMap.Entry dst) {
LinkedHashMap.Entry b = dst.before = src.before;
LinkedHashMap.Entry a = dst.after = src.after;
if (b == null)
head = dst;
else
b.after = dst;
if (a == null)
tail = dst;
else
a.before = dst;
}
void reinitialize() {
super.reinitialize();
head = tail = null;
}
Node newNode(int hash, K key, V value, Node e) {
LinkedHashMap.Entry p =
new LinkedHashMap.Entry(hash, key, value, e);
linkNodeLast(p);
return p;
}
Node replacementNode(Node p, Node next) {
LinkedHashMap.Entry q = (LinkedHashMap.Entry)p;
LinkedHashMap.Entry t =
new LinkedHashMap.Entry(q.hash, q.key, q.value, next);
transferLinks(q, t);
return t;
}
TreeNode newTreeNode(int hash, K key, V value, Node next) {
TreeNode p = new TreeNode(hash, key, value, next);
linkNodeLast(p);
return p;
}
TreeNode replacementTreeNode(Node p, Node next) {
LinkedHashMap.Entry q = (LinkedHashMap.Entry)p;
TreeNode t = new TreeNode(q.hash, q.key, q.value, next);
transferLinks(q, t);
return t;
}
void afterNodeRemoval(Node e) { // unlink
LinkedHashMap.Entry p =
(LinkedHashMap.Entry)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
void afterNodeAccess(Node e) { // move node to last
LinkedHashMap.Entry last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry p =
(LinkedHashMap.Entry)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
void internalWriteEntries(java.io.ObjectOutputStream s) throws IOException {
for (LinkedHashMap.Entry e = head; e != null; e = e.after) {
s.writeObject(e.key);
s.writeObject(e.value);
}
}
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(Map m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
public boolean containsValue(Object value) {
for (LinkedHashMap.Entry e = head; e != null; e = e.after) {
V v = e.value;
if (v == value || (value != null && value.equals(v)))
return true;
}
return false;
}
public V get(Object key) {
Node e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
public V getOrDefault(Object key, V defaultValue) {
Node e;
if ((e = getNode(hash(key), key)) == null)
return defaultValue;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
public void clear() {
super.clear();
head = tail = null;
}
protected boolean removeEldestEntry(Map.Entry eldest) {
return false;
}
public Set keySet() {
Set ks = keySet;
if (ks == null) {
ks = new LinkedKeySet();
keySet = ks;
}
return ks;
}
final class LinkedKeySet extends AbstractSet {
public final int size() { return size; }
public final void clear() { LinkedHashMap.this.clear(); }
public final Iterator iterator() {
return new LinkedKeyIterator();
}
public final boolean contains(Object o) { return containsKey(o); }
public final boolean remove(Object key) {
return removeNode(hash(key), key, null, false, true) != null;
}
public final Spliterator spliterator() {
return Spliterators.spliterator(this, Spliterator.SIZED |
Spliterator.ORDERED |
Spliterator.DISTINCT);
}
public final void forEach(Consumer action) {
if (action == null)
throw new NullPointerException();
int mc = modCount;
for (LinkedHashMap.Entry e = head; e != null; e = e.after)
action.accept(e.key);
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
public Collection values() {
Collection vs = values;
if (vs == null) {
vs = new LinkedValues();
values = vs;
}
return vs;
}
final class LinkedValues extends AbstractCollection {
public final int size() { return size; }
public final void clear() { LinkedHashMap.this.clear(); }
public final Iterator iterator() {
return new LinkedValueIterator();
}
public final boolean contains(Object o) { return containsValue(o); }
public final Spliterator spliterator() {
return Spliterators.spliterator(this, Spliterator.SIZED |
Spliterator.ORDERED);
}
public final void forEach(Consumer action) {
if (action == null)
throw new NullPointerException();
int mc = modCount;
for (LinkedHashMap.Entry e = head; e != null; e = e.after)
action.accept(e.value);
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
public Set> entrySet() {
Set> es;
return (es = entrySet) == null ? (entrySet = new LinkedEntrySet()) : es;
}
final class LinkedEntrySet extends AbstractSet> {
public final int size() { return size; }
public final void clear() { LinkedHashMap.this.clear(); }
public final Iterator> iterator() {
return new LinkedEntryIterator();
}
public final boolean contains(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry) o;
Object key = e.getKey();
Node candidate = getNode(hash(key), key);
return candidate != null && candidate.equals(e);
}
public final boolean remove(Object o) {
if (o instanceof Map.Entry) {
Map.Entry e = (Map.Entry) o;
Object key = e.getKey();
Object value = e.getValue();
return removeNode(hash(key), key, value, true, true) != null;
}
return false;
}
public final Spliterator> spliterator() {
return Spliterators.spliterator(this, Spliterator.SIZED |
Spliterator.ORDERED |
Spliterator.DISTINCT);
}
public final void forEach(Consumer> action) {
if (action == null)
throw new NullPointerException();
int mc = modCount;
for (LinkedHashMap.Entry e = head; e != null; e = e.after)
action.accept(e);
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
public void forEach(BiConsumer action) {
if (action == null)
throw new NullPointerException();
int mc = modCount;
for (LinkedHashMap.Entry e = head; e != null; e = e.after)
action.accept(e.key, e.value);
if (modCount != mc)
throw new ConcurrentModificationException();
}
public void replaceAll(BiFunction function) {
if (function == null)
throw new NullPointerException();
int mc = modCount;
for (LinkedHashMap.Entry e = head; e != null; e = e.after)
e.value = function.apply(e.key, e.value);
if (modCount != mc)
throw new ConcurrentModificationException();
}
abstract class LinkedHashIterator {
LinkedHashMap.Entry next;
LinkedHashMap.Entry current;
int expectedModCount;
LinkedHashIterator() {
next = head;
expectedModCount = modCount;
current = null;
}
public final boolean hasNext() {
return next != null;
}
final LinkedHashMap.Entry nextNode() {
LinkedHashMap.Entry e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
current = e;
next = e.after;
return e;
}
public final void remove() {
Node p = current;
if (p == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
K key = p.key;
removeNode(hash(key), key, null, false, false);
expectedModCount = modCount;
}
}
final class LinkedKeyIterator extends LinkedHashIterator
implements Iterator {
public final K next() { return nextNode().getKey(); }
}
final class LinkedValueIterator extends LinkedHashIterator
implements Iterator {
public final V next() { return nextNode().value; }
}
final class LinkedEntryIterator extends LinkedHashIterator
implements Iterator> {
public final Map.Entry next() { return nextNode(); }
}
} 最大的特点是 遍历输出时,可以按照我们添加的顺序进行输出。但是并没有改变它是无序的。
LinkedHashMap linkedHashMap = new LinkedHashMap<>();
linkedHashMap.put("123", "abc");
linkedHashMap.put("456", "bcd");
linkedHashMap.put("789", "cde");
System.out.println(linkedHashMap);
// {123=abc, 456=bcd, 789=cde} 看看构造方法:
public LinkedHashMap() {
super();
accessOrder = false;
}可以看到,无参构造方法里面调用的是父类 HashMap构造方法,然后设置了accessOrder=false
当调用put方法时,我们查看 LinkedHashMap的源码发现没有put方法。说明调用的是父类 HashMap的put方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}put方法又调用了 putVal方法,而LinkedHashMap也没有重写这个方法。即还是调用的 HashMap的 putVal方法。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
// 调用 newNode 方法,这个方法 LinkedHashMap 重写了
tab[i] = newNode(hash, key, value, null);
else {
Node e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
} 这个putVal方法里面 调用newNode方法时, LinkedHashMap 进行了重写。这里才开始体现了 LinkedHashMap 的区别。
怎么才知道有没有重写? 拿方法名在 LinkedHashMap 类里面搜索一下就知道了。
Node newNode(int hash, K key, V value, Node e) {
// 创建 LinkedHashMap.Entry 对象
LinkedHashMap.Entry p =
new LinkedHashMap.Entry(hash, key, value, e);
linkNodeLast(p);
return p;
} 这里里面 new了 自己的Entry 类对象
static class Entry extends HashMap.Node {
// 多了 before 、after 指针 来记录顺序
Entry before, after;
Entry(int hash, K key, V value, Node next) {
super(hash, key, value, next);
}
} 1.2 Hashtable 古老实现类
线程安全、效率低。不能存储null值的key和value
1.2.1 Properties
常用来处理配置文件,由于配置文件中的 key、value都是String类型
所以 Properties的key 和Value都是String 类型的。
存取数据时,建议使用 setProperty 方法 和getProperty 方法
Properties prop = new Properties();
FileInputStream inputStream = new FileInputStream("G:\\study\\leetCode\\JavaBaseStudy\\src\\main\\resources\\jdbc.properties");
prop.load(inputStream);
String name = prop.getProperty("name");
String password = prop.getProperty("password");
System.out.println(name);
System.out.println(password);1.3 TreeMap
按照添加的key-value进行排序,具体是按照key值进行排序的。能够实现排序遍历。要求key必须实现Comparable接口,或者创建TreeMap时,传入Comparator实现类对象。
2种添加方式 :
向TreeMap中添加 键值对,要求key必须是同一个类创建的对象。原因是要按照key进行排序
TreeMap map = new TreeMap<>();
Cat cat1 = new Cat(10, "jj");
Cat cat2 = new Cat(15, "aa");
Cat cat3 = new Cat(5, "dd");
Cat cat4 = new Cat(45, "cc");
map.put(cat1, 0);
map.put(cat2, 1);
map.put(cat3, 2);
map.put(cat4, 3);
Set> entries = map.entrySet();
for (Map.Entry entry : entries) {
System.out.println(entry);
}
//
Cat{age=5, type='dd'}=2
Cat{age=10, type='jj'}=0
Cat{age=15, type='aa'}=1
Cat{age=45, type='cc'}=3 添加的自定义类 Cat 内部实现了 Comparable 接口,重写了compareTo方法。
public class Cat implements Comparable{
public int age;
public String type = "cat";
@Override
public int hashCode() {
int result = age;
result = 31 * result + (type != null ? type.hashCode() : 0);
return result;
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (!(o instanceof Cat)) {
return false;
}
Cat cat = (Cat) o;
if (age != cat.age) {
return false;
}
return Objects.equals(type, cat.type);
}
@Override
public int compareTo(Object o) {
if ( !(o instanceof Cat)){
throw new RuntimeException("必须传入相同类型的对象");
}
Cat cat = (Cat) o;
if (this == cat){
return 0;
}
return Integer.compare(this.age, cat.age);
}
public Cat(int age, String type) {
this.age = age;
this.type = type;
}
public Cat() {
}
@Override
public String toString() {
return "Cat{" +
"age=" + age +
", type='" + type + '\'' +
'}';
}
}方式二: 在new TreeMap 时,传入一个Comparator 实现类对象。这样就不要求当做key的自定义类实现Comparable 接口。即使实现了,还是按照 Comparator 实现类对象定义的方式进行排序。
TreeMap map = new TreeMap<>(
// Comparator 匿名实现类
new Comparator() {
@Override
public int compare(Object o1, Object o2) {
if (o1 instanceof Cat && o2 instanceof Cat){
Cat c1 = (Cat) o1;
Cat c2 = (Cat) o2;
return Integer.compare(c1.age, c2.age);
}
throw new RuntimeException("传入的类型不匹配!");
}
}
);
Cat cat1 = new Cat(10, "jj");
Cat cat2 = new Cat(15, "aa");
Cat cat3 = new Cat(5, "dd");
Cat cat4 = new Cat(45, "cc");
map.put(cat1, 0);
map.put(cat2, 1);
map.put(cat3, 2);
map.put(cat4, 3);
Set> entries = map.entrySet();
for (Map.Entry entry : entries) {
System.out.println(entry);
} 1.4 CurrentHashMap
分段锁,高并发效率高
2、Collections 工具类
这个工具类提供了操作Collection 和Map的很多方法。
这个工具类 非常大,大概5500行代码。
这里只讲一些常用方法
-
void reverse(List list) 方法:反转List中的元素。没有返回值意味着是对原List进行操作
List list = new ArrayList<>();
list.add(123);
list.add(34);
list.add(7);
list.add(12);
list.add(-8);
list.add(0);
System.out.println(list); // [123, 34, 7, 12, -8, 0]
Collections.reverse(list);
System.out.println(list); // [0, -8, 12, 7, 34, 123]-
void shuffle(List list) 方法: 随机打乱List中的顺序(每次执行结果都可能不一样),也是对原List进行操作
void shuffle(List list, Random rnd) 有一个重载方法,第二个参数传入一个随机种子。
List list = new ArrayList<>();
list.add(123);
list.add(34);
list.add(7);
list.add(12);
list.add(-8);
list.add(0);
System.out.println(list);// [123, 34, 7, 12, -8, 0]
Collections.shuffle(list);
System.out.println(list);// [34, 7, 0, 12, 123, -8]-
void sort(List
list) 排序方法:调用List元素内的compareTo方法。这要求Lsit中的元素类型一致,且实现了Comparable接口,并重写了compareTo方法。还是对原List进行排序。 有一个重载方法:void sort(List
list, Comparator c) 这个方法第二个参数是传入一个Comparator 实现类对象,这个方法就不要求一定要实现Comparable接口了。即使实现了,也是按照Comparator中定义的比较方法进行排序。
List list = new ArrayList<>();
list.add(123);
list.add(34);
list.add(7);
list.add(12);
list.add(-8);
list.add(0);
System.out.println(list);// [123, 34, 7, 12, -8, 0]
Collections.sort(list);
System.out.println(list); // [-8, 0, 7, 12, 34, 123]-
void swap(List list, int i, int j) 交换list的指定索引的元素,对原List操作
List list = new ArrayList<>();
list.add(123);
list.add(34);
list.add(7);
list.add(12);
list.add(-8);
list.add(0);
System.out.println(list);// [123, 34, 7, 12, -8, 0]
Collections.swap(list, 2,5);
System.out.println(list); // [123, 34, 0, 12, -8, 7]-
T max(Collection coll) 求 List中的最大元素,按照 Comparable接口进行比较
T max(Collection coll, Comparator comp) 求 List中的最大元素,按照 Comparator接口进行比较
T min(Collection coll) 求 List中的最小元素,按照 Comparable接口进行比较
T min(Collection coll, Comparator comp) 求 List中的最小元素,按照 Comparator接口进行比较
List list = new ArrayList<>();
list.add(123);
list.add(34);
list.add(7);
list.add(12);
list.add(-8);
list.add(0);
System.out.println(list);
Comparable max = Collections.max(list);
Comparable min = Collections.min(list);
System.out.println(max); // 123
System.out.println(min); // -8-
int frequency(Collection c, Object o) 找到指定的元素在List中出现的次数,返回值是int型
List list = new ArrayList<>();
list.add(123);
list.add(34);
list.add(7);
list.add(34);
list.add(12);
list.add(-8);
list.add(0);
int i = Collections.frequency(list, 34);
int i1 = Collections.frequency(list, 9);
System.out.println(i); // 2
System.out.println(i1); // 0-
void copy(List dest, List src) 复制List,第一参数是 目标List,第二个参数是 源List
下面是 copy方法的源码:
public static void copy(List dest, List src) {
int srcSize = src.size();
if (srcSize > dest.size())
throw new IndexOutOfBoundsException("Source does not fit in dest");
if (srcSize < COPY_THRESHOLD ||
(src instanceof RandomAccess && dest instanceof RandomAccess)) {
for (int i=0; i di=dest.listIterator();
ListIterator si=src.listIterator();
for (int i=0; i 可以看到 源List的长度 不能大于 目标 List的长度,否则会抛异常。
下面这种写法就会有异常:原因是 直接new的List 长度为 0
List list = new ArrayList<>();
List list1 = new ArrayList<>();
list.add(123);
list.add(34);
list.add(7);
list.add(34);
list.add(12);
list.add(-8);
list.add(0);
Collections.copy(list1, list); // 异常:IndexOutOfBoundsException: Source does not fit in dest
System.out.println(list1);所以,复制之前要先填充好。
List list = new ArrayList<>();
list.add(123);
list.add(34);
list.add(7);
list.add(34);
list.add(12);
list.add(-8);
list.add(0);
// 先填充好
List list1 = Arrays.asList(new Object[list.size()]);
System.out.println(list1); // [null, null, null, null, null, null, null]
// 再调用copy方法
Collections.copy(list1, list);
System.out.println(list1); // [123, 34, 7, 34, 12, -8, 0]-
boolean replaceAll(List
list, T oldVal, T newVal) 将List中所有的 旧值 替换为 新值,返回值为Boolean类型
List list = new ArrayList<>();
list.add(123);
list.add(34);
list.add(7);
list.add(34);
list.add(12);
list.add(-8);
list.add(0);
// 将 原List中的 7 全部替换为 5
boolean b = Collections.replaceAll(list, 7, 5);
System.out.println(b); // true
System.out.println(list); // [123, 34, 5, 34, 12, -8, 0]
// 将 原List中的 7 全部替换为 5
boolean b1 = Collections.replaceAll(list, 7, 5);
System.out.println(b1); // false
System.out.println(list); // [123, 34, 5, 34, 12, -8, 0]-
Collections 工具类提供了多个 线程同步方法 synchronizedXXX 方法,作用是 将指定的集合包装成线程同步的集合,解决多线程并发访问集合时的线程安全问题。会返回一个新的线程安全的集合。

List list = new ArrayList<>();
list.add(123);
list.add(34);
list.add(7);
list.add(34);
list.add(12);
list.add(-8);
list.add(0);
// 得到线程安全的 list
List list1 = Collections.synchronizedList(list);