Python+FPDF 实现灵活的导出数据至PDF
2023.6.13补充
本文介绍的这种方式通过修改FPDF源码可能会比原本的包好用一些(如果你有类似的需求的话)
但是这种方法不好维护且实现起来比较复杂,代码中分支比较多,在实际生产环境中还是更推荐使用HTML to PDF或者WORD to PDF在实现起来会更好一些
另外使用HTML to PDF这种方式时,由于HTML的表格会自动的调整列宽,因此在一行内容过多时,不用程序员干预,会自动进行调整每行显示。
前言
我的职位是Python后端,在工作中会用到Tornado框架来开发接口,最近遇到了一个需求是将数据按一定的格式导出到PDF中。相信后端工程师或多或少会接触到导出数据的工作。在导出PDF时,我所了解到的解决方案有以下几种:
1、通过操作html,然后用一些第三方包将html转化成pdf。
2、将word转化成pdf。
3、也就是本文介绍的方式使用FPDF向pdf中写入数据。
FPDF简单介绍
FPDF内置了一些方法,可以实现一些常规的数据导出操作。
安装:pip install fpdf
例如:
pdf.cell() 输出一个格子,可以设置宽高、文本、是否换行、是否有边框、文本靠左、居中、靠右。
pdf.image() 可以显示一张图片,同样设置宽高、图片路径。
pdf.ln() 可以指定换行大小。
值得一提的是FPDF可以在输出cell或者image的时候自动增加新页,FPDF对象在整个文档期间控制作用的是self.x和self.y, 可以不设置其文本或者图像的输出位置,默认使用这两个变量来定位输出的位置。
尽管FPDF已经提供了很多功能,但是在实际使用中,发现使用内置的方法并不能够很好的达到心里预期的结果,并且网络上的博文大都只是泛泛的介绍了一下FPDF,针对个人遇到的问题,希望给在看的你们一点启示。
下面介绍在使用FPDF期间我遇到的一些问题和解决方案,因为FPDF开源,不可避免的会修改一些它的包体源码来满足我的需求。
为了描述方法方便 定义一个FPDF类实例:
pdf = FPDF("L", "mm", "A4") # 横向,单位毫米,A4纸张
一、问题1:FPDF不支持中文数据的问题
如果使用其默认的字体, 如果数据中出现中文,中文或者中文字符、标点会报如下错误:
UnicodeEncodeError: 'latin-1' codec can't encode characters in position 82-83: ordinal not in range(256)
解决方案
在网络上找一个支持中文的字体下载下来拷贝到自己的项目路径,可以下载fireflysung.ttf字体。
在项目中使用pdf.add_font('fireflysung', '', f'fonts/fireflysung.ttf', uni=True)添加字体;
使用pdf.set_font('fireflysung', '', 10)设置字体。
二、问题2:使用pdf.image()方法通过参数控制是否换行
FPDF默认在输出图片后自动换行,有时我们并不想让其自动换行,而在图片后面还想继续写入文字的话,可以通过修改包体源码fpdf.py
image方法增加默认参数new_line=False来控制。

三、问题3:通过人为控制页面x、y、page变量实现的复杂数据布局的导出
这种方法我认为是一种进阶用法:
—self.x变量控制每行的横坐标,当cell指定换行或者ln时self.x会被置为10(受人为设置的页面距大小的影响)也就是下一行的起始位置。
—self.y变量控制这一页的纵坐标,每页起始为10(同上),每页最大的纵坐标为180(A4)左右。需要注意的是当认为换页pdf.add_page()之后或者自动换页之后,y会被置为10(同上)。
所以我们可以根据这一特性,控制这三个变量来得到我们想要的pdf页面效果。
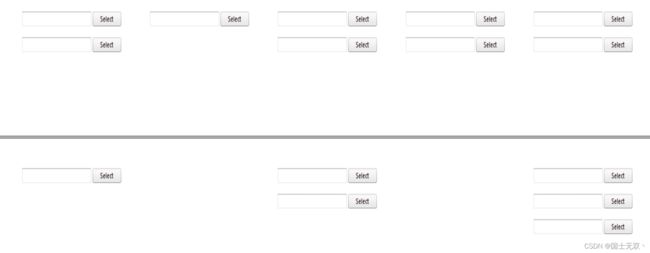
3.1、举栗:通过fpdf实现下图效果

Python代码
"""
需要控制的三个变量
注意:set_page()方法需要在源码补充下。
"""
x, y, page = pdf.get_x(), pdf.get_y(), pdf.page_no()
# 共输出5列
for idx in range(5):
pdf.set_y(y)
pdf.set_page(page)
# 每列输出3个图片
for i in range(3):
pdf.image("file.jpg", w=40, h=10, new_line=True) # 通过new_line=True控制换行显示
pdf.set_x(pdf.get_x() + 50)
3.2、根据上栗实现图片的分页显示
Python代码
x, y, page = pdf.get_x(), pdf.get_y(), pdf.page_no()
# 设置每列显示数量
colume_cnt = [3, 1, 4, 2, 5]
for idx in range(5):
pdf.set_y(y)
pdf.set_page(page)
for i in range(colume_cnt[idx]):
pdf.image("file.jpg", w=40, h=10, new_line=True)
pdf.set_x(pdf.get_x() + 50)
当然,如果直接复制代码运行,效果可能是这样的
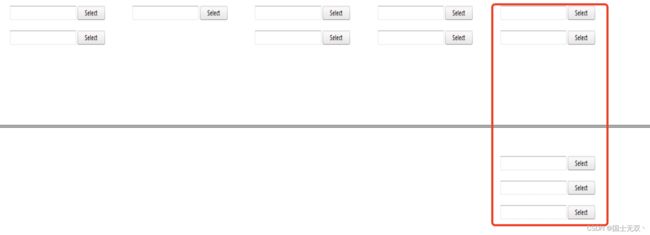
BUG原因:
这是因为我们因为是按列输出的 数据在一页显示不了,也就是说每列都要依赖fpdf的自动分页的机制,每次添加一页,添加新的一页时,旧页面的内容不会保存,这就导致了每一列都会覆盖其前面一列的新一页的内容,结果就是只有最后一列在新一页上有内容。
解决方案:
用于指示当前页的变量为self.page而用于存储每页信息的是self.pages,它是一个dict,key是页码的数字1 2 3 4...,我们只需要在image方法检测是否触发自动分页的代码里加入判断,当前self.page指向的页码+1是否存在于self.pages的KEY中,不存在时在允许其执行自动分页,若存在直接将self.page += 1指向已存在的最新页码即可保留旧页面的内容不被覆盖。
找到Image方法的这一行代码:if (self.y + h > self.page_break_trigger and not self.in_footer and self.accept_page_break()):将其上下文修改为:
if (self.y + h > self.page_break_trigger and not self.in_footer and self.accept_page_break()):
if not self.pages.get(self.page_no() + 1):
# Automatic page break
x = self.x
self.add_page(self.cur_orientation)
self.x = x
else:
self.page += 1
self.y = 10
By The Way:上方两个例子较简单,在实际的应用中,可能每列的宽度不定宽,高度不定以及每列每行数据对齐的问题等等;但通过控制x、y、page的方法来导出数据是较为便捷的。
四、问题4:当数据量大且恰好要求必须一行展示较多数据时
这种问题我的解决方案是,首先定义一个比例系数以及确定一行要展示几列数据,提前用
pdf.cell()/pdf.image()指定分配每列格子的宽度、高度,在输出数据时,提前预估一下,每个格子的宽度是否能装下这么多文字,不会溢出;如果不能比例系数相应缩小,再次尝试。
确定下比例系数后,将此值应用到设置字体大小、图片上,将字号/图片宽高乘此系数,即可解决,值得一提的是字号最小是1,每行可容纳的数据量还是挺大的。