Dubbo——容错策略
Cluster接口关系
在微服务环境中,可能多个节点同时都提供同一个服务。当上层调用Invoker时,无论实际存在多少个Invoker,只需要通过Cluster层,即可完成整个调用容错逻辑,包括获取服务列表、路由、负载均衡等,整个过程对上层都是透明的。当然,Cluster接口只是串联起整个逻辑,其中ClusterInvoker只实现了容错逻辑部分,其他逻辑则是调用了Directory、Router、LoadBalance等接口实现。
容错的接口主要分为两大类,第一类是Cluster类,第二类是ClusterInvoker类。Cluster和ClusterInvoker之间的关系也非常简单:Cluster接口下面有多种不同的实现,每种实现中都需要实现接口的join方法,在方法中会"new"一个对应的ClusterInvoker实现。以FailoverCluster实现为例进行说明:
public class FailoerCluster implement Cluster {
...
@Override
public <T> Invoker<T> join(Directory<T> directory) throws RpcException{
return new FailoverClusterInvoker<T>(directory);
}
}
FailoverCluster是Cluster的其中一种实现,FailoverCluster中直接创建了一个新的FailoverClusterInvoker并返回。FailoverClusterInvoker继承的接口是Invoker。光看文字描述还是比较难懂。因此,在理解集群容错的原理之前,先看一下整个集群容错的接口关系。
Cluster接口的类图关系如下:
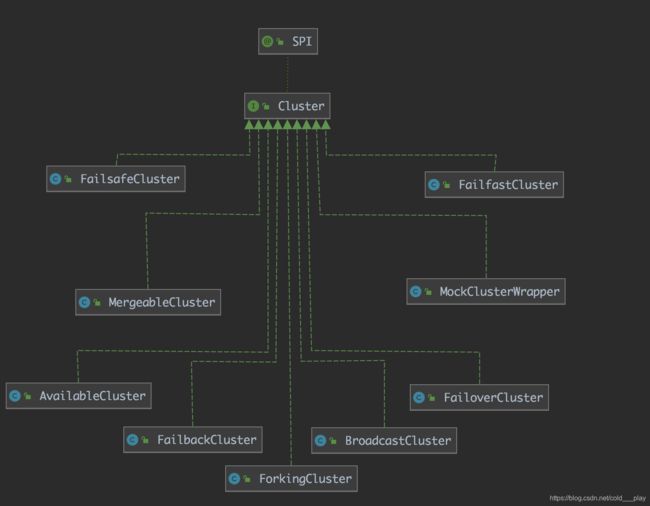
Cluster是最上层的接口,下面一共有9个实现类。Cluster接口上有SPI注解,也就是说,实现类是通过扩展点机制动态生成的。每个实现类里都只有一个join方法,实现也很简单,直接"new"一个对应的ClusterInvoker。其中AvailableCluster例外,直接使用匿名内部类实现了所有功能。
ClusterInvoker的类结构:
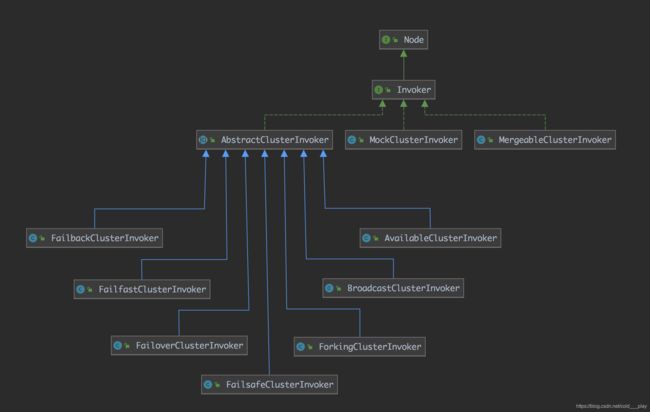
Invoker接口是最上层的接口,它下面分别有AbstractClusterInvoker、MockClusterInvoker和MergeableClusterInvoker三个类。其中,AbstractClusterInvoker是一个抽象类,其封装了通用的模板逻辑,如获取服务列表、负载均衡、调用服务提供者等,并预留了一个doInvoke方法需要子类实现。AbstractClusterInvoker下面有7个子类,分别实现了不同的集群容错机制。
MockClusterInvoker和MergeableClusterInvoker由于并不适用于正常的集群容错逻辑,因此没有挂在AbstarctClusterInvoker下面,而是直接继承了Invoekr接口。
Failover策略
Cluster接口上有SPI注解@SPI(FailoverCluster.NAME),即默认实现是Failover。该策略的代码逻辑如下:
- 校验。校验从AbstractClusterInvoker传入的Invoker列表是否为空。
- 获取配置参数。从调用URL汇总获取对应的retries重试次数。
- 初始化一些集合对象。用户保存调用过程中出现的异常、记录调用了哪些节点(这个会在负载均衡中使用),在某些配置下,尽量不要一直掉同一个服务。
- 使用for循环实现重试,for循环的次数就是重试的次数。成功则返回,否则继续循环。如果for循环完,还没有一个成功返回,则抛出异常,把3中记录的信息抛出去。
前3步都是做一些校验、数据准备工作。第4步开始真正的调用逻辑。以下步骤是for循环中的逻辑:
- 校验。如果for循环次数大于1,即有过一次失败,则会再次校验节点是否被销毁、传入的Invoker列表是否为空。
- 负载均衡。调用select方法做负载均衡,得到要调用的节点,并记录这个节点到步骤3的集合里,再把已经调用的节点信息放进RPC上下文中。
- 远程调用。调用invoker#invoke方法做远程调用,成功则返回,异常则记录异常信息,再做下次循环。
Failover流程如下图:
FailFast策略
Failfast会在失败后直接抛出异常并返回结果,实现非常简单,步骤如下:
- 校验。校验从AbstractClusterInvoker传入的Invoker列表是否为空。
- 负载均衡。调用select方法做负载均衡,得到要调用的节点。
- 进行远程调用。在try代码块中用invoker#invoke方法做远程调用。如果捕获到异常,则直接封装成RpcException抛出。
整个过程非常简短,也不会做任何中间信息的记录。
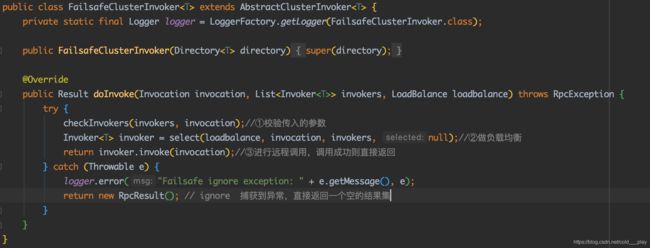
Failsafe策略
Failsafe调用时如果出现异常,则会直接忽略。实现也非常简单,步骤如下:
- 校验传入的参数。校验从AbstractClusterInvoker传入的Invoker列表是否为空。
- 负载均衡。调用select方法做负载均衡,得到要调用的节点。
- 远程调用。在try代码块总调用invoker#invoke方法做远程调用,”catch“到任何异常都直接"吞掉",返回一个空的结果集。
Failback策略
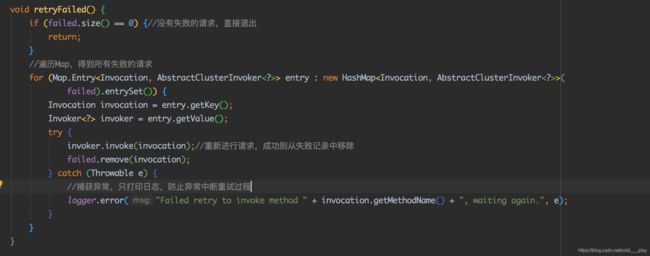
Failback如果调用失败,则会定期重试。FailbackClusterInvoker里面定义了一个ConcurrentHashMap,专门用来保存失败的调用。另外定义了一个定时线程池,默认每5秒把所有失败的调用拿出来,重试一次。如果调用重试成功,则会从ConcurrentHashMap中移除。
doInvoker的调用逻辑如下:
- 校验传入的参数。校验从AbstractClusterInvoker传入的Invoker列表是否为空。
- 负载均衡。调用select方法做负载均衡,得到要调用的节点。
- 远程调用。在try代码块中调用invoker#invoke方法做远程调用,"catch"到异常后直接把invocation保存到重试的ConcurrentHashMap中,并返回一个空的结果集。
- 定时线程池会定时把ConcurrentHashMap汇中的失败请求拿出来重新请求,请求成功则从ConcurrentHashMap中移除。如果请求还是失败,则异常也会被"catch"住,不会影响ConcurrentHashMap后面的重试。

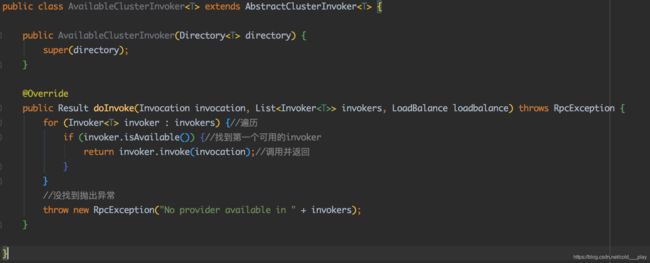
Available策略
Available是找到第一个可用的服务直接调用,并返回结果:
- 遍历从AbstractClusterInvoker传入的Invoker列表,如果Invoker是可用的,则直接调用并返回。
- 如果遍历整个列表还没有找到可用的Invoker,则抛出异常。
Broadcast策略
Broadcast会广播所有可用的节点,如果任何一个节点报错,则返回异常。步骤如下:
- 前置操作。校验从AbstractClusterInvoker传入的Invoker列表是否为空;在RPC上下文设置Invoker列表;初始化一些对象,用于保存调用过程中产生的异常的结果信息等。
- 循环遍历所有Invoker,直接做RPC调动。
任何一个节点调用出错,并不会中断整个广播过程,会先记录异常,在最后广播完成后再抛出。如果过个节点异常,则只有最后一个节点的异常会抛出,前面的异常会被覆盖。

Forking策略
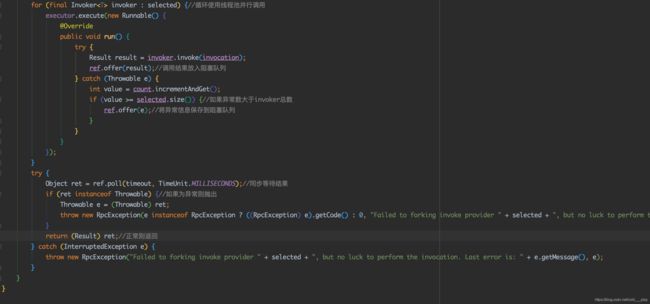
Forking可以同时并行请求多个服务,有任何一个返回,则直接返回。相对于其他调用策略,Forking的实现是最复杂的。其步骤如下:
- 准备工作。校验传入的Invoker列表是否可用;初始化一个Invoker集合,用于保存真正要调用的Invoker列表;从URL中得到最大并行数、超时时间。
- 获取最终要调用的Invoker列表。假设用户色红孩子最大的并行数为n,实际可以调用的最大服务数为v。如果n<0或n
注意:在Invoker加入集合时,会做去重操作。因此,如果用户设置的负载均衡策略每次返回的都是同一个Invoker,那么集合中最后只会存在一个Invoker,也就是只会调用一个节点。
- 调用前的准备工作。设置要调用的Invoker列表到RPC上下文;初始化一个异常计数器;初始化一个阻塞队列,用于记录并行调用的结果。
- 执行调用。循环使用线程池并行调用,调用成功,则把结果加入阻塞队列;调用失败,则失败计数+1。如果所有线程的调用都失败了,即失败计数>=所有可调用的Invoker时,则把异常信息加入阻塞队列。
注意:并行调用是如何保证个别调用失败不返回异常信息,只有全部失败才会返回异常信息呢?
因为有判断条件,当失败计数>=所有可调用的Invoker时,才会把异常信息放入阻塞队列,所以只有当最后一个Invoker也调用失败时才会把异常信息保存到阻塞队列,从而达到全部失败才返回异常的效果。
- 同步等待结果。由于步骤4中的步骤是在线程池中执行的,因此主线程还会继续往下执行,主线程中会使用阻塞队列的
poll("超时时间")方法,同步等待阻塞队列中的第一个结果,如果是正常结果则返回,如果是异常则抛出。
从上面步骤可得知,Forking的超时是通过再阻塞队列的poll方法中传入超时时间实现的;线程池汇总并发调用会获取第一个正常返回的结果只有所有请求都失败了,Forking才会失败。