高并发下的缓存问题及布隆过滤器
一. 高并发下缓存的三大问题
1. 概述
- 背景
- 在高并发场景下,如果系统直连数据库,数据库会出现性能问题,甚至造成数据库宕机,服务不可用。
- 为了降低数据库的压力,我们通常会设计一个缓存系统,在访问数据库之前,拦截一部分流量,保证系统的稳定和数据库的可用。
- 高并发场景下缓存最常见的三大问题
- 缓存雪崩
- 缓存穿透
- 缓存击穿
2. 缓存雪崩
2.1 缓存雪崩的含义
- 缓存雪崩:当某一个时刻出现大规模的缓存失效的情况,那么就会导致大量的请求直接打在数据库上面,导致数据库压力巨大,如果在高并发的情况下,可能瞬间就会导致数据库宕机。

2.2 分析
- 造成缓存雪崩的关键:在同一时间大规模的key失效。
- 出现缓存雪崩的原因
- 第一种:可能是Redis宕机
- 第二种:可能是采用了相同的过期时间。
2.3 缓存雪崩的解决方案
- 法1:搭建Redis集群,防止Redis宕机导致缓存雪崩的问题,提高Redis的容灾性。
- 法2:在原有的失效时间上加一个随机值(比如1-5分钟随机),避免采用相同过期时间的key同时失效。
- 法3:提高数据库的容灾能力,可以使用分库分表,读写分离的策略。
- 法4:增加兜底措施(熔断机制或服务降级),防止过多请求打到数据库。
3. 缓存击穿
3.1 缓存击穿的含义
-
缓存击穿:一个热点Key(数据库存在该数据),有大并发集中对其进行访问,突然间这个Key失效了,导致大并发全部打在数据库上,导致数据库压力剧增,这种现象就叫做缓存击穿。

-
缓存雪崩 && 缓存击穿
- 缓存雪崩:大规模key同时失效;
- 缓存击穿:一个热点key。
3.2 分析
- 关键:某个热点的key失效,导致大并发集中打在数据库上。
- 解决方案的考虑
- 第一种:热点key不设置过期时间;
- 第二种:降低打在数据库的请求数量。
3.3 缓存击穿的解决方案
- 法1:如果业务允许,将热点key设置为永不过期;
- 法2:使用互斥锁,针对同一个key只允许一个线程到数据库查询。
- 说明:如果缓存失效的情况,只有拿到锁才可以查询数据库,降低了在同一时刻打在数据库上的请求,防止数据库打死。
- 问题:导致系统的性能变差。
4. 缓存穿透
4.1 缓存穿透的含义
- 缓存穿透:缓存和数据库都没有的数据,被大量请求,这些请求像“穿透”了缓存一样直接打在数据库上,这种现象就叫做缓存穿透。

4.2 分析
- 关键:传进来的key在缓存和数据库均不存在。
- 说明:假如有黑客传进大量的不存在的key,则大量的请求打在数据库上是很致命的,因此在日常开发中要对参数做好校验,一些非法的参数,不可能存在的key就直接返回错误提示,要对调用方保持这种“不信任”的心态。
4.3 缓存穿透的解决方案
- 法1:缓存空值/默认值,即把无效的Key存入缓存。
- 详解:如果Redis查不到数据,数据库也查不到,我们把这个Key存入缓存,设置其value=null,当下次再通过这个Key查询时就不需要再查询数据库。
- 缺点:如果传进来的这个不存在的Key值每次都是随机的,那存进Redis也没有意义。
- 法2:使用布隆过滤器。
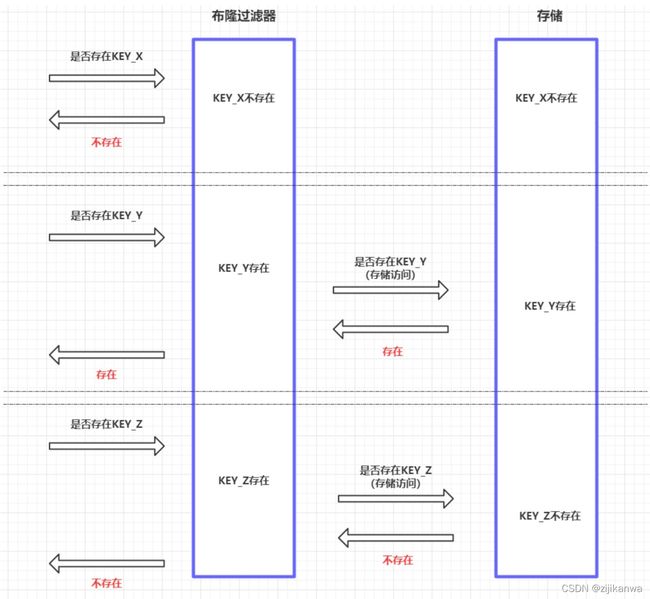
- 概述:布隆过滤器是一种概率性数据结构,它可以告诉我们数据一定不存在或可能存在。
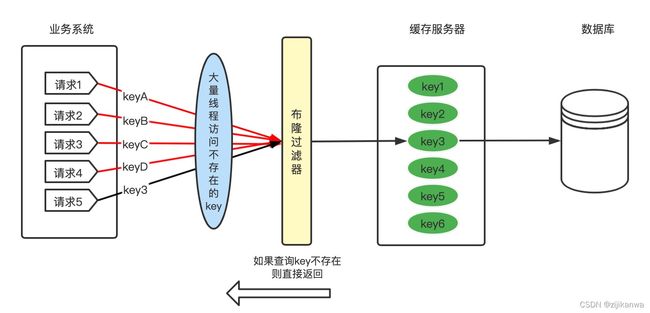
- 详解:我们可以在缓存之前再加一层布隆过滤器,在查询的时候先去布隆过滤器查询key是否存在,如果不存在就直接返回。
二. 布隆过滤器及其变体的介绍与应用
1. 布隆过滤器介绍
1.1 概述
- 布隆过滤器(Bloom Filter)是一种比较巧妙的、空间高效的、概率型数据结构,该数据结构于1970年由布隆(Burton Howard Bloom)提出。
- 其特点是高效插入和查询,主要用于快速检测一个元素是否在集合中,即告诉我们数据一定不存在或可能存在。
1.2 基本思想
- 数据结构:它由固定大小的二进制向量/位数组,以及一系列随机映射函数(哈希函数)两部分组成。
- 思想:其核心思想就是利用多个不同的Hash函数来解决冲突。
- Hash碰撞:两个不同元素映射到同一个哈希函数后得到的值可能相同。
- 基本思想:它引入多个哈希函数来减少冲突。如果某一个哈希函数得出元素不在集合中,则该元素肯定不在集合中;只有所有哈希函数都判定该元素在集合中,才能确定该元素存在于集合中。
1.3 原理
- 位数组:布隆过滤器使用一个m比特的数组来保存信息。在初始状态时,对于长度为m的位数组,它的所有位都被置为0。

- Hash函数:为了表达S={x1, x2,…,xn}这样一个n个元素的集合,它使用k个相互独立的哈希函数,分别将集合中的每个元素映射到{1,…,m}的范围中。
- 添加元素到集合:当有变量被加入集合时,使用k个哈希函数得到k个哈希值,然后将数组中对应的比特位设置为1(假定有2个元素,3个映射函数)
- 注意:如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。

- 判断元素是否存在:如判断y是否属于这个集合,只需要对y使用k个哈希函数得到k个哈希值,如果所有hash(y)的位置都是1,则布隆过滤器会认为y是集合中的元素,否则不在集合中。
1.4 误判率和特性
思考:判断两个元素y1和y2。
- y1:y1通过三个哈希函数的映射有一个位置为0,因此布隆过滤器会判断y1不在集合中。
- y2:y2通过三个哈希函数的映射所有位置均为1,因此布隆过滤器会判断y2在集合中。但实际上,y2可能属于这个集合,也可能不属于,因为每个位置都可能与其他元素共用(即发生Hash冲突)。
- 误判率
- 布隆过滤器的误判:指多个输入经过哈希之后在相同的bit位置都为1,这样就无法判断究竟是哪个输入产生的。
- 误判的概率:取决于Hash函数的个数、Hash函数冲撞的概率、位数组的大小。
- 通常在工程里Hash函数用3~5个,实际值视需求而定。
- 假阳性:把本来不存在布隆过滤器中的元素误判为存在的情况叫做假阳性。
- 特性
- 从容器的角度
- 如果布隆过滤器判断元素在集合中存在,则不一定存在;
- 如果布隆过滤器判断不存在,则一定不存在。
- 从元素的角度
- 如果元素实际存在,则布隆过滤器一定判断存在;
- 如果元素实际不存在,则布隆过滤器可能判断存在。
- 从容器的角度
1.5 优缺点
- 优点:它的空间效率和查询时间都远远超过一般的数据结构(如传统的List、Set、Map等数据结构)。
- 空间效率和插入/查询效率都是常数O(K)
- 哈希函数相互独立,利于硬件并行实现
- 不需要存储元素本身,数据安全 - 缺点
- 存在一定的误判率;
- 存放在布隆过滤器的数据不能删除。
1.6 适用场景和典型应用
- 适用场景:用于判定给定数据是否存在,但不严格要求100%正确的场合。
- 典型应用
- 数据库防止穿库。Bigtable、HBase、Cassandra以及Postgresql使用布隆过滤器来减少不存在的行或列的磁盘查找,大幅度提高数据库查询的性能。
- 判断用户是否阅读过某视频/文章。当然会导致一定的误判,但不会让用户看到重复的内容。
- 缓存穿透场景。如果有一波冷数据,在缓存前先通过布隆过滤器。如果布隆过滤器返回不存在,则直接返回;只有布隆过滤器返回存在,才去查询缓存,如果没查询到,则到数据库查询。
- WEB拦截器,如果相同请求则拦截,防止重复被攻击。用户第一次请求,将请求参数放入布隆过滤器中,当第二次请求时,先判断请求参数是否被布隆过滤器命中,可以提高缓存命中率。Google Chrome浏览器使用了布隆过滤器加速安全浏览服务。
- 布隆过滤器使用场景示意图
2. 布隆过滤器的实现
2.1 布隆过滤器在Guava中的实现
- 概述
- 谷歌的Guava中提供了一个现成的布隆过滤器。
- 占用内存很小:如存储100万元素只占用0.87M的内存,生成了5个哈希函数。
- 说明
- 布隆过滤器提供的存放元素的方法是put()
- 布隆过滤器提供的判断元素是否存在的方法是migjtContain()
- 布隆过滤器的误判率默认设置为0.03,也可以在创建时自行指定。
- 位图的容量是基于元素个数和误判率计算出来的。
- 根据位数组的大小,可以进一步计算出哈希函数的个数。
- 实现示例
-
引入依赖
<dependency> <groupId>com.google.guavagroupId> <artifactId>guavaartifactId> <version>25.0-jreversion> dependency> -
实现示例
public class bloomFilterTest { public static void main(String[] args) { // 创建布隆过滤器对象:创建了一个最多存放1500个字符串的布隆过滤器,并且误判率为0.01 BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.integerFunnel(),1500,0.01); // 将元素添加进布隆过滤器 String data = "data01"; bloomFilter.put(data); // 判断指定元素是否存在 System.out.println(filter.mightContain(data)); } }
-
- 说明
- 当mightContain()方法返回true时,我们可以99%确定该元素在过滤器中;当过滤器返回false时,我们可以100%确定该元素不存在于过滤器中。
- Guava提供的布隆过滤器实现算法比较权威,但只能在单机使用,而现在系统通常都是分布式场景。
2.2 基于Tair的布隆过滤器
-
概述:为了解决分布式场景的问题,集团的分布式缓存中间件Tair(Tair 2.0 RDB)也实现了BloomFilter。
-
实现示例
- 引入依赖
<dependency> <groupId>com.taobao.rdbgroupId> <artifactId>rdb-client2artifactId> <version>2.5.0-hotkeyversion> dependency> - 实现代码
RdbSmartApi rdbSmartApi = RdbSmartFactory.getClientManager("xxx"); rdbSmartApi.setPassWord("xxx"); rdbSmartApi.init(); //Bloom过滤器的名字 String filterName = "myBloomFilter"; //预计要插入的数据大小 Long size = 10000000L; //误判率,0.00001代表错误率为0.001% double errorRate = 0.00001; //创建一个BloomFilter String result = rdbSmartApi.sync().bfreserve(filterName.getBytes(),size,errorRate); //创建成功则返回OK if("OK".equals(result)){ String data = "data01"; //向BloomFilter中插入一条数据 boolean success = rdbSmartApi.sync().bfadd(filterName.getBytes(),data.getBytes()); if(success){ //exist为是否存在 boolean exist = rdbSmartApi.sync().bfexists(filterName.getBytes(),data.getBytes()); } }
- 引入依赖
2.3 基于Redis的布隆过滤器
- 概述:Redis v4.0之后有了Module(模块/插件)功能,Redis Modules让Redis可以使用外部模块扩展其功能,布隆过滤器就是其中的Module,官网推荐RedisBloom作为Redis布隆过滤器的Module。
- Redis Modules的介绍:https://redis.io/modules
- RedisBloom的介绍:https://github.com/RedisBloom/RedisBloom
- 安装RedisBloom
- 法1:直接编辑进行安装
git clone https://github.com/RedisBloom/RedisBloom.git cd RedisBloom make #编译 会生成一个rebloom.so文件 redis-server --loadmodule /path/to/rebloom.so #运行redis时加载布隆过滤器模块 redis-cli # 启动连接容器中的 redis 客户端验证 - 法2:使用Docker进行安装
docker pull redislabs/rebloom:latest # 拉取镜像 docker run -p 6379:6379 --name redis-redisbloom redislabs/rebloom:latest #运行容器 docker exec -it redis-redisbloom bash redis-cli
- 法1:直接编辑进行安装
- 使用
- 基本指令
bf.add:添加元素到布隆过滤器 bf.exists:判断元素是否在布隆过滤器 bf.madd:添加多个元素到布隆过滤器 bf.mexists:判断多个元素是否在布隆过滤器127.0.0.1:6379> bf.add user Tom (integer) 1 127.0.0.1:6379> bf.exists user Tom (integer) 1 127.0.0.1:6379> bf.exists user John (integer) 0 127.0.0.1:6379> bf.madd user Barry Jerry Mars 1) (integer) 1 2) (integer) 1 3) (integer) 1 127.0.0.1:6379> bf.mexists user Barry Linda 1) (integer) 1 2) (integer) 0 - Redis的客户端Redisson和lettuce基于布隆过滤器做了封装。示例:Redisson
<dependency> <groupId>org.redissongroupId> <artifactId>redissonartifactId> <version>3.15.1version> dependency>public class RedissonBloomFilterDemo { public static void main(String[] args) { Config config = new Config(); config.useSingleServer().setAddress("redis://127.0.0.1:6379"); RedissonClient redisson = Redisson.create(config); // 布隆过滤器的名称 RBloomFilter<String> bloomFilter = redisson.getBloomFilter("user"); // 初始化布隆过滤器,预计统计元素数量为55000000,期望误判率为0.03 bloomFilter.tryInit(55000000L, 0.03); bloomFilter.add("Tom"); bloomFilter.add("Jack"); System.out.println(bloomFilter.count()); //2 System.out.println(bloomFilter.contains("Tom")); //true System.out.println(bloomFilter.contains("Linda")); //false } }
- 基本指令
3. 布隆过滤器的变体
3.1 CountingBloomFilter(计数布隆过滤器)
- 背景:标准的布隆过滤器只支持插入和查找两种操作,在集合是静态集合时,它可以很好地工作。但是如果集合经常变动,其弊端就显现出来了,因为它不支持删除操作。
- 概述:CountingBloomFilter是BloomFilter的一个变种,它扩展标准布隆过滤器的数据结构,将底层数组的每一位扩展为一个4位大小的计数器Counter,用来存储某个下标映射成功的频次。它以占用更多的空间来换取支持删除操作。
- 插入元素时,通过k个哈希函数映射到k个计数器,这些命中的计数器值增加1;
- 删除元素时,删除元素的时候,通过k个散列函数映射到k个计数器,这些计数器值减少1。
- 使用CBF判断元素是否在集合的规则
- 某个元素通过k个散列函数映射到k个计数器,如果某个计数器的值为0,那么元素必定不在集合中;
- 某个元素通过k个散列函数映射到k个计数器,如果所有计数器的值都大于0,那么元素可能在集合中。

- 单机CountingBloomFilter的实现示例
- 引入依赖
<dependency> <groupId>org.apache.hadoopgroupId> <artifactId>hadoop-commonartifactId> <version>2.4.1version> dependency> - 实现代码
public class CountingBloomFilterDemo { public static void main(String[] args) { //预计数据的大小 int dataSize = 100000000; //hash函数的个数 int hashCount = 3; //使用的hash函数类型,0代表JenkinsHash,1代表MurmurHash int hashType = 1; //初始化一个CountingBloomFilter CountingBloomFilter filter = new CountingBloomFilter(dataSize,hashCount,hashType); //要put的数据 String data = "data01"; Key key = new Key(data.getBytes()); //将data put到CountingBloomFilter中 filter.add(key); //判断data是否存在 boolean exist = filter.membershipTest(key); //将data从CountingBloomFilter中删除 filter.delete(key); //判断data是否存在 filter.membershipTest(key); } }
- 引入依赖
3.2 CuckooFilter(布谷鸟过滤器)
- 概述
- 解决标准BloomFilter无法删除元素的问题;有更高的查询效率;相比其他支持删除的Filter更容易实现。
- 它源于布谷鸟哈希算法。
(1)布谷鸟哈希算法
- 数据结构:布谷鸟哈希表,它由一个桶数组组成,每个桶由一个数据项组成。
- 原理
- 每个插入项都有由哈希函数h1(x)和h2(x)确定的两个候选桶,查找过程会检查两个桶是否任意一个桶包含此项。
- 如果x的两个桶中任何一个是空的,则算法将x插入到该空桶中,插入完成;
- 如果两个桶都没有空间,项会选择一个候选桶,踢出去现有的项,并将此被踢出项重新插入到它的备用位置。这个过程可能会重复,直到找到一个空桶或达到最大位移次数。如果没有找到空桶,则认为此哈希表太满,则进行扩容和ReHash后,再次插入。
- 虽然布谷鸟哈希可能执行一系列重置,但其均摊插入时间为O(1)。

说明
- 图(a):将新项x插入到8个桶的哈希表中的示例,其中x可以放置在桶2或6中。
- 图(b):表示待插入x的两个桶都没有空间,随机选择了候选桶6,踢出现有项a,重新放置“a”触发了另一个重置,将现有的项“c”从桶4踢到桶1。
(2)布谷鸟过滤器
-
布谷鸟过滤器对布谷鸟哈希的改变
- 为了提高桶的利用率,使用多路哈希桶。
- 为了减少内存的使用,只存储元素的指纹信息。
-
布谷鸟过滤器的数据结构:由一个哈希表组成,哈希表由一个桶数组组成,其中一个桶可以有多个条目,每个条目存储一个指纹。
-
哈希计算两个候选桶索引的方案
- 问题:布谷鸟过滤器只存储指纹,因此无法恢复和重新哈希原始键以找到它们的替代位置;
- 解决:利用一种称为部分键布谷鸟哈希的技术,来根据其指纹导出一个项的备用位置。

-
插入
Algorithm 1: Insert(x)
f = fingerprint(x);
i1 = hash(x);
i2 = i1 ⊕ hash(f);
if bucket[i1] or bucket[i2] has an empty entry then
add f to that bucket;
return Done;
// must relocate existing items;
i = randomly pick i1 or i2;
for n = 0; n < MaxNumKicks; n++ do
randomly select an entry e from bucket[i];
swap f and the fingerprint stored in entry e;
i = i ⊕ hash(f);
if bucket[i] has an empty entry then
add f to bucket[i];
return Done;
// Hashtable is considered full;
return Failure;
- 查找:给定一个项x,算法首先根据公式 (1)计算x的指纹和两个候选桶。然后读取这两个桶:如果两个桶中的任何现有指纹匹配,则布谷鸟过滤器返回true,否则过滤器返回false。
Algorithm 2: Lookup(x)
f = fingerprint(x);
i1 = hash(x);
i2 = i1 ⊕ hash(f);
if bucket[i1] or bucket[i2] has f then
return True;
return False;
- 删除:它检查给定项的两个候选桶。如果任何桶中的指纹匹配,则从该桶中删除匹配指纹的一份副本。
- 注意:要安全地删除项x,必须事先插入它,否则删除非插入项可能会无意中删除碰巧共享相同指纹的不同项。这一要求也适用于所有其他支持删除的过滤器。
Algorithm 3: Delete(x)
f = fingerprint(x);
i1 = hash(x);
i2 = i1 ⊕ hash(f);
if bucket[i1] or bucket[i2] has f then
remove a copy of f from this bucket;
return True;
return False;
- 说明:CuckooFilter不能扩容。因为我们已经丢失了原值 x,则无法计算扩容后新的位置 hash(x)
(3)布谷鸟过滤器的实现
-
CockooFilter的Java单机版实现
- 引入依赖
<dependency> <groupId>com.github.mgunlogsongroupId> <artifactId>cuckoofilter4jartifactId> <version>1.0.2version> dependency> - 代码实现
public class CockooFilterDemo { public static void main(String[] args) { //要put的数据 String data = "data01"; //预计数据的大小 long dataSize = 100000000L; //初始化一个CuckooFilter CuckooFilter<String> filter = new CuckooFilter.Builder<String> (Funnels.stringFunnel(Charset.defaultCharset()), dataSize).build(); //将data put到CuckooFilter中 filter.put(data); //判断data是否存在 boolean exist = filter.mightContain(data); //将data从CuckooFilter中移除 filter.delete(data); } }
- 引入依赖
-
基于Redis的CockooFilter:Redis的module的形式同样支持CuckooFilter。和BloomFilter一样,Jedis也没有CuckooFilter的客户端api调用实现。下面是redis官网对支持CuckooFilter的操作说明。

-
基于Tair的CockooFilter:集团Tair RDB2.0支持高级数据结构中,同样包含CockooFilter。
- 引入依赖
<dependency> <groupId>com.taobao.rdbgroupId> <artifactId>rdb-client2artifactId> <version>2.5.0-hotkeyversion> dependency> - 代码实现
public class CockooFilterTairDemo { public static void main(String[] args) { RdbSmartApi rdbSmartApi = RdbSmartFactory.getClientManager("xxx"); rdbSmartApi.setPassWord("xxx"); rdbSmartApi.init(); //Bloom过滤器的名字 String filterName = "myBloomFilter"; //预计要插入的数据大小 Long size = 10000000L; //创建一个CuckooFilter String result = rdbSmartApi.sync().cfreserve(filterName.getBytes(),size); //创建成果,则返回OK if("OK".equals(result)){ String data = "permission"; //向BloomFilter中插入一条数据 boolean success = rdbSmartApi.sync().bfadd(filterName.getBytes(),data.getBytes()); if(success){ //exist为是否存在,根据BloomFiler的特点,若exist为false,则代表该data一定不存在 boolean exist = rdbSmartApi.sync().bfexists(filterName.getBytes(),data.getBytes()); //将data从CuckFilter中删除,这个歌功能BloomFilter是没有的 rdbSmartApi.sync().cfdel(filterName.getBytes(),data.getBytes()); } } } }
- 引入依赖
3.3 ScalableBloomFilter(可动态扩容的布隆过滤器)
-
概述
TairBloom是云redis企业版(Tair3.0)上自带的一个扩展数据结构,其采用redis module方式实现了一个可动态扩容的布隆过滤器(ScalableBloomFilter)。- TairBloom内部本质上是多层布隆过滤器(ScalableBloomFilter)的链式组合,只能执行插入、查询操作,无法执行删除操作。
- 它解决了标准布隆过滤器容量受限、无法动态扩容的问题;具有动态扩容的能力,可在容量不足或者false positive无法保证时进行自动动态扩容,业务无需担心容量问题;非常适合需要对大量数据进行高效去重的场景。
-
ScalableBloomFilter的思想:新建一个布隆过滤器,将多个布隆过滤器“组装”成一个布隆过滤器使用。 -
ScalableBloomFilter的原理

- 如图展示的就是一个
ScalableBloomFilter模型(下文简称SBF),该SBF一共包含BF0和BF1两层。 - 插入过程:只会向最后一层插入数据
- 最开始时,SBF只包含BF0这一层,插入了a、b、c三个元素。
- 这时,假设BF0已经无法保证用户设定的误判率,此时就需要进行扩容,因此新的一层BF1被创建并加入进来。后来的d、e、f元素都会被插入到BF1中。
- 同理,当BF1也无法满足该层事先设定的误判率时,新的一层BF2也将被加入进来,如此进行下去。
- 查询过程:由后向前
- 查询g这个元素是否在SBF中
- 先在BF1中进行查询。如果查询显示存在,则直接响应客户端;
- 如果查询显示不存在,则继续查询BF0。如果BF0中显示存在g,则响应客户端g存在。否则,因为BF0已经是最后一层了,则响应客户端g不存在。
- 如图展示的就是一个
-
说明:SBF的插入和查询过程比较简单。但是注意,首先,BF1在直观上要比BF0长很多(m比特位数高);其次,BF1上的散列函数k(哈希函数个数)也要比BF0上的大。
-
应用场景:非常适合推荐系统场景。文章阅读功能,如果想留住用户,就要尽可能给用户推荐他喜欢类型的文章,但是又不能推荐重复的文章(特别是用户最近刚读过的文章)。为此,将用户读过的文章加入到TairBloom中,并在推荐给用户之前,先去TairBloom中查询一下该用户是否读过该文章,如果读过就不推荐,否则就可以加入推荐列表。

参考资料
- 详解布隆过滤器的原理,使用场景和注意事项
- 布谷鸟过滤器:实际上优于布隆过滤器
- 布谷鸟哈希和布谷鸟过滤器
- 冷饭新炒:理解布隆过滤器算法的实现原理
- 缓存穿透、缓存击穿、缓存雪崩,看这篇就够了