阿里云天池学习赛之恶意程序检测(学习笔记)
1:构建的特征有
a:不同样本调用api,tid,index的频次信息
b:对数值字段采用mean,max,min等函数生成数值特征
c:对api调用tid的次数统计形成特征(采用pd.pivot_table)
d:对api调用不同tid的次数统计形成特征
注:对训练集和测试集中api种类统计发现不完全重合(有很大交集),因此,删除训练集中独有的三种api信息。并特征选取时采用训练集特征构建测试集的c和d类特征(这样对数据有一定的浪费)
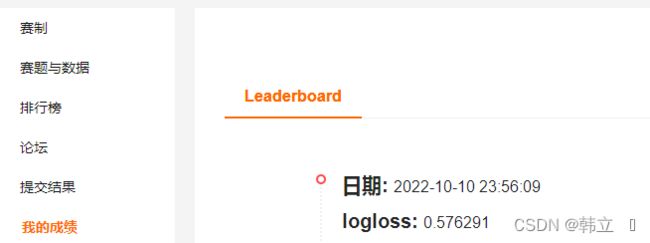
2:采用的算法:LGB(其它算法未怎么尝试,先练练手,熟悉流程)
代码如下
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from neicunyasuo import _Data_Preprocess
import lightgbm as lgb
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')
memory_process = _Data_Preprocess()
path = '../恶意程序检测分类/恶意程序数据/'
train = pd.read_csv(path + 'security_train.csv')
test = pd.read_csv(path + 'security_test.csv')
train = train[(train.api != 'EncryptMessage')&(train.api !='WSASendTo')&(train.api !='RtlCompressBuffer')].reset_index()
# {'EncryptMessage', 'WSASendTo', 'RtlCompressBuffer'}
# 反映样本调用api,tid,index的频率信息的特证
def simple_sts_features(df):
simple_fea = pd.DataFrame()
simple_fea['file_id'] = df['file_id'].unique()
simple_fea = simple_fea.sort_values('file_id')
df_grp = df.groupby('file_id')
simple_fea['file_id_api_count'] = df_grp['api'].count().values
simple_fea['file_id_api_nunique'] = df_grp['api'].nunique().values
simple_fea['file_id_tid_count'] = df_grp['tid'].count().values
simple_fea['file_id_tid_nunique'] = df_grp['tid'].nunique().values
simple_fea['file_id_index_count'] = df_grp['index'].count().values
simple_fea['file_id_index_nunique'] = df_grp['index'].nunique().values
return simple_fea
simple_train_fea1 = simple_sts_features(train)
simple_test_fea1 = simple_sts_features(test)
# 提取其数值特征
def simple_numerical_sts_features(df):
simple_numerical_fea = pd.DataFrame()
simple_numerical_fea['file_id'] = df['file_id'].unique()
simple_numerical_fea = simple_numerical_fea.sort_values('file_id')
df_grp = df.groupby('file_id')
simple_numerical_fea['file_id_tid_mean'] = df_grp['tid'].mean().values
simple_numerical_fea['file_id_tid_min'] = df_grp['tid'].min().values
simple_numerical_fea['file_id_tid_std'] = df_grp['tid'].std().values
simple_numerical_fea['file_id_tid_max'] = df_grp['tid'].max().values
simple_numerical_fea['file_id_index_mean'] = df_grp['index'].mean().values
simple_numerical_fea['file_id_index_min'] = df_grp['index'].min().values
simple_numerical_fea['file_id_index_std'] = df_grp['index'].std().values
simple_numerical_fea['file_id_index_max'] = df_grp['index'].max().values
return simple_numerical_fea
simple_train_fea2 = simple_numerical_sts_features(train)
simple_test_fea2 = simple_numerical_sts_features(test)
# 每个api调用线程的次数 高级特征:数据透视表运用
def api_pivot_count_features(df):
tmp = df.groupby(['file_id', 'api'])['tid'].count().to_frame('api_tid_count').reset_index()
tmp_pivot = pd.pivot_table(data=tmp, index = 'file_id', columns='api', values='api_tid_count', fill_value=0)
tmp_pivot.columns = [tmp_pivot.columns.names[0] + '_pivot_'+ str(col) for col in tmp_pivot.columns]
tmp_pivot.reset_index(inplace = True)
tmp_pivot = memory_process._memory_process(tmp_pivot)
return tmp_pivot
simple_train_fea3 = api_pivot_count_features(train)
simple_test_fea3 = api_pivot_count_features(test)
# 每个api调用不同线程的次数 高级特征
def api_pivot_nunique_features(df):
tmp = df.groupby(['file_id','api'])['tid'].nunique().to_frame('api_tid_nunique').reset_index()
tmp_pivot = pd.pivot_table(data=tmp,index = 'file_id',columns='api',values='api_tid_nunique',fill_value=0)
tmp_pivot.columns = [tmp_pivot.columns.names[0] + '_pivot_'+ str(col) for col in tmp_pivot.columns]
tmp_pivot.reset_index(inplace = True)
tmp_pivot = memory_process._memory_process(tmp_pivot)
return tmp_pivot
simple_train_fea4 = api_pivot_count_features(train)
simple_test_fea4 = api_pivot_count_features(test)
train_label = train[['file_id', 'label']].drop_duplicates(subset=['file_id', 'label'], keep='first')
test_submit = test[['file_id']].drop_duplicates(subset=['file_id'], keep='first')
# 训练集&测试集构建
train_data = train_label.merge(simple_train_fea1, on='file_id', how='left')
train_data = train_data.merge(simple_train_fea2, on='file_id', how='left')
train_data = train_data.merge(simple_train_fea3, on='file_id', how='left')
train_data = train_data.merge(simple_train_fea4, on='file_id', how='left')
test_submit = test_submit.merge(simple_test_fea1, on='file_id', how='left')
test_submit = test_submit.merge(simple_test_fea2, on='file_id', how='left')
test_submit = test_submit.merge(simple_test_fea3, on='file_id', how='left')
test_submit = test_submit.merge(simple_test_fea4, on='file_id', how='left')
train_features = [col for col in train_data.columns if col not in ['label', 'file_id']]
train_label = 'label'
from sklearn.model_selection import StratifiedKFold, KFold
params = {
'task': 'train',
'num_leaves': 255,
'objective': 'multiclass', # 多分类的意思
'num_class': 8, # 八分类
'min_data_in_leaf': 50,
'learning_rate': 0.05,
'feature_fraction': 0.85,
'bagging_fraction': 0.85,
'bagging_freq': 5,
'max_bin': 128,
'random_state': 100,
'metric': 'multi_logloss'
}
folds = KFold(n_splits=5, shuffle=True, random_state=15)
predict_res = 0
models = []
for fold_, (trn_idx, val_idx) in enumerate(folds.split(train_data)):
print("fold n°{}".format(fold_))
trn_data = lgb.Dataset(train_data.iloc[trn_idx][train_features], label=train_data.iloc[trn_idx][train_label].values)
val_data = lgb.Dataset(train_data.iloc[val_idx][train_features], label=train_data.iloc[val_idx][train_label].values)
clf = lgb.train(params, trn_data, num_boost_round=2000, valid_sets=[trn_data, val_data], verbose_eval=50,
early_stopping_rounds=100)
models.append(clf)
# 特征重要性分析
feature_importance = pd.DataFrame()
feature_importance['fea_name'] = train_features
feature_importance['fea_imp'] = clf.feature_importance()
feature_importance = feature_importance.sort_values('fea_imp', ascending=False)
feature_importance.sort_values('fea_imp', ascending=False)
plt.figure(figsize=[40, 20])
plt.figure(figsize=[40, 20])
sns.barplot(x = feature_importance.iloc[:10]['fea_name'], y = feature_importance.iloc[:10]['fea_imp'])
plt.show()
plt.figure(figsize=[40, 20])
sns.barplot(x = feature_importance['fea_name'], y = feature_importance['fea_imp'])
plt.show()
# 模型测试
pred_res = 0
fold = 5
for model in models:
pred_res +=model.predict(test_submit[train_features]) * 1.0 / fold
test_submit['prob0'] = 0
test_submit['prob1'] = 0
test_submit['prob2'] = 0
test_submit['prob3'] = 0
test_submit['prob4'] = 0
test_submit['prob5'] = 0
test_submit['prob6'] = 0
test_submit['prob7'] = 0
test_submit[['prob0','prob1','prob2','prob3','prob4','prob5','prob6','prob7']] = pred_res
test_submit[['file_id','prob0','prob1','prob2','prob3','prob4','prob5','prob6','prob7']].to_csv('baseline2.csv',index = None)
后续可改进的地方:采用其它算法,采用分层多折交叉验证等