Pytorch学习
Transformer的使用
ToTensor()
这个方法会把输入的 PIL Image 转换为 PyTorch 的 Tensor类型;ToTensor()将输入数据的值域从[0, 255]变为[0, 1],并且如果输入数据有颜色通道(比如RGB图像),那么会将其从(height, width, channel)的形状变为(channel, height, width)的形状
img_path = "datasets/train/ants/0013035.jpg"
# 返回一个 Image 对象
img = Image.open(img_path)
# transforms.ToTensor() 这个方法会把输入的 PIL Image转换为 PyTorch 的 Tensor
tensor_trans = transforms.ToTensor()
# 将一个image图片转化为tensor类型的图片
tensor_img = tensor_trans(img)- 通过tensorboard展示图片
# 创建了一个 SummaryWriter 对象并命名为 writer,传入的参数是日志文件的保存路径
writer = SummaryWriter("logs")
# 将一个图像数据(tensor_img)写入到 TensorBoard 日志中,并使用 "Tensor_img" 作为标签
writer.add_image("Tensor_img", tensor_img)Normalize对图象进行归一化处理
- ToTensor操作
trans_totensor = transforms.ToTensor() # 创建了一个转换对象
# 使用transforms.ToTensor()函数将图像转换为张量
img_tensor = trans_totensor(img)
writer.add_image("ToTensor", img_tensor)
# 使用SummaryWriter.add_image()函数将其添加到TensorBoard日志中- 归一化操作
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
# 使用transforms.Normalize()函数对图像进行归一化处理
# 该函数的第一个参数是一个长度为3的列表,其中包含每个通道的平均值。
# 第二个参数也是一个长度为3的列表,其中包含每个通道的标准差
img_norm = trans_norm(img_tensor)
# 将img_tensor张量传递给transforms.Normalize()函数,并将结果存储在img_norm张量中Resize
- PIL类型->PIL类型
trans_resize = transforms.Resize((200, 200)) # 不能超过图片本身的大小
# img(PIL类型) -> resize -> img_resize(PIL类型)
img_resize = trans_resize(img)- PIL类型->tensor类型
# img_resize(PIL类型) -> totensor -> img_resize(tensor类型)
img_resize = trans_totensor(img_resize)Compose
trans_resize_2 = transforms.Resize(250)
trans_compose = transforms.Compose([trans_resize_2, trans_totensor])
# 当我们将图像传递给这个 trans_compose 对象时,
# 它首先会通过 trans_resize_2 进行大小调整,然后再通过 trans_totensor 将图像转换为张量
# PIL -> PIL -> tensor(trans_totensor)
img_resize_2 = trans_compose(img)
# 将img张量传递给trans_compose()函数,并将结果存储在img_resize_2张量中RandomCrop
trans_random = transforms.RandomCrop(260)
# 从图像中随机裁剪出一个260x260的区域。这个随机裁剪的操作是可逆的,
# 也就是说,如果对裁剪后的图像进行相同的操作,可以恢复原始图像
trans_compose_2 = transforms.Compose([trans_random, trans_totensor])
for i in range(10):
img_crop = trans_compose_2(img)
# 在循环内,这行代码将原始图像img传递给trans_compose_2对象。
# trans_compose_2会先对图像进行随机裁剪,然后将其转换为张量
writer.add_image("RandomCrop", img_crop, i)Dataloader
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
1. "./dataset"是数据集的路径,表示将数据集存储在当前目录下的一个名为"dataset"的文件夹中。如果该文件夹不存在或者不包含CIFAR10的数据文件,将会自动下载并解压到这个文件夹下。注意这个路径可以是绝对路径也可以是相对路径。
2. train=False表示我们希望加载的是测试集而不是训练集。如果你想加载训练集,可以设置train=True。默认情况下,train参数为True。
3. transform=torchvision.transforms.ToTensor()表示我们对数据集中的图片应用ToTensor()转换
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=False, num_workers=0, drop_last=True)
# 数据源是之前创建的 test_data dataset=test_data
# batch_size指定每个批次中包含的数据样本数
# shuffle 指定是否对数据进行随机打乱,这里设置为 False,表示不进行打乱
# num_workers 指定用于数据加载的线程数,设置为0表示不使用多线程加载
# drop_last 指的是如果数据的长度不是batch_size的整数倍时,是否抛弃最后一批不完整的数据,这里设置为 True,表示抛弃测试数据集中图片target
img, target = test_data[0]
print(img.shape)
# torch.Size([3, 32, 32])指的是这是一个彩色图片(3通道),宽为32、高为32
print(target)
# 在CIFAR10数据集中,这将是一个0到9之间的整数,代表该图像属于的类别卷积操作
二维卷积操作
import torch
import torch.nn.functional as F
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
# 卷积核
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0],
])
input = torch.reshape(input, (1, 1, 5, 5))
# 第一个维度表示每批次图像的个数,第二个维度表示通道数,第三个和第四个维度表示高度和宽度
kernel = torch.reshape(kernel, (1, 1, 3, 3))
print(input.shape)
print(kernel.shape)
output = F.conv2d(input, kernel, stride=1)
print(output)
# tensor([[[[10, 12, 12],
# [18, 16, 16],
# [13, 9, 3]]]])
output2 = F.conv2d(input, kernel, stride=2)
# stride指的是卷积核上下左右每次移动的距离
print(output2)
# tensor([[[[10, 12],
# [13, 3]]]])
output3 = F.conv2d(input, kernel, stride=1, padding=1)
print(output3)
# padding指的是在输入数据的周围添加一圈零填充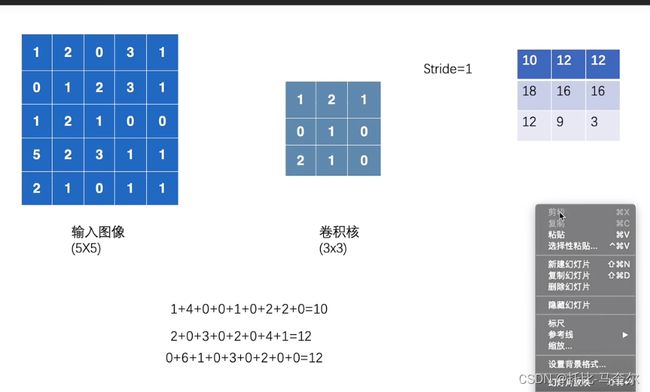
测试数据集的二维卷积操作
dataset = torchvision.datasets.CIFAR10("./data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# "./data"数据集的本地路径是用来存储CIFAR10数据集的
dataloader = DataLoader(dataset, batch_size=64)
# 使用了 DataLoader 类,该类可以将数据集分成多个小批次,以便在训练模型时进行批量处理
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
tudui = Tudui()
writer = SummaryWriter("./logs")
step = 0
for data in dataloader:
imgs, targets = data
output = tudui(imgs)
# torch.Size([64, 3, 32, 32])
print(imgs.shape)
# torch.Size([64, 6, 30, 30])
print(output.shape) # 经过卷积之后,图像的大小会变小,通道从3变为6
writer.add_images("input", imgs, step)
# torch.Size([64, 6, 30, 30])
# 其中6个channel没法显示,所以需要调用reshape()方法;同时因为out_channel改变,
# 所以batch_size也会随之改变,但是因为没法知道确切的batch_size大小,所以可以先设置为-1
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images("output", output, step)
step = step + 1二维卷积的注意事项
- in_channels: 输入图像的通道数(彩色图像一般都是三个通道)
out_channels: 通过卷积之后的通道数
kernel_size(int/tuple): 定义的是卷积核的大小,如果输入的是3的话,则生成的是3*3的卷积核。也可以输入一个不规则的元组。例如(1,2)
stride:进行卷积核时,横向或者纵向的步径大小;默认为kernel_size
padding:在进行卷积核时,是否需要对原图象的边缘进行填充。默认是0
padding_mode: 填充时的模式,默认是zeros。指的就是边缘填充的数据都为0
二维卷积的通道问题

最大池化
dilation:空洞卷积(卷积核的每一行的三个元素不是紧密相连的,中间有n个洞);默认值为1
ceil_mode: True,则向上取整;False则向下取整;默认是False
strides默认为kernel_size
最大池化不改变channel数
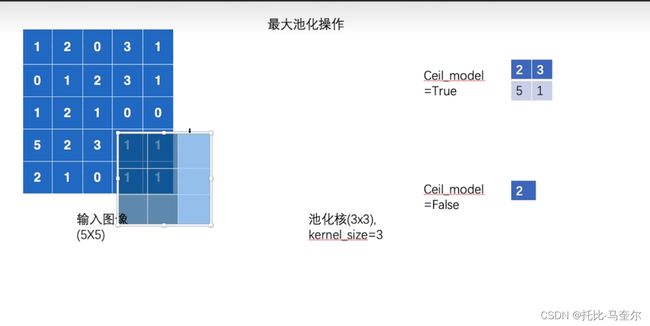
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]], dtype=torch.float32)
# dtype=torch.float32的操作使该张量中的所有元素都将是32位浮点数
input = torch.reshape(input, (-1, 1, 5, 5))
print(input.shape)
# torch.Size([1, 1, 5, 5])
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool1(input)
return output
tudui = Tudui()
output = tudui(input)
print(output)
# tensor([[[[2., 3.],
# [5., 1.]]]])
print(output.shape)
# torch.Size([1, 1, 2, 2])训练集(类似马赛克)操作
dataset = torchvision.datasets.CIFAR10("./data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool1(input)
return output
tudui = Tudui()
writer = SummaryWriter("logs_maxpool")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, step)
output = tudui(imgs)
writer.add_images("output", output, step)
step = step + 1
writer.close()
线性层Linear
dataset = torchvision.datasets.CIFAR10("./data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
# 创建一个新的全连接层,其中输入特征的数量为196608,输出的特征数量为10
self.linear1 = Linear(196608, 10)
def forward(self, input):
output = self.linear1(input)
return output
tudui = Tudui()
for data in dataloader:
imgs, targets = data
print(imgs.shape) # torch.Size([64, 3, 32, 32])
# output = torch.reshape(imgs, (1, 1, 1, -1))
# print(output.shape) # torch.Size([1, 1, 1, 196608])
# 将输入的imgs(假设它是一个多维的PyTorch张量)转换成一个一维的张量
output = torch.flatten(imgs)
print(output.shape) # torch.Size([196608])
output = tudui(output)
print(output.shape) # torch.Size([10])非线性激活
当数据小于零时,直接将其截断为0
input = torch.tensor([[1, -0.5],
[-1, 3]])
input = torch.reshape(input, (-1, 1, 2, 2))
print(input.shape)
# 定义了一个名为Tudui的新类,该类继承自nn.Module
class Tudui(nn.Module):
def __init__(self):
# 在子类中调用父类构造函数
super(Tudui, self).__init__()
# 创建一个ReLU对象并将其存储为该子类的成员变量
self.relu1 = ReLU()
# 神经网络的核心,定义了输入数据如何通过这个网络层产生输出
def forward(self, input):
# forward函数接收一个输入input,然后将其传递给self.relu1
output = self.relu1(input)
return output
tudui = Tudui()
output = tudui(input)
print(output)torch.Size([1, 1, 2, 2])
tensor([[[[1., 0.],
[0., 3.]]]])
训练集操作
dataset = torchvision.datasets.CIFAR10("./data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
# 定义了一个名为Tudui的新类,该类继承自nn.Module
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.relu1 = ReLU()
# Sigmoid类,它可能是一个实现了Sigmoid激活函数的类。
# 激活函数用于添加非线性特性,使得网络可以更好地学习和模拟复杂的数据分布。
self.sigmoid1 = Sigmoid()
def forward(self, input):
output = self.sigmoid1(input)
return output
tudui = Tudui()
writer = SummaryWriter("logs_relu")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, step)
output = tudui(imgs)
writer.add_images("output", output, step)
step = step + 1
writer.close()
Sequentia

import torch
from torch import nn
from torch.nn import Flatten, MaxPool2d, Conv2d, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
# 简化操作,并且按顺序进行操作
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
# self.conv1 = Conv2d(3, 32, 5, padding=2)
# # 为了保证第一步进行之后,图片的尺寸不变,所以需要修改默认的padding
# self.maxpool1 = MaxPool2d(2)
# # 最大池化不改变通道数
# self.conv2 = Conv2d(32, 32, 5, padding=2)
# self.maxpool2 = MaxPool2d(2)
# self.conv3 = Conv2d(32, 64, 5, padding=2)
# self.maxpool3 = MaxPool2d(2)
# self.flatten = Flatten()
# self.linear1 = Linear(1024, 64)
# self.linear2 = Linear(64, 10)
def forward(self, x):
x = self.model1(x)
# x = self.conv1(x)
# x = self.maxpool1(x)
# x = self.conv2(x)
# x = self.maxpool2(x)
# x = self.conv3(x)
# x = self.maxpool3(x)
# x = self.flatten(x)
# x = self.linear(x)
# x = self.linear2(x)
return x
tudui = Tudui()
print(tudui)
input = torch.ones((64, 3, 32, 32))
# 用于处理一批大小为64的RGB图像,每张图像的大小为32x32
output = tudui(input)
print(output.shape)
writer = SummaryWriter("./logs_seq")
writer.add_graph(tudui, input)
writer.close()
卷积操作中padding的计算公式

dilation默认为1
损失函数与反向传播
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
# 因为只能计算float类型,所以需要dtype=torch.float32对整型进行操作
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
loss = L1Loss()
result = loss(inputs, targets)
print(result) # tensor(0.6667)
loss = L1Loss(reduction='sum')
result = loss(inputs, targets)
print(result) # tensor(2.)
# 平方的差
loss_mse = MSELoss()
result = loss_mse(inputs, targets)
# ((1-1)+(2-2)+(3-5)^2)/3
print(result) # tensor(1.3333)
# 交叉熵
x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1]) # 代表目标值
x = torch.reshape(x, (1, 3))
# 1指的是batchsize,3指的是类别 一个batch里面包含1个样本,这个样本有三个类别的概率分布
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x, y)
print(result_cross) # tensor(1.1019)交叉熵

预测为人的概率为0.1,预测为狗的概率为0.2,预测为猫的概率为0.3
计算过程中是以e为底数的
优化器的选择与使用
dataset = torchvision.datasets.CIFAR10("./data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
# 观察怎么在神经网络中使用损失函数
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
# 简化操作,并且按顺序进行操作
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
tudui = Tudui()
# 1.首先定义一个优化器,这里使用的是随机梯度下降(SGD)作为优化算法
optim = torch.optim.SGD(tudui.parameters(), lr=0.01)
for epoch in range(20): # 进行多次学习
running_loss = 0.0
# 初始化运行损失为0,用于累计每次迭代的损失
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs, targets)
# 2.将网络中的每个参数的梯度全部设置为0
# 将网络中每个参数的梯度清零。这是为了确保每次只使用当前批次的梯度进行更新,不会混杂之前的梯度
optim.zero_grad()
# 3.反向传播;求出每个输出节点相对于模型参数的梯度
result_loss.backward()
# 4.对模型中的参数进行调优
optim.step()
# 将当前批次的损失累加到运行损失中,用于在epoch结束后统计总的损失
running_loss = running_loss + result_loss
print(running_loss)