深入理解Android图形系统(0.2)
学习方法论
写作原则
标题括号中的数字代表完成度与完善度
0.0-1.0 代表完成度,1.1-1.5 代表完善度
0.0 :还没开始写
0.1 :写了一个简介
0.3 :写了一小部分内容
0.5 :写了一半内容
0.9 :还有个别内容没写
1.0 :内容都写完了,但是不一定完善
1.1 :内容比较完善
1.3 :内容很完善
1.5 :内容非常完善,接近完美
目录
- 一、图形系统简介
-
- 1.1 图形系统的诞生
- 1.2 图形系统的总体结构
- 1.3 图形系统的各层职能
- 二、安卓图形系统
-
- 2.1 框架概览
- 2.2 渲染系统概览
- 2.3 窗口系统概览
- 2.4 显示系统概览
- 三、生产者消费者模型
-
- 3.1 概览
- 3.2 BufferQueue
- 3.3 显存分配与同步
- 3.4 生产消费流程
- 四、渲染系统
-
- 4.1 2D渲染
- 4.2 3D渲染
- 4.3 控件库
- 五、窗口系统
-
- 5.1 框架概览
- 5.2 窗口管理器
- 5.3 合成管理器
- 5.4 硬件合成
- 六、显示系统
-
- 6.1 DRM驱动模型
- 6.2 Display硬件结构
- 6.3 DRM 软件结构
- 6.4 DRM 实现
- 七、总结回顾
推荐阅读: 操作系统导论
一、图形系统简介
图形系统是计算机中最重要的子系统之一。我们平时使用的电脑、手机都是图形界面的。对于普通人来说,没有图形界面的计算机几乎是没法用的,今天我们就来讲一讲图形系统背后的原理。
1.1 图形系统的诞生
早期的计算机是没有图形界面的,都是命令行界面。大家坐在终端前面输入命令、执行命令、等待命令完成,如此循环往复。这样的计算机比较适合科研人员、理工男使用,但是想要普及到千家万户是不可能的。后来施乐公司帕克研究中心(Xerox Palo Alto Research Center,Xerox PARC)率先研究出了图形界面的计算机,提出了WIMP的概念。WIMP就是Window(窗口)、Icon(图标)、Menu(菜单)、Pointer(指针/鼠标)。我们现在的计算机仍然是WIMP模式的。可惜施乐公司并没有把图形界面的计算机做起来,而是被乔布斯和比尔盖茨发扬光大了。乔布斯去参观帕克研究中心的时候,被他们所展示的图形界面惊呆了,回去之后立马在自己公司做起了图形界面的操作系统。比尔盖茨发现苹果的图形界面确实不错,也开始自己做图形界面,于是便有了Windows系统。后来苹果和微软因为图形界面的问题还打起了官司。
1.2 图形系统的总体结构
图形模式与命令行模式相比,编程模式和软件结构都发生了很大的变化。在命令行模式的时候,程序员只需要考虑程序本身的流程,然后通过标准输入输出和终端打交道就可以了。但是到了图形模式的时候,一切都变了。程序员首先要考虑是如何绘制程序的界面,然后再通过消息循环对程序的点击等各种事件进行处理。不仅程序员编程的模式变了,操作系统实现的方式也发生了很大的变化。命令行模式下,操作系统只需要提供一个shell,shell不断地读取命令、执行命令就可以了。但是在图形模式下,操作系统首先要提供一个桌面,作为用户使用电脑的起点,还要提供文件管理器,方便用户查看管理文件。对程序员来说,操作系统还要提供图形编程接口,提供渲染库,还要负责对所有的窗口进行合成和显示。于是在操作系统里面便诞生了一个重要又庞大的子系统,图形系统。根据前面几句的描述,我们先来看一下图形系统的简单结构。
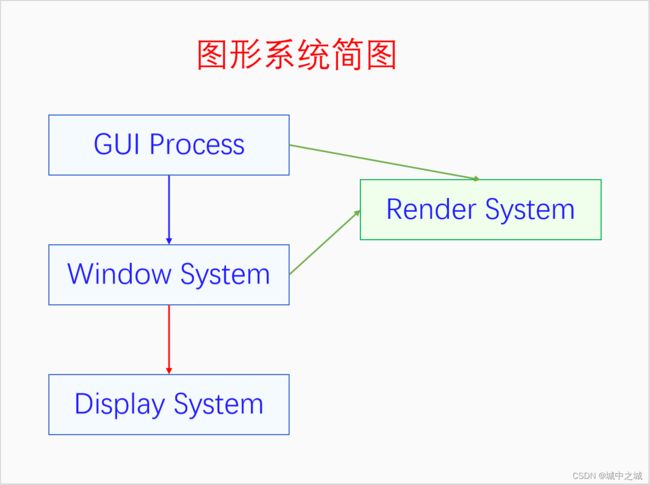
可以看到图形系统的总体结构还挺简单的,GUI进程需要窗口系统来创建和管理窗口,需要渲染系统来帮忙绘制界面,最后让显示系统把画面显示到显示器上。
1.3 图形系统的各层职能
知道了图形系统的总体结构,我们再来详细描述一下各层的职能。
窗口系统一般以进程的方式运行在用户空间,我们把它的进程叫做DisplayServer。窗口系统有两个职责:一是窗口管理器,负责窗口的创建、缩放、销毁等工作;二是合成管理器,负责把各个GUI进程绘制完成之后的窗口合成为一个位图,然后送到显示系统去显示。
渲染系统是以so库的形式存在,被加载到每个GUI进程的内存空间中。渲染系统负责执行GUI进程的绘制命令,在窗口的显示Buffer上生成相应的位图。渲染分为2D渲染和3D渲染,2D渲染一般用CPU来执行,3D渲染一般用GPU来执行。但是现在经常也将2D渲染用GPU来做。不过很多普通程序并不是直接使用渲染库的,而是使用的控件库,因为直接使用渲染库太麻烦了。比如我们要画一个按钮,用渲染库API来画的话是非常麻烦的,但是使用控件库API的话,我们只需要指定位置、大小、样式等属性就可以轻松画一个按钮。
显示系统是以驱动的形式存在于内核中,驱动是屏幕控制器的驱动或者DPU的驱动。显示系统的作用就是把所有窗口形成的一个位图在显示器上显示。早期的显示驱动模型是FBDEV,它针对的是屏幕控制器,屏幕控制器没有运算能力,只能接收窗口系统已经合成好的位图来显示。此时窗口系统的合成管理器会使用渲染系统来合成各个窗口的位图,合成也可以看出是一种特殊的渲染。后来屏幕控制器逐渐发展成了DPU,具有了运算能力,能进行合成操作。此时也诞生了新的显示驱动模型DRM,DRM允许窗口系统不进行合成操作,而是把各个窗口的显存都发给自己,通过DPU进行合成操作,然后再送到显示器显示。
二、安卓图形系统
Android是目前最流行的移动操作系统之一,我们今天就来具体分析一下Android的图形系统。
2.1 框架概览
在讲Android之前,我们先来看一下Linux发行版的图形系统。由于Android的内核也是Linux,所以它们的显示系统是一样的。Linux的渲染系统用的是OpenGL,以及最新的Vulkan,控件库用的是GTK(GNOME)或者Qt(KDE)。Linux的窗口系统历史悠久且复杂,可以追述到UNIX时代。这里我们就不展开说了,我们直接说现状。在Linux上,窗口系统的协议和实现是明确分开的,Linux长期使用的窗口协议叫做X Window,实现是X.org。不过由于X Window太过古老,很多设计都不符合现状的情况,还有沉重的历史包袱。因此有人设计了新的窗口的协议Wayland,Wayland最流行的实现叫做Weston。现在大部分Linux发行版已经开始转向Wayland/Weston了。
了解了Linux发行版的图形体系,我们再来看一下Android的图形体系。

Android的图形系统并没有明确的协议,实现既协议。这是因为Linux系统是标准的开源系统,很多事情都喜欢先定个协议,然后谁都可以实现这个协议。而Android虽然也开源,但是它是由谷歌直接实现的,其它厂商拿来用,所以没有必要定个协议。Android的图形系统在具体细节上和Linux的图形系统差别还是很大的,这是因为Linux图形系统面向的是桌面系统,Android图形系统面向的是移动系统,两者的使用环境不同,开发环境不同,导致了具体的实现细节也不相同。其中一个最大的不同就是Android图形系统中没有典型的窗口概念。在其它窗口系统中,一般都会有个CreateWindow的接口用来创建一个窗口,返回值是窗口句柄,然后我们就可以用这个窗口句柄来做其它事了。但是在Android中,不是这样的逻辑,窗口的概念被隐藏并分散在具体的实现中去了,程序员面对的是Activity和View、ViewGroup。下面几个小节会对Android图形系统的各个部分进行介绍。
2.2 渲染系统概览
Android中一开始用的是OpenGL ES进行3D渲染,用skia进行2D 软件渲染。后来为了优化2D渲染,开发了hwui进行硬件渲染,hwui是对OpenGL ES的封装。再后来变成了hwui调用skia,skia对OpenGL ES进行了封装来进行硬件渲染,当然skia也保留了软件渲染部分。下面我们看一下图。
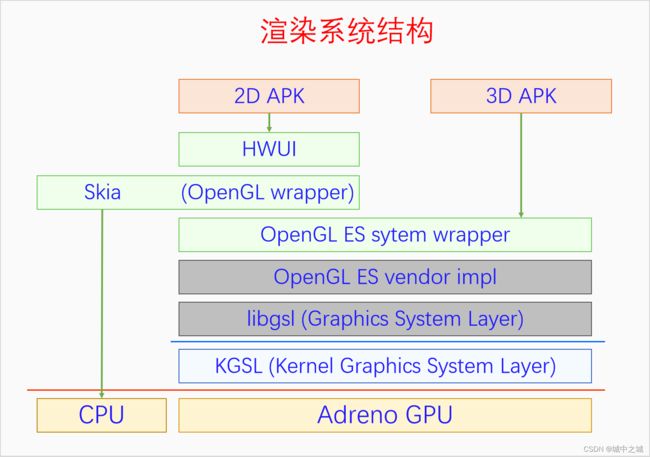
OpenGL ES system wrapper是系统提供的标准接口库,它的so位置是固定的,方便程序加载,其接口是标准规定的接口,方便程序使用。不过它本身没有任何实现逻辑,所有的实现逻辑都在GPU厂商提供的不开源的库里面。
普通APK并不会直接使用这些渲染库,而是使用的系统提供的控件库。Android提供的控件大部分都在package android.view 和android.widget中。
2.3 窗口系统概览
窗口系统有两个职责,窗口管理器和合成管理器。在Android中这两者并不在一起,窗口管理器是在system_server进程中实现,名字叫做WindowManagerService(WMS),是用Java语言实现的,因为system_server就是Java进程。Android为什么要把WindowManagerService放在system_server中实现呢?这是system_server中有ActivityManagerService(AMS),两者的关系比较密切,放在一起比较合适。合成管理器是在一个独立进程中实现的,叫做SurfaceFlinger。最开始的时候SurfaceFlinger是直接进行合成的,后来由于硬件合成的兴起,SurfaceFlinger不再直接进行合成操作了,而是把合成操作转发给底层。WindowManagerService和SurfaceFlinger之间使用Binder进程间通信来交互。下面我们来看一下图:
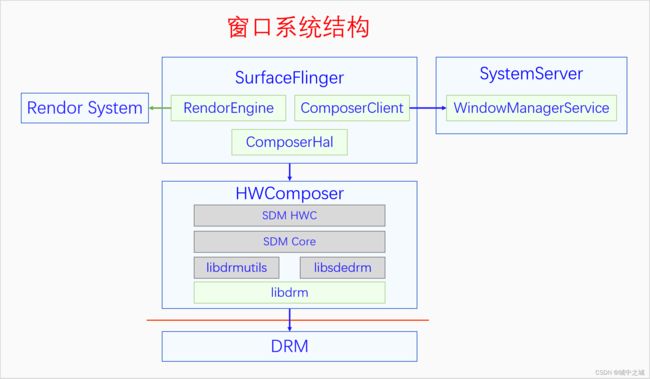
谷歌推出了叫做HWC(硬件合成器)的模块,用来处理硬件合成。刚开始的时候HWC只是个so库,运行在SurfaceFlinger进程中,后来HWC独立成单独的进程了。在HWC中有很多厂商提供的不开源和半开源的库。
这个图里面没有画和APK之间的交互。窗口系统和APK之间的交互有两部分,一是程序在创建Activity的时候会和WMS交互来创建窗口。Android里面没有典型的窗口概念,可以把PhoneWindow、DecorView、ViewRootImpl、Surface糅合在一起当做窗口的概念。还有一部分没有画,是APK的渲染与SurfaceFlinger合成之间的生产者消费者关系,这个逻辑在下一章里讲。
想要深入地学习AMS,推荐阅读老罗的Android之旅中的WMS篇:https://blog.csdn.net/Luoshengyang/article/details/8462738
,以及袁辉辉写的WMS分析:http://gityuan.com/2017/01/08/windowmanger/
2.4 显示系统概览
显示系统直接和屏幕相关,属于内核里的驱动。内核一般对任一类型的硬件都会有个驱动模型,所有的硬件厂商都在这个硬件模型上开发驱动。最早对显示器抽象出来的驱动模型叫做FBDEV,后来随着硬件和软件的发展,又诞生了新的驱动模型DRM。现在大部分系统都转向DRM了,所有我们这里讲一下DRM。先画个图看一下:
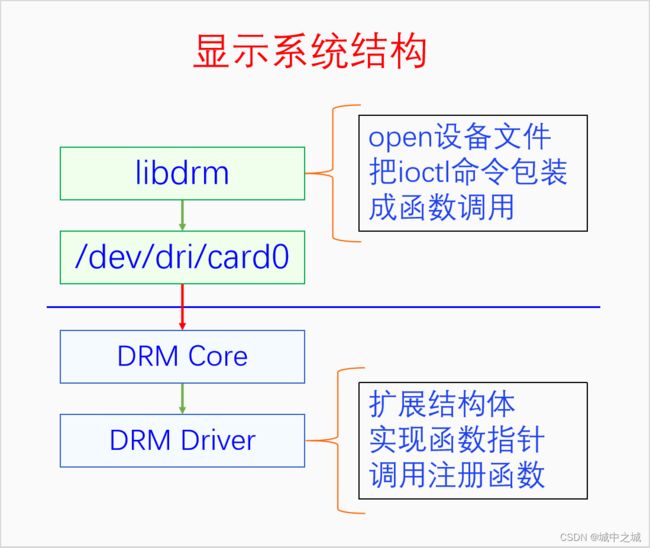
这个结构其实也是很多驱动的结构。内核定义并实现了DRM Core,硬件厂商按照DRM Core的要求扩展结构体,实现函数指针,然后调用注册函数注册自己。在用户空间使用的硬件会创建一个设备文件,用户空间可以open设备文件,用ioctl来调用各种命令,ioctl的命令是Core定义好的,具体的驱动要去实现这些命令。用户空间直接使用ioctl命令还是比较麻烦的,所以还会有一个libdrm库,用来封装各种ioctl命令,转化为函数接口,这样进程使用就比较方便了。关于DRM的具体细节我们在第六章中讲。
三、生产者消费者模型
在讲渲染与合成之前,我们先来讲一讲它们之间的关系以及它们交互的流程。
3.1 概览
渲染与合成是生产者消费者关系,那么它们之间是怎么交互的呢?Android实现了一个生产者消费者模型BufferQueue,生成者与消费者通过BufferQueue来交互。BufferQueue管理的是GraphicBuffer,生产者渲染的内容要放到GraphicBuffer上,消费者合成内容的来源来自GraphicBuffer。GraphicBuffer通过谷歌定义的Hidl接口Gralloc来分配内存,Gralloc又通过ION分配内存。ION是建立在DMA-BUF的基础之上的跨空间跨设备的内存分配方法。为了加快生产消费的流程,BufferQueue可以采取异步的模式,异步的时候就需要进行步调同步了,为此采取的办法是Fence。Fence是一种跨空间跨设备的同步机制。跨空间的意思是指进程与进程之间、内核与用户空间之间,跨设备指的是两个设备的驱动之间或者驱动与进程之间。下面我们画个图看一下它们的总体关系。
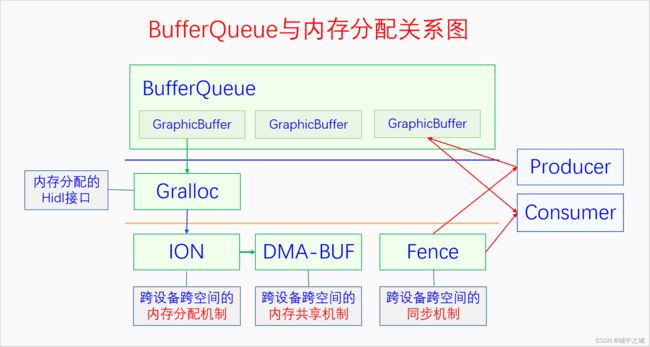
3.2 BufferQueue
BufferQueue是Android中对渲染与合成这一对生产消费关系模型的实现。我们先来看BufferQueue的使用方法。
void BufferQueue::createBufferQueue(sp<IGraphicBufferProducer>* outProducer,
sp<IGraphicBufferConsumer>* outConsumer)
{
sp<BufferQueueCore> core(new BufferQueueCore());
sp<IGraphicBufferProducer> producer(new BufferQueueProducer(core));
sp<IGraphicBufferConsumer> consumer(new BufferQueueConsumer(core));
*outProducer = producer;
*outConsumer = consumer;
}
可以看到创建一个BufferQueue就是创建一个BufferQueueCore,然后以这个core为参数分别创建生产者基础接口和消费者基础接口。一般情况下都是在消费者进程中创建的BufferQueue,然后把生产者接口用Binder跨进程传递给生产者进程。当然也可以反过来,也可以两者都跨进程,也可以两者都不跨进程。之所以大部分情况下选择在消费者进程中创建BufferQueue,是为了想让消费者准备好,然后生产者一生成就可以立马得到消费了。
一般情况下我们并不会直接使用原始的生产者或者消费者接口,而是会对它们进行层层封装,封装之后的接口就比较方便使用了。下面我们看一下它的封装逻辑图。
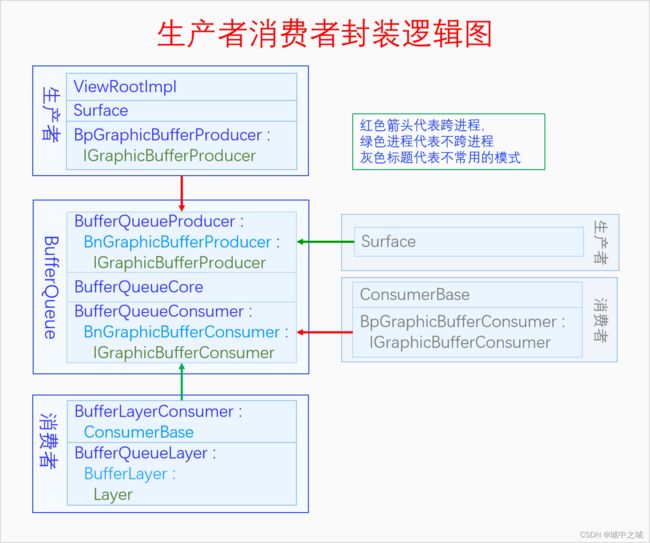
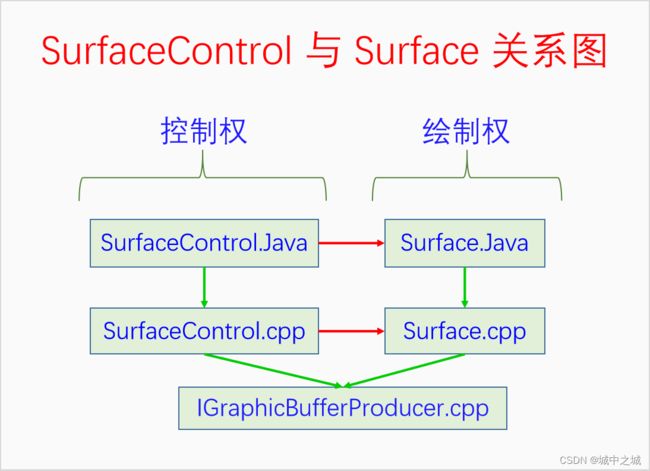
这个图画的是APK与SurfaceFlinger对BufferQueue的使用情况。可以看到对原始生产者接口的封装一般都是Surface,但是我们也会经常在代码中看到SurfaceControl,这是怎么回事呢?这是为了完成控制权与绘制权的分离。APK启动的时候会去请求WMS创建窗口也就是Surface,WMS再去请求SurfaceFlinger创建BufferQueue,并获得其原始生产者接口。WMS自身把原始生产者封装为SurfaceControl,以便对Surface进行控制。然后又把原始生产者封装为Surface传递给APK,这样APK就只有绘制权了。APK如果想设置Surface的属性,还得请求WMS的帮忙。下面画个图看一下:
下面我们再看一下BufferQueue的内部管理逻辑。BufferQueue管理的是GraphicBuffer,但又不是直接管理的GraphicBuffer,而是定义了BufferSlot结构体。BufferSlot包含对GraphicBuffer的智能指针应用和对Fence的智能指针引用,以及BufferState。BufferQueueCore包含一个BufferSlot的数组,有64个元素,由于BufferSlot内部都是智能指针引用,所以它一开始都是空的,只有用到了才会分配。BufferQueue在管理BufferSlot的时候并不会直接去操作它们,而是会管理它们的下标。下面我们画个图看一下。

BufferQueue用4个整数容器来管理BufferSlot,BufferSlot的下标放在不同的容器中有不同的含义。首先是BufferQueue硬编码定义的64是all slots,当创建BufferQueue之后我们可以使用接口函数来设置我们要用多少个Buffer,不用的下标就会被放置在容器mUnusedSlots中,使用的下标就会被放置在容器mFreeSlots中。然后当我们使用某个Buffer的时候,无论是生产者使用还是消费者使用,都会把它的下标放入容器mActiveBuffers中去。当消费者使用完一个Buffer的时候又会把它放入容器mFreeBuffers中去。mFreeBuffers和mFreeSlots的区别是前者的BufferSlot已经关联上GraphicBuffer了,而后者仅仅是一个空的slot。Buffer的状态变迁我们在3.4节中讲。
3.3 显存分配与同步
当我们第一次使用BufferSlot的时候就会去分配GraphicBuffer,那么GraphicBuffer又是怎么样分配内存的呢?GraphicBuffer会通过谷歌定义的Gralloc接口来分配内存。Gralloc接口又是通过两个Hidl接口IAllocator和IMapper来实现的。下面我们画图来看一下。


可以看到最终分配内存的方法是ION。ION是一种跨空间跨设备的内存分配方法,ION是基于DMA-BUF的,我们先来说一下DMA-BUF。
DMA-BUF是一种跨空间跨设备的内存共享机制,它仅仅是一个框架,并不能分配内存。DMA-BUF既不是DMA也不是BUF,而是Sharing。DMA-BUF定义了两个角色:Exporter(导出者),负责分配内存,一个体系中只能存在一个导出者;Importer(导入者),也叫User,负责使用内存,可以有N个,一般有两个,一个写,既生产者,一个读,既消费者。下面我们画图来看一下:
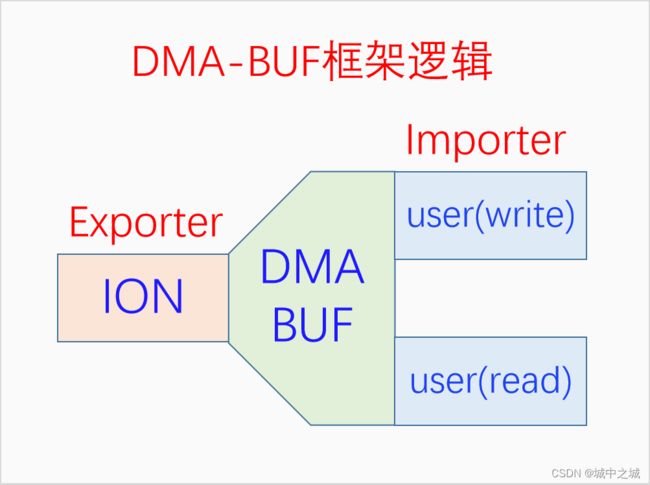
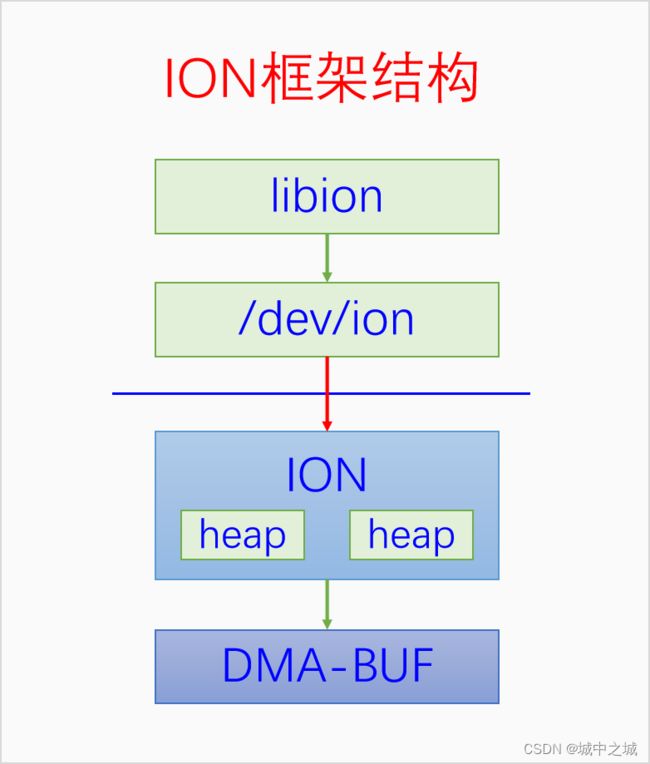
明白了DMA-BUF,我们再来看一下ION。ION是建立在DMA-BUF的基础之上的,ION能够在进程之间、进程和内核之间、设备之间共享内存都归功于DMA-BUF。ION自身有许多heap,不同的heap用来分配不同类型的内存,ION默认使用system heap。内核里的代码可以直接使用ION的接口,为了让用户空间也能使用ION,ION创建了一个设备文件/dev/ion。用户空间可以用各种ioctl命令来使用ION,显然这不太方便,于是产生了libion来帮助大家方便地使用ION。总结一下,如下图所示:
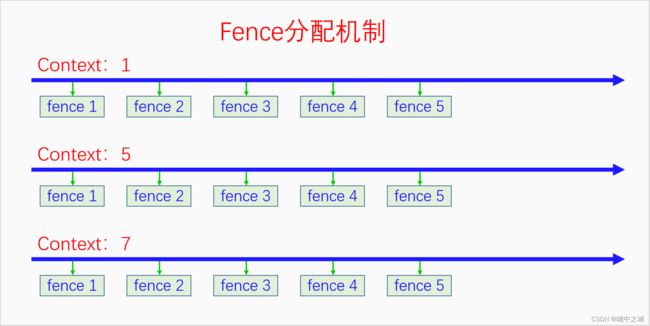
GraphicBuffer的内存分配完成之后,就可以用来渲染和合成了。但是我们现在只能进行同步操作,而GPU的渲染是异步,为了能提高性能,我们需要一种异步使用下的等待通知机制。为此内核中实现了Fence,它主要是给DMA-BUF用的,所以它也是一种跨空间跨设备的机制。因此,Fence是一种跨设备跨空间的wait/notify机制,它和Java中的wait/notify、C++中条件变量的wait/signal的语义是一样的,不同的是,Java、C++中的机制只能在进程内使用。Fence还有一个很大的特点就是它的notify信号不会丢失,这是因为Fence是一次性的,用完就扔,每次使用都需要重新申请一个,不能复用,因此Fence都是有编号的。Fence不仅有编号,还有context,不同的场景都可以创建context。同一个context下的fence编号是有可比较性的,编号小的时间在前。不同context下的fence编号不具有可比较性。下面我们画图来看一下。
3.4 生产消费流程
明白了前面的知识之后,我们就要来看一看生产消费的具体流程了。我们先来看一下BufferSlot的状态变迁,BufferSlot的状态变化是和生产消费的流程相关的。我们先看图再来解说。

一个BufferSlot最初是处于Free状态的,当生产者准备生产的时候,会先dequeueBuffer,此时就会得到BufferSlot,BufferSlot的状态也会变为Dequeued。得到的BufferSlot如果之前是空的slot,就会去分配内存,流程在上一节中说过了,如果是已经分配内存的slot则直接使用。然后生产者开始生产,把生产的内存都放到GraphicBuffer中去。当生产完成时就会调用queueBuffer,以告诉消费者我生产完了,你可以开始消费了。queueBuffer之后,BufferSlot的状态就由Dequeue转变为Queued。此时的GraphicBuffer会被封装为一个BufferItem结构体,放入mQueue队列中。消费者得到消息后就要准备消费了。消费者先acquireBuffer,从mQueue队列中获取一个BufferItem,其对应的BufferSlot的状态就转化为Acquired了。然后消费者就可以开始消费了,当消费完成的时候,会调用releaseBuffer表明自己消费完成,把BufferSlot还给BufferQueue,此时BufferSlot的状态就回归Free了。
明白了BufferSlot的状态变化以及生成消费的基本流程之后,我们再来看一下,在VSync下,在有Fence的情况下,生成消费的流程。我们先看图:

首先渲染和合成是两个独立的线程,两者是同时进行的,双方都是在收到VSync信号时开始执行的。其次渲染和合成都分别有一个额外的线程来进行异步渲染与合成,不会阻塞主流线程。主流线程没有阻塞操作,不会卡住,两个异步线程都在等Fence信号,有可能会卡住。当某个异步线程一直卡住的时候,比如说合成线程卡住了,会导致渲染线程一直在wait Fence信号也会卡住,但是主线程还能继续运行。
四、渲染系统
暂略
4.1 2D渲染
4.2 3D渲染
4.3 控件库
五、窗口系统
暂略
5.1 框架概览
5.2 窗口管理器
5.3 合成管理器
5.4 硬件合成
六、显示系统
现在大部分系统都不在DisplayServer中使用软件合成了,而是在DRM中进行硬件合成。主要是因为DPU有了运算能力,用DPU做合成效率更高。下面我们看一下DRM是怎么对DPU进行抽象的。
6.1 DRM驱动模型
DRM驱动模型把DPU分成四个部分,首先是Plane,代表一个合成来源或者说一个Surface,Plane是通过关联一个framebuffer(这个framebuffer仅仅是个结构体),framebuffer又被用户空间关联到具体的Surface的GraphicBuffer上。多个Plane连接到一个CRTC上,CRTC负责合成。合成之后再把数据送给Encode进行编码,编码之后通过Connector送到显示器上。如下图所示:

6.2 Display硬件结构
下面是一个具体的DPU和屏幕模组的硬件结构,和DRM基本是一致的。

6.3 DRM 软件结构
暂略
6.4 DRM 实现
暂略
七、总结回顾
通过本文我们对Android的图形系统有了基本的了解,对图形渲染与合成这一对生产者消费者模型也有了大概的认知。下面让我们看图再来回顾一下:
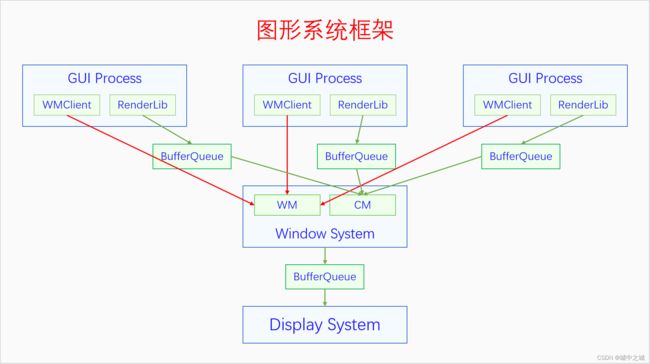 图形系统由渲染系统、窗口系统、显示系统三部分组成,渲染系统负责帮助GUI进程实现界面的绘制,窗口系统负责为GUI进程分配窗口、管理窗口并对所有的Surface进行合成,显示系统负责把合成的画面送到显示器里去显示。现在硬件合成比较流行,窗口系统都是把图形合成的任务交给显示系统通过硬件来完成。
图形系统由渲染系统、窗口系统、显示系统三部分组成,渲染系统负责帮助GUI进程实现界面的绘制,窗口系统负责为GUI进程分配窗口、管理窗口并对所有的Surface进行合成,显示系统负责把合成的画面送到显示器里去显示。现在硬件合成比较流行,窗口系统都是把图形合成的任务交给显示系统通过硬件来完成。
参考文献:
https://blog.csdn.net/hexiaolong2009/category_9281458.html
https://blog.csdn.net/hexiaolong2009/category_9705063.html
https://blog.csdn.net/hexiaolong2009/category_10331964.html
http://www.wowotech.net/sort/graphic_subsystem