MP-SPDZ详细介绍
基础知识概述
隐私计算底层协议包括两种:其一是基础的加密传输协议,用于信息分发,包括不经意传输、秘密分享、同态加密、零知识证明等。其二是加密计算协议,包括乱码电路、同态加密、零知识证明等。
- 不经意传输是所有隐私计算协议的基础,是基本的两方加密协议,用于n选m数据的加密传输。
- 秘密共享是一种多用于组织间秘密数据的共享与保护,比如多组织间共享密钥的加密存储,是隐私计算的基础协议之一。经典的秘密分享算法有Shamir门限秘密共享方案。
- 乱码电路通过加密来掩盖电路的输入和电路的结构,以此来实现各个参数参与者的隐私信息的保密,再通过电路计算来实现安全多方计算的目标函数计算。乱码电路有布尔电路和算术电路两种。算术电路适用于整数的加法和乘法,二进制电路比较适合比较等。布尔电路通过与门、或门、非门来模拟任意的函数(加法、乘法、比较);算术电路直接进行加法、乘法运算,也可以构造比较器。常见的乱码电路协议有:姚氏乱码电路(姚氏GC,或姚氏混淆电路)、GMW、BGW、BMR、SPDZ等。
- 同态加密是指对加密数据进行加减、乘除运算。分为半同态、类同态、全同态。其中半同态是仅支持一种密文运算(有限次的同态加或有限次的同态乘)。类同态同时支持有限的同态加和有限的同态乘。全同态加密支持任意形式的加密运算。半同态加密算法常用的算法有Paillier算法。目前主流的全同态加密算法包括BGV方案、BFV方案和CKKS方案等。
- 零知识证明指证明者能够在不向验证者提供任何有用信息的情况下,使验证者相信某个论断是正确的,允许证明者、验证者证明某个提议的真实性,却不必泄露除了“提议是真实的”之外的其他信息。常见的零知识证明有交互式零知识证明和非交互式零知识证明。非交互式零知识证明最典型的是zkSNARK(zero-knowledge Sucinct Noninteractive ARguments of Knowledge)技术。zkSNARK的基础是算术电路。
MP-SPDZ项目介绍
从开源的代码完整度、功能、性能、安全性等多方面进行对比,最后选定MP-SPDZ作为隐私计算演示平台实现方案。
基本介绍
MP-SPDZ是SPDZ-2(Keller等人,CCS’13)的分支,SPDZ是多方计算(MPC)协议SPDZ(Damgård等人,Crypto’12)的实现。MP-SPDZ将SPDZ-2扩展到了34种MPC协议,所有这些协议都可以用同一个基于Python的高级编程接口来使用。这大大简化了不同协议和安全模型的成本比较。这些协议涵盖了所有常用的安全模型(诚实/不诚实的多数人和半诚实/恶意模型),以及二进制和算术电路的计算(后者的模数为素数和二次幂)。所采用的基本基元包括秘密共享、不经意传输、同态加密和混淆电路。参考论文《MP-SPDZ-A Versatile Framework for Multi-Party Computation》。
架构设计
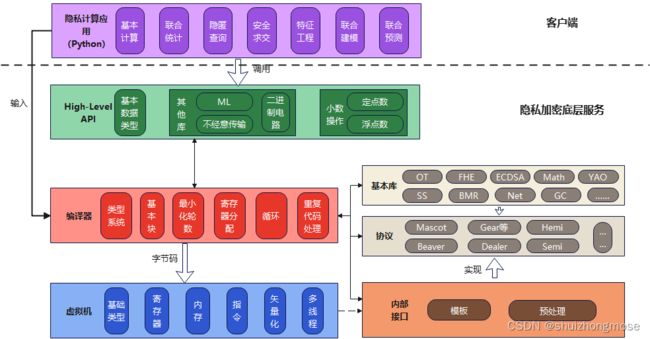
图 MP-SPDZ 项目架构图
虚拟机VM
MP-SPDZ虚拟机代码见【MP-SPDZ/Processor】目录。
多方安全计算虚拟机的主要特点是涉及通信的指令允许参数数量不受限制,从而最大限度地减少通信轮数。因为在多方安全计算中,份额的加法和乘法之间不仅存在数量上的差异,而且存在质量上的差异。因此前者可以在本地完成,而后者涉及通信。这种质的差异具有因协议而异的含义,由于网络延迟,不受限制的并行化通信的好处是显而易见的。
MP-SPDZ使用时需要明确指定类型,因为每个计算域中数字的大小是不同的。
MP-SPDZ的虚拟机为每种基本数据类型提供无限数量的寄存器。寄存器编号被硬编码到字节码中。寄存器通常用于存储指令的输入和输出,他们是本地线程的。
MP-SPDZ内存供数组、矩阵和高维结构使用。内存阵列是全局的,因此运行线程之间传递消息。与寄存器不同,可以使用存储器在整数寄存器中的运行时值来访问内存。内存必须在编译时分配。
MP-SPDZ提供以下几种指令类型:拷贝,基本计算(加、减、乘、除、移位等线性运算),安全指令(比如私有输入、乘法,公共输出等),预处理信息,控制流,高级输入输出(比如打印、客户端通信等),协议信息(比如获取计算方数量等)等。
MP-SPDZ提供矢量化功能,意味着根据请求对能尽可能多地连续寄存器执行相同的操作。这大大减少编译期间和执行期间表示重复计算的的开销。矢量化还有助于将值结构化地连续加载到寄存器中
MP-SPDZ提供多线程功能,但是要求最大线程数在编译时就知道,所以线程数必须使用常量指定。
Compiler
Compiler作用是将使用Python编写的隐私计算应用代码编译为虚拟机可以执行的字节码。
MP-SPDZ 遵循 Python 的动态类型范式。 这使得编程更加直观,例如,任何涉及秘密和公共值的操作都会产生秘密值。
基本块。 这个概念取自一般编译器设计,表示没有分支的指令序列。 编译器仅在基本块的上下文中执行最小化优化,因为它需要重新排列指令。
MP-SPDZ与SPDZ-2的区别是:前者独立地合并不同操作,而后者适用Beaver乘法将乘法减少到开口,使得后者不支持不使用Beaver乘法的协议。MP-SPDZ编译器的打开过程分为了两步(startopen和stoopopen),使得在等待网络信息的时候可以执行本地计算,减少耗时,但是增加了编译器复杂性。MP-SPDZ打开过程总共分为3步:首先创建所有指令的有向无环图,然后根据轮次合并算法合并指令,最后根据依赖图的关系拓扑输出。
MP-SPDZ支持编译时和运行时公共数据的循环,应用中通过函数装饰器执行循环。MP-SPDZ通过trade-off的方式在循环合并和通信之间进行了平衡:通过使用生成指令数量的预算来调整他们的方法,该预算用作总编译成本的代理。
基本库
MP-SPDZ的基本库包括以下几种:
隐私计算数据分发加密协议:不经意传输(OT)、秘密分享(SS)、同态加密(FHE、FHEOffline)、SimpleOT(第三方库);
乱码电路协议:GC、Yao、BMR;
密码库:ECDSA;
数据库:Math、MPIR(开源的多精度整数和有理数计算库);
网络处理库:Networking
其他库:Utils、Tools、SIMDE(本机不支持它们的硬件上提供了 SIMD 内在函数的快速、可移植实现,例如在 ARM 上调用 SSE 函数)、Scripts(脚本库);
编译工具:comiple.py。
协议
MP-SPDZ根据计算加法、乘法的方法分为如下几种协议:
| 安全模型 | Mod prime / GF(2^n) | Mod 2^k | Bin. SS(二进制秘密分享) | Garbling(混淆电路) |
|---|---|---|---|---|
| 恶意安全模型 多数不诚实安全模型 | MASCOT / LowGear / HighGear | SPDZ2k | Tiny / Tinier | BMR |
| 隐蔽安全模型 多数不诚实安全模型 | CowGear / ChaiGear | N/A | N/A | N/A |
| 半诚实安全模型 多数不诚实安全模型 | Semi / Hemi / Temi / Soho | Semi2k | SemiBin | Yao’s GC / BMR |
| 恶意安全模型 多数诚实安全模型 | Shamir / Rep3 / PS / SY | Brain / Rep / PS / SY | Rep3 / CCD / PS | BMR |
| 半诚实安全模型、多数诚实安全模型 | Shamir / ATLAS / Rep3 | Rep3 | Rep3 / CCD | BMR |
| 半诚实安全模型 dealer安全模型 | Dealer | Dealer | Dealer | N/A |
MP-SPDZ可以通过编译时指定协议类型,适配多种MPC协议。各协议的简介如下所示:
(1)MASCOT 指的是Faster Malicious Arithmetic Secure Computation with Oblivious Transfer,即使用不经意传输实现的快速抗恶意算数安全计算。MASCOT协议在安全性上,可以对抗大多数参与方是静态的、恶意的情况。“大多数”指的是在总共个参与方中,可以有至多个参与方是不诚实的。“静态”指的是在协议开始执行之前,这些不诚实的参与方就已经确定了。“恶意”指的是这些不诚实的参与方,不仅会尝试从协议中窥探其他人的数据,而且会主动破坏协议的执行,让协议输出不正确的结果。
MASCOT协议是计算算术电路的,需要实现安全的加法和乘法。MASCOT整体上分为离线和在线两部分,其中离线部分用来进行预处理,在线部分用来计算所需要的函数。离线部分与在线部分是独立的,与参与方的输入、所需计算的函数无关。
(2)SPDZ为可认证秘密分享方案。SPDZ方案的核心思想是设置一个全局MAC(Message Authenticated Code,消息认证码)密钥,但任何参与方都无法得到这个全局MAC密钥。SPDZ是同时支持同态加法和同态常量乘法。在恶意攻击模型下SY/SPDZ-wise是最高效的模型,因为它需要最少的通信,并且是唯一一种提供持续通信的点积。
(3)LowGear和HighGear的虚拟机运行类似于Rotaru等人的密钥生成。主要区别在于使用 daBits(doubly-authenticated bits) 生成 maBits。
(4)CowGear和ChaiGear表示LowGear和HighGear的秘密安全版本。在所有相关程序中,选项在两者中激活TopGear零知识证明。
(5)Hemi和Soho分别表示LowGear和HighGear的剥离版本,用于类似于Semi的半诚实安全性,即使用半同态加密生成加法共享的Beaver三元组。Temi反过来又表示Cramer等人对基于LWE的半同态加密的适应性。Hemi和Temi都使用Halevi和Shoup的对角线填料进行矩阵乘法。ATLAS 的扩展性优于普通的 Shamir 协议,Temi 的扩展性优于 Hemi 或 Semi。ATLAS支持更多参与方的情况。
(6)Tiny 表示 SPDZ2k 对二进制设置的适应。特别是,SPDZ2k牺牲对位不起作用,因此我们根据Furukawa等人将其替换为cut-and-choose。
非线性计算
虽然加法和乘法的计算因协议而异,但非线性计算,例如算术域中的比较(模数不是 2)在整个 MP-SPDZ 中只有三种形式:
(1)未知素数模。这种方法可以追溯到 Catrina 和 de Hoogh。 它主要依赖于在算术域中使用秘密随机位。足够多的此类位允许屏蔽一个秘密值,以便安全地显示屏蔽值。 然后可以将其拆分为位,因为它是公开的。然后使用公共位和秘密掩码位来计算许多非线性函数。相同的想法已被用于实现定点和浮点计算。我们将此方法称为“未知素数模数”,因为它只要求给定明文范围的最小模数大小,大致是明文位长度加上统计安全参数。它的缺点是隐式执行明文范围。
(2)已知素数模。Damgård 等人已经提出了涉及精确素数模数的非线性计算。MP-SPDZ已经实现了 Nishide 和 Ohta 的精细位分解,这使得进一步的非线性计算成为可能。MP-SPDZ对这种方法的假设是明文空间在以素数为模的全范围内略小。这允许通过取一个差异并提取最高有效位来进行比较,这与上述实现两个正数模素数比较的工作不同。MP-SPDZ还使用了 Makri 等人的想法,即如果k位的随机数足够接近,则该随机数与模数p无法区分。
(3)二次幂模数。在非线性计算的背景下,素数模数设置有两个重要区别:
(a)乘以 2 的幂有效地擦除了一些最高有效位。
(b)没有使用乘法的右移。以素数为模,乘以2的倒数的幂允许将具有足够零作为最低有效位的数字右移。
非线性计算的另一种方法是切换到部分计算的二进制计算。MP-SPDZ 实施了许多工作为特定安全模型提出的协议:Demmler 等人、Mohassel 和 Rindal 以及 Dalskov 等人。 MP-SPDZ 还实现了更通用的方法,例如 daBits 和 edaBits。下表是各协议对应的二进制计算方法:
| 协议 | 二进制计算 |
|---|---|
| MASCOT, SPDZ2k, LowGear, HighGear, CowGear, ChaiGear | Tinier with improved cut-and-choose analysis by Furukawa et al. |
| Semi, Hemi, Temi, Soho, Semi2k | SemiBin (Beaver triples modulo 2 using OT) |
| Malicious Shamir | Malicious Shamir over for secure sacrificing |
| Malicious Rep3, Post-Sacrifice, SPDZ-wise replicated | Malicious Rep3 modulo 2 |
| Rep4 | Rep4 modulo 2 |
| Shamir | Shamir over |
| ATLAS | ATLAS over |
| Rep3 | Rep3 |
内部接口
MP-SPDZ 大量使用模板来允许在不同协议之间重用代码。 run() 就是一个简单的例子。 Processor目录下的整个虚拟机都是基于同样的原理构建的。中心类型是表示特定类型中的份额的类型。
所有协议的接口都分四个阶段进行:
(1)初始化。 这是在连续使用中初始化和重置数据结构所必需的;
(2)本地数据准备;
(3)沟通;
(3)输出提取。
代码示例如下:
protocol.init_dotprod(&processor);
for (int i = 0; i < n; i++)
protocol.prepare_dotprod(a[i], b[i]);
protocol.next_dotprod();
protocol.exchange();
c = protocol.finalize_dotprod(n);
值得注意的是,在MP-SPDZ中内部接口通常不是线程安全的。所以在整个程序中只使用一个 ProtocolSetup 实例,并且每个线程应该只使用一个CryptoPlayer/PlainPlayer 和 ProtocolSet 实例。
内部接口列表参考【官方文档Low-Level Interface】。
预处理
MP-SPDZ的预处理大部分是进行随机性的产生。通常用于半诚实和恶意安全或其他协议的特定实现,比如平方计算、daBits、edaBits生成等。其中daBits和edaBits是上述非线性计算中算术和二进制数据类型之间的转换技术。daBits是扩展的双重认证位(edaBits),它对应于算术域中的共享整数,其位分解在二进制域中共享。
预处理的目的是为了避免不必要的计算,这点与SCALE-MAMBA不同。后者在每次运行计算时由于都会生成使用较少的正方形产生的问题,这不仅会减慢计算速度,还会导致应用程序在最后似乎挂起,因为预处理尚未完成。
High-Level API
High-Level API向上层提供底层调用接口。包括整数操作、小数操作和其他复杂功能。
其中小数操作包括定点数和浮点数操作。
复杂功能包括机器学习、不经意传输结构、二进制电路等。
机器学习提供逻辑回归和深度学习推理的功能。前者运行sigmoid函数的准确实现和类似ABY3的近似值之间进行选择。后者支持MobileNets中使用的量化方案及DenseNet、ResNet、SqueezeNet等几种ImageNet解决方案。
不经意传输结构包括数组、队列和堆栈实现。这些结构都支持秘密状态下的读和写。Oblivious RAM(ORAM)技术在大规模数据下是实现高效计算的核心技术。比如ORAM库包含了 Dijkstra 算法的示例实现,用于图形中的最短路径,以及用于稳定匹配的 Gale-Shapley 算法。
二进制电路模块包含使用所谓 Bristol Fashion 格式的电路的功能。由于二进制电路只包括与、或、非三种门。Bristol Fashion 格式的电路则新设计了多种电路门,比如MAND,门操作(XOR、AND、INV、EQ、EQW 或 MAND)等。
隐私计算应用
基于上述High-Level API的定义,用户可以使用对应的接口实现特定的隐私计算功能,比如基本计算、联合统计、隐匿查询、安全求交、特征工程、联合建模、联合与的等功能。
接口文档参考【官方接口文档手册】。示例代码参考【MP-SPDZ/Programs/Source/】目录。
MP-SPDZ性能对比
MPC计算模块会被封装为隐私计算SDK部署在MPC节点上,由隐私计算合约进行调用。
MP-SPDZ与其他MPC框架题在i7处理器,2.8GHz下同时对两个100000元素的数组进行内积运算,性能对比如下表所示。
| SH 2-party (OT) | SH replicated 3-party | Shamir | Malicious Shamir | SPDZ (HighGear) | Yao’s GC (32-bit) | |
|---|---|---|---|---|---|---|
| ABY | 1.8 | ⊥ | ⊥ | ⊥ | ⊥ | ⊥ |
| ABY3 | ⊥ | 0.02 | ⊥ | ⊥ | ⊥ | ⊥ |
| EMP-toolkit | ⊥ | ⊥ | ⊥ | ⊥ | ⊥ | 10 |
| MPyC | ⊥ | ⊥ | 8.45 | ⊥ | ⊥ | ⊥ |
| Obliv-C | ⊥ | ⊥ | ⊥ | ⊥ | ⊥ | 29 |
| ObliVM | ⊥ | ⊥ | ⊥ | ⊥ | ⊥ | 700 |
| PICCO | ⊥ | ⊥ | 0.10 | ⊥ | ⊥ | ⊥ |
| SCALE-MAMBA | ⊥ | ⊥ | ⊥ | 8.3 | 314 | ⊥ |
| MP-SPDZ | 0.9 | 0.03 | 0.08 | 0.4 | 67 | 9 |
MP-SPDZ目录结构介绍
.
├── bin
├── BMR
│ └── network
├── Compiler
│ └── GC
├── doc
│ └── \_static
├── ECDSA
├── ExternalIO
├── FHE
├── FHEOffline
├── GC
├── local
│ ├── include
│ ├── lib
│ └── share
│ └── info
├── logs
├── Machines
├── Math
├── mine-scripts
│ └── dockers
├── mpir
│ ├── autom4te.cache
│ ├── cxx
│ ├── devel
│ ├── doc
│ │ └── devel
│ ├── fft
│ ├── mpf
│ ├── mpir.net
│ │ ├── build.vc
│ │ ├── build.vc11
│ │ │ ├── mpir.net
│ │ │ └── mpir.net-tests
│ │ ├── build.vc12
│ │ │ ├── mpir.net
│ │ │ └── mpir.net-tests
│ │ ├── build.vc14
│ │ │ ├── mpir.net
│ │ │ └── mpir.net-tests
│ │ ├── build.vc15
│ │ │ ├── mpir.net
│ │ │ └── mpir.net-tests
│ │ ├── mpir.net
│ │ └── mpir.net-tests
│ │ ├── HugeFloatTests
│ │ ├── HugeIntTests
│ │ ├── HugeRationalTests
│ │ ├── IntegrationTests
│ │ ├── OtherTests
│ │ ├── Properties
│ │ └── Utilities
│ ├── mpn
│ │ ├── alpha
│ │ │ ├── ev5
│ │ │ ├── ev6
│ │ │ └── ev67
│ │ ├── arm
│ │ ├── generic
│ │ ├── ia64
│ │ ├── mips32
│ │ ├── mips64
│ │ ├── powerpc32
│ │ │ ├── 750
│ │ │ └── vmx
│ │ ├── powerpc64
│ │ │ ├── mode32
│ │ │ ├── mode64
│ │ │ └── vmx
│ │ ├── sparc32
│ │ │ └── v9
│ │ ├── sparc64
│ │ ├── x86
│ │ │ ├── applenopic
│ │ │ │ └── core2
│ │ │ ├── core2
│ │ │ ├── fat
│ │ │ ├── i386
│ │ │ ├── i486
│ │ │ ├── k6
│ │ │ │ ├── k62mmx
│ │ │ │ └── mmx
│ │ │ ├── k7
│ │ │ │ └── mmx
│ │ │ │ └── k8
│ │ │ ├── nehalem
│ │ │ ├── p6
│ │ │ │ ├── mmx
│ │ │ │ └── p3mmx
│ │ │ ├── pentium
│ │ │ │ └── mmx
│ │ │ └── pentium4
│ │ │ ├── mmx
│ │ │ └── sse2
│ │ ├── x86_64
│ │ │ ├── atom
│ │ │ ├── bobcat
│ │ │ ├── bulldozer
│ │ │ │ └── piledriver
│ │ │ ├── core2
│ │ │ │ └── penryn
│ │ │ ├── fat
│ │ │ ├── haswell
│ │ │ │ ├── avx
│ │ │ │ └── broadwell
│ │ │ ├── k8
│ │ │ │ ├── k10
│ │ │ │ │ └── k102
│ │ │ │ └── k8only
│ │ │ ├── nehalem
│ │ │ │ └── westmere
│ │ │ ├── netburst
│ │ │ ├── sandybridge
│ │ │ │ └── ivybridge
│ │ │ └── skylake
│ │ │ └── avx
│ │ ├── x86_64w
│ │ │ ├── atom
│ │ │ ├── bobcat
│ │ │ ├── broadwell
│ │ │ │ └── avx
│ │ │ ├── bulldozer
│ │ │ │ └── piledriver
│ │ │ ├── core2
│ │ │ │ └── penryn
│ │ │ ├── fat
│ │ │ ├── haswell
│ │ │ │ └── avx
│ │ │ ├── k8
│ │ │ │ └── k10
│ │ │ │ └── k102
│ │ │ ├── nehalem
│ │ │ │ └── westmere
│ │ │ ├── netburst
│ │ │ ├── sandybridge
│ │ │ │ └── ivybridge
│ │ │ └── skylake
│ │ │ └── avx
│ │ └── x86w
│ │ ├── p3
│ │ │ └── p3mmx
│ │ ├── p4
│ │ │ ├── mmx
│ │ │ └── sse2
│ │ ├── p6
│ │ │ ├── mmx
│ │ │ └── p3mmx
│ │ └── pentium4
│ │ ├── mmx
│ │ └── sse2
│ ├── mpq
│ ├── mpz
│ ├── printf
│ ├── scanf
│ ├── tests
│ │ ├── cxx
│ │ ├── devel
│ │ ├── fft
│ │ ├── misc
│ │ ├── mpf
│ │ ├── mpn
│ │ ├── mpq
│ │ ├── mpz
│ │ └── rand
│ └── tune
├── Networking
├── OT
├── Player-Data
│ ├── 2-2-128
│ ├── 2-p-128
│ ├── 2-p-192
│ └── 2-TT-8
├── Processor
├── Programs
│ ├── Bytecode
│ ├── Circuits
│ ├── Public-Input
│ ├── Schedules
│ └── Source
├── Protocols
├── Scripts
├── simde
│ ├── docker
│ │ ├── bin
│ │ └── cross-files
│ ├── simde
│ │ ├── arm
│ │ │ └── neon
│ │ ├── wasm
│ │ └── x86
│ │ └── avx512
│ └── test
│ ├── arm
│ │ └── neon
│ ├── cmake
│ ├── common
│ ├── docker
│ ├── munit
│ ├── wasm
│ └── x86
│ └── avx512
├── SimpleOT
├── Tools
├── Utils
└── Yao
参考文献
(1)官方手册
(2)MP-SPDZ Github
(3)官方论文:MP-SPDZ-A Versatile Framework for Multi-Party Computation