C语言系统化精讲(三):C语言变量和数据类型-上篇
文章目录
- 一、C语言中的常量
-
- 1.1 生活中的数据
- 1.2 生活中的数据在C语言中的描述
- 二、C语言中的输出函数
-
- 2.1 单字符输出函数 putchar()
- 2.2 多字符输出函数 puts()
- 2.3 格式化输出函数 printf()
-
- 2.3.1 牛刀小试
- 2.3.2 轻量进阶
- 2.3.3 printf() 不能立即输出的问题
- 三、C语言中的变量
-
- 3.1 变量
- 3.2 数据类型
- 3.3 数据的长度
- 四、C语言中的整数
-
- 4.1 整型的长度
- 4.2 sizeof操作符
- 4.3 不同整型的输出
- 4.4 不同整型的后缀
- 4.5 C语言中的二进制数、八进制数和十六进制数
-
- 4.5.1 二进制数、八进制数和十六进制数的表示
- 4.5.2 二进制数、八进制数和十六进制数的输出
- 4.6 C语言中的正负数及其输出
- 4.7 C语言整数的取值范围以及数值溢出
-
- 4.7.1 无符号数的取值范围
- 4.7.2 有符号数的取值范围
- 4.7.3 数值溢出
一、C语言中的常量
1.1 生活中的数据
整数: 168,188,520,1314
小数: 1.68,1.88,5.20,13.14
字母: a/A,b/B,c/C,d/D
单词: welcome,hello,world
1.2 生活中的数据在C语言中的描述
所谓常量,就是值永远不允许被改变的量,比如一年中有12个月、一天有24小时等。分类:
①: 整型常量 例如: 10,20,30,40,800,900,-1,-2,-3
②: 浮点数常量(小数) 3.1415926,4.88,3.14e8,3.14e-9
ps: 3.14e8 ==> 这里的
e相当于数学的底数10,8为幂,等价于数学中 3.14*108
③: 字符常量。在C语言中我们把字母叫做字符,字符用单引号引用。 例如: 'A','B','a','1','8'
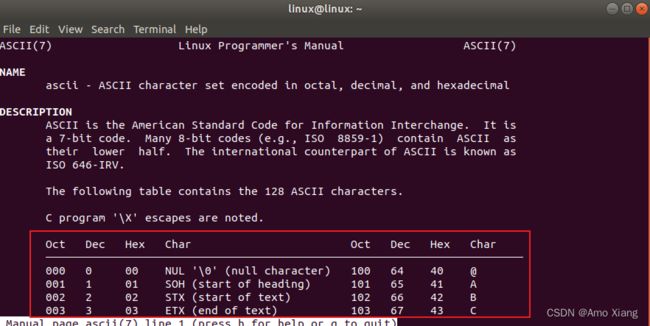
ps: 在C语言中规定,每个字符有个对应的
ASCII的整数值与之对应。 Linux 中查询ASCII码的方法:man ascii
④: 字符串常量。在C语言中单词我们叫做字符串,字符串用双引号引用。 例如:"welcome","hello","world"
字符串常量以
""引用起来,等价于多个字符的结合 +'\0',例如:"ABC"<===>'A'+'B'+'C'+'\0'、"1234"、"XYZ"
⑤: 标识常量(宏定义)。功能:用宏名来代替某些常量数据,在某些特殊的场合可以提高程序的可读性。 宏名替换后为常量,常大写。 格式:
#define 标识符号名 常量数据
// 举例:
#define MAX 100
#define STR "This is a example"
二、C语言中的输出函数
当程序解决了问题之后,还要使用输出语句将计算的结果显示出来。本小节致力于使读者掌握如何对程序的 输出 进行操作。
2.1 单字符输出函数 putchar()
单个字符操作,就是每次只能操作一个字符,输出单个字符使用函数 putchar()。在C语言中,putchar() 函数是输出字符数据,它的作用是向显示设备输出一个字符。其语法格式如下:
int putchar(int ch); //参数ch是要进行输出的字符,可以是字符型变量或整型变量,也可以是常量和转义字符
示例:
#include运行结果如下图所示:

2.2 多字符输出函数 puts()
字符串输出就是将字符串输出在控制台上,例如一句名言、一串数字等等。在C语言中,字符串输出使用的是 puts() 函数,它的作用是输出一个字符串到屏幕上。其语法格式如下:
//使用puts()函数时,先要在程序中添加stdio.h头文件。其中,形式参数str是字符串指针类型,可以用来接收要输出的字符串
int puts(char *str); // puts(const char *_Str);
ps: C语言中没有字符串类型,想要表示字符串要用字符型数组和字符型指针,这两种概念会在后续章节进行详细讲解。
示例:使用 puts() 函数输出一个字符串,代码如下:
#include运行结果如下图所示:

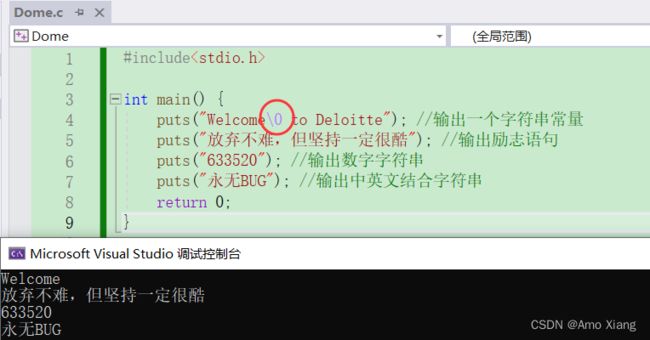
ps:这段语句是输出一个字符串,之后会自动进行换行操作。 puts() 函数会在字符串中判断 \0 结束符,遇到结束符时,后面的字符不再输出并且自动换行。例如:
2.3 格式化输出函数 printf()
2.3.1 牛刀小试
在 2.2小节 中,我们使用 puts() 函数来输出字符串。puts() 函数是 output string 的缩写,只能用来输出字符串,不能输出整数、小数、字符等,我们需要用另外一个函数,那就是 printf() 函数。printf() 比 puts() 更加强大,不仅可以输出字符串,还可以输出整数、小数、单个字符等,并且输出格式也可以自己定义,例如:
- 以十进制、八进制、十六进制形式输出;
- 要求输出的数字占 n 个字符的位置;
- 控制小数的位数。
printf 是 print format 的缩写,意思是 格式化打印。这里所谓的 打印 就是在屏幕上显示内容,与 输出 的含义相同,所以我们一般称 printf 是用来格式化输出的。其语法格式如下:
printf(格式控制,输出列表)
①: 格式控制是用双引号括起来的字符串,也称为转换控制字符串。其中包括格式字符和普通字符。
// 1.1 格式字符:用来进行格式说明的字符,作用是将输出的数据转换为指定的格式。格式字符通常以 `%` 开头。
// 1.2 普通字符:需要原样输出的字符,包括双引号内的逗号、空格和换行符。
②: 输出列表列出的是要进行输出的一些数据,可以是常量、变量或表达式。
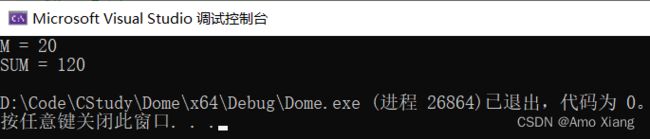
举例:要输出整型常量,代码如下:
#include运行结果如下图所示:

ps: puts 输出完成后会自动换行,而 printf 不会,要自己添加换行符,这是 puts 和 printf 在输出字符串时的一个区别。
所谓换行,就是让文本从下一行的开头输出,相当于在编辑 Word 或者 TXT 文档时按下回车键。
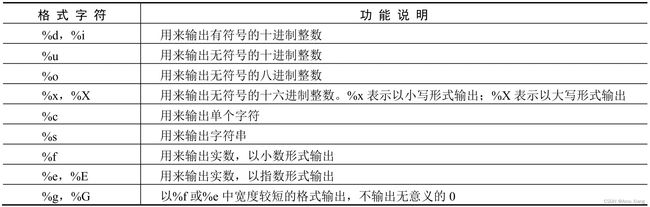
printf() 格式字符:
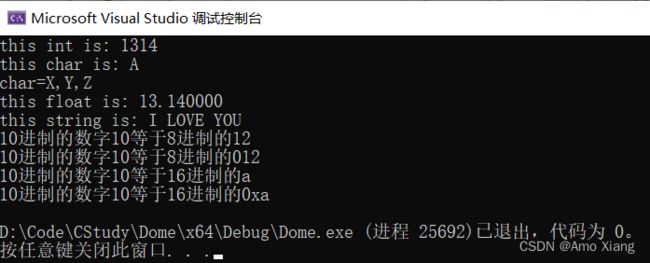
示例:使用格式输出函数 printf() 输出不同类型的变量。
#include运行结果如下图所示:
示例:在数据之中,宏定义是原样替换
//03-define.c
#include 运行结果如下图所示:
2.3.2 轻量进阶
格式控制符:

printf() 格式控制符的完整形式如下:
%[flag][width][.precision]type // [] 表示可选,可以省略
①: type 表示输出类型,比如 %d,%f,%c,%lf,type 就分别对应 d,f,c,lf。ps: type 这一项必须有,这意味着输出时必须要知道是什么类型。
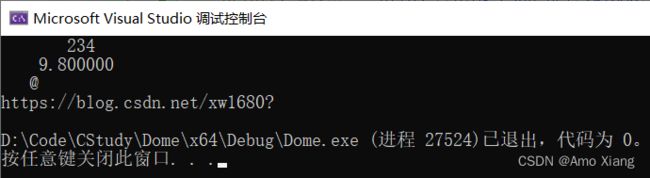
②: width 表示最小输出宽度,也就是至少占用几个字符的位置;例如,%-9d 中 width 对应 9,表示输出结果最少占用 9 个字符的宽度。当输出结果的宽度不足 width 时,以空格补齐(如果没有指定对齐方式,默认会在左边补齐空格);当输出结果的宽度超过 width 时,width 不再起作用,按照数据本身的宽度来输出。下面的代码演示了 width 的用法:
#include运行结果如下图所示:
③: .precision 表示输出精度,也就是小数的位数。说明如下:
- 当小数部分的位数大于 precision 时,会按照四舍五入的原则丢掉多余的数字。
- 当小数部分的位数小于 precision 时,会在后面补 0。
- 用于整数时,.precision 表示最小输出宽度。与 width 不同的是,整数的宽度不足时会在左边补 0,而不是补空格。
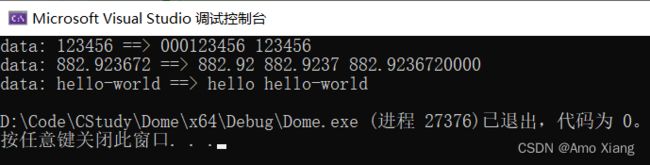
- 用于字符串时,.precision 表示最大输出宽度,或者说截取字符串。当字符串的长度大于 precision 时,会截掉多余的字符;当字符串的长度小于 precision 时,.precision 就不再起作用。
示例:
#include运行结果如下图所示:
④ flag 是标志字符。例如,%#x 中 flag 对应 #,%-9d 中 flags 对应 -。下表列出了 printf() 可以用的 flag:

示例:
#include 运行结果如下图所示:
2.3.3 printf() 不能立即输出的问题
printf() 有一个尴尬的问题,就是有时候不能立即输出,请看下面的代码:
#include在 Linux 或者 Mac OS 下运行该程序,会发现第一个 printf() 并没有立即输出,而是等待 5 秒以后,和第二个 printf() 一起输出了,请看下面的动图演示:
修改一下代码,在第一个 printf() 的最后添加一个换行符,如下所示:
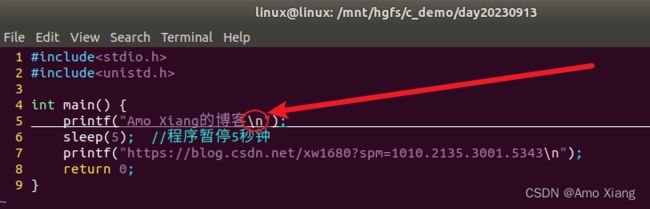
再次编译并运行程序,发现第一个 printf() 首先输出(程序运行后立即输出),等待 5 秒以后,第二个 printf() 才输出,请看下面的动图演示:
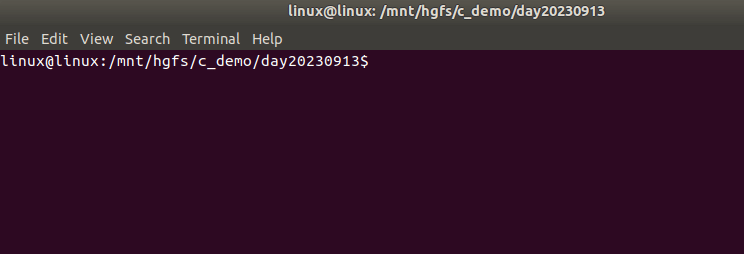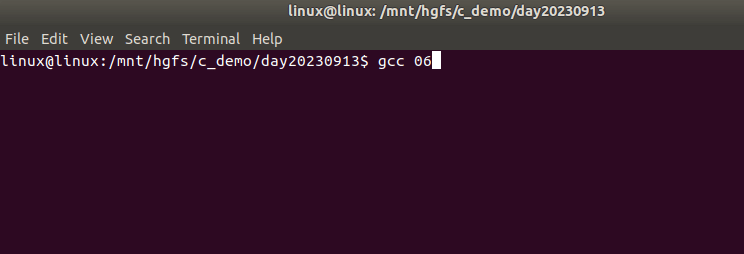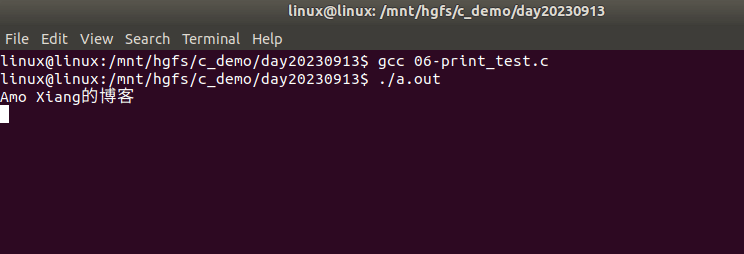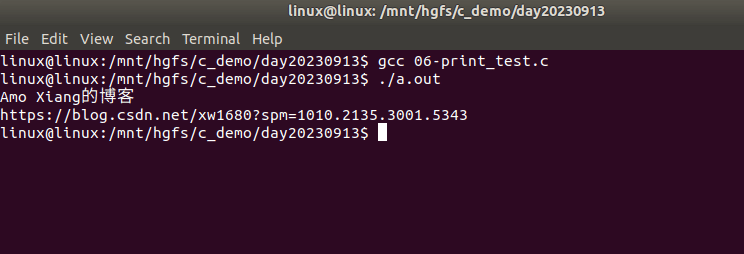
从本质上讲,printf() 执行结束以后数据并没有直接输出到显示器上,而是放入了缓冲区,直到遇见换行符 \n 才将缓冲区中的数据输出到显示器上。更加深入的内容,我们将在后续的章节中详细讲解。
ps: Windows 和 Linux、Mac OS 的情况又不一样。这是因为,Windows 和 Linux、Mac OS 的缓存机制不同。更加深入的内容,我们将在后续的章节中详细讲解。要想破解 printf() 输出的问题,必须要了解缓存,它能使你对输入输出的认识上升到一个更高的层次,以后不管遇到什么疑难杂症,都能迎刃而解。可以说,输入输出的
命门就在于缓存。
小结:在以后的编程中,我们会经常使用 printf,说它是C语言中使用频率最高的一个函数一点也不为过,每个C语言程序员都应该掌握 printf 的用法,这是最基本的技能。
三、C语言中的变量
3.1 变量
现实生活中我们会找一个小箱子来存放物品,一来显得不那么凌乱,二来方便以后找到。计算机也是这个道理,我们需要先在内存中找一块区域,规定用它来存放 数据,并起一个好记的名字 (标识符/变量名), 方便以后查找。这块区域就是 小箱子,我们可以把数据放进去了。C语言中这样在内存中找一块区域:
数据类型 变量名;
int weight; // 举例:这个语句的意思是:在内存中找一块区域,命名为 weight,用它来存放整数
不过 int weight; 仅仅是在内存中找了一块可以保存整数的区域,那么如何将 123,100,999 这样的数字放进去呢?C语言中这样向内存中放整数:
weight = 123;
= 是一个新符号,它在数学中叫 等于号,例如 1+2=3,但在C语言中,这个过程叫做 赋值(Assign)。 赋值是指把数据放到内存的过程。把上面的两个语句连起来:
int weight;
weight = 123;
//把 123 放到了一块叫做 weight 的内存区域。等价于:
int weight = 123;
// weight 中的整数不是一成不变的,只要我们需要,随时可以更改。更改的方式就是再次赋值,例如:
int weight;
weight = 123;
weight = 520;
weight = 1314;
第二次赋值,会把第一次的数据 覆盖(擦除) 掉,也就是说,a 中最后的值是 1314,123,520 已经不存在了,再也找不回来了。因为 weight 的值可以改变,所以我们给它起了一个形象的名字,叫做 变量(Variable)。
int weight;创造了一个变量 weight,我们把这个过程叫做变量定义。weight = 123; 把 123 交给了变量 weight,我们把这个过程叫做给变量赋值;又因为是第一次赋值,也称变量的初始化,或者赋初值。
可以先定义变量,再初始化,也可以在定义的同时进行初始化。这两种方式是等价的:
// 第一种方式
int weight;
weight = 123;
// 第二种方式
int weight = 123;
3.2 数据类型
数据是放在内存中的,变量是给这块内存起的名字,有了变量就可以找到并使用这份数据。但问题是,该如何使用呢?我们知道,诸如数字、文字、符号、图形、音频、视频等数据都是以二进制形式存储在内存中的,它们并没有本质上的区别,那么,00010000 该理解为数字16呢,还是图像中某个像素的颜色呢,还是要发出某个声音呢?如果没有特别指明,我们并不知道。
也就是说,内存中的数据有多种解释方式,使用之前必须要确定;上面的 int weight; 就表明,这份数据是整数,不能理解为像素、声音等。int 有一个专业的称呼,叫做 数据类型(Data Type)。 顾名思义,数据类型用来说明数据的类型,确定了数据的解释方式,让计算机和程序员不会产生歧义。 在C语言中,有多种数据类型,例如:

这些是最基本的数据类型,是C语言自带的,如果我们需要,还可以通过它们组成更加复杂的数据类型,后面我们会一一讲解。为了让程序的书写更加简洁,C语言支持多个变量的连续定义,例如:
数据类型 变量名1 = 值1, 变量名2 = 值2, 变量名3 = 值3...;
// 举例
int weight = 129, age = 29, eyes = 200;
int a, b, c;
float m = 13.14, n = 5.20;
char p, q = '@';
// ps:连续定义的多个变量以逗号,分隔,并且要拥有相同的数据类型;变量可以初始化,也可以不初始化
3.3 数据的长度
所谓 数据长度(Length), 是指数据占用多少个字节。占用的字节越多,能存储的数据就越多,对于数字来说,值就会更大,反之能存储的数据就有限。多个数据在内存中是连续存储的,彼此之间没有明显的界限,如果不明确指明数据的长度,计算机就不知道何时存取结束。例如我们保存了一个整数 1000,它占用4个字节的内存,而读取时却认为它占用3个字节或5个字节,这显然是不正确的。所以,在定义变量时还要指明数据的长度。而这恰恰是数据类型的另外一个作用。数据类型除了指明数据的解释方式,还指明了数据的长度。因为在C语言中,每一种数据类型所占用的字节数都是固定的,知道了数据类型,也就知道了数据的长度。 在32位环境中,各种数据类型的长度一般如下:

C语言有多少种数据类型,每种数据类型长度是多少、该如何使用,这是每一位C程序员都必须要掌握的,后续会一一进行讲解。举例:
#include运行结果如下图所示:

小结: 数据是放在内存中的,在内存中存取数据要明确三件事情:数据存储在哪里、数据的长度以及数据的处理方式。 变量名不仅仅是为数据起了一个好记的名字,还告诉我们数据存储在哪里,使用数据时,只要提供变量名即可;而数据类型则指明了数据的长度和处理方式。所以诸如 int n;char c;float money; 这样的形式就确定了数据在内存中的所有要素。C语言提供的多种数据类型让程序更加灵活和高效,同时也增加了学习成本。而有些编程语言,例如 Python,JavaScript 等,在定义变量时不需要指明数据类型,编译器会根据赋值情况自动推演出数据类型,更加智能。除了C语言, Java,C++,C# 等在定义变量时也必须指明数据类型,这样的编程语言称为强类型语言。而 Python,JavaScript 等在定义变量时不必指明数据类型,编译系统会自动推演,这样的编程语言称为弱类型语言。强类型语言一旦确定了数据类型,就不能再赋给其他类型的数据,除非对数据类型进行转换。弱类型语言没有这种限制,一个变量,可以先赋给一个整数,然后再赋给一个字符串。ps:数据类型只在定义变量时指明,而且必须指明;使用变量时无需再指明,因为此时的数据类型已经确定了。
四、C语言中的整数
整数是编程中常用的一种数据,C语言通常使用 int 来定义整数(int 是 integer 的简写),这在 三、C语言中的变量 中已经进行了详细讲解。
在现代操作系统中,int 一般占用 4 个字节(Byte)的内存,共计 32 位(Bit)。如果不考虑正负数,当所有的位都为 1 时它的值最大,为 232-1 = 4,294,967,295 ≈ 43亿,这是一个很大的数,实际开发中很少用到,而诸如 1、99、12098 等较小的数使用频率反而较高。使用 4 个字节保存较小的整数绰绰有余,会空闲出两三个字节来,这些字节就白白浪费掉了,不能再被其他数据使用。现在个人电脑的内存都比较大了,配置低的也有 8G,浪费一些内存不会带来明显的损失;而在C语言被发明的早期,或者在单片机和嵌入式系统中,内存都是非常稀缺的资源,所有的程序都在尽力节省内存。反过来说,43 亿虽然已经很大,但要表示全球人口数量还是不够,必须要让整数占用更多的内存,才能表示更大的值,比如占用 6 个字节或者 8 个字节。
让整数占用更少的内存可以在 int 前边加 short,让整数占用更多的内存可以在 int 前边加 long,还不够的话可以在 int 前面加两个 long,例如:
short int a = 10;
short int b, c = 99;
long int m = 102023;
long int n, p = 562131;
long long int x = 12233720;
long long int y, z = 92949685;
//也可以将 int 省略,只写 short、long 和 long long,如下所示:
short a = 10;
short b, c = 99;
long m = 102023;
long n, p = 562131;
long long x = 12233720;
long long y, z = 92949685; //这样的写法更加简洁,实际开发中常用。
这样 a、b、c 各自只占用 2 个字节的内存,m、n、p 可能 占用 8 个字节,x、y、z 各自占用 8 个字节。 int 是基本的整数类型,short、long 和 long long 是在 int 的基础上进行的扩展,short 可以节省内存,long 和 long long 可以容纳更大的值。short、int、long 是C语言中常见的整数类型,long long 在某些场景中也会用到。其中,int 称为整型,short 称为短整型,long 称为长整型,long long 称为超长整形。
4.1 整型的长度
细心的读者可能会发现,上面我们在描述 short、int、long、long long 类型的长度时,只对 short 和 long long 使用肯定的说法,而对 int、long 使用了 一般、可能 等不确定的说法。这种描述的言外之意是,short 和 long long 的长度是确定的,分别是 2 和 8 个字节,而 int、long 的长度无法确定,在不同的环境下有不同的表现。一种数据类型占用的字节数,称为该数据类型的长度。 例如,short 占用 2 个字节的内存,那么它的长度就是 2。实际情况也确实如此,C语言并没有严格规定 short、int、long、long long 的长度,只做了宽泛的限制:
short 至少占用 2 个字节。
int 建议为一个机器字长。32 位环境下机器字长为 4 字节,64 位环境下机器字长为 8 字节。
short 的长度不能大于 int,long 的长度不能小于 int,long long 不能小于 long。
总结起来,它们的长度(所占字节数)关系为:
2 ≤ short ≤ int ≤ long ≤ long long
这就意味着,short 并不一定真的 短,long 也并不一定真的 长,它们有可能和 int 占用相同的字节数。同样,long long 也不一定真的比 long 长,它们占用的字节数可能相同。在 16 位环境下,short 的长度为 2 个字节,int 也为 2 个字节,long 为 4 个字节,long long 为 8 个字节。16 位环境多用于单片机和低级嵌入式系统,在 PC 和服务器上已经见不到了。对于 32 位的 Windows、Linux 和 Mac OS,short 的长度为 2 个字节,int 为 4 个字节,long 也为 4 个字节,long long 为 8 个字节。PC 和服务器上的 32 位系统占有率也在慢慢下降,嵌入式系统使用 32 位越来越多。在 64 位环境下,不同的操作系统会有不同的结果,如下所示:

目前我们使用较多的 PC 系统为 Win7,Win10,Win11,Mac OS,Linux,在这些系统中,short、int 和 long long 的长度都是固定的,分别为 2、4 和 8,大家可以放心使用,只有 long 的长度在 Win64 和类 Unix 系统下会有所不同,使用时要注意移植性。
4.2 sizeof操作符
获取某个数据类型的长度可以使用 sizeof 操作符,如下所示:
#include 在 32 位环境以及 Win64 环境下的运行结果为:

在 64 位 Linux 和 Mac OS 下的运行结果为:
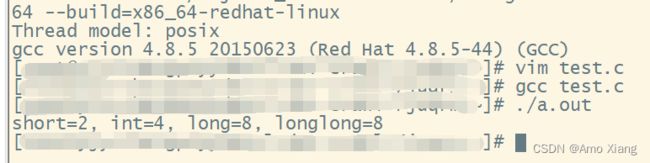
sizeof 用来获取某个数据类型或变量所占用的字节数,如果后面跟的是变量名称,那么可以省略 (), 如果跟的是数据类型,就必须带上 ()。
4.3 不同整型的输出
在之前 2.3 格式化输出函数 printf() 小节已经讲解过 printf() 函数的详细用法,只不过是以常量来进行演示,此小姐用变量来进行演示。使用不同的格式控制符可以输出不同类型的整数,它们分别是:
%hd用来输出 short int 类型,hd 是 short decimal 的简写
%d用来输出 int 类型,d 是 decimal 的简写
%ld用来输出 long int 类型,ld 是 long decimal 的简写
%lld用来输出 long long int 类型,lld 是 long long decimal 的简写
下面的例子演示了不同整型的输出:
#include 运行结果如下图所示:

在编写代码的过程中,我建议将格式控制符和数据类型严格对应起来,养成良好的编程习惯。当然,如果你不严格对应,一般也不会导致错误,例如,很多初学者都使用 %d 输出所有的整数类型,请看下面的例子:
#include 运行结果仍然是:

当使用 %d 输出 short,或者使用 %ld 输出 short、int,又或者使用 %lld 输出 short、int 和 long 时,不管值有多大,都不会发生错误,因为格式控制符足够容纳这些值。当使用 %hd 输出 int、long、long long,或者使用 %d 输出 long、long long,又或者使用 %ld 输出 long long 时,如果要输出的值比较小(就像上面的情况),一般也不会发生错误,如果要输出的值比较大,就很有可能发生错误,例如:
#include 运行结果为:
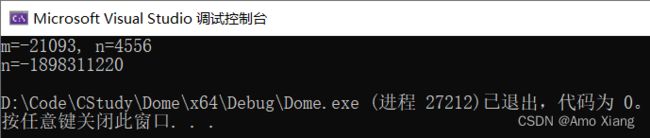
输出结果完全是错误的,这是因为 %hd 容纳不下 m 和 n 的值,%d 也容纳不下 n 的值。读者需要注意,当格式控制符和数据类型不匹配时,编译器会给出警告,提示程序员可能会存在风险。编译器的警告是分等级的,不同程度的风险被划分成了不同的警告等级,而使用 %d 输出 short、long 和 long long 类型的风险较低,如果你的编译器设置只对较高风险的操作发出警告,那么此处你就看不到警告信息。
4.4 不同整型的后缀
大家已经学完了 short、int、long 和 long long 四种整数类型,假设程序中有一个整数 100,它是什么类型的呢?实际开发中用到的整数,它们的值通常不会很大,类型默认为 int。如果整数的值很大,需要占用比 int 更多的内存,它的类型可能是 long、long long 等(还可能是无符号整形,后续会讲)。举个简单的例子:
long a = 100;
int b = 294;
单纯看 100 和 294 这两个整数,它们的类型都是 int。分析这两行代码:第一行:变量 a 的类型是 long,整数 100 的类型是 int,它们的类型不同,编译器会先将 100 的类型转换成 long,再将它赋值给 a;第二行:变量 b 的类型是 int,整数 294 的类型是 int,它们的类型相同,编译器直接将 294 赋值给变量 b。关于数据类型的转换,这里先简单了解一下,我们将在后续的文章中深入探讨。对于数值不是很大的整数,我们也可以手动指定它们的类型为 long 和 long long,具体写法是:
整数后面紧跟 l(小写的 L)或者 L,表明它的类型是 long;
整数后面紧跟 ll(小写的 LL)或者 LL,表明它的类型是 long long。
举个简单的例子:
int a = 10;
long b = 100L;
long long c = 1000LL;
short d = 32L;
其中,10 的类型是 int,100 和 32 的类型是 long,1000 的类型是 long long。我们习惯把 L、LL 这样的类型标识叫做整数的后缀。再次强调,一个整数赋值给某个变量时,它们的类型不一定相同,比如将 100L 赋值给 b,它们的类型是相同的;再比如将 32L 赋值给 d,它们的类型是不同的,编译器会先将 32 转换为 short 类型,然后再赋值给 d。对于初学者,很少会用到数字的后缀,加不加往往没有什么区别,也不影响实际编程。但是既然系统地学习 C语言,这个知识点还是要掌握的,否则哪天看到别人的代码这样写,你却不明白怎么回事,那就尴尬了。
4.5 C语言中的二进制数、八进制数和十六进制数
C语言中的整数除了可以使用十进制,还可以使用二进制、八进制和十六进制。
4.5.1 二进制数、八进制数和十六进制数的表示
一个数字默认就是十进制的,表示一个十进制数字不需要任何特殊的格式。但是,表示一个二进制、八进制或者十六进制数字就不一样了,为了和十进制数字区分开来,必须采用某种特殊的写法,具体来说,就是在数字前面加上特定的字符,也就是加前缀。
1) 二进制: 二进制由 0 和 1 两个数字组成,使用时必须以 0b或0B, 例如:
//合法的二进制
int a = 0b101; //换算成十进制为 5
int b = -0b110010; //换算成十进制为 -50
int c = 0B100001; //换算成十进制为 33
//非法的二进制
int m = 101010; //无前缀 0B,相当于十进制
int n = 0B410; //4不是有效的二进制数字
读者请注意,标准的C语言并不支持上面的二进制写法,只是有些编译器自己进行了扩展,才支持二进制数字。换句话说,并不是所有的编译器都支持二进制数字,只有一部分编译器支持,并且跟编译器的版本有关系,有兴趣的读者可以自行测试。
2) 八进制: 八进制由 0~7 八个数字组成,使用时必须以0开头(注意是数字 0,不是字母 o),例如:
//合法的八进制数
int a = 015; //换算成十进制为 13
int b = -0101; //换算成十进制为 -65
int c = 0177777; //换算成十进制为 65535
//非法的八进制
int m = 256; //无前缀 0,相当于十进制
int n = 03A2; //A不是有效的八进制数字
3) 十六进制: 十六进制由数字 0~9、 字母 A~F 或 a~f(不区分大小写)组成,使用时必须以 0x或0X 开头,例如:
//合法的十六进制
int a = 0X2A; //换算成十进制为 42
int b = -0XA0; //换算成十进制为 -160
int c = 0xffff; //换算成十进制为 65535
//非法的十六进制
int m = 5A; //没有前缀 0X,是一个无效数字
int n = 0X3H; //H不是有效的十六进制数字
4) 十进制: 十进制由 0~9 十个数字组成,没有任何前缀,和我们平时的书写格式一样,不再赘述。
4.5.2 二进制数、八进制数和十六进制数的输出
C语言中常用的整数有 short、int、long 和 long long 四种类型,通过 printf 函数,可以将它们以八进制、十进制和十六进制的形式输出。上小节我们讲解了如何以十进制的形式输出,本小节我们重点讲解如何以八进制和十六进制的形式输出,下表列出了不同类型的整数、以不同进制的形式输出时对应的格式控制符:
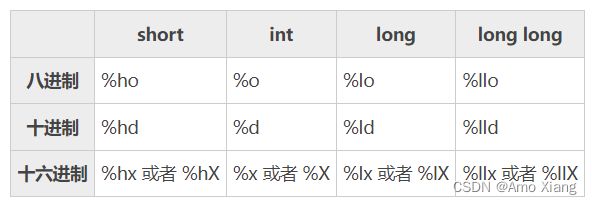
十六进制数字的表示用到了英文字母,有大小写之分,要在格式控制符中体现出来:
%hx、%x、%lx 和 %llx 中的x小写,表明以小写字母的形式输出十六进制数
%hX、%X、%lX 和 %llX 中的X大写,表明以大写字母的形式输出十六进制数
八进制数字和十进制数字不区分大小写,所以格式控制符都用小写形式。如果你比较叛逆,想使用大写形式,那么行为是未定义的,请你慎重:
有些编译器支持大写形式,只不过行为和小写形式一样
有些编译器不支持大写形式,可能会报错,也可能会导致奇怪的输出
注意,虽然部分编译器支持二进制数字的表示,但是却不能使用 printf 函数输出二进制,这一点比较遗憾。当然,通过转换函数可以将其它进制数字转换成二进制数字,并以字符串的形式存储,然后在 printf 函数中使用 %s 输出即可。考虑到读者的基础还不够,这里就先不讲这种方法了。举例,以不同进制的形式输出整数:
#include 运行结果如下图所示:

从这个例子可以发现,一个数字不管以何种进制来表示,都能够以任意进制的形式输出。数字在内存中始终以二进制的形式存储,其它进制的数字在存储前都必须转换为二进制形式;同理,一个数字在输出时要进行逆向的转换,也就是从二进制转换为其他进制。
输出时加上前缀: 请读者注意观察上面的例子,会发现有一点不完美,如果只看输出结果:
对于八进制数字,它没法和十进制、十六进制区分,因为八进制、十进制和十六进制都包含 0~7 这几个数字。
对于十进制数字,它没法和十六进制区分,因为十六进制也包含0~9这几个数字.如果十进制数字中还不包含8和9,那么也不能和八进制区分了
对于十六进制数字,如果没有包含 a~f 或者 A~F,那么就无法和十进制区分,如果还不包含 8 和 9,那么也不能和八进制区分了。
区分不同进制数字的一个简单办法就是,在输出时带上特定的前缀。在格式控制符中加上 # 即可输出前缀,例如 %#x,%#o,%#lX,%#ho 等,请看下面的代码:
#include 程序运行结果如下图所示:
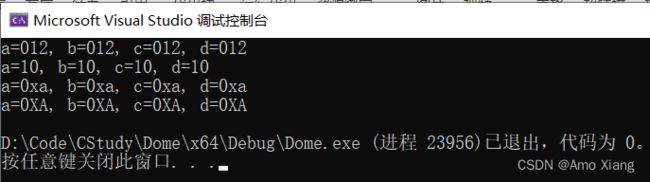
十进制数字没有前缀,所以不用加 #。 如果你加上了,那么它的行为是未定义的,有的编译器支持十进制加 #,只不过输出结果和没有加 # 一样,有的编译器不支持加#,可能会报错,也可能会导致奇怪的输出;但是,大部分编译器都能正常输出,不至于当成一种错误。
4.6 C语言中的正负数及其输出
在数学中,数字有正负之分。在C语言中也是一样,short、int、long 和 long long 都可以带上正负号,例如:
//负数
short a1 = -10;
short a2 = -0x2dc9; //十六进制
//正数
int b1 = +10;
int b2 = +0174; //八进制
int b3 = 22910;
//负数和正数相加
long c = (-9) + (+12);
long long d = 5 + (-3);
如果不带正负号,默认就是正数。符号也是数字的一部分,也要在内存中体现出来。符号只有正负两种情况,用 1 位(Bit)就足以表示;C语言规定,把内存的最高位作为符号位。 以 int 为例,它占用 32 位的内存,0~30 位表示数值,31 位表示正负号。如下图所示:
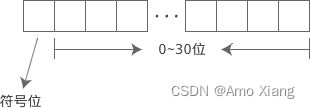
在编程语言中,计数往往是从 0 开始,例如字符串 "abc123", 我们称第 0 个字符是 a,第 1 个字符是 b,第 5 个字符是 3。这和我们平时从 1 开始计数的习惯不一样,大家要慢慢适应,培养编程思维。C语言规定,在符号位中,用 0 表示正数,用 1 表示负数。例如 int 类型的 -10 和 +16 在内存中的表示如下:
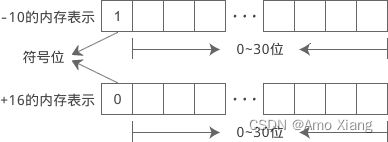
short、int、long 和 long long 类型默认都是带符号位的,符号位以外的内存才是数值位。C语言提供了 signed 关键字,加到数据类型的前面,可以强调此类型是带符号位的,例如:
signed short a = -10;
signed int b = -100;
signed long c = -1000;
signed long long d = -10000;
以 short 为例,signed short 和 short 其实是同一种类型,所以我们一般会省略 signed,直接写 short。short、int、long 和 long long 能表示正数和负数,如果只考虑正数,那么各种类型能表示的数值范围 (取值范围) 就比原来小了一半。但是在很多情况下,我们非常确定某个数字只能是正数,比如班级学生的人数、字符串的长度、内存地址等,这个时候符号位就是多余的了,就不如删掉符号位,把所有的位都用来存储数值,这样能表示的数值范围更大(大一倍)。C语言允许我们这样做,如果不希望设置符号位,可以在数据类型前面加上 unsigned 关键字,例如:
unsigned short a = 10;
unsigned int b = 100;
unsigned long c = 1000;
unsigned long long d = 10000;
这样,short、int、long 和 long long 中就没有符号位了,所有的位都用来表示数值,正数的取值范围更大了。这也意味着,使用了 unsigned 后只能表示正数,不能再表示负数了。如果将一个数字分为符号和数值两部分,那么不加 unsigned 的数字称为有符号数,能表示正数和负数,加了 unsigned 的数字称为无符号数,只能表示正数。请读者注意一个小细节,如果是 unsigned int 类型,那么可以省略 int ,只写 unsigned,例如:
unsigned n = 100; // 等价于: unsigned int n = 100;
无符号数的输出: 无符号数可以以八进制、十进制和十六进制的形式输出,它们对应的格式控制符分别为:

上一小节我们也讲到了不同进制形式的输出,但是上节我们还没有讲到正负数,所以也没有关心这一点,只是 笼统 地介绍了一遍。现在本节已经讲到了正负数,那我们就再深入地说一下。严格来说,格式控制符和整数的符号是紧密相关的,具体就是:
%d 以十进制形式输出有符号数
%u 以十进制形式输出无符号数
%o 以八进制形式输出无符号数
%x 以十六进制形式输出无符号数
那么,如何以八进制和十六进制形式输出有符号数呢?很遗憾,printf 并不支持,也没有对应的格式控制符。在实际开发中,也基本没有 输出负的八进制数或者十六进制数 这样的需求,我想可能正是因为这一点,printf 才没有提供对应的格式控制符。下表全面地总结了不同类型的整数,以不同进制的形式输出时对应的格式控制符(–表示没有对应的格式控制符)。

有读者可能会问,上一小节我们也使用 %o 和 %x 来输出有符号数了,为什么没有发生错误呢?这是因为:当以有符号数的形式输出时,printf 会读取数字所占用的内存,并把最高位作为符号位,把剩下的内存作为数值位;当以无符号数的形式输出时,printf 也会读取数字所占用的内存,并把所有的内存都作为数值位对待。对于一个有符号的正数,它的符号位是 0,当按照无符号数的形式读取时,符号位就变成了数值位,但是该位恰好是 0 而不是 1,所以对数值不会产生影响,这就好比在一个数字前面加 0,有多少个 0 都不会影响数字的值。如果对一个有符号的负数使用 %o 或者 %x 输出,那么结果就会大相径庭,读者可以亲试。可以说,有符号正数的最高位是 0 这个巧合才使得 %o 和 %x 输出有符号数时不会出错。再次强调,不管是以 %o、%u、%x 输出有符号数,还是以 %d 输出无符号数,编译器都不会报错,只是对内存的解释不同了。%o、%d、%u、%x 这些格式控制符不会关心数字在定义时到底是有符号的还是无符号的:
你让我输出无符号数,那我在读取内存时就不区分符号位和数值位了,我会把所有的内存都看做数值位
你让我输出有符号数,那我在读取内存时会把最高位作为符号位,把剩下的内存作为数值位
说得再直接一些,我管你在定义时是有符号数还是无符号数呢,我只关心内存,有符号数也可以按照无符号数输出,无符号数也可以按照有符号数输出,至于输出结果对不对,那我就不管了,你自己承担风险。下面的代码进行了全面的演示:
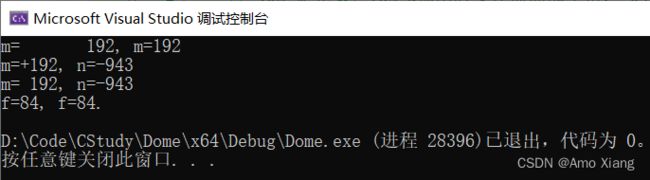
#include 程序运行结果如下图所示:

对于绝大多数初学者来说,b、m、n 的输出结果看起来非常奇怪,甚至不能理解。按照一般的推理,b、m、n 这三个整数在内存中的存储形式分别是:

当以 %x 输出 b 时,结果应该是 0x80000001;当以 %hd、%d 输出 m、n 时,结果应该分别是 -7fff、-0。但是实际的输出结果和我们推理的结果却大相径庭,这是为什么呢?
注意,-7fff 是十六进制形式。%d 本来应该输出十进制,这里只是为了看起来方便,才改为十六进制。
其实这跟整数在内存中的存储形式以及读取方式有关。b 是一个有符号的负数,它在内存中并不是像上图演示的那样存储,而是要经过一定的转换才能写入内存;m、n 的内存虽然没有错误,但是当以 %d 输出时,并不是原样输出,而是有一个逆向的转换过程(和存储时的转换过程恰好相反)。也就是说,整数在写入内存之前可能会发生转换,在读取时也可能会发生转换,而我们没有考虑这种转换,所以才会导致推理错误。那么,整数在写入内存前,以及在读取时究竟发生了怎样的转换呢?为什么会发生这种转换呢?参考文章:https://blog.csdn.net/xw1680/article/details/132417469
无符号数的后缀: C语言中的整数默认都是有符号数,它们的类型通常是 int,添加后缀 l(L) 或者 ll(LL) 可以指定它们的类型为 long 或者 long long。
通过给正整数添加以下几种后缀,可以将它指定为无符号数:
正整数后面紧跟 u 或者 U,表明它的类型是 unsigned int
正整数后面紧跟 ul 或者 UL,表明它的类型是 unsigned long
正整数后面紧跟 ull 或者 ULL,表明它的类型是 unsigned long long
请看下面的代码:
unsigned int a = 10U;
unsigned long b = 100UL;
unsigned long long c = 1000ULL;
其中,100U 是 unsigned int 类型的无符号数;100UL 是 unsigned long 类型的无符号数;1000ULL 是 unsigned long long 类型的无符号数。对于初学者,很少会用到数字的后缀,加不加往往没有什么区别,也不影响实际编程,但是既然学了C语言,还是要知道这个知识点的,万一看到别人的代码这么用了,而你却不明白怎么回事,那就尴尬了。
4.7 C语言整数的取值范围以及数值溢出
short、int、long 和 long long 是 C语言中常用的四种整数类型,分别称为短整型、整型、长整型和超长整形。在现代操作系统中,short、int、long、long long 的长度分别是 2、4、4 或者 8、8,它们只能存储有限的数值,当数值过大或者过小时,超出的部分会被直接截掉,数值就不能正确存储了,我们将这种现象称为 溢出(Overflow)。 溢出的简单理解就是,向木桶里面倒入了过量的水,木桶盛不了了,水就流出来了。要想知道数值什么时候溢出,就得先知道各种整数类型的取值范围。
4.7.1 无符号数的取值范围
计算无符号数 (unsigned 类型) 的取值范围(或者说最大值和最小值)很容易,将内存中的所有位(Bit) 都置为 1 就是最大值,都置为 0 就是最小值。以 unsigned char 类型为例,它的长度是 1,占用 8 位的内存,所有位都置为 1 时,它的值为 28 - 1 = 255,所有位都置为 0 时,它的值很显然为 0。由此可得,unsigned char 类型的取值范围是 0~255。
char 是一个字符类型,是用来存放字符的,但是它同时也是一个整数类型,也可以用来存放整数,请大家暂时先记住这一点,更多细节我们将在 C语言变量和数据类型-下篇 一文中进行介绍。
有读者可能会对 unsigned char 的最大值有疑问,究竟是怎么计算出来的呢?下面我就讲解一下这个小技巧。将 unsigned char 的所有位都置为 1,它在内存中的表示形式为 1111 1111,最直接的计算方法就是:
20 + 21 + 22 + 23 + 24 + 25 + 26 + 27 = 1 + 2 + 4 + 8 + 16 + 32 + 64 + 128 = 255
这种 按部就班 的计算方法虽然有效,但是比较麻烦,如果是 8 个字节的 long 类型,那足够你计算半个小时的了。我们不妨换一种思路,先给 1111 1111 加上 1,然后再减去 1,这样一增一减正好抵消掉,不会影响最终的值。给 1111 1111 加上 1 的计算过程为:
0B1111 1111 + 0B1 = 0B1 0000 0000 = 28 = 256
可以发现,1111 1111 加上 1 后需要向前进位(向第 9 位进位),剩下的 8 位都变成了 0,这样一来,只有第 9 位会影响到数值的计算,剩下的 8 位对数值都没有影响。第 9 位的权值计算起来非常容易,就是:29-1 = 28 = 256 然后再减去 1:
28 - 1 = 256 - 1 = 255
加上 1 是为了便于计算,减去 1 是为了还原本来的值;当内存中所有的位都是 1 时,这种 凑整 的技巧非常实用。按照这种巧妙的方法,我们可以很容易地计算出所有无符号数的取值范围(括号内为假设的长度):

4.7.2 有符号数的取值范围
有符号数以补码的形式存储,计算取值范围也要从补码入手。我们以 char 类型为例,从下表中找出它的取值范围:

我们按照从大到小的顺序将补码罗列出来,很容易发现最大值和最小值。淡黄色背景的那一行是我要重点说明的。如果按照传统的由补码计算原码的方法,那么 1000 0000 是无法计算的,因为计算反码时要减去 1,1000 0000 需要向高位借位,而高位是符号位,不能借出去,所以这就很矛盾。是不是该把 1000 0000 作为无效的补码直接丢弃呢?然而,作为无效值就不如作为特殊值,这样还能多存储一个数字。计算机规定,1000 0000 这个特殊的补码就表示 -128。
为什么偏偏是 -128 而不是其它的数字呢?首先,-128 使得 char 类型的取值范围保持连贯,中间没有 空隙。 其次,我们再按照“传统”的方法计算一下 -128 的补码:-128 的数值位的原码是 1000 0000,共八位,而 char 的数值位只有七位,所以最高位的 1 会覆盖符号位,数值位剩下 000 0000。最终,-128 的原码为 1000 0000。接着很容易计算出反码,为 1111 1111。反码转换为补码时,数值位要加上 1,变为 1000 0000,而 char 的数值位只有七位,所以最高位的 1 会再次覆盖符号位,数值位剩下 000 0000。最终求得的 -128 的补码是 1000 0000。-128 从原码转换到补码的过程中,符号位被 1 覆盖了两次,而负数的符号位本来就是 1,被 1 覆盖多少次也不会影响到数字的符号。你看,虽然从 1000 0000 这个补码推算不出 -128,但是从 -128 却能推算出 1000 0000 这个补码,这么多么的奇妙,-128 这个特殊值选得恰到好处。负数在存储之前要先转换为补码,从 -128 推算出补码 1000 0000 这一点非常重要,这意味着 -128 能够正确地转换为补码,或者说能够正确的存储。
关于零值和最小值
仔细观察上表可以发现,在 char 的取值范围内只有一个零值,没有 +0 和 -0 的区别,并且多存储了一个特殊值,就是 -128,这也是采用补码的另外小小的优势。如果直接采用原码存储,那么 0000 0000 和 1000 0000 将分别表示 +0 和 -0,这样在取值范围内就存在两个相同的值,多此一举。另外,虽然最大值没有变,仍然是 127,但是最小值却变了,只能存储到 -127,不能存储 -128 了,因为 -128 的原码为 1000 0000,这个位置已经被 -0 占用了。
按照上面的方法,我们可以计算出所有有符号数的取值范围(括号内为假设的长度):

4.7.3 数值溢出
char、short、int、long 和 long long 的长度是有限的,当数值过大或者过小时,有限的几个字节就不能表示了,就会发生溢出。发生溢出时,输出结果往往会变得奇怪,请看下面的代码:
#include 程序运行结果如下图所示:

变量 a 为 unsigned int 类型,长度为 4 个字节,能表示的最大值为 0xFFFFFFFF,而 0x100000000 = 0xFFFFFFFF + 1,占用 33 位,已超出 a 所能表示的最大值,所以发生了溢出,导致最高位的 1 被截去,剩下的 32 位都是0。也就是说,a 被存储到内存后就变成了 0,printf 从内存中读取到的也是 0。变量 b 是 int 类型的有符号数,在内存中以补码的形式存储。0xffffffff 的数值位的原码为 1111 1111 …… 1111 1111,共 32 位,而 int 类型的数值位只有 31 位,所以最高位的 1 会覆盖符号位,数值位只留下 31 个 1,所以 b 的原码为:1111 1111 …… 1111 1111,这也是 b 在内存中的存储形式。当 printf 读取到 b 时,由于最高位是 1,所以会被判定为负数,要从补码转换为原码:
[1111 1111 …… 1111 1111]补
= [1111 1111 …… 1111 1110]反
= [1000 0000 …… 0000 0001]原
= -1
最终 b 的输出结果为 -1。
如果想要很好的理解本文后续所讲的内容,一定要仔细认真阅读文章 计算机组成原理之数据的表示和运算(一): https://blog.csdn.net/xw1680/article/details/132417469
至此今天的学习就到此结束了,笔者在这里声明,笔者写文章只是为了学习交流,以及让更多学习C语言的读者少走一些弯路,节省时间,并不用做其他用途,如有侵权,联系博主删除即可。感谢您阅读本篇博文,希望本文能成为您编程路上的领航者。祝您阅读愉快!

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请点赞、评论、收藏一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
编码不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!