Python数据结构与算法篇(十二)-- 树和二叉树
1 树的概念
1.1 定义
树(英语:tree)是一种抽象数据类型(ADT)或是实作这种抽象数据类型的数据结构,用来模拟具有树状结构性质的数据集合。它是由 n n n( n ≥ 1 n\geq 1 n≥1)个有限节点组成一个具有层次关系的集合。把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点:
- 每个节点有零个或多个子节点;
- 没有父节点的节点称为根节点;
- 每一个非根节点有且只有一个父节点;
- 除了根节点外,每个子节点可以分为多个不相交的子树;

1.2 树的术语
- 节点的度:一个节点含有的子树的个数称为该节点的度;
- 树的度:一棵树中,最大的节点的度称为树的度;
- 叶节点或终端节点:度为零的节点;
- 父亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点;
- 孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点;
- 兄弟节点:具有相同父节点的节点互称为兄弟节点;
如下图,A 节点就是 B 节点的父节点,B 节点是 A 节点的子节点。B、C、D 这三个节点的父节点是同一个节点,所以它们之间互称为兄弟节点。我们把没有父节点的节点叫做根节点,也就是图中的节点 E。我们把没有子节点的节点叫做叶子节点或者叶节点,比如图中的 G、H、I、J、K、L 都是叶子节点。

- 节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
- 树的高度或深度:树中节点的最大层次;
- 堂兄弟节点:父节点在同一层的节点互为堂兄弟;
- 节点的祖先:从根到该节点所经分支上的所有节点;
- 子孙:以某节点为根的子树中任一节点都称为该节点的子孙;
- 森林:由 m m m( m ≥ 0 m\geq 0 m≥0)棵互不相交的树的集合称为森林。
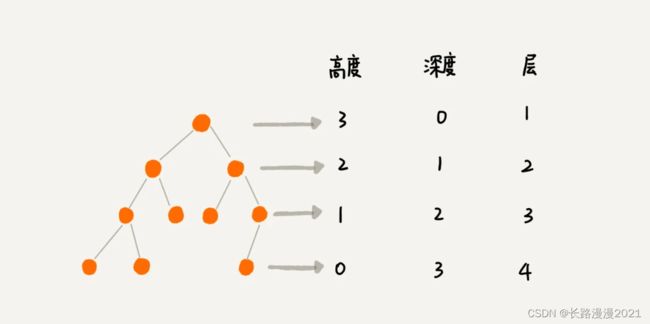
- 深度:对于任意节点n, n 的深度为从根到 n 的唯一路径长,根的深度为0;
- 高度:对于任意节点n, n的高度为从 n 到一片树叶的最长路径长,所有树叶的高度为 0;
- 结点的层次:规定根结点在1层,其它任一结点的层数是其父结点的层数加1
- 树的深度:树中所有结点中的最大层次是这棵树的深度
- 路径和路径长度:从结点n1到nk的路径为一个结点序列 n 1 , n 2 , ⋯ , n k , n i n_1, n_2, \cdots, n_k, n_i n1,n2,⋯,nk,ni 是 n i + 1 n_{i+1} ni+1 的父结点。路径所包含边的个数为路径的长度。
1.3 树的种类
- 无序树:树中任意节点的子节点之间没有顺序关系,这种树称为无序树,也称为自由树;
- 有序树:树中任意节点的子节点之间有顺序关系,这种树称为有序树;
- 二叉树:每个节点最多含有两个子树的树称为二叉树;
- 完全二叉树:对于一颗二叉树,假设其深度为d(d>1)。除了第d层外,其它各层的节点数目均已达最大值,且第d层所有节点从左向右连续地紧密排列,这样的二叉树被称为完全二叉树,其中满二叉树的定义是所有叶节点都在最底层的完全二叉树;
- 平衡二叉树(AVL树):当且仅当任何节点的两棵子树的高度差不大于1的二叉树;
- 排序二叉树(二叉查找树(英语:Binary Search Tree),也称二叉搜索树、有序二叉树);
- 霍夫曼树(用于信息编码):带权路径最短的二叉树称为哈夫曼树或最优二叉树;
- B树:一种对读写操作进行优化的自平衡的二叉查找树,能够保持数据有序,拥有多余两个子树。
- 二叉树:每个节点最多含有两个子树的树称为二叉树;
用图片来展示什么是完全二叉树,请看下图:

下面这两棵树都是搜索树
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 它的左、右子树也分别为二叉排序树

最后一棵 不是平衡二叉树,因为它的左右两个子树的高度差的绝对值超过了1。

1.4 树的存储和表示
1. 链式存储法
一种基于指针或者引用的二叉链式存储法,每个节点有三个字段,其中一个存储数据,另外两个是指向左右子节点的指针。我们只要拎住根节点,就可以通过左右子节点的指针,把整棵树都串起来。这种存储方式我们比较常用。大部分二叉树代码都是通过这种结构来实现的。结构如下图:

2. 顺序存储法
顺序存储:将数据结构存储在固定的数组中,然在遍历速度上有一定的优势,但因所占空间比较大,是非主流二叉树。我们把根节点存储在下标 i = 1 的位置,那左子节点存储在下标 2 * i = 2 的位置,右子节点存储在 2 * i + 1 = 3 的位置。以此类推,B 节点的左子节点存储在 2 * i = 2 * 2 = 4 的位置,右子节点存储在 2 * i + 1 = 2 * 2 + 1 = 5 的位置。即如果节点 X 存储在数组中下标为 i 的位置,下标为 2 * i 的位置存储的就是左子节点,下标为 2 * i + 1 的位置存储的就是右子节点。
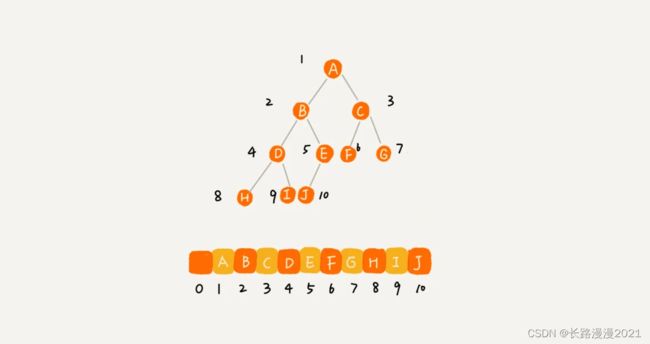
不过上图是一颗完全二叉树,所以数组仅仅浪费了下标为0的存储位置,如果是非完全二叉树,则可能会浪费比较多的数组内存空间。所以当要存储的树是一颗完全二叉树时,数组才是最合适的选择。所以,二叉树通常以链式存储。
2 二叉树
二叉树是每个节点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。
2.1 二叉树的性质
1.层结点
在二叉树的第 i i i 层上最多有 2 i − 1 2^{i-1} 2i−1 个结点(i>=1)
2.总结点
深度为 k k k 的二叉树最多有 2 k + 1 − 1 2^{k+1}-1 2k+1−1 个结点(k>=1)
3.深度
具有 n n n 个结点的完全二叉树的深度为 ⌊ log 2 n ⌋ \lfloor \log_{2}n \rfloor ⌊log2n⌋
4. 结点数
对于任意一棵二叉树,度为 0 的结点数等于度为 2 的结点数 +1。
5. 孩子结点
对完全二叉树,若从上至下、从左至右编号,则编号为 i i i 的结点,其左孩子编号必为 2 i 2i 2i,其右孩子编号必为 2 i + 1 2i+1 2i+1 ;其双亲的编号必为i/2(i=1 时为根,除外)
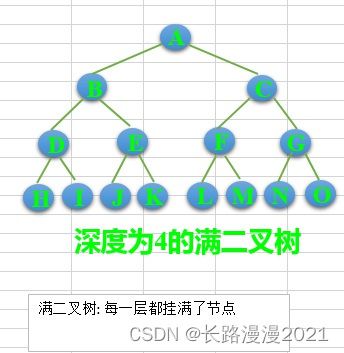
完全二叉树————若设二叉树的高度为 h h h,除第 h h h 层外,其它各层 ( 1 h − 1 ) (1~h-1) (1 h−1) 的结点数都达到最大个数,第 h h h 层有叶子结点,并且叶子结点都是从左到右依次排布,这就是完全二叉树。

满二叉树——除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。
2.2 二叉树的实现
1. 列表实现
#! /user/bin/env python3
# -*- coding:utf-8 -*-
"""
@author: CarpeDiem
@date: 23/2/27
@version: 0.1
@description: 树的列表实现
"""
def binary_tree(r):
return [r, [], []]
def insert_left(root, new_branch):
t = root.pop(1) # 取出左子树
if len(t) > 1: # 左子树已存在
root.insert(1, [new_branch, t, []])
else:
root.insert(1, [new_branch, [], []])
return root
def insert_right(root, new_branch):
t = root.pop(2) # 取出右子树
if len(t) > 1: # 右子树已存在
root.insert(2, [new_branch, [], t])
else:
root.insert(2, [new_branch, [], []])
return root
def get_root_val(root):
return root[0]
def set_root_val(root, new_val):
root[0] = new_val
def get_left_child(root):
return root[1]
def get_right_child(root):
return root[2]
r = binary_tree(3)
insert_left(r, 4)
insert_left(r, 5)
insert_right(r, 6)
insert_right(r, 7)
print(r)
l = get_left_child(r)
print(l)
set_root_val(l, 9)
print(r)
insert_left(l, 11)
print(r)
print(get_right_child(get_right_child(r)))
2. 链表实现
class BinaryTree:
def __init__(self, root_obj):
self.key = root_obj
self.left_child = None
self.right_child = None
def insert_left(self, new_node):
if self.left_child == None:
self.left_child = BinaryTree(new_node)
else:
t = BinaryTree(new_node)
t.left_child = self.left_child
self.left_child = t
def insert_right(self, new_node):
if self.right_child == None:
self.right_child = BinaryTree(new_node)
else:
t = BinaryTree(new_node)
t.right_child = self.right_child
self.right_child = t
def get_right_child(self):
return self.right_child
def get_left_child(self):
return self.left_child
def set_root_val(self, obj):
self.key = obj
def get_root_val(self):
return self.key
2.3 二叉树的遍历
二叉树主要有两种遍历方式:
- 深度优先遍历:先往深走,遇到叶子节点再往回走。
- 广度优先遍历:一层一层的去遍历。
从深度优先遍历和广度优先遍历进一步拓展,才有如下遍历方式:
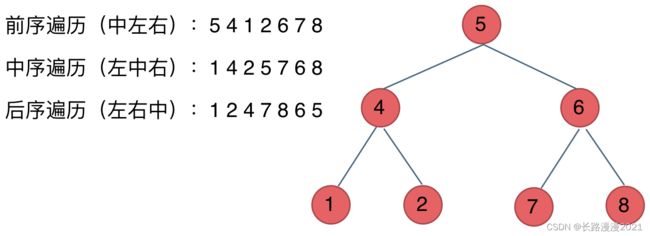
- 深度优先遍历
- 前序遍历(递归法,迭代法)
- 中序遍历(递归法,迭代法)
- 后序遍历(递归法,迭代法)
- 广度优先遍历
- 层次遍历(迭代法)
下面以LeetCode为例,如下:
class TreeNode:
def __init__(self, value):
self.value = value
self.left = None
self.right = None
2.3.1 前序遍历
- 遍历顺序:根结点->左子树->右子树
- 动态图解:和上面的动态图一样,先序遍历就像一个小人从根结点开始,围绕二叉树的外圈开始跑(遇到缝隙就钻进去),按照跑的顺序,依次输出序列
1. 递归遍历
class Solution:
def preorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
# 递归实现
self.result = [] # 使用布局变量存储结果
self.traverse(root)
return self.result
def traversal(self, root):
if not root: return
self.result.append(root.val) # 前序
self.traverse(root.left) # 左
self.traverse(root.right) # 右
2. 迭代遍历
前序遍历是中左右,每次先处理的是中间节点,那么先将根节点放入栈中,然后将右孩子加入栈,再加入左孩子。
为什么要先加入 右孩子,再加入左孩子呢? 因为这样出栈的时候才是中左右的顺序。
class Solution:
def preorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
# 迭代法
if not root: return []
stack = [root]
result = []
while stack:
node = stack.pop()
result.append(node.val) # 中结点先处理
if node.right:
stack.append(node.right) # 右子树先入栈
if node.left:
stack.append(node.left) # 左子树先入栈
return result
2.3.2 中序遍历
- 遍历顺序:左子树->根结点->右子树
- 动态图解:中序遍历就像投影仪一样,将二叉树从最左侧到最右侧依次投影到同一水平线上面,得到的从左到右的相关序列就是二叉树的中序遍历
1. 递归遍历
class Solution:
def inorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
self.result = []
self.traversal(root)
return self.result
def traversal(self, root: Optional[TreeNode]):
if not root: return
self.traversal(root.left) # 前
self.result.append(root.val) # 中
self.traversal(root.right) # 后
2. 顺序遍历
分析一下为什么前面写的前序遍历的代码,不能和中序遍历通用呢,因为前序遍历的顺序是中左右,先访问的元素是中间节点,要处理的元素也是中间节点,所以刚刚才能写出相对简洁的代码,因为要访问的元素和要处理的元素顺序是一致的,都是中间节点。
那么再看看中序遍历,中序遍历是左中右,先访问的是二叉树顶部的节点,然后一层一层向下访问,直到到达树左面的最底部,再开始处理节点(也就是在把节点的数值放进result数组中),这就造成了处理顺序和访问顺序是不一致的。
那么在使用迭代法写中序遍历,就需要借用指针的遍历来帮助访问节点,栈则用来处理节点上的元素。
class Solution:
def inorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
if not root: return []
stack = [] # 不能提前将root结点加入stack中
result = []
cur = root
while cur or stack:
if cur: # 先迭代访问最底层的左子树结点
stack.append(cur)
cur = cur.left
else: # 到达最左节点后处理栈顶结点
cur = stack.pop()
result.append(cur.val)
cur = cur.right # 取栈顶元素右节点
return result
2.3.3 后序遍历
- 遍历顺序:左子树->右子树->根结点
- 动态图解: 后序遍历也是按照先序遍历的顺序输出,不过后序遍历就像剪葡萄,只能一个个剪,不能让超过1个的葡萄一起掉下来,那就错了。例如上图中的 B,剪去 B 后面的 D、E、H、I、J 都会掉下来,而 H 剪去只会掉下 H,规律就是这个规律
1. 递归遍历
class Solution:
def postorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
self.result = []
self.traversal(root)
return self.result
def traversal(self, root: Optional[TreeNode])-> List[int]:
if not root: return
self.traversal(root.left) # 左
self.traversal(root.right) # 右
self.result.append(root.val) # 中
2. 顺序遍历
先序遍历是中左右,后续遍历是左右中,那么我们只需要调整一下先序遍历的代码顺序,就变成中右左的遍历顺序,然后在反转result数组,输出的结果顺序就是左右中了,如下图:

class Solution:
def postorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
# 迭代遍历
if not root: return []
stack = [root]
result = []
while stack:
node = stack.pop()
result.append(node.val) # 中结点先处理
if node.left: stack.append(node.left) # 左子树先入栈
if node.right: stack.append(node.right) # 右子树后入栈
return result[::-1] # 将最终数组反转
2.3.4 层序遍历
层序遍历一个二叉树。就是从左到右一层一层的去遍历二叉树。这种遍历的方式和我们之前讲过的都不太一样。
需要借用一个辅助数据结构即队列来实现,队列先进先出,符合一层一层遍历的逻辑,而用栈先进后出适合模拟深度优先遍历也就是递归的逻辑。
而这种层序遍历方式就是图论中的广度优先遍历,只不过我们应用在二叉树上。
使用队列实现二叉树广度优先遍历,动画如下:
1. 迭代法
from collections import deque
class Solution:
# 二叉树层序遍历迭代解法
if not root: return []
results = []
que = deque([root])
while que:
size = len(que)
result = []
for _ in range(size): # 这里一定要使用固定大小size,不要使用len(que),因为len(que)是不断变化的
cur = que.popleft()
result.append(cur.val)
if cur.left:
que.append(cur.left)
if cur.right:
que.append(cur.right)
results.append(result)
return results
2. 递归法
from collections import deque
class Solution:
# 递归法
def levelOrder(self, root: Optional[TreeNode]) -> List[List[int]]:
self.res = []
self.helper(root, 0)
return self.res
def helper(self, root: Optional[TreeNode], depth) -> Optional:
if not root: return []
if len(self.res) == depth: self.res.append([])
self.res[depth].append(root.val)
if root.left: self.helper(root.left, depth+1)
if root.right: self.helper(root.right, depth+1)
二叉树基础部分已整理完毕,后面在学习中持续补充,谢谢大家的鼓励和支持!

参考
- 树结构详解:http://c.biancheng.net/data_structure/tree/
- 树和二叉树全面总结:https://juejin.cn/post/7065513748789723150
- 数据结构与算法————二叉树:https://www.cnblogs.com/jasonbourne3/p/17143620.html
- 二叉树入门和刷题:https://zhuanlan.zhihu.com/p/136758152