Java应用调优实战-工具支持
哪些资源,容易成为瓶颈
当系统存在短板时,就会对性能造成较大的负面影响,比如当 CPU 的负载特别高时,任务就会排队,不能及时执行。而其中,CPU、内存、I/O 这三个系统组件,又往往容易成为瓶颈,所以接下来我会对这三方面分别进行讲解。
CPU
首先介绍计算机中最重要的计算组件中央处理器 CPU,围绕 CPU 一般我们可以:
- 通过 top 命令,来观测 CPU 的性能;
- 通过负载,评估 CPU 任务执行的排队情况;
- 通过 vmstat,看 CPU 的繁忙程度。
具体情况如下。
- top 命令 —— CPU 性能
如下图,当进入 top 命令后,按 1 键即可看到每核 CPU 的运行指标和详细性能。

CPU 的使用有多个维度的指标,下面分别说明:
us 用户态所占用的 CPU 百分比,即引用程序所耗费的 CPU;
sy 内核态所占用的 CPU 百分比,需要配合 vmstat 命令,查看上下文切换是否频繁;
ni 高优先级应用所占用的 CPU 百分比;
wa 等待 I/O 设备所占用的 CPU 百分比,经常使用它来判断 I/O 问题,过高输入输出设备可能存在非常明显的瓶颈;
hi 硬中断所占用的 CPU 百分比;
si 软中断所占用的 CPU 百分比;
st 在平常的服务器上这个值很少发生变动,因为它测量的是宿主机对虚拟机的影响,即虚拟机等待宿主机 CPU 的时间占比,这在一些超卖的云服务器上,经常发生;
id 空闲 CPU 百分比。
一般地,我们比较关注空闲 CPU 的百分比,它可以从整体上体现 CPU 的利用情况。
- 负载 —— CPU 任务排队情况
如果我们评估 CPU 任务执行的排队情况,那么需要通过负载(load)来完成。除了 top 命令,使用 uptime 命令也能够查看负载情况,load 的效果是一样的,分别显示了最近 1min、5min、15min 的数值。
那 load 为 1 代表的是啥?针对这个问题,误解还是比较多的。
很多人看到 load 的值达到 1,就认为系统负载已经到了极限。这在单核的硬件上没有问题,但在多核硬件上,这种描述就不完全正确,它还与 CPU 的个数有关。例如:
(1). 单核的负载达到 1,总 load 的值约为 1;
(2). 双核的每核负载都达到 1,总 load 约为 2;
(3). 四核的每核负载都达到 1,总 load 约为 4。
所以,对于一个 load 到了 10,却是 16 核的机器,你的系统还远没有达到负载极限。
- vmstat —— CPU 繁忙程度
要看 CPU 的繁忙程度,可以通过 vmstat 命令,下图是 vmstat 命令的一些输出信息。

比较关注的有下面几列:
(1)b 如果系统有负载问题,就可以看一下 b 列(Uninterruptible Sleep),它的意思是等待 I/O,可能是读盘或者写盘动作比较多;
(2)si/so 显示了交换分区的一些使用情况,交换分区对性能的影响比较大,需要格外关注;
(3)cs 每秒钟上下文切换(Context Switch)的数量,如果上下文切换过于频繁,就需要考虑是否是进程或者线程数开的过多。
每个进程上下文切换的具体数量,可以通过查看内存映射文件获取,如下代码所示:
[root@localhost ~]# cat /proc/2788/status
...
voluntary_ctxt_switches: 93950
nonvoluntary_ctxt_switches: 171204
内存
-
top 命令

如上图所示,我们看一下内存的几个参数,从 top 命令可以看到几列数据,注意方块框起来的三个区域,解释如下:
(1)VIRT 这里是指虚拟内存,一般比较大,不用做过多关注;
(2)RES 我们平常关注的是这一列的数值,它代表了进程实际占用的内存,平常在做监控时,主要监控的也是这个数值;
(3)SHR 指的是共享内存,比如可以复用的一些 so 文件等。 -
CPU 缓存
由于 CPU 和内存之间的速度差异非常大,解决方式就是加入高速缓存。实际上,这些高速缓存往往会有多层,如下图所示。
在 Java 中,和 CPU 缓存相关的最典型的知识点,就是在并发编程中,针对 Cache line 的伪共享(False Sharing)问题。
伪共享指的是在这些高速缓存中,以缓存行为单位进行存储,哪怕你修改了缓存行中一个很小很小的数据,它都会整个刷新。所以,当多线程修改一些变量的值时,如果这些变量都在同一个缓存行里,就会造成频繁刷新,无意中影响彼此的性能。
CPU 的每个核,基本是相同的,我们拿 CPU0 来说,可以通过以下的命令查看它的缓存行大小,这个值一般是 64。
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
cat /sys/devices/system/cpu/cpu0/cache/index1/coherency_line_size
cat /sys/devices/system/cpu/cpu0/cache/index2/coherency_line_size
cat /sys/devices/system/cpu/cpu0/cache/index3/coherency_line_size
当然,通过 cpuinfo 也能得到一样的结果:
# cat /proc/cpuinfo | grep cache
cache size : 20480 KB
cache_alignment : 64
cache size : 20480 KB
cache_alignment : 64
cache size : 20480 KB
cache_alignment : 64
cache size : 20480 KB
cache_alignment : 64
在 JDK8 以上的版本,通过开启参数 -XX:-RestrictContended,就可以使用注解 @sun.misc.Contended 进行补齐,来避免伪共享的问题。具体情况,在 12 课时并行优化中,我们再详细讲解。
-
HugePage
传统的页大小是 4KB,在大内存时代这个值偏小了,解决的办法就是增加页的尺寸,比如将其增加到 2MB,这样,就可以使用较少的映射表来管理大内存。而这种将页增大的技术,就是 Huge Page。
同时,HugePage 也伴随着一些副作用,比如竞争加剧,但在一些大内存的机器上,开启后在一定程度上会增加性能。 -
预先加载
另外,一些程序的默认行为也会对性能有所影响,比如 JVM 的 -XX:+AlwaysPreTouch 参数。
I/O
I/O 设备可能是计算机里速度最慢的组件了,它指的不仅仅是硬盘,还包括外围的所有设备。
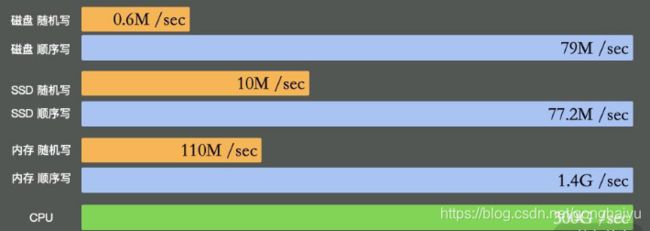
如上图所示,可以看到普通磁盘的随机写与顺序写相差非常大,但顺序写与 CPU 内存依旧不在一个数量级上。
缓冲区依然是解决速度差异的唯一工具,但在极端情况下,比如断电时,就产生了太多的不确定性,这时这些缓冲区,都容易丢。由于这部分内容的篇幅比较大,我将在第 06 课时专门讲解。
- iostat
最能体现 I/O 繁忙程度的,就是 top 命令和 vmstat 命令中的 wa%。如果你的应用写了大量的日志,I/O wait 就可能非常高。
- 零拷贝
硬盘上的数据,在发往网络之前,需要经过多次缓冲区的拷贝,以及用户空间和内核空间的多次切换。如果能减少一些拷贝的过程,效率就能提升,所以零拷贝应运而生。
零拷贝是一种非常重要的性能优化手段,比如常见的 Kafka、Nginx 等,就使用了这种技术。我们来看一下有无零拷贝之间的区别。
(1)没有采取零拷贝手段
如下图所示,传统方式中要想将一个文件的内容通过 Socket 发送出去,则需要经过以下步骤:
a. 将文件内容拷贝到内核空间;
b. 将内核空间内存的内容,拷贝到用户空间内存,比如 Java 应用读取 zip 文件;
c. 用户空间将内容写入到内核空间的缓存中;
d. Socket 读取内核缓存中的内容,发送出去。
(2)采取了零拷贝手段
零拷贝有多种模式,我们用 sendfile 来举例。如下图所示,在内核的支持下,零拷贝少了一个步骤,那就是内核缓存向用户空间的拷贝,这样既节省了内存,也节省了 CPU 的调度时间,让效率更高。Netty中有大量的这种操作。包括FileChannel.transferTo()。

如何获取代码性能数据?
磁盘之所以慢,主要就是慢在寻道的操作上面。Kafka 官方测试表明,这个寻道时间长达 10ms。磁盘的顺序写和随机写的速度比,可以达到 6 千倍,Kafka 就是采用的顺序写的方式。
经过上一课时我们了解到,想要进行深入排查,需要收集较详细的性能数据,包括操作系统性能数据、JVM 的性能数据、应用的性能数据等。
nmon —— 获取系统性能数据
除了在上一课时中介绍的 top、free 等命令,还有一些将资源整合在一起的监控工具,nmon 便是一个老牌的 Linux 性能监控工具,它不仅有漂亮的监控界面(如下图所示),还能产出细致的监控报表。
我在对应用做性能评估时,通常会加上 nmon 的报告,这会让测试结果更加有说服力。你在平时工作中也可如此尝试。
上一课时介绍的一些操作系统性能指标,都可从 nmon 中获取。它的监控范围很广,包括 CPU、内存、网络、磁盘、文件系统、NFS、系统资源等信息。
nmon 在 sourceforge 发布,我已经下载下来并上传到了仓库中。比如我的是 CentOS 7 系统,选择对应的版本即可执行。
./nmon_x86_64_centos7
按 C 键可加入 CPU 面板;按 M 键可加入内存面板;按 N 键可加入网络;按 D 键可加入磁盘等。
通过下面的命令,表示每 5 秒采集一次数据,共采集 12 次,它会把这一段时间之内的数据记录下来。比如本次生成了 localhost_200623_1633.nmon 这个文件,我们把它从服务器上下载下来。
./nmon_x86_64_centos7 -f -s 5 -c 12 -m -m .
注意:执行命令之后,可以通过 ps 命令找到这个进程。
[root@localhost nmon16m_helpsystems]# ps -ef| grep nmon
root 2228 1 0 16:33 pts/0 00:00:00 ./nmon_x86_64_centos7 -f -s 5 -c 1
使用 nmonchart 工具(见仓库),即可生成 html 文件。下面是生成文件的截图。
jvisualvm —— 获取 JVM 性能数据
jvisualvm 原是随着 JDK 发布的一个工具,Java 9 之后开始单独发布。通过它,可以了解应用在运行中的内部情况。我们可以连接本地或者远程的服务器,监控大量的性能数据。
要想监控远程的应用,还需要在被监控的 App 上加入 jmx 参数。
-Dcom.sun.management.jmxremote.port=14000
-Dcom.sun.management.jmxremote.authenticate=false
-Dcom.sun.management.jmxremote.ssl=false
上述配置的意义是开启 JMX 连接端口 14000,同时配置不需要 SSL 安全认证方式连接。
对于性能优化来说,我们主要用到它的采样器。注意,由于抽样分析过程对程序运行性能有较大的影响,一般我们只在测试环境中使用此功能。
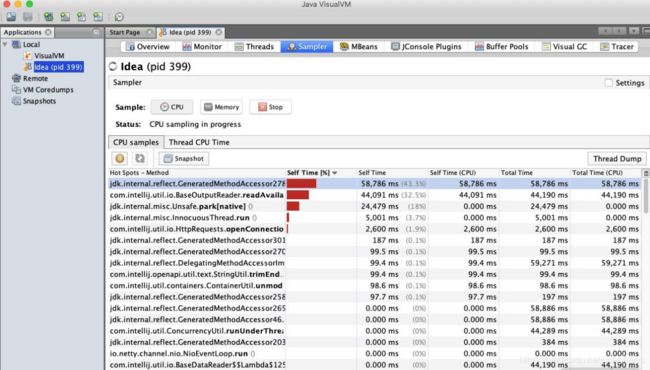
对于一个 Java 应用来说,除了要关注它的 CPU 指标,垃圾回收方面也是不容忽视的性能点,我们主要关注以下三点。
- CPU 分析:统计方法的执行次数和执行耗时,这些数据可用于分析哪个方法执行时间过长,成为热点等。
- 内存分析:可以通过内存监视和内存快照等方式进行分析,进而检测内存泄漏问题,优化内存使用情况。
- 线程分析:可以查看线程的状态变化,以及一些死锁情况。
JMC —— 获取 Java 应用详细性能数据
对于我们常用的 HotSpot 来说,有更强大的工具,那就是 JMC。 JMC 集成了一个非常好用的功能:JFR(Java Flight Recorder)。
Flight Recorder 源自飞机的黑盒子,是用来录制信息然后事后分析的。在 Java11 中,它可以通过 jcmd 命令进行录制,主要包括 configure、check、start、dump、stop 这五个命令,其执行顺序为,start — dump — stop,例如:
jcmd JFR.start
jcmd JFR.dump filename=recording.jfr
jcmd JFR.stop
JFR 功能是建在 JVM 内部的,不需要额外依赖,可以直接使用,它能够监测大量数据。比如,我们提到的锁竞争、延迟、阻塞等;甚至在 JVM 内部,比如 SafePoint、JIT 编译等,也能去分析。
JMC 集成了 JFR 的功能,下面介绍一下 JMC 的使用。
-
录制
下图是录制了一个 Tomcat 一分钟之后的结果,从左边的菜单栏即可进入相应的性能界面。

通过录制数据,可以清晰了解到某一分钟内,操作系统资源,以及 JVM 内部的性能数据情况。 -
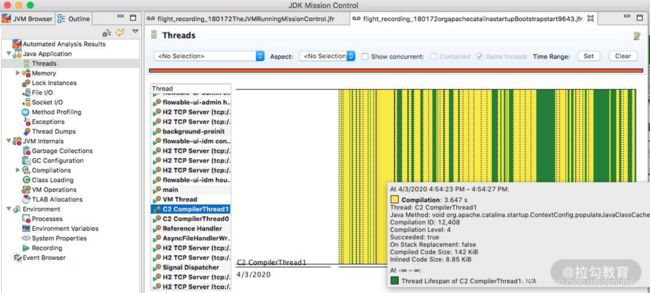
线程
选择相应的线程,即可了解线程的执行情况,比如 Wait、Idle 、Block 等状态和时序。
以 C2 编译器线程为例,可以看到详细的热点类,以及方法内联后的代码大小。如下图所示,C2 此时正在疯狂运转。
3. 内存
通过内存界面,可以看到每个时间段内内存的申请情况。在排查内存溢出、内存泄漏等情况时,这个功能非常有用。
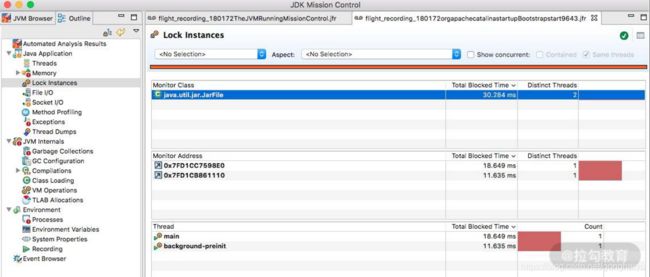
- 锁
一些竞争非常严重的锁信息,以及一些死锁信息,都可以在锁信息界面中找到。
可以看到,一些锁的具体 ID,以及关联的线程信息,都可以进行联动分析。
5. 文件和 Socket
文件和 Socket 界面能够监控对 I/O 的读写,界面一目了然。如果你的应用 I/O 操作比较繁重,比如日志打印比较多、网络读写频繁,就可以在这里监控到相应的信息,并能够和执行栈关联起来。

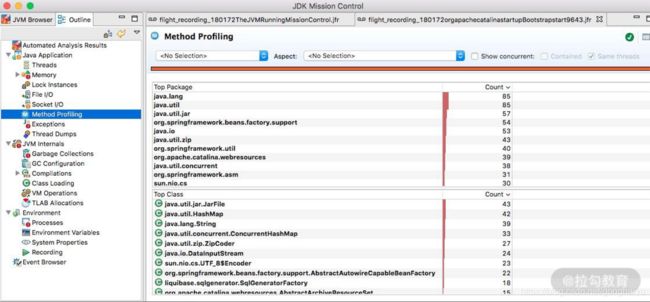
- 方法调用
这个和 jvisualvm 的功能类似,展示的是方法调用信息和排行。从这里可以看到一些高耗时方法和热点方法。
7. 垃圾回收
如果垃圾回收过于频繁,就会影响应用的性能。JFR 对垃圾回收进行了详细的记录,比如什么时候发生了垃圾回收,用的什么垃圾回收器,每次垃圾回收的耗时,甚至是什么原因引起的等问题,都可以在这里看到。

8. JIT
JIT 编译后的代码,执行速度会特别快,但它需要一个编译过程。编译界面显示了详细的 JIT 编译过程信息,包括生成后的 CodeCache 大小、方法内联信息等。

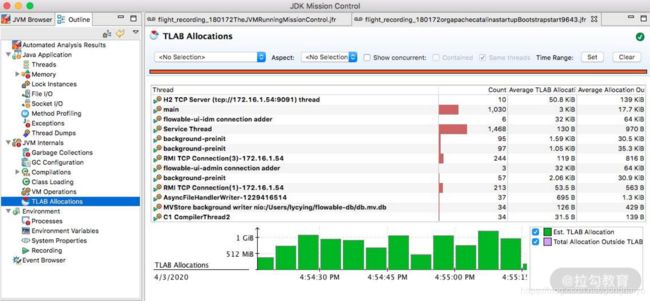
9. TLAB
JVM 默认给每个线程开辟一个 buffer 区域,用来加速对象分配,这就是 TLAB(Thread Local Allocation Buffer)的概念。这个 buffer,就放在 Eden 区。
原理和 Java 语言中的 ThreadLocal 类似,能够避免对公共区的操作,可以减少一些锁竞争。如下图所示的界面,详细地显示了这个分配过程。
Arthas —— 获取单个请求的调用链耗时
Arthas 是一个 Java 诊断工具,可以排查内存溢出、CPU 飙升、负载高等内容,可以说是一个 jstack、jmap 等命令的大集合。
有时候,我们统计到某个接口的耗时非常高,但又无法找到具体原因时,就可以使用这个 trace 命令。该命令会从方法执行开始记录整个链路上的执行情况,然后统计每个节点的性能开销,最终以树状打印,很多性能问题一眼就能看出来。
下面就是一个执行结果示例。
$ trace demo.MathGame run
Press Q or Ctrl+C to abort.
Affect(class-cnt:1 , method-cnt:1) cost in 28 ms.
`---ts=2019-12-04 00:45:08;thread_name=main;id=1;is_daemon=false;priority=5;TCCL=sun.misc.Launcher$AppClassLoader@3d4eac69
`---[0.617465ms] demo.MathGame:run()
`---[0.078946ms] demo.MathGame:primeFactors() #24 [throws Exception]
`---ts=2019-12-04 00:45:09;thread_name=main;id=1;is_daemon=false;priority=5;TCCL=sun.misc.Launcher$AppClassLoader@3d4eac69
`---[1.276874ms] demo.MathGame:run()
`---[0.03752ms] demo.MathGame:primeFactors() #24 [throws Exception]
wrk —— 获取 Web 接口的性能数据
wrk(点击进入 GitHub 网站查看)是一款 HTTP 压测工具,和 ab 命令类似,它也是一个命令行工具。
Running 30s test @ http://127.0.0.1:8080/index.html
12 threads and 400 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 635.91us 0.89ms 12.92ms 93.69%
Req/Sec 56.20k 8.07k 62.00k 86.54%
22464657 requests in 30.00s, 17.76GB read
Requests/sec: 748868.53
Transfer/sec: 606.33MB
可以看到,wrk 统计了常见的性能指标,对 Web 服务性能测试非常有用。同时,wrk 支持 Lua 脚本,用来控制 setup、init、delay、request、response 等函数,可以更好地模拟用户请求。
基准测试 JMH,精确测量方法性能
JMH—基准测试工具
JMH(the Java Microbenchmark Harness)就是这样一个能做基准测试的工具。如果你通过 04 课时介绍的一系列外部工具,定位到了热点代码,要测试它的性能数据,评估改善情况,就可以交给 JMH。它的测量精度非常高,可达纳秒级别。
JMH 已经在 JDK 12中被包含,其他版本的需要自行引入 maven,坐标如下:
<dependencies>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>1.23</version>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>1.23</version>
<scope>provided</scope>
</dependency>
</dependencies>
JMH 是一个 jar 包,它和单元测试框架 JUnit 非常像,可以通过注解进行一些基础配置。这部分配置有很多是可以通过 main 方法的 OptionsBuilder 进行设置的。
下面,我们介绍一下这个工具的使用。
JMH 是一个 jar 包,它和单元测试框架 JUnit 非常像,可以通过注解进行一些基础配置。这部分配置有很多是可以通过 main 方法的 OptionsBuilder 进行设置的。

上图是一个典型的 JMH 程序执行的内容。通过开启多个进程,多个线程,先执行预热,然后执行迭代,最后汇总所有的测试数据进行分析。在执行前后,还可以根据粒度处理一些前置和后置操作。
一段简单的 JMH 代码如下所示:
@BenchmarkMode(Mode.Throughput)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@State(Scope.Thread)
@Warmup(iterations = 3, time = 1, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Fork(1)
@Threads(2)
public class BenchmarkTest {
@Benchmark
public long shift() {
long t = 455565655225562L;
long a = 0;
for (int i = 0; i < 1000; i++) {
a = t >> 30;
}
return a;
}
@Benchmark
public long div() {
long t = 455565655225562L;
long a = 0;
for (int i = 0; i < 1000; i++) {
a = t / 1024 / 1024 / 1024;
}
return a;
}
public static void main(String[] args) throws Exception {
Options opts = new OptionsBuilder()
.include(BenchmarkTest.class.getSimpleName())
.resultFormat(ResultFormatType.JSON)
.build();
new Runner(opts).run();
}
}
下面,我们逐一介绍一下比较关键的注解和参数。
关键注解
- @Warmup
样例如下:
@Warmup(
iterations = 5,
time = 1,
timeUnit = TimeUnit.SECONDS)
我们不止一次提到预热 warmup 这个注解,可以用在类或者方法上,进行预热配置。可以看到,它有几个配置参数:
timeUnit:时间的单位,默认的单位是秒;
iterations:预热阶段的迭代数;
time:每次预热的时间;
batchSize:批处理大小,指定了每次操作调用几次方法。
上面的注解,意思是对代码预热总计 5 秒(迭代 5 次,每次一秒)。预热过程的测试数据,是不记录测量结果的。
我们可以看一下它执行的效果:
# Warmup: 3 iterations, 1 s each
# Warmup Iteration 1: 0.281 ops/ns
# Warmup Iteration 2: 0.376 ops/ns
# Warmup Iteration 3: 0.483 ops/ns
一般来说,基准测试都是针对比较小的、执行速度相对较快的代码块,这些代码有很大的可能性被 JIT 编译、内联,所以在编码时保持方法的精简,是一个好的习惯。具体优化过程,我们将在 18 课时介绍。
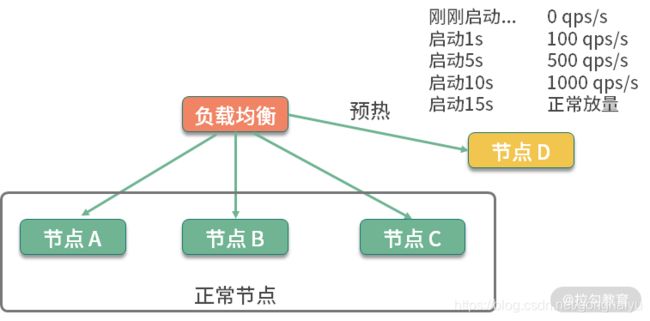
说到预热,就不得不提一下在分布式环境下的服务预热。在对服务节点进行发布的时候,通常也会有预热过程,逐步放量到相应的服务节点,直到服务达到最优状态。如下图所示,负载均衡负责这个放量过程,一般是根据百分比进行放量。
总结
事实上,我们经常是等生产有压力的时候,比如偶尔出现OOM时才会去找问题。这个时候,我们必须要在启动产生中加入一些配置,如下所示。否则遇到问题了根本就没办法定位。尤其是一些瞬时压力。
nohup java -Xmx4096m -Xms2048m -XX:PermSize=256m -XX:MaxPermSize=512m -XX:+HeapDumpOnOutOfMemoryError -javaagent:/apps/agent/skywalking-agent.jar -Dskywalking.agent.service_name=app -Dskywalking.collector.backend_service=10.0.60.133:22800 -jar -Dspring.profiles.active=pro $JAR_NAME >/dev/null 2>&1 &