sql基础+考点+题
查询:select + from
筛选:where
and和or
排序:order by(降序排列需要指定DESC关键字)
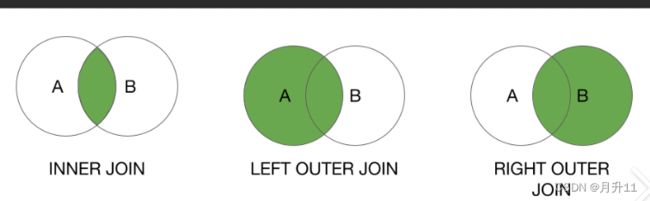
join:left join 、right join 和inner join
分组聚合:group by ---搭配count , sum , avg
过滤:having
通配符:like :“a”%like 、like‘%a%”、like%差不多是这样
增删改查
insert、delete、drop、select
insert into 表名 values (值1,值2……)
delete from表名称 where 列名称 = 值
sql考点
1.首先是sql的执行顺序
from--join--on--where--group by--having--select--distinct--order by--limit
2.去重:distinct
select distinct UID from table结合count函数:count(distinct uid)--表中有多少个不重复的uid
3.对查询数据进行分类--case when
case when col1 in (‘a’,’b’) then 1
when col1 in (‘c’,’d’) then 2
else 0 end as flag根据给定的条件,如果 col1 的值为 ‘a’ 或 ‘b’,则返回 1;如果 col1 的值为 ‘c’ 或 ‘d’,则返回 2;否则,返回 0,这个标志列被命名为 “flag”。函数只会返回第一个符合条件的值
4.Between操作符
between操作符选取介于两个值之间的数据范围内的值,btween 30 and 60 其实等价于 ≥30 and ≤60
5.各种连接方式的区别
inner join:内连接
lelft join、right join、all join:join那边就一那边为准,另一边的不符合的为空了
cross join :交叉连接 结果是笛卡尔积,第一个表符合查询条件的行数乘以第二个表符合查询条件的行数
6.where和on 的区别
在left join中,无论on的条件是否真,都会返回左边中全部的值
但是where就不一样来,where一般都是用在临时表生成以后(连接函数完成之后),对数据进行筛选
on执行在前,where执行在后
where和having的区别
复习一下执行顺序:.....where--group by--having.....
where子句的作用是对查询结果进行分组前将不符合where条件的行去掉,having则是筛选满足条件的组。
注意:在where进行筛选的时候不能使用字段的别名,having的时候可以。
7.索引的作用
索引(标志符号)主要建立在:①经常搜索的列;②主键所在列;③外键所在列
索引包括聚集索引与非聚集索引:区别在于索引记录的顺序与表记录的顺序是否一致
聚集索引:索引记录的顺序与表记录的顺序一致
非聚集索引:索引的顺序与表中数据记录的顺序不一定一致
8.delete和drop的区别?
drop会删除整个表,以后都不能再用
delete知识删除表中的数据,保留表的字段和结构
9.主键和外键是什么?
主键是一张表中能够确定一条记录的唯一标志(数据库中的一条记录中有若干个属性,若其中某一个属性组(注意是组)能唯一标识一条记录,该属性组就可以成为一个主键 ),比如身份证号。
外键用于和另一张表进行关联。例如,A字段是A表的主键,那么出现在B表中的A字段能够作为B表的外键,实现A,B表的连接查询。
10.子查询中in和exist的应用场景?
简单的理解就是主查询和子查询的表是否较大且有索引
主查询表较大且有索引,子查询小就用in
主表小,子查询大且有索引则用exist
11.如何连接多个select的查询结果
union:无重复值,只出现两表共同的值
union all:允许重复值,并且是逐表呈现
intersect:合并两表的相同数据,=交集
minus:
12:排序函数的区别
常用:rank、dense rank、row number
rank:1(100分)、2(99)、2(99)、4(98).....
dense rank :1(100分)、2(99分)、2(99)、3(98)
row number:1、2、3、4、5、6......
13.开窗函数over()
排序函数和非排序函数
排序函数:row number, rank等函数可以给数据排序
非排序函数:sum()over(),sum()over()则是累计求和函数,over()中加入partition by则可进行分区累计求和
重要的开窗函数
count() over(partition by ... order by ...):求分组后的总数。
max () over(partition by ... order by ...):求分组后的最大值。
min () over(partition by ... order by ...):求分组后的最小值。
avg () over(partition by ... order by ...):求分组后的平均值。
lag () over(partition by ... order by ...):分组取出前n行数据。
lead () over(partition by ... order by ...):分组取出后n行数据。
14.mysql和hivesql的区别?
1.存储位置hive是在HDFS中,mysql是存储在自己的系统中
2.子查询:在hive中不使用子查询,会报错或很长时间跑不出来,可以用join和left join等函数
3.拆分字符串:在sql语法中,往往使用substring进行字符串的截取,比如substring(被截取字段,从第几位开始截取,截取长度)。在hive中则是使用split进行分割,比如select split('abcdef', 'c') from test 意味着在‘c’处进行分割,得到的结果为 "ab", "def"。
4.数据格式:hive可以自定义,mysql自己定义的
5.数据更新:hive不支持更新,只能读取,不可写入,mysql支持读写操作
6.索引:hive 没有索引
sql经典问题
1.连续问题
取出连续数据
最常规的思路是借助row_number()over()的开窗函数
首先是row——number函数排序子查询,然后就是用日期列-排序列,相减后得到>n的id
取出不连续的数据
lag()over()函数,这个函数可以将列记录向下,然后用data列-向下列,就可以找找到哦啊
新增用户
用row()number()函数获取用户的登陆时间获取每天新增用户的数量,取出排序为1的记录后,对时间维度对用户id进行去重聚合
用户留存统计
row number后,把表自连接,在on的条件中限定date的差值空值在1-3的范围内筛选
用户相邻点击行为
选出商品销量大于100 的商家=找出销量小于100的商家
where id not in (select id from table4 where cnt<100)
hivesql的写法
select distinct a.id from table4 a left join (select distinct id from table4 where cnt<100)b on a.id=b.id where b.id is null
删除重复数据 delete table5 where index not in (select min(index) from table5 group by product, price 针对SQL部分,下面会有一个场景的具体SQL写法:
假如你是腾讯视频会员的产品经理:有一个会员表,命名为 txsp_vip,三个字段,date,qq,status(1为会员,0为非会员),按 date 分区,每个分区全量数据。(写出对应 SQL语句)
1. 当日会员总量,当日新增会员数,当日回流会员数,当日到期会员数这四个指标怎么算?(注:历史状态统一选取昨天对比)
2. 提取当月的所有新会员号码包
------当日会员总量
select count(distinct qq) from txsp_vip where date='当日日期' and status=1;
------当日新增会员数
select count(distinct a.qq) from
(select qq from txsp_vip where date='当日日期' and status=1) a
left join
(select qq from txsp_vip where date='昨天日期' and status=1) b
on a.qq=b.qq
where b.qq is null
------当日回流会员数
select count(distinct a.qq) from
(select qq from txsp_vip where date='当日日期' and status=1) a
join
(select qq from txsp_vip where date='昨日日期' and status=1) b
on a.qq=b.qq
------当日到期会员数
select count(distinct a.qq) from
(select qq from txsp_vip where date='当日日期' and status=0) a
join
(select qq from txsq_vip where data='昨天日期' and status=1) b
on a.qq=b.qq
------提取当月的所有新会员号码包。
select count(a.qq) from
(select qq from txsp_vip where date>='当月第一天' and date<='当月最后一天' and status=1) a
left join
(select qq from txsp_vip where data='上月最后一天' and status=1) b
on a.qq=b.qq
where b.qq is null
)