Hystrix请求熔断与服务降级
1.1 概述
在微服务架构中,根据业务来拆分成一个个的服务,服务与服务之间可以相互调用·(RPC),在Spring Cloud可以用RestTemplate+Ribbon和Feign来调用。为了保证其高可用,单个服务通常会集群部署。由于网络原因或者自身的原因,服务并不能保证100%可用,如果单个服务出现问题,调用这个服务就会出现线程阻塞,此时若有大量的请求涌入,Servlet容器的线程资源会被消耗完毕,导致服务瘫痪。服务与服务之间的依赖性,故障会传播,会对整个微服务系统造成灾难性的严重后果,这就是服务故障的“雪崩”效应。
为了解决这个问题,业界提出了断路器模型。
Spring Cloud Netflix Hystrix就是隔离措施的一种实现,可以设置在某种超时或者失败情形下断开依赖调用或者返回指定逻辑,从而提高分布式系统的稳定性。
比如:订单系统请求库存系统,结果一个请求过去,因为各种原因,网络超时,在规定几秒内没反应,或者服务本身就挂了,这时候更多的请求来了,不断的请求库存服务,不断的创建线程,因为没有返回,也就资源没有释放,这也导致了系统资源被耗尽,你的服务奔溃了,这订单系统好好的,你访问了一个可能有问题的库存系统,结果导致你的订单系统也奔溃了,你再继续调用更多的依赖服务,可会会导致更多的系统奔溃,这时候Hystrix可以实现快速失败,如果它在一段时间内侦测到许多类似的错误,会强迫其以后的多个调用快速失败,不再访问远程服务器,从而防止应用程序不断地尝试执行可能会失败的操作进而导致资源耗尽。这时候Hystrix进行FallBack操作来服务降级,Fallback相当于是降级操作。对于查询操作, 我们可以实现一个fallback方法,当请求后端服务出现异常的时候,可以使用fallback方法返回的值。fallback方法的返回值一般是设置的默认值或者来自缓存,通知后面的请求告知这服务暂时不可用了。
使得应用程序继续执行而不用等待修正错误,或者浪费CPU时间去等到长时间的超时产生。Hystrix熔断器也可以使应用程序能够诊断错误是否已经修正,如果已经修正,应用程序会再次尝试调用操作。
1.2 Hystrix详解
Netflix开源了Hystrix组件,实现了断路器模式,在微服务架构中,一个请求需要调用多个服务是非常常见的,如下图所示:
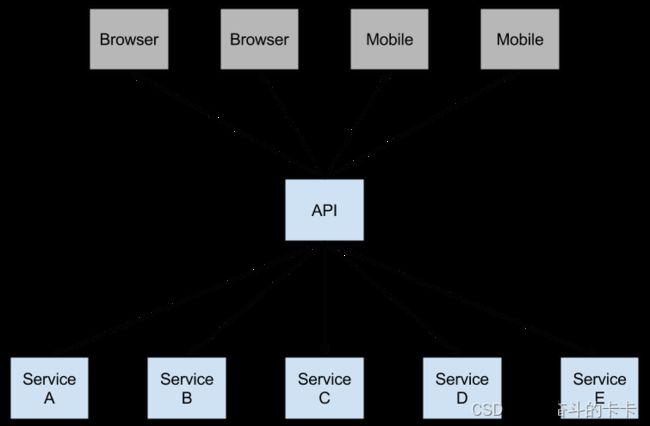
底层服务出现故障可能导致用户级联故障。当调用特定服务达到一定阈值时(Hystrix中的默认值为5秒内的20次故障),电路打开,不进行通话。在开路的情况下,可以使用备用的方法进行处理。如下图所示:
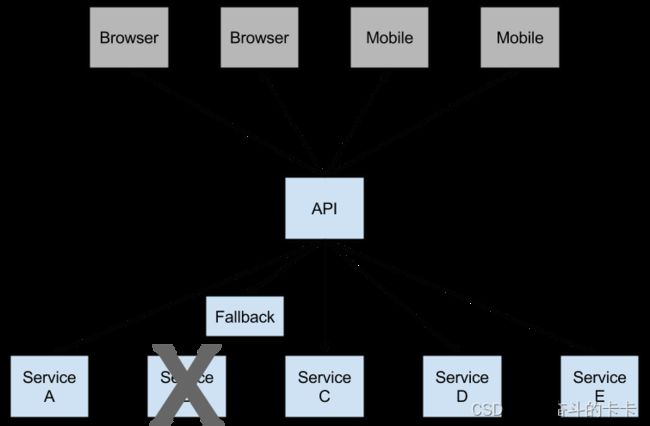
当服务B挂掉或者访问超时后, 断路打开,可用避免连锁故障,fallback方法可以直接返回一个固定值。
1.2.1 Hystrix设计原则
1、防止单个服务的故障,耗尽整个系统服务的容器(比如tomcat)的线程资源,避免分布式环境里大量级联失败。通过第三方客户端访问(通常是通过网络)依赖服务出现失败、拒绝、超时或短路时执行回退逻辑。
2、用快速失败代替排队(每个依赖服务维护一个小的线程池或信号量,当线程池满或信号量满,会立即拒绝服务而不会排队等待)和优雅的服务降级;当依赖服务失效后又恢复正常,快速恢复。
3、提供接近实时的监控和警报,从而能够快速发现故障和修复。监控信息包括请求成功,失败(客户端抛出的异常),超时和线程拒绝。如果访问依赖服务的错误百分比超过阈值,断路器会跳闸,此时服务会在一段时间内停止对特定服务的所有请求。
4、将所有请求外部系统(或请求依赖服务)封装到HystrixCommand或HystrixObservableCommand对象中,然后这些请求在一个独立的线程中执行。使用隔离技术来限制任何一个依赖的失败对系统的影响。每个依赖服务维护一个小的线程池(或信号量),当线程池满或信号量满,会立即拒绝服务而不会排队等待。
1.2.3 Hystrix特性
1、请求熔断:当Hystrix Command请求后端服务失败数量超过一定比例(默认50%),断路器会切换到开路状态(Open)。 这时所有请求会直接失败而不会发送到后端服务。断路器保持在开路状态一段时间后(默认5秒),自动切换到半开路状态(HALF-OPEN)。
这时会判断下一次请求的返回情况,如果请求成功,断路器切回闭路状态(CLOSED), 否则重新切换到开路状态(OPEN)。 Hystrix的断路器就像我们家庭电路中的保险丝, 一旦后端服务不可用, 断路器会直接切断请求链, 避免发送大量无效请求影响系统吞吐量, 并且断路器有自我检测并恢复的能力。
2、服务降级:Fallback相当于是降级操作。 对于查询操作, 我们可以实现一个fallback方法, 当请求后端服务出现异常的时候, 可以使用fallback方法返回的值。 fallback方法的返回值一般是设置的默认值或者来自缓存。告知后面的请求服务不可用了,不要再来了。
3、依赖隔离:在Hystrix中, 主要通过线程池来实现资源隔离。 通常在使用的时候我们会根据调用的远程服务划分出多个线程池。比如说,一个服务调用两外两个服务,你如果调用两个服务都用一个线程池,那么如果一个服务卡在哪里,资源没被释放。
后面的请求又来了,导致后面的请求都卡在哪里等待,导致你依赖的A服务把你卡在哪里,耗尽了资源,也导致了你另外一个B服务也不可用了。这时如果依赖隔离,某一个服务调用A B两个服务,如果这时我有100个线程可用,我给A服务分配50个,给B服务分配50个,这样就算A服务挂了,我的B服务依然可以用。
4、请求缓存:比如一个请求过来请求我userId=1的数据,你后面的请求也过来请求同样的数据,这时我不会继续走原来的那条请求链路了,而是把第一次请求缓存过了,把第一次的请求结果返回给后面的请求。
5、请求合并:我依赖于某一个服务,我要调用N次,比如说查数据库的时候,我发了N条请求发了N条SQL然后拿到一堆结果,这时候我们可以把多个请求合并成一个请求,发送一个查询多条数据的SQL的请求,这样我们只需查询一次数据库,提升了效率。
1.2.4 Hystrix流程图
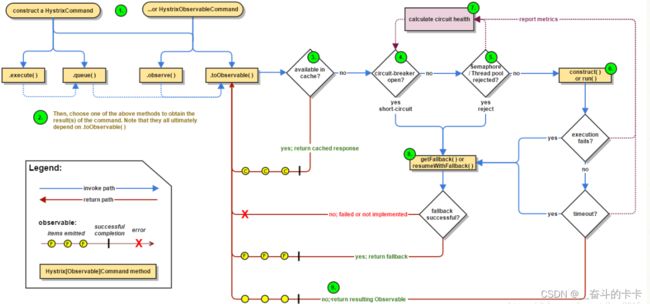
Hystrix流程说明:
1、每次调用创建一个新的HystrixCommand,把依赖调用封装在run()方法中
2、执行execute()/queue做同步或异步调用
3、判断熔断器(circuit-breaker)是否打开,如果打开跳到步骤7,进行降级策略,如果关闭进入步骤4
4、判断线程池/队列/信号量是否跑满,如果跑满进入降级步骤8,否则继续后续步骤5
5、调用HystrixCommand的run方法。运行依赖逻辑
5a、依赖逻辑调用超时,进入步骤7
6、判断逻辑是否调用成功
6a、返回成功调用结果
6、调用出错,进入步骤7
7、计算熔断器状态,所有的运行状态(成功, 失败, 拒绝,超时)上报给熔断器,用于统计从而判断熔断器状态
8、getFallback()降级逻辑。以下四种情况将触发getFallback调用:
(1):run()方法抛出非HystrixBadRequestException异常
(2):run()方法调用超时
(3):熔断器开启拦截调用
(4):线程池/队列/信号量是否跑满
8a、没有实现getFallback的Command将直接抛出异常
8b、fallback降级逻辑调用成功直接返回
8c、降级逻辑调用失败抛出异常
9、返回执行成功结果