让自动驾驶一骑绝尘!BEV-LaneDet:暴涨十个点,单目3D车道线新SOTA!(CVPR'23)...
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【车道线检测】技术交流群
后台回复【车道线综述】获取基于检测、分割、分类、曲线拟合等近几十篇学习论文!
简介
3D车道检测在自动驾驶轨控中起着至关重要的作用,最近成为自动驾驶领域一个快速发展的话题。之前的工作由于其复杂的空间转换模块和不灵活的三维车道表示很难真正在实际业务中应用。面对这些问题,本文提出了一个高效且简单的单目3D车道线检测方法,称为BEV-LaneDet,有三个主要贡献。首先,引入了Virutal Camera,统一了安装在不同车辆上的相机的内/外参数,以保证相机之间空间关系的一致性。由于统一的视觉空间,它可以有效地促进网络的学习过程。其次,提出了一个简单而有效的三维车道表示法,称为关键点表示法(Key-Points Representation), 这个模块更适合于表示复杂多样的三维车道结构。最后,本文提出了一个轻量级和芯片友好的空间转换模块,名为空间转换金字塔(Spatial Transformation Pyramid),用于将多尺度的前视特征转换成BEV特征。实验结果表明,BEV-LaneDet在F-Score方面优于最先进的方法,在OpenLane数据集上高出10.6%,在Apollo 3D合成数据集上高出6.2%,V-100上速度为185FPS。
论文链接:https://arxiv.org/abs/2210.06006
代码链接:https://github.com/gigo-team/bev_lane_det
总结一下:
本文提出了一种简单实用,几乎适用于所有芯片的3D车道线检测方法 BEV-LaneDet。
本文提出了Virtual Camera、Spatial Transformation Pyramid、Key-Points Representation三个模块,创新性没有那么大,但是组合起来非常好用。
在速度飞快的同时,能做到在公开集OpenLane(+10.6%)和Apollo 3D synthetic上大幅度涨点(+6.2%),尤其是Apollo 3D synthetic上F-Score几乎已经刷满了。在总体来讲,这篇文章的工程性大于其学术性。
方法概述
总览

如上图所示,整个网络架构由五个部分组成:1)虚拟相机(Virtual Camera):统一相机内在和外在参数的预处理方法;2)Backbone:前视特征提取器;3)空间转换金字塔(Spatial Transformation Pyarmid)。将前视特征投射到BEV特征;4)关键点表示(Key-Points Representation):基于关键点的三维车头检测器;5)2D图像监督:2D车道检测检测头,提供辅助监督。
主要模块
Virtual Camera
不同车辆的内/外在参数是不同的,这对3D车道线的结果有很大影响。不同于将摄像机内、外参数整合到网络特征中的方法不同(PersFormer、LSS等),本文实现了一种统一相机内外参的预处理方法,即通过建立具有固定内外参数的虚拟相机(Virtual Camera)完成各个相机的图像内/外参数的快速统一。

论文假设是与当地路面相切的平面。路面的切线。由于3D车道检测更关注平面,论文利用homography矩阵的共面性将当前摄像机的图像通过homography 投影到虚拟摄像机的图像中。如下图所示:通过homography矩阵将当前摄像机的图像投射到虚拟像机的视图中。因此,Virutal Camera实现了不同像机的空间关系的一致性。虚拟像机的内参和外参是固定的,这些参数是由训练数据集的内/外参数的平均值算出来的。
在训练和推理阶段,根据当前相机提供的相机内参数和外参以及虚拟相机的内/外参来计算。具体的,首先,论文在BEV平面上选择四个点,其中 。然后论文将它们分别投射到当前像机的图像和虚拟像机的图像上,分别得到 和 。最后,通过最小二乘法得到,如公式1所示:
实际上,在推理的时候,把原始相机的图像和传入到OpenCV的库函warpPerspective即可得到虚拟相机下的图像。
关于Virtual Camera的效果,可以通过消融实验看出,对x_error(-0.5m)和F1-Score(+3.3)都有着比较明显的效果。

MLP Based Spatial Transformation Pyramid

空间转化模块对视觉3D任务尤为关键,基于深度的方法和基于transformer的方法在计算量上开销很大,而且在部署到自动驾驶芯片上也不太方便。为了解决这个问题,本文引入了一个轻量级和易于部署的空间转换模块,即基于MLP的视图转化模块(VRM)。该模块R学习展平后对前视特征和展平后的BEV特征中任意两个像素位置之间的关系。然而,VRM是一个固定的映射,忽略了不同相机参数带来的变化。幸运的是,本文提出的虚拟相机统一了不同相机的内/外参数,弥补了这一不足。VRM对前视特征层的位置很敏感。本文分析了VRM中不同尺度的前视特征的影响,如下表格。

通过实验发现,低分辨率的特征更适合在VRM中进行空间转换。本文认为,低分辨率的特征包含更多的全局信息,而且由于基于MLP的空间变换是一个固定的映射,低分辨率的特征需要较少的映射参数,比较容易学习。受FPN的启发,本文设计了一个基于VRM的空间变换金字塔。
通过实验比较,本文最终分别用输入图像的1/64分辨率特征S64和1/32分辨率特征S32进行变换,然后将变换结果串联起来。然后将两者的结果连接起来,一起送往提取BEV的特征。
Key-Points Representation
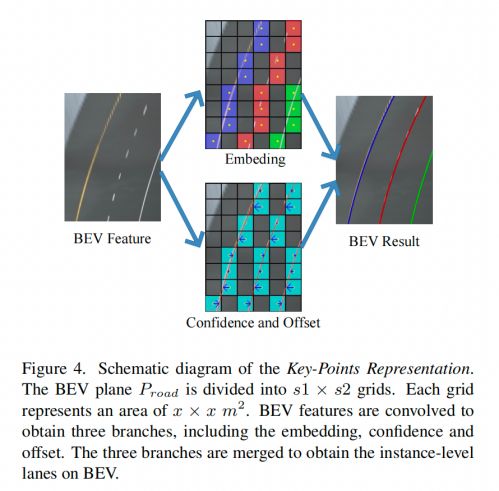
3D车道线的表示方法对3D车道检测的结果有很大影响。本文参照YOLO和LaneNet,提出了一个简单但稳健的表示方法来预测BEV上的3D车道。如图4所示,论文将BEV平面,即道路坐标中的平面划分为个grid。每个grid代表 (默认为0.5米)。本文直接预测具有相同分辨率的四个head,包括置信度confidence、用于聚类的embedding、gird中心到车道在y方向的偏移offset以及每个grid的平均高度。grid的大小对3D车道的预测有很大影响。过小的grid尺寸会影响confidence分支中正负样本的平衡,如下表格所示。

然而,如果grid大小过大,不同车道的embedding就会重叠。考虑到车道任务的稀疏性,本文通过实验建议网格单元的大小为平方米。在训练和推理中,论文在道路地面坐标系中预测了方向的(-10m,10m)和方向的(3m,103m)范围内的车道线。因此,从3D道检测头输出四个200×40分辨率的张量,包括confidence、embedding、offset和height。confidence、embedding和offset分支合并得到BEV下的实例级车道
针对这4个head,产生了4个loss:
confidence loss
就是前后背景的分割loss,本文采用交叉熵损失,其中代表groud thuth,代表预测值。
offset loss
由于置信度分支不能准确表示车道的位置,offset分支负责预测从grid中心到车道线在y方向的精确偏移量。如图4所示,预测的偏移量被Sigmoid归一化并减去0.5,因此偏移量的范围是(-0.5, 0.5)。偏移损失可以用MSE损失。值得注意的是,本文只计算confidence为1的grid cell的偏移量。即只有这个grid 有车道线经过才会算offset loss。
代表有车道线经过本grid。
embeding loss
为了区分每个grid的车道线id,本文预测每个grid的embedding,这里直接借鉴了LaneNet中的做法。在训练阶段,拉近属于同一车道id的grid的embedding之间的距离,而属于不同车道id的grid的embedding之间的距离被拉大。在模型的推理中,本文使用了一种快速的无监督聚类后处理方法来预测可变数量的车道线。作者认为与存在消失点的2d车道线检测不同,3d车道更适合于这种embedding聚类损失函数。这里作者没有展开,可能是因为和LaneNet一模一样,所以懒得写了吧。
height loss
作者在这里用grid中车道线的均值作为本grid车道线的height 真值,有点小粗暴。这也是本文中Z error 比较大原因之一吧。同时和offset一样,只有这个grid 有车道线经过才会算height loss。
效果展示
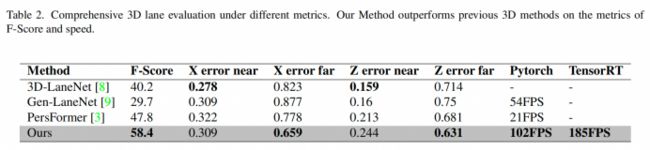
作者分别在OpenLane和Apollo 3D synthetic上展示了他们的成果,无论是速度和指标都有着大幅度的提升。
OpenLane 指标
速度和效果都有着非常大的提升!
Apollo 3D synthetic 指标
效果一骑绝尘的感觉!!

可视化
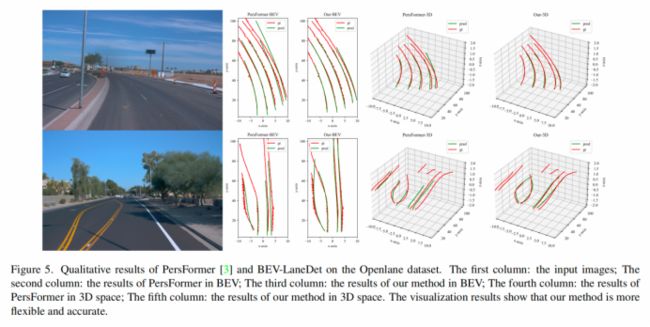
OpenLane对比可视化
Apollo 3D synthetic 对比可视化
关于本篇文章的补充解释可以参考本文作者和通讯作者的笔记:
一作补充解释:https://zhuanlan.zhihu.com/p/612697272
通讯作者补充解释:https://zhuanlan.zhihu.com/p/614191683
参考
[1] BEV-LaneDet: a Simple and Effective 3D Lane Detection Baseline
视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、传感器标定、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称