CV算法复现(分类算法6/6):MobileNet(2017年V1,2018年V2,2019年V3,谷歌)
致谢:霹雳吧啦Wz:霹雳吧啦Wz的个人空间_哔哩哔哩_Bilibili
目录
致谢:霹雳吧啦Wz:霹雳吧啦Wz的个人空间_哔哩哔哩_Bilibili
1 本次要点
1.1 pytorch框架语法
2 网络简介
2.1 历史意义
2.2 网络亮点
V1版亮点
V2版亮点
V3版亮点
2.3 V1网络
DW卷积和PW卷积介绍
计算量
网络结构(和VGG差不多,就是卷积层的串联)
效果
2.4 V2网络
倒残差结构
ReLU6激励函数
V2网络结构
效果
2.5 V3网络
V3算法的 block结构
SE模块(注意力机制)
重新设计耗时层结构
重新设计激活函数
V3网络结构
3 代码结构(V2版)
3.1 model.py
3.2 train.py
3.3 predict.py
1 本次要点
1.1 pytorch框架语法
- 要使用DW卷积功能,只要设定nn.conv2d中groups参数即可。
- pytorch自带relu6激励函数。nn.ReLU6()。
2 网络简介
2.1 历史意义
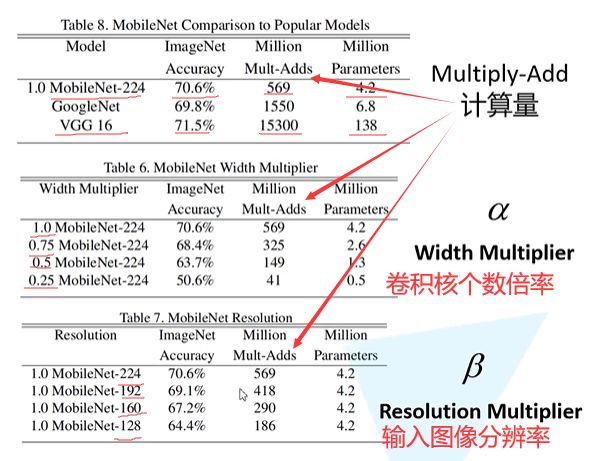
2017年,为了满足移动和嵌入式视觉任务的需要,MobileNet V1构造了一种体量小(参数量是VGG16的1/32)、运算少(计算量是GoogeNet的1/3)网络架构,精度相比VGG仅低了0.9%。
2018年,提出了MobileNet V2。
2019年,提出了MobileNet V3。
2.2 网络亮点
V1版亮点
- Depthwise Convolution( DW卷积,大大减少运算量和参数数量)
- 增加超参数α(卷积核个数)、β(输入图像的分辨率)
V2版亮点
- Inverted Residuals (倒残差结构 )
- Linear Bottlenecks
V3版亮点
- 更新block(bneck):在V2倒残差结构基础上进行了简单改动。
- SE模块:注意力机制。
- 更新了激活函数。
- 使用NAS(neural architecture search 神经结构搜索)搜索参数
- 重新设计耗时层结构
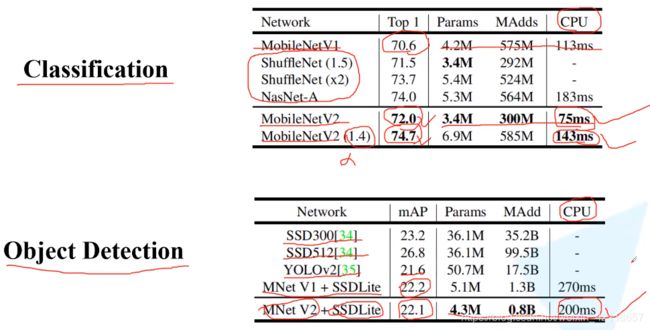
效果:更准确、更高效
2.3 V1网络
DW卷积和PW卷积介绍
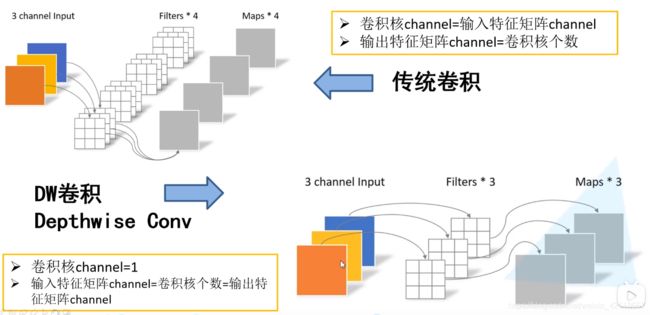
传统卷积:
- 卷积核channel=输入特征channel:这是卷积计算的定义,以前长时间误解卷积核channel就是1,比如输入特征是1024通道,那么单个卷积核也要是1024个通道,单个通道两两匹配做卷积计算,然后1024个通道矩阵的相应位置元素值累加,1024个元素(不是特征图,是特征图中单个元素)累加后,再加一次bias,此时的元素值,就是特征图中的元素值。
- 卷积核个数=输出的通道数:所以,刚开始1*1卷积的发明,不是做特征提取,而是用来做通道数扩增或降维。
DW卷积:
- 卷积核通道就1层,而且只和输入的单通道进行卷积。具体DW原理见上图。
- 这种运算对输入层的每个通道独立进行卷积运算,没有利用不同通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map。
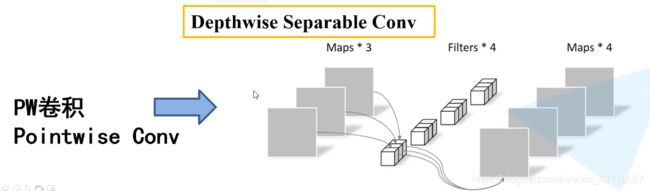
PW卷积:
- 作用跟1*1卷积一模一样,在这里换了个名字,作用是控制输出的通道数。具体如上图。
计算量
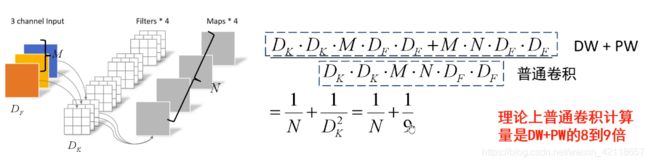
M是输入特征的通道数,N是输出特征的通道数,通常卷积核是3*3的,使用DW+PW替换常规卷积,分子除以分母约为1/9。
当然,实际上,由于计算机底层计算机制等原因,可能DW卷积计算方式比常规卷积计算更费时间。
网络结构(和VGG差不多,就是卷积层的串联)
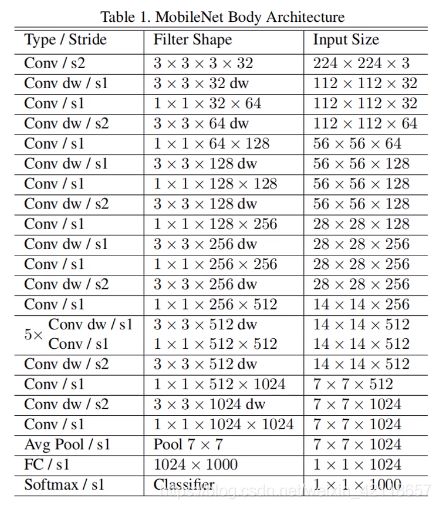
注意与解释:
- conv / s2 :普通卷积;步长为2。
- 3 x 3 x 3 x 32:卷积核尺寸为 3 x 3;卷积核深度为3;卷积核组数为32(即输出32个特征图)
- conv dw / s1:DW卷积;步长为1。
- 3 x 3 x 32 dw:卷积核尺寸为 3 x 3;DW卷积核深度为1,所以这里默认不写;卷积核组数为32。
- PW卷积就是常规的1x1卷积,所以网络结构中,每个dw卷积后面接一个1x1常规卷积。
在V1版本中,DW部分的卷积核容易废掉,即卷积核参数大部分为0,基本没起作用。V2中有了改善。
效果
2.4 V2网络
倒残差结构

左图是残差结构,右图是倒残差结构,升维降维顺序反过来。
V2论文中有两种连接方式,如下:
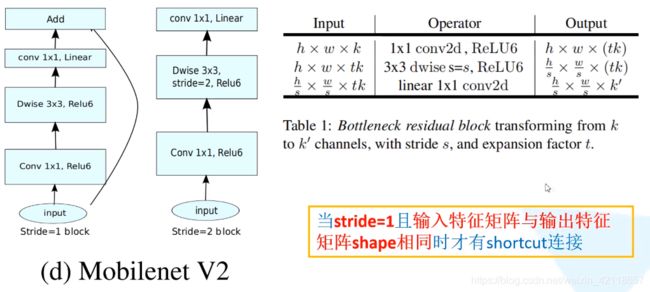
论文中,只有stride=1且输入特征矩阵与输出特征矩阵shape相同时才有shortcut连接。
ReLU6激励函数

替换常规ReLU原因是:常规ReLU对低维的特征造成大量损失,而对高维影响才小。

V2网络结构

- t 是扩展因子:就是DW卷积通道拓展倍数。
- bottleneck只有s=1时(即bottleneck中第一层DW卷积步长为1),才使用有shortcut分支版本block。(原因:DW卷积步长为2时,特征图尺度会发生变化,没法前后add了)
- 最后一层 1 x 1 卷积层,因为输入向量也是1x1x1280,所以相当于一个全连接层。
效果
2.5 V3网络
V3算法的 block结构
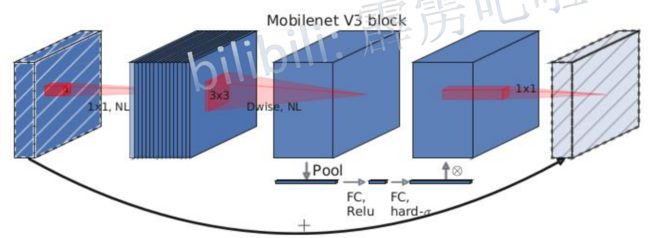
NL:非线性激活函数的意思。(V2算法中没有用)
后面的1x1卷积层:用于降维,也没有用激活函数。
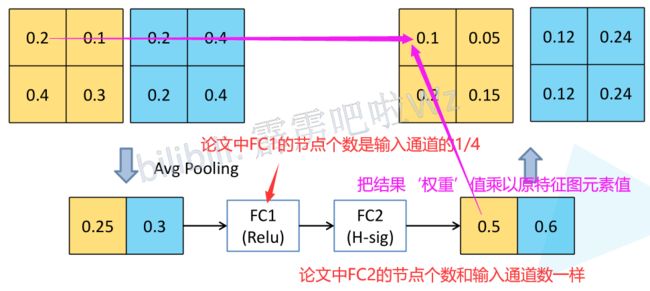
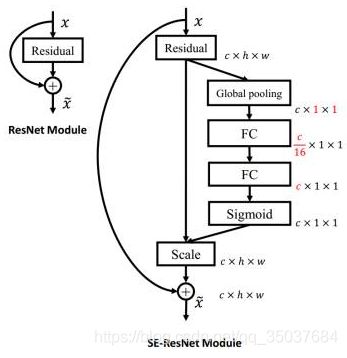
SE模块(注意力机制)
SE是Squeeze and Excitation的缩写(‘紧缩和激励’),该模块的提出主要是考虑到模型通道之间的相互依赖性。
细节解释:
- pool:每个通道特征图,使用global pooling,比如全局平均池化,求得特征图所有元素的平均值。
一个例子:
SE-ResNet结合示意图:
重新设计耗时层结构
- 减少第一个卷积层的卷积核个数(V2版是32,V2版是16)(我:这也算创新吗,这感觉完全是实验测试发现精度不降,速度能提升。。。)
- 效果:精度一样,速度提升2毫秒(约3%提速)
- 精简Last State 结构
- 效果:速度提升7毫秒(11%提速)

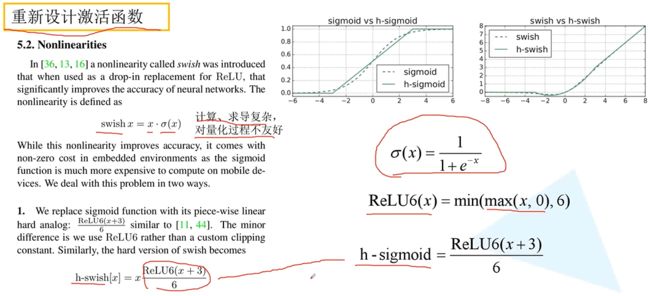
重新设计激活函数
问题:swish激活函数能提升网络精度,但是求导复杂、量化过程也不友好。
解决:发明 h-swish 激活函数,形态和swish相近,但计算和量化好的多。
V3网络结构

3 代码结构(V2版)
- model.py
- train.py
- predict.py
3.1 model.py
from torch import nn
import torch
"""
目的:将输入通道数调整为输出通道数的整数倍
ch:卷积核个数(即输出特征图channel)
divisor:一个基数。
_make_divisible就是要把ch调整成divisor的整数倍。
可能原因:有利于并行运算或多机器分布式运算。
"""
def _make_divisible(ch, divisor=8, min_ch=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_ch is None:
min_ch = divisor
# 以下一句,相当于四舍五入
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
# 确保向下取整时不会超过10%
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
"""
Conv + BN + ReLU6 模块
继承nn.Sequential类,因为后续要使用pytorch官方预训练权重。
groups=1表示普通卷积,其他值将为DW卷积。
"""
class ConvBNReLU(nn.Sequential):
def __init__(self, in_channel, out_channel, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
#传入3个参数
super(ConvBNReLU, self).__init__(
nn.Conv2d(in_channel, out_channel, kernel_size, stride, padding, groups=groups, bias=False),
nn.BatchNorm2d(out_channel),
nn.ReLU6(inplace=True)
)
# 倒残差结构
class InvertedResidual(nn.Module):
def __init__(self, in_channel, out_channel, stride, expand_ratio):
super(InvertedResidual, self).__init__()
hidden_channel = in_channel * expand_ratio #扩展因子t
# use_shortcut:是否使用shortcut结构
self.use_shortcut = stride == 1 and in_channel == out_channel
layers = []
if expand_ratio != 1: #如果为1,则不要1*1卷积
# 1x1 pointwise conv
layers.append(ConvBNReLU(in_channel, hidden_channel, kernel_size=1))
# layers.append()是一个个插入。而layers.extend()能批量插入。
layers.extend([
# 3x3 depthwise conv
ConvBNReLU(hidden_channel, hidden_channel, stride=stride, groups=hidden_channel),
# 1x1 pointwise conv(linear 线性激活函数)
nn.Conv2d(hidden_channel, out_channel, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channel),
# 注意:线性激活函数,就相当于y=x,所以也就是BN层后不需要加激活函数了。
])
self.conv = nn.Sequential(*layers)
def forward(self, x):
if self.use_shortcut:
return x + self.conv(x)
else:
return self.conv(x)
"""
alpha:卷积核个数的倍率
round_nearest:
"""
class MobileNetV2(nn.Module):
def __init__(self, num_classes=1000, alpha=1.0, round_nearest=8):
super(MobileNetV2, self).__init__()
block = InvertedResidual
# _make_divisible:将输入通道数调整为输出通道数的整数倍
# 可能原因:有利于并行运算或多机器分布式运算。
input_channel = _make_divisible(32 * alpha, round_nearest)
last_channel = _make_divisible(1280 * alpha, round_nearest)
inverted_residual_setting = [
# t, c, n, s(具体含义,见网络详解图)
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
features = []
# conv1 layer
features.append(ConvBNReLU(3, input_channel, stride=2))
# building inverted residual residual blockes
for t, c, n, s in inverted_residual_setting:
output_channel = _make_divisible(c * alpha, round_nearest)
for i in range(n):
stride = s if i == 0 else 1
features.append(block(input_channel, output_channel, stride, expand_ratio=t))
input_channel = output_channel
# building last several layers
features.append(ConvBNReLU(input_channel, last_channel, 1))
# combine feature layers
self.features = nn.Sequential(*features)
# building classifier
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(last_channel, num_classes)
)
# weight initialization 权重初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias) #bias设为0
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight) #方差设为1
nn.init.zeros_(m.bias) #bias设为0
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01) #将权重调整为均值为0,方差为0.01的正态分布。
nn.init.zeros_(m.bias) #bias设为0
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x3.2 train.py
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import json
import os
import torch.optim as optim
from model import MobileNetV2
# import torchvision.models.mobilenet 点进去里面有mobilenet_v2预训练模型的下载路径。
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path
image_path = os.path.join(data_root, "data_set", "flower_data") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 16
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=nw)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=nw)
print("using {} images for training, {} images fot validation.".format(train_num,
val_num))
net = MobileNetV2(num_classes=5)
# load pretrain weights
# download url: https://download.pytorch.org/models/mobilenet_v2-b0353104.pth
model_weight_path = "./mobilenet_v2.pth" #imageNet预训练模型,输出节点是1000,所以最后一层在此不能用。
assert os.path.exists(model_weight_path), "file {} dose not exist.".format(model_weight_path)
pre_weights = torch.load(model_weight_path)
# delete classifier weights
# 遍历权重字典,看权重名称中是否有“classifier”参数,有表示是最后一层全连接层参数,
pre_dict = {k: v for k, v in pre_weights.items() if "classifier" not in k} #排除最后一层名叫"classifier"的全连接层。
missing_keys, unexpected_keys = net.load_state_dict(pre_dict, strict=False) # 通过字典载入权重
# freeze features weights
# 冻结 features结构部分(特征提取部分)权重。
for param in net.features.parameters(): # 如果是net.parameters(),则所有网络结构都冻结。
param.requires_grad = False # 不求导,也不参数更新。
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0001)
best_acc = 0.0
save_path = './MobileNetV2.pth'
for epoch in range(5):
# train
net.train()
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
images, labels = data
optimizer.zero_grad()
logits = net(images.to(device))
loss = loss_function(logits, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
# print train process
rate = (step+1)/len(train_loader)
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
print("\rtrain loss: {:^3.0f}%[{}->{}]{:.4f}".format(int(rate*100), a, b, loss), end="")
print()
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
for val_data in validate_loader:
val_images, val_labels = val_data
outputs = net(val_images.to(device)) # eval model only have last output layer
# loss = loss_function(outputs, test_labels)
predict_y = torch.max(outputs, dim=1)[1]
acc += (predict_y == val_labels.to(device)).sum().item()
val_accurate = acc / val_num
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('[epoch %d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, running_loss / step, val_accurate))
print('Finished Training')
if __name__ == '__main__':
main()冻结输出层之外的层参数,训练结果:

作者最高训练到94%。
如果基于预训练模型,所有层都进行更新训练,能达到98.1%。
3.3 predict.py
import torch
from model import MobileNetV2
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
import json
data_transform = transforms.Compose(
[transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
# load image
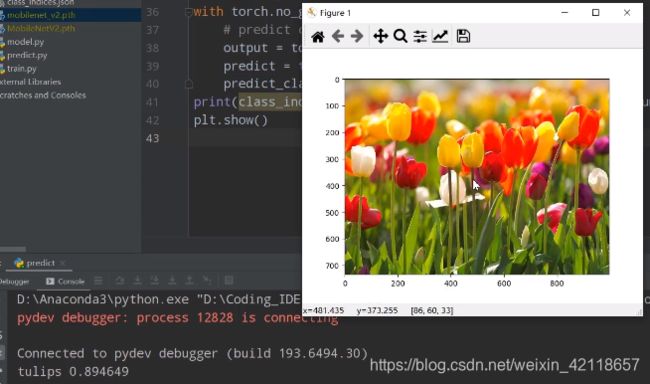
img = Image.open("../tulip.jpg")
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
try:
json_file = open('./class_indices.json', 'r')
class_indict = json.load(json_file)
except Exception as e:
print(e)
exit(-1)
# create model
model = MobileNetV2(num_classes=5)
# load model weights
model_weight_path = "./MobileNetV2.pth"
model.load_state_dict(torch.load(model_weight_path))
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img)) #压缩batch维度
predict = torch.softmax(output, dim=0) #将输出值转为概率分布。
predict_cla = torch.argmax(predict).numpy()
print(class_indict[str(predict_cla)], predict[predict_cla].numpy())
plt.show()预测输出: