淘宝双十二活动复盘——Mysql数据分析+Tableau可视化
项目目录
- 一、项目介绍
-
- 1.1 项目背景
- 1.2 分析思路
- 二、数据预处理
-
- 2.1 数据来源与认识
- 2.2 观察数据
- 2.3 添加字段
- 2.4 检查空值
- 2.5 检查重复值
- 2.6 检查异常值
- 三、数据分析
-
- 3.1 人
-
- 3.1.1 获客分析(PV、UV、访问深度)
- 3.1.2 留存分析(留存率、跳失率)
- 3.1.3 行为分析(时间序列分析、漏斗模型、购买路径)
- 3.1.4 用户价值分析(RFM模型、复购率)
- 3.2 货
-
- 3.2.1 热门商品品类分析
- 3.2.2 热门商品分析
- 3.2.3 商品四象限分析
- 3.3 场
-
- 3.3.1 平台推荐优化
- 3.3.2 平台购买路径优化
- 四、总结
一、项目介绍
1.1 项目背景
淘宝是中国深受欢迎的网购零售平台,一年一度的双十二更是集聚了海量的用户行为数据,在这个数字经济的时代,拥有数据且能够有效运用数据是推动产品高效运营的关键。
本次项目的数据集来源于2014年双十二期间,淘宝平台上真实的用户商品行为数据,通过对数据集的指标进行结构分析拆解,探索淘宝用户行为模式的同时进行活动复盘,为下一次活动的更好举办提供数据决策基础。
1.2 分析思路
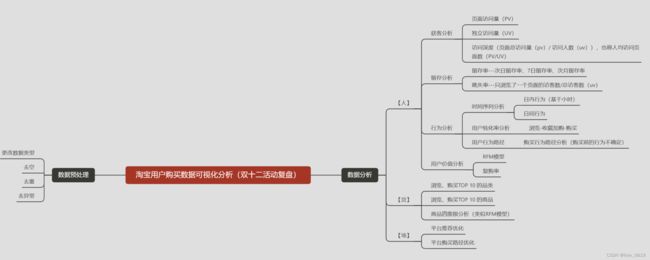
基于人、货、场三个维度进行分析,使用AARRR漏斗模型、RFM模型、商品四象限分析(矩阵分析方法)等方法进行探究。
二、数据预处理
2.1 数据来源与认识
数据链接: 淘宝用户购物行为数据可视化分析
本次分析数据为阿里天池公开数据集user_action.csv,数据包含了抽样出来的1W用户在一个月时间(11.18-12.18)之内的移动端行为数据。
| 字段 | 字段说明 | 提取说明 |
|---|---|---|
| user_id | 用户标识 | 抽样&字段脱敏 |
| item_id | 商品标识 | 字段脱敏 |
| behavior_type | 用户对商品的行为类型 | 包括浏览、收藏、加购物车、购买,对应取值分别是1、2、3、4。 |
| item_category | 商品分类标识 | 字段脱敏 |
| time | 行为时间 | 精确到小时级别 |
数据包含5个字段,前4个字段应为数值型,最后一个time字段应转换为时间。
2.2 观察数据
select * from user_action
limit 10;
观察前10行数据,发现要将时间转换为日期和小时方便后续分析
2.3 添加字段
# 添加字段名,日期dates和小时hours,用substring(字符串,开始位置,截取长度)函数
alter table user_action add dates char(10) null;
alter table user_action add hours char(2) null;
update user_action set dates = substring(time,1,10),
hours = substring(time,12,2);
2.4 检查空值
select count(*)
,count(user_id)
,count(item_id)
,count(behavior_type)
,count(item_category)
,count(time)
from user_action;
![]()
发现无空值
2.5 检查重复值
为后期调用不改变原数据且方便,建临时表temp_user,同时去除重复值:
#创建临时表,存放去重后的数据
create table temp_user like user_action;
insert into temp_user select distinct * from user_action;
# 去重后还有6213379行数据
2.6 检查异常值
本数据集有时间范围,2014-11-18到2014-12-18,若时间不在此范围,应剔除:
select min(dates), max(dates) from temp_user;
发现无异常值
三、数据分析
3.1 人
3.1.1 获客分析(PV、UV、访问深度)
按天分组
# 基于天
select dates,
count(user_id) pv,
count(distinct user_id) uv,
round(count(user_id) / count(distinct user_id),2) 'pv/uv'
from temp_user
group by dates;
得到基于天的用户PV、UV、访问深度(PV / UV),并借助Tableau进行可视化:
采用双轴进行展示,结果展示PV、UV大体趋势一致,均在双十二当天出现峰值,且附近日期数值明显高于其他日期,由此可知:
- 双十二活动用户集中消费,使用APP的频率高,购物倾向高;
- 建议:商家重点关注节日、大促活动,推出特定的优惠活动吸引用户
按小时分组
# 基于小时
select hours,
count(user_id) pv,
count(distinct user_id) uv,
round(count(user_id) / count(distinct user_id),2) 'pv/uv'
from temp_user
group by hours;
# 特定日期(12-12)
select hours,
count(user_id) pv,
count(distinct user_id) uv,
round(count(user_id) / count(distinct user_id),2) 'pv/uv'
from temp_user
where dates = '2014-12-12'
group by hours;
得到基于小时的用户PV、UV、访问深度(PV / UV)并与双十二当天的数据进行对比,借助Tableau进行可视化:

可以看出:
- PV值在19点之后持续升高,高峰期出现在20-22点,说明淘宝的主要用户是学生群体和上班族,他们下课、下班后使用淘宝;
- 双十二当天的PV值与整月PV值趋势相似,主要差别在于双十二的PV值曲线有较多的拐点,曲线并不平滑,可能原因是整点时商家平台发放优惠券及推动促销活动,引起用户访问量上升;
- UV值相对来说较稳定,9-23点之间没有较大波动,可能的原因是用户在清醒的时候就可能会打开淘宝,看看商品或物流等信息,因此UV值在一天之内相较于PV值波动不大;
- 双十二当天UV值在9点后略有下降,在19点后持续上升至峰值,说明用户目的性强,大多数均参与20点的促销活动;
- 凌晨1-6点,PV、UV的趋势一致,均是一天中流量最小的时间段(低谷期),最大的原因是用户在休息。
- 建议:商家要抓住黄金时期18-21点进行促销活动宣传推广,采用多渠道发送信息,并且针对不同用户要精准推广,主要集中在上班族和学生党用户群体。
3.1.2 留存分析(留存率、跳失率)
留存率
# 将表关联,筛选出b表的日期大于a表的日期
select * from
(select user_id, dates from temp_user group by user_id, dates) a
left join
(select user_id, dates from temp_user group by user_id, dates) b
on a.user_id = b.user_id
where a.dates <= b.dates;
使用datediff()函数计算次日留存率、7日留存率、月留存率:
select a.dates,
count(distinct a.user_id) theday, -- 当天计数
count(if(datediff(b.dates,a.dates)=1,b.user_id,null)) / count(distinct a.user_id) remain1, -- 次日留存率
count(if(datediff(b.dates,a.dates)=7,b.user_id,null)) / count(distinct a.user_id) remain7, -- 七日留存率
count(if(datediff(b.dates,a.dates)=30,b.user_id,null)) / count(distinct a.user_id) remain30 -- 月留存率
from
(select user_id, dates from temp_user group by user_id, dates) a
left join
(select user_id, dates from temp_user group by user_id, dates) b
on a.user_id = b.user_id
where a.dates <= b.dates
group by a.dates;


可以看到留存率均在70%-80%之间,说明用户忠诚度高,双十二活动的效果好。
跳失率
每日只访问了一个页面就离开的访问人数占该页面总访问人数的比例。跳失率可以反映用户对APP\网站内容的认可程度,或者说网站\APP是否对用户有吸引力,基于天进行计算:
select dates, count(*) '每日跳失数'
from (
select dates, user_id
from temp_user
where behavior_type = 1
group by dates, user_id
having count(behavior_type) = 1
) a
group by dates; -- 存入daily_jump表
# 将表daily_jump与day_pv_uv联结,计算流失率
select dj.dates, 每日跳失数, uv
,round(每日跳失数 / uv,4) '跳失率'
from daily_jump dj join day_pv_uv dpu
on dj.dates = dpu.dates;

可视化结果看出:每日跳失率很低,仅占当天访问人数的9%左右,说明用户粘性高,商品吸引力强。
结合留存率和跳失率来看,淘宝用户的忠诚度较高,用户粘性强,并且淘宝的内容质量好,吸引用户深入浏览,所以在获取新用户的同时,也要关注老客的忠诚度,要重视用户关系管理,不断维系新老用户,进一步培养用户忠诚度。
3.1.3 行为分析(时间序列分析、漏斗模型、购买路径)
时间序列分析
# 基于日期-小时的用户行为
select dates, hours,
count(if(behavior_type=1,1,null)) pv,
count(if(behavior_type=2,1,null)) fav,
count(if(behavior_type=3,1,null)) cart,
count(if(behavior_type=4,1,null)) buy
from temp_user
group by dates, hours
order by dates, hours;

- 观察趋势图,可见4种用户行为的变化趋势基本一致,除去峰值12-12(“双十二”)及其相邻日期,每天的波动不大。
- 因此,建议商家可以针对特殊节日,进行针对性地计划营销策略,可实现更好的商业效益。
- 发现用户行为购买的流量结果与浏览、收藏、加购物车这三类用户行为的差异性较大。因此,可以考虑进一步分析各个环节的转化率,并分析相关原因,是否可以采取相应措施,提高转化率。

- 观察日内行为趋势图对比30天数据,由于30天数据过于密集,影响观看体验,故筛选12.8-12.15日的用户行为,可以看到:
- 每日19点后有明显的增长,20-23点是用户购物的高峰期,2-6点是低峰,符合实际场景。建议商家即时把握时机,可采取相关营销活动,如推送店铺活动等,可进一步促进转化率,下面即分析转化率。
用户转化率
数据集中用户行为包括浏览、收藏、加购、购买,是单向的用户行为流程,非常适合使用漏斗模型进行分析。
由于收藏和加购同属于购买前置行为,本研究中将数据简化成浏览-收藏加购-购买的漏斗模型。
select behavior_type, count(*) num from temp_user
group by behavior_type;
# +-------------+--------+
# behavior_type |num |
# +-------------+--------+
# |1 |5535879|
# |2 |239472 |
# |3 |331350 |
# |4 |106678 |
# +-------------+--------+
select (239472+331350) / 5535879, 106678 / 5535879;
-- 0.1031;0.0193
# 双十二当天的漏斗模型
select behavior_type, count(behavior_type) num from temp_user
where dates = '2014-12-12'
group by behavior_type;
# +-------------+--------+
# behavior_type |num |
# +-------------+--------+
# |1 |298410 |
# |2 |10309 |
# |3 |23879 |
# |4 |13866 |
# +-------------+--------+
select (23879+10309) / 298410, 13866 / 298410;
-- 0.1146;0.0465
由结果看到,整月的浏览-收藏加购的转化率为10.31%,收藏加购-购买的转化率仅为1.93%;双十二当天的浏览-收藏加购的转化率为11.46%,收藏加购-购买的转化率为4.65%,较整月整体有上升趋势,但是依旧偏低。

但是用户并非一定收藏加购后再购买,因此收藏加购-支付转化率并不准确。我们在此继续细分用户行为:
# 用户行为
create view user_behavior_view as
select user_id
,item_id
,count(if(behavior_type = 1,1,null)) pv
,count(if(behavior_type = 2,1,null)) fav
,count(if(behavior_type = 3,1,null)) cart
,count(if(behavior_type = 4,1,null)) buy
from temp_user
group by user_id, item_id;
# 用户行为标准化
create view user_behavior_standard as
select user_id
,item_id
,(case when pv>0 then 1 else 0 end) '浏览了'
,(case when fav>0 then 1 else 0 end) '收藏了'
,(case when cart>0 then 1 else 0 end) '加购了'
,(case when buy>0 then 1 else 0 end) '购买了'
from user_behavior_view
group by user_id, item_id;
# 购买路径类型
# 将行为连接,以此作为字段计数分析:
create view user_behavior_path as
select *
, concat(浏览了,收藏了,加购了,购买了) '购买路径类型'
from user_behavior_standard ubs
where ubs.购买了>0;
# 统计各购买路径数量
select 购买路径类型
, count(*) '数量'
from user_behavior_path
group by 购买路径类型
order by 数量 desc;

- 结合购买路径类型分析,发现购买转化自收藏加购的占比并不大,而绝大部分来自于浏览加购后购买以及浏览后购买,两者占比超80%,这也符合日常操作。
- 精准推荐是提升重点,建议APP可以从推荐机制入手,优化推荐机制以及商品关键词设置,以用户日常行为作为依据,尽量精准推荐,减少用户寻找商品的时间成本,从而提高转化率。
- 作为商家,一方面要拓展流量,加大获客力度,增加曝光点击量;另一方面可以多举办限时促销活动,以及优化商品图片、标题、商品详情页,突出产品的特点和优势,提高用户对商品的兴趣,促使用户尽快下单。
3.1.4 用户价值分析(RFM模型、复购率)
一般来说,通过分析用户在电商平台上的消费金额、购买频次、及最近一次购买的日期,可以发现哪些用户是高价值用户,哪些用户是低价值用户。但由于数据集中不包含消费金额,因此我们可以通过分析用户的近期一次消费(R)和购买频次(F),来粗略评估用户的价值。可以将用户分为以下几类(1代表高,0代表低):
价值用户(11):最近消费时间近、消费频次都高,是电商平台的主要贡献者。
保持用户(01):最近消费时间较远,但消费频次高,说明这是个一段时间没来的忠诚客户,是电商平台的中坚力量,也是潜在的高价值用户,需要主动和他保持联系。
发展用户(10):最近消费时间较近,但频次不高,忠诚度不高,是很有潜力的用户,可考虑重点发展。
挽留用户(00):最近消费时间较远、消费频次不高,可能是将要流失或者已经要流失的用户,是电商平台的边缘用户,需要进一步开发和引导并给予挽留措施。
# 计算最近购买日期和购买次数
select user_id
, max(dates) '最近购买日期'
, count(user_id) '购买次数'
from temp_user
where behavior_type = 4
group by user_id
order by 2 desc, 3 desc;
## 建立rfm_model表,并添加f_score列
update rfm_model
set f_score= case
when(购买次数 between 0 and 10) then 1
when(购买次数 between 10 and 50) then 2
when(购买次数 between 50 and 100) then 3
when(购买次数 between 100 and 200) then 4
else 5 end;
# 添加r_score列
alter table rfm_model add column r_score int;
update rfm_model
set r_score= case
when 最近购买日期 in ('2014-11-18','2014-11-24') then 1
when 最近购买日期 in ('2014-11-24','2014-11-30') then 2
when 最近购买日期 in ('2014-11-30','2014-12-06') then 3
when 最近购买日期 in ('2014-12-06','2014-12-12') then 4
else 5 end;
再对用户进行分层:
# 对用户分层
set @f_avg = null;
set @r_avg = null; -- 定义用户变量存储平均值,加@以区分列名
select avg(f_score) into @f_avg from rfm_model;
select avg(r_score) into @r_avg from rfm_model;
alter table rfm_model add column class char(4);
update rfm_model set class = case
when f_score > @f_avg and r_score > @r_avg then '价值客户'
when f_score > @f_avg and r_score < @r_avg then '保持客户'
when f_score < @f_avg and r_score > @r_avg then '发展客户'
when f_score < @f_avg and r_score < @r_avg then '挽留客户'
end;
可视化结果如图

各类用户特性:
1)价值用户占比超30%,说明优质用户较多,应继续重点关注,既要保持其粘性,又要继续引导消费,可为这类用户提供vip服务;
2)发展用户的特点是近期有消费但频次不高,占比近50%,要提高这类用户群体的消费频次,具体措施有促销活动提醒和优惠券活动等;
3)保持用户的特点是消费频次高但有一段时间没有消费,此类群体数量相对较少,也符合常理,可能用户在一段活动期间多次购买,囤积商品够长期使用,策略是重新唤醒,应通过APP消息推送,以及站外广告营销吸引其注意力,促进复购;
4)挽留用户近期没有消费且频次不高,若不加以挽留,会有流失的可能, 对于这类用户一方面需要保持曝光量,持续推送活动和优惠信息;另一方面需要进一步研究其兴趣和需求,才能采取有效的运营策略。
复购率
复购率可以直观看出用户的忠诚度,由此可为本次活动举办成功与否提供依据,并且可以推动活动运营的优化。
select count(if(购买总数>1,a.user_id,null)) 复购人数
, count(if(购买总数>0,a.user_id,null)) 购买总人数
, concat(round(count(if(购买总数>1,1,null)) * 100 / count(if(购买总数>0,1,null)),2),'%') 复购率
from(
select user_id
, count(if(behavior_type = 4,1,null)) 购买总数
from temp_user
group by user_id) a; -- 8117,8886,91.35%

复购率高达90%以上,可以看出淘宝用户忠诚度非常高,淘宝商品对用户的吸引力高,因此更要抓住这点推出更多吸引用户的商品,提高用户粘性,进而刺激用户消费。
3.2 货
3.2.1 热门商品品类分析
查询浏览量、购买量前十的商品品类,并进行对比:
#查询品类浏览量前十
select *
,rank()over(order by 品类浏览量 desc) rk
from
(select item_category
, count(if(behavior_type = 1,1,null)) '品类浏览量'
from temp_user
group by item_category
order by 2 desc) a
where a.品类浏览量>0
limit 10; -- 创建表category_pv_rank记录数据
#查询品类购买量前十
select *
,rank()over(order by 品类购买量 desc) rk
from
(select item_category
, count(if(behavior_type = 4,1,null)) '品类购买量'
from temp_user
group by item_category
order by 2 desc) a
where a.品类购买量>0
limit 10; -- 创建表category_buy_rank记录数据
通过创建category_pv_rank表和category_buy_rank表分别记录品类浏览量前十和购买量前十,将两表连接,对比浏览量前十和购买量前十品类:
#连接category_pv_rank和category_buy_rank表
select *
from category_pv_rank p join category_buy_rank b
on p.item_category = b.item_category
order by p.rk;

结果表明:
- 浏览量高的品类不一定购买量高,浏览量排第2的品类购买量才排第9,而浏览量排第10的品类购买量排第3;
- 应重点关注浏览量高而购买量低的品类,提升这个品类的点击-购买转化率。
3.2.2 热门商品分析
共有2876947种商品,活动复盘一个关键就是找出转化好的商品继续保持,找出转化差的商品进行下架。
查询浏览量、购买量前十的商品,并进行对比:
# 浏览量前十的商品
select *
,rank()over(order by 商品浏览量 desc) rk
from
(select item_id
, count(if(behavior_type = 1,1,null)) '商品浏览量'
from temp_user
group by item_id
order by 2 desc) a
where a.商品浏览量>0
limit 10;
# 购买量前十的商品
select *
,rank()over(order by 商品购买量 desc) rk
from
(select item_id
, count(if(behavior_type = 4,1,null)) '商品购买量'
from temp_user
group by item_id
order by 2 desc) a
where a.商品购买量>0
limit 10;
通过创建item_pv_rank表和item_buy_rank表分别记录商品浏览量前十和购买量前十,将两表连接,对比浏览量前十和购买量前十商品:
select *
from item_pv_rank p join item_buy_rank b
on p.item_id = b.item_id
order by p.rk;

结果表明:
- 浏览量前10的商品中只有一件商品购买量排在前10,说明互联网长尾效应严重,大多数商品被大量浏览后只被少量购买,甚至没有购买;
- 对于此类商品应转换推广策略,针对特定人群精准投放广告,以免造成资源浪费。
3.2.3 商品四象限分析
由于对商品笼统的浏览量、销售量排名难以明确,因此对商品从浏览量和销售量两个维度进行商品四象限分析(矩阵分析方法),类似上文RF模型。
# 将商品浏览量表和购买量表连接
select p.item_id, 商品浏览量, 商品购买量
from item_pv_rank p join item_buy_rank b
on p.item_id = b.item_id;
# 添加分数字段
alter table 商品四象限分析 add column pv_score int;
alter table 商品四象限分析 add column buy_score int;
由于人眼不好分组,所以将数据导入Tableau进行群集分组,得到每一组的区间范围:
# 放入tableau可视化,进行群集分组
# 商品浏览量
update 商品四象限分析 set pv_score=case
when 商品浏览量 between 280 and 550 then 5
when 商品浏览量 between 100 and 280 then 4
when 商品浏览量 between 50 and 100 then 3
when 商品浏览量 between 20 and 50 then 2
else 1 end;
# 商品购买量
update 商品四象限分析 set buy_score=case
when 商品购买量 between 12 and 28 then 5
when 商品购买量 between 7 and 12 then 4
when 商品购买量 between 4 and 7 then 3
when 商品购买量 between 2 and 4 then 2
else 1 end;
设置变量存储分数的平均值:
# 对商品分层
set @pv_avg = null;
set @buy_avg = null; -- 定义商品变量存储平均值,加@以区分列名
select avg(pv_score) into @pv_avg from 商品四象限分析;
select avg(buy_score) into @buy_avg from 商品四象限分析;
对四类商品进行命名:
pv、buy均大于平均值,高价值商品;
pv大于平均值,buy小于平均值,高性价商品;
pv小于平均值,buy大于平均值,高发展商品;
pv、buy均小于平均值,高潜力商品。
alter table 商品四象限分析 add column class char(5);
update 商品四象限分析 set class = case
when pv_score > @pv_avg and buy_score > @buy_avg then '高价值商品'
when pv_score > @pv_avg and buy_score < @buy_avg then '高性价商品'
when pv_score < @pv_avg and buy_score > @buy_avg then '高发展商品'
when pv_score < @pv_avg and buy_score < @buy_avg then '高潜力商品'
end;
可视化结果:
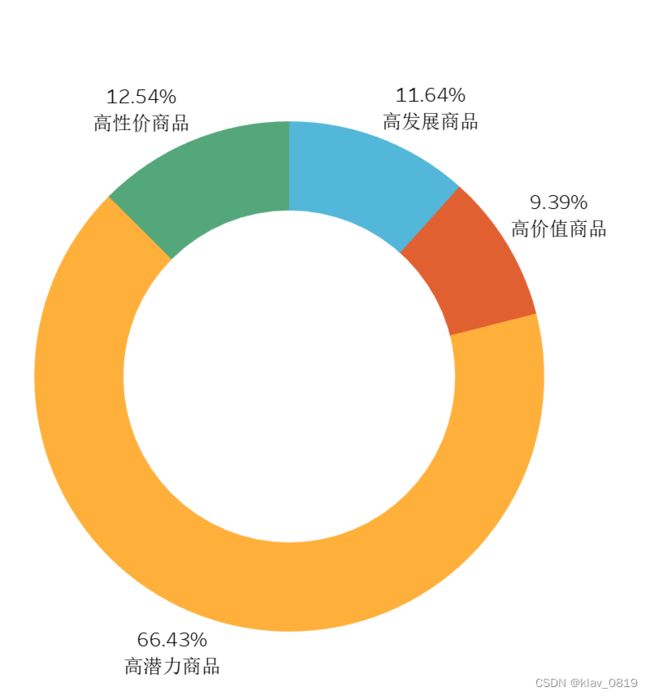
针对第一象限:高价值商品
- 此类商品目前情况较好,可以考虑加大宣传力度、触及更多用户,从而提高购买量,转化潜在消费者;
针对第二象限:高发展商品
- 此类商品浏览量较少,购买量却高于均值,说明有特定消费群体有目标性的购买;
- 商品本身转化率较高,但是曝光过少,商家应加大宣传力度,使用户接触到该类商品的渠道增多,从而提高商品浏览量,进一步提高销售额;
针对第三象限:高潜力商品
- 此类商品浏览量和购买量均低于均值,占比超66%,主要是流量入口和商品本身两方面原因,可以先尝试加大对商品的宣传力度,提高曝光量;
- 如果效果并不显著,可能是商品本身不是用户需要的,在同类商品中不占优势,可以考虑直接优化掉。
针对第四象限:高性价商品
- 此类商品浏览量高于均值,但是购买量较少,说明商品整体的转化率很低;
- 可能是商品宣传很有吸引力,文案、配图方面吸引大量消费者浏览,但是没有触及想购买的用户,应加大精准推送的力度,根据商品特征和用户画像进行宣传;
- 可能商品价格偏高,导致用户没有购买,应观察同类型商品的价格,指定合理且有竞争力的价格,提高用户购买欲望;
- 商品评论、客服:评论区是否有非常让人难以忍受的差评,客服的态度是否良好,有没有让用户产生不良的体验,若出现此类问题,应尽快更正。
3.3 场
3.3.1 平台推荐优化
淘宝是中国深受欢迎的网购零售平台,每时每刻都有海量用户数据,数据中显示高发展商品(浏览量较少,购买量较高)、高性价商品(浏览量较高,购买量较少)占比较高,应优化平台推荐机制,对特定群体投放资源从而避免资源浪费,增加用户了解信息的沟通渠道,提高商品曝光量,增加用户触及商品的可能性;同时针对商品特性和用户群体画像精准推荐,选取合适的商品关键词,使其更加符合用户画像。
3.3.2 平台购买路径优化
从用户购买路径分析看出,绝大多数用户选择浏览加购后购买以及浏览后购买进行购买,两者占比超80%,造成收藏加购使用率不高,应加大力度引导用户使用收藏加购功能,可在商品详情页或商品点击页面显示收藏加购的优惠之处,并紧密结合淘宝平台的优惠活动,以优惠为突破点吸引顾客。重点提升点击进入详情页的用户的收藏加购使用率。
四、总结
本分析从人、货、场三个维度分析了来自淘宝用户行为的千万级数据,进行双十二活动复盘,得到结论如下:
- 双十二活动用户集中消费,使用APP的频率高,购物倾向高;用户的忠诚度较高,用户粘性强,并且淘宝的内容质量好,吸引用户深入浏览,所以在获取新用户的同时,也要关注老客的忠诚度,要重视用户关系管理,不断维系新老用户,进一步培养用户忠诚度。
- 商品购买量与浏览量的相关性比较差,浏览量、购买量均低的高潜力商品占绝大多数,主要是流量入口和商品本身两方面原因,可以先尝试加大对商品的宣传力度,提高曝光量,如果效果并不显著,可能是商品本身不是用户需要的,在同类商品中不占优势,可以考虑直接优化掉。同时浏览量较高,但是购买量较少的高性价商品也较多,因此没有必要一味提高浏览量,销量并不会随之增加。对于这类商品可以从目标人群送达、优化定价、商品详情页、客服及评论区等方面着手优化。此外,平台应多推荐高价值商品、高发展商品;对高性价商品和高潜力商品适当提高曝光量,并根据情况采取下一步措施。
- 平台要优化推荐功能和购买路径功能,对特定群体投放资源从而避免资源浪费,增加用户了解信息的沟通渠道,提高商品曝光量,增加用户触及商品的可能性;同时针对商品特性和用户群体画像精准推荐,选取合适的商品关键词,使其更加符合用户画像;加大力度引导用户使用收藏加购功能,可在商品详情页或商品点击页面显示收藏加购的优惠之处,并紧密结合淘宝平台的优惠活动,以优惠为突破点吸引顾客。重点提升点击进入详情页的用户的收藏加购使用率。
参考资料:
【MySQL实战】基于100万真实电商用户的1亿条行为数据分析
浅析淘宝用户购物行为数据可视化分析
淘宝用户行为分析项目——MySQL数据分析+Tableau可视化