大结果集SQL引发的ClickHouse空闲超时
一、 问题现象
1. java报错
业务反馈查询遇到java报错,并且反复尝试都在同一个语句遇到相同报错
Code:[DBUtilErrorCode-06], Description:[执行数据库 Sql 失败, 请检查您的配置的 column/table/where/querySql或者向 DBA 寻求帮助.].
执行的SQL为: select id,...,create_time from mytabs where (create_time >= '2022-10-31 07:05:00')
具体错误信息为:java.sql.SQLException: java.io.IOException: Reached end of input stream after reading 42 of 104 bytesJDBC连接串为 jdbc:clickhouse://xxxx:8123/mydb?socket_timeout=300000
检查当时DB负载很低,尝试手动该查询不报错,但数据量很大,将近3000万行。由于影响到生产业务,联系阿里云后台共同排查。
2. clickhouse后台报错
由于以上为java报错,无法排查,查询query_log查看其在中对应报错
select * from clusterAllReplicas(default,system,query_log) where query like '%create_time from mytabs where (create_time >= \'2022-10-31 07:05:00\')%' order by event_time desc limit 5;
或者
select _shard_num, * from clusterAllReplicas(default, system, query_log) where exception_code > 0 and exception_code not in (13009, 341) and http_user_agent='ClickHouse Java Client' order by event_time desc limit 5 format Vertical;发现出现了两类报错:
- Connection reset by peer,while reading from socket... 报错相关函数为 ReadBufferFromPocoSocket
- Timeout exceeded while writing to socket... 报错相关函数为 WriteBufferFromPocoSocket
推测该报错与socket timeout有关,并且由业务方提供的jdbc连接串 jdbc:clickhouse://xxxx:8123/mydb?socket_timeout=300000 可以看到,设置了socket_timeout=300000
关于 socket_timeout 的介绍如下 JDBC 中 socketTimeout 的作用 - 范兵 - 博客园

但是,报错的语句是一个select * 的查询,而不是聚合分析语句,并且手动执行很快也有数据返回,不太符合上面的情况。
二、 报错排查
1. 业务场景
跟开发了解到该业务是一个数据同步场景,利用数据同步工具(jdbc程序)从ch查询数据,同步(按主键update)到 pg。
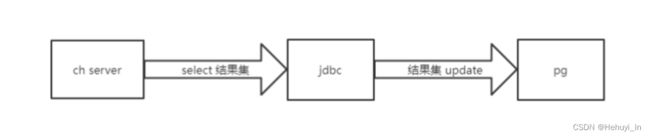
由于select总结果集将近3000万行数据,jdbc不可能是一次取完,并且取出后的结果需要到目标库按主键update,怀疑是目标端处理速度较慢,引起了socket timeout。
恰好开发反馈,将目标库处理方式改为插入至新表而非逐行update后,该请求可以执行成功。另外开发发现,ch中的表数据量有将近3000万行数据,而pg中的目标表只有60多万行数据,相差非常大。而对ch中的表按主键去重后,实际也只有60多万行数据。
由此可以得到一个优化方案:ch端的查询改为按主键group by,只取最新值同步到pg,可以将同步数据量由3000万大幅降低至60万,同时减少同步时间和各端负载。
以上发现加大了对目标端处理速度问题的怀疑。
2. ch后台debug日志
在 13:44:23到14:30:51,开发再次执行该语句并遇到报错,阿里云查询后台debug日志如下:
主查询节点日志
关键信息:
- 13:44:23 从分布式表 mytabs 读取5848758 行数据
- 14:30:51 报错 Connection reset by peer, while reading from socket
2022.11.04 13:44:23.746012 [ 6247 ] {be8a2988-a624-4adb-b220-2794adce016c} executeQuery: (from xxxx:44810, user: xxx) select id,...,create_time from mytabs where (create_time >= '2022-10-31 07:05:00')
2022.11.04 13:44:23.747047 [ 6247 ] {be8a2988-a624-4adb-b220-2794adce016c} mytabs_local (SelectExecutor): Key condition: (column 0 in [1667171100, +inf))
2022.11.04 13:44:23.747061 [ 6247 ] {be8a2988-a624-4adb-b220-2794adce016c} mytabs_local (SelectExecutor): MinMax index condition: unknown
2022.11.04 13:44:23.747388 [ 6247 ] {be8a2988-a624-4adb-b220-2794adce016c} mytabs_local (SelectExecutor): Selected 12 parts by date, 10 parts by key, 776 marks by primary key, 776 marks to read from 10 ranges
2022.11.04 13:44:23.747808 [ 6247 ] {be8a2988-a624-4adb-b220-2794adce016c} mytabs_local (SelectExecutor): Reading approx. 5848758 rows with 15 streams
2022.11.04 14:30:51.968534 [ 6247 ] {be8a2988-a624-4adb-b220-2794adce016c} executeQuery: Code: 210, e.displayText() = DB::NetException: Connection reset by peer, while reading from socket (xxx:3003): while receiving packet from xxx:3003: While executing Remote (version 20.8.17.25) (from xxx:44810) (in query: select id,...,create_time from mytabs where (create_time >= '2022-10-31 07:05:00')), Stack trace (when copying this message, always include the lines below):
2022.11.04 14:30:51.974662 [ 6247 ] {be8a2988-a624-4adb-b220-2794adce016c} DynamicQueryHandler: Code: 210, e.displayText() = DB::NetException: Connection reset by peer, while reading from socket (xxx:3003): while receiving packet from xxx:3003: While executing Remote, Stack trace (when copying this message, always include the lines below):
2022.11.04 14:30:51.974884 [ 6247 ] {be8a2988-a624-4adb-b220-2794adce016c} MemoryTracker: Peak memory usage (for query): 313.65 MiB.子查询节点日志
关键信息:
- 13:44:23 从本地表 mytabs_local 读取5871717 行数据
- 13:56:30 报错 Timeout exceeded while writing to socket
2022.11.04 13:44:23.750101 [ 6454 ] {40fe2280-7c75-48f7-ae20-d9f573179550} executeQuery: (from xxx:62298, initial_query_id: be8a2988-a624-4adb-b220-2794adce016c) SELECT id, xxx, create_time FROM mytabs_local WHERE create_time >= '2022-10-31 07:05:00'
2022.11.04 13:44:23.750946 [ 6454 ] {40fe2280-7c75-48f7-ae20-d9f573179550} mytabs_local (SelectExecutor): Key condition: (column 0 in [1667171100, +inf))
2022.11.04 13:44:23.750961 [ 6454 ] {40fe2280-7c75-48f7-ae20-d9f573179550} mytabs_local (SelectExecutor): MinMax index condition: unknown
2022.11.04 13:44:23.751277 [ 6454 ] {40fe2280-7c75-48f7-ae20-d9f573179550} mytabs_local (SelectExecutor): Selected 15 parts by date, 12 parts by key, 786 marks by primary key, 786 marks to read from 12 ranges
2022.11.04 13:44:23.759369 [ 6454 ] {40fe2280-7c75-48f7-ae20-d9f573179550} mytabs_local (SelectExecutor): Reading approx. 5871717 rows with 15 streams
2022.11.04 13:56:30.605183 [ 6454 ] {40fe2280-7c75-48f7-ae20-d9f573179550} executeQuery: Code: 209, e.displayText() = DB::NetException: Timeout exceeded while writing to socket (xxx:62298) (version 20.8.17.25) (from xxx:62298) (in query: SELECT id, xxx, create_time FROM mytabs_local WHERE create_time >= '2022-10-31 07:05:00'), Stack trace (when copying this message, always include the lines below):
2022.11.04 13:56:56.520048 [ 6454 ] {40fe2280-7c75-48f7-ae20-d9f573179550} MemoryTracker: Peak memory usage (for query): 323.68 MiB. SQL执行后,由分布式表发起一个对本地表的子查询,但是子查询节点12分钟后和主查询的节点连接断开了,当时资源和网络都没有很高。又过去34分钟后,主查询节点才发现这个连接断开了。也就是说,连接其实在第12分钟就断开了,但是在第40多分钟才返回报错给客户端。
ch的查询结果是一个管道,jdbc客户端要不断取数据,直至把数据取完。而主查询也是在40多分钟的时候,JDBC来读数据,它再从子查询的pipelie读数据,才会发现连接断开了。也就是说jdbc取第一批数据去处理,处理了40多分钟,所以它40多分钟后才去要第二批数据。
三、 报错原因梳理
- 当前的模式是业务层从jdbc中读取结果集,然后将结果集更新到pg中
- 通过jdbc从ch中读取数据是流式的,ch中查询执行也是流式的,结果集更新到pg这步耗时很长
- 导致ch root server的tcp receive_queue满且没有一直不被消费,进而导致其他child server的tcp send_queue满,write() syscall 被block,时间超过tcp协议栈的send_timeout配置,进而报错write timed out,并且TCP协议栈主动将root server到child server的tcp连接重置
- 当最终root server的tcp receive_queue中的数据被消费走之后,root server再次联系child server进行数据读取,发现该连接已经被重置,所以报错connection reset。
- 简单说就是tcp connection是一个通道,业务层jdbc不读数据,server端就写不进去,导致write syscall超时。
如下图所示

四、 补充说明
1. 优化方案
建议ch端的查询改为按主键group by,只取最新值同步到pg,可以将同步数据量由3000万大幅降低至60万,同时减少同步时间和各端负载
2. 调整jdbc socket_timeout能否解决
由于本次报错首先并不发生在jdbc端,因此调整jdbc socket_timeout并不解决该问题
3. 单副本实例会有这个问题吗
ch的 send_timeout 与 receive_timeout 存在于client与server端之间,不仅限于分布式表与local表间,因此单副本模式同样可能出现该问题
4. 为什么query_log中既有read报错又有write报错
- Connection reset by peer,while reading from socket...
- Timeout exceeded while writing to socket...
上图中的root server和child server两端都可以关闭tcp连接:
- 如果root server先关了,child server去写就报write错误
- 如果child server先关了,root server去读就报read错误
参考
https://clickhouse.com/docs/en/operations/settings/settings/#connect-timeout-receive-timeout-send-timeout
ClickHouse 源码阅读 —— SQL的前世今生-阿里云开发者社区
ClickHouse源码阅读(0000 1001) —— CK Server对SQL的处理 | 码农家园
ClickHouse源码阅读(0000 1100) —— TCPHandler.cpp中的in和out分析_B_e_a_u_tiful1205的博客-CSDN博客
ClickHouse源码阅读(0000 1011) —— ClickHouse Client端如何接收Server端发送回来的数据_B_e_a_u_tiful1205的博客-CSDN博客