zookeeper
我们都知道zookeeper 是分布式协调框架,kafka 这些都会依托于zk来存储元数据
zk 要了解他的数据结构以及监听机制,这个才是他能够作为分布式协调框架最核心的功能
zk是比较典型的CP架构
zk是很早的分布式协调框架 相当于分布式协调框架的鼻祖 现在已经有很多的方案 比如说etcd
zk的作用主要是保证我们的一致性 特别是我们的强一致性
大概是怎么实现的 以注册中心为例

我客户端要拉取我们的服务端列表,同时我也要获取到最新的服务列表
因为有些服务可能出问题了,宕机了,我客户端可以感知到这种变化
这个时候需要我们服务发现的组件(我们的注册中心)
zk可以作为注册中心,他是怎么去做的,zk可以当作注册中心 他是怎么去做的
1.提供一个注册功能(类似于文件目录的方式),在我们中间有3个子节点 service1、service2. service3,节点是可以存储数据的 (比如说他的ip :port)
这首先是他的第一个功能,是存储的功能,而且是基于我们的树型结构,类似于linux文件系统的目录结构
可以把有那些服务对应的端口ip 都进行存储, client就可以从我们的集群中 可以通过接口
查到service下面有那些节点 有那些服务

但是我们服务发现最重要的是可以感知我们的服务是否有异常 比如说你宕机了 此时宕机是不可以用的 要把这个剔除
有个监听机制,意思是我们可以对zk的这个节点进行监听(注册成为一个临时节点)
只要你down机了就断开连接了,断开连接的话,他这个临时节点会自动删除了
他有个观察者模式 我监听到这个节点down机了,我就可以通知我客户端 告诉客户端是down机了
1.存储是按照文件系统的方式进行存储的
2.他对每个节点是有监听机制的, 可以监听节点中数据的变化
这就是zk, 基于zk的功能我们可以实现
搭建zk环境 我这边基于docker搭建的,
可以看这里https://blog.csdn.net/zhuganlai168/article/details/130224626
zk他如果作为配置中心或者注册中心他和nacos功能是差不多的
nacos 也是做注册中心和配置中心的 这个就是zk的默认文件夹

启动客户端 启动服务端 然后 可以看到zk 默认使用的是zoo.cfg 的文件进行启动,这样的化我服务就起来了,像文件夹一样的目录
我们既然像linux 文件系统一样 我们可以通过Ls来看

我们就可以基于zk做CURD 操作

比如说我的create操作,我可以创建一个节点,
我可以给这个节点设置一个值,我可以给这个节点获取一个值
我还可以在lvhao 后面继续创建子节点


crud 有点像我们的redis 创建一个节点 删除一个节点
这是一个基本操作
关键是zk 有几种节点 以及他的监听机制
以及我们可以利用他的监听机制干一些事情,Zk这么一个结构
其实就类似我们这种Linux系统的这种结构

我比如说我监听/app1,我就可以知道他的子节点有没有新增,有没有减少,
我只要监听 /app1的话,你新增一个子服务,或者删除一个子服务的话 我都可以感知到,
这就很方便,这是他的一个结构类似于文件系统的层次结构,而不是单纯像redis 一样这种key value
因为他考虑监听

get -s /lvhao 我们可以通过 这个命令来查看节点的状态

zk的节点分临时和持久节点
持久节点 创建之后一直存在
临时节点 临时节点,一旦和我们服务端断开连接 就会被del 所以服务注册都是临时节点,
我可以基于zk的临时节点去做分布式锁 因为临时节点创建之后 再来一个客户端是创建不了的

我当前线程想创建这个临时节点,一个线程过来创建的节点,我另外一个线程也想创建这个临时节点
就是你创建完了,你lock节点已经存在了,他其他线程肯定是不能,其他线程去创建了lock锁的
他会提示你已经存在, 因为这个节点已经存在了 所以会失败
我们可以基于这个功能实现分布式锁
临时节点的特点 就是当我断开连接 他这个临时节点就会删除.当我们会话超时或者发生异常的时候 临时节点他也会被干掉
也就是说加锁的时候,如果我服务意外宕机了,没有正常释放锁,他 此时会断开连接,我就可以避免我程序死锁,
呢其他线程怎么知道你锁什么时候释放,我加锁失败了就会阻塞我什么时候知道我可以去尝试
我们可以用 stat -w /lock 这个命令来监听,一旦第一个线程delete这个锁的时候
我们就可以监听到这个锁释放了.继而就可以去做我们的业务逻辑了
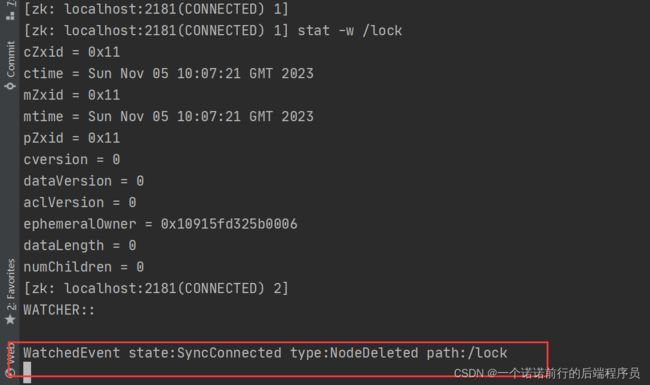
我可以开启针对于这个节点的监听,如果那边释放锁,我就可以监听到,继而继续create -e /lock加锁
通过这个临时节点,我就可以实现独占锁.
我创建一个节点,尝试获取这个锁,我就可以获取这个锁,失败的话,我就去监听这个锁,当我监听到这个锁
释放了的话, 我就可以继续加锁
临时节点的特性:客户端超时 或者是发生异常 意外的终止 会话结束了他这个节点就会删除 这样以来我们如果利用在锁的场景下 我们可以避免死锁
持久节点他就会一直存在 他会有一个有序节点
有序节点的特点 一般我们会创建一个临时有序的节点

我们可以根据这个有序节点的特性来实现分布式唯一自增Id,如果我创建这个临时节点是有序的 他不会提示我节点冲突
有序 -s
https://blog.csdn.net/zxf126126/article/details/127993071 [zk的数据写入半数机制]
zk如果从集群看的话 他是强一致的,比如说我们set (key,value),如果他是集群的话,会有个过半机制
如果有大多数节点响应 的话,才可以提交.



当我们对节点set值得时候 mZxid 就会更新,而且版本号也会加1 ,当我们基于当前节点去创建子节点得时候,pZxid 就会发生变化(此时数据得版本号不会改变)
ZK的节点 有
cZxid = 0x4 创建节点的事务Id
mZxid = 0x5
pZxid = 0x6

我们可以基于zk的版本号机制实现乐观锁

zk的监听机制,就是说 我可以监听某个节点的变化(zk的watch机制)
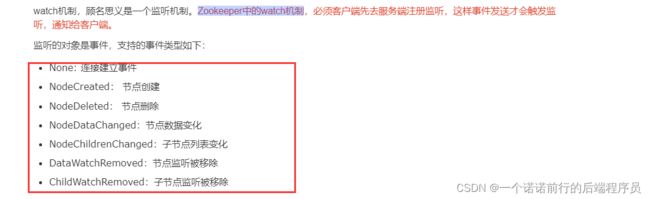
例如数据节点发生变化了, 我们就可以监听到,继而就可以做我们自己的操作了
我们可以利用zk的监听机制实现类似于k8s可以自动检测服务并且拉服务的这种模式.系统中只能有一个master , master能实时获取系统中worker的情况。
比如说 我master节点监听worker变化,如果worker宕机的话, 我重启一个就好了。
类似于k8s 一样当一个节点出问题之后。我可以自动启动起来 可以实现自动转移
借助于zk 我就可以实现 我把这个元数据信息 我存储在zk 中存储起来
他就可以记录master 以及worker进程状态
当 发现有变化的时候 比如说worker挂了 我就可以感知到 继而去做处理
他就可以监听到worker 进程挂了 我回调方法我再去启动一个worker进程就可以了