Python实用编程技巧(二)
文章目录
- 文件IO
-
- 问题:如何读写文本文件
- 问题:如何处理二进制文件
- 问题:如何设置文件的缓冲
- 问题:如何将文件映射到内存
- 问题:如何访问文件的状态
- 问题:如何使用临时文件
- 类与对象
-
- 问题:如何派生内置不可变类型
- 问题:如何为创建大量实例节省内存
- 问题:如何让对象支持上下文管理
- 问题:如何创建可管理的对象属性
- 如何让类支持比较操作
- 问题:如何使用描述符对实例属性做类型检查
- 问题:如何在环状数据结构中管理内存
- 问题:如何通过方法名的字符串调用方法
- 多线程并发
-
- 问题:如何使用多线程
- 问题:如何实现线程间通信
- 问题:如何实现线程间事件通知
- 问题:如何使用线程本地数据
- 问题:如何使用线程池
- 问题:如何使用多进程
- 装饰器
-
- 问题:如何使用装饰器
- 问题:如何保存原函数的信息
- 问题:如何定义带参数的装饰器
- 问题:如何实现属性可修改的函数装饰器
- 问题:如何在类中定义装饰器
- 小结
文件IO
- 文件IO效率相关问题和技巧
问题:如何读写文本文件
- 这里需要关注一个变化

- 也就是说,在python3中所有文本默认实用Unicode编码,无需加
u'',str类型 - python2中读写文件需要解码编码(因为是字节串),python3中默认以
t方式打开文件(真正的字符串),可以通过encoding指明编码即可,更便捷
- 也就是说,在python3中所有文本默认实用Unicode编码,无需加
问题:如何处理二进制文件
- 案例:处理wav文件,获取头部信息,这里需要了解wav文件的数据结构(包格式)
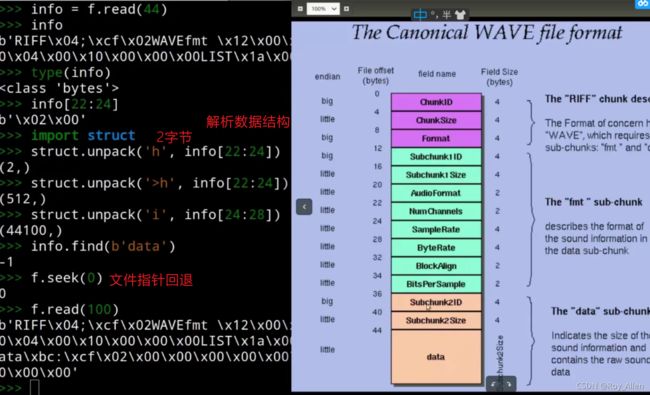
- 这里咱就用个文本文件,指定二进制模式
b,就不是t了,读取的是字节也不是str struct模块的unpack方法可以解析二进制数据import struct f = open('opera.txt', 'rb') fc = f.read() print(type(fc)) #print(struct.unpack('h', fc[0:2])) # (-30490,) 解析出来是元组! - 二进制数据可以用
f.readinto方法写入到numpy.zeros()创建的buffer中,然后用其tofile方法直接写入文件
问题:如何设置文件的缓冲
- 为了减少IO操作次数(费时且按块执行),需要设置缓冲
- 一般分为全缓冲、行缓冲、无缓冲
# 可以在Linux中打开要写入的文件,然后 f = open('opera.txt', 'wb') f.write(b'abc') # 此时会发现打开的文件没有变化,因为内容在缓冲区 # 缓冲区大小和磁盘的blocksize有关,可以在系统使用相关命令查看 # 假设为4096字节 f.write(b'a'*4093) f.write(b'b') # 查看此时使用tail打开的文件是否已写入 - 当我们已
t默认模式打开的时候,会发现写了4096以上的字符仍然没有刷盘- 这是因为python3中的t模式其实是基于二进制模式的,他的缓冲容量为8192
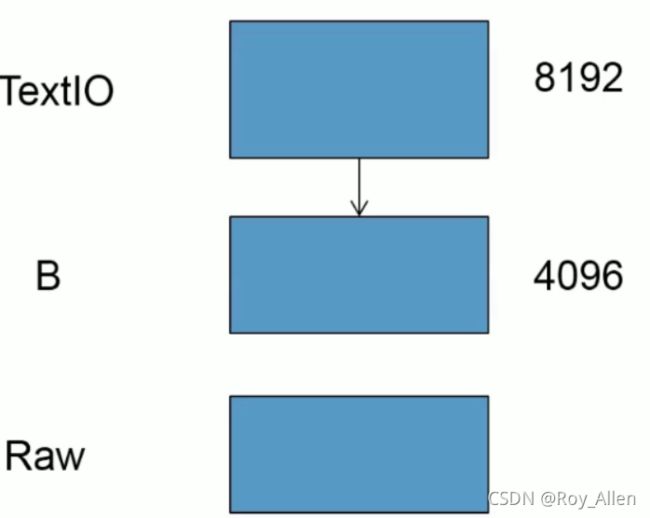
- 这是因为python3中的t模式其实是基于二进制模式的,他的缓冲容量为8192
- 以上是文本模式的全缓冲;行缓冲是遇到换行就读入,常见的bash就是行缓冲模式,一个命令敲回车就执行
- 使用python,可以指定无缓冲
f = open('opera.txt', 'wb', buffering=0) # 指定为1就是行缓冲,但是只能在文本模式下!!! f.write(b'abc') # buffer=0可以在b模式
问题:如何将文件映射到内存
- 实际案例:

- 大文件都是保存在磁盘中的(使用时装载,操作系统决定),如果希望能统一加载到内存操作
- 使用标准库中的
mmap,将文件映射到进程的内存地址空间;具体操作可以查资料,知道有这么一种场景即可!
问题:如何访问文件的状态
- 文件信息
- 文件类型
- 访问权限
- 最后的修改/访问时间
- 文件大小
- 都是通过系统调用完成,python中使用
os模块import os print(os.stat('opera.txt')) # os.stat_result(st_mode=33206, st_ino=3659174697950400, st_dev=752934806, st_nlink=1, # st_uid=0, st_gid=0, st_size=18, st_atime=1633529209, st_mtime=1633529209, st_ctime=1633529209) os.path.isfile('opera.txt') # os.path也可以获得一些信息 fd = os.open('opera.txt', os.O_RDONLY) print(fd) # 4 文件描述符 fn = os.read(fd, 5) # 传入file description 5字节 print(fn) # b'abc'st_nlink是硬链接,指针指向!软连接是只保存了数据路径- 其他参数包括了文件的所有信息
问题:如何使用临时文件
- 有事保存了大量的临时数据做数据分析,使用后依旧占用空间
from tempfile import TemporaryFile # 这是系统级别的临时文件,直接使用os.open tf = TemporaryFile() tf.write(b'*'*4096) tf.seek(0) # 必须回到起点 print(tf.read(512)) tf.close() # 临时文件销毁 # 没有名字,也找不到 - 有名字的临时文件,多进程想同时使用
from tempfile import NamedTemporaryFile ntf = NamedTemporaryFile(delete=False) # 关闭不删 print(ntf.name) # C:\Users\WINDOW~1\AppData\Local\Temp\tmp_4m8z61i import tempfile print(tempfile.gettempprefix()) # 前缀tmp - 这一部分还是遇到实际问题更容易理解一些!了解即可
类与对象
- 类与对象深度问题
问题:如何派生内置不可变类型
- 实战案例:

- 我们可以自定义这个类,在构造方法中过滤,然后传递给父类的构造方法
# 代码大致是这个样子 class IntTuple(tuple): def __init__(self, iter): int_tup = (i for i in iter if isinstance(i, int) and i>0) super().__init__(int_tup) - 这里会出现问题,
# TypeError: object.__init__() takes exactly one argument (the instance to initialize)- 错误提示调用了父类
object的init构造方法
- 错误提示调用了父类
- 区别是这样的
- 所有的对象归根结底都是有
object类的__new__()方法创建,这个方法使用cls(我们定义的类名)作为参数(源)
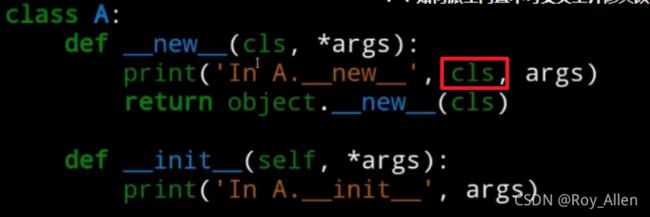
- 我们观察下面的显式调用的例子就懂了:
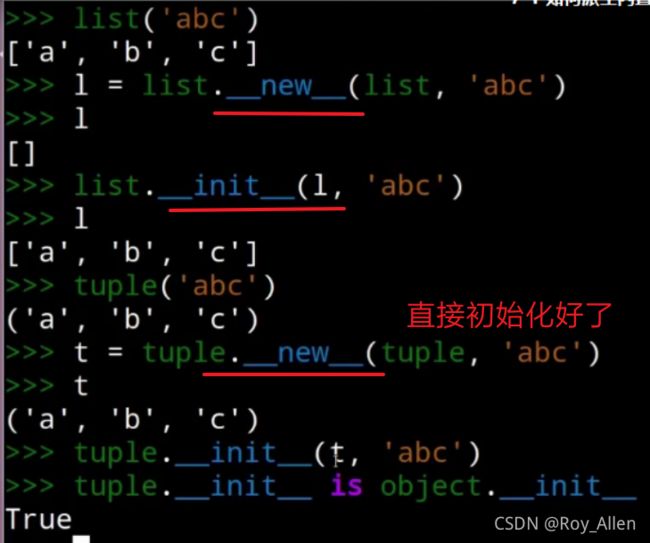
- 所有的对象归根结底都是有
- 也就是说,有的类(list)会经过new和init两个方法产生对象;一般是在init中,所以我们也叫它构造方法
- 有的类(tuple)在new的时候就已经产生了对象,根本没有实现init方法(
is父类的init方法)class IntTuple(tuple): def __new__(cls, iter): int_tup = (i for i in iter if isinstance(i, int) and i>0) return super().__new__(cls, int_tup) # 返回对象 it = IntTuple(['aa', 1, 2, 3, '6']) print(it) # (1, 2, 3)
问题:如何为创建大量实例节省内存
- 案例:

- 这里用到
__slots__变量class Person1(): def __init__(self, name, uuid, age): self.name = name self.uuid = uuid self.age = age class Person2(): __slots__ = ['name', 'uuid', 'age'] def __init__(self, name, uuid, age): self.name = name self.uuid = uuid self.age = age p1 = Person1('Roy', 1002, 18) p2 = Person2('Roy', 1002, 18) # dir() 函数不带参数时,返回当前范围内的变量、方法和定义的类型列表 # 带参数时,返回参数的属性、方法列表 # __dir__()被定义就会调用,未定义就尽可能收集信息 alist = set(dir(p1))-set(dir(p2)) # 求差集 print(alist) # {'__weakref__', '__dict__'} p1.w = 120 # p2.w = 140 # AttributeError: 'Person2' object has no attribute 'w' print(p1.__dict__) # {'name': 'Roy', 'uuid': 1002, 'age': 18, 'w': 120} import sys print(sys.getsizeof(p1.__dict__)) # 144B print(sys.getsizeof(p1.name)) # 52B print(sys.getsizeof(p1.uuid)) # 28B print(sys.getsizeof(p1.age)) # 28B print(sys.getsizeof(p1.w)) # 28B__dict__中存储的就是成员变量和定义的临时变量- 定义了
__slot__就无法添加临时变量,关闭动态绑定属性!
- 怎么证明这一点呢?
import tracemalloc
tracemalloc.start()
# 分别打开创建p1和p2的注释,运行程序,发现p2占用内存明显少
# p1 = [Person1(1,2,3) for _ in range(10000)] # 1567K
p2 = [Person2(1,2,3) for _ in range(10000)] # 630K
snap = tracemalloc.take_snapshot()
top = snap.statistics('filename') # 整个文件占用的内存 lineno看某行代码耗费的内存
for i in top[:10]:
print(i) # 前10
问题:如何让对象支持上下文管理
- 常见的上下文管理器就是
with,可以优雅的打开和关闭文件- 工作流程解析:其实是调用了
__enter__和__exit__方法
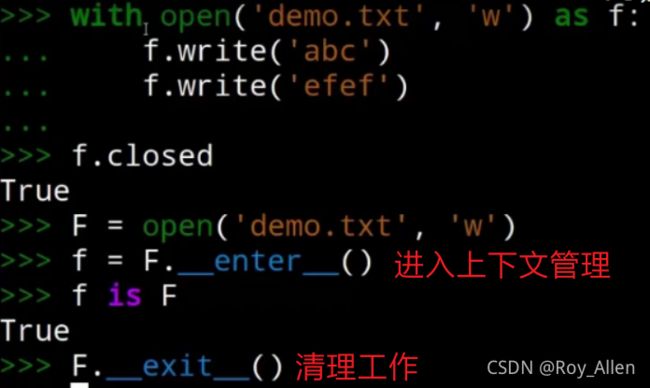
- 工作流程解析:其实是调用了
- 同样的,我们可以借助
with并自定义上述方法实现自己的上下文管理


- 可以捕获异常不让他向上抛出
问题:如何创建可管理的对象属性
- 方法是对象的接口,一般获取属性也使用方法
- 使用方法繁琐,直接获取属性太暴露;所以希望在形式上是直接访问属性,实际上内部调用的是方法
- 简单+安全,使用
property实现import math class Circle(): def __init__(self,radius): self.radius = radius def get_r(self): return round(self.radius,2) # 保留两位 def set_r(self, r): if not isinstance(r, (int, float)): raise TypeError('请输入整数或者小数') self.radius = r @property def S(self): # get_area return self.radius**2 * math.pi @S.setter def S(self, s): # set_area self.radius = math.sqrt(s/math.pi) R = property(get_r, set_r) # 这是一种形式,还可以使用装饰器 c = Circle(3) print(c.R) # 4 c.R = 4 print(c.R) # 4 print(c.S) print(c.R) c.S = 80 print(c.S) # 80.00000000000001 print(c.R) # 5.05 - 上面通过两种方法通过property创建可管理属性,安全便捷
如何让类支持比较操作
- 很简单,根据需求,对比较运算符进行重载
- 这里使用
total_ordering,只需定义两个比较方法,就能自动推算,无需重写所有!from functools import total_ordering @total_ordering class Rect(): def __init__(self, w, h): self.width = w self.height = h def get_area(self): return self.width * self.height def __lt__(self, obj): return self.get_area() < obj.get_area() def __eq__(self, obj): return self.get_area() == obj.get_area() r1 = Rect(2,3) r2 = Rect(3,4) print(r1 < r2) # True print(r1 <= r2) # True print(r1 >= r2) # False - 如果我们定义类时忘了定义area之类的方法,就尴尬了,可以使用继承的方法限定
from functools import total_ordering from abc import ABCMeta @total_ordering class Shape(metaclass=ABCMeta): @classmethod def get_area(self): pass def __lt__(self, obj): return self.get_area() < obj.get_area() def __eq__(self, obj): return self.get_area() == obj.get_area() class Rect(Shape): def __init__(self, w, h): self.width = w self.height = h def get_area(self): return self.width * self.height def __lt__(self, obj): return self.get_area() < obj.get_area() def __eq__(self, obj): return self.get_area() == obj.get_area() r1 = Rect(2,3) r2 = Rect(3,4) print(r1 < r2) # True print(r1 <= r2) # True print(r1 >= r2) # False
问题:如何使用描述符对实例属性做类型检查
- 这个描述符其实就是自定义一个重写了一些方法的类,可以在业务类中校验属性
class Desc: def __init__(self, key): self.key = key def __set__(self, instance, value): ''' :param instance: 实例化的类对象 :param value: 设置的值 :return: ''' instance.__dict__[self.key] = value def __get__(self, instance, owner): print('get', instance,owner) return instance.__dict__[self.key] def __delete__(self, instance): del instance.__dict__[self.key] class Student: name = Desc('Roy') age = Desc(18) - 好的,改写一下,做类型校验,不过要注意这里的类定义,不需再按照传统方式
class Desc: def __init__(self, key, _type): self.key = key self._type = _type def __set__(self, instance, value): ''' :param instance: 实例化的类对象 :param value: 设置的值 :return: ''' if not isinstance(value, self._type): raise TypeError('不是想要的类型') instance.__dict__[self.key] = value # 动态绑定 def __get__(self, instance, owner): print('get', instance,owner) return instance.__dict__[self.key] def __delete__(self, instance): del instance.__dict__[self.key] class Student: # def __init__(self, name, age): # 在init中Desc不起作用 # self.name = Desc(name, str) # self.age = Desc(age, int) name = Desc('Roy', str) age = Desc(18, int) s = Student() # s.name = 15 # TypeError: 不是想要的类型 s.name = 'roy' s.age = 23 s.name = 18 print(s.name) # roy
问题:如何在环状数据结构中管理内存
- 循环引用会让对象垃圾不能被及时回收

- 可以通过
__del__方法查看析构的过程,通过下面的例子可以证明循环引用带来的问题class Node: ''' 双向链表,链表:抓住一个节点就OK ''' def __init__(self, data): self.data = data self.right = None self.left = None def add_right(self, node): # 只能右端添加节点 self.right = node node.left = self def __str__(self): # 打印链表节点值 return 'Node:<%s>'%self.data def __del__(self): # 析构 print('__del__',self) def double_link(n): ''' 常见有n个节点的列表 :param n: :return: ''' head = current = Node(1) for i in range(2, n+1): node = Node(i) current.add_right(node) current = node return head head = double_link(20) head = None # 按道理讲应该析构,但是没,如果data中存的是其他内容?内存开销严重 import time for i in range(5): time.sleep(1) print('run...') - 左指针使用弱引用,不增加引用计数;注意属性访问方式的变化(使用property,属性变函数,简单安全)
import weakref class Node: ''' 双向链表,链表:抓住一个节点就OK ''' def __init__(self, data): self.data = data self.right = None self._left = None def add_right(self, node): # 只能右端添加节点 self.right = node # 右边是引用(指出去),左边为弱引用(被指向),不增加引用计数 node.left = weakref.ref(self) # 当我们head=None,就会析构后续节点 @property def left(self): return self._left() # 统一访问方式, 实例.left def __str__(self): # 打印链表节点值 return 'Node:<%s>'%self.data def __del__(self): # 析构 print('__del__',self) def double_link(n): ''' 常见有n个节点的列表 :param n: :return: ''' head = current = Node(1) for i in range(2, n+1): node = Node(i) # node.left() # 弱引用,必须用left() current.add_right(node) current = node return head head = double_link(20) head = None # 按道理讲应该析构,但是没,如果data中存的是其他内容?内存开销严重 import time for i in range(5): time.sleep(1) print('run...')
问题:如何通过方法名的字符串调用方法
- 有时不同类的相同作用的方法,其名称不同,如何通过名称调用?可以借助
getattr
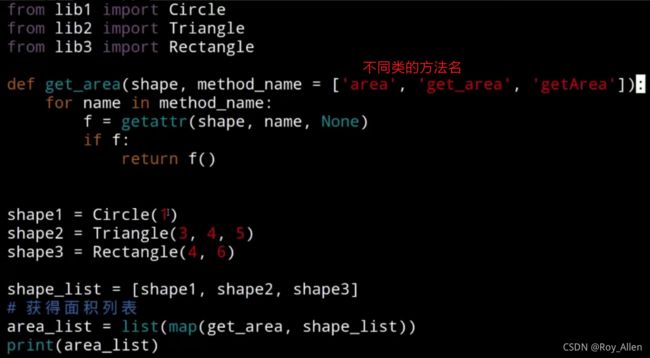
- 还可以使用
operator中的方法# 演示: from operator import methodcaller s = '15de55dsab45e' print(methodcaller('find', 'ab')(s)) # 8 方法,参数 后面传对象,反着的!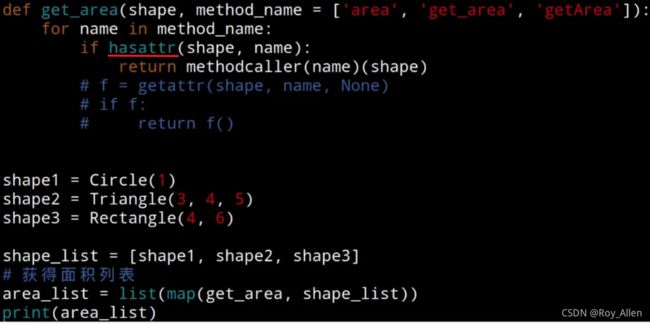
多线程并发
- 多线程并发相关问题与解决技巧
问题:如何使用多线程
- 例如要下载某个接口的数据并保存,可以使用多线程加速
- 我们通过访问网站下载CSV资源来说明问题
import requests import base64 from io import StringIO import csv from xml.etree.ElementTree import ElementTree, Element, SubElement USERNAME = b'7f304a2df40829cd4f1b17d10cda0304' PASSWORD = b'aff978c42479491f9541ace709081b99' def download_csv(page_number): print('download csv data [page=%s]' % page_number) # 网站中提供的API url = "http://api.intrinio.com/prices.csv?ticker=AAPL&hide_paging=true&page_size=200&page_number=%s" % page_number auth = b'Basic ' + base64.b64encode(b'%s:%s' % (USERNAME, PASSWORD)) headers = {'Authorization' : auth} response = requests.get(url, headers=headers) if response.ok: return StringIO(response.text) def csv_to_xml(csv_file, xml_path): # 转换CSV为xml格式 print('Convert csv data to %s' % xml_path) reader = csv.reader(csv_file) headers = next(reader) root = Element('Data') root.text = '\n\t' root.tail = '\n' for row in reader: book = SubElement(root, 'Row') book.text = '\n\t\t' book.tail = '\n\t' for tag, text in zip(headers, row): e = SubElement(book, tag) e.text = text e.tail = '\n\t\t' e.tail = '\n\t' ElementTree(root).write(xml_path, encoding='utf8') def download_and_save(page_number, xml_path): # IO csv_file = None while not csv_file: csv_file = download_csv(page_number) # CPU # csv_to_xml(csv_file, 'data%s.xml' % page_number) csv_to_xml(csv_file, 'data%s.xml' % xml_path) from threading import Thread # 多线程使用方法一:面向对象 class MyThread(Thread): def __init__(self, page_number, xml_path): super().__init__() # 必须调用父类init self.page_number = page_number self.xml_path = xml_path def run(self): # 相当于start() download_and_save(self.page_number, self.xml_path) if __name__ == '__main__': import time t0 = time.time() thread_list = [] for i in range(1, 6): t = MyThread(i, 'data%s.xml' % i) t.start() thread_list.append(t) for t in thread_list: t.join() # 每个都join,阻塞主线程事后在结束 # 多线程使用方法二: # 直接使用 # i = 1 # t = Thread(target=download_and_save(i, 'data%s'%i)) # t.start() # t.join() # 串行:不适用多线程 # for i in range(1, 6): # download_and_save(i, 'data%s.xml' % i) print(time.time() - t0) print('main thread end.') - 在主要的
download_and_save函数中,下载属于IO密集型操作,转换属于CPU密集操作 - 多线程只能加速IO操作,可以同时请求并下载(无需CPU过多参与),但不能加速CPU密集操作,除非多核并行(但这也不叫多线程加速了,属于多进程)
问题:如何实现线程间通信
- 上面说不能加速CPU密集型运算,为什么呢?
- 这是由于全局解释器锁(GIL)的存在
- 在同一进程(当前任务)的各个线程中,当我们给每个线程分配一个CPU核加速运算,各线程都要先拿到这个GIL才能执行,所以多核和一核并无区别
- 对IO操作是没有这个限制的,GIL锁会自动释放
- 可以用一个线程和两个线程试一下,使用
top命令监控CPU状态 - 多进程是独立的,不受影响
- 更改一下上面的代码架构
- 多个线程下载资源,使用标准库中的
queue.Queue(线程安全的),放入队列 - 一个线程进行转换,从队列中取数据(生产者-消费者模型)
- 线程安全的意思是
Queue自带了加锁机制,多线程访问时可以避免混乱import requests import base64 from io import StringIO import csv from xml.etree.ElementTree import ElementTree, Element, SubElement from threading import Thread USERNAME = b'7f304a2df40829cd4f1b17d10cda0304' PASSWORD = b'aff978c42479491f9541ace709081b99' # class MyThread(Thread): # def __init__(self, page_number, xml_path): # super().__init__() # self.page_number = page_number # self.xml_path = xml_path # # def run(self): # download_and_save(self.page_number, self.xml_path) class DownloadThread(Thread): def __init__(self, page_number, queue): super().__init__() self.page_number = page_number self.queue = queue def run(self): csv_file = None while not csv_file: csv_file = self.download_csv(self.page_number) self.queue.put((self.page_number, csv_file)) def download_csv(self, page_number): print('download csv data [page=%s]' % page_number) url = "http://api.intrinio.com/prices.csv?ticker=AAPL&hide_paging=true&page_size=200&page_number=%s" % page_number auth = b'Basic ' + base64.b64encode(b'%s:%s' % (USERNAME, PASSWORD)) headers = {'Authorization' : auth} response = requests.get(url, headers=headers) if response.ok: return StringIO(response.text) class ConvertThread(Thread): def __init__(self, queue): super().__init__() self.queue = queue def run(self): # 这样写不能自动结束,怎么判断? while True: page_number, csv_file = self.queue.get() self.csv_to_xml(csv_file, 'data%s.xml' % page_number) def csv_to_xml(self, csv_file, xml_path): print('Convert csv data to %s' % xml_path) reader = csv.reader(csv_file) headers = next(reader) root = Element('Data') root.text = '\n\t' root.tail = '\n' for row in reader: book = SubElement(root, 'Row') book.text = '\n\t\t' book.tail = '\n\t' for tag, text in zip(headers, row): e = SubElement(book, tag) e.text = text e.tail = '\n\t\t' e.tail = '\n\t' ElementTree(root).write(xml_path, encoding='utf8') from queue import Queue if __name__ == '__main__': queue = Queue() thread_list = [] for i in range(1, 6): t = DownloadThread(i, queue) t.start() thread_list.append(t) convert_thread = ConvertThread(queue) convert_thread.start() for t in thread_list: t.join() print('main thread end.') - 我们分别定义下载线程和转换线程,使用队列作为参数
- 思考:线程安全如何实现的?
- 多个线程下载资源,使用标准库中的
问题:如何实现线程间事件通知
- 接着上面的任务

- 我们可以使用
threading.Event,并使用tarfile包,增加一个打包的线程import requests import base64 from io import StringIO import csv from xml.etree.ElementTree import ElementTree, Element, SubElement from threading import Thread from queue import Queue import tarfile import os USERNAME = b'7f304a2df40829cd4f1b17d10cda0304' PASSWORD = b'aff978c42479491f9541ace709081b99' class DownloadThread(Thread): def __init__(self, page_number, queue): super().__init__() self.page_number = page_number self.queue = queue def run(self): csv_file = None while not csv_file: csv_file = self.download_csv(self.page_number) self.queue.put((self.page_number, csv_file)) def download_csv(self, page_number): print('download csv data [page=%s]' % page_number) url = "http://api.intrinio.com/prices.csv?ticker=AAPL&hide_paging=true&page_size=100&page_number=%s" % page_number auth = b'Basic ' + base64.b64encode(b'%s:%s' % (USERNAME, PASSWORD)) headers = {'Authorization': auth} response = requests.get(url, headers=headers) if response.ok: return StringIO(response.text) class ConvertThread(Thread): ''' 需要和打包线程通知状态 ''' def __init__(self, queue, c_event, t_event): super().__init__() self.queue = queue self.c_event = c_event self.t_event = t_event def run(self): count = 0 while True: page_number, csv_file = self.queue.get() # 会阻塞 if page_number == -1: # 没有file可取,退出 self.c_event.set() # 通知:转换事件已结束 self.t_event.wait() # 等待通知,打包事件状态 break self.csv_to_xml(csv_file, 'data%s.xml' % page_number) count += 1 if count == 2: # 两个一打包 count = 0 # 通知转换完成 self.c_event.set() # 通知:转换事件已结束,可以打包 # 等待打包完成 self.t_event.wait() # 等待通知,打包事件状态 self.t_event.clear()# wait和clear一般都是是一起的 # 循环继续 def csv_to_xml(self, csv_file, xml_path): print('Convert csv data to %s' % xml_path) reader = csv.reader(csv_file) headers = next(reader) root = Element('Data') root.text = '\n\t' root.tail = '\n' for row in reader: book = SubElement(root, 'Row') book.text = '\n\t\t' book.tail = '\n\t' for tag, text in zip(headers, row): e = SubElement(book, tag) e.text = text e.tail = '\n\t\t' e.tail = '\n\t' ElementTree(root).write(xml_path, encoding='utf8') class TarThread(Thread): ''' 打包线程,等待来自转换线程的通知 ''' def __init__(self, c_event, t_event): ''' :param c_event: 转换线程事件 :param t_event: 打包线程事件 ''' super().__init__(daemon=True) # 主线程结束,子线程跟着退出;这里设不设都一样,在转换线程中阻塞住了,这边完成了主线程才退出! self.count = 0 self.c_event = c_event self.t_event = t_event def run(self): while True: # 阻塞,等待足够的xml打包,那边转换好了调用set()方法这边就能开闸放水 self.c_event.wait() # 相当于更新事件,后面还会有阻塞通知 self.c_event.clear() print('打包......') # 打包方法 self.tar_xml() # 通知打包完成 self.t_event.set() def tar_xml(self): self.count += 1 tfname = 'data%s.tgz' % self.count print('tar %s...' % tfname) tf = tarfile.open(tfname, 'w:gz') # 打gz方式的包 for fname in os.listdir('.'): if fname.endswith('.xml'): tf.add(fname) # 加入即可 os.remove(fname) # 打包并移除! tf.close() if not tf.members: os.remove(tfname) from threading import Event if __name__ == '__main__': queue = Queue() c_event = Event() t_event = Event() thread_list = [] for i in range(1, 15): t = DownloadThread(i, queue) t.start() thread_list.append(t) convert_thread = ConvertThread(queue, c_event, t_event) convert_thread.start() tar_thread = TarThread(c_event, t_event) tar_thread.start() # 等待下载线程结束 for t in thread_list: t.join() # 通知Convert线程退出,解决上个问题中无法自动退出的问题 queue.put((-1, None)) # 如果是下载线程还没准备好文件put? # 等待转换线程结束 convert_thread.join() # 无需等待打包线程 print('main thread end.') - 转换和打包共享两个
Event,转换结束使用set解除打包中的wait,打包结束解除转换中的wait - 思考:
join的作用,上面使用put(-1)的方法,退出转换线程是否合理?- 合理,join是阻塞,子线程完毕才会执行后面的代码!所以主线程中的
start()一定要放在最前面
- 合理,join是阻塞,子线程完毕才会执行后面的代码!所以主线程中的
- 思考:一直在使用
io包中的StringIO,特点是什么? - 思考:除了消息队列,操作系统还用什么实现进程、线程间通信?
问题:如何使用线程本地数据
- 场景:使用
opencv库实时监控,我们在本地使用http在浏览器获取视频数据 - 这里使用操作系统级别的管道
os.pipe()发送摄像头数据给线程import os, cv2, time, struct, threading from http.server import HTTPServer, BaseHTTPRequestHandler from socketserver import TCPServer, ThreadingTCPServer from threading import Thread, RLock from select import select class JpegStreamer(Thread): def __init__(self, camera): super().__init__() self.cap = cv2.VideoCapture(camera) self.lock = RLock() self.pipes = {} def register(self): pr, pw = os.pipe() self.lock.acquire() self.pipes[pr] = pw self.lock.release() return pr def unregister(self, pr): self.lock.acquire() pw = self.pipes.pop(pr) self.lock.release() os.close(pr) os.close(pw) def capture(self): cap = self.cap while cap.isOpened(): ret, frame = cap.read() if ret: ret, data = cv2.imencode('.jpg', frame, (cv2.IMWRITE_JPEG_QUALITY, 40)) yield data.tostring() def send_frame(self, frame): n = struct.pack('l', len(frame)) self.lock.acquire() if len(self.pipes): _, pipes, _ = select([], self.pipes.values(), [], 1) for pipe in pipes: os.write(pipe, n) os.write(pipe, frame) self.lock.release() def run(self): for frame in self.capture(): self.send_frame(frame) class JpegRetriever: def __init__(self, streamer): self.streamer = streamer self.local = threading.local() def retrieve(self): while True: ns = os.read(self.local.pipe, 8) n = struct.unpack('l', ns)[0] data = os.read(self.local.pipe, n) yield data def __enter__(self): if hasattr(self.local, 'pipe'): raise RuntimeError() self.local.pipe = streamer.register() return self.retrieve() def __exit__(self, *args): self.streamer.unregister(self.local.pipe) del self.local.pipe return True class WebHandler(BaseHTTPRequestHandler): retriever = None @staticmethod def set_retriever(retriever): WebHandler.retriever = retriever def do_GET(self): if self.retriever is None: raise RuntimeError('no retriver') if self.path != '/': return self.send_response(200) self.send_header('Content-type', 'multipart/x-mixed-replace;boundary=jpeg_frame') self.end_headers() with self.retriever as frames: for frame in frames: self.send_frame(frame) def send_frame(self, frame): sh = b'--jpeg_frame\r\n' sh += b'Content-Type: image/jpeg\r\n' sh += b'Content-Length: %d\r\n\r\n' % len(frame) self.wfile.write(sh) self.wfile.write(frame) from concurrent.futures import ThreadPoolExecutor class ThreadingPoolTCPServer(ThreadingTCPServer): def __init__(self, server_address, RequestHandlerClass, bind_and_activate=True, thread_n=100): super().__init__(server_address, RequestHandlerClass, bind_and_activate=True) self.executor = ThreadPoolExecutor(thread_n) def process_request(self, request, client_address): self.executor.submit(self.process_request_thread, request, client_address) if __name__ == '__main__': # 创建Streamer,开启摄像头采集。 streamer = JpegStreamer(0) streamer.start() # http服务创建Retriever retriever = JpegRetriever(streamer) WebHandler.set_retriever(retriever) # 开启http服务器 HOST = 'localhost' PORT = 9000 print('Start server... (http://%s:%s)' % (HOST, PORT)) httpd = ThreadingPoolTCPServer((HOST, PORT), WebHandler, thread_n=3) #httpd = ThreadingTCPServer((HOST, PORT), WebHandler) httpd.serve_forever() - 这里有个问题:只有一个客户端能获取到数据,也就是说无法共享
- 我们可以在第一个类中通过建立一个管道的字典,发送图像帧给多个客户端
- 上面使用
threading.local,使用线程本地数据实现JpegRetriever类,单独建立管道;解释一下特点:from threading import Thread, local lo = local() lo.x = 1 def ch_local(local): local.x = 2 print(local.x) # 2 Thread(target=ch_local, args=(lo,)).start() print(lo.x) # 1- 也就是说,函数中的
local.x其实是调用时新创建的,属于这个线程的本地(私有)数据,和主线程独立 - 也是利用这个特性,多个
WebHandler线程中,每个retriever都需要在注册管道时使用local变量,相当于创建独立的管道通信
- 也就是说,函数中的
问题:如何使用线程池
- 代码已经在上部分展示,使用线程池对连接请求做限制,避免资源耗尽!
- 使用线程池还能避免频繁创建消耗资源,演示一下:
import threading, time from concurrent.futures import ThreadPoolExecutor def func(a,b): print(threading.current_thread().name,a ,b) time.sleep(0.01) # 必须睡一会儿,否则只是用一个线程 return a+b exe = ThreadPoolExecutor(3) # 3个线程的线程池 # result = exe.submit(func, 2, 3) ## print(result.result()) # 5 # 还可以使用map函数执行指定函数 result = exe.map(func, range(1,4), range(2,5)) # range返回迭代器,这里多出池内个数 # result是结果的迭代器 print(list(result)) # [3, 5, 7] # 这里只有3个结果,池子里的不够用,占坑的还没释放,直接不干了 # ThreadPoolExecutor-0_0 1 2 # ThreadPoolExecutor-0_1 2 3 # ThreadPoolExecutor-0_2 3 4 - 我们直接将
ThreadingTCPServer继承,追踪代码找到他需要的__init__参数,调用父类构造器并创建线程池,使用线程池的submit/map调用它的核心方法process_request中的process_request_thread - 以上也是改写代码的基本流程!
问题:如何使用多进程
- 想要处理CPU密集型任务,可以使用多进程,看两段多进程的演示代码
from multiprocessing import Process import time x = 0 def func(): global x x += 1 time.sleep(1) print('x:',x) # 1 if __name__ == '__main__': p = Process(target=func) p.start() p.join() # 等待子进程结束,主进程再执行 print('x:',x) # 0 不同进程之间是隔离的,这个x并没有改变 print('main process end...')- 和多线程之间最大的不同是,不同进程之间使用不同的虚拟地址空间(不共享资源)
- 所以,这里的全局
x结果不同
- 进程之间的通信可以使用管道,演示一下:
from multiprocessing import Queue, Pipe, Process def func(c): data = c.recv() print(data) c.send(data + 1) if __name__ == '__main__': c1, c2 = Pipe() # 两端!双工 p1 = Process(target=func, args=(c2,)).start() c1.send(99) print(c1.recv()) # 100 - 看一段判断水仙花数的代码:
from threading import Thread from multiprocessing import Process from queue import Queue as Thread_Queue from multiprocessing import Queue as Process_Queue def is_armstrong(n): a, t = [], n while t: a.append(t % 10) t //= 10 k = len(a) return sum(x ** k for x in a) == n def find_armstrong(a, b, q=None): res = [x for x in range(a, b) if is_armstrong(x)] if q: q.put(res) return res # 使用多线程实现,需要60s def find_by_thread(*ranges): q = Thread_Queue() workers = [] for r in ranges: a, b = r t = Thread(target=find_armstrong, args=(a, b, q)) t.start() workers.append(t) res = [] for _ in range(len(ranges)): res.extend(q.get()) return res # 使用多进程实现 def find_by_process(*ranges): # 元组参数解包 q = Process_Queue() workers = [] for r in ranges: a, b = r t = Process(target=find_armstrong, args=(a, b, q)) t.start() workers.append(t) # 没卵用,4个进程的一些信息 res = [] for _ in range(len(ranges)): res.extend(q.get()) # q中存的是列表 return res if __name__ == '__main__': import time t0 = time.time() # 进程数量由参数决定 res = find_by_process([10000000, 15000000], [15000000, 20000000], [20000000, 25000000], [25000000, 30000000]) # 16s print(res) print(time.time() - t0)- 注意区别进程中的
Queue - 可以看一下CPU,一下4个核就满了
- 注意区别进程中的
- 思考:进程间队列和线程间队列的区别是什么?
装饰器
- 装饰器使用及相关技巧
问题:如何使用装饰器
- 场景:想为多个函数添加统一的功能,又不想写多份一样的代码
- 用两个递归的例子来说明
# 斐波那契数列 # 1 1 2 3 5 8... def fib(n): if n<=1: return 1 return fib(n-1) + fib(n-2) print(fib(6)) # 爬楼梯问题 # 每次可以爬1/2/3级台阶,问有多少种爬法 def climb(n): ''' :param n: 还剩多少台阶 :return: n个台阶的爬法 ''' count = 0 if n==0: count = 1 # 爬完了! 从简单情况出发,若只有1/2/3级,一步跨完,算一种方法,其他方法交给另外两个climb elif n>0: count = climb(n-1)+climb(n-2)+climb(n-3) return count print(climb(4)) - 跟踪上面两个递归的过程会发现,有很多重复的计算,我们可以建立
cache加速 - 如何一次实现给两个函数加cache?
# 装饰器:工厂模式 def deco(func): # 传入被装饰的函数 cache = {} # 使用字典作为缓存 def wrap(*args): # 接收函数参数 res = cache.get(args) # 元组可以作为字典的键 if not res: res = cache[args] = func(*args) return res return wrap # 返回包装后的函数 fib = deco(fib) # 使用同名接收,可以对用户透明 print(fib(6)) # 装饰也可以直接使用语法糖 @deco def fib(n): if n<=1: return 1 return fib(n-1) + fib(n-2) @deco def climb(n): ''' :param n: 还剩多少台阶 :return: n个台阶的爬法 ''' count = 0 if n==0: count = 1 # 爬完了! 从简单情况出发,若只有1/2/3级,一步跨完,算一种方法,其他方法交给另外两个climb elif n>0: count = climb(n-1)+climb(n-2)+climb(n-3) return count- 装饰之后秒出结果,这就是算法的魅力!使用cache也是加速递归最常用的思想
问题:如何保存原函数的信息
- 函数中保存着一些必要的信息
print(climb.__name__) # 函数名 print(climb.__doc__) # 函数文档字符串 print(climb.__module__) # 所属模块 print(climb.__dict__) # 属性字典 print(climb.__defaults__) # 默认参数元组 print(climb.__annotations__) # 参数及返回值注释 {'n':, 'return': } - 使用装饰器后,返回的就是wrap函数的信息了,怎么整?
- 我们可以在装饰器中将wrap的信息替换为func的,
wraps装饰器帮我们实现了
from functools import update_wrapper, wraps # wraps是装饰器,内部调用update_wrapper def deco(func): @wraps(func) def wrap(*args): ''' 这是wrap的文档 :param args: :return: ''' return func() # 被装饰函数有返回值就要return return wrap @deco def func(a): ''' func的文档 :param a: :return: ''' print(a) print(func.__doc__) - 我们可以在装饰器中将wrap的信息替换为func的,
问题:如何定义带参数的装饰器
- 场景:使用装饰器检测函数参数类型,不同函数参数长度、类型不一,这就需要给装饰器定义参数
- 这个需求也可以理解为:生产装饰器的装饰器!
- 实现类型的检查,可以通过绑定参数实现,用
inspect,下面是例子:import inspect # Get useful information from live Python objects. def func1(a,b,c): print(a,b,c) func1_sig = inspect.signature(func1) # 得到函数的签名 bind = func1_sig.bind(int,int,str) # 一一对应,给函数参数绑定类型值 print(bind.arguments) # {'a':, 'b': , 'c': } - 可以将传递给装饰器的参数类型和函数调用时的参数值分别绑定到函数,校验!
def deco_wrap(*typet, **typed): def deco(func): func_sig = inspect.signature(func) # 绑定正确参数类型 bind = func_sig.bind_partial(*typet, **typed).arguments # 不一定全部绑定 def wrap(*args, **kwargs): # 绑定参数值 for name, value in func_sig.bind(*args, **kwargs).arguments.items(): # 这里可以使用bind,因为是绑定值,不传入所需参数直接报错 right_type = bind[name] if right_type: if not isinstance(value, right_type): raise TypeError("not match, %s must be %s type"%(name, right_type)) return func(*args, **kwargs) return wrap return deco @deco_wrap(int, str) def func2(a,b): print(a,b) func2(1,2) # TypeError: not match, b must betype
问题:如何实现属性可修改的函数装饰器
- 场景
- 统计被装饰函数的单次运行时间
- 如果时间大于timeout,就记录到log中
- 能动态的修改
timeout参数
import random import logging import time def deco_wrap(timeout): def deco(func): def wrap(*args): t0 = time.time() res = func(*args) use = time.time() - t0 if use>timeout: logging.warning("%s %s %s"%(func.__name__, use, timeout)) # 控制台打印 return res def set_time(new_timeout): nonlocal timeout # 类似于函数中使用全局变量,global一下 timeout = new_timeout # 修改成功 wrap.set_time = set_time # 给定调用方法,用deco返回;相当于wrap的子函数 return wrap return deco @deco_wrap(1.0) def func(i): while random.randint(0,1): time.sleep(0.5) print('in func[%d]'%i) if __name__ == '__main__': for i in range(15): func(i) if i==5: func.set_time(1.5) # 调用装饰后的函数修改- 重点是学习装饰器内部定义多个函数并返回调用的方法
- 在程序中如果不是面向对象式编程(class中用self,一样的道理),必须要用
global参数,函数才能访问外部全局变量
问题:如何在类中定义装饰器
- 上一个问题中,我们需要在函数中使用外部的变量,能否通过类的属性实现变量的全局传递呢?
- 当然可以!道理是相同的,Demo如下:
import time import logging DEFAULT_FORMAT = '%(func_name)s -> %(call_time)s\t%(used_time)s\t%(call_n)s' class CallInfo: def __init__(self, log_path, format_=DEFAULT_FORMAT, on_off=True): self.log = logging.getLogger(log_path) self.log.addHandler(logging.FileHandler(log_path)) self.log.setLevel(logging.INFO) self.format = format_ self.is_on = on_off # 装饰器方法 def info(self, func): _call_n = 0 def wrap(*args, **kwargs): func_name = func.__name__ call_time = time.strftime('%x %X', time.localtime()) t0 = time.time() res = func(*args, **kwargs) used_time = time.time() - t0 nonlocal _call_n _call_n += 1 call_n = _call_n if self.is_on: self.log.info(self.format % locals()) return res return wrap def set_format(self, format_): self.format = format_ # 便于修改属性 def turn_on_off(self, on_off): self.is_on = on_off # 测试代码 import random ci1 = CallInfo('mylog1.log') # 带参数的装饰器,但参数被维护在构造方法里 ci2 = CallInfo('mylog2.log') @ci1.info def f(): sleep_time = random.randint(0, 6) * 0.1 time.sleep(sleep_time) @ci1.info def g(): sleep_time = random.randint(0, 8) * 0.1 time.sleep(sleep_time) @ci2.info def h(): sleep_time = random.randint(0, 7) * 0.1 time.sleep(sleep_time) for _ in range(30): random.choice([f, g, h])() ci1.set_format('%(func_name)s -> %(call_time)s\t%(call_n)s') # 直接使用实例对象调用方法修改,相当于将函数全部托管给类 for _ in range(30): random.choice([f, g])() print(type(g)) #是的,已经属于类了 - 把类的实例方法作为装饰器,在wrap函数中就可以持有实例对象,便于修改属性和拓展功能!
- 装饰一个函数就实例化一个对象吧,避免牵一发而动全身!
小结
- 至此,总结了大部分的实用编程技巧,还有很多需要在工作中改进学习的地方,逐步积累!