《机器学习》第6章 支持向量机
文章目录
- 6.1 间隔与支持向量
- 6.2 对偶问题
- 6.3 核函数
-
- 支持向量展式
- 核函数
- 6.4 软间隔与正则化
- 6.5 支持向量回归(SVR)
- 6.6 核方法
6.1 间隔与支持向量
分类学习最基本的想法就是基于训练集D在样本空间中找到一个划分超平面,将不同类别的样本分开.但能将训练样本分开的划分超平面可能有很多,如图6.1所示,我们应该努力去找到哪一个呢?
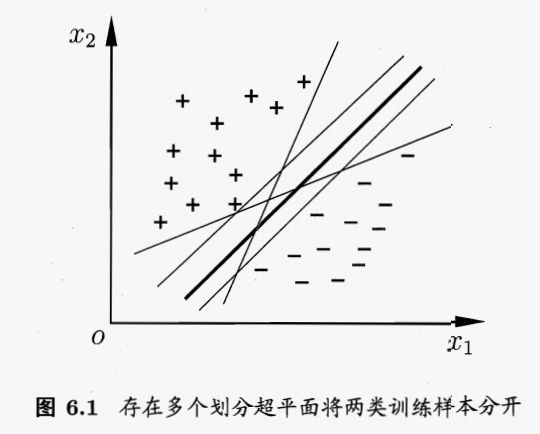
在样本空间中,划分超平面可通过如下线性方程来描述:w为法向量,决定了超平面的方向;b为位移项,决定了超平面与远点间的距离。

样本空间中任意点x到超平面(w,b)的距离可写为:

假设超平面(w,b)能将训练样本正确分类,则有:

如图6.2所示,距离超平面最近的这几个训练样本点使式(6.3)的等号成立,它们被称为“支持向量”(support vector),两个异类支持向量到超平面的距离之和为

它被称为间隔。
支持向量与间隔:

目标:找最大间隔

即:
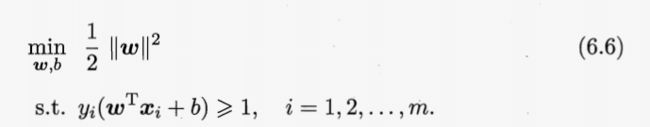
这就是支持向量机(简称SVM) 的基本型。
6.2 对偶问题
问题:求解(6.6)式得到大间隔划分超平面所对应的模型
对式(6.6)使用拉格朗日乘子法可得到其“对偶问题”(dual problem).具体来说,对式(6.6)的每条约束添加拉格朗日乘子α≥0,则该问题的拉格朗日函数可写为

求偏导:

代回原式得到对偶问题:


求解得到模型:
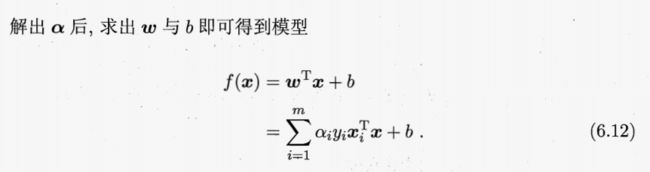
(6.6)式有不等式约束,因此上述过程需要满足KKT条件限制:

支持向量机的一个重要性质:
训练完成后,大部分的训练样本都不需保留,最终模型仅与支持向量有关。
如何求解(6.11)式呢?
SMO算法:

![]()
6.3 核函数
问题:在现实任务中,原始样本空间并不存在一个能正确划分两类样本的超平面。
解决方案:向高维空间映射。

如果原始空间是有限维,即属性数有限,那么一定存在一个高维特征空间使样本可分。
映射模型:

转换:

其对偶问题是:
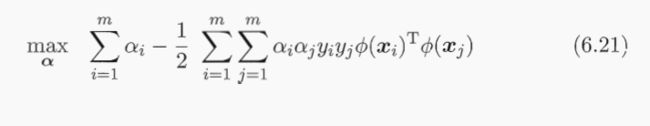
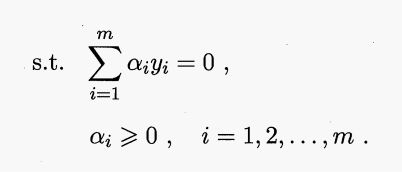
支持向量展式
又提出一个难题?

函数重写·:

求解:

什么样的函数能作核函数呢?
核函数

定理6.1表明, 只要一个对称函数所对应的核矩阵半正定,它就能作为核函数使用.事实上,对于一个半正定核矩阵,总能找到一个与之对应的映射.换言之,任何一个核函数都隐式地定义了一个称为“再生核希尔伯特空间”(Reproducing Kernel Hilbert Space.简称RKHS)的特征空间。
通过前面的讨论可知,我们希望样本在特征空间内线性可分,因此特征空间的好坏对支持向量机的性能至关重要.需注意的是,在不知道特征映射的形式时,我们并不知道什么样的核函数是合适的,而核函数也仅是隐式地定义了这个特征空间.于是,“核函数选择” 成为支持向量机的最大变数.若核函数选择不合适,则意味着将样本映射到了一个不合适的特征空间,很可能导致性能不佳.

性质:



6.4 软间隔与正则化
在前面的讨论中,我们一直假定训练样本在样本空间或特征空间中是线性可分的,即存在一个超平面能将不同类的样本完全划分开.然而,在现实任务中往往很难确定合适的核函数使得训练样本在特征空间中线性可分;退一步说,即便恰好找到了某个核函数使训练集在特征空间中线性可分,也很难断定这个貌似线性可分的结果不是由于过拟合所造成的.
缓解该问题的一个办法是允许支持向量机在一些样本上出错.为此,要引入“软间隔”(soft margin)的概念,如图6.4所示.

具体来说,前面介绍的支持向量机形式是要求所有样本均满足约束(6.3),即所有样本都必须划分正确,这称为“硬间隔”,而软间隔则是允许某些样本不满足约束。

当然,在最大化间隔的同时,不满足约束的样本尽可能少,于是,优化目标可写为:

0/1损失函数非凸、非连续,数学性质不好,使得(6.29)式不易直接求解,于是人们通常用一些函数来替代损失函数,以下给出了三种替代损失函数:
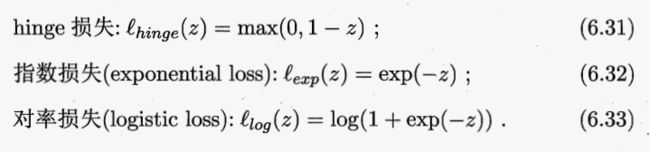
若采用hinge损失,则式(6.29)变成

引入松弛变量,对(6.34)重写:

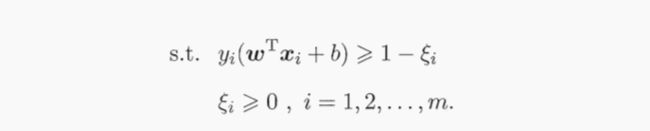

6.5 支持向量回归(SVR)

SVR问题可形式化为:

不敏感损失函数:

引入松弛变量,将式(6.43)重写为:
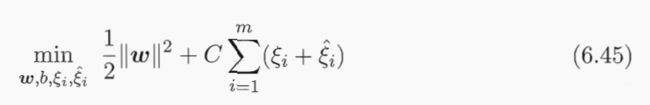
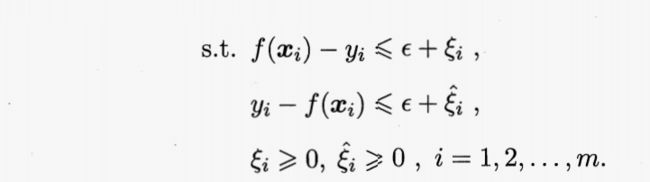

6.6 核方法

人们发展出一系列基于核函数的学习方法,统称为“核方法”(kernelmethods).最常见的,是通过“核化”(即引入核函数)来将线性学习器拓展为非线性学习器.下面我们以线性判别分析为例来演示如何通过核化来对其进行非线性拓展,从而得到“核线性判别分析”(Kernelized Linear DiscriminantAnalysis,简称KLDA).
假设:

类似于式(3.35),KLDA的学习目标是

均值:

两个散度矩阵分别为

函数h(x)可写为:

于是由式(6.59)可得


