【C++】关于C++11系列,你需要知道这些事——C++11最全系列讲解(上篇)
目录
一、C++11内容简介
二、初始化表达式
2.1 C++98中{}的初始化问题
2.2 内置类型的列表初始化
2.3 自定义类型的列表初始化
补充:std::initializer_list
三、 声明
3.1 auto
3.2 decltype
补充:C++11后越界检查
四、(重点)右值引用和移动语义
4.1什么是左值、右值?
左值
右值
4.2左值引用与右值引用比较
左值引用总结:
右值引用总结:
4.3 右值引用使用场景和意义
4.4右值引用引用左值及其一些更深入的使用场景分析
五、完美转发
完美转发实际中的使用场景:
一、C++11内容简介


二、初始化表达式
2.1 C++98中{}的初始化问题
在 C++98 中,标准允许使用花括号 {} 对数组元素进行统一的列表初始值设定。比如:
int array1[] = {1,2,3,4,5};
int array2[5] = {0};对于一些自定义的类型,却无法使用这样的初始化。比如:
vectorv{1,2,3,4,5}; 就无法通过编译,导致每次定义vector时,都需要先把vector定义出来,然后使用循环对其赋初始值,非常不方便。C++11扩大了用大括号括起的列表(初始化列表)的使用范围,使其可用于所有的内置类型和用户自定义的类型,使用初始化列表时,可添加等号(=),也可不添加。
2.2 内置类型的列表初始化
int main()
{
// 内置类型变量
int x1 = {10};
int x2{10};
int x3 = 1+2;
int x4 = {1+2};
int x5{1+2};
// 数组
int arr1[5] {1,2,3,4,5};
int arr2[]{1,2,3,4,5};
// 动态数组,在C++98中不支持
int* arr3 = new int[5]{1,2,3,4,5};
// 标准容器
vector v{1,2,3,4,5};
map m{{1,1}, {2,2,},{3,3},{4,4}};
return 0;
} 注意:列表初始化可以在{}之前使用等号,其效果与不使用=没有什么区别。
但是实话实说,虽然可以省略括号,但是我们并不建议这样用,因为加上等号之后更可以体现出代码的规范性。
2.3 自定义类型的列表初始化
这里我们先以日期类举例,看到自定义类型初始化列表的情况。
class Date
{
public:
Date(int year = 0, int month = 1, int day = 1)
:_year(year)
, _month(month)
, _day(day)
{
cout << "Date(int year, int month, int day)" << endl;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
Point p1 = { 1, 2 };
Point p2 { 1, 2 };
int x1 = 1;
int x2{ 2 };
// !!!
int* p3 = new int[4]{0};
int* p4 = new int[4]{1,2,3,4};
Date d1;
Date d2(2022, 1, 17);
// 这里虽然可以这么用,但是我们建议大家用,这种用法是为其他地方准备的
Date d3{2022, 1, 18};
Date d4 = { 2022, 1, 18 };
return 0;
}补充:std::initializer_list
文档介绍链接:initializer_list - C++ Reference

那么这个到底是什么类型呢?

我们看到的是 initializer_list 可以进行大括号进行初始化。那么这个容器到底有什么用呢?我们来看一下下面的这几个赋值
vector v = { 1, 2, 3, 4, 5 };
list lt { 10, 20, 30};
vector vd = { { 2022, 1, 17 }, Date{ 2022, 1, 17 }, { 2022, 1, 17 } };
map dict = { make_pair("sort", 1), { "insert", 2 } }; 这里你会发现,这些都可以进行大括号赋值,那么为什么会出现这种情况呢,显然,这些都不是凭空支持的。
显然,这里并不是C++11语法性质支持,而是每一个容器接口里面都有一个initializer_list的构造函数,大括号的列表直接就是一个initializer_list的类型,这个时候就会调用initializer_list的构造函数,把他的所有值取出来,然后一个一个进行赋值。
我们可以尝试用Vector模拟实现initializer_list。
这里我们可以进行模拟实现以下:
namespace self
{
template
class vector {
public:
typedef T* iterator;
vector(initializer_list l)
{
_start = new T[l.size()];
_finish = _start + l.size();
_endofstorage = _start + l.size();
iterator vit = _start;
/*typename initializer_list::iterator lit = l.begin();
while (lit != l.end())
{
*vit++ = *lit++;
}*/
for (auto e : l)
*vit++ = e;
}
vector& operator=(initializer_list l) {
vector tmp(l);
std::swap(_start, tmp._start);
std::swap(_finish, tmp._finish);
std::swap(_endofstorage, tmp._endofstorage);
return *this;
}
private:
iterator _start;
iterator _finish;
iterator _endofstorage;
}; 就是通过start,finish ,size(),这三个接口来进行赋值内容的记录,实现用大括号给其内容赋值的工作。
三、 声明
c++11提供了多种简化声明的方式,尤其是在使用模板时。
3.1 auto

int main()
{
int i = 10;
auto p = &i;
auto pf = strcpy;
cout << typeid(p).name() << endl;
cout << typeid(pf).name() << endl;
map dict = { {"sort", "排序"}, {"insert", "插入"} };
//map::iterator it = dict.begin();
auto it = dict.begin();
return 0; } 3.2 decltype
#include
using namespace std;
// decltype的一些使用使用场景
template
void F(T1 t1, T2 t2) {
decltype(t1 * t2) ret;
cout << typeid(ret).name() << endl;
}
int main()
{
const int x = 1;
double y = 2.2;
decltype(x * y) ret; // ret的类型是double
decltype(&x) p;// p的类型是int *
cout << typeid(ret).name() << endl;
cout << typeid(p).name() << endl; F(1, 'a');
return 0;
} 总而言之,用的还是比较少的,大概就是可以进行推演。
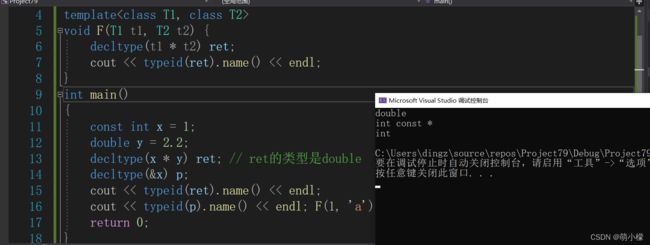
一些特定的使用场景:
template
void F(T1 t1, T2 t2)
{
decltype(t1 * t2) ret;
cout << typeid(ret).name() << endl;
}
void f(int)
{
cout << "void f(int)" << endl;
}
void f(int*)
{
cout << "void f(int*)" << endl;
}
int main()
{
const int x = 1;
double y = 2.2;
decltype(x * y) ret; // ret的类型是double
//auto ret = x*y;
decltype(&x) p; // p的类型是int*
cout << typeid(ret).name() << endl;
cout << typeid(p).name() << endl;
f(NULL);
f(nullptr);
F(x, y);
return 0;
} 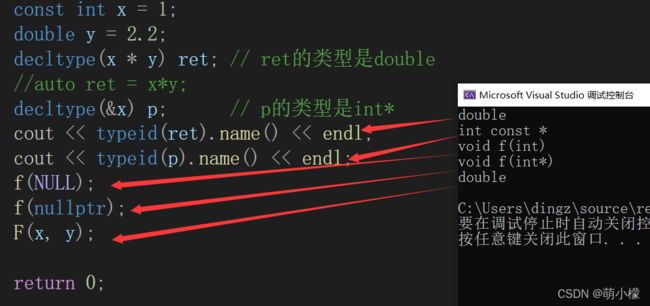
根据函数重载,可以看出哪些是指针(nullptr),哪些是整型。
3.3 nullptr
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif补充:C++11后越界检查
前期在越界时候,如果出现了不过分的越界现象,编译器不一定能查出,但是C++11之后,出现了更加严格的与业界检查标准。
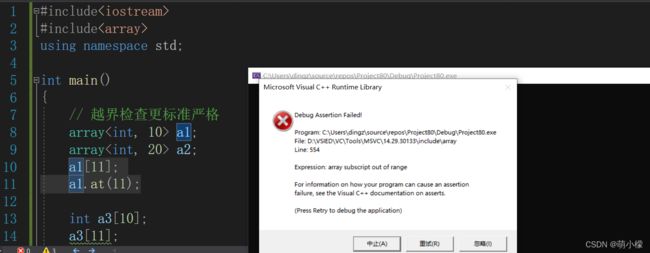
int main()
{
// 越界检查更标准严格
array a1;
array a2;
//a1[11];
//a1.at(11);
int a3[10];
a3[11];//未检查出
vector v;
v.resize(10);
return 0;
} 在没有放开注释部分之前,虽然有警告,但是并没有出现报错,传统定义的数组a3越界但是编译器没有检查出来。

当把注释部分放开之后我们发现,直接出现了越界报错,array定义的在C++11标准,有了更加严格的越界检查。
四、(重点)右值引用和移动语义
4.1什么是左值、右值?
左值
int main()
{
// 以下的p、b、c、*p都是左值
int* p = new int(0);
int b = 1;
const int c = 2;
// 以下几个是对上面左值的左值引用
int*& rp = p;
int& rb = b;
const int& rc = c;
int& pvalue = *p;
return 0; }右值
int main()
{
double x = 1.1, y = 2.2;
// 以下几个都是常见的右值
10; x + y;
fmin(x, y);
// 以下几个都是对右值的右值引用
int&& rr1 = 10;
double&& rr2 = x + y;
double&& rr3 = fmin(x, y);
// 这里编译会报错:error C2106: “=”: 左操作数必须为左值
10 = 1; x + y = 1;
fmin(x, y) = 1;
return 0; }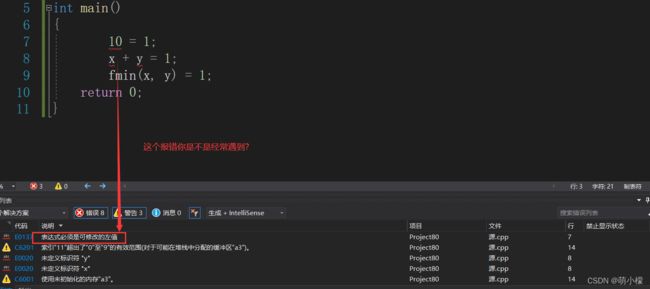
int main()
{
double x = 1.1, y = 2.2;
int&& rr1 = 10;
const double&& rr2 = x + y;
rr1 = 20;
rr2 = 5.5; // 报错
return 0;
}4.2左值引用与右值引用比较
左值引用总结:
int main()
{
// 左值引用只能引用左值,不能引用右值。
int a = 10;
int& ra1 = a; // ra为a的别名
//int& ra2 = 10; // 编译失败,因为10是右值
// const左值引用既可引用左值,也可引用右值。
const int& ra3 = 10;
const int& ra4 = a;
return 0;
}右值引用总结:
int main()
{
// 右值引用只能右值,不能引用左值。
int&& r1 = 10;
// error C2440: “初始化”: 无法从“int”转换为“int &&”
// message : 无法将左值绑定到右值引用
int a = 10;
int&& r2 = a;
// 右值引用可以引用move以后的左值
int&& r3 = std::move(a);
return 0;
}4.3 右值引用使用场景和意义
namespace Self
{
class string
{
public:
typedef char* iterator;
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
string(const char* str = "")
:_size(strlen(str))
, _capacity(_size)
{
//cout << "string(char* str)" << endl;
_str = new char[_capacity + 1];
strcpy(_str, str);
}
// s1.swap(s2)
void swap(string& s)
{
::swap(_str, s._str);
::swap(_size, s._size);
::swap(_capacity, s._capacity);
}
// 拷贝构造
string(const string& s)
:_str(nullptr)
{
cout << "string(const string& s) -- 深拷贝" << endl;
string tmp(s._str);
swap(tmp);
}
// 移动构造
string(string&& s)
:_str(nullptr)
, _size(0)
, _capacity(0)
{
cout << "string(string&& s) -- 移动构造" << endl;
this->swap(s);
}
// 移动赋值
string& operator=(string&& s)
{
cout << "string& operator=(string&& s) -- 移动赋值" << endl;
this->swap(s);
return *this;
}
// 赋值重载
string& operator=(const string& s)
{
cout << "string& operator=(string s) -- 深拷贝" << endl;
string tmp(s);
swap(tmp);
return *this;
}
~string()
{
delete[] _str;
_str = nullptr;
}
char& operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
void reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
void push_back(char ch)
{
if (_size >= _capacity)
{
size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;
reserve(newcapacity);
}
_str[_size] = ch;
++_size;
_str[_size] = '\0';
}
//string operator+=(char ch)
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
const char* c_str() const
{
return _str;
}
private:
char* _str;
size_t _size;
size_t _capacity; // 不包含最后做标识的\0
};
Self::string to_string(int value)
{
bool flag = true;
if (value < 0)
{
flag = false;
value = 0 - value;
}
Self::string str;
while (value > 0)
{
int x = value % 10;
value /= 10;
str += ('0' + x);
}
if (flag == false)
{
str += '-';
}
std::reverse(str.begin(), str.end());
return str;
}
}// 左值引用的使用场景
// 1、做参数
// 2、做返回值
void func1(bit::string s)
{}
void func2(const bit::string& s)
{}
int main()
{
Self::string s1("hello world");
// func1和func2的调用我们可以看到左值引用做参数减少了拷贝,提高效率的使用场景和价值
func1(s1);
func2(s1);
return 0;
}

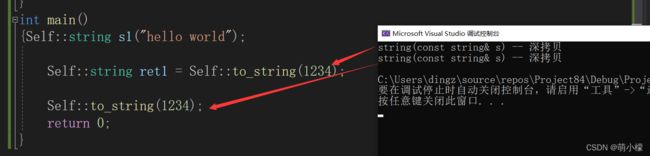
int main()
{Self::string s1("hello world");
s1 += 'A';
return 0;
}但是你会发现to_string 不能用左值引用返回,这个就是左值引用短板
如果函数返回对象除了函数作用域就不在了,就不能使用做引用返回,就会存在拷贝。

一般编译器优化之后,进行一次深拷贝,代价比较大。
这个时候我们应该如何来进行优化呢,这个时候就需要用到右值引用了。
我们再对右值加深这里我们仿照拷贝赋值,让他于拷贝形成一个对比,再写一个移动赋值
这里我们多一层理解,右值分为两类:
1.纯的右值,如10;x+y;
2.临时创建的对象,将要销毁的返回值。

优化的点在哪里呢?
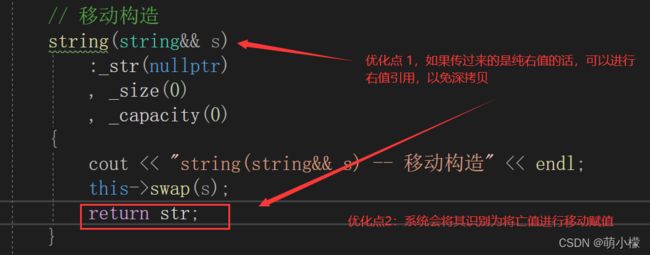

// 移动赋值
string& operator=(string&& s) {
cout << "string& operator=(string&& s) -- 移动语义" << endl;
swap(s);
return *this; }
int main()
{
Self::string ret1;
ret1 = Self::to_string(1234);
return 0; }
// 运行结果:
// string(string&& s) -- 移动语义
// string& operator=(string&& s) -- 移动语义运行结果如上,我们不难发现这里运行后,我们看到调用了一次移动构造和一次移动赋值。因为如果是用一个已经存在的对象 接收,编译器就没办法优化了。self::to_string函数中会先用str生成构造生成一个临时对象,但是 我们可以看到,编译器很聪明的在这里把str识别成了右值,调用了移动构造。然后在把这个临时 对象做为Self::to_string函数调用的返回值赋值给ret1,这里调用的移动赋值。
int main()
{
list lt;
std::string s1("1111");
// 这里调用的是拷贝构造
lt.push_back(s1);
// 下面调用都是移动构造
lt.push_back("2222");
lt.push_back(std::string("2222"));
lt.push_back(std::move(s1));
return 0;
} 4.4右值引用引用左值及其一些更深入的使用场景分析
template
inline typename remove_reference<_Ty>::type&& move(_Ty&& _Arg) _NOEXCEPT
{
// forward _Arg as movable
return ((typename remove_reference<_Ty>::type&&)_Arg);
}
int main()
{
Self::string s1("hello world");
// 这里s1是左值,调用的是拷贝构造
Self::string s2(s1);
// 这里我们把s1 move处理以后, 会被当成右值,调用移动构造
// 但是这里要注意,一般是不要这样用的,因为我们会发现s1的
// 资源被转移给了s3,s1被置空了。
bit::string s3(std::move(s1));
return 0; } 下图为优化图解,其本质原理大概为:
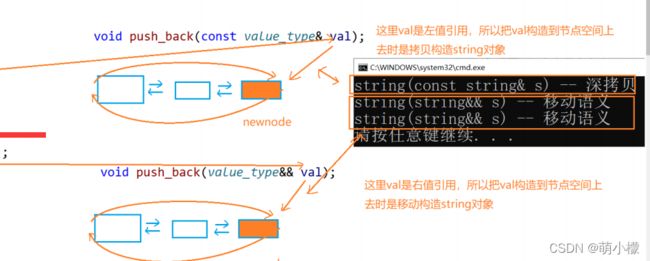
总结:
右值引用出来以后,并不是直接使用右值引用去减少拷贝,提高效率。而是支持深拷贝的类,提供移动构造和移动赋值,这时这些类的对象进行传值返回或者是参数为右值时,则可以用移动构造和移动赋值,转移资源,避免深拷贝,提高效率。
五、完美转发
void Fun(int &x){ cout << "左值引用" << endl; }
void Fun(const int &x){ cout << "const 左值引用" << endl; }
std::forward 完美转发在传参的过程中保留对象原生类型属性
void Fun(int &&x){ cout << "右值引用" << endl; }
void Fun(const int &&x){ cout << "const 右值引用" << endl; }
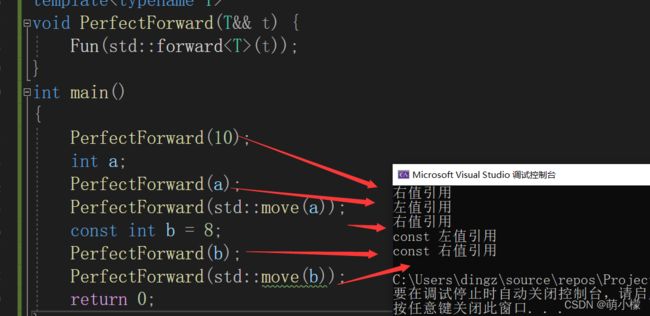
template
void PerfectForward(T&& t) {
Fun(t);
}
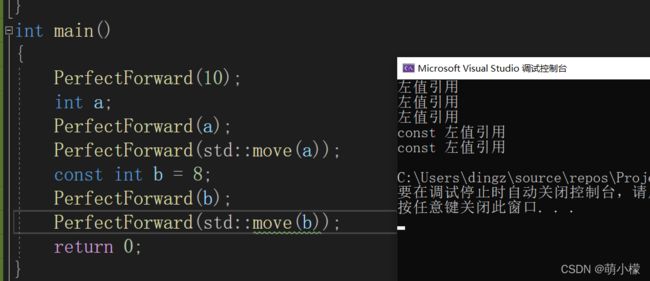
int main()
{
PerfectForward(10); // 右值
int a;
PerfectForward(a); // 左值
PerfectForward(std::move(a)); // 右值
const int b = 8;
PerfectForward(b); // const 左值
PerfectForward(std::move(b)); // const 右值
return 0; } 按说应该是按照上面的注释中的左右值进行输出,但是结果是什么呢?我们看到的是
这是为什么呢?
模板中的&&不代表右值引用,而是万能引用,其既能接收左值又能接收右值。
模板的万能引用只是提供了能够接收同时接收左值引用和右值引用的能力,
但是引用类型的唯一作用就是限制了接收的类型,后续使用中都退化成了左值,
我们希望能够在传递过程中保持它的左值或者右值的属性, 就需要用我们下面学习的完美转发。
这个时候咋办?我们引进一个 std::forward
其作用为:完美转发在传参的过程中保留对象原生类型属性.
完美转发实际中的使用场景:
这里我们以链表为例,我们进行详细看一下
template
struct ListNode
{
ListNode* _next = nullptr;
ListNode* _prev = nullptr;
T _data;
};
template
class List
{
typedef ListNode Node;
public:
List()
{
_head = new Node;
_head->_next = _head;
_head->_prev = _head;
}
void PushBack(T&& x)
{
//Insert(_head, x);
Insert(_head, std::forward(x));
}
void PushFront(T&& x)
{
//Insert(_head->_next, x);
Insert(_head->_next, std::forward(x));
}
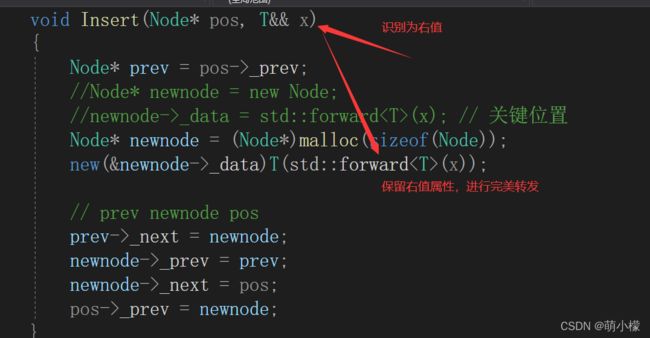
void Insert(Node* pos, T&& x)
{
Node* prev = pos->_prev;
Node* newnode = new Node;
newnode->_data = std::forward(x); // 关键位置
// prev newnode pos
prev->_next = newnode;
newnode->_prev = prev;
newnode->_next = pos;
pos->_prev = newnode;
}
void Insert(Node* pos, const T& x)
{
Node* prev = pos->_prev;
Node* newnode = new Node;
newnode->_data = x; // 关键位置
// prev newnode pos
prev->_next = newnode;
newnode->_prev = prev;
newnode->_next = pos;
pos->_prev = newnode;
}
private:
Node* _head;
};
int main()
{
List lt;
lt.PushBack("1111");
lt.PushFront("2222");
return 0; } int main()
{
List lt;
Self::string s1("1111");
lt.PushBack(s1);
lt.PushBack("1111");
lt.PushFront("2222");
list lt;
std::string s1("1111");
//这里调用的是拷贝构造
lt.push_back(s1);
// 下面调用都是移动构造
lt.push_back("2222");
lt.push_back(std::string("2222"));
lt.push_back(std::move(s1));
return 0;
} 在选择插入删除时候,调用模板,为了提高效率,就必须保证其原属性,那么这个时候就必须用到完美转发,在这里得以应用