使用scrapy爬取斗鱼直播间信息
目录
- 1. 谷歌抓包工具的使用
-
- 1.1 打开Chrome开发者工具的方法
- 1.2 开发者工具的结构
- 1.3 network模块
- 2. 使用谷歌抓包工具抓取斗鱼数据
- 3. 使用scrapy爬取斗鱼直播间信息
1. 谷歌抓包工具的使用
1.1 打开Chrome开发者工具的方法
- 在Chrome界面按F12
- or在页面元素上右键点击,选择“检查”
1.2 开发者工具的结构

根据上图结构,从左到右依次介绍如下:
Elements(元素面板):使用“元素”面板可以通过自由操纵DOM和CSS来重演您网站的布局和设计。
Console(控制台面板):在开发期间,可以使用控制台面板记录诊断信息,或者使用它作为 shell,在页面上与JavaScript交互
Sources(源代码面板):在源代码面板中设置断点来调试 JavaScript ,或者通过Workspaces(工作区)连接本地文件来使用开发者工具的实时编辑器
Network(网络面板):从发起网页页面请求Request后得到的各个请求资源信息(包括状态、资源类型、大小、所用时间等),并可以根据这个进行网络性能优化
Performance(性能面板):使用时间轴面板,可以通过记录和查看网站生命周期内发生的各种事件来提高页面运行时的性能
Memory(内存面板):分析web应用或者页面的执行时间以及内存使用情况
Application(应用面板):记录网站加载的所有资源信息,包括存储数据(Local Storage、Session Storage、-IndexedDB、Web SQL、Cookies)、缓存数据、字体、图片、脚本、样式表等
Security(安全面板):使用安全面板调试混合内容问题,证书问题等等
Audits(审核面板):对当前网页进行网络利用情况、网页性能方面的诊断,并给出一些优化建议。比如列出所有没有用到的CSS文件等。
1.3 network模块
定义:Network 面板记录页面上每个网络操作的相关信息,包括详细的耗时数据、HTTP 请求与响应标头和 Cookie
结构:由五个窗格组成,如图
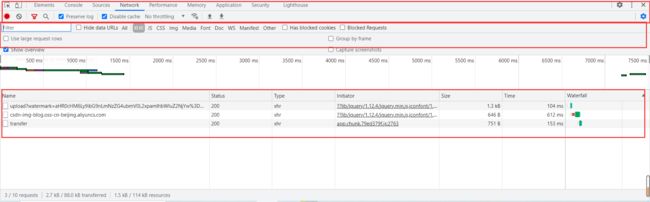
Controls(控件) 使用这些选项可以控制 Network(网络)面板的外观和功能
Filters(过滤器)使用这些选项可以控制在请求列表中显示哪些资源
Overview(概览)这个图表显示检索资源的时间轴。如果您看到多个垂直堆叠的栏,这意味着这些资源被同时检索。
提示:按住Ctrl(Window / Linux),然后点击过滤器可以同时选择多个过滤器。
这里,XHR主要是用来抓取ajax的请求,如图所示:

然后,我们就可以利用以上知识尝试抓取斗鱼页面的传输数据包
2. 使用谷歌抓包工具抓取斗鱼数据
1) 清空初始状态下的自动获取的请求列表,单击第二页的按钮,通过谷歌浏览器抓包抓取ajax请求,如图所示:

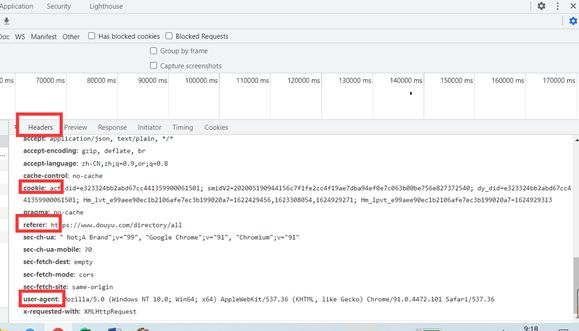
2) 查看对应url的请求头,分析需要携带的参数,这里简单介绍一下请求头中各个参数的作用:
Accept
作用: 浏览器端可以接受的媒体类型,
例如: Accept: text/html 代表浏览器可以接受服务器回发的类型为 text/html 也就是我们常说的html文档,
Accept-Encoding:
作用: 浏览器申明自己接收的编码方法,通常指定压缩方法,是否支持压缩,支持什么压缩方法(gzip,deflate),(注意:这不是只字符编码);
Accept-Language
作用: 浏览器申明自己接收的语言。
语言跟字符集的区别:中文是语言,中文有多种字符集,比如big5,gb2312,gbk等等;
Connection
例如: Connection: keep-alive 当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接
Host(发送请求时,该报头域是必需的)
作用: 请求报头域主要用于指定被请求资源的Internet主机和端口号,它通常从HTTP URL中提取出来的
Referer
当浏览器向web服务器发送请求的时候,一般会带上Referer,告诉服务器我是从哪个页面链接过来的,服务器籍此可以获得一些信息用于处理。比如从我主页上链接到一个朋友那里,他的服务器就能够从HTTP Referer中统计出每天有多少用户点击我主页上的链接访问他的网站。
User-Agent
作用:告诉HTTP服务器, 客户端使用的操作系统和浏览器的名称和版本.
Cookie
Cookie是用来存储一些用户信息以便让服务器辨别用户身份的(大多数需要登录的网站上面会比较常见),比如cookie会存储一些用户的用户名和密码,当用户登录后就会在客户端产生一个cookie来存储相关信息,这样浏览器通过读取cookie的信息去服务器上验证并通过后会判定你是合法用户,从而允许查看相应网页。当然cookie里面的数据不仅仅是上述范围,还有很多信息可以存储是cookie里面,比如sessionid等。
在这里我们通常使用的是cookie,referer和user-agent
如下图所示:
3) JSON 是前后端传输数据最常见的用法之一,是从 web 服务器上读取 JSON 数据(作为文件或作为 HttpRequest),将 JSON 数据转换为 JavaScript 对象,然后在网页中使用该数据。
我们的任务是要抓取到的json格式的数据,分析json的数据结构,找到我们要提取数据内容所在的位置。
通过分析,我们可以发现数据是存放在r1列表下的各个字典中的,我们可以使用循环,然后通过dict[‘key’]的方式来提取数据。

4) 分析url的相关规律,想办法构造多页的ajax请求,从而获取多页的数据

分析之后发现,url最后的一个数字是控制ajax请求的页码。
至此,抓包分析过程结束
3. 使用scrapy爬取斗鱼直播间信息
1)使用start_requests函数进行构造20页的url列表。
这里start_requests方法必须返回一个可迭代对象(iterable)。该对象包含了spider用于抓取的第一个Request。
当spider开始抓取并且未指定start_urls时,该方法将会被调用。该方法仅仅会被scrapy调用一次,因此可以将其实现为url生成器。
使用scrapy.Request可以发送一个GET请求,传送到指定的函数进行处理。
详细代码操作如下:
def start_requests(self):
for i in range(1,20):
start_url = "https://www.douyu.com/gapi/rkc/directory/mixList/0_0/{}".format(i)
yield scrapy.Request(
url=start_url,
callback=self.parse
)
2)使用parse函数提取数据
这里需要掌握几个重要的方法应用
response.text 请求返回的响应的字符串格式的数据
json.loads() loads方法是将str转化为dict格式数据
json.dumps() dumps方法是将dict格式的数据转化为str
具体代码操作如下:
data_dict = json.loads(response.text)
使用循环遍历json数据中的各个具体直播间数据的信息,新建一个item字典进行数据存储,然后使用yield传递给引擎进行相应的处理
代码操作如下:
for data in data_dict['data']['rl']:
domain = "https://www.douyu.com"
item = {}
item["直播间名称"] = data['rn']
item["主播名字"] = data['nn']
item["直播间id"] = data['rid']
item["直播类型"] = data['c2name']
item["主播别称"] = data['od']
item["直播间地址"] = domain + data["url"]
在管道中将提取到的数据保存成CSV文件
首先,先导入csv模块
import csv
定义csv文件需要的列标题
headers = ["room_name", "zhubo_name", "zhubo_id", "zhubo_type", "zhubo_other_name", "room_addr"]
每次调用pipline的时候,都会运行一遍
class Day02Pipeline:
def process_item(self, item, spider):
文件默认保存到当前目录下的douyu.csv中
这里a是追加操作
with open('douyu.csv', 'a', encoding='utf-8', newline='') as fa:
保存headers规定的列名内容
writer = csv.DictWriter(fa, headers)
writer.writerow(item)
print(item)
return item
4)最后,我们来查看一下运行结果,以及保存好的csv文件
终端运行结果如下:

CSV文件保存结果如下:
