2021-06 电商项目客户行为分析及预测
项目记录:本项目原始数据为某电商平台半年业务数据。
需根据业务数据完成:
1、结合业务素具,对订单客户进行初步用户画像描绘;
2、根据业务数据进行数据分析,建立模型,通过业务数据训练模型,拟定大促期间商品下单量:
**项目说明:
第一个模块为根据已有半年数据进行客户画像描绘;
涉及工具:python(pandas)、excel、tableau
第二个模块为根据前期数据行为预测出商品下单量
涉及工具:python(numpy、sklearn)、tableau**
第一个项目:客户画像描绘
项目背景
促销活动来袭,某平台希望通过发短信的形式,向潜在的用户发送广告和优惠信息,吸引他们来购物。
由于短信服务商限制,需要对客户进行精细匹配,通过已有信息进行客户画像描绘,找到最容易转化的人群,并且通过数据可以发现客户更青睐于在哪些时段下单,以期在适合时段进行短信推送。
项目目的
对于背景将任务拆解:
通过数据,找到最有可能转化的人群特征(年龄、性别、地域)等;
通过数据,决定出最有利于转化的营销短信投放时间。
项目资料
业务部门提供,包括三部分内容:
用户行为表:最近 6 个月的用户行为记录。
VIP 会员表:用户 VIP 会员开通情况。
用户信息表:用户的相关信息。
首先对于每个表的内容进行解释:
-
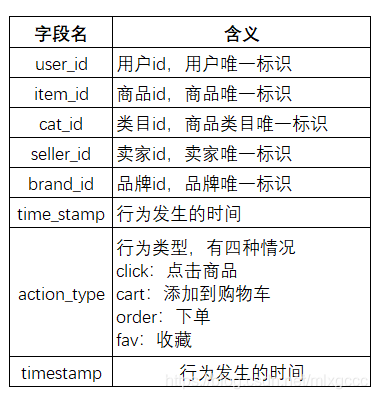
用户行为表:user_behavior_time_resampled.csv,包括
-
vip会员情况 vip_user.csv

-
用户信息情况 user_info.csv
-

用excel单独点开各自csv,发现三个表数据的量级分别是1100万,30万和40万,用excel操作比较费力。
因而需要用python中的pandas等库进行分析处理。
整个过程包括 数据预处理-异常值剔除-按照要求进行处理分析
分析过程
a. 导入有关数据
import pandas as pd
df_user_log = pd.read_csv("data/user_behavior_time_resampled.csv")
df_user_info = pd.read_csv("data/user_info.csv")
df_vip_user = pd.read_csv("data/vip_user.csv")
# 查看有关数据
df_user_log
df_user_info
df_vip_user
b. 异常值分析-时间节点
在第一个行为表中出现了time_stamp与timestamp两个情况,需要对两个数据展开分析分别代表用户的哪种时间行为。
在数据表中
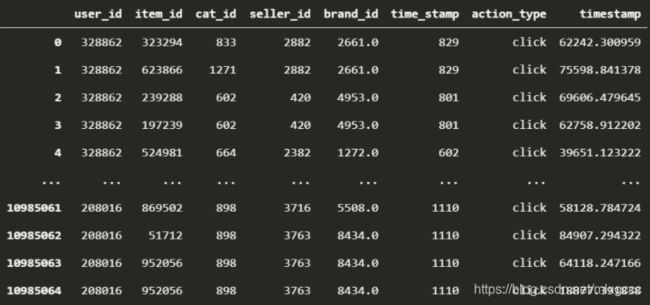
两个时间戳字段 time_stamp 和 timestamp 的值是不一样的。 time_stamp 看起来是个整数,值比较小,而 timestamp 看起来是个浮点数,值比较大,普遍在五位数,其他看不出来。
对于不明确的数据,一般用的是看边界:也就是看整个列中最大值与最小值,输入代码:
time_stamp_max = str(df_user_log['time_stamp'].max())
time_stamp_min = str(df_user_log['time_stamp'].min())
print("time_stamp max: " + time_stamp_max, "time_stamp min: " + time_stamp_min)
timestamp_max = str(df_user_log['timestamp'].max())
timestamp_min = str(df_user_log['timestamp'].min())
print("timestamp max: " + timestamp_max, "timestamp min: " + timestamp_min)
结果显示:
time_stamp max: 1112, time_stamp min: 511
timestamp max: 86399.99327792758, timestamp min: 0.10787397733480476
由此可见,time_stamp 的最大值为 1112,最小值为 511,而 timestamp 的最大值为 86399.99 最小值为 0.1。
考虑到是要对近6个月的情况进行分析,511-1112,更像是5月11日至11月12日近半年的情况,而timestamp的最大值为86399,根据一天24小时,每小时60分,每分60秒,一天86400s,所以这列数据为每天的第几秒发生了操作这个行为。
补充知识:在日期分析时,需要对【86400】敏感,因为一天共有86400s
随后对 time_stamp进行重命名
# time_stamp 改为 date
df_user_log.rename(columns={'time_stamp':'date'}, inplace = True)
df_user_log
c. 清洗各表数据
这里首先对空值进行统计,用的是pandas中的isnull.sum
- 对于log表进行清洗
# 清洗表1数据
df_user_log.isnull().sum()
输出结果:
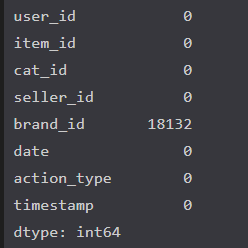
18132对于整个1100万数据来说,缺失率为0.1%,占比较小,所以可跳过不进行额外处理。
- 对于info表进行清洗
df_user_info.isnull().sum()
结果:
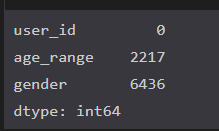
对于整体30w数据,缺失值影响也不大,但考虑到后面还要对年龄和性别进行描绘,所以要对异常值进行删除处理。
操作代码:
df_user_info = df_user_info.dropna()
df_user_info
查看处理过的数据情况
print(df_user_info.loc[df_user_info["age_range"] == 0.0, ["user_id"]].shape)
print(df_user_info.loc[df_user_info["gender"] == 0.0, ["user_id"]].shape)
# 第一行代表年龄为空的记录数,第二行代表性别为空的记录数。
结果:
(90638, 1)
(285634, 1)
补充-缺失值处理方法(pandas)
查看缺失值:
按单元格查看:df.isna()
按列查看:df.isna().sum()
按行查看:df.isna().sum(1)
有缺失值的列:df.loc[:, df.isna().any()]
有缺失值的行:df_scores.loc[df_scores.isna().any(1),:]
缺失值总个数:df.isna().sum().sum()
处理缺失值:
删除缺失值:df.dropna()
缺失值替换:df.fillna()
缺失值插值(线性):df.interpolate()
处理重复值:
查看重复行:df.duplicated()
删除重复行:df.drop_duplicates()
- 清洗vip表
代码:
df_vip_user.isnull().sum()
结果:

这个表数据完整,不需要做清洗。
c. 数据分析环节
(1)用户年龄分布分析
df_user_info.age_range.value_counts()
结果:
3.0 110952
0.0 90638
4.0 79649
2.0 52420
5.0 40601
6.0 35257
7.0 6924
8.0 1243
1.0 24
用tableau可视化:

由图可见:
取值为 3.0 和 4.0 的占到绝大多数,根据上面数据集的定义,取值为 3 代表 25~30 岁,取值为 4 代表 30~34 岁。
所以年龄在可以得到, 25~34 岁之间的用户占绝大多数。(age_range 取值 3.0、4.0)。
然后,我们可以通过代码计算出 25~34 岁用户的比例。首先通过 loc 函数筛选出所有不等于 0 的记录,然后计算年龄段等于 3.0 与年龄段等于 4.0 的总数除以所有非 0 记录的总数,计算的代码如下:
user_ages = df_user_info.loc[df_user_info["age_range"] != 0, "age_range"]
user_ages.loc[(user_ages == 3) | (user_ages == 4) ].shape[0] / user_ages.shape[0]
计算结果发现:25~34 岁用户占到了 58% 的比例
换句话说,平台对于未成年人购买控制较好,而平台购买的主力人群是中青年。
(2)用户性别分布分析
采用value_counts 分析,代码如下:
df_user_info.gender.value_counts()
输出结果
0.0 285634
1.0 121655
2.0 10419
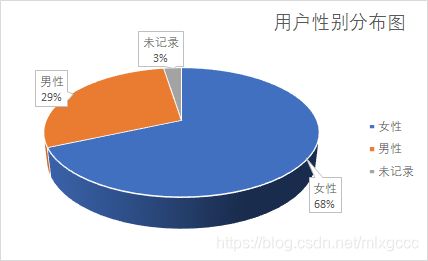
数据显示,女性是男性购买数量的2.35倍。
从用户群体的分析上,已经大概勾勒出我们的目标用户画像,25~34 岁之间的女性群体。但目前分析的只是注册用户的信息,需要结合其他表对购买情况来分析,从购买力的角度出发去判断。
(3)不同年龄段用户下单行为分析
前边提到过,三个表都有字段:user_id,并且该字段是唯一属性,那么可以将所需表通过user_id联结起来(类比sql知识)
# 第三步 user_log与user_info合并
df_user_log = pd.read_csv("data/user_behavior_time_resampled.csv")
df_user_log.rename(columns={'time_stamp':'date'}, inplace=True)
df_user_log = df_user_log.join(df_user_info.set_index('user_id'), on = 'user_id')
df_user_log
结果:
这里我们需要过滤出下单用户判断其购买力,如果是excel可以直接筛选,但是数量级较大,则需要用pandas中的loc模块
# 第四步分析和并表,从不同年龄段分析
df_user_log.loc[df_user_log["action_type"] == "order", ["age_range"]].age_range.value_counts()
# 数据集定义应该为 action_type = order
输出结果
3.0 172525
4.0 153795
0.0 114908
5.0 79298
6.0 61534
2.0 59072
7.0 10785
8.0 1924
1.0 21
购买人群年龄分布图
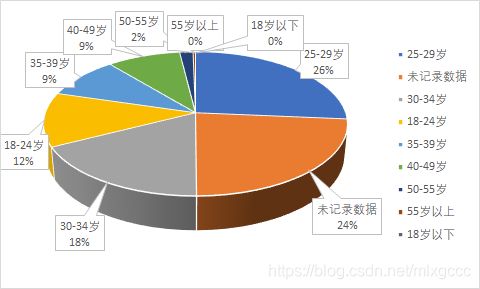
重点关注的还是最终的下单转化情况,所以我们筛选了行为为 “order”的记录,查看其年龄段分布。
可以看到,下单的年龄段分布和用户信息的分布基本一致,25-34 岁的人占到 59.9%。
(4)不同性别用户下单行为分析
类比年龄,条件筛选改为性别
df_user_log.loc[df_user_log["action_type"] == "order", ["gender"]].gender.value_counts()
输出结果
0.0 467381
1.0 161999
2.0 24482
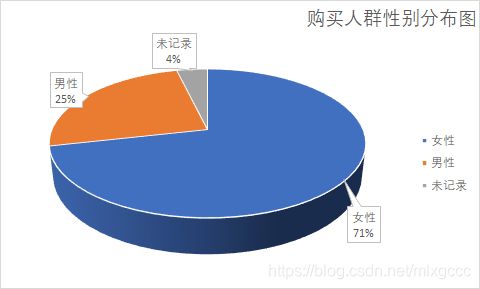
可以看到,女性用户不仅注册用户远超过男性,购买力同样惊人,是男性下单量的 2.9 倍。
基本可以确定,营销信息要聚焦的用户群应该是 25~34 岁的女性。
(5)不同日期的下单行为分析
这里可以对date日期进行value_count,但若是可以对日期进行精准匹配,效果会更好,那么:
通过给 value_counts 函数增加 bins 参数,bins 的值代表要分成几组,之后的数据分布就会按组输出。在这里,因为数据集是半年的,所以我们分六组(看每个月的分布)
PS.精细分上下半月可以分成12个bins,分成6个月的代码:
df_user_log.loc[df_user_log["action_type"] == "order", ["date"]].date.value_counts(bins = 6)
输出结果:
(1011.0, 1111.0] 333721
(811.0, 911.0] 70699
(911.0, 1011.0] 69427
(510.399, 611.0] 68776
(611.0, 711.0] 62901
(711.0, 811.0] 54053
Name: date, dtype: int64
转化成图表(tableau)-气泡图

接下来对于每天下单时间进行解析,这里更倾向于基于小时级的数据去分析。
所以我们考虑基于 timestamp 这一列,新创建一列时间,来表示小时。
在这里,我们就是以 timestamp 列为基础,将其值除 3600, 然后用这个值创建一个新的列:time_hours_view.
直接用 value_count 来统计新增的 time_hours_view 字段,就可以实现对一天中的小时级分布进行分布统计。我们以两个小时为尺度,来查看分布,所以分为 12 组,也可以分成24组,查看每小时的下单数。
# 第七步 不同时间段的下单情况分析
# time_stamp 记录的是每条记录的下单时间,从当天零点的记录值
# 创建新列:time_hours_view
# df_user_log.loc["time_hours_view"] = df_user_log["timestamp"]/3600
df_user_hour = df_user_log["timestamp"]/3600
# 以两个小时为跨度,查看分布情况
df_user_log.loc[df_user_log["action_type"] == "order", ["time_hours_view"]].time_hours_view.value_counts(bins = 12)
# 以一个小时为跨度,查看分布情况
df_user_log.loc[df_user_log["action_type"] == "order", ["time_hours_view"]].time_hours_view.value_counts(bins = 24)
每小时的下单情况结果:
(21.0, 22.0] 47204
(20.0, 21.0] 47005
(19.0, 20.0] 46476
(22.0, 23.0] 46098
(23.0, 24.0] 45431
(18.0, 19.0] 44854
(17.0, 18.0] 44147
(16.0, 17.0] 41534
(15.0, 16.0] 39146
(14.0, 15.0] 36226
(13.0, 14.0] 33298
(12.0, 13.0] 30282
(11.0, 12.0] 27007
(10.0, 11.0] 23902
(9.0, 10.0] 20777
(8.0, 9.0] 18161
(7.0, 8.0] 15118
(6.0, 7.0] 12844
(5.0, 6.0] 10575
(4.0, 5.0] 8853
(3.0, 4.0] 6999
(2.0, 3.0] 5640
(1.0, 2.0] 4412
(-0.025, 1.0] 3588
各时间段下单情况树状图:

柱状图:
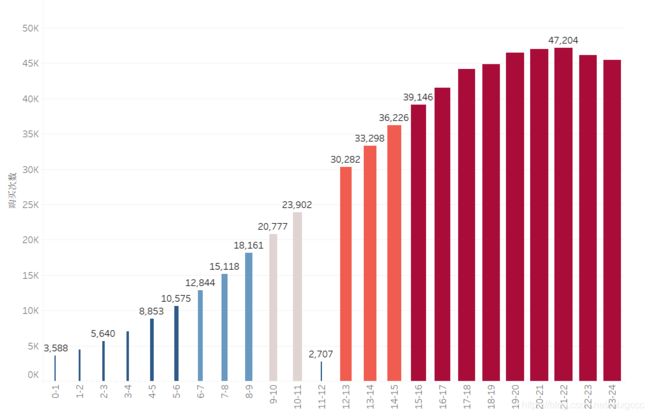
从上面图标可以看出,尽量避开中午11-12点进行促销信息投送,晚间17点之后是下单高峰期,建议在该时段进行广告投放。
第一个项目数据分析小结
考虑投放成本,如果成本/时间有限,那么:
用户首先应该针对 25~34 岁的女性,
优先投放时间为10 月中下旬到 11 月中旬
优先投放时间为晚上 5 点之后
其次根据成本,按照高比例目标群体进行短信投放
第二个项目:回归模型预测出产品销量**
项目背景:
根据用户行为记录,预测出每款商品的销量,这样可以提前知会供应商按照预测销量进行准备,避免之前准备不足的问题.
项目准备
仍是第一个项目所用的三个表格,具体字段解释也如同表1.
整个项目进行目标拆解:
数据清洗——分析指标拆解——特征工程——训练模型输出结果
1. 数据清洗
首先导入库
import pandas as pd
import numpy as np
df_user_log = pd.read_csv("data/user_behavior_time_resampled.csv")
df_user_info = pd.read_csv("data/user_info.csv")
df_vip_user = pd.read_csv("data/vip_user.csv")
结果(以log表为例):
接着要对缺失值进行查看:
df_user_log.isnull().sum()
结果:
user_id 0
item_id 0
cat_id 0
seller_id 0
brand_id 18132
time_stamp 0
action_type 0
timestamp 0
click 0
cart 0
order 0
fav 0
dtype: int64
第二个项目主要对用户行为(click、fav、order、cart)进行分析,对brand要求不高,所以不对缺失值进行插值/删除等异常值处理。
对关注的用户行为进行统计:
df_user_log["action_type"].value_counts()
结果:

```python
# 分别插入 click、cart、order、fav 四列,表示点击、加购物车、下单和收藏
# 规则见上面的文字描述
# 这里用到了lambda表达式,这是一种精简的函数表示法:
# def fn(参数):
#return 参数表达式
df_user_log["click"] = df_user_log.action_type.apply(lambda l:1 if l=="click" else 0)
df_user_log["cart"] = df_user_log.action_type.apply(lambda l:1 if l=="order" else 0)
df_user_log["order"] = df_user_log.action_type.apply(lambda l:1 if l=="fav" else 0)
df_user_log["fav"] = df_user_log.action_type.apply(lambda l:1 if l=="cart" else 0)
# 查看添加之后的 user_log 表
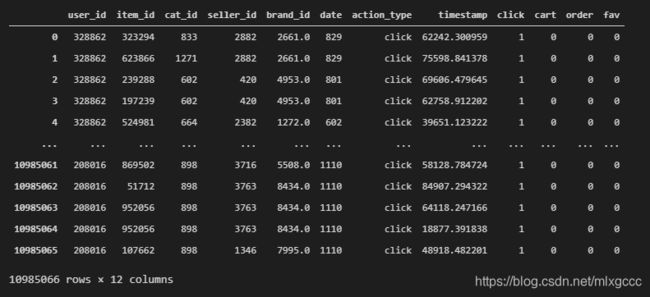
``
2. 目标拆分
我们更关注的指标是用户下单数,而在对下单数产生影响的有 点击数、加购物车数、收藏量以及从店铺角度出发的用户数、商品数等。
ps.正常在做商业数据分析通常思考的维度是人、货、物。
人:用户分析——用户的新增/活跃情况,时段分布、渠道用户、地域分布及启动/激活情况
货:产品分析——产品分析了解产品的浏览量、点击量、订单、入篮量、购买用户数等信息,帮助企业了解不同商品、不同品牌用户的关注度、购买力等信息。
物:场景运营分析,从用户体验的角度来分析,对各个购物场景进行优化,提升用户的体验,增强用户粘性。
# 商品维度——查看数据分布
print("click 数据分布:\n",df_user_log.click.value_counts())
print("order 数据分布:\n",df_user_log.order.value_counts())
print("fav 数据分布:\n",df_user_log.fav.value_counts())
print("cart 数据分布:\n",df_user_log.cart.value_counts())
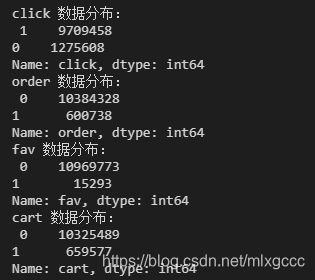
挑选出相关性高的:
df_clean = df_user_log[["item_id", "click", "cart", "order","fav"]]
df_clean
结果:
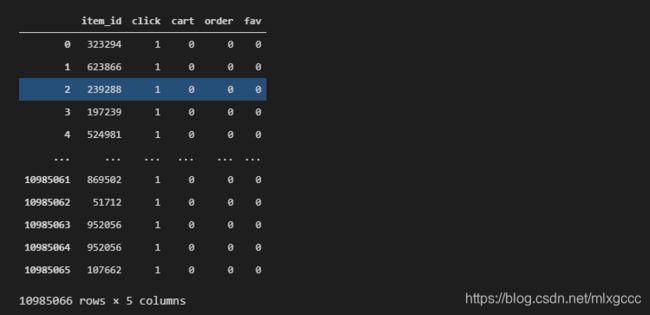 按照要求进行聚合
按照要求进行聚合
# 按照“item_id”进行聚合
df_item = df_clean.groupby(["item_id"]).sum()
df_item
# 从结果上看,我们以2号商品为例,它总计是点击511次,加车67次,下单60次,没有被加入到收藏夹

接着从商家角度出发进行数据整合及分析
商家表在三个表中都有涉及,首先对数据量较小的vip表进行查看
发现,原字段是“merchant_id”,所以先改名,然后根据要求进行筛选
# 重命名 merchant_id 为 seller_id
df_vip_user = df_vip_user.rename( columns={"merchant_id" : "seller_id"})
# 选取 seller_id和label 这连烈,斌将结果通过 seller_id 聚合,相同 seller_id 的记录的label求和
df_brand_vip_users = df_vip_user[["seller_id","label"]].groupby("seller_id").sum()
# 查看保存了店铺 vip 用户数的表的内容
df_brand_vip_users
# 解释:第二个店铺(店铺id=2)有着2个vip用户
结果:
seller_id label
2 2
8 1
9 1
10 16
13 15
... ...
4987 0
4988 2
4991 0
4992 73
4993 4
接着需要计算每个店铺的商品数
计算店铺的商品数,首先我们可以从用户行为表中筛选出 seller_id 和 item_id。 因为我们只关心店铺的商品数,所以我们可以先按 item_id 去重,这样留下来的记录就是商品的总数。然后我们在这个表的基础上,将 item_id 列都赋值为 1 ,然后再按 seller_id 聚合,让 item_id 做求和的运算,就可以得出每个 seller_id 对应的商品数。
代码:
# 筛选出 seller_id 和 item_id
df_seller_item_count = df_user_log[["seller_id", "item_id"]]
# 按item_id 去重,因为 itemid 一样的记录,seller_id 肯定也一样,所以 seller_id没有影响
df_seller_item_count = df_seller_item_count.drop_duplicates("item_id")
# 将 item_id 列赋值为 1,方便做求和
df_seller_item_count["item_id"] = 1
# 按seller_id 聚合,然后针对 item_id 列求和
df_seller_item_count = df_seller_item_count.groupby("seller_id").sum()
# 将 item_id 列改为 item_count, 避免有歧义
df_seller_item_count = df_seller_item_count.rename(columns = {"item_id" : "item_count"})
# 查看结果
df_seller_item_count
结果:
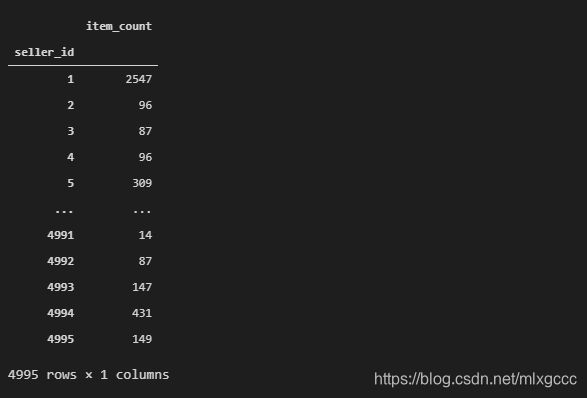
我们第二个店铺特征的表也准备好了,index 为 seller_id, 有一列 item_count 代表店铺的商品总数。
接着把商品与用户连接在一起。
先查看一下商品特征表
df_item
可以看到,目前商品特征表中只有 item_id,没有 seller_id。 所以没有办法直接关联店铺特征表。所以第一步,我们首先需要把商品特征表增加 seller_id 的字段。
要增加 seller_id,只需要我们用类似之前的方法,从原始的行为表中抽取出 seller_id 和 item_id 的对应关系表,然后再将对应关系表拼接进商品特征表中即可。代码如下:
# 从原始行为表中取出 item_id 和seller_id ,构成新表
df_brand_item_map = df_user_log[["item_id", "seller_id"]]
# 按照item_id去重,去重后得到的结果就相当于是 item id 和 seller_id 的映射关系
df_brand_item_map = df_brand_item_map.drop_duplicates("item_id")
# 将 df_brand_item_map 映射进 df_item, 以 item_id 为 key
df_item = df_item.merge(df_brand_item_map, how="left", on="item_id")
# 查看最新的商品特征表
df_item
结果:
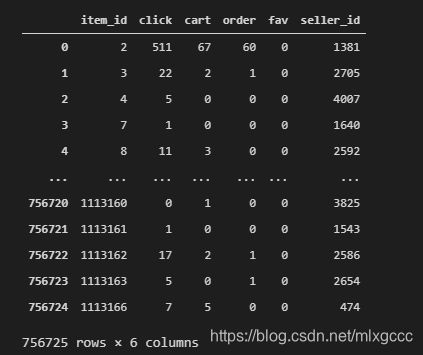
可以看到,现在商品特征表已经多了 seller_id 的字段,现在可以将两个店铺特征表拼接进商品特征表
首先拼接店铺的 VIP 用户数表。代码如下
# 将店铺vip用户特征表拼接到商品特征表中,以 seller_id 为 key
df_item = df_item.merge(df_brand_vip_users,how = "left", on="seller_id")
df_item
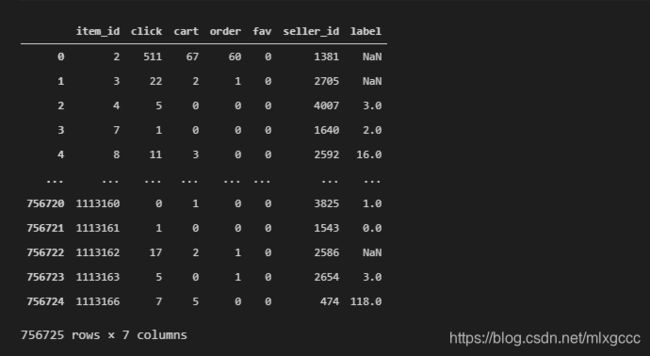
对于结果中的空值:
# 用 0 填充缺失值
df_item["label"] = df_item["label"].fillna(0)
df_item
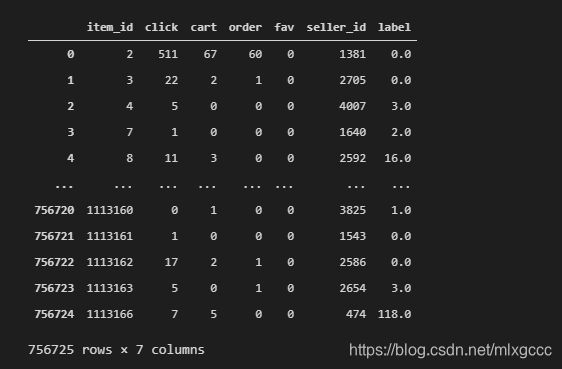
接着把需要的商品参数表添加到总表中
df_item = df_item.merge(df_seller_item_count, how = "left", on = "seller_id")
df_item

3.模型回归分析
#总表已经做好,现在要开始进行回归分析
#一般常见的做法是,将现有的数据拆成两份,比如 70% 一份,30% 一份。 70% 的数据用来训练模型,训练完之后用剩下的 30% 的数据进行测试。这样就能够在模型上线之前就能够衡量模型的好坏。sklearn 提供了现成的 train_test_split 函数,可以帮我们实现数据集的分割。
在这之前,需要:
#确定因变量和自变量。因变量是order列,商家最关心下单的情况。而自变量是除了order之外其他的参数。
# 导入分割的方法
from sklearn.model_selection import train_test_split
# 自变量的数据表(删去无关因素-order、seller_id、item_id)
X = df_item.drop(columns=["order", "seller_id","item_id"])
# 因变量
y = df_item["order"]
# 分别切割出训练集,测试集,测试机的比例是 20%
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20, random_state=42)
# random_state:随机数种子是为了保证每次随机的结果都是一样的
# 查看自变量的测试集合
X_train
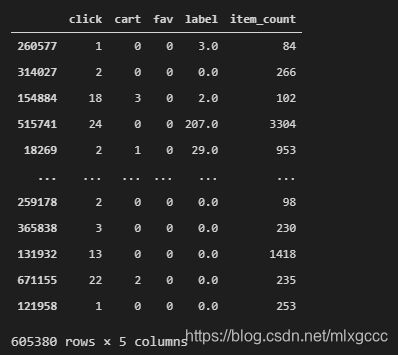
可以看出训练集有60w行,基本占原75w数据的80%。
建立线性回归模型
这次因变量和自变量参数都较少,直接调用 fit 方法来从 X_train 和 y_train 中训练模型:
训练结束之后,我们可以用 linear_model 来 predict X_test,然后拿 predict 函数返回的结果和 y_test 比较,就能知道我们模型的误差:
代码:
# 创建线性回归
from sklearn.linear_model import LinearRegression
linear_model = LinearRegression()
linear_model.fit(X_train, y_train)
# predict X_test 对应的 y 值
y_pred = linear_model.predict(X_test)
# 用 scores 方法,查看模型自变量和因变量的相关性
print("Scores:", linear_model.score(X_test, y_test))
# 查看 predict y 和 y test的平均绝对误差 print("MAE:", mean_absolute_error(y_test, y_pred))
# 查看模型的 b 值
print("intercept:", linear_model.intercept_)
# 查看模型的系数
print("coef_:", linear_model.coef_)
结果:
Scores: 0.5953635262886714
intercept: 0.21366637452290682
coef_: [1.90125287e-02 2.27102336e-01 3.48815749e+00 2.33892260e-03
8.03289578e-05]
MAE: 0.99399
PS. MAE=平均绝对误差(Mean Absolute Error),观测值与真实值的误差绝对值的平均值
模型的相关性分数说 0.44, 对于现实世界中的回归问题来说,这也算是个不错的成绩,说明我们的特征还是很大程度能够影响下单量。MAE 是 0.99,说明对于测试集而言,我们模型预测的结果和实际的真实结果非常接近,说明模型的拟合还是比较好的。
从模型系数中可以看到,我们的前三个特征:click、fav、cart 的系数比较大,后两个特征 label 和 item_count 的系数比较小,说明对于商品的下单量而言,前三个特征更加重要,关联性更强,后两者则对结果影响相对较小。
有时候凭我们的主观判断,对于特征的重要性判断可能是不准的
在这里都一并带上,然后在模型训练的环节,通过拟合算法自动去找到不同特征的重要性。
可以测试一下线性模型,我们做一次示例:
# 示例:假设某个商品在预热期间,一共有50次点击,2 次加购物车,4 次收藏,这个商品所在的店铺有 10 个vip 用户,一共有 20 个商品。那根据我们的模型来预测这个商品的下单数:
print(linear_model.predict([[50, 2 ,4, 10, 20]]))
输出结果:15.5次

总结以下第二个项目的思路与方法:
通过 df.groupby(“xxx”).sum() 的形式来聚合数据表;
通过 df.merge函数来拼接数据表,前提是两个数据表有相同的字段;
通过 train_test_split 来将数据集拆分为训练集和测试集;
通过LinearRegression 来建立线性回归模型。