李宏毅机器学习课程视频笔记5:Transformer
文章目录
- Seq2seq模型的应用
- Transformer模型介绍
-
- Encoder
- Decoder
-
- Autoregressive Decoder
- Non-Autoregressive Decoder
- 怎么训练Transformer模型
-
- Training Tips
- 参考资料
Transformer模型本质上是一个sequence-to-sequence(简写为seq2seq)的model,input a sequence, output a sequence and the output length is determined by the model 生成序列式模型
Seq2seq模型,是针对任务类型进行的命名
Seq2seq模型的应用
Speech recognition(语音识别任务)
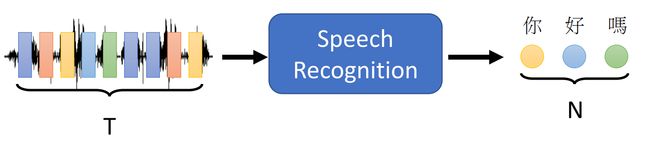
Machine Translation(机器翻译)

Speech Translation(语音翻译)

ps:这里对语音识别和语音翻译之间的区别进行说明,语音识别任务所做的是将声音讯号直接转换为对应语言的文字。而语音翻译则是将声音讯号转换为指定语言的文字。并且语音翻译并不是集成Speech recognition+Machine Translation来做的,于是Speech Translation可以针对性地处理那些没有文字的语言的声音讯号
Text-to-Speech(TTS) Synthesis 使用的一个名叫"echotron"的Transformer模型

Seq2seq for Chatbot
QA Answering

ps:由于大多数的NLP问题都可以转化为QA questions,Transfomer这样的Seq2seq模型是可以在很多NLP tasks上大显身手的
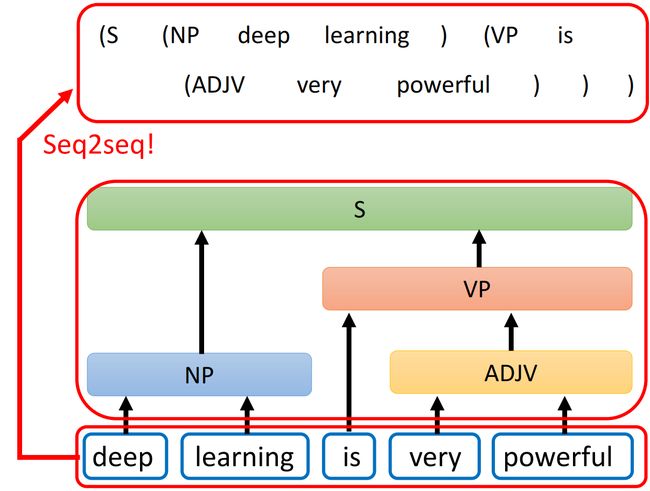
Syntactic Parsing(句法分析)
本来Syntactic Parsing的结果应该是一个句法分析结果树,通过将句法分析结果树转化为一个序列就能够应用Seq2seq模型
Multi-label Classification(多标签分类)
这里需要辨析Multi-class Classification和Multi-label Classification两种分类任务。Multi-class是每个object只属于一个class,所有object可以划分为多个class,Multi-label是每个object可能同时属于多个class,在对这个object进行分类的时候,需要将这多个class都找出来。而这多个class标签就可以组成一个序列,于是可以使用Seq2seq model

Object Detection(图像识别)

在这里使用的Seq2seq模型架构和经典的Transformer模型架构是非常相似的
Transformer模型介绍
Seq2seq模型图示

Transformer模型图示

Encoder
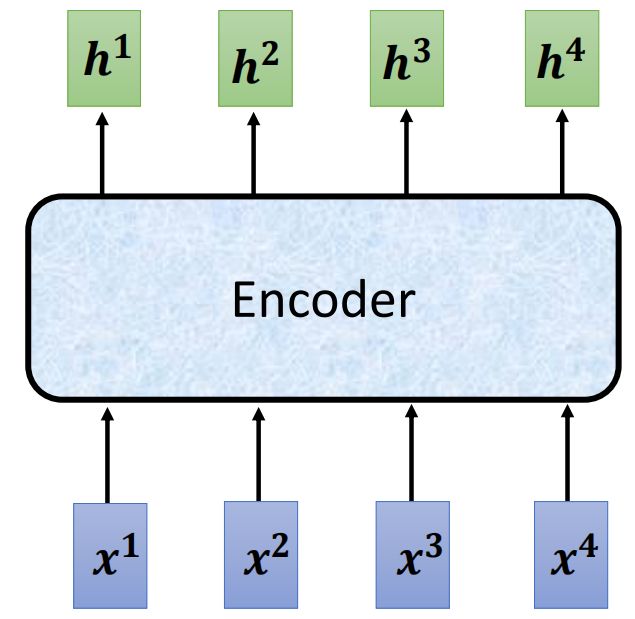
分析Encoder部分
从转换结果来看,Encoder部分是所做的事情是输入一组向量,输出一组向量,如下图所示
从这个层面而言,Transformer的encoder部分和RNN、CNN没有区别。
对Encoder部分进行分析,其可分为一个个的Block对input进行处理,每个block的input和output都是两个同样大小的向量组
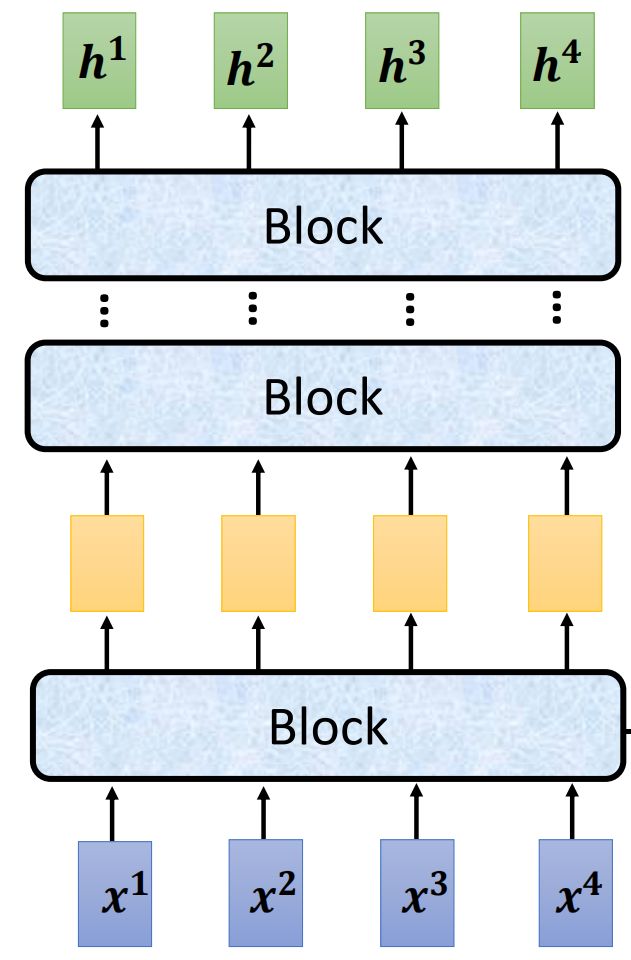
对Block进行细化分析,每个Block是包含好几个layer的
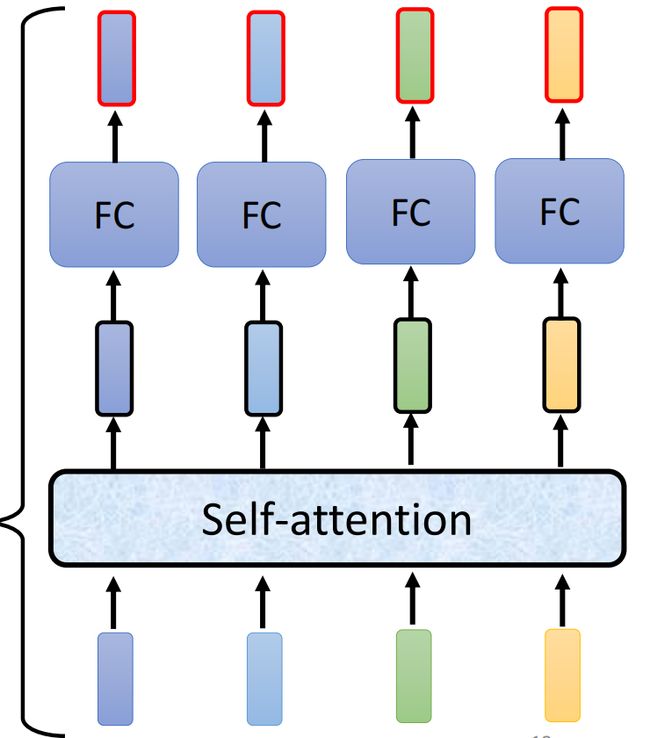
而每一个layer的组织方式都是类似的,经过Self-attention层或者Fully-connected层后,对得到的向量组进行residual connection处理(input&output addition)后,再对ouput进行layer Normalization
ps:这里的norm处理是layer norm,需要与batch norm区别开,layer norm是针对一个vector的各个维度进行归一化,而batch norm是针对batch中所有vector的同一维度进行归一化

观察Transformer内部,它引入了自注意力机制(Multi-Head Attention)和前馈神经网络(Feed Forward)作为子层,并且在每个子层处理之后都是用残差连接和层归一化(Add&Norm)对结果进行处理得到最后的输出
值得一提的是residual connection在Transformer中的使用,这有助于解决梯度爆炸和梯度消失的问题,使得长距离模型的构建与训练更加成功
Transformer的初始架构是在17年提出的,后来的学者在不断地修改以取得better performance
李宏毅教授列举了两篇讨论Transformer模型中layer normalization的文章
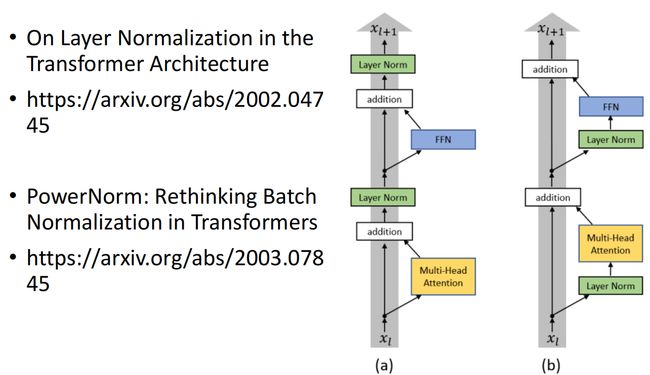
我们是否可以改变Add&Norm在Tranformer架构中的位置,layer Norm的效果为什么比batch Norm的效果好
Decoder
分析Decoder部分
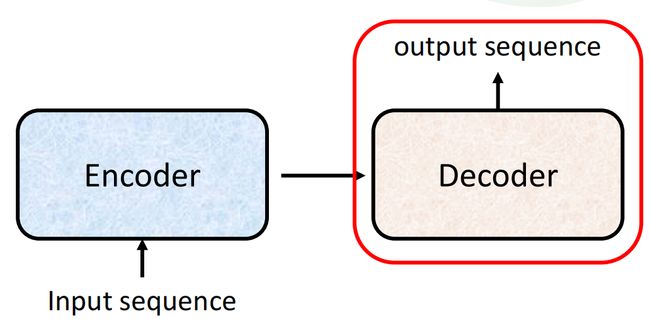
将Encoder的output作为input,经过处理后得到Transformer模型的output sequence
根据不同的设计思路,Decoder部分可以设计为Autoregressive的模型和Non-Autoregressive的模型。两者的区别在于Autoregressive模型生成序列的每个元素依赖先前生成的元素,从左到右依次生成;而Non-Autoregressice模型生成序列的每个元素是独立生成的,不依赖之前的结果,可以实现并行生成整个序列。
Autoregressive Decoder
Autoregressive Decoder的input包含Encoder的输出和当前序列元素之前的output序列

对于获得output的每一个序列元素,Decoder部分使用了softmax函数,输出每一个可能元素的probability,取几率最大的那个元素作为output元素,相当于一个vocabulary size大小的分类问题
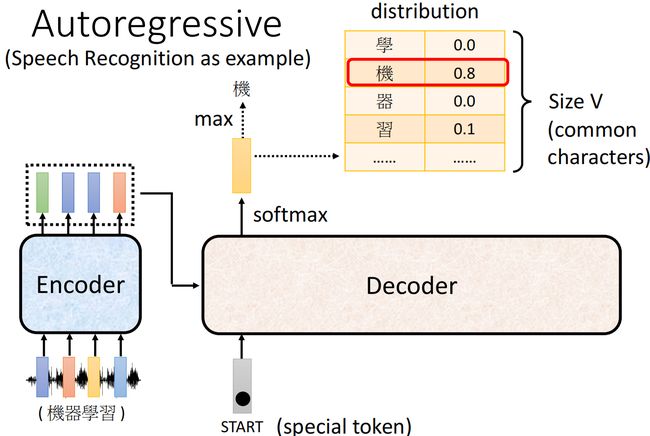
另外对于Autoregressive Decoder的处理机制,有一个潜在的error propagation(错误传播)的问题,若decoder得到了一个错误的序列元素,这个错误的序列元素将作为input参与下一个序列元素的生成
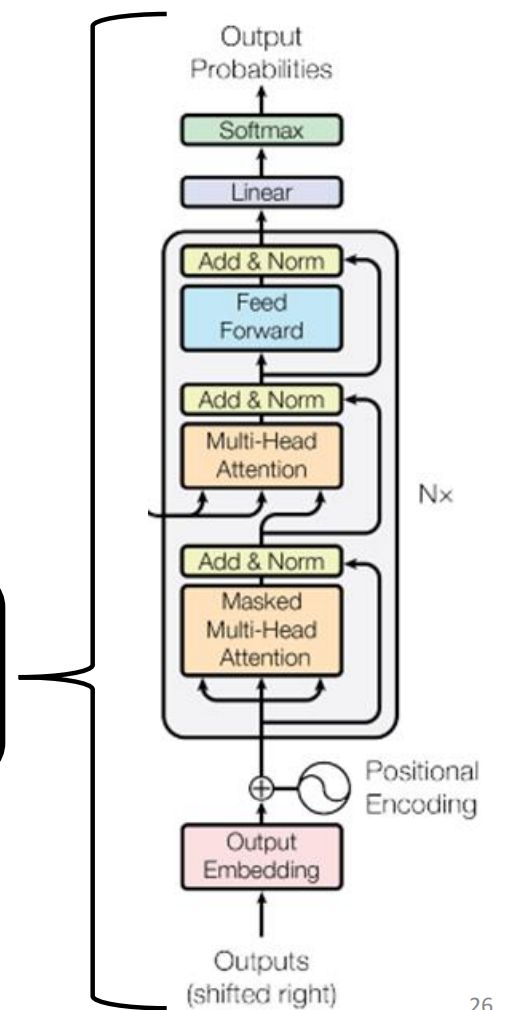
观察Decoder部分的模型架构
与Encoder部分对比,其block组成新增了一个Masked Multi-Head Attention层
对比Self-attention和Masked Self-attention
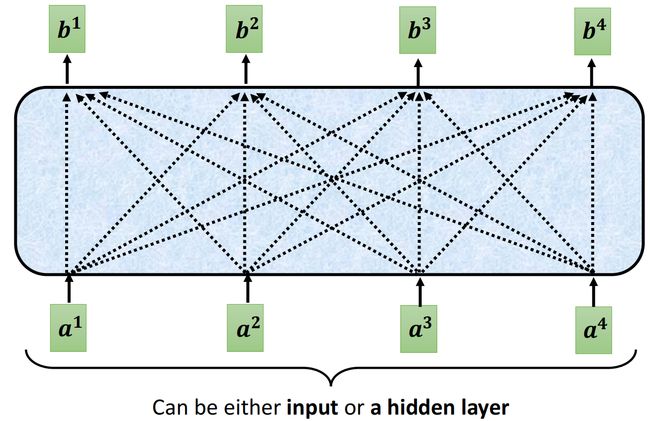

在这里考虑时,将b作为output,a作为input进行分析
如果是Self-attention的架构,产生output时,全部的input向量都是被纳入考虑的;而对于Masked Self-attention,产生output时,对input加入了constrain限制,“产生 b n b^n bn 时, a n + 1 a^{n+1} an+1 及之后的input向量是不被纳入计算的”
李宏毅教授在这里提出了两个问题
Why masked?
因为对于Autoregressive Decoder部分而言,其输入是包括Decoder部分的输出的,而其输出是一个一个序列元素依次产生的,即“在产生 b n b^n bn 时, a n + 1 a^{n+1} an+1 及之后的input向量是不存在的”。
How does decoder work?
在计算 b 2 b^2 b2 时,加入attention计算的是由 a 1 a^1 a1 得到的 k 1 、 v 1 k^1、v^1 k1、v1 和由 a 2 a^2 a2 得到的 q 2 q^2 q2 、 k 2 k^2 k2 、 v 2 v^2 v2 vector q和vector k相加,与vector v做weighted sum
另一个问题是How to know the correct output’s length? 也即Decoder何时停止产生序列元素
加入一个特殊的token,作为序列终止符
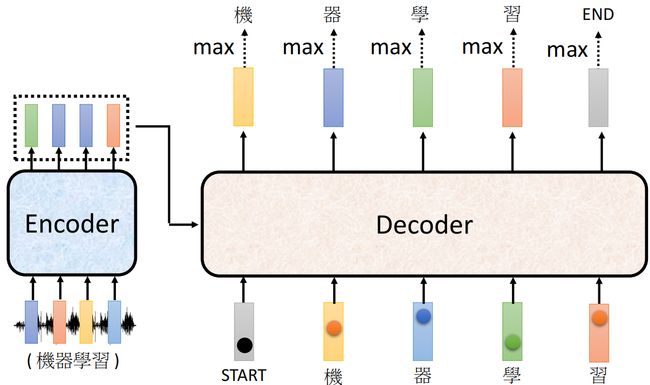
Non-Autoregressive Decoder

NAT模型的output序列长度?
第一种做法是加入一个确定output length的predictor跟decoder一起train
第二种做法是将输出一个足够长的包含end终止token的sequence,最后截取正确的sequence
对比AT模型和NAT模型?
AT模型考虑了之前生成的内容,因此相比NAT,AT生成内容更加准确,但AT是串行生成结果,生成速度慢并且不适合实时生成

在Decoder的Multi-Head Attention部分,Encoder提供了多个input,属于cross attention的使用
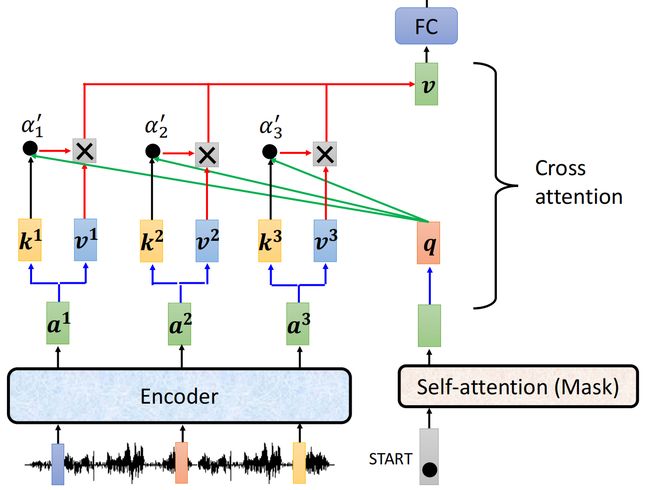
对于Encoder输出的每一个vector 的vector k部分,使用的是self-attention输出的同样的vector q进行处理,然后进行norm操作,与
vector v进行weighted sum得到最终结果
怎么训练Transformer模型

类似分类问题,最小化cross entropy的损失函数
Teacher Forcing:将真实的标签作为Decoder的输入进行训练
Training Tips
- Copy Mechanism(复制机制):在Machine Translation中专有名词的直接复用,在Chatbot中的上下文对话情景中的专有名词复用,Summarization中的使用。如Pointer Network
- Guided Attention:用于增强Transformer中self-attention模块,用于引导self-attention的attention weights,使得模型在生成序列时更专注于特定的位置或信息。如果仅仅是简单的自注意机制,注意权重是由该位置与其他所有位置的相似度来确定的。Guided Attention所做的是引入其他信息,如任务的先验知识等来影响这些注意权重。例如Machine Translation中,如果我们知道源语言中某个单词的翻译对应于目标语言的特定位置,我们可以使用Guided Attention使得模型更关注这些位置
- Beam Search:在序列生成任务中,一种生成候选序列的搜索方法。在每个待生成标记处都从模型生成的概率分布中选出几个最有可能的候选标记,这些标记称为beam。然后模型将每个beam作为input产生新的概率分布,重复上述步骤。
- Sampling:在Beam Search的基础上加上一定的randomness,或者使用某种 sampling method
- 使用RL来做optimization。训练Transformer模型时使用的策略是最小化the cross-entropy,而生成序列任务的评价标准是bleu score(一种常用于评价机器翻译模型性能的指标)
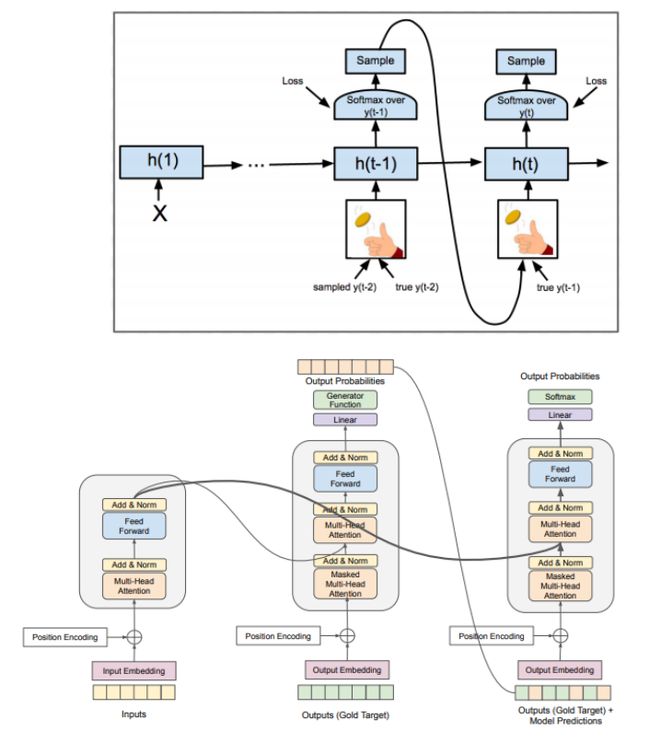
- Schedule Sampling:因为Transformer模型在训练时将样本的ground truth加入训练,而在测试时使用的是output,这造成了exposure bias问题。解决办法是在训练模型时加入错误的label来调节。常用method是schedule sampling,在训练过程中通过参数控制逐步减少ground truth作为input的比例,让模型逐渐适应自身生成的标记,以更好地处理训练和测试时的数据分布差异。
Schedule Sampling如下图所示
参考资料
- 李宏毅机器学习课程视频Transformer部分链接:https://www.youtube.com/watch?v=N6aRv06iv2g